1. 자연어 생성(NLG)의 모든 것
- 자연어 생성(Natural Language Generation, NLG)은 시스템이 유창하고, 일관성 있으며, 유용한 자연어 텍스트를 출력하는 모든 작업을 의미합니다.
1) NLG의 범주
- 자연어 처리(NLP)는 크게 두 가지로 나뉩니다.
- 자연어 이해 (NLU): 입력이 텍스트 (예: 감성 분석, 기계 독해)
- 자연어 생성 (NLG): 출력이 텍스트 (예: 번역, 요약, 챗봇)
- 과거에는 템플릿 기반의 규칙 시스템이 사용되었지만, 현재는 딥러닝, 특히 자기회귀(Auto-regressive) 언어 모델이 NLG의 표준으로 자리 잡았습니다.
- 이 모델은 이전에 생성된 단어들을 바탕으로 다음 단어를 순차적으로 예측하는 방식으로 작동합니다.
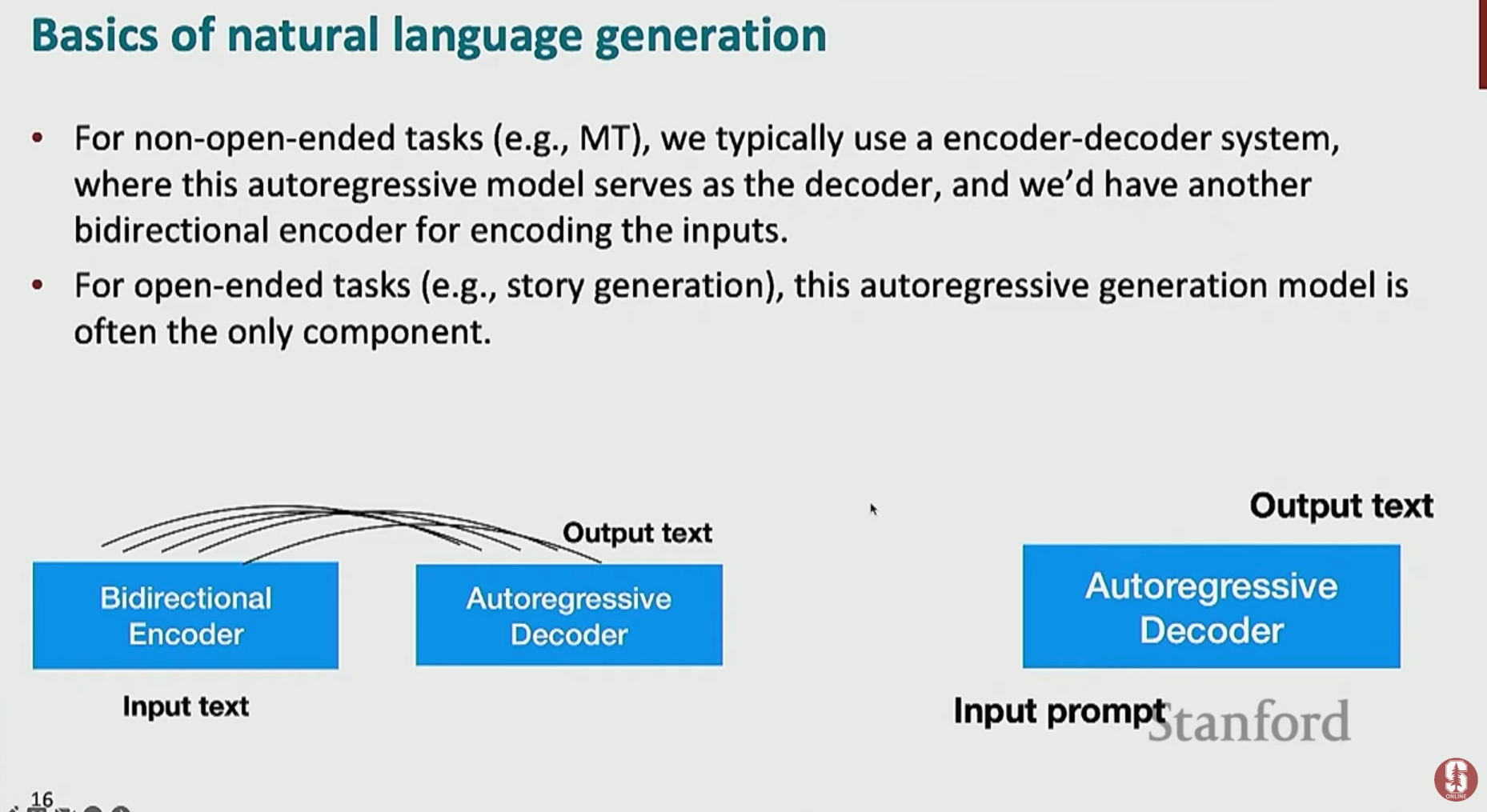
2) 개방성에 따른 NLG 작업 분류
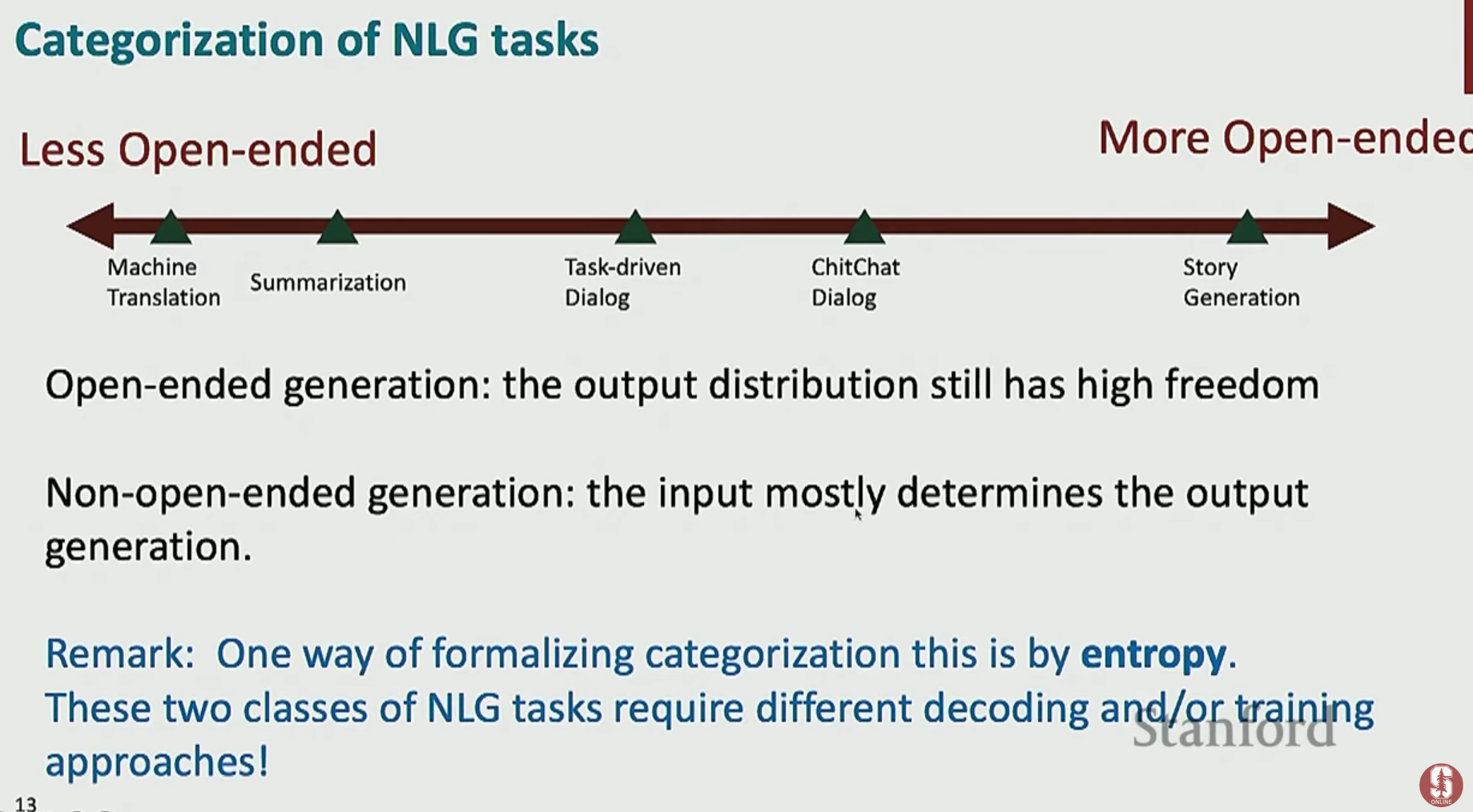
- NLG 작업은 입력에 따라 출력의 정해진 정도, 즉 개방성(Openness)에 따라 분류할 수 있습니다.
비개방형 (Closed-ended): 입력이 주어지면 출력이 거의 하나로 정해지는 작업. (예: 기계 번역, 요약)
개방형 (Open-ended): 유효한 출력이 매우 다양하고 창의성이 요구되는 작업. (예: 스토리 생성, 챗봇 대화)
2. 디코딩: 모델의 생각을 텍스트로 바꾸는 방법
