1. Pre-training 이전의 근본적 문제: 단어 표현
- BERT와 같은 모델이 등장하기 전, 초기 단어 임베딩 모델(Word2Vec 등)들은 '어휘집(Vocabulary)'에 기반하는 근본적인 문제가 있었습니다.
1) 미등록 단어 문제 (Out-of-Vocabulary, OOV)
- 훈련 데이터에 존재하지 않았던 새로운 단어(예: 신조어 'transformerify')나 오타가 발생하면, 모델은 이를 인식하지 못하고 전부 '알 수 없는 토큰(UNK)'으로 처리했습니다.
- 이는 정보의 손실로 이어졌고, 특히 형태론이 복잡한 언어(예: 스와힐리어)에서는 수많은 파생 단어를 모두 어휘집에 추가할 수 없어 비효율적이었습니다.

2) 해결책: 서브워드 분절 (Subword Tokenization)
- 이 문제를 해결하기 위해, 단어를 더 작은 의미 단위인 **'서브워드(Subword)'**로 분절하는 방식이 도입되었습니다.
- 예를 들어, 'transformerify'라는 단어는 'transform', 'er', 'ify'와 같이 의미를 가진 더 작은 조각으로 나눌 수 있습니다.
- 이 방식을 통해 모델은 처음 보는 단어도 아는 서브워드들의 조합으로 이해할 수 있게 되어 OOV 문제를 효과적으로 해결했습니다. BERT나 GPT 같은 현대 모델들은 모두 이 서브워드 방식을 기반으로 합니다.


2. Pre-training 패러다임의 시작
- 이전까지의 NLP 모델들은 Word2Vec과 같은 '사전 훈련된 단어 임베딩'을 가져와 모델의 맨 아래층(입력층)에만 사용하고, 나머지 부분(예: LSTM, Transformer)은 무작위 값으로 시작하여 특정 과제에 맞게 처음부터 학습했습니다.
1) 기존 방식의 한계: 문맥을 이해하지 못하는 단어 벡터
- Word2Vec 같은 기존의 임베딩 방식은 하나의 단어에 하나의 벡터만 할당했습니다.
- 이로 인해 "Please record this video" (동사)와 "She broke the world record" (명사)에서 'record'는 완전히 다른 의미임에도 불구하고, 동일한 벡터로 표현되는 한계가 있었습니다. 문맥에 따른 의미 변화를 포착할 수 없었죠.


2) 새로운 패러다임: Pre-training & Fine-tuning
- 현대적인 NLP 모델들은 새로운 접근법을 채택했습니다. 바로 모델의 모든 파라미터를 미리 학습시키는 사전 훈련(Pre-training)과, 특정 과제에 맞게 약간만 조정하는 미세 조정(Fine-tuning) 방식입니다.
사전 훈련(Pre-training)
- 대규모의 텍스트 데이터(예: 위키피디아, 책)를 사용해 '언어 자체'를 학습합니다.
- 모델은 문법, 의미, 단어 간의 관계, 심지어 세상의 상식까지 배우게 됩니다.
미세 조정(Fine-tuning)
- 이렇게 똑똑해진 사전 훈련 모델을 가져와, 우리가 풀고 싶은 특정 문제(예: 감성 분석, 질문 답변)에 대한 소량의 정답 데이터로 약간만 추가 학습을 시킵니다.
위 방식은 훨씬 적은 데이터로도 매우 높은 성능을 달성하게 하는 혁신을 가져왔습니다.

