1. 현대 신경망의 핵심 개념
정규화(Regularization)
- 손실 함수를 최소화하는 것을 넘어 모델 성능을 향상시키기 위해 학습된 매개 변수를 조작하는 것을 포함합니다.
- L2 정규화는 과적합을 방지하는 고전적인 접근법이었지만, 최신 신경망은 완벽한 손실을 달성하기 위해 훈련 데이터에 "과적합"하는 경향이 있으며, 여전히 잘 일반화됩니다.
드롭아웃(Dropout)
- 훈련 중에 네트워크의 중간 레이어에 대한 입력을 무작위로 "제거"하는 인기 있는 정규화 기술입니다.
- 이는 모델을 견고하게 만들고 기능의 공동 적응을 방지합니다.
벡터화(Vectorization)
- 딥 러닝 계산을 위해 for 루프 대신 벡터, 행렬, 텐서를 사용하여 CPU 및 GPU의 속도를 활용하는 것이 중요합니다.
매개 변수 초기화(Initialization)
- 대칭성을 깨고 학습이 효과적으로 이루어질 수 있도록 매개 변수를 작은 무작위 숫자로 초기화하는 것이 중요합니다. (Ex. Saddle point)
최적화 도구
- Adam과 같은 더 정교한 최적화 도구는 과거의 경사를 기반으로 각 매개 변수에 대한 학습률을 조정하여 훈련을 개선하므로 하이퍼 매개 변수를 올바르게 설정하는 것에 대한 의존도를 낮춥니다.
