1. Word Vector 학습의 원리
- 워드 벡터 모델의 목표는 단어를 숫자 벡터로 표현하여 단어 간의 의미적 유사성을 포착하는 것입니다.
- 이 과정은 경사 하강법(Gradient Descent)이라는 최적화 기법을 사용해 이루어집니다.
기울기 하강법 (Gradient Descent)
- 모델의 예측값과 실제값의 차이(손실 함수)를 줄이기 위해 매개변수를 조금씩 업데이트하는 방법입니다.
- 강의에서는 전체 데이터를 한 번에 사용하는 Batch Gradient Descent의 비효율성을 개선한 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 소개합니다.
- SGD는 데이터 일부만 사용하여 훨씬 빠르게 모델을 학습시킬 수 있습니다.
Word2Vec의 학습 과정
- 모델은 처음에 모든 단어 벡터를 무작위로 초기화합니다.
- 그리고 특정 단어(중심 단어)를 기준으로 그 주변 단어(문맥)를 예측하며 벡터 값을 조정해 나갑니다.
- 이 반복적인 과정을 통해 비슷한 문맥에 나타나는 단어들의 벡터는 서로 가까워지고, 다른 단어들의 벡터는 멀어지게 됩니다.
실습
- gensim 모델을 활용해서 단어의 유사도를 확인할 수 있고, 이를 통해, 특정 단어들과 유사하고 특정 단어들과 거리가 먼 단어를 계산을 통해 구할 수 있다
2. Word2Vec 모델의 효율성 개선
- 강의는 Word2Vec의 학습 효율을 높이는 두 가지 방법을 다룹니다.
네거티브 샘플링 (Negative Sampling)
- 기존 Word2Vec 모델은 모든 단어에 대해 예측 확률을 계산하는 소프트맥스(Softmax) 함수를 사용하는데, 이는 어휘집 크기가 커질수록 엄청난 연산 비용을 발생시킵니다.
- 네거티브 샘플링은 이 문제를 해결하기 위해, 긍정적인 단어(실제로 주변에 있는 단어)와 무작위로 선택된 소수의 부정적인 단어를 구분하는 이진 분류 문제로 바꾸어 연산량을 획기적으로 줄입니다.
- 이를 통해, 모델은 전체 vocabulary가 아니라, 단 한 개의 긍정 샘플과 몇 개의 부정 샘플만으로 학습을 진행하여, 비용이 많이 감소합니다.
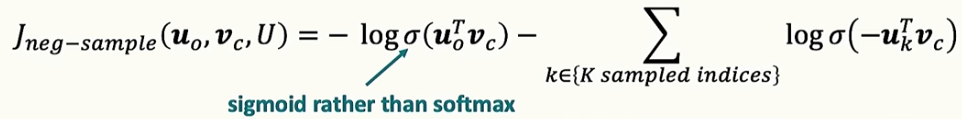
- 위의 손실함수 식처럼, 긍정 샘플인 는 커지도록 하고, 몇 개의 부정 샘플인 는 작아지게 합니다.
- 샘플링은 로 unigram Distribution의 3/4 제곱을 통해서, 빈도가 낮은 단어의 발생 확률을 상대적으로 증가해서 샘플링을 진행합니다.
카운트 기반 접근법과 GLoVE
- 강의는 Word2Vec과 같은 신경망 기반 방법 외에, 단어 동시 발생 횟수를 세어 단어 벡터를 만드는 카운트 기반 접근법을 소개합니다.
