1. 확산 모델(Diffusion Models)과 흐름 매칭(Flow Matching)의 기초
확산 모델은 무작위 노이즈 벡터를 점진적으로 디노이징(Denoising)하여 실사 이미지로 변환하는 반복적(Iterative) 프로세스입니다.
- 반복적 성격: 한 번에 생성되는 GAN과 달리, 확산 모델은 순차적으로 노이즈를 제거하며 이미지를 정제합니다.
- 조건부 생성: 텍스트 프롬프트와 같은 조건을 부여하여 생성 과정을 제어할 수 있으며, 이는 사용자에게 매우 자유로운 창작 환경을 제공합니다,.
- 학습 목표 (-objective): 훈련 시 모델은 원본 이미지에 추가된 노이즈의 양을 예측하도록 학습됩니다. 수학적으로는 가우시안 분포에서 추출된 노이즈 을 예측하는 것이 목표입니다,.
- 흐름 매칭(Flow Matching): 최근 Flux나 Stable Diffusion 3에서 사용되는 기법으로, 노이즈와 깨끗한 데이터를 직선 경로(Straight path)로 연결하려 시도합니다. 확산 모델보다 경로가 단순화되어 계산 효율성을 높일 수 있습니다.
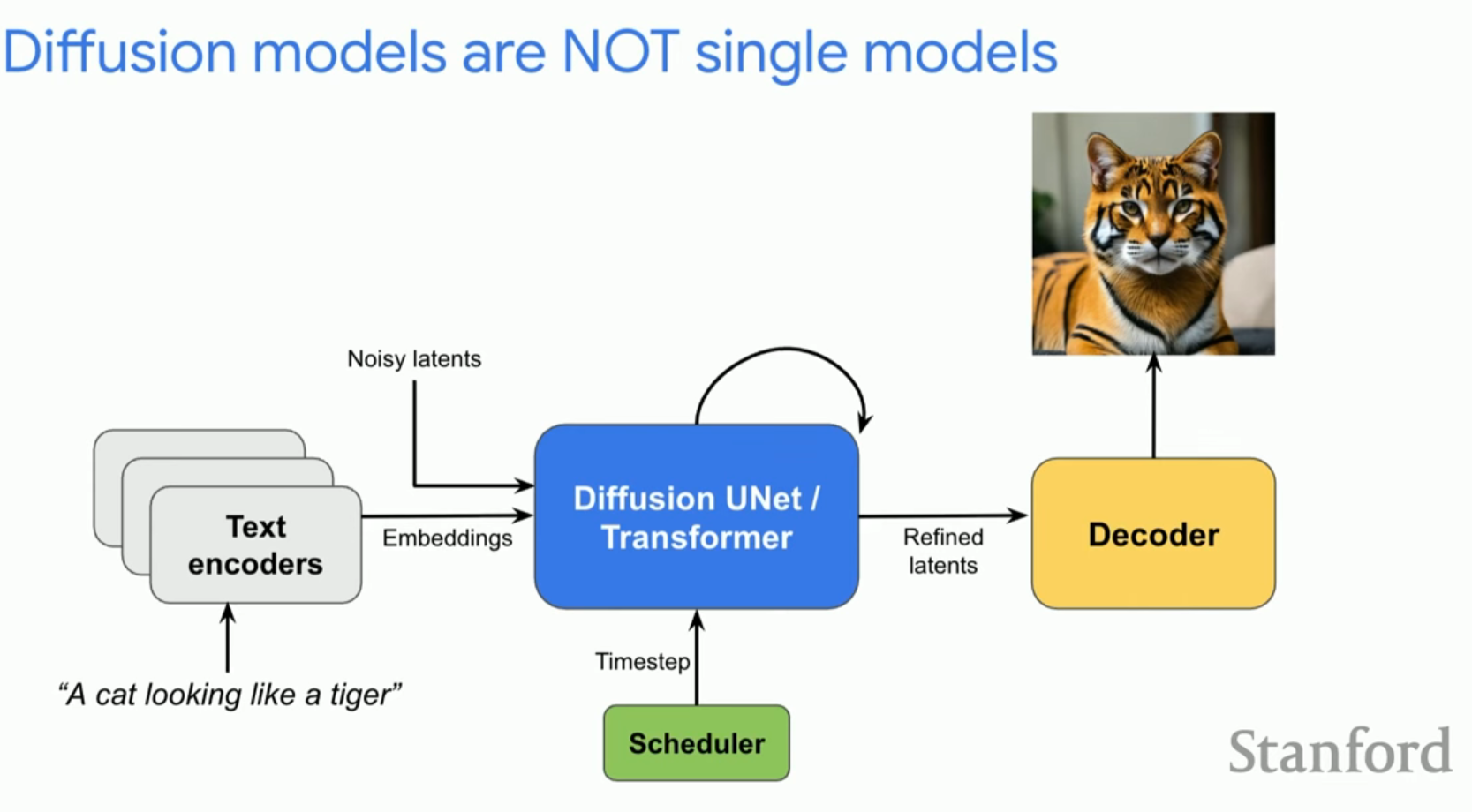
2. 이미지 생성 시스템의 구성 요소
상태 최첨단(SOTA) 텍스트-이미지 생성 시스템은 다음과 같은 핵심 구성 요소들로 이루어집니다.
- 텍스트 인코더(Text Encoders): 프롬프트를 임베딩으로 변환합니다. Stable Diffusion 3는 1개가 아닌 3개의 텍스트 인코더를 사용하여 고도로 정밀한 표현을 얻습니다.
- 노이즈 잠재 변수(Noisy Latents): 가우시안 분포에서 추출된 무작위 노이즈입니다.
- 타임스텝(Time step): 스케줄러를 통해 현재 디노이징 궤적의 어느 지점에 있는지를 모델에 알려줍니다.
- 잠재 공간 확산(Latent Space Diffusion): 픽셀 공간에서 직접 작업하는 것은 계산 비용이 매우 크기 때문에, 대부분의 최신 모델은 압축된 잠재 공간에서 동작합니다.
