
1. 순환 신경망(RNN)의 기본 구조와 동작
- RNN(Recurrent Neural Network)은 자연어와 같이 순서가 중요한 시퀀스 데이터를 처리하기 위해 설계된 신경망입니다.
- 핵심 아이디어는 이전 시점의 정보를 은닉 상태(hidden state)에 저장하고, 이를 현재 시점의 계산에 활용한다는 점입니다.
순전파 (Forward Propagation)
-
은닉 상태($h_t$) 계산
현재 입력 $x_t$와 이전 은닉 상태 $h_{t-1}$을 결합하여 새로운 은닉 상태를 계산합니다.
-
출력($y_t$) 계산
은닉 상태를 기반으로 다음 단어의 확률 분포를 얻습니다.
2. 언어 모델의 평가 척도: 퍼플렉서티(Perplexity)
- 언어 모델의 성능은 보통 **퍼플렉서티(Perplexity)**로 평가합니다.
- 퍼플렉서티는 모델이 문장을 얼마나 잘 예측하는지를 수치화한 값이며, 낮을수록 더 좋은 성능을 의미합니다.
-
역사적 발전
- n-gram 모델 → 약 67
- RNN 초기 모델 → 51
- LSTM → 43, 30
- 최신 LLM → 한 자릿수

3. RNN의 근본적 한계
- RNN은 강력한 구조이지만, 다음과 같은 문제가 있습니다.
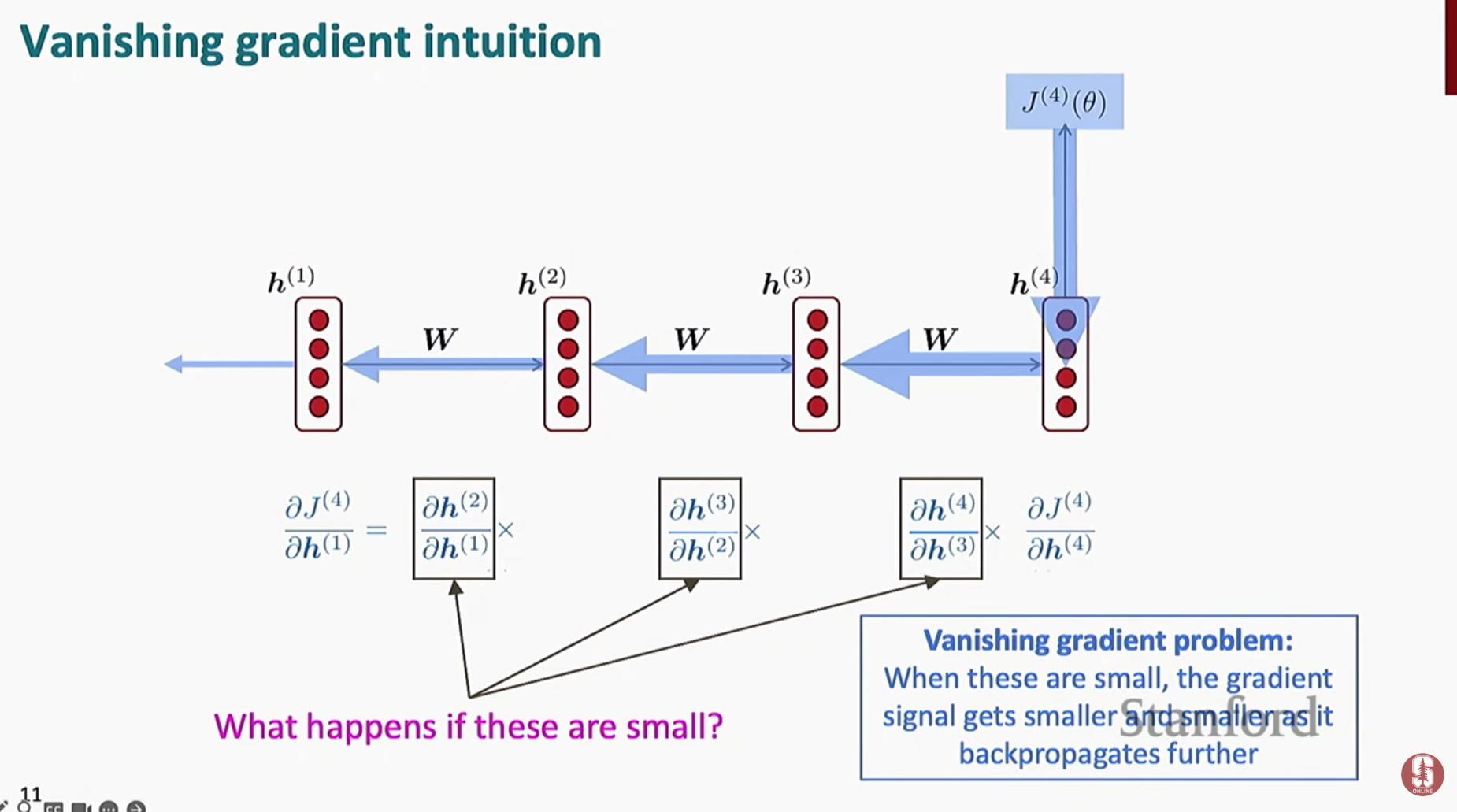
1) 기울기 소실 (Vanishing Gradient)
- 역전파 시, 긴 시퀀스를 거쳐 전달되는 기울기가 점점 작아져 초반 정보가 소실됩니다.