2. 언어 모델

- 언어 모델은 시퀀스에서 다음 단어를 예측하거나 텍스트 조각에 확률을 할당하는 시스템입니다.
- 과거에는 짧은 단어 시퀀스(예: 바이그램, 트라이그램)의 빈도를 세어 확률을 추정하는 N-그램 모델을 사용하여 언어 모델을 구축했습니다.
- 이 모델은 구축하기 쉽지만, 컨텍스트 크기가 증가함에 따라 희소성과 저장 문제에 시달립니다.
- 훈련 데이터에서 보이지 않는 단어를 처리하기 위해 카운트에 작은 델타를 추가하고 더 작은 N-그램으로 "백오프"하는 기술이 사용되었습니다.(희소성 문제 해결)
- N-그램 모델은 종종 국소적으로 일관되고 문법적으로 올바른 텍스트를 생성할 수 있었지만 장기적인 일관성이 부족했습니다.

3. 신경망 언어 모델
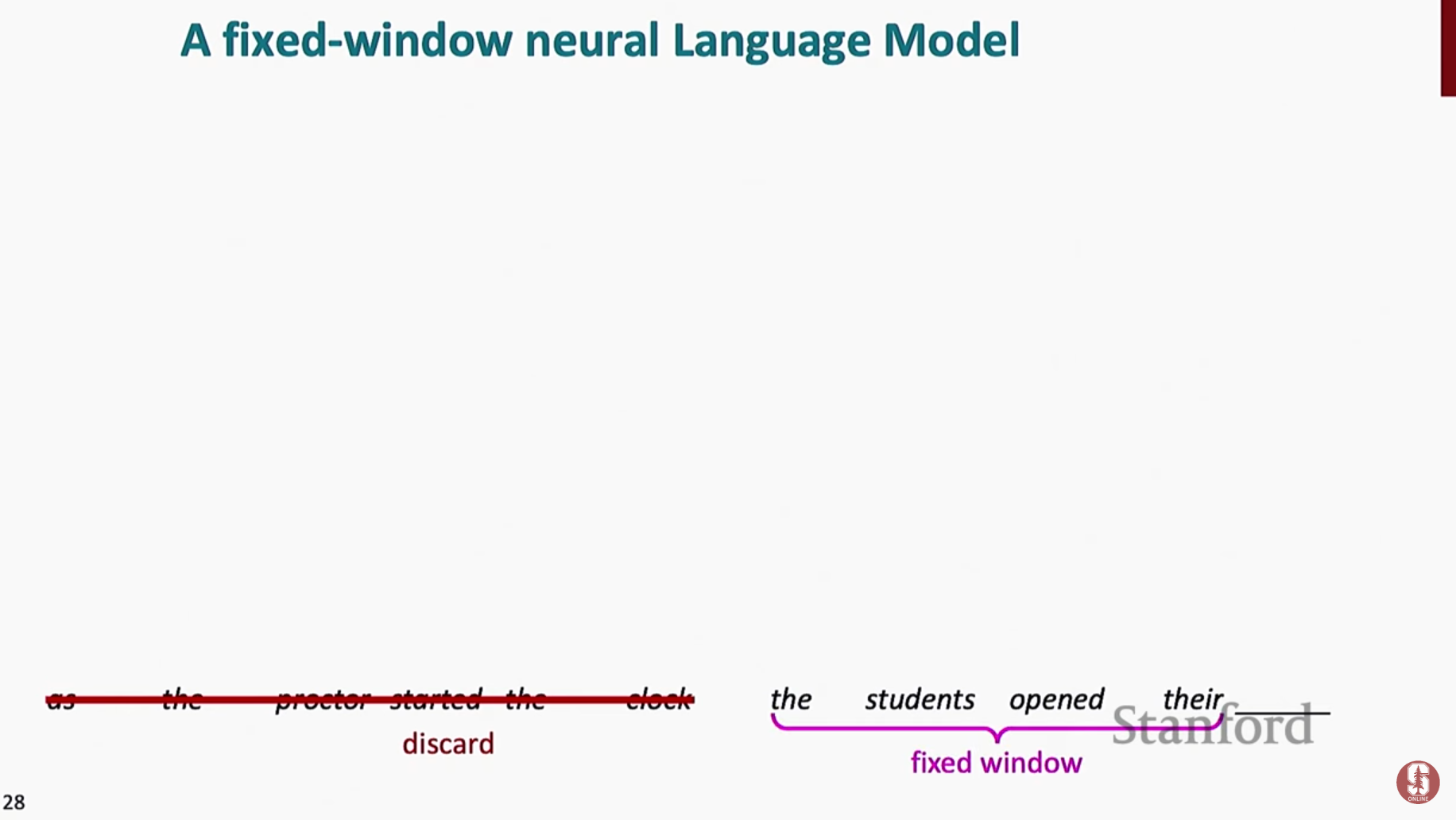
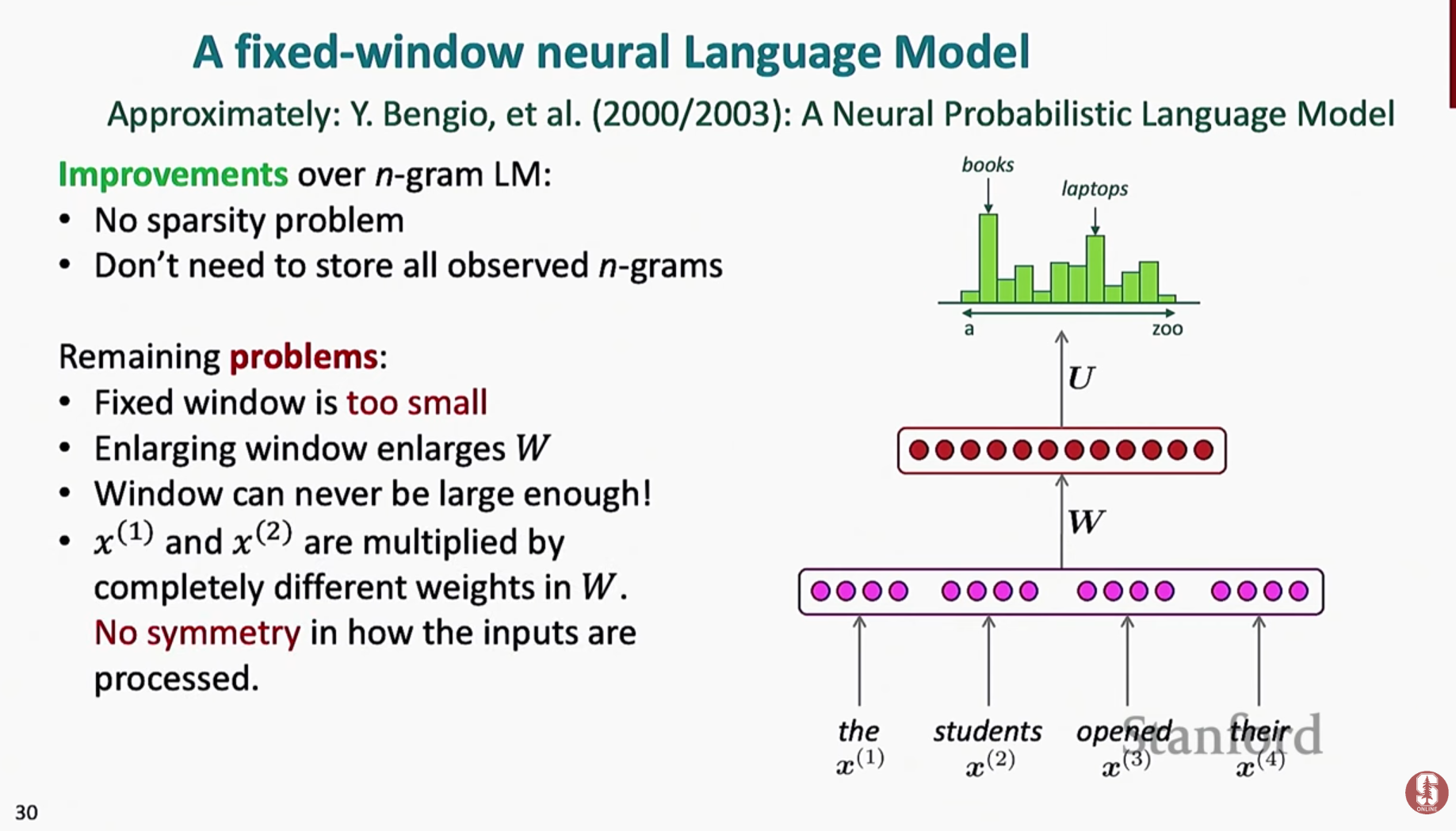
Fixed-window neural language model(고정 창 신경망 언어 모델)
- 고정 창 신경망 언어 모델은 요슈아 벤지오가 제안한 초기 접근법으로, 작고 고정된 크기의 단어 임베딩 창을 신경망에 대한 입력으로 사용하여 다음 단어를 예측했습니다.
