1. BLEU
1) BLEU의 기본 개념
- BLEU는 생성된 문장(candidate)과 기준(reference) 문장 사이의 n-gram 겹침 정도를 측정합니다.
- 쉽게 말하면:
- 번역 결과 문장과 사람 번역 문장을 n-gram 단위로 비교
- 겹치는 정도가 높을수록 점수가 높음
- BLEU의 핵심 아이디어는 정확도(precision)에 기반한 평가입니다.
- 즉, 생성된 문장 내의 n-gram이 기준 문장에 얼마나 포함되는지를 보는 것이죠.
2) BLEU의 장단점
장점
- 자동화 가능 → 사람이 일일이 평가할 필요 없음
- 빠른 계산 → 대규모 데이터셋 평가 가능
- 여러 reference 사용 가능 → 다양성 반영 가능
단점
- 의미(semantic) 반영 부족 → 단순 겹침만 계산
- 길이 민감 → 지나치게 짧은 문장 페널티
- 유창성/문법 고려 부족 → 단어 순서가 조금 달라도 점수 하락

2. Attention
1) why attention?
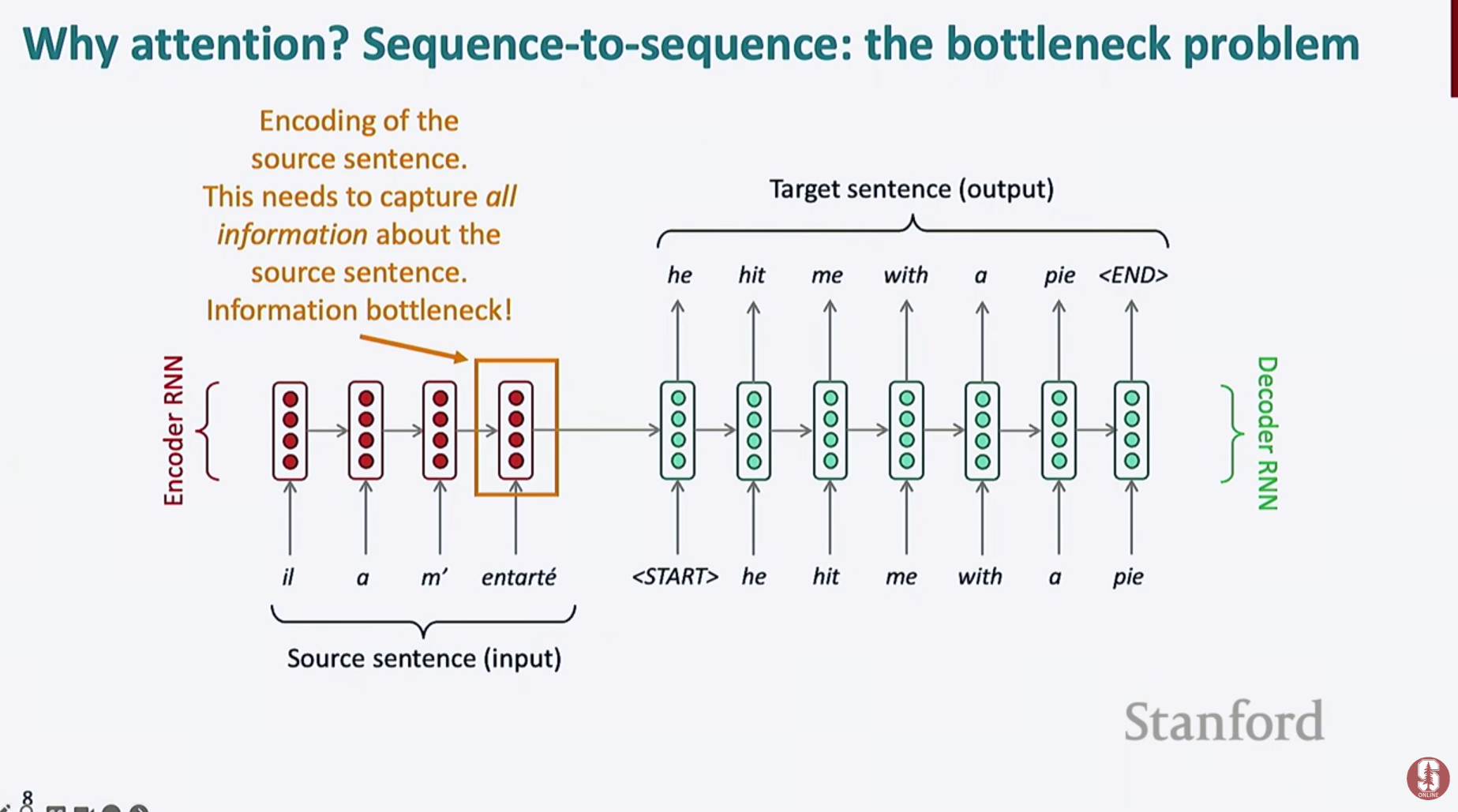
- 전통적인 Seq2Seq 모델은 RNN 기반 인코더가 입력 시퀀스를 하나의 고정 길이 벡터로 압축하고, 디코더가 이를 바탕으로 출력 시퀀스를 생성합니다.