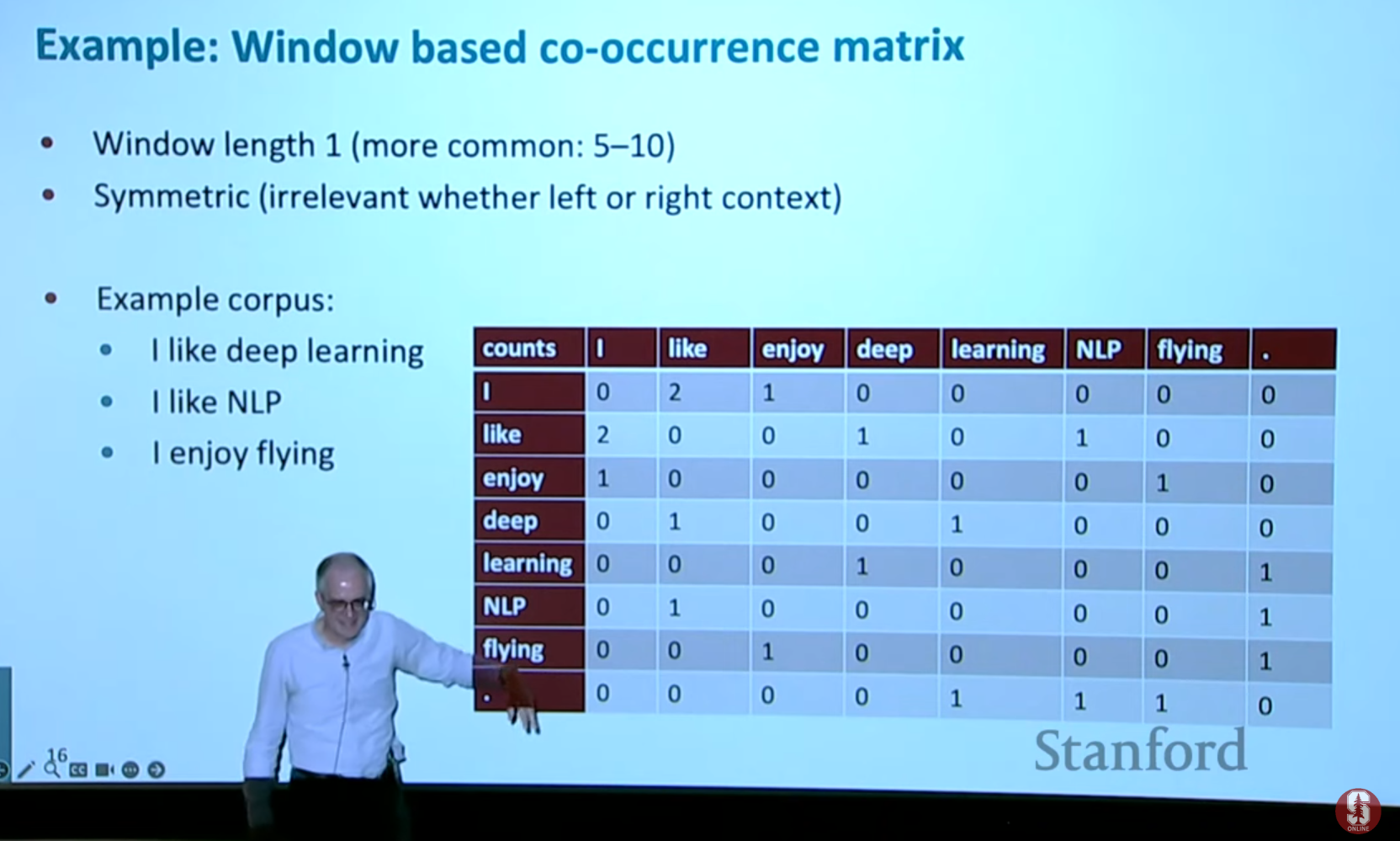
동시 발생 행렬(co-occurrence matrix)
- 텍스트 말뭉치에서 특정 단어(행)가 다른 단어(열)와 함께 얼마나 자주 나타나는지 횟수를 세어 행렬을 만듭니다.
- 이 행렬 자체가 단어 벡터로 사용될 수 있지만, 어휘집 크기가 크면 행렬이 너무 방대해져 다루기 어렵다는 한계가 있습니다.