- 언어 모델이 다음 단어에 대한 확률 분포를 계산했을 때, 그중 어떤 단어를 최종적으로 선택할지를 결정하는 알고리즘을 디코딩(Decoding)이라고 합니다.
- 이는 NLG 시스템의 품질을 결정하는 매우 중요한 단계입니다.



1) 최대 확률 기반 디코딩: 가장 그럴듯한 길 찾기
- 목표: 전체 문장의 확률을 최대화하는 단어 시퀀스를 찾는 것.
Greedy Decoding
- 가장 간단한 방식으로, 각 단계(time step)에서 가장 확률이 높은 단어 하나만을 선택하여 다음으로 넘어갑니다.
- 빠르지만 근시안적인 선택으로 인해 최적의 문장을 놓칠 수 있습니다.
Beam Search
- 빔 서치(Beam Search)는 Greedy Decoding의 단점을 보완한 디코딩 방식으로, 각 단계에서 가장 확률이 높은 단어 하나만 선택하는 대신, 지정된 K개(빔 너비, Beam Width)만큼의 후보 문장을 항상 유지하며 탐색하는 기법입니다.
작동 방식:
- 첫 단계에서 가장 확률이 높은 K개의 단어를 선택하여 K개의 후보 문장을 만듭니다.
- 각 후보 문장에 대해, 다음에 올 수 있는 모든 단어를 계산하여 가능한 모든 다음 문장을 생성합니다.
- 생성된 모든 다음 문장들 중에서, 전체 문장의 누적 확률이 가장 높은 상위 K개를 다시 선택합니다.
- 이 과정을 문장이 끝날 때까지 반복하고, 최종적으로 완성된 K개의 문장 중 가장 높은 확률을 가진 문장을 선택합니다.