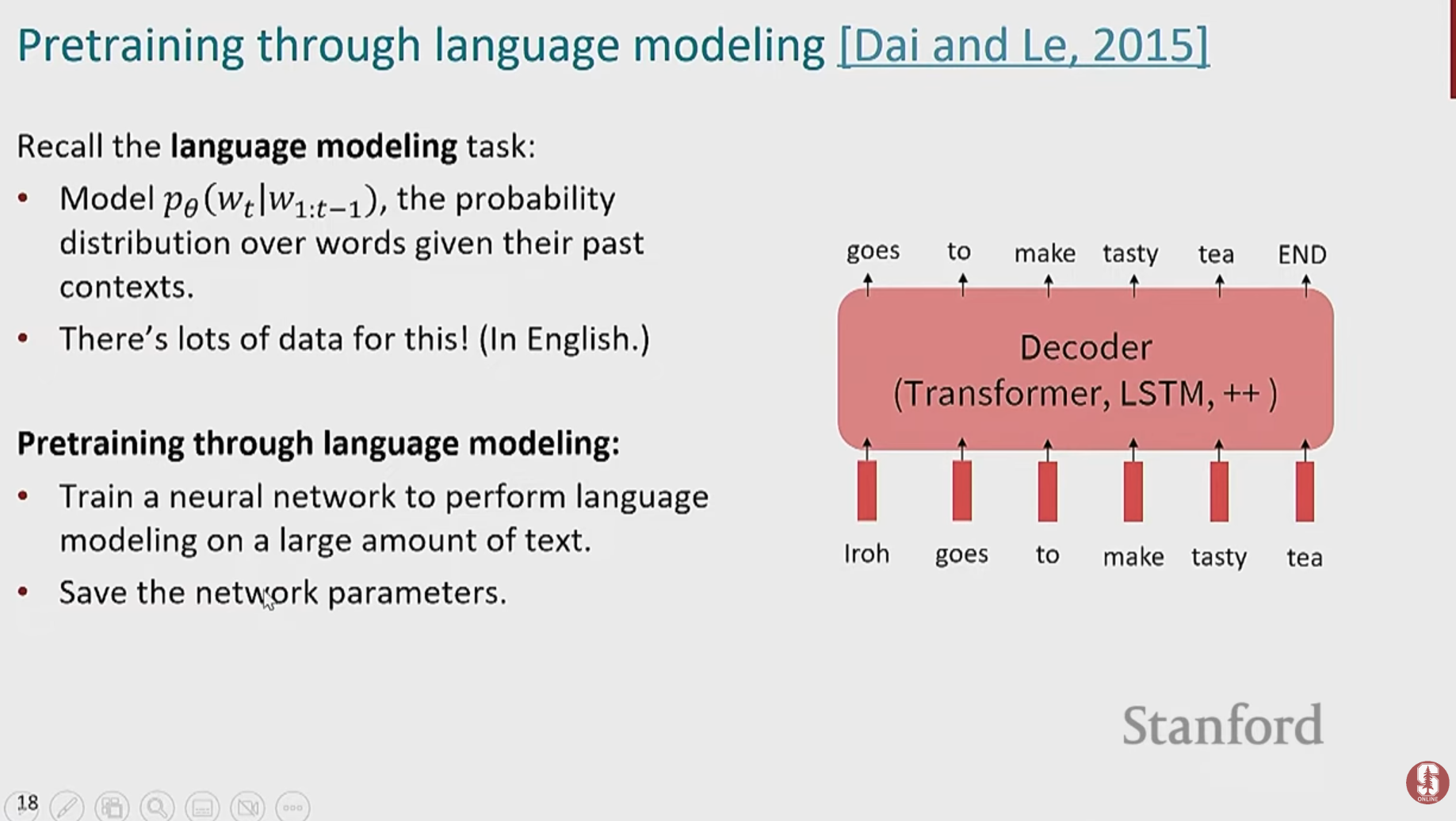
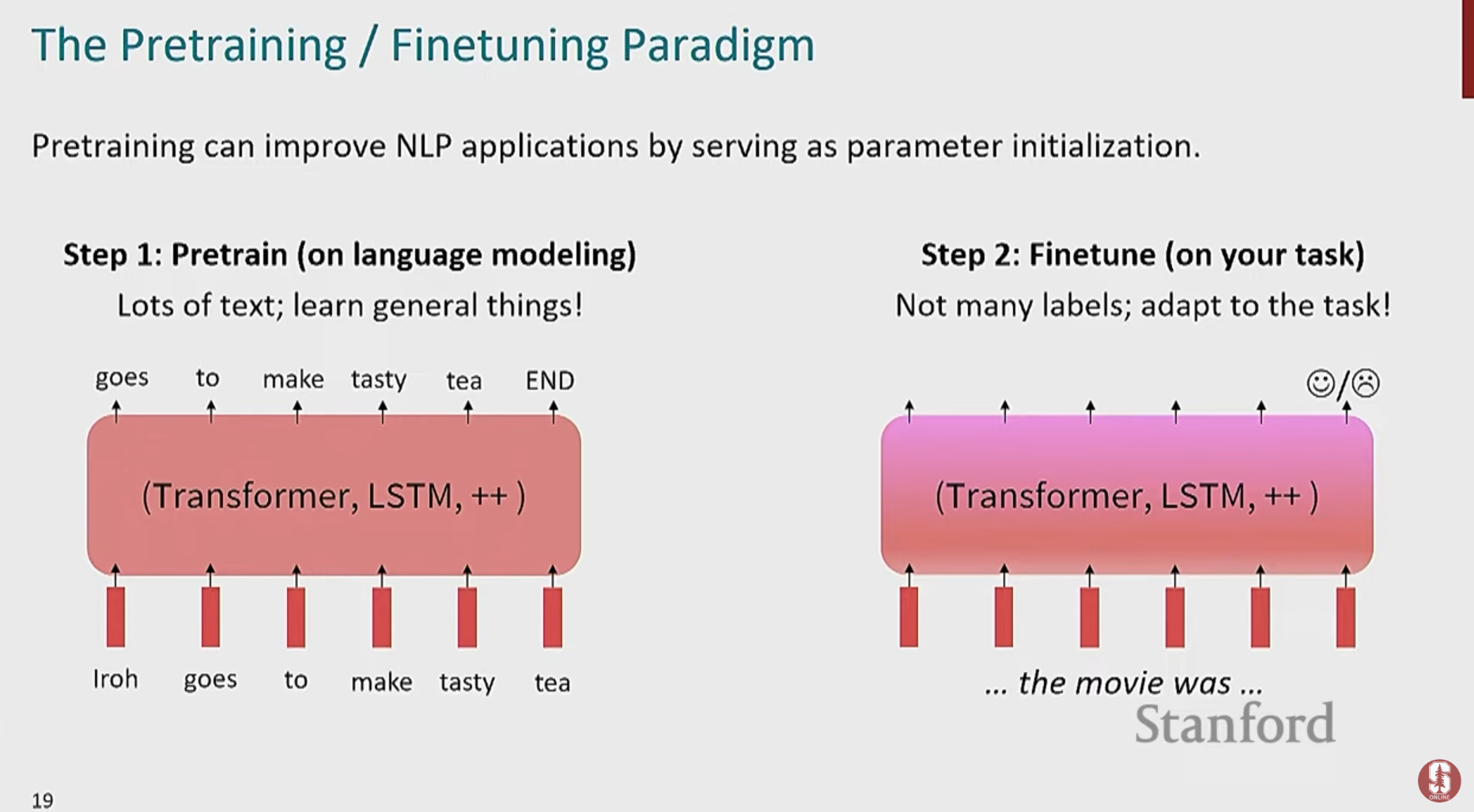