- 이 모델은 희소성과 저장 비용을 제거했지만 여전히 고정된 컨텍스트 창의 한계에 시달렸습니다.
- 또한 창 내에서 위치에 따라 단어를 처리하기 위해 별도의 매개 변수를 사용하기 때문에 비효율적으로 보였습니다.
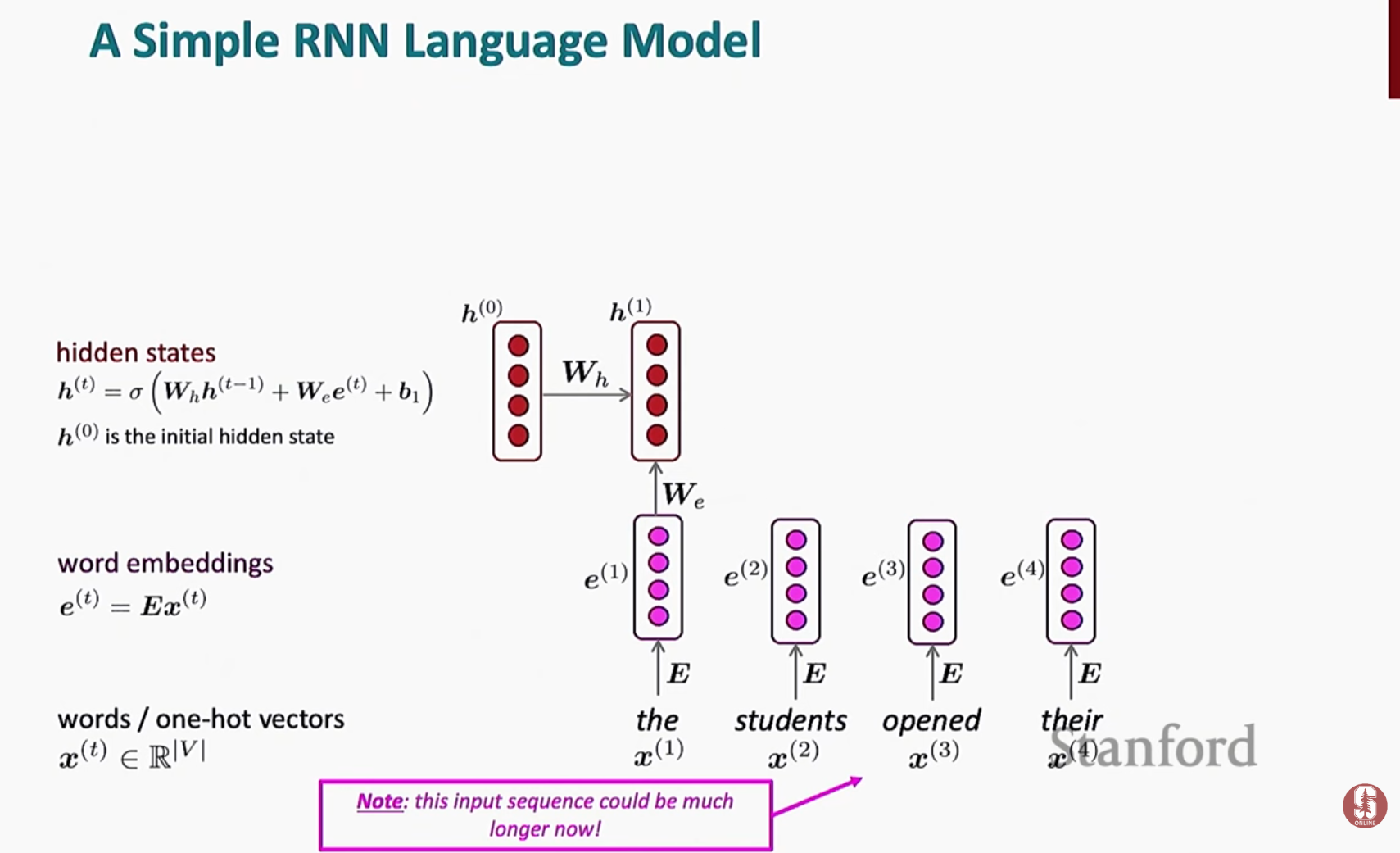
순환 신경망(RNN)
- RNN은 단일 가중치 집합을 사용하여 모든 길이의 시퀀스를 처리함으로써 고정 창 모델의 한계를 해결하기 위해 개발되었습니다.