장점과 한계:
- 장점: Greedy Decoding보다 더 넓은 탐색 공간을 고려하므로, 전체적으로 더 자연스럽고 확률이 높은 문장을 찾을 가능성이 큽니다.
- 한계: 여전히 최종 목표는 '가장 확률이 높은 단 하나의 문장'을 찾는 것이기 때문에, 창의적인 생성이 필요한 개방형 작업에서는 Greedy Decoding과 마찬가지로 지루하고 반복적인 텍스트를 생성하는 '퇴행(Degeneration)' 문제를 해결하지는 못합니다.

치명적인 문제점: 퇴행 현상 (Degeneration)
- 이 방식들은 비개방형 작업(번역 등)에서는 잘 작동하지만, 개방형 생성 작업에서는 매우 지루하고, 의미 없이 반복적인 텍스트("I don't know I don't know I don't know...")를 생성하는 경향이 있습니다.
- 원인:
- 모델이 "I don't know"와 같은 흔하고 안전한 표현을 한번 생성하기 시작하면, 그 표현이 다음 단어를 예측하는 문맥으로 다시 입력됩니다.
- 이는 모델이 해당 표현을 생성할 확률을 더욱 높이는 '자기 강화(self-reinforcing)' 효과를 일으켜, 결국 같은 구절에 갇혀버리게 만듭니다.


2) 샘플링 기반 디코딩: 인간처럼 자연스럽게 말하기
- 최대 확률이 항상 최선은 아니라는 인식에서 출발합니다.
- 인간의 언어는 예측 불가능성과 다양성을 포함하므로, 확률 분포에서 단어를 '추출(Sampling)'하여 더 자연스러운 텍스트를 생성하려는 접근법입니다.
- 문제점: 롱테일 분포 (Long-tail Distribution)
- 순수하게 확률에 따라 샘플링하면, 언어의 '롱테일' 문제에 부딪힙니다.
- 어휘집에는 확률이 매우 낮지만 개수가 엄청나게 많은 부적절한 단어들(예: 'xylophone', 'pterodactyl')이 존재합니다.
- 이들의 개별 확률은 낮지만, 모두 합치면 무시할 수 없는 확률 질량을 차지하여, 샘플링 시 이상한 단어가 튀어나올 위험이 큽니다.
- 해결책: 꼬리 자르기 (Truncating the Tail)
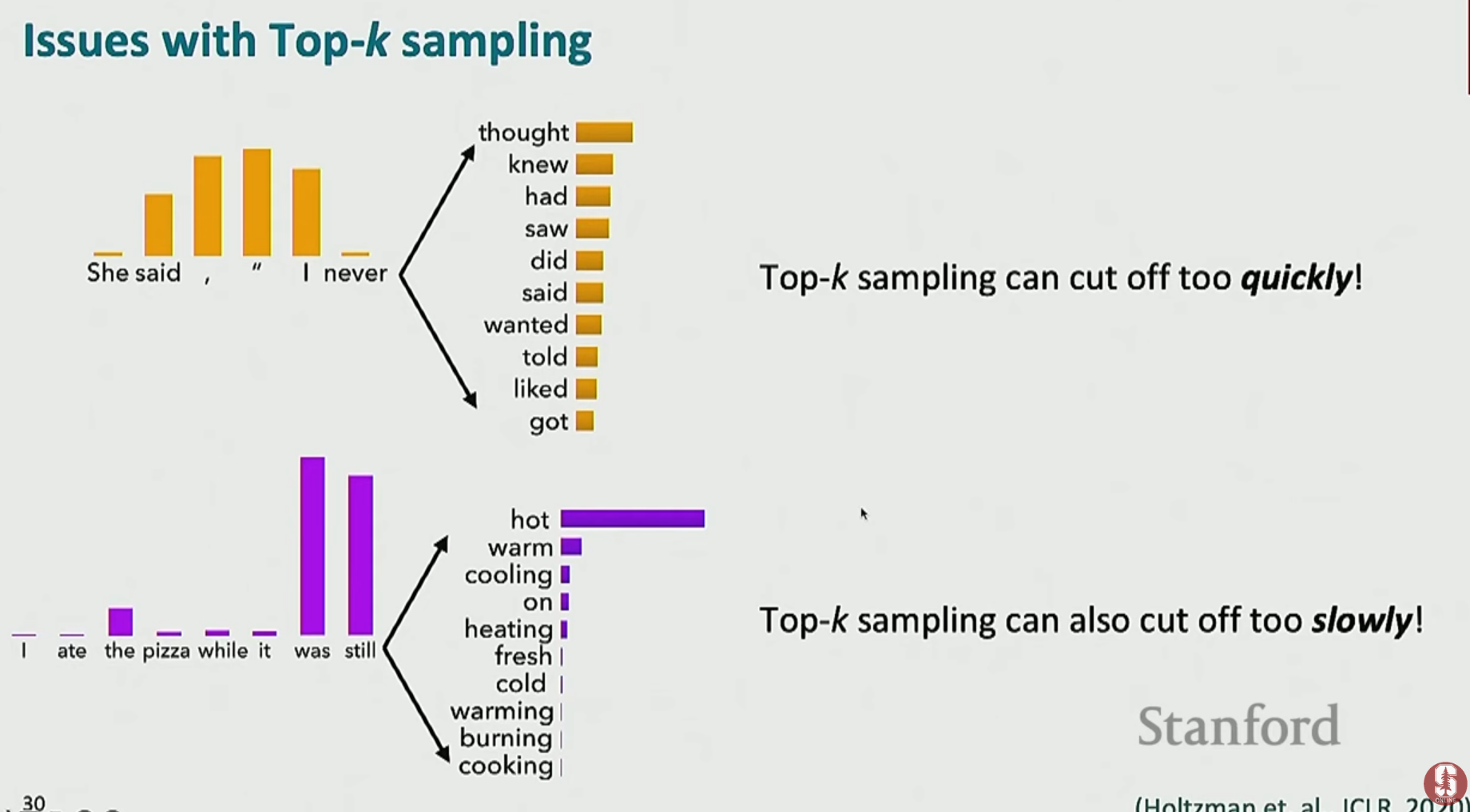
- Top-K Sampling:
- 확률 분포에서 가장 확률이 높은 상위 K개의 단어만을 후보로 삼고, 그 안에서만 샘플링합니다.