Pretraining for three types of architectures
(1) 인코더 (Encoder-Only) 아키텍처
- 인코더만 사용하는 구조로, BERT가 가장 대표적인 모델입니다.
- 문장 전체를 한 번에 입력받아 특정 단어의 앞뒤 문맥을 모두 참고하여 의미를 파악합니다.
- 주로 텍스트의 일부를 가리고 (Masking) 원래 단어를 맞추는 방식으로 학습하여, 문맥을 깊이 이해하는 데 매우 뛰어난 능력을 보입니다.
- 대표 모델: BERT, RoBERTa
- 핵심 목적: 텍스트 이해 및 분석 (NLU - Natural Language Understanding)
- 주요 과제: 감성 분석, 문장 분류, 개체명 인식 등
(2) 디코더 (Decoder-Only) 아키텍처
- 디코더만 사용하는 구조이며, GPT 계열이 대표적입니다.
- 이전 단어들을 바탕으로 다음에 올 단어를 순차적으로 예측하는 방식으로 작동합니다.
- 한 방향으로만 정보를 처리하기 때문에, 아주 자연스럽고 논리적인 문장을 생성하는 데 특화되어 있습니다.
- 대표 모델: GPT 계열, LLaMA, Claude
- 핵심 목적: 텍스트 생성 (NLG - Natural Language Generation)
- 주요 과제: 챗봇, 기사 작성, 소설 쓰기, 코드 생성 등
(3) 인코더-디코더 (Encoder-Decoder) 아키텍처
- 인코더와 디코더를 모두 결합한 구조입니다.
- 인코더가 입력 문장을 이해하여 핵심 의미를 추출하면, 디코더가 이 의미를 바탕으로 새로운 문장을 생성합니다.
- 입력된 정보를 다른 형태의 정보로 변환하는 작업에 가장 효과적입니다.
- 대표 모델: T5, BART, 초창기 Transformer
- 핵심 목적: 입력된 텍스트를 다른 텍스트로 변환 (Sequence-to-Sequence)
- 주요 과제: 기계 번역, 문서 요약, 질문-답변 등