- RNN은 새로운 입력과 이전의 은닉 상태를 기반으로 각 시간 단계에서 업데이트되는 메모리 역할을 하는 은닉 상태를 유지합니다.
- 이 아키텍처는 모델이 모델 크기의 기하급수적인 증가 없이 시퀀스에서 여러 단계 이전의 정보를 사용할 수 있게 합니다.
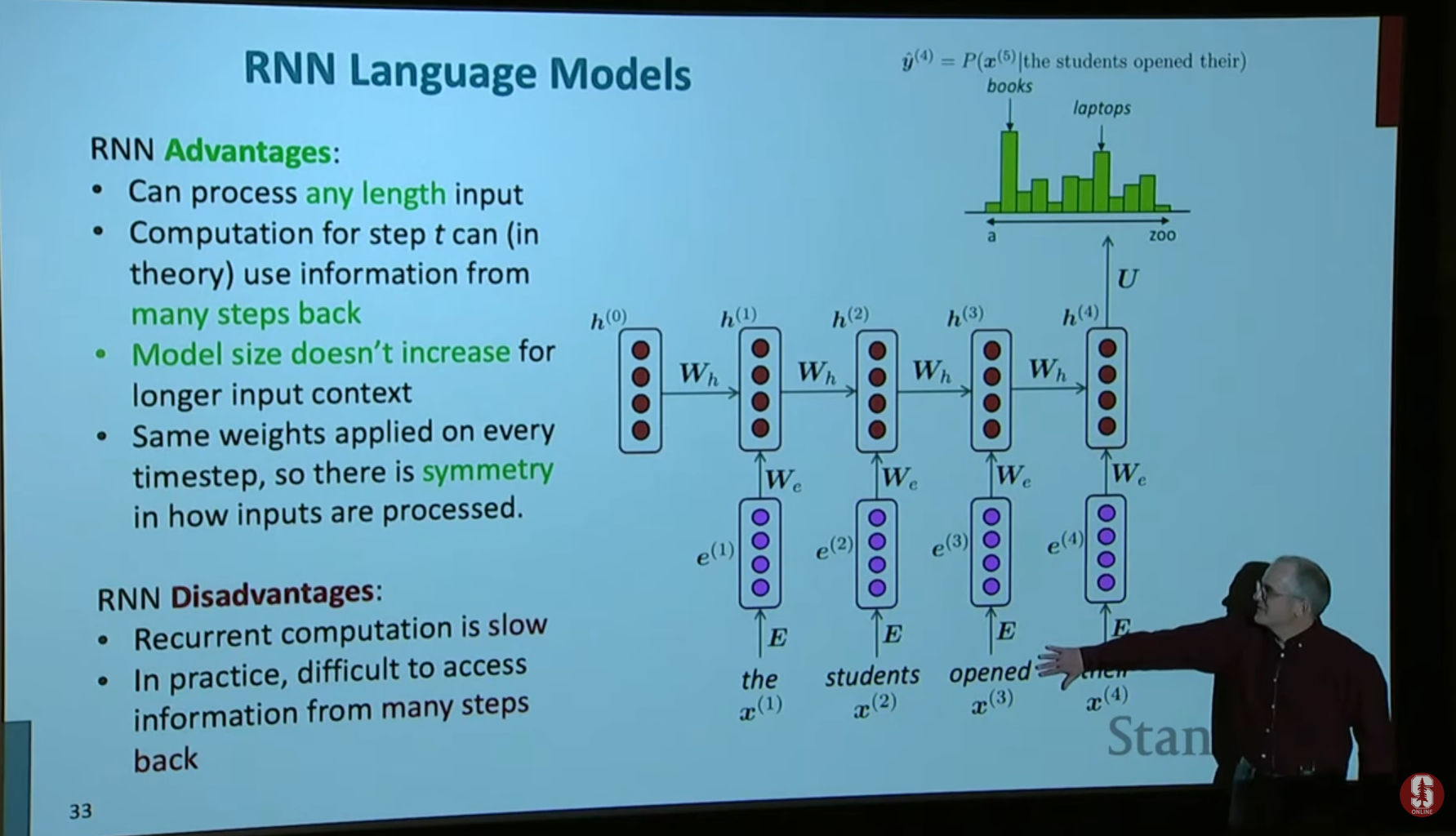
RNN의 주요 장점
-
시퀀스의 길이에 구애받지 않는 처리 능력
- N-그램 모델이나 고정 창 신경망 언어 모델은 처리할 수 있는 문맥의 길이가 제한적입니다.
- 하지만 RNN은 순환 구조를 통해 모든 길이의 시퀀스를 처리할 수 있습니다.