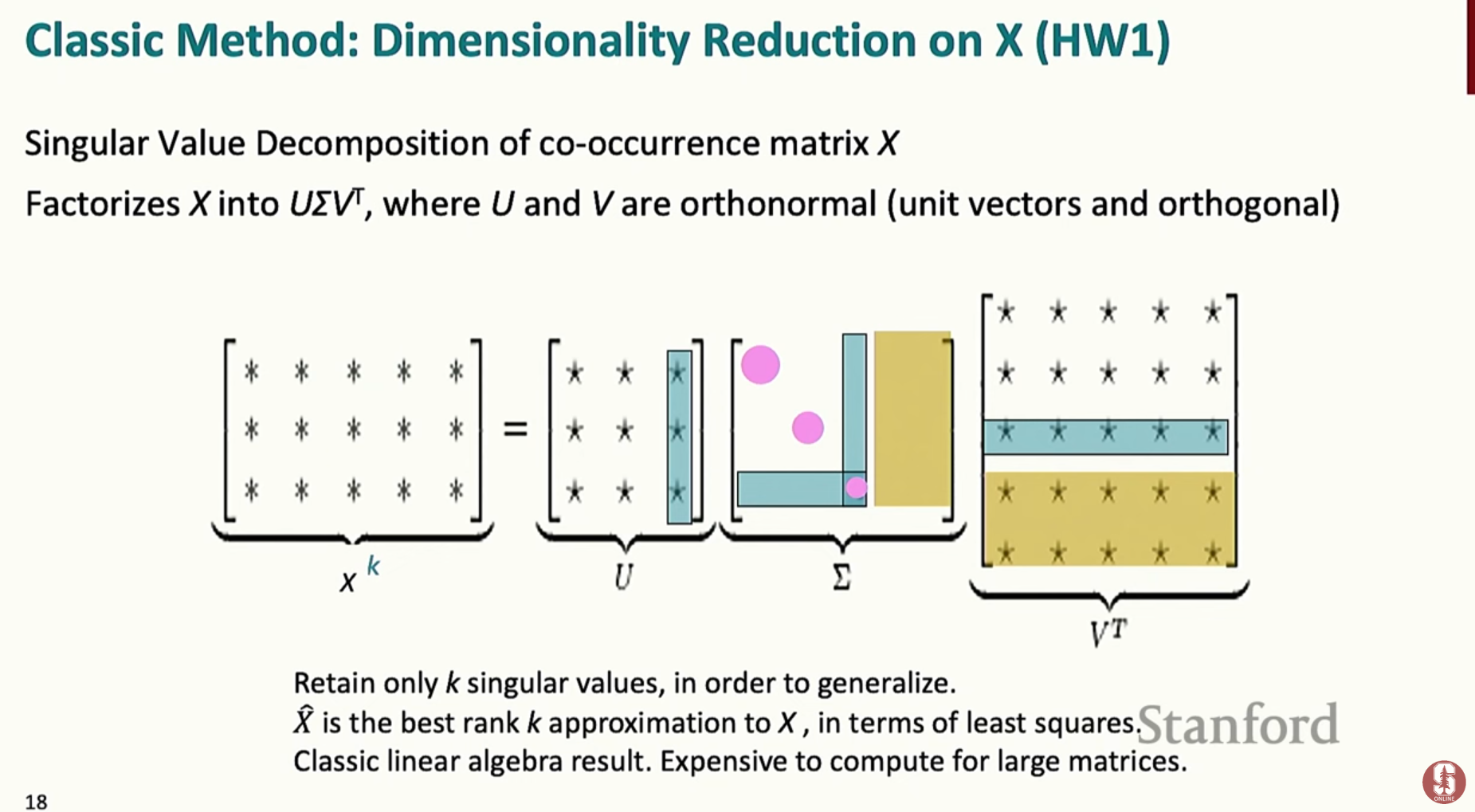
특이값 분해(SVD)
- 이 문제를 해결하기 위해 특이값 분해(SVD)를 사용해 거대한 동시 발생 행렬의 차원을 줄이는 방법을 설명합니다.
- SVD를 통해 가장 중요한 의미적 정보를 담고 있는 소수의 벡터만 남겨두고, 나머지는 버려서 효율적인 저차원 단어 벡터를 만들 수 있습니다.
GLoVE(Global Vectors for Word Representation)
- 강의는 이러한 카운트 기반 방법의 연장선상에서 GloVe 모델을 소개합니다.