3. U-Net에서 Transformer로의 패러다임 전환
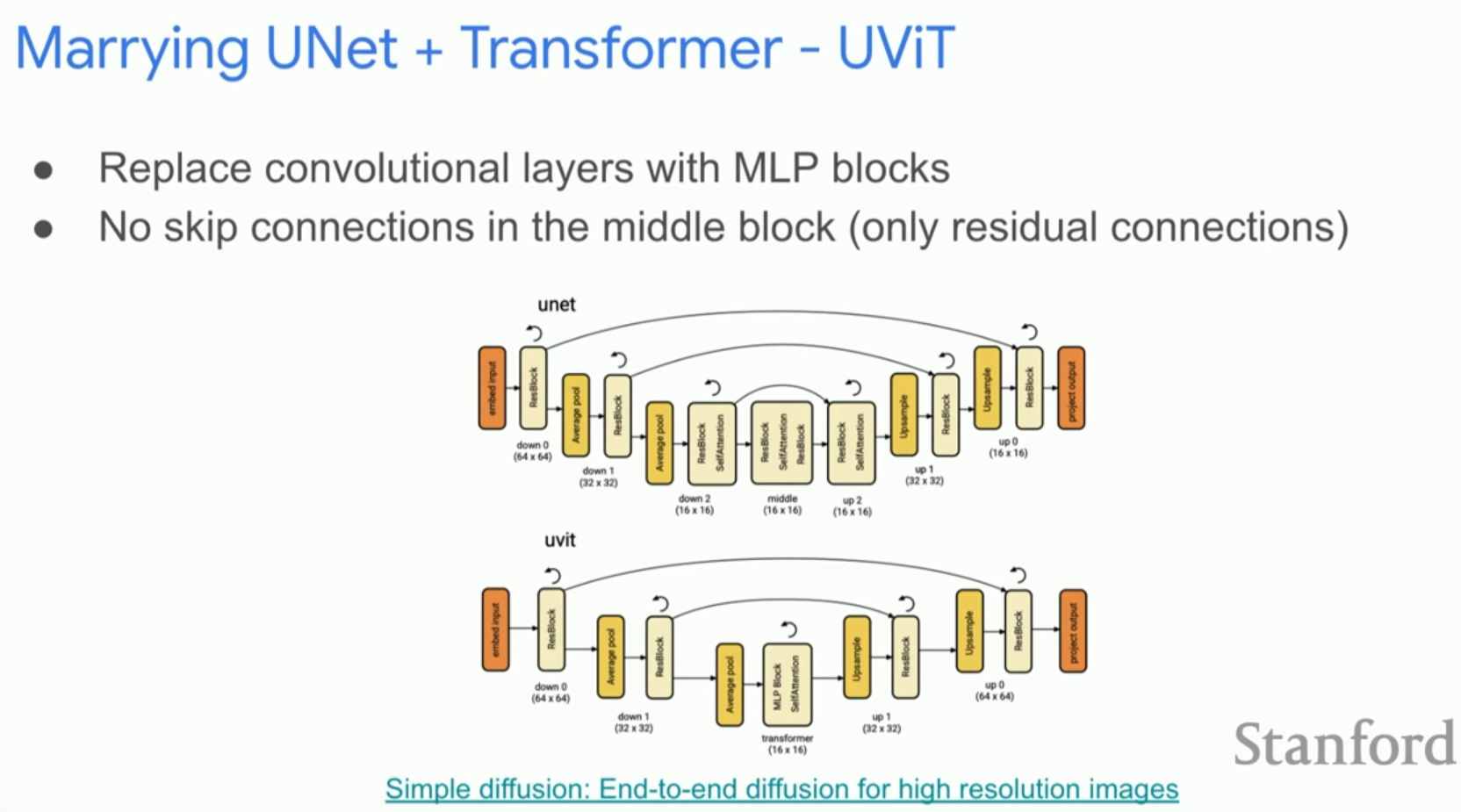
과거에는 DDPM, LDM, SDXL 등 대부분의 모델이 U-Net 아키텍처를 기반으로 했습니다.
U-Net의 한계와 Transformer 도입 배경
- U-Net의 구조: 합성곱(Convolutional) Stem, 다운 블록(Down blocks), 업 블록(Up blocks) 등으로 구성된 거대한 구조로, 머릿속으로 시각화하기조차 복잡합니다,.
- 전환 이유: 트랜스포머의 스케일링 특성(Scaling properties)을 활용하고, SwiGLU, QK Normalization과 같은 트랜스포머의 최신 발전 사항을 이미지 생성에 도입하기 위함입니다. 또한, 거대 언어 모델(LLM) 백본과의 통합이 훨씬 용이해집니다.