- K를 어떻게 정하느냐에 따라 성능이 크게 달라지는 단점이 있습니다. (K가 너무 작으면 다양성 부족, 너무 크면 롱테일 문제 재발)
- Top-P (Nucleus) Sampling:
- 고정된 K개 대신, 확률의 누적 합이 특정 임계값(P, 예: 0.92)에 도달할 때까지의 상위 단어들(핵심 집합, Nucleus) 내에서만 샘플링합니다.
- 이는 문맥에 따라 후보 단어의 수를 동적으로 조절하는 매우 효과적인 방법입니다.
- 예를 들어, 모델이 다음에 올 단어를 확신하는 상황(뾰족한 분포)에서는 후보 수를 적게 가져가고, 불확실한 상황(평평한 분포)에서는 더 많은 후보를 고려하여 유연하게 대처합니다.
- Top-K Sampling:


3) 기타 디코딩 기법: 섬세한 조율
-
온도 (Temperature):
- 소프트맥스 함수에 온도 T 매개변수를 추가하여 분포의 뾰족함을 조절합니다.
- T > 1이면 분포가 평평해져 더 다양하고 창의적인(때로는 엉뚱한) 텍스트가 생성되고, T < 1이면 분포가 뾰족해져 더 안전하고 정해진 텍스트가 생성됩니다.
- T가 0에 가까워지면 Greedy Decoding과 같아집니다.

-
재랭킹 (Re-ranking):
- 일단 샘플링 기법 등으로 여러 개의 후보 문장을 생성한 뒤, 유창성, 사실성, 다양성, 반복성 등 별도의 정교한 평가 기준으로 점수를 매겨 가장 좋은 문장을 최종 선택하는 방식입니다.
- 생성 후 품질을 한 번 더 검증하는 과정입니다.

3. 모델 훈련의 과제와 해결책
- 표준적인 최대 우도 추정(Maximum Likelihood Estimation, MLE) 훈련 방식은 NLG에서 몇 가지 근본적인 문제를 야기합니다.
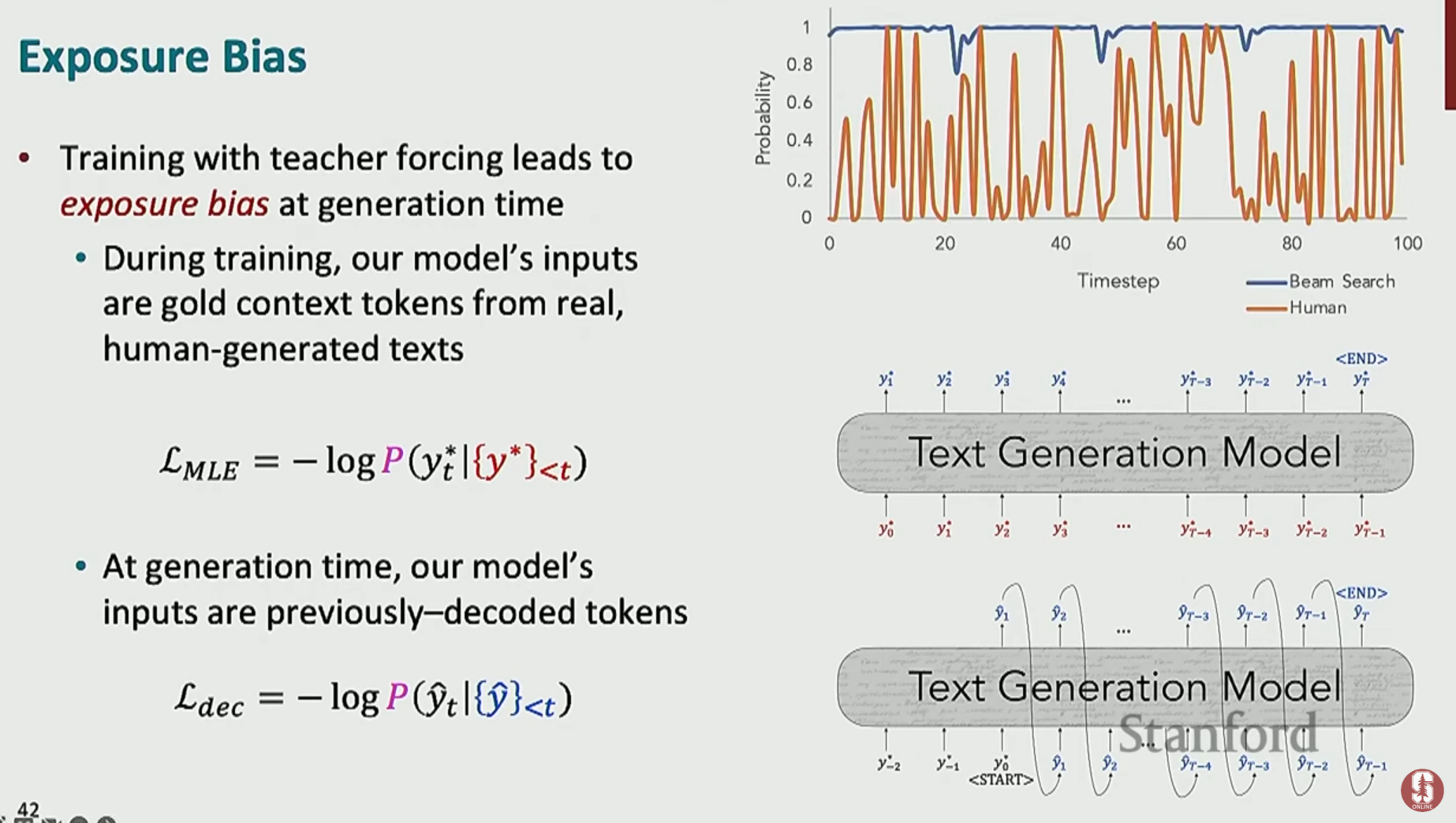
1) 노출 편향 (Exposure Bias)
- 핵심 문제: 훈련과 테스트 환경의 불일치에서 비롯됩니다.