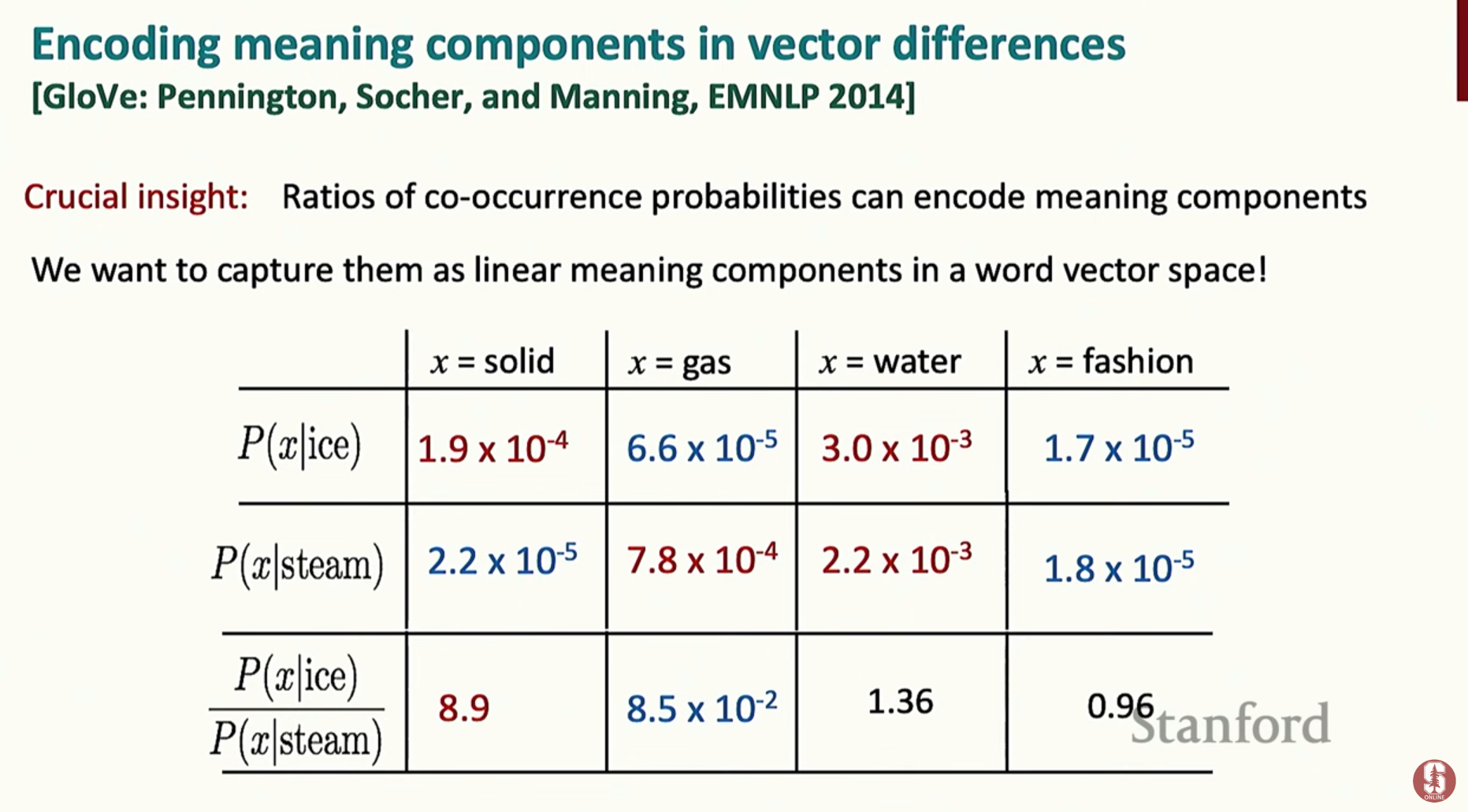
- GLoVE의 핵심 아이디어는 단어 간 동시 발생 확률의 비율을 사용해 의미적 관계를 포착하는 것입니다.
- 예를 들어, 'ice'와 'steam' 같은 단어가 다른 단어와 함께 나타나는 비율을 비교하여 '고체-물-기체'와 같은 의미적 차원을 모델링할 수 있음을 보여줍니다.
- GloVe는 단어 벡터의 내적이 동시 발생 확률의 로그 값과 비슷해지도록 학습하는 방식으로 작동합니다.

GLoVE 등장 배경
- GloVe(Global Vectors for Word Representation)는 Word2Vec과 LSA(잠재 의미 분석)의 장점을 결합하여 탄생했습니다.
- GloVe는 다음과 같은 두 가지 단어 벡터 학습 방식의 한계를 극복하기 위해 개발되었습니다.
1. 예측 기반 모델의 한계
- Word2Vec과 같은 예측 기반 모델은 중심 단어 주변의 문맥(local context)을 학습하는 데 뛰어나지만, 전체 말뭉치의 통계적 정보(global statistics)는 잘 반영하지 못합니다.
- 예를 들어, 한 단어의 전체적인 출현 빈도 같은 정보는 Word2Vec 학습 과정에서 간접적으로만 활용됩니다.
- 이로 인해 대규모 말뭉치 전체에 걸친 의미 관계를 포착하는 데 한계가 있었습니다.
2. 카운트 기반 모델의 한계
- LSA(잠재 의미 분석)와 같은 카운트 기반 모델은 전체 말뭉치의 단어 동시 발생 행렬을 만들어 학습합니다.