- 하지만 이 접근 방식에는 다음과 같은 한계가 있습니다.
- 입력 시퀀스가 길어질수록 모든 정보를 단일 벡터에 압축해야 하므로 정보 손실 발생
- 디코더가 먼 시점의 입력 단어와 관련된 정보를 기억하기 어려움
- 이러한 구조적 한계를 Bottleneck 문제라고 부르며, 이는 번역 품질 저하의 주요 원인이 됩니다.
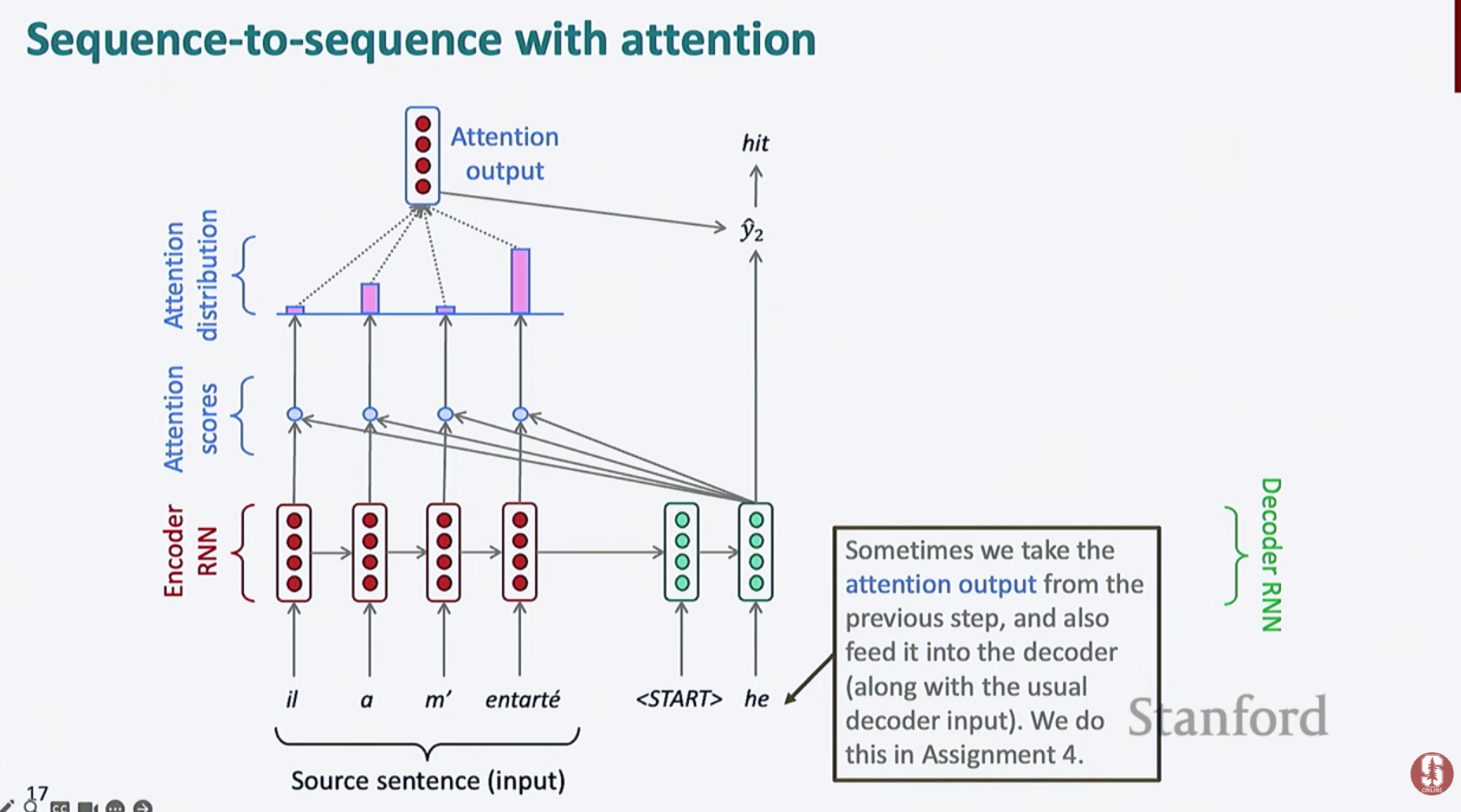
2) Attention의 구조
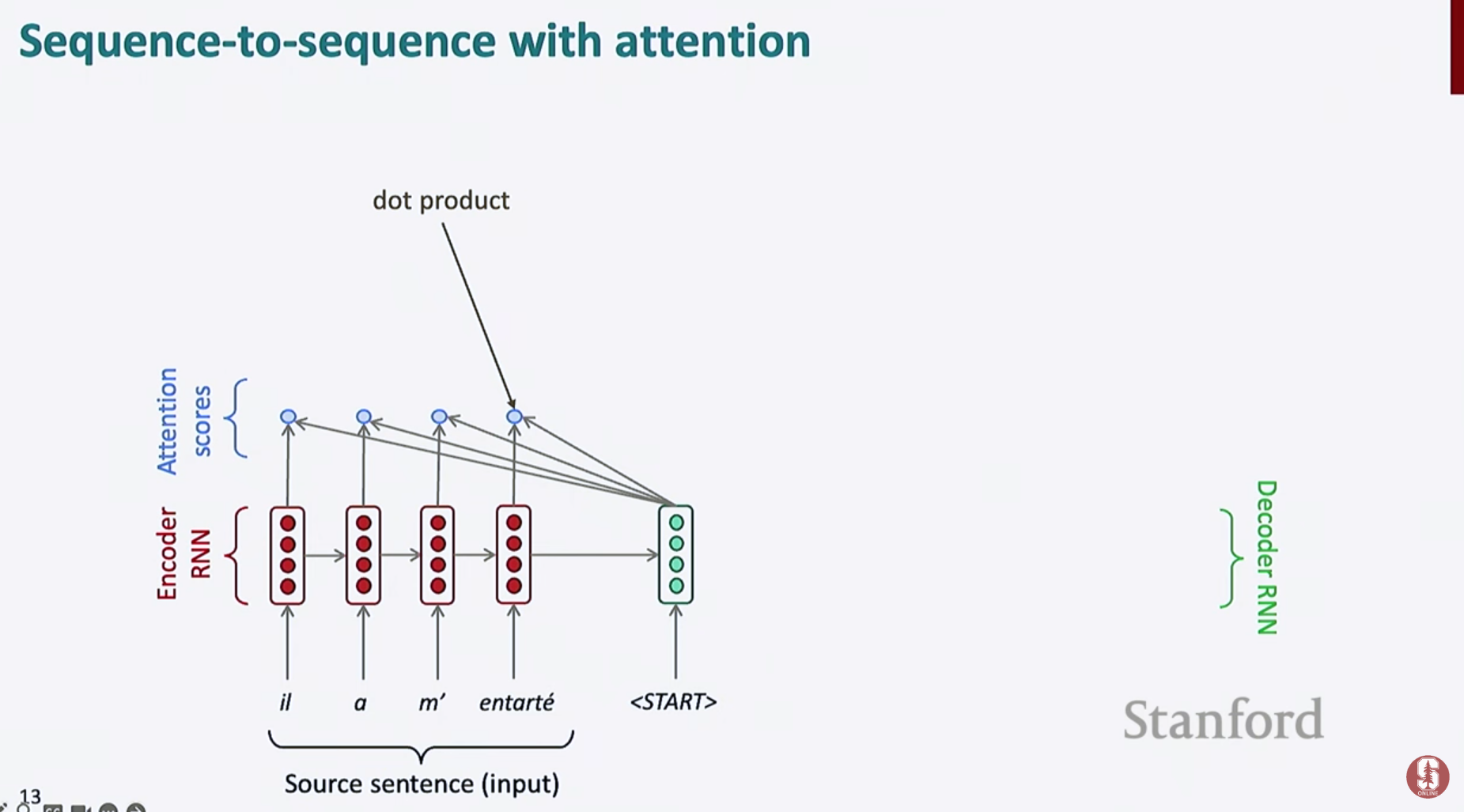