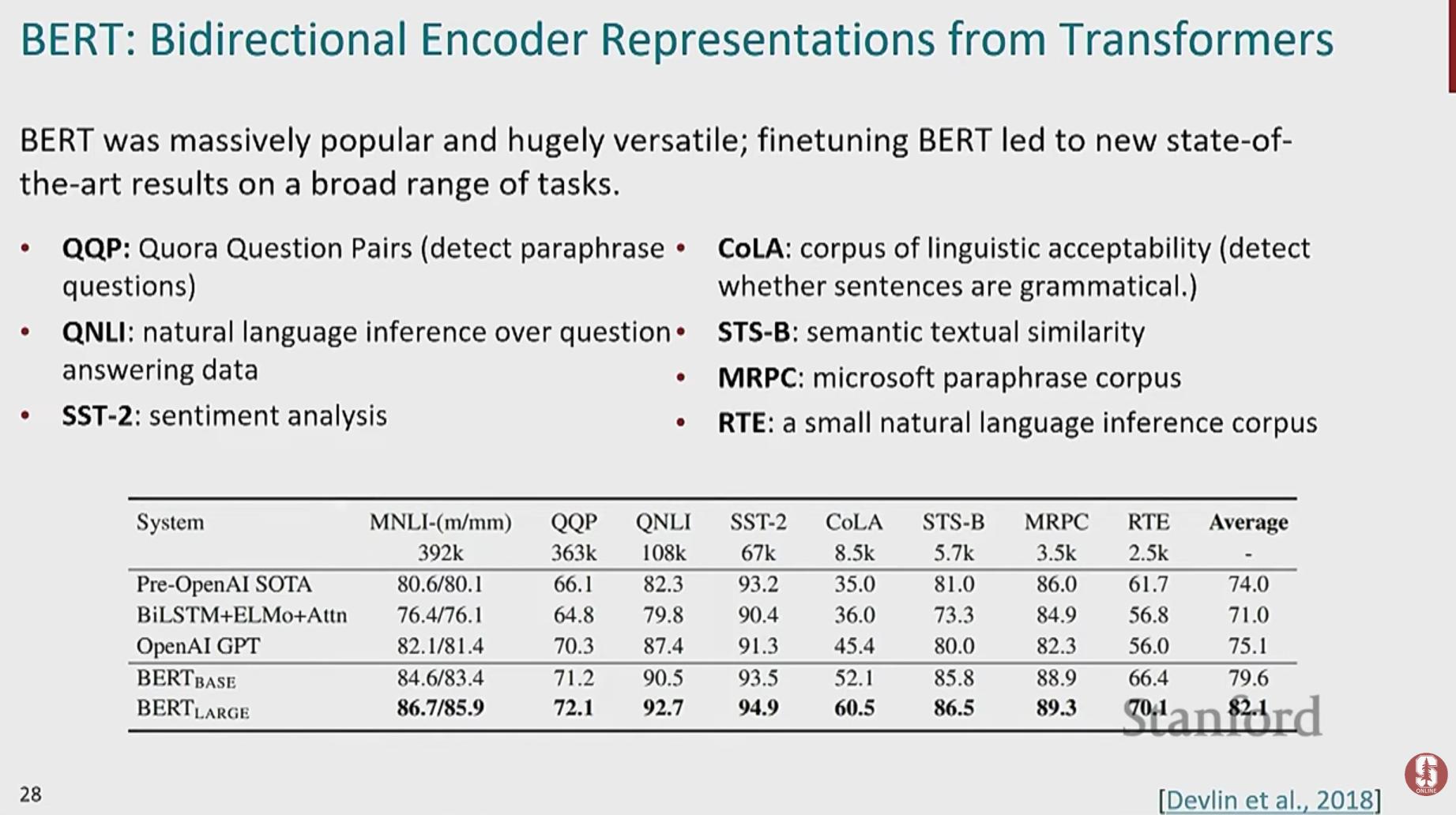
3. BERT: '이해'에 집중한 양방향 모델
- BERT(Bidirectional Encoder Representations from Transformers)는 Transformer의 인코더 구조만을 사용하여, 문장의 양방향 문맥을 동시에 깊이 이해하는 데 특화된 모델입니다.

1) 기술적 특징: 입력 표현 (Input Representation)
- BERT가 양방향 문맥과 문장 간의 관계를 학습할 수 있는 비결은 독특한 입력 방식에 있습니다.
- 입력은 세 가지 임베딩의 합으로 구성됩니다.
토큰 임베딩 (Token Embeddings)
- 각 서브워드 토큰의 의미를 나타내는 벡터입니다.
세그먼트 임베딩 (Segment Embeddings)
- NSP 과제를 위해, 입력이 두 문장으로 구성될 때 앞 문장(A)과 뒷 문장(B)을 구분해주는 벡터입니다.
위치 임베딩 (Position Embeddings)
- Transformer 인코더가 단어의 순서를 알 수 있도록 위치 정보를 더해주는 벡터입니다.
또한, 문장의 시작에는 항상 [CLS] 토큰을, 문장과 문장 사이 및 문장 끝에는 [SEP] 토큰을 추가하여 모델이 입력의 구조를 명확히 이해하도록 합니다.