- 이는 전체적인 통계 정보를 잘 반영하지만, 단어 간의 복잡한 미세한 의미 관계를 포착하는 데에는 한계가 있었습니다.
- 특히, 행렬이 너무 커지면 연산 부담이 커지고 희소성(sparsity) 문제가 발생합니다.
GloVe의 목표
- GloVe는 이 두 모델의 장점을 모두 취하는 것을 목표로 합니다.
- 전체 말뭉치의 통계 정보 반영: 단어 동시 발생 행렬을 기반으로 하여 전체 말뭉치의 통계적 정보를 학습에 활용합니다.
- 미세한 의미 관계 포착: Word2Vec처럼 단어 벡터의 내적을 이용해 문맥 정보를 효율적으로 포착합니다.
GLoVE vs Word2vec
- GloVe는 기술적으로 Word2Vec의 한계를 보완하고 발전시킨 모델이지만, Word2Vec이 더 유명한 데에는 몇 가지 주요 이유가 있습니다.
1. 혁신성과 대중성
- Word2Vec은 2013년 구글에서 발표되었으며, 그전까지의 복잡한 언어 모델과 달리 단순한 신경망 구조로 고품질의 단어 벡터를 효율적으로 학습하는 방법을 제시했습니다.
- 이는 마치 게임의 규칙을 바꾸는 혁신처럼 여겨졌고, 자연어 처리 분야에 단어 임베딩 열풍을 불러일으켰습니다.
- 구글이라는 거대 기업의 발표와 함께 대중적으로 빠르게 확산되었습니다.
2. 직관적인 모델 구조
- Word2Vec의 핵심 아이디어인 '주변 단어를 예측한다'는 개념은 컴퓨터 과학 및 비전공자들에게도 직관적으로 이해하기 쉬웠습니다.
- 반면 GloVe는 단어의 동시 발생 행렬을 기반으로 하여 통계학적 개념이 더 강하고, 그 배경에 있는 수학적 원리가 상대적으로 복잡하게 느껴질 수 있습니다.
3. GloVe의 등장 시점
- GloVe는 Word2Vec이 발표된 지 약 1년 후(2014년)에 나왔습니다.
- Word2Vec이 이미 단어 임베딩의 개념을 대중화하고 시장을 선점한 상태였기 때문에, GloVe는 '새로운 패러다임'을 제시하기보다는 '기존 방법의 단점을 보완한 진화된 버전'으로 인식되었습니다.
- GloVe는 학술적으로 높은 가치를 인정받았지만, Word2Vec이 가져온 충격적인 첫인상을 넘어서기는 어려웠습니다.
3. 단어 벡터의 평가와 한계
- 단어 벡터의 성능은 다양한 방법으로 평가할 수 있습니다.

내재적 평가 (Intrinsic Evaluation)
- 내재적 평가는 모델이 학습한 단어 벡터 자체의 품질을 측정하는 방법입니다.
단어 유사성(Word Similarity)
- 벡터 공간에서 단어들 간의 거리를 측정하여 단어의 의미적 유사성을 평가합니다.