- 이로 인해 장거리 의존성(long-distance dependency) 학습이 어렵습니다.

2) 기울기 폭발 (Exploding Gradient)
- 반대로, 기울기가 지나치게 커져서 학습이 불안정해질 수 있습니다.
- 보통 Gradient Clipping 기법으로 해결합니다.

4. LSTM(Long Short-Term Memory)의 혁신
- RNN의 한계를 극복하기 위해 등장한 구조가 LSTM입니다.
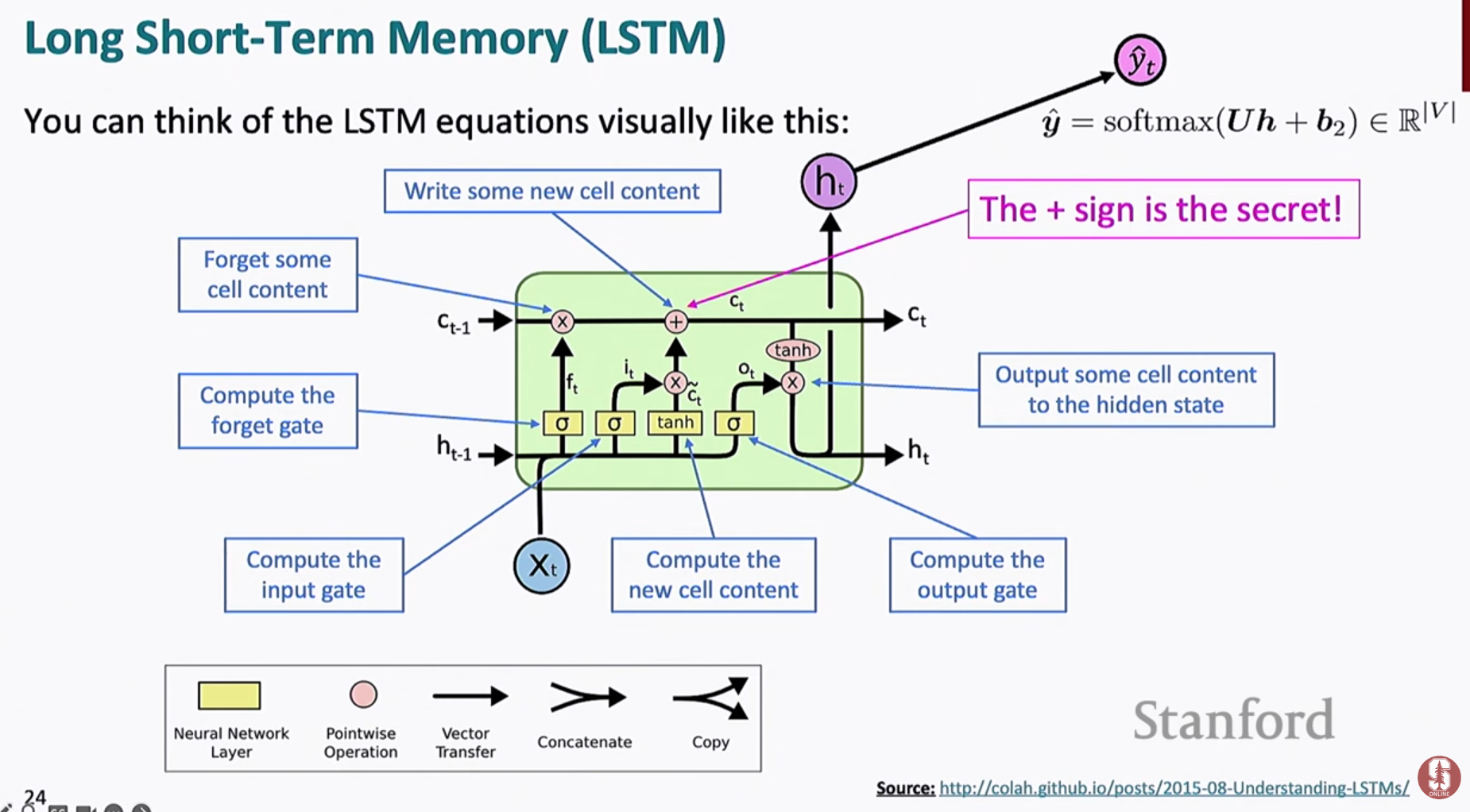
핵심은 **셀 상태($C_t$)**와 세 가지 게이트를 사용하여 정보를 장기적으로 보존한다는 점입니다.