- 각 시점의 입력과 이전 시점의 은닉 상태를 결합하여 문맥 정보를 계속해서 업데이트하기 때문에, 이론적으로는 아무리 긴 문장이라도 처리할 수 있습니다.
-
'기억'을 통한 문맥 이해
- RNN은 은닉 상태(hidden state)라는 내부 메모리 역할을 하는 벡터를 가지고 있습니다.
- 이 은닉 상태는 이전 단계의 모든 정보를 압축하여 저장하고 다음 단계로 전달됩니다.
- 이를 통해 모델은 단지 현재 입력뿐만 아니라 과거의 문맥을 '기억'하고 활용하여 다음 단어의 확률을 예측할 수 있습니다.
- 이 능력은 복잡한 문장이나 긴 문단에서도 일관성을 유지하는 데 필수적입니다.
-
매개 변수의 효율성
- RNN은 시퀀스의 길이에 관계없이 동일한 가중치 집합을 재사용합니다.
- 즉, 문장이 길어지더라도 모델의 매개 변수 수가 기하급수적으로 늘어나지 않습니다.
- 이는 모델의 크기를 관리하기 용이하게 하며, N-그램 모델의 저장 공간 문제를 해결하는 데 큰 도움이 됩니다.
순환 신경망(RNN)의 주요 단점
-
순차적 계산으로 인한 느린 학습 속도 (Recurrent computation is slow)