- 훈련 시 (Teacher Forcing): 모델은 항상 완벽한 정답(Ground Truth) 단어를 다음 입력으로 받으며 학습합니다. 마치 운전 교관이 항상 옆에서 핸들을 바로잡아주는 것과 같습니다.
- 테스트 시 (Student Forcing): 모델은 정답 없이, 오직 이전에 자신이 생성한 단어를 다음 입력으로 사용해야 합니다. 교관 없이 혼자 운전하는 것과 같죠.
- 결과: 이 불일치 때문에, 모델은 훈련 중에 자신의 실수를 경험하고 바로잡을 기회가 전혀 없습니다. 따라서 실제 생성 시 한번 실수를 시작하면 그 오류가 다음 단계의 입력으로 들어가 더 큰 오류를 낳는 오류 누적(compounding errors) 현상이 발생합니다.
2) 노출 편향 해결을 위한 접근법
스케줄드 샘플링 (Scheduled Sampling)
- 훈련 시 일정 확률로 정답 대신 모델 자신의 예측을 입력으로 사용합니다.
- 훈련 초기에는 정답만 보여주다가, 점차 모델 자신의 예측을 보여주는 비율을 높여 테스트 환경에 점진적으로 적응시킵니다.
데이터셋 통합 (DAgger)
- 훈련 중간중간 현재 모델을 사용해 텍스트를 생성하고, 이 생성된 텍스트들을 다시 훈련 데이터에 추가하여 모델이 자신의 실수로부터 배울 수 있는 기회를 제공합니다.
검색 증강 생성 (Retrieval Augmented Generation, RAG)
- 모델이 처음부터 텍스트를 창작하는 대신, 외부 데이터베이스에서 관련 정보를 먼저 검색(Retrieve)하고, 검색된 내용을 바탕으로 이를 편집(삽입, 삭제 등)하여 최종 답변을 생성하도록 훈련하는 방식입니다.
- 품질 높은 텍스트를 기반으로 시작하므로, 생성 초반에 잘못된 길로 빠져 오류가 누적되는 노출 편향 문제를 완화하는 데 효과적입니다.
강화학습 (Reinforcement Learning, RL)
- 텍스트 생성을 마르코프 결정 과정으로 간주합니다.
- 정책(Policy): 언어 모델 자신
- 행동(Action): 다음 단어 선택
- 보상(Reward): 생성된 전체 텍스트의 품질 점수
- 이 프레임워크에서, 모델은 생성된 텍스트의 품질(예: 번역의 BLEU 점수, 요약의 ROUGE 점수, 혹은 인간의 선호도)을 '보상(Reward)'으로 정의하고, 이 보상을 최대화하는 방향으로 훈련됩니다.
- 이는 최종 출력의 품질을 직접적으로 최적화한다는 장점이 있습니다.


3) 최신 모델의 훈련 파이프라인 (ChatGPT 방식)
- 현대의 대규모 언어 모델은 이러한 문제들을 해결하기 위해 정교한 3단계 파이프라인을 통해 훈련됩니다.
- 사전 훈련 (Pre-training): 대규모 텍스트 데이터로 언어의 일반적인 패턴을 학습합니다. (예: GPT-3)
- 명령어 미세 조정 (Instruction Fine-tuning): 인간의 지시를 잘 따르도록, '지시-응답' 쌍으로 구성된 데이터셋으로 지도 학습(Supervised Fine-tuning)을 진행합니다.
- 인간 피드백 기반 강화학습 (RLHF): 이것이 핵심입니다.
a. 모델이 여러 답변을 생성하면, 인간 평가자가 어떤 답변이 더 나은지 순위를 매깁니다.
b. 이 순위 데이터를 사용하여 인간의 선호도를 모방하는 별도의 **'보상 모델(Reward Model)'**을 훈련합니다.
c. 원래의 언어 모델은 이 보상 모델로부터 더 높은 점수를 받는 텍스트를 생성하도록 강화학습을 통해 정교하게 조정됩니다.