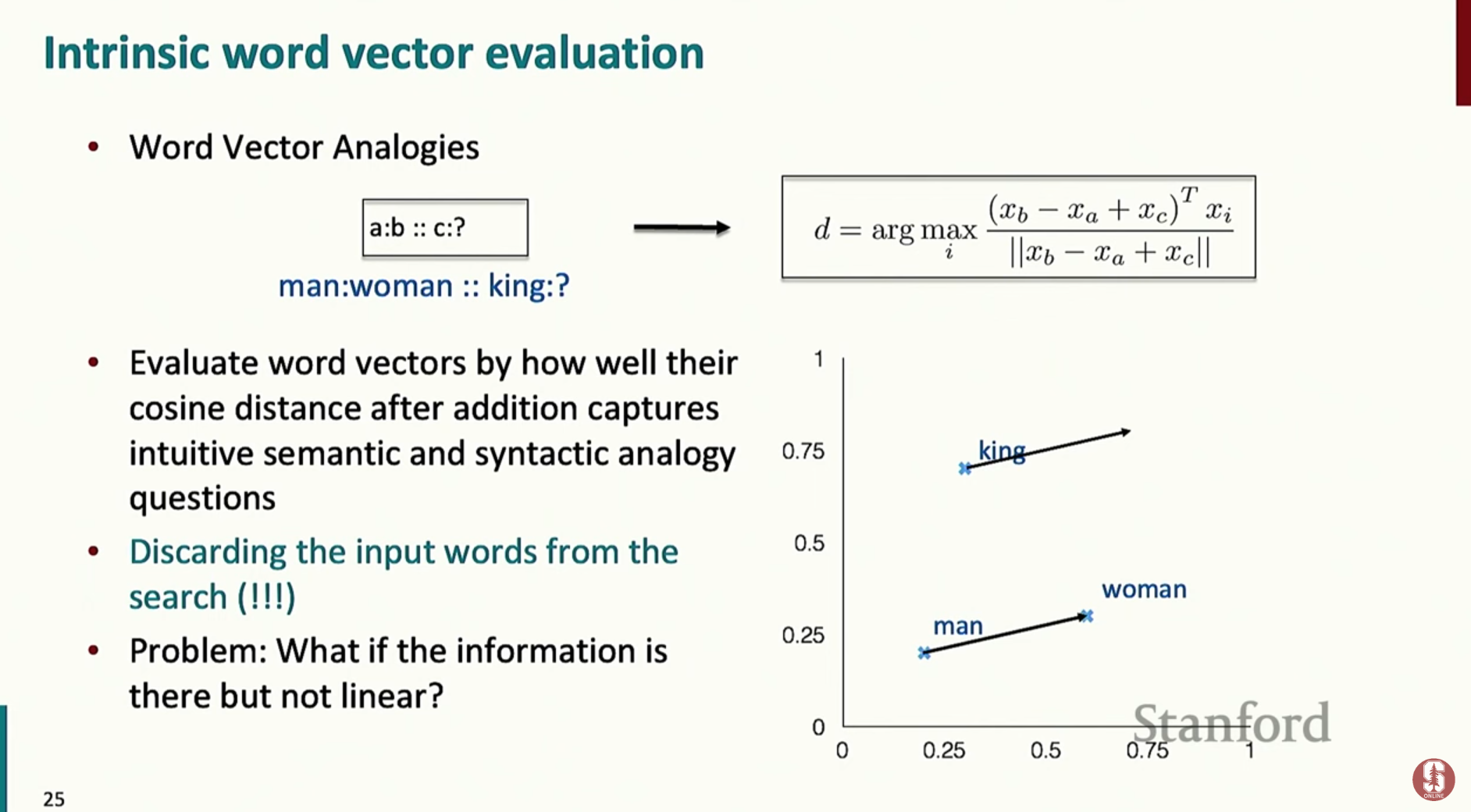
유추 작업(Analogy Task)
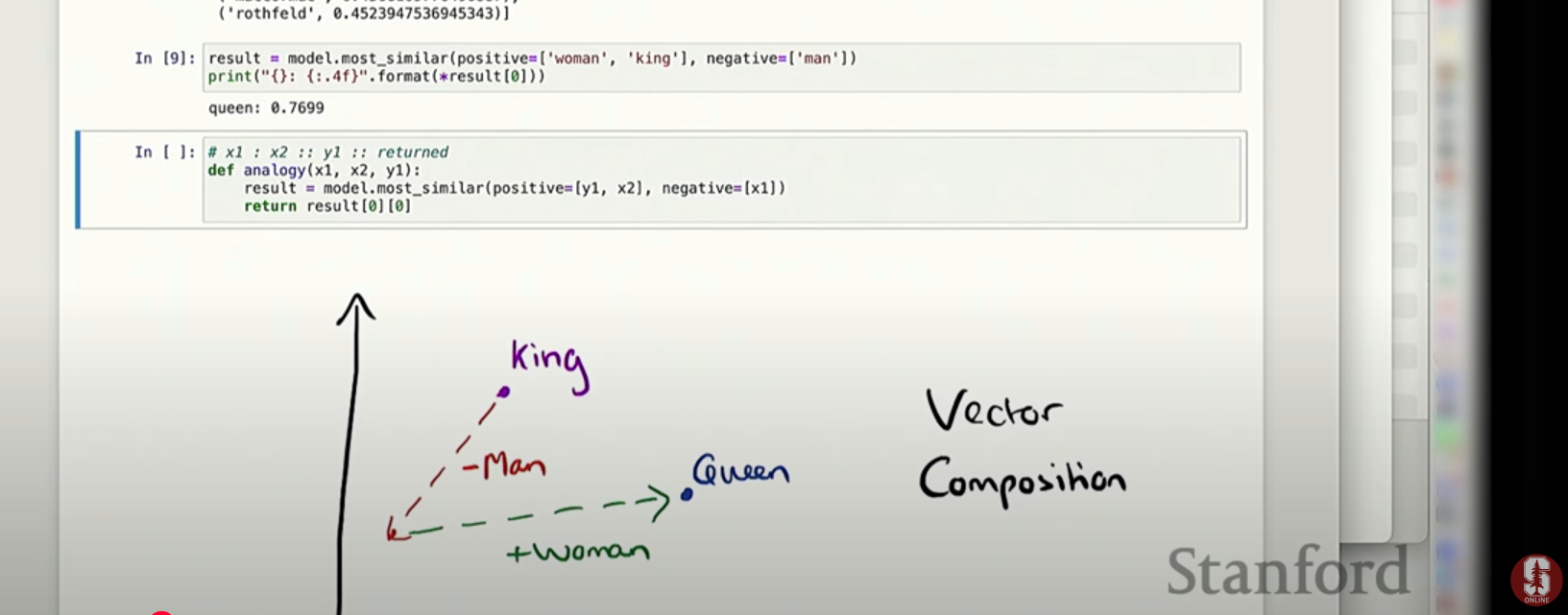
- 단어 벡터의 관계를 사용하여 유추 문제를 푸는 작업입니다.
- 예를 들어, '남자:왕 = 여자:여왕'과 