- RNN은 입력 시퀀스를 한 번에 병렬 처리할 수 없습니다.
- 각 시점의 은닉 상태가 이전 시점의 은닉 상태에 의존하기 때문에, 계산이 순차적으로 진행될 수밖에 없습니다.
- CNN이나 Transformer 같은 모델은 GPU에서 병렬 연산이 가능하지만, RNN은 시퀀스의 길이가 길어질수록 연산 속도가 느려집니다.
- 따라서 긴 문장이나 대규모 데이터셋을 다룰 때 학습 시간이 크게 늘어나는 단점이 있습니다.
-
장기 의존성 문제 (Difficult to access information from many steps back)
- RNN은 이론적으로는 긴 문맥 정보를 다룰 수 있지만, 실제로는 멀리 떨어진 시점의 정보를 효과적으로 기억하기 어렵습니다.
- 시간이 지남에 따라 기울기 소실(vanishing gradient) 문제가 발생하여, 초기 입력 정보가 점점 희미해집니다.
- 반대로, 기울기 폭발(exploding gradient) 현상도 나타날 수 있어 학습이 불안정해집니다.
- 결과적으로, 멀리 떨어진 단어 간의 관계를 학습하는 데 어려움이 있으며, 이는 긴 문장에서 문맥을 정확히 이해하지 못하는 문제로 이어집니다.