- 망각 게이트 ()불필요한 과거 정보를 제거
- 입력 게이트 ()새로운 입력 정보를 얼마나 반영할지 결정
- 출력 게이트 ()은닉 상태로 보낼 정보를 선택
- 셀 상태 업데이트(여기서 는 원소별 곱)
👉 덧셈 연산을 활용하기 때문에 기울기가 사라지지 않고 장기 의존성을 학습할 수 있습니다.
1) 은닉 상태() vs 셀 상태()
(1) 은닉 상태 (Hidden State, )
-
정의:
현재 시점 까지의 입력 정보를 요약한 출력 벡터입니다. -
역할:
다음 시점의 계산에 입력으로 사용되며, 동시에 최종 출력(예: 다음 단어 예측)에 직접적으로 연결됩니다. -
특징:
- 시점마다 매번 갱신됨
- 네트워크의 출력과 연결됨 (예: softmax 입력으로 들어감)
- 단기적인 문맥(short-term dependencies)을 잘 반영
(2) 셀 상태 (Cell State, ) → LSTM에서만 존재
-
정의:
네트워크가 "장기적인 기억(long-term memory)"을 저장하는 내부 메모리 벡터입니다. -
역할:
정보가 게이트(입력 게이트, 망각 게이트, 출력 게이트)를 통해 선택적으로 추가·제거되면서 비교적 장기적인 의존성(long-term dependency) 을 유지하는 역할을 합니다. -
특징:
- LSTM만 가지고 있는 상태 (기본 RNN, GRU는 없음)
- 은닉 상태보다 "더 깊은 기억 저장소" 역할
- 망각 게이트(forget gate)를 통해 필요 없는 정보를 지워내고, 입력 게이트(input gate)를 통해 새로운 정보를 추가
(3) 정리
- RNN (기본형) → 은닉 상태 만 존재.
- LSTM → 은닉 상태 + 셀 상태 모두 존재.
- GRU → 은닉 상태 하나만 존재하지만, 게이트 구조를 통해 LSTM의 기능 일부를 흡수.
- : 장기 메모리 (information highway 역할, 게이트를 거쳐 업데이트)
- : 단기 메모리 + 출력 (실제로 다음 예측에 직접 활용됨)
- 은닉 상태(h) = 매 시점마다 바뀌는 단기적 문맥 + 출력에 직접 사용
- 셀 상태(c) = 장기적 문맥을 유지하는 메모리 저장소
좋습니다 👍
앞서 정리해 주신 스타일에 맞춰, **“출력 게이트(Output Gate)의 필요성”**을 새로운 파트로 추가해서 정리해 드릴게요.
2) 출력 게이트(Output Gate)의 필요성
- LSTM은 입력 게이트($i_t$), 망각 게이트($f_t$), 출력 게이트($o_t$)라는 세 가지 게이트를 가지고 있습니다.
- 이 중 출력 게이트는 다소 직관적으로 이해하기 어려울 수 있지만, LSTM의 안정적 학습과 표현력 강화에 매우 중요한 역할을 합니다.
(1) 출력 게이트의 정의
- 출력 게이트는 셀 상태($c_t$)에서 현재 시점에 필요한 정보만 골라 은닉 상태($h_t$)로 전달합니다.
- $c_t$: 장기적인 정보를 담은 메모리 (Cell State)
- $o_t$: 출력 게이트 (필터 역할)
- $h_t$: 실제 출력 + 다음 시점 입력으로 쓰이는 은닉 상태
(2) 출력 게이트가 없다면?
만약 출력 게이트가 없다면 단순히
로 계산해야 합니다.
즉, 셀 상태의 모든 정보를 매 시점마다 그대로 드러내게 되며, 불필요한 정보까지 출력에 반영됩니다.
이 경우 다음과 같은 문제가 발생합니다.
- 불필요한 정보까지 출력으로 흘러가 잡음 증가
- 셀 상태($c_t$)와 은닉 상태($h_t$)의 역할이 모호해짐
- 장기 기억을 안정적으로 유지하기 어려워짐
(3) 출력 게이트가 필요한 이유
- 정보 필터링 (Information Filtering)
- 셀 상태에 있는 모든 정보를 다 쓰는 대신,
현재 시점에서 필요한 일부 정보만 선택적으로 출력합니다.
- 셀 상태에 있는 모든 정보를 다 쓰는 대신,
- 역할 분리 (Role Separation)
- $c_t$: 장기적인 정보 저장소 (잘 변하지 않음)
- $h_t$: 단기적 문맥 + 출력에 직접 사용 (자주 변함)
- 출력 게이트가 있어야 이 두 상태의 역할이 명확하게 나눠집니다.
- 학습 안정성
- $c_t$는 장기 기억을 안정적으로 유지하고,
- $h_t$는 출력과 gradient 흐름에 맞춰 빠르게 변화할 수 있습니다.
(4) 비유로 이해하기
- 셀 상태($c_t$) = 도서관 전체 (모든 책 저장)
- 출력 게이트($o_t$) = 사서 (어떤 책만 빌려줄지 결정)
- 은닉 상태($h_t$) = 실제로 빌려간 책 (즉, 당장 필요한 정보)
👉 도서관에 모든 책이 있어도, 독자가 당장 필요한 책만 빌려야 효율적입니다.