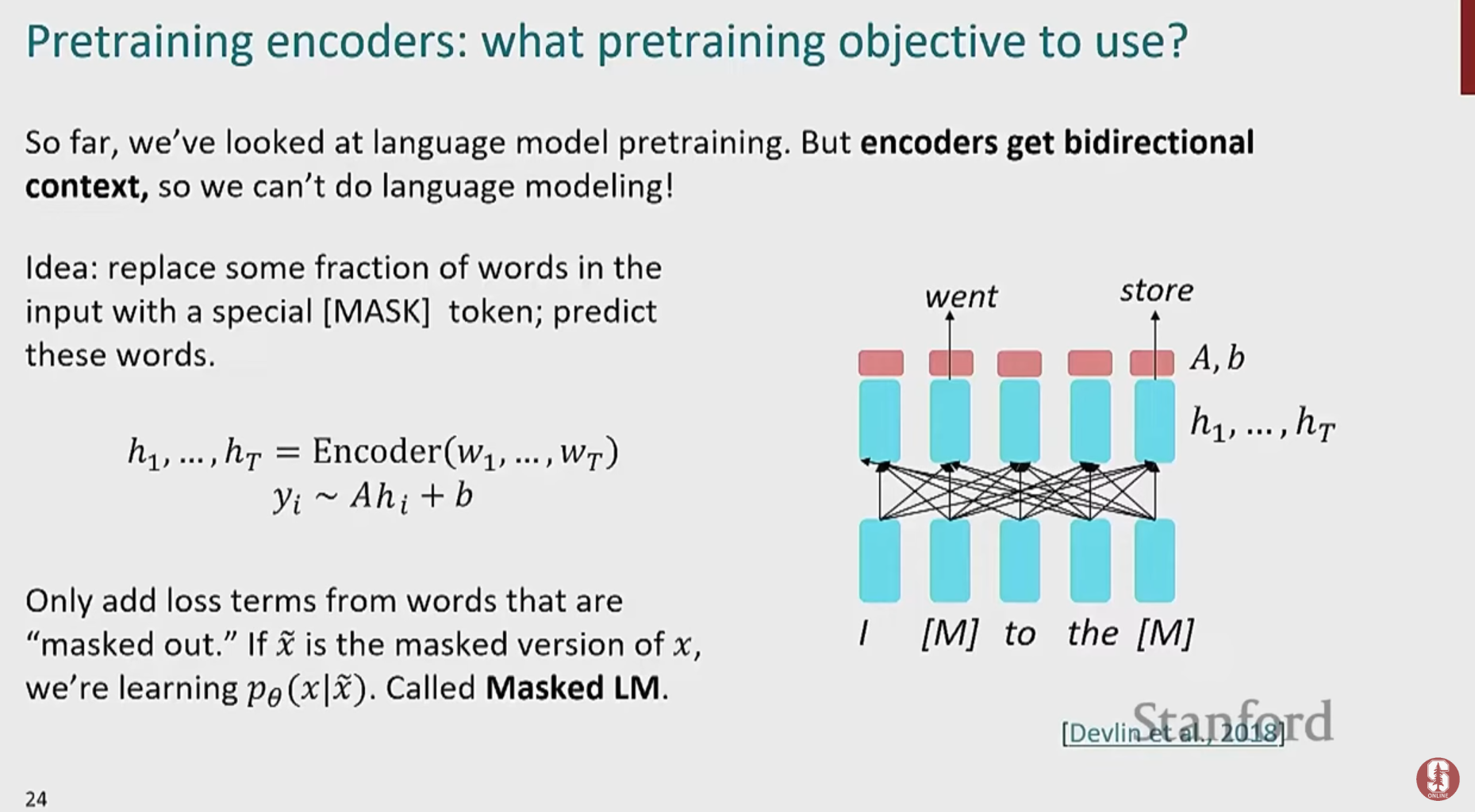
2) 핵심 훈련 방식: Masked Language Model (MLM)
- BERT는 다음 단어를 예측하는 대신, 문장의 일부를 무작위로 가리고(masking) 가려진 단어가 무엇인지 맞추는 '빈칸 채우기' 방식으로 학습합니다.
- "스탠포드 대학은 [MASK]에 위치해 있다."라는 문장에서 [MASK]가 '팔로 알토'임을 맞추려면 문장의 앞뒤 문맥을 모두 이해해야 합니다.
- 15% 규칙: 전체 단어의 15%를 선택하여 다음과 같은 세 가지 방식으로 빈칸 문제를 만듭니다.
- 80%: 진짜 [MASK] 토큰으로 바꿉니다. (가장 일반적인 방식)
- 10%: 완전히 다른 무작위 단어로 바꿉니다. (모델이 모든 단어를 의심하게 하여 표현력을 높임)
- 10%: 원래 단어 그대로 둡니다. (모델이 실제 단어의 표현도 학습하도록 함)

3) 보조 훈련 방식: Next Sentence Prediction (NSP)
- BERT는 문장 간의 관계를 학습하기 위해, 두 문장을 주고 두 번째 문장이 첫 번째 문장의 바로 다음에 이어지는 문장이 맞는지를 예측하는 과제를 함께 수행했습니다. (※ 이후 RoBERTa와 같은 후속 모델에서 이 과제는 큰 효과가 없음이 밝혀져 제거되기도 했습니다.)