이러한 한계 때문에, 실제 자연어 처리에서는 RNN 대신 LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit) 같은 게이트 기반 모델이 등장했습니다.
RNN 훈련
- 모델은 대규모 텍스트 말뭉치에서 각 시간 단계에서 다음 단어를 예측하고 교차 엔트로피를 사용하여 손실을 계산하여 훈련됩니다.
- 이 프로세스는 종종 모델의 다음 입력이 모델 자체가 생성한 단어가 아닌 텍스트의 실제 다음 단어인 교사 강요(teacher forcing)를 사용합니다.
- 모델의 매개 변수는 각 시간 단계의 경사를 합산하는 시간을 통한 역전파(backpropagation through time)를 사용하여 업데이트됩니다.

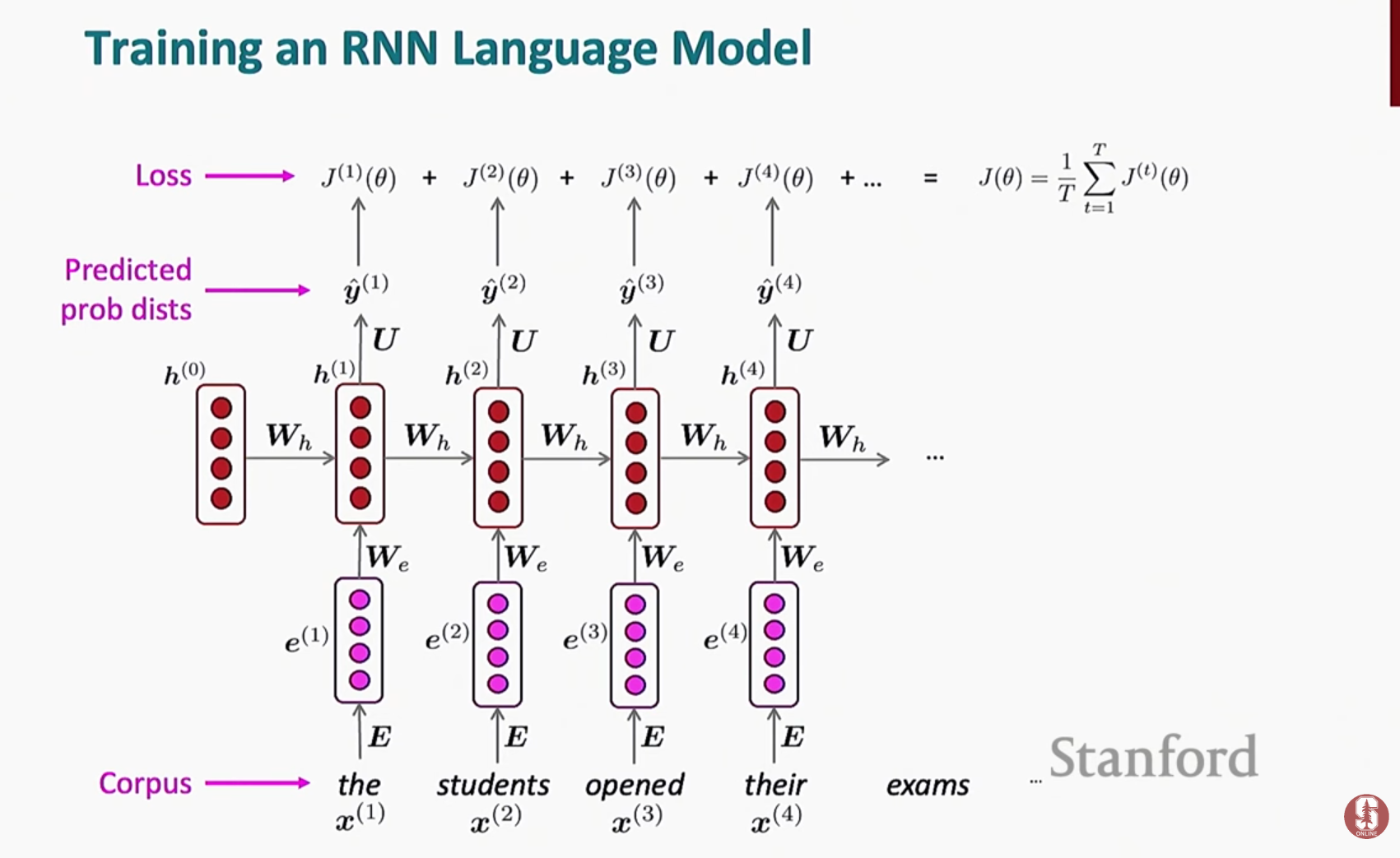

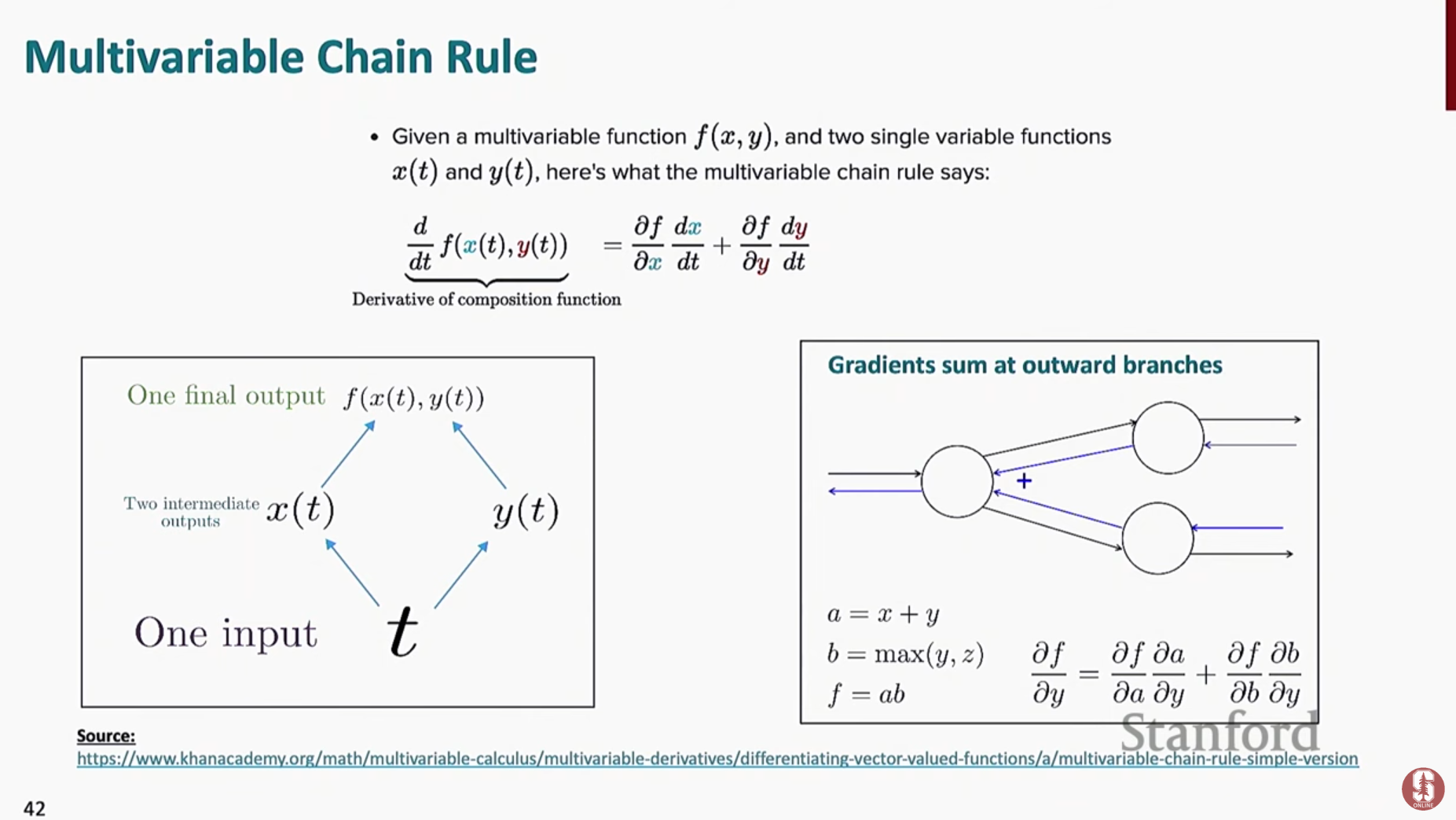
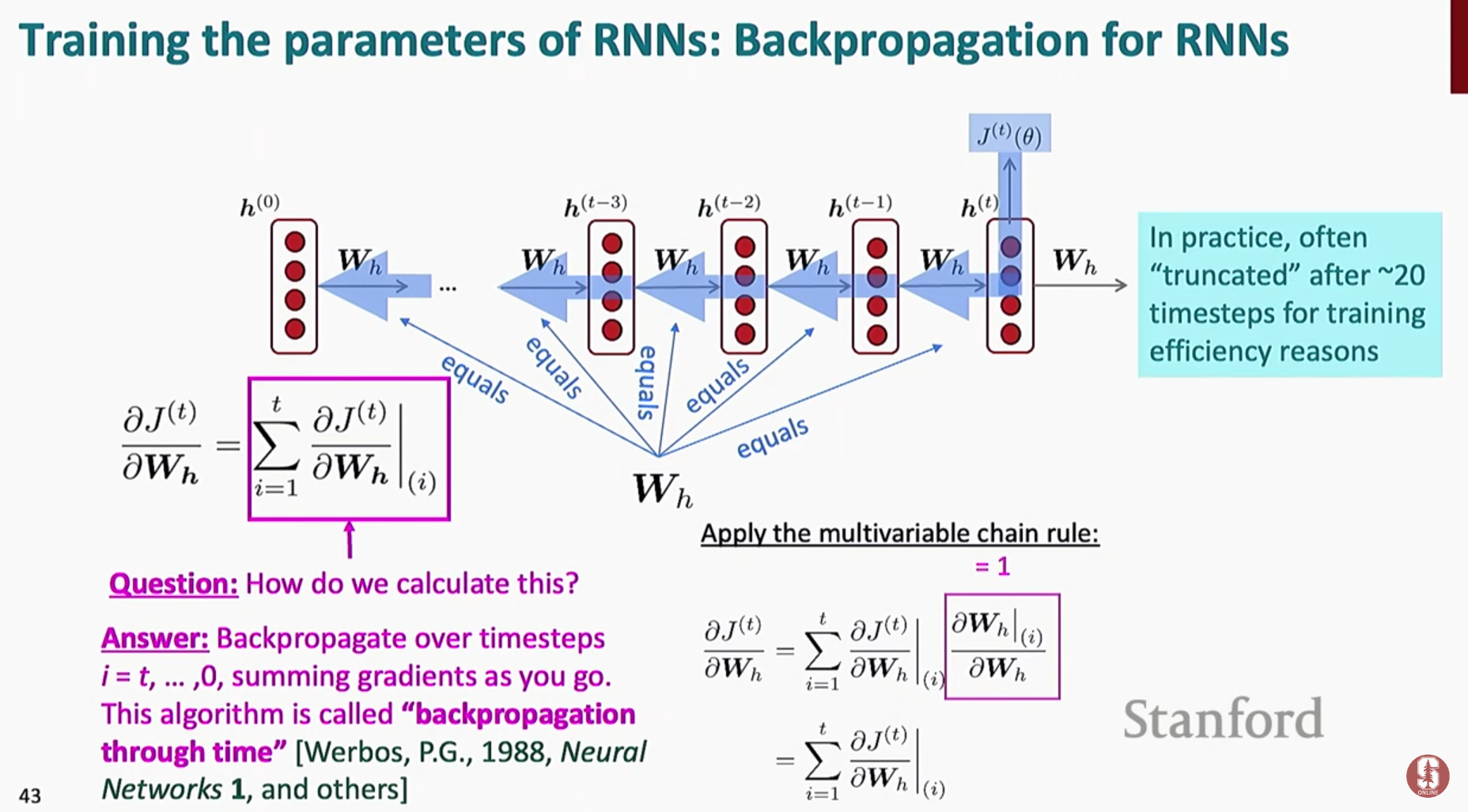
- 즉, RNN은 forward-propagation 단계에서 구한 Loss들의 합에 대해서 derivative를 구하고, 최종적으로 한번만 를 업데이트하면 됩니다.