출력 게이트가 바로 그 역할을 합니다.
(5) 정리
- 출력 게이트는 셀 상태를 그대로 노출하지 않고 필요한 정보만 선택적으로 전달합니다.
- 이를 통해
- 잡음을 줄이고,
- 장기 기억과 단기 출력을 분리하며,
- 안정적인 학습이 가능해집니다.
즉, 출력 게이트는 “모든 기억을 다 보여주지 말고, 필요한 기억만 꺼내라”는 필터입니다.
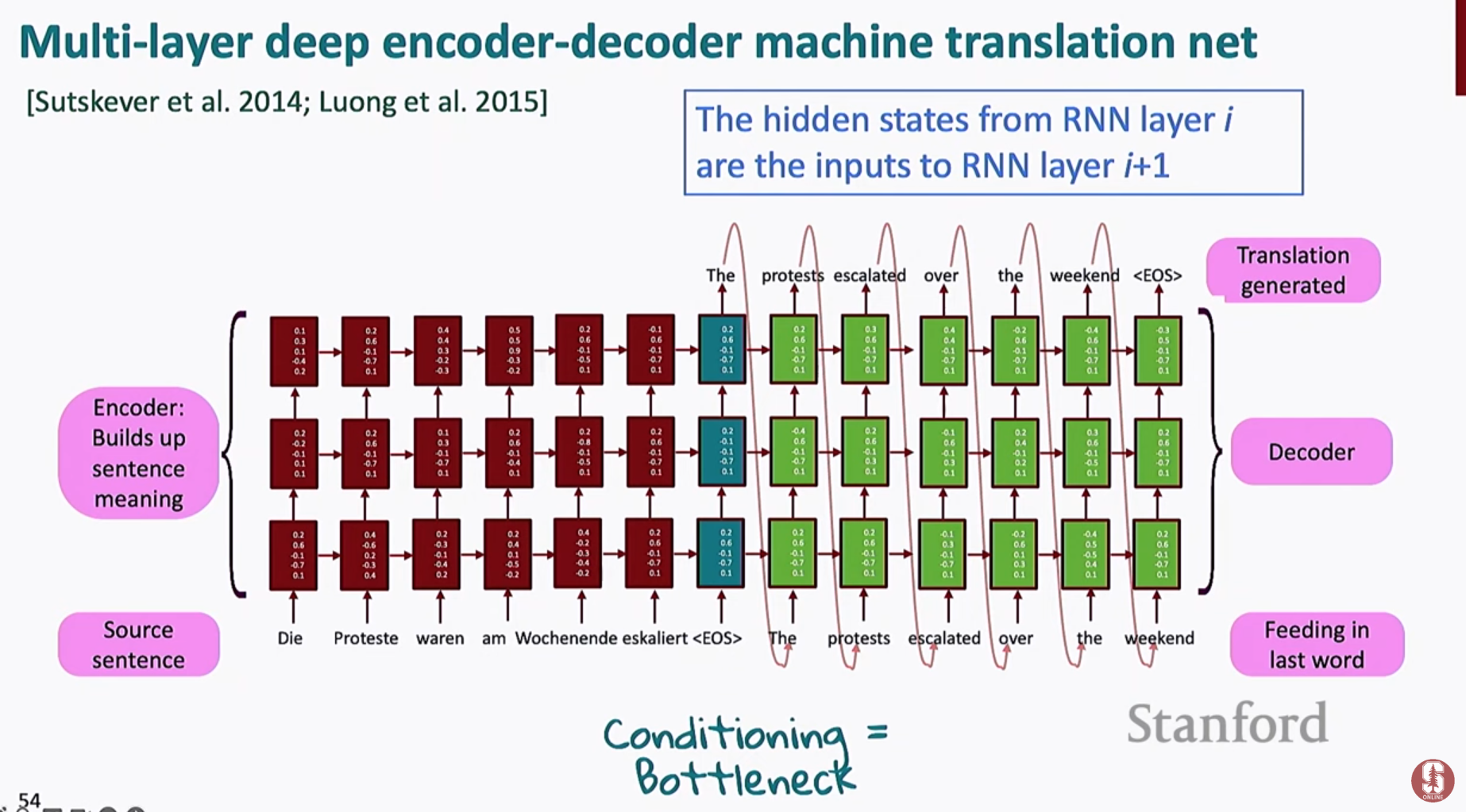
5. RNN의 응용과 Seq2Seq
1) 다양한 RNN 변형
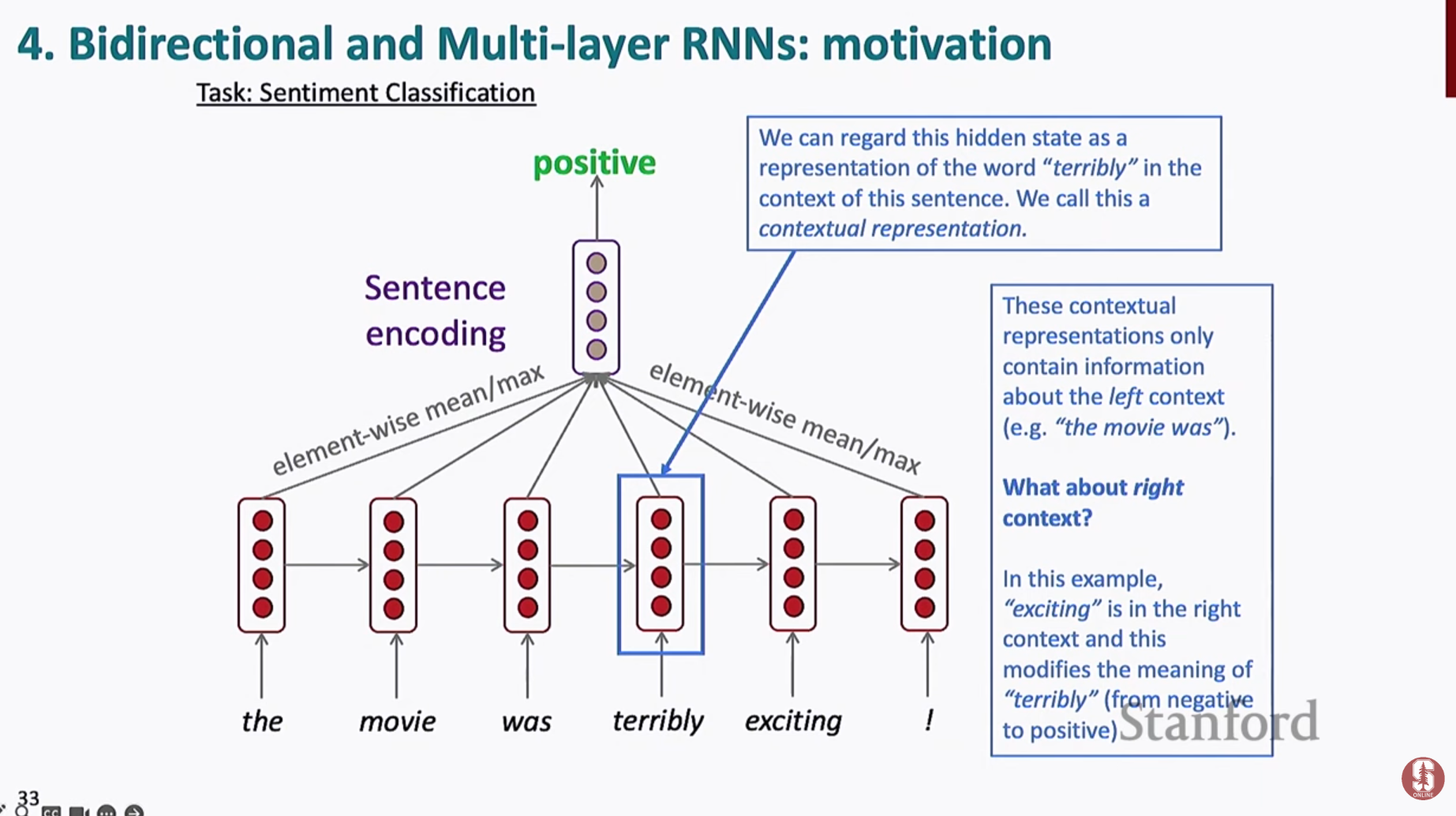
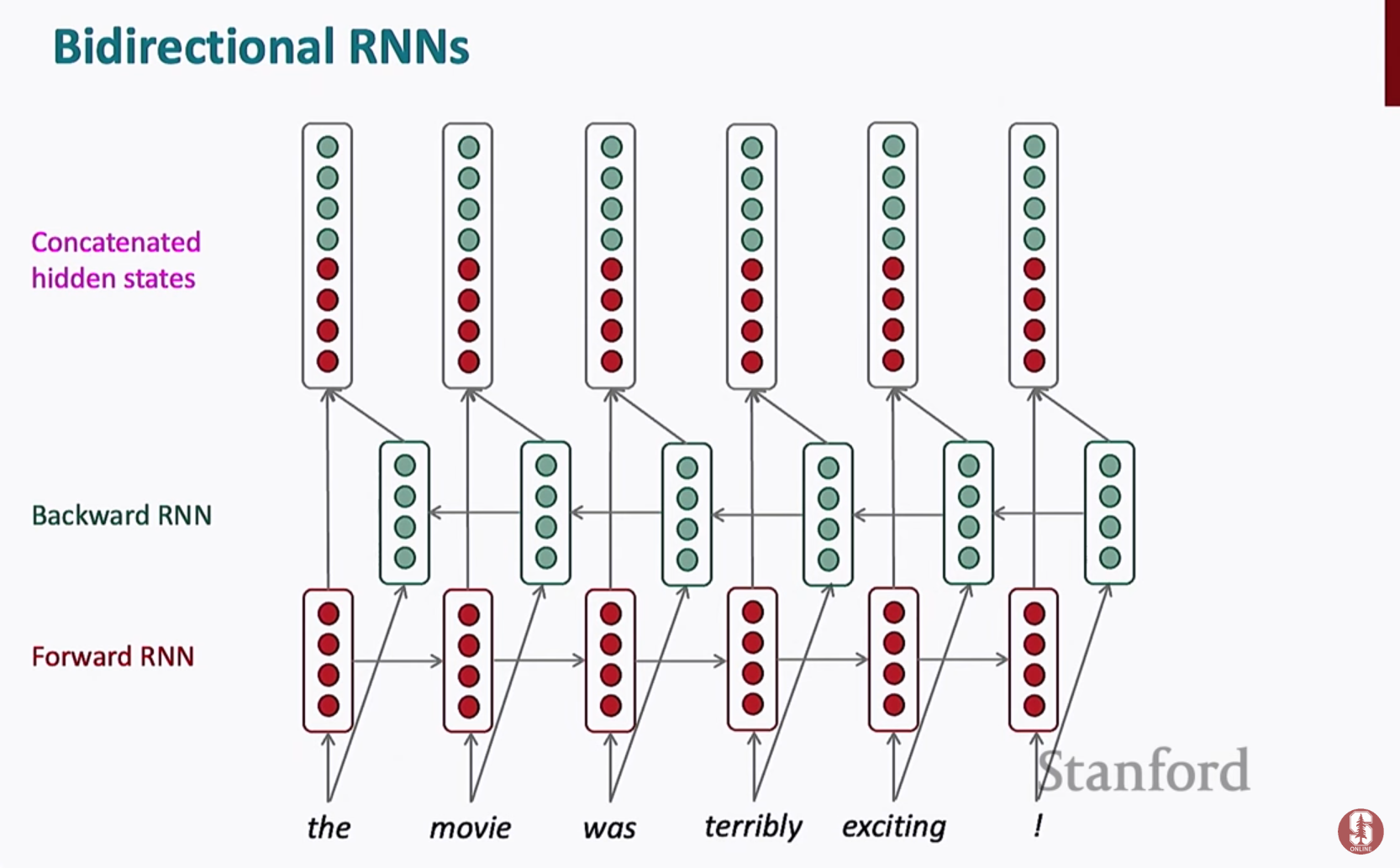
- 양방향 LSTM (Bidirectional LSTM)