같은 비례 관계를 벡터 연산을 통해 평가합니다.
외재적 평가 (Extrinsic Evaluation)
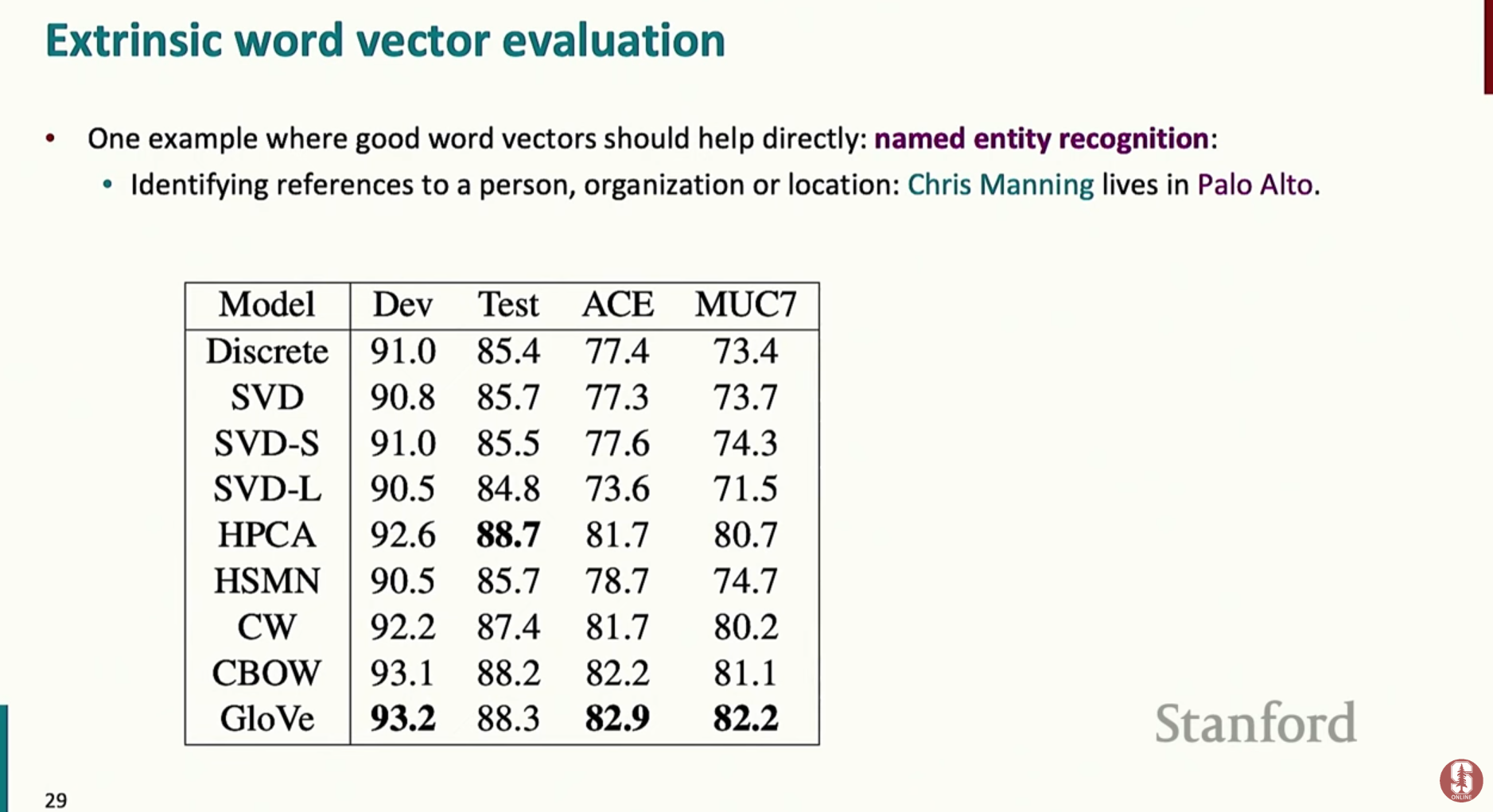
- 외재적 평가는 단어 벡터가 실제 자연어 처리 응용 작업에 사용될 때 얼마나 효과적인지를 측정하는 방법입니다.