- 이 과정을 통해 모델은 단순히 그럴듯한 문장을 넘어, 인간이 선호하는 유용하고(Helpful), 진실되며(Honest), 무해한(Harmless) 답변을 생성하도록 정렬(Align)됩니다.
4. NLG 평가의 어려움: 좋은 텍스트란 무엇인가?
- 생성된 텍스트의 품질을 자동으로 평가하는 것은 자연어 생성 분야에서 가장 어렵고 중요한 문제입니다.
- 강의에서는 현재 사용되는 평가 방법들을 소개하며 각각의 명확한 한계를 지적합니다.

1) 자동 평가 지표: 빠르지만 얕은 접근
- 인간의 평가를 흉내 내어 점수를 자동으로 계산하는 방식으로, 빠르고 비용이 저렴해 널리 사용됩니다.
어휘 중복 기반 지표 (Content Overlap Metrics)
- 개념: 생성된 텍스트가 사람이 만든 정답(Reference) 텍스트와 얼마나 많은 단어(n-gram)를 공유하는지를 기반으로 점수를 매깁니다. 대표적으로 번역에 사용되는 BLEU, 요약에 사용되는 ROUGE가 있습니다.
- 치명적인 한계: 이 방식은 '어휘'에만 의존하기 때문에 의미를 전혀 파악하지 못합니다.
- 오탐 (False Positive): "고양이가 매트 위에 있다"라는 정답에 대해, 모델이 "매트 위에 고양이는 없다"라고 생성하면, 단어 중복률이 높아 높은 점수를 받지만 의미는 정반대입니다.
- 오인 (False Negative): "고양이가 양탄자 위에 앉아있다"처럼 의미는 완전히 동일하지만 다른 단어를 사용하면, 단어 중복률이 낮아 낮은 점수를 받습니다.
- 결론: 비개방형 작업에서는 최소한의 기준으로 사용될 수 있으나, 다양한 표현이 가능한 개방형 작업에서는 거의 무의미한 지표가 될 수 있습니다.



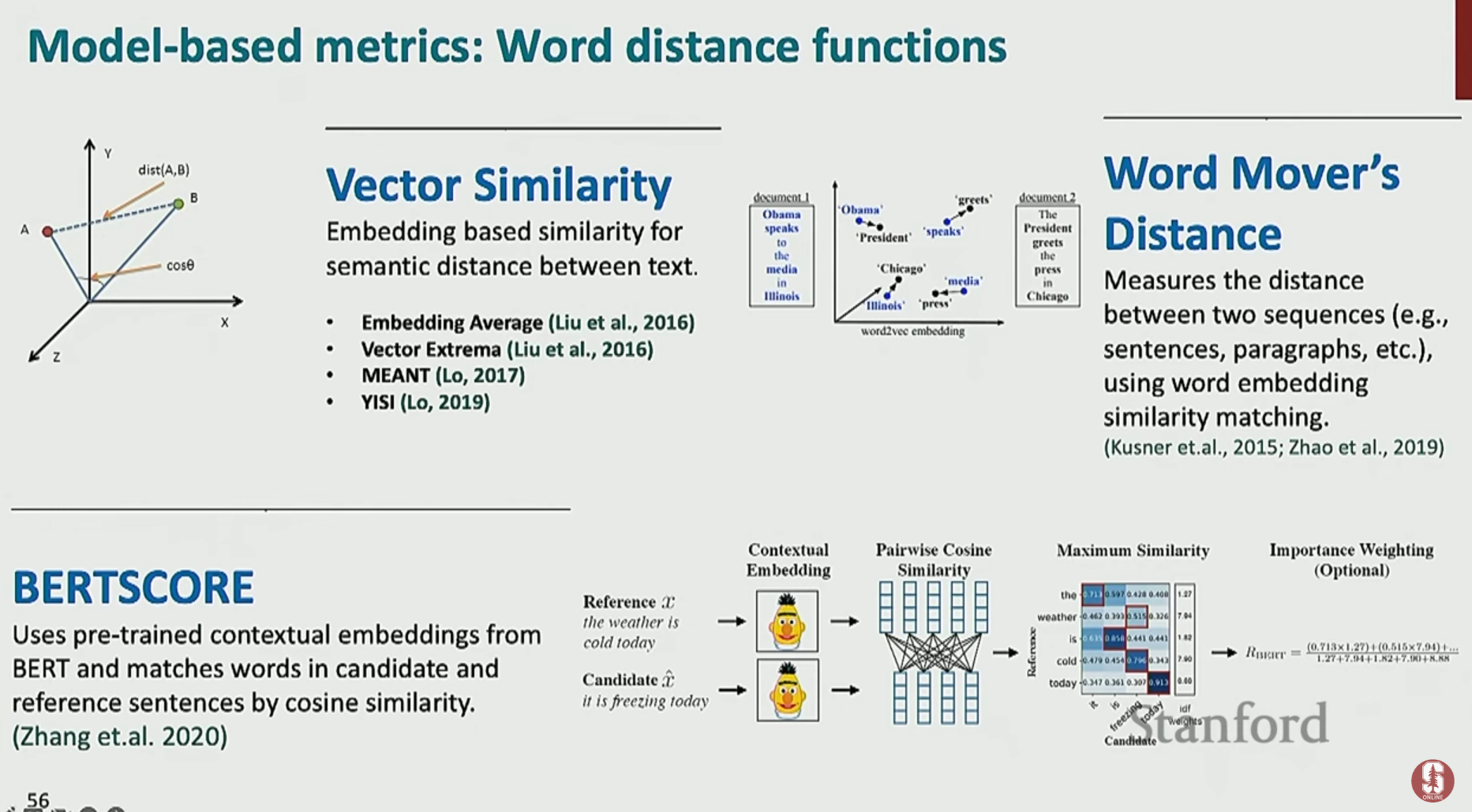
모델 기반 지표 (Model-Based Metrics)
- 개념: 단순한 단어 비교를 넘어, BERT와 같은 사전 훈련된 언어 모델을 사용하여 두 문장 간의 의미적 유사도를 측정하는 발전된 방식입니다.