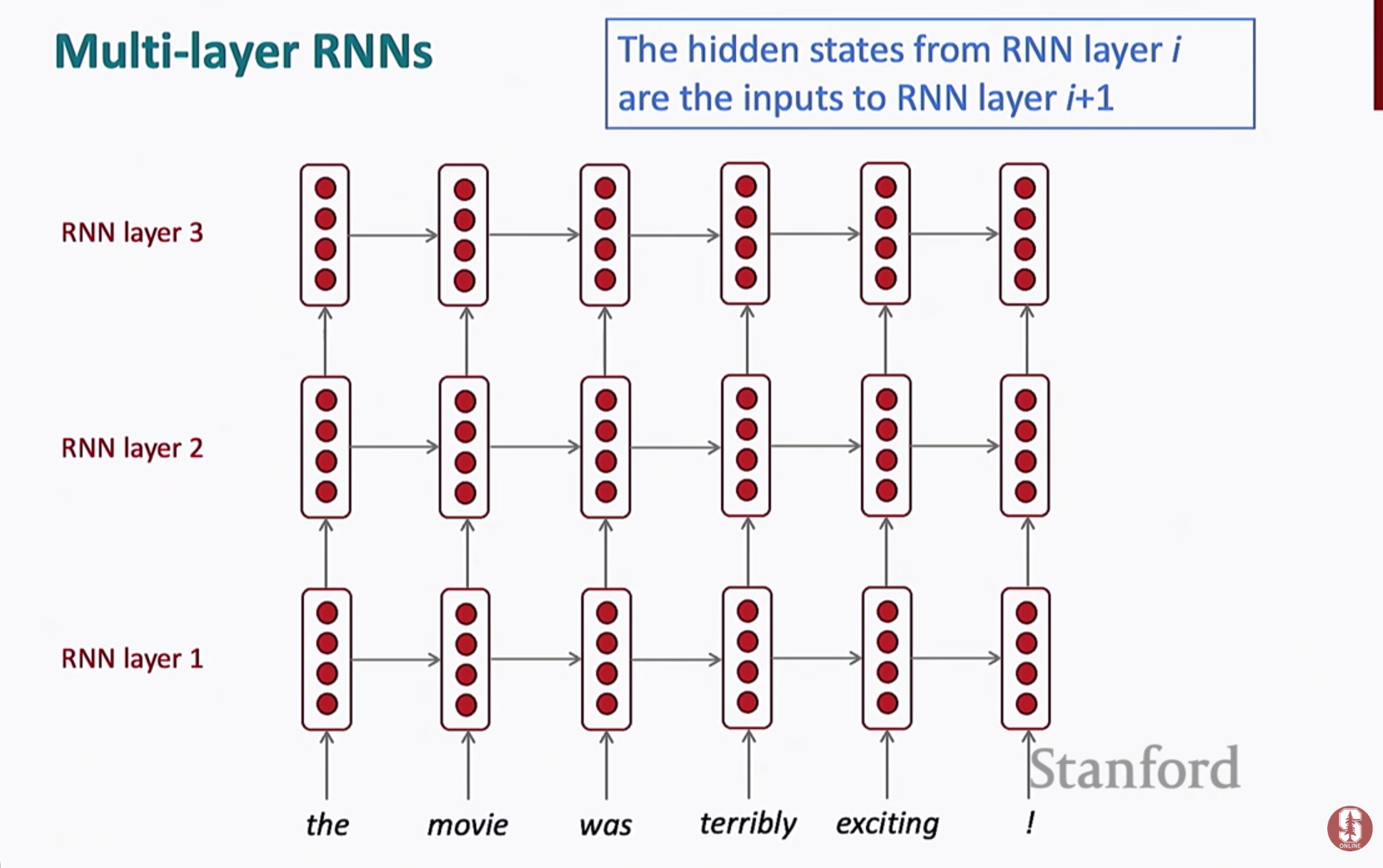
앞뒤 문맥을 모두 고려하여 더 정확한 표현 학습 - 스택 RNN (Stacked RNN)
여러 층을 쌓아 더 복잡한 패턴 학습


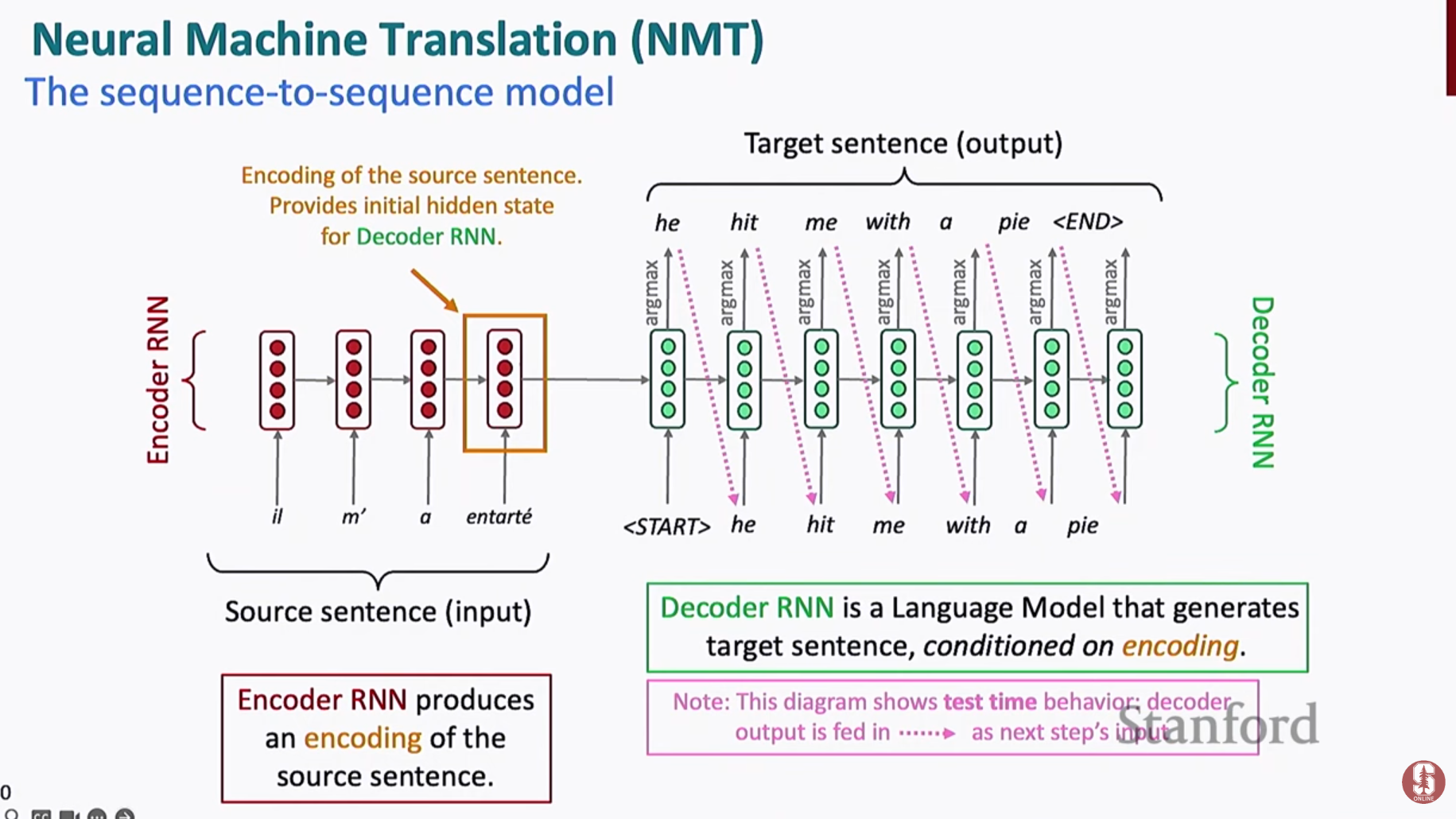
2) 신경망 기계 번역 (Neural Machine Translation, NMT)