실제 응용 작업
- 개체명 인식(Named Entity Recognition)과 같은 실제 태스크에 단어 벡터를 입력으로 사용하여, 그 최종 성능을 평가하는 것을 의미합니다.
한계
- 강의에서는 '파이크', '재규어'처럼 여러 의미를 가진 단어의 중의성(Polysemy) 문제를 언급하며, 단일 벡터가 모든 의미를 통합(superposition)하여 표현한다는 한계를 지적합니다.
4. 신경망 분류기 기초
- 강의 후반부에는 워드 벡터를 활용한 신경망 분류기의 기본 개념을 소개합니다.
구조
- 입력층(단어 벡터), 은닉층(행렬 곱과 활성화 함수), 출력층(분류 결과)으로 구성됩니다.
- 여러 단어 벡터를 컨텍스트 윈도우로 묶어 입력으로 사용하면 문맥을 고려한 분류가 가능해집니다.


- 위 구조는, museums in paris are amazing이라는 문장을 input으로 넣고, 각 단어가 center word가 되어, location(장소)를 의미하는 단어인지 주변 단어를 통해 판별하게 되는 구조의 신경망입니다.
개체명 인식(Named Entity Recognition)
- '워싱턴은 도시이다'라는 문장에서 '워싱턴'이 사람 이름이 아닌 도시 이름임을 문맥을 통해 파악하는 것이 대표적인 예시입니다.

💡 추가로 알았으면 하는 내용
1. Word2Vec의 두 가지 아키텍처
- 강의에서 언급된 Word2Vec에는 두 가지 주요 모델이 있습니다.
- 강의는 중심 단어를 통해 주변 단어를 예측하는 Skip-gram 모델을 주로 다루지만, 그 외에 CBOW(Continuous Bag-of-Words) 모델도 있습니다.
CBOW
- 주변 단어들(문맥)을 기반으로 중심 단어를 예측합니다.
- Skip-gram보다 학습 속도가 빠르며, 자주 등장하는 단어에 대해 더 좋은 성능을 보입니다.
Skip-gram
- 중심 단어 하나로 주변 단어들을 예측합니다.
- 드물게 등장하는 단어(rare words)를 더 잘 표현하는 경향이 있습니다.
두 모델은 서로 반대의 방향으로 학습하지만, 최종 목표는 비슷한 의미의 단어들이 가까운 위치에 있도록 단어 벡터를 학습하는 것입니다.
2. Word2Vec의 한계
- Word2Vec은 뛰어난 성능을 보이지만 다음과 같은 한계가 있어 후속 모델들이 등장했습니다.
의미의 중의성
- 강의에서 언급된 것처럼, 한 단어에 여러 의미가 있을 때(예: '사과' - 과일 vs. 행동), 하나의 벡터로는 여러 의미를 구분하기 어렵습니다.
OOV(Out-Of-Vocabulary) 문제
- 훈련 데이터에 없던 새로운 단어(미등록 단어)가 나타나면 해당 단어에 대한 벡터를 만들 수 없습니다.
- 이는 'subword information'을 사용하는 fastText 같은 모델이 등장하게 된 계기가 됩니다.

AI 공부합니다