4) 심화 내용: BERT의 구조와 한계
아키텍처 종류
- BERT는 주로 두 가지 크기로 제공됩니다. BERT-Base (12-layers, 768-hidden, 110M parameters)와 BERT-Large (24-layers, 1024-hidden, 340M parameters)이며, 후자가 더 높은 성능을 보입니다.
'진정한' 양방향성 (Deeply Bidirectional)
- 이전 모델인 ELMo 등이 단순히 정방향 RNN과 역방향 RNN의 결과를 얕게 결합(Shallow Concatenation)한 것에 비해, BERT의 Transformer 인코더는 Self-Attention을 통해 모든 단어가 모든 다른 단어와 처음부터 직접 상호작용합니다.
- 이는 '깊은 양방향' 문맥 이해를 가능하게 하는 핵심적인 차이점입니다.
사전 훈련과 미세 조정의 불일치 (Pre-train/Fine-tune Discrepancy)
- BERT의 주요 한계점 중 하나는, [MASK] 토큰이 사전 훈련 단계에서는 사용되지만 실제 데이터를 다루는 미세 조정 단계에서는 전혀 등장하지 않는다는 것입니다.
계산 비용
- 양방향 Self-Attention은 시퀀스 길이에 따라 계산량이 제곱으로 증가하여 매우 비용이 높습니다.
- 이 때문에 DistilBERT나 ALBERT처럼 모델의 크기와 계산량을 줄이려는 경량화 연구가 활발히 진행되었습니다.

4. GPT: '생성'과 '추론'의 새로운 패러다임
- BERT가 '이해'의 시대를 열었다면, GPT 시리즈는 Transformer의 디코더 구조만을 사용하여 '생성' 능력을 극대화했고, NLP의 패러다임을 다시 한번 전환시켰습니다.



1) 기술적 특징: 자기회귀 언어 모델 (Autoregressive LM)
- GPT는 오직 단방향(왼쪽에서 오른쪽) 문맥만 볼 수 있으며, 전통적인 언어 모델링, 즉 다음 단어를 예측하는 방식으로만 사전 훈련됩니다.
- 오직 생성에만 특화되어 매우 자연스럽고 일관성 있는 긴 글을 생성하는 데 탁월한 능력을 보입니다.

2) GPT-3: 새로운 능력의 출현 (Emergent Properties)
- 1750억 개의 파라미터라는 전례 없는 크기로 만들어진 GPT-3는 양적인 성장이 질적인 변화를 가져온 대표적인 사례입니다.
- 이전 모델에서는 볼 수 없었던 새로운 능력들이 나타났습니다.
In-Context Learning (Few-shot Learning)
- 가장 혁신적인 변화로, 일종의 메타 학습(Meta-learning) 능력으로 해석됩니다.
- 모델은 별도의 가중치 업데이트(미세 조정) 없이, 프롬프트에 제공된 몇 개의 예시(Few-shot)의 패턴을 추론하여 새로운 문제를 해결합니다.



사고의 연쇄 프롬프팅 (Chain-of-Thought, CoT)
- 이는 모델 아키텍처의 변화가 아닌 프롬프팅 기법의 발견입니다.
- 복잡한 추론 문제에 대해, 답만 알려주는 대신 답을 도출하는 중간 추론 과정(생각의 흐름)을 예시로 함께 제공하는 방식입니다.
- 이를 통해 사전 훈련된 모델에 잠재되어 있던 다단계 추론 능력이 활성화되었습니다.

3) 모델 성장의 법칙: Chinchilla의 발견
- GPT-3 이후, 무조건 모델 크기를 키우는 것이 최선인가에 대한 질문이 제기되었습니다.
- DeepMind의 Chinchilla 모델 연구를 통해, GPT-3가 파라미터 수에 비해 학습 데이터가 부족했다는 점, 즉 '불균형 성장'을 했다는 점이 밝혀졌습니다.
- Chinchilla는 GPT-3보다 모델 크기는 작지만, 훨씬 더 많은 데이터로 학습하여 GPT-3를 능가하는 성능을 보였습니다.
- 이를 통해 모델 성능을 최적으로 높이려면, 모델 파라미터 수와 학습 데이터의 양을 균형 있게 확장(Scaling Laws)해야 한다는 중요한 원칙이 확립되었습니다.

4) 심화 내용: Instruction Tuning과 RLHF
GPT-3의 한계
- GPT-3는 다음 단어를 예측하도록 훈련되었기 때문에, 사용자의 '지시(Instruction)'를 따르기보다는 인터넷의 글처럼 문장을 이어가는 경향이 있었습니다.
Instruction Tuning (지시 미세 조정)
- 이 문제를 해결하기 위해, "시를 써줘", "이 문단을 요약해줘"와 같이 인간이 작성한 다양한 '지시'와 그에 대한 '바람직한 결과물' 데이터셋으로 추가 미세 조정을 수행합니다.
RLHF (Reinforcement Learning from Human Feedback)
- Instruction Tuning을 한 단계 더 발전시킨 기법으로, ChatGPT의 핵심 기술입니다.
- 인간 평가자가 선호하는 답변에 더 높은 보상을 주도록 '보상 모델'을 학습시키고, 언어 모델이 이 보상 모델로부터 더 높은 점수를 받도록 강화학습을 통해 정교하게 조정합니다.
5. 그 외의 아키텍처 및 기법
- BERT와 GPT 외에도 다양한 접근법이 존재합니다.
1) 인코더-디코더 모델 (Encoder-Decoders)
- T5, BART와 같은 모델들은 BERT와 GPT의 특징을 결합한 인코더-디코더 구조를 가집니다.
- 문장의 일부에 연속적으로 마스킹(Span Corruption)을 하고, 디코더가 마스킹된 부분을 생성해내는 방식으로 학습합니다.
- 양방향 문맥을 이해하는 능력과 텍스트를 생성하는 능력을 모두 갖추고 있어, 번역이나 요약과 같은 생성 과제에 특히 강력한 성능을 보입니다.