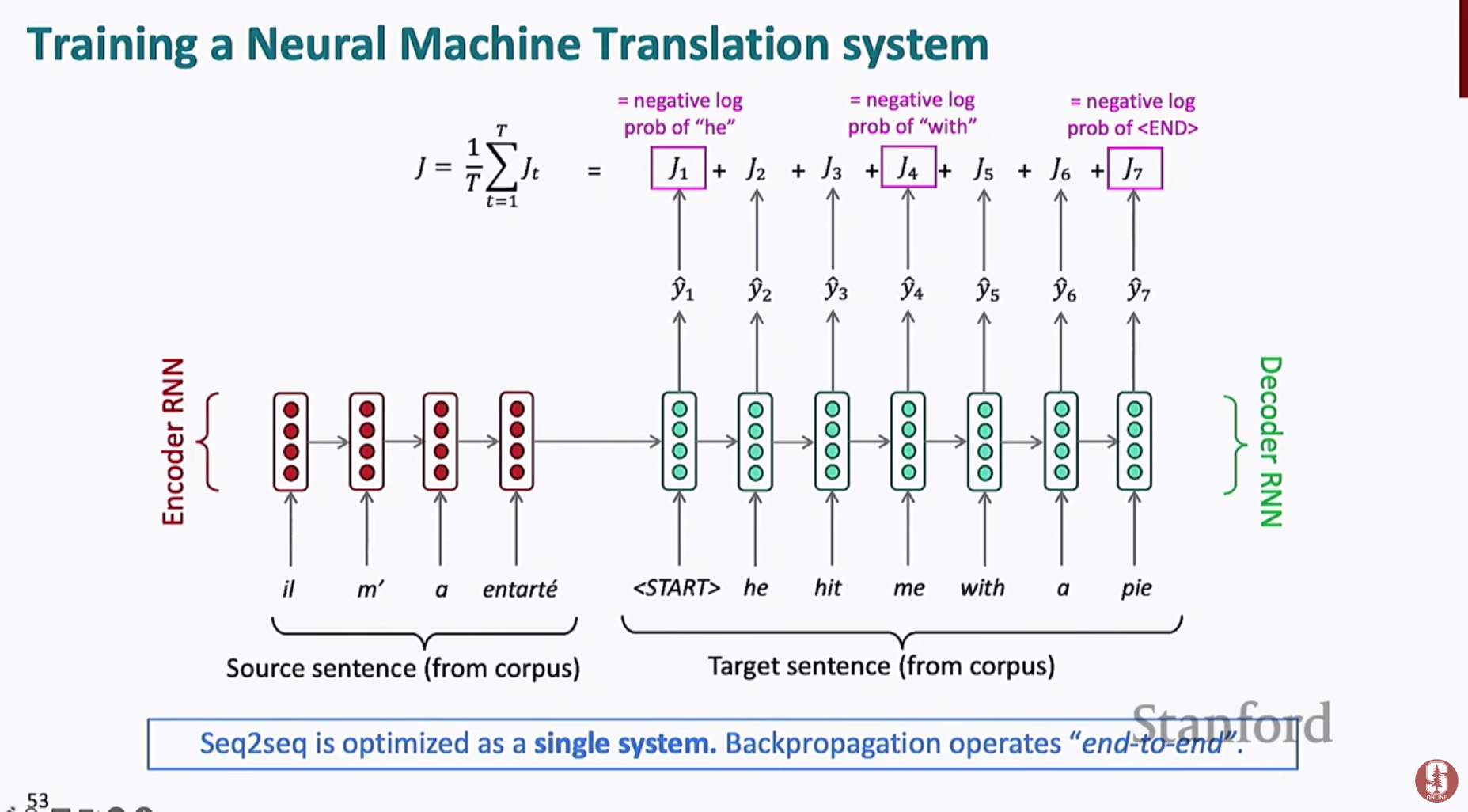
- 2014년, LSTM 기반 인코더-디코더(Seq2Seq) 구조 등장
- 인코더: 원문을 읽고 하나의 의미 벡터로 압축
- 디코더: 그 벡터를 바탕으로 번역문 생성
- End-to-End 학습 가능 → 병렬 코퍼스만 있으면 전체 번역기를 한 번에 훈련
👉 2016년 이후, 구글 번역을 비롯한 대규모 서비스들이 이 방식으로 전환

✍️ 위 내용을 정리하면, RNN은 N-gram 모델의 한계를 극복하며 NLP를 크게 발전시켰지만, 기울기 소실/폭발 문제 때문에 LSTM, GRU, 그리고 오늘날 Transformer 기반 LLM으로 이어지는 발전 경로를 만들었다고 할 수 있습니다.