- 주요 기법:
- BERTScore: 생성된 문장과 정답 문장의 각 단어를 BERT로 임베딩한 뒤, 단어들 간의 코사인 유사도를 계산하여 최적으로 정렬하고 점수를 매깁니다. 어휘가 달라도 의미가 비슷하면 높은 점수를 줄 수 있습니다.
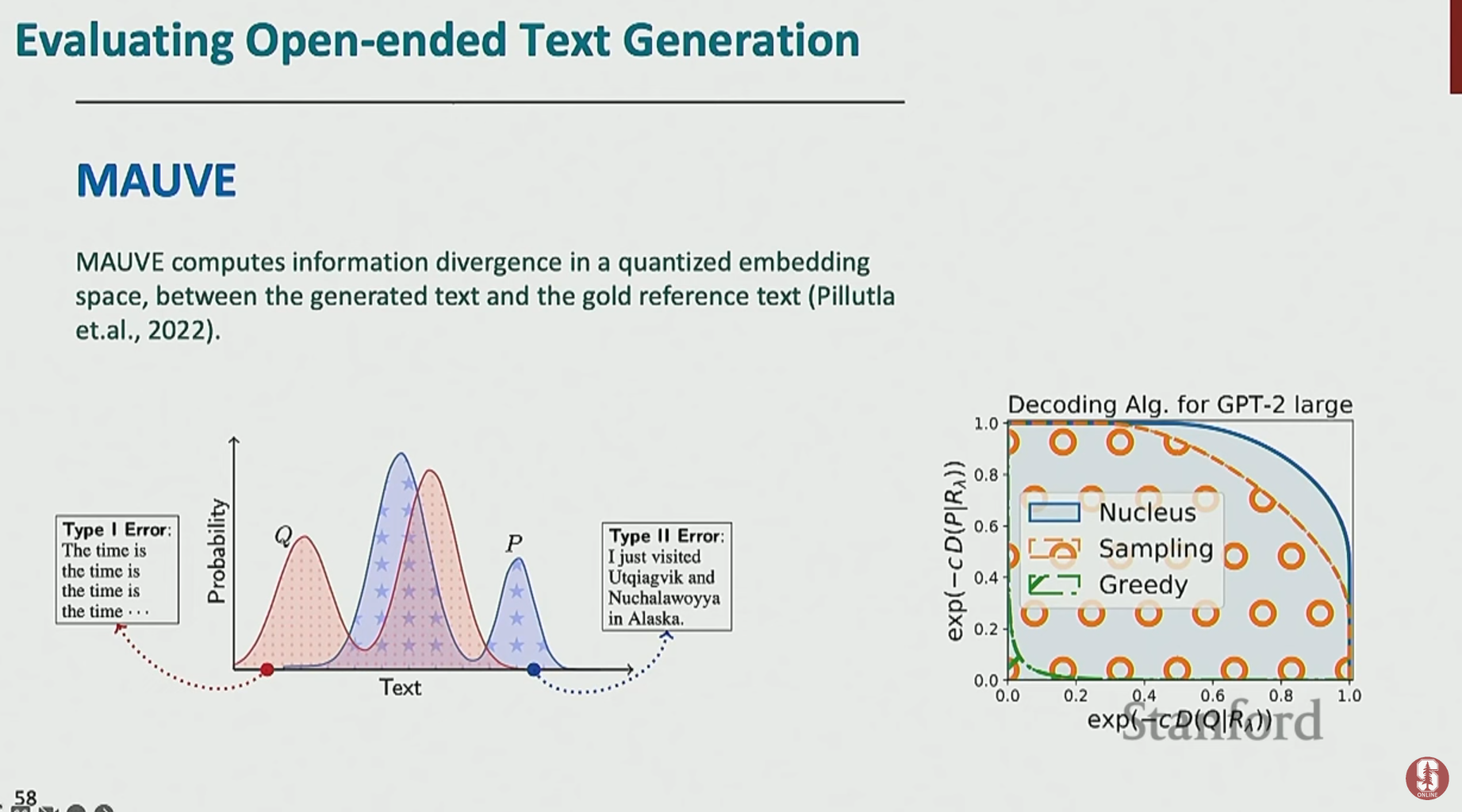
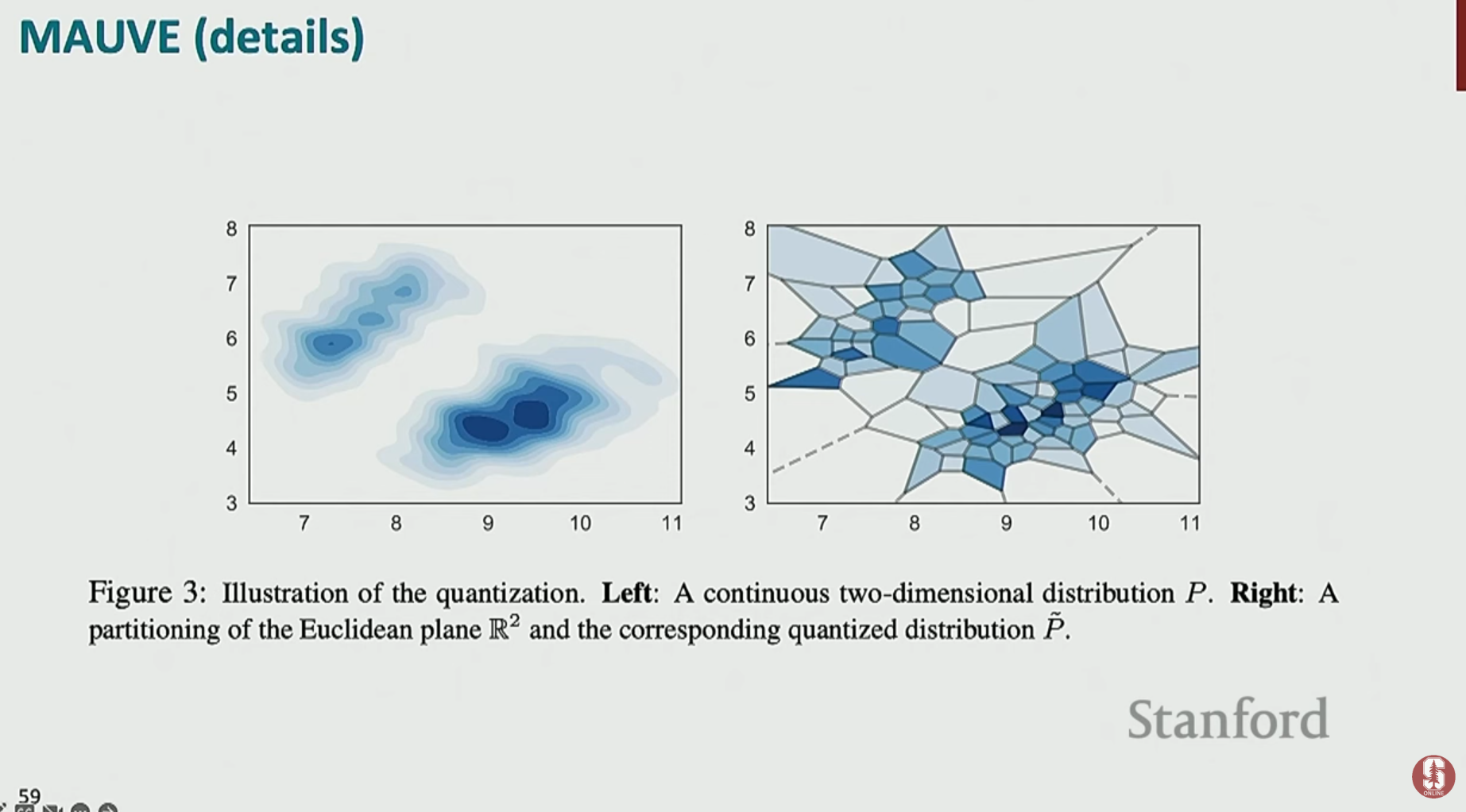
- MAUVE: 개방형 생성을 위해 고안된 지표로, 생성된 텍스트의 전체 분포와 인간이 쓴 텍스트의 분포 간의 차이(발산)를 측정합니다.
- 한계: 어휘 중복 기반 지표보다는 훨씬 뛰어나지만, 여전히 미묘한 의미 차이나 사실성 오류 등을 완벽하게 잡아내지는 못합니다.

2) 인간 평가: 가장 정확하지만 가장 어려운 방법
- 개념: 실제 사람이 생성된 텍스트를 직접 읽고, 다양한 기준에 따라 품질을 평가하는 '골드 스탠다드' 방식입니다.
- 평가 기준:
- 유창성 (Fluency): 문법적으로 자연스러운가?
- 일관성 (Coherence): 앞뒤 내용이 논리적으로 연결되는가?
- 사실성 (Factuality): 내용이 사실에 부합하는가? (특히 중요)