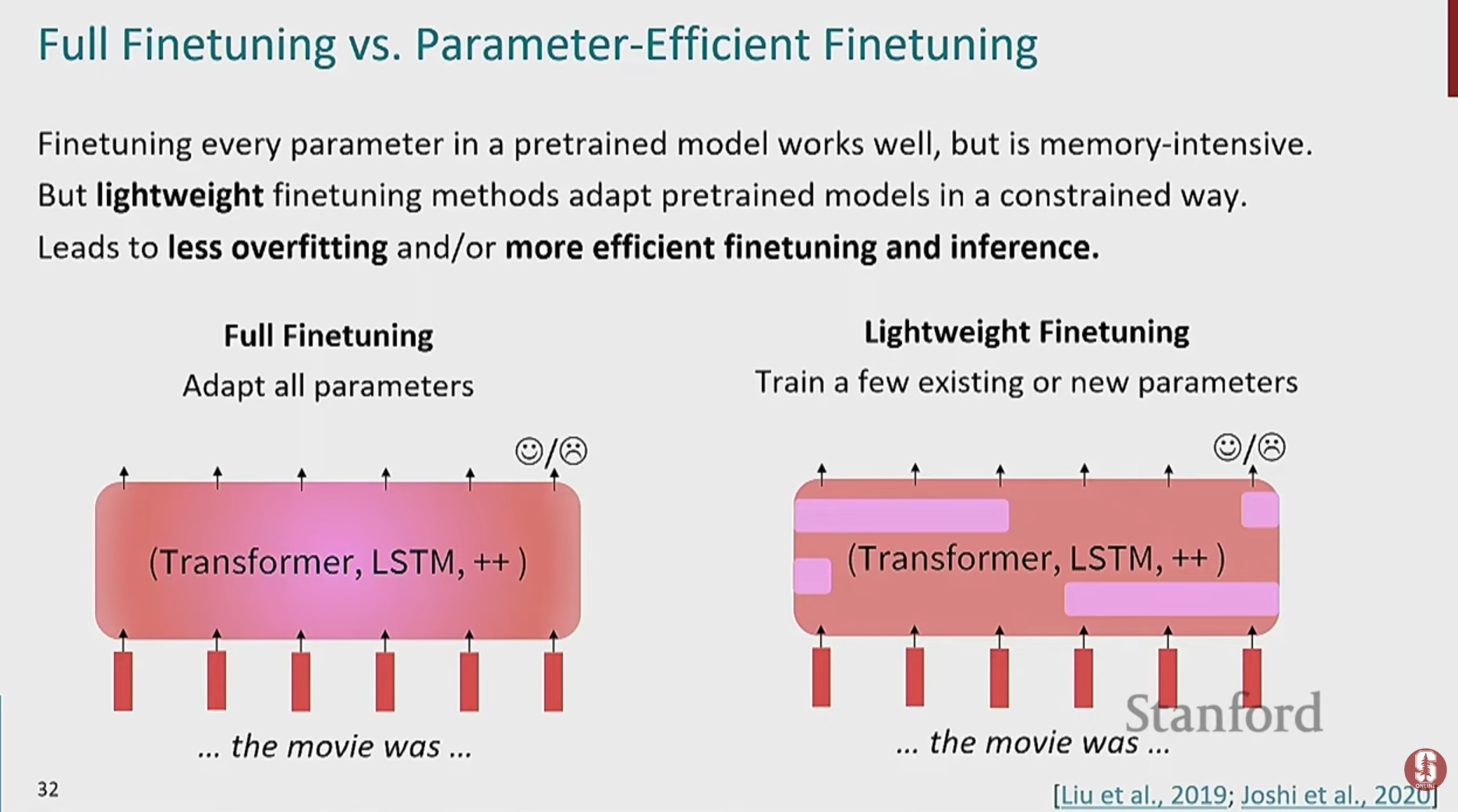
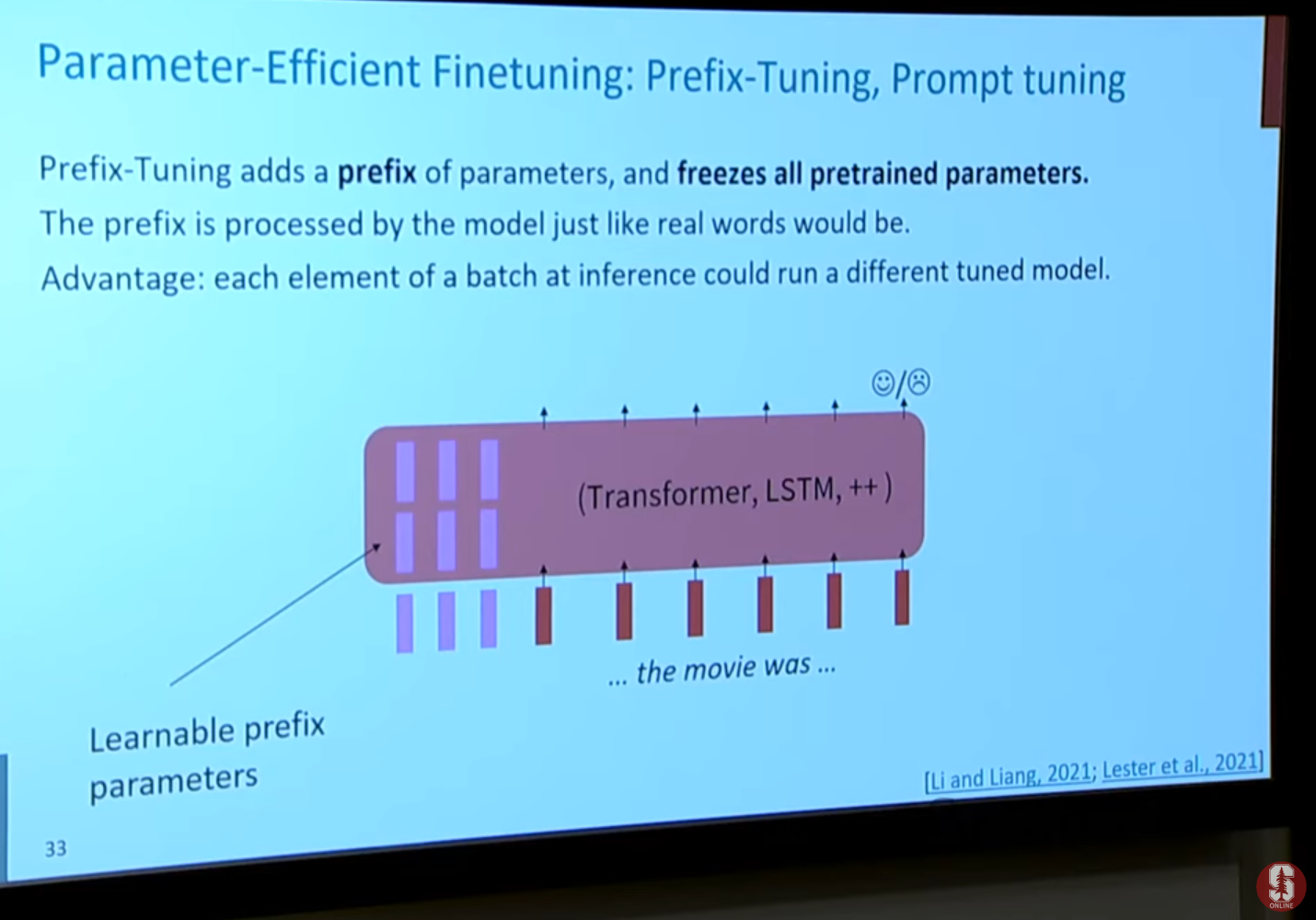
2) 파라미터 효율적 미세 조정 (Parameter-Efficient Fine-tuning, PEFT)
- 거대한 사전 훈련 모델 전체를 미세 조정하는 것은 막대한 계산 비용이 듭니다.
- 이를 해결하기 위해 모델 대부분의 가중치는 그대로 두고, 아주 일부의 파라미터만 학습시키는 효율적인 방법들이 제안되었습니다.
- LoRA(Low-Rank Adaptation)와 같은 기법은 적은 파라미터로도 기존 미세 조정과 유사한 성능을 낼 수 있어 널리 사용됩니다.

6. 결론: 사전 훈련 모델이 학습하는 것
- 사전 훈련을 통해 이 거대한 모델들은 단순히 문법이나 단어의 의미를 넘어, 세상의 상식, 추론 능력, 문맥 파악 능력 등 복합적인 지식을 학습합니다.
- 하지만 동시에, 학습 데이터에 내재된 사회적 편견(인종, 성별 등) 또한 그대로 학습하고 증폭시킬 수 있다는 명확한 한계와 위험성을 가지고 있습니다.
- 따라서 이러한 모델들의 작동 방식을 이해하고 책임감 있게 사용하는 것이 앞으로의 중요한 과제가 될 것입니다.

AI 공부합니다