- Attention 메커니즘은 디코더가 출력 시점마다 입력 시퀀스 전체를 참조하도록 설계되어 Bottleneck 문제를 해결합니다.
- 각 디코더 시점 에서 컨텍스트 벡터 를 계산
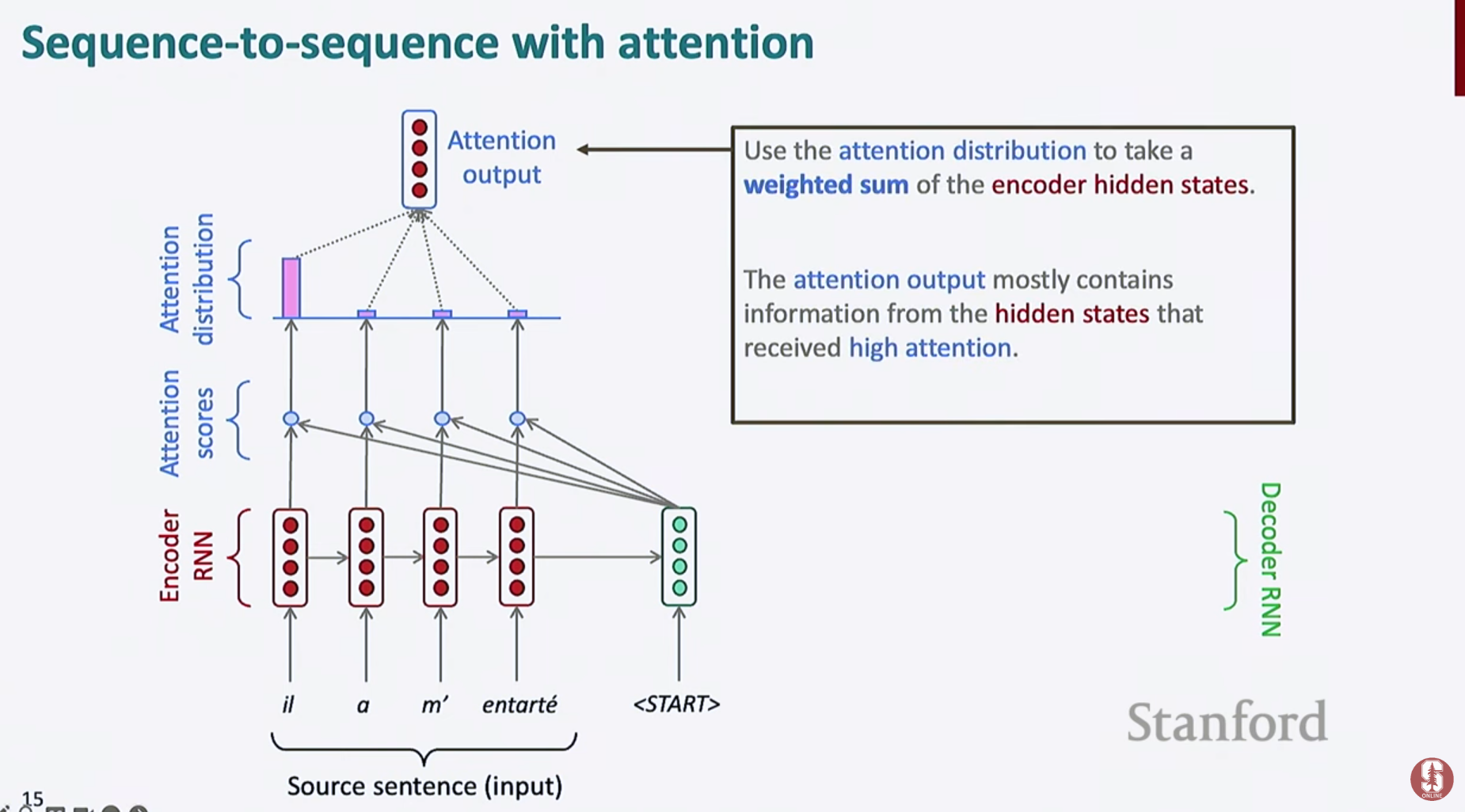
- 컨텍스트 벡터는 인코더의 모든 hidden state 와 attention weight 의 가중합으로 구성됩니다.
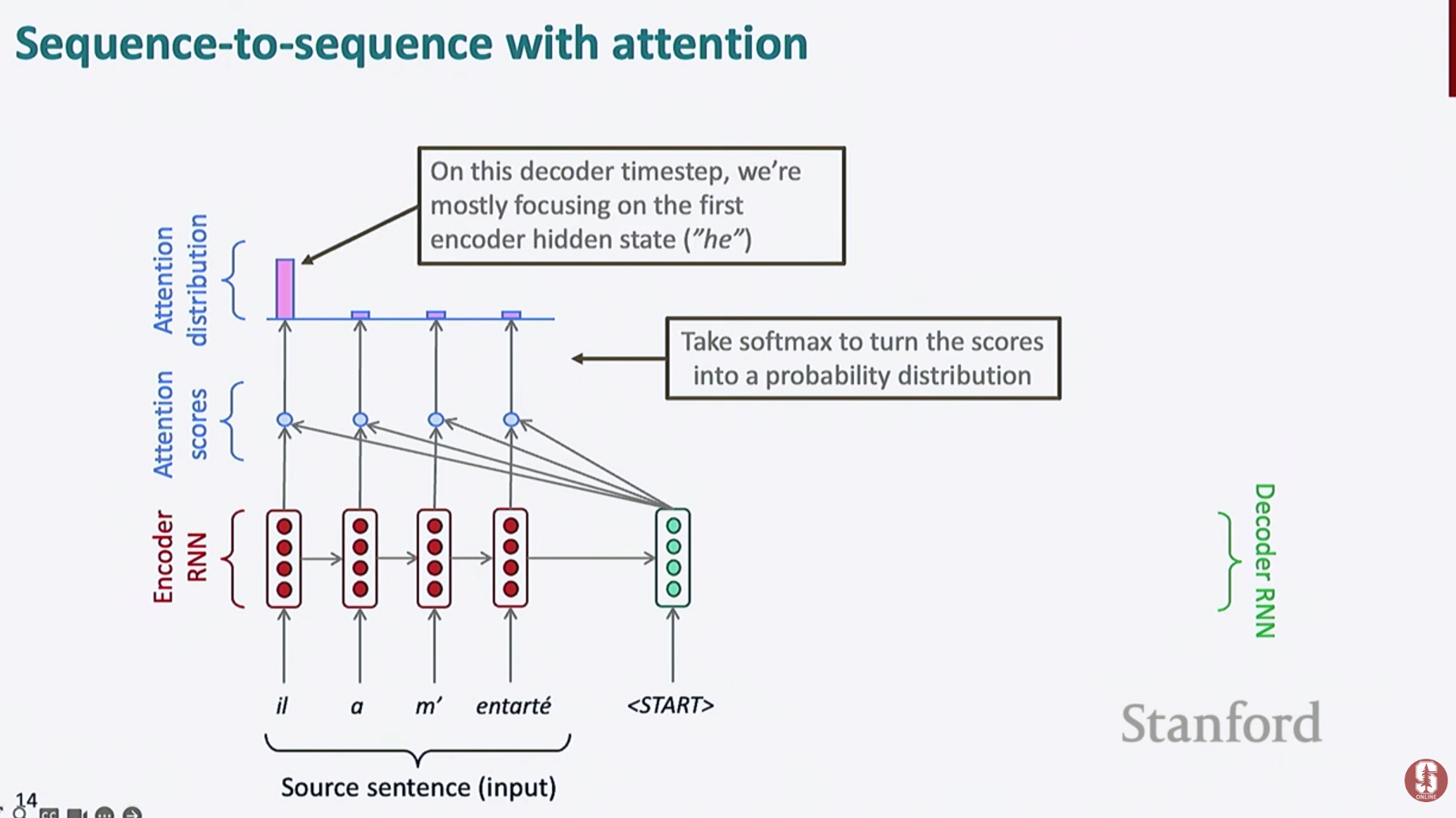
- 는 디코더가 i번째 입력 단어에 얼마나 주목하는지를 나타내는 확률 분포입니다.
- 디코더는 와 이전 hidden state 를 결합하여 다음 단어를 예측합니다.