- 는 모든 시점에서 동일하니까, 시점별로 업데이트를 할 필요가 없는 특징을 가집니다.
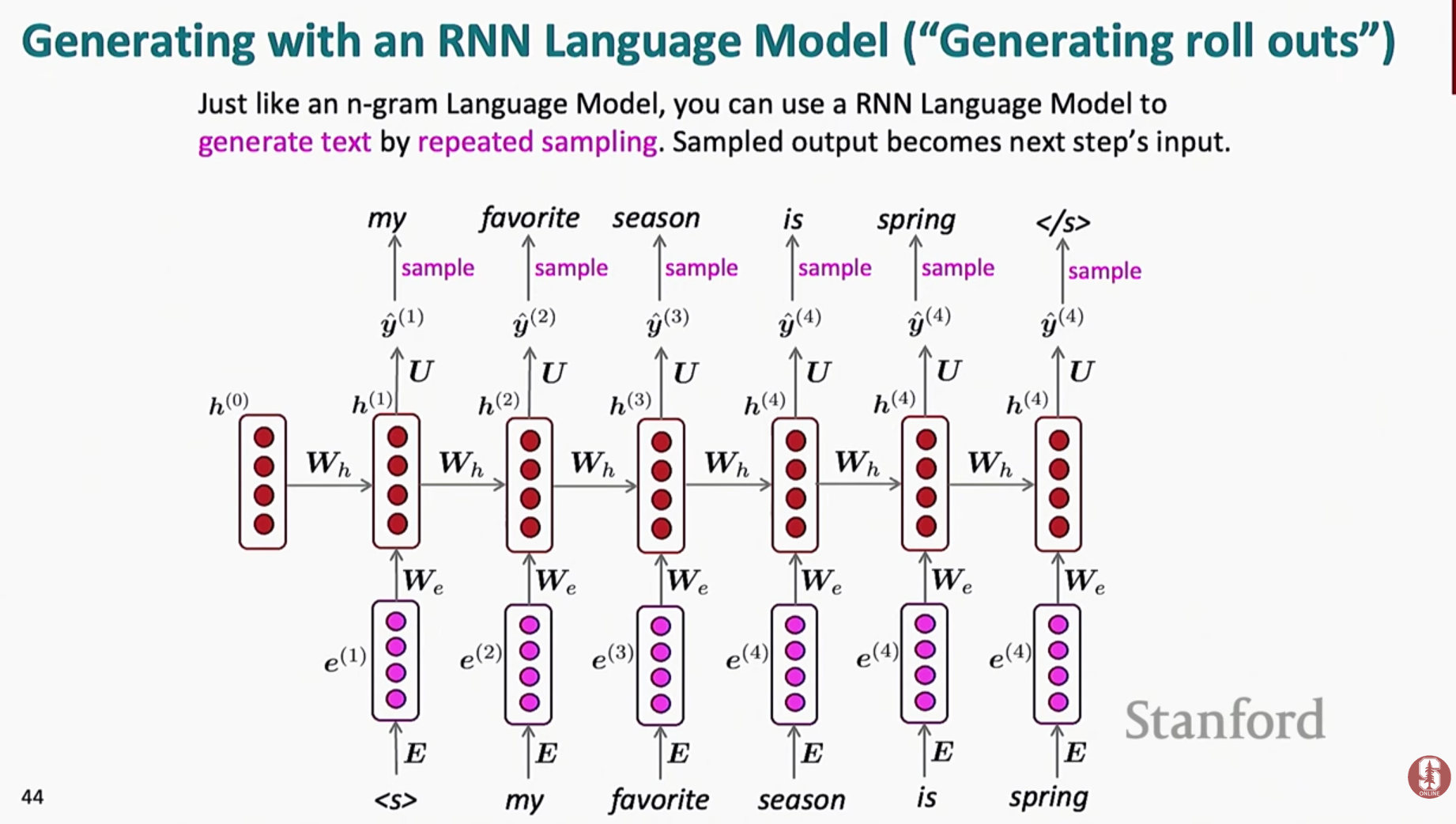
RNN을 이용한 텍스트 생성
- 생성된 단어를 다음 입력으로 모델에 다시 공급함으로써, RNN은 "롤아웃"이라고 불리는 과정에서 훈련 데이터의 스타일과 구조를 모방하는 연속적인 텍스트 시퀀스를 생성할 수 있습니다.

AI 공부합니다