- 스타일, 상식 등: 주어진 스타일에 맞게 쓰였는가? 상식적인 내용인가?
- 현실적인 문제점: 가장 정확함에도 불구하고, 다음과 같은 여러 문제점을 안고 있습니다.
- 높은 비용과 시간: 많은 사람을 고용하여 평가를 진행해야 하므로 매우 비싸고 느립니다.
- 낮은 재현성 및 일관성: 평가자의 주관이 개입되므로, 누가 언제 평가하는지에 따라 결과가 달라질 수 있습니다. A 연구의 인간 평가 점수와 B 연구의 점수를 직접 비교하기 어렵습니다.
- 모호한 평가 기준: '일관성'과 같은 추상적인 기준은 평가자마다 다르게 해석할 수 있습니다.
- 정밀도(Precision)만 측정: "생성된 이 텍스트가 좋은가?"는 평가할 수 있지만, "이 외에 다른 좋은 답변은 없는가?"(재현율, Recall)는 측정하지 못합니다.

3) 미래 방향: 인간과 모델의 협력
- 이처럼 자동 평가와 인간 평가는 모두 명확한 한계를 가지고 있습니다.
- 따라서 강의에서는 인간의 판단 데이터를 학습하여 평가 모델을 만들거나, 인간과 모델이 상호작용하는 과정을 평가하는 등 두 가지를 결합하는 하이브리드 방식이 앞으로의 중요한 연구 방향임을 시사하며 마무리됩니다.


AI 공부합니다