3) Attention 수식
- Score 계산 (유사도 측정)
- Softmax를 통한 정규화
- Context Vector 계산
- 이 과정에서 score 함수는 Attention의 핵심이며, 여러 방식으로 정의될 수 있습니다.

4) Attention의 장점
- Long-term dependency 해결
- 멀리 떨어진 입력 단어도 참조 가능
- Interpretability 제공
- 를 통해 모델이 주목한 입력 위치를 확인 가능
- 성능 향상
- 기계 번역, 텍스트 요약, 질의응답 등 다양한 NLP 태스크에서 우수한 성능
- 동적 context
- 고정 벡터가 아닌 시점별 컨텍스트 벡터 사용 → 유연성 확보

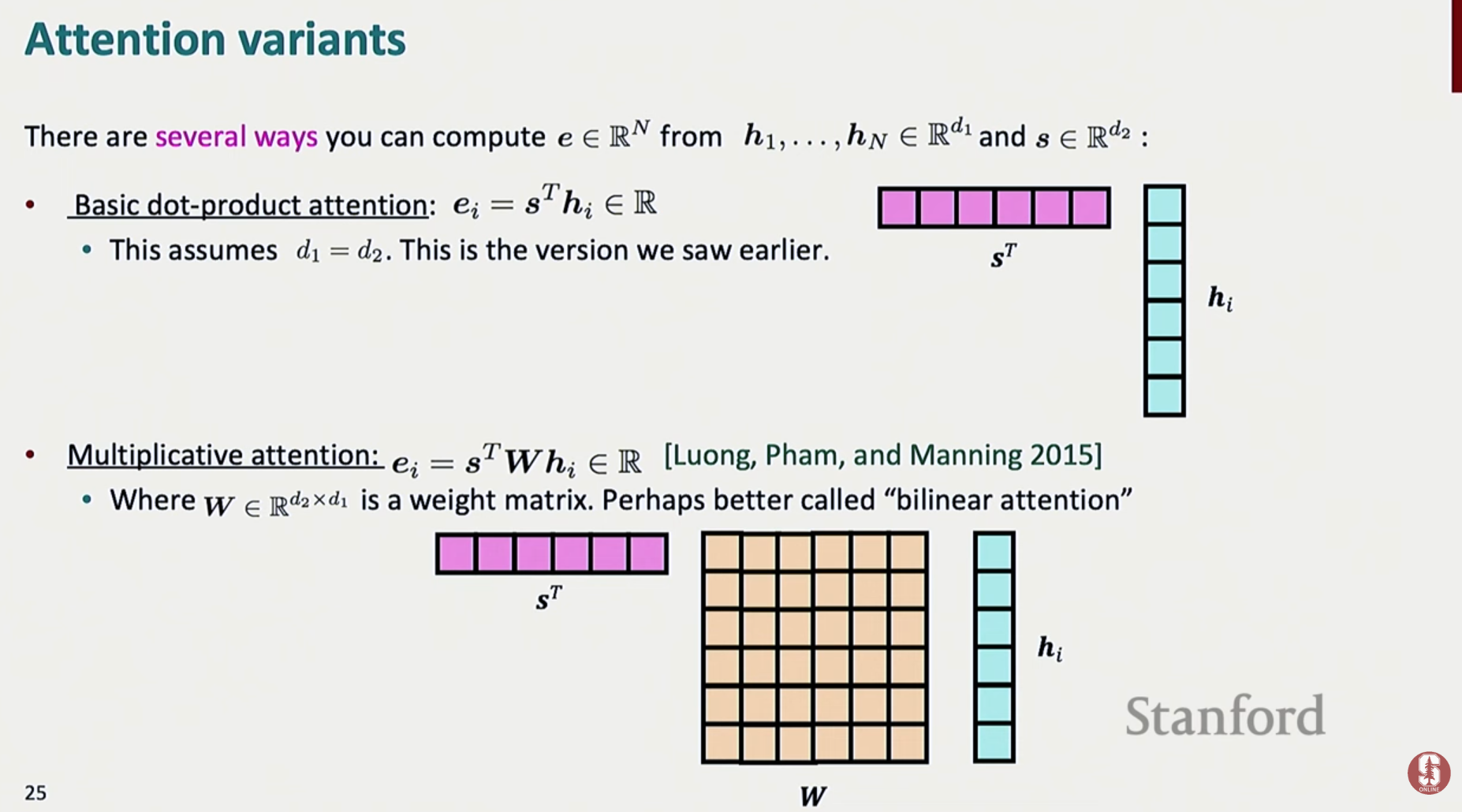
5) Attention Score 계산 방식
5.1 Dot-product Attention
5.2 Multiplicative (Luong-style) Attention
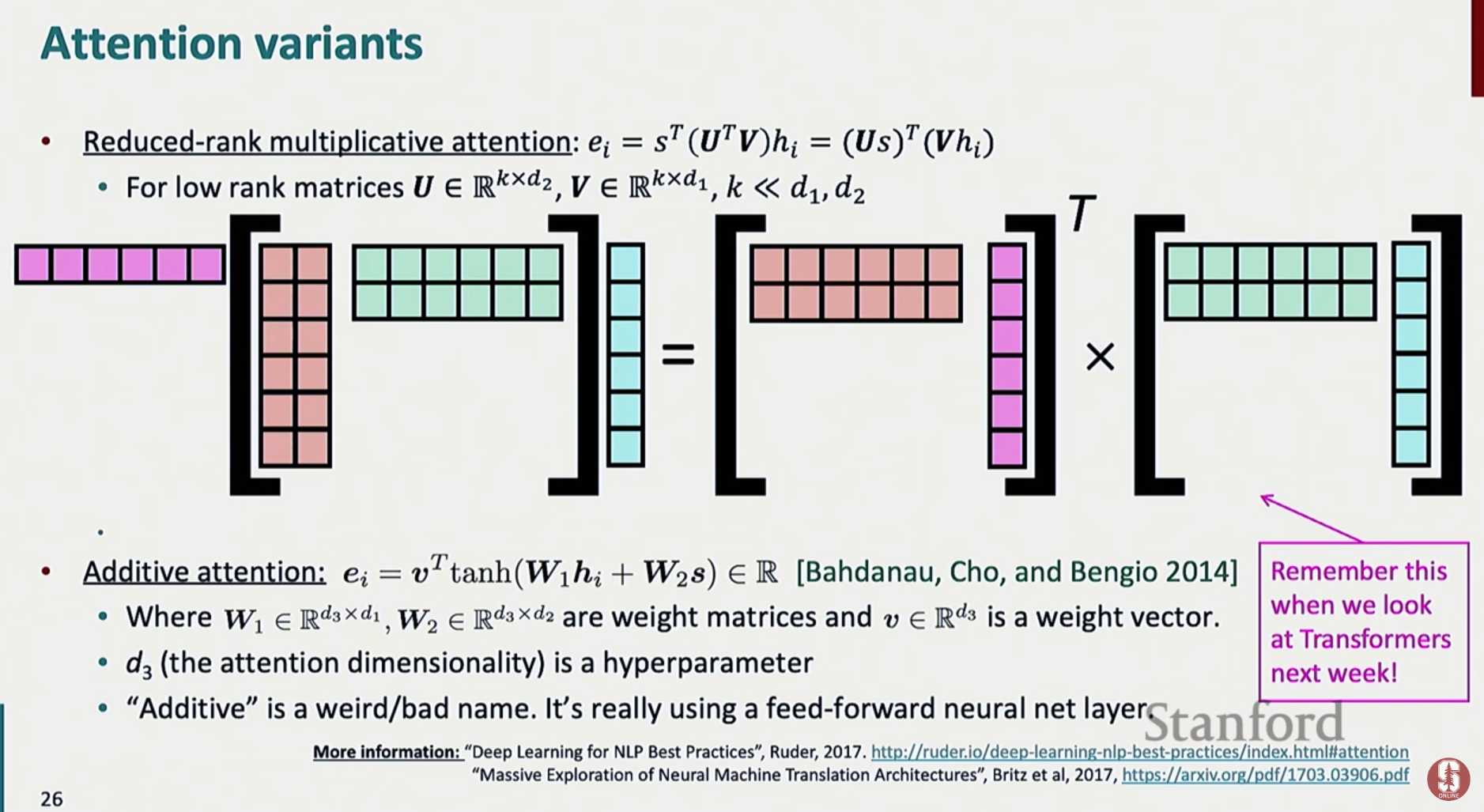
5.3 Reduced-rank Multiplicative Attention
- W를 낮은 rank로 근사 → 계산 효율 향상
5.4 Additive (Bahdanau-style) Attention
- 비선형 변환 적용
- 작은 hidden size에서 학습 안정성 증가

6) Attention의 일반화 (Q, K, V)
-
Attention은 Query-Key-Value 구조로 일반화될 수 있습니다.
- Query(Q): 디코더 hidden state
- Key(K): 인코더 hidden state
- Value(V): 인코더 hidden state 또는 다른 정보
- Scaling factor : dot-product 값이 커 softmax gradient가 작아지는 문제 방지
-
이 정의는 Transformer를 포함한 현대 NLP 모델의 핵심 구조입니다.

참고 논문
- Bahdanau et al., “Neural Machine Translation by Jointly Learning to Align and Translate,” ICLR 2015
- Luong et al., “Effective Approaches to Attention-based Neural Machine Translation,” EMNLP 2015
- Vaswani et al., “Attention Is All You Need,” NIPS 2017

AI 공부합니다