4. Diffusion Transformer (DiT)의 핵심 아키텍처
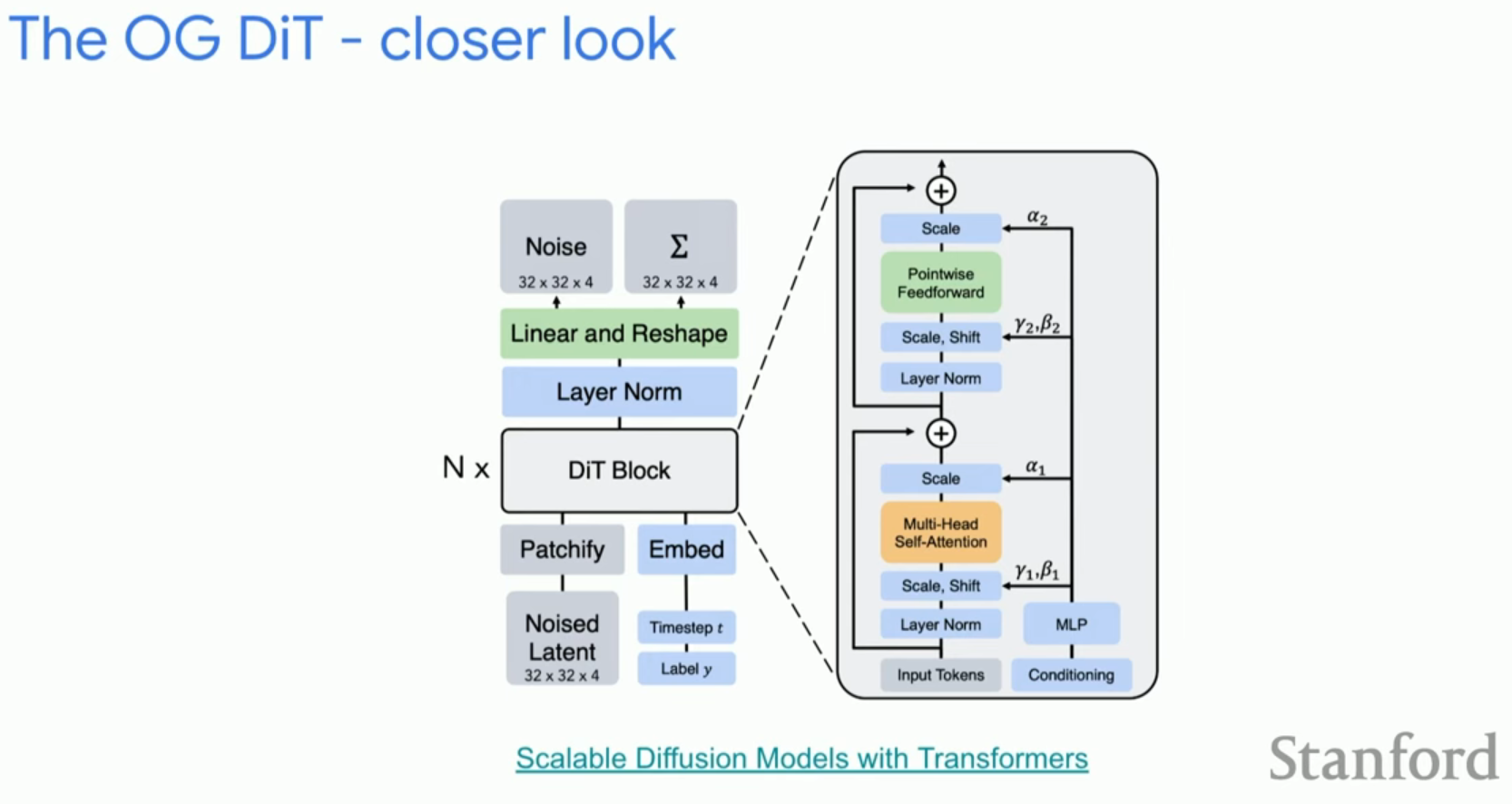
DiT는 비전 트랜스포머(ViT)의 설계를 이미지 생성에 맞게 확장한 모델입니다.
수학적 모델링과 adaLN (Adaptive Layer Norm)
DiT는 조건 정보(타임스텝, 클래스 레이블)를 주입하기 위해 adaLN을 사용합니다.
- 작동 원리: 표준 레이어 정규화(Layer Norm) 후에 조건부 공간에서 계산된 변조 파라미터(Modulation parameters)를 적용합니다.
- 수식:
- 여기서 는 타임스텝 임베딩과 클래스 임베딩의 합입니다,. 이 방식은 크로스 어텐션(Cross attention)보다 계산 효율이 높으면서도 성능이 우수함이 입증되었습니다.
DiT의 구성 요소 및 초기화
- 타임스텝 임베딩: 0~1000 사이의 값을 사인파 주파수(Sinusoidal frequency)로 인코딩하여 위상을 인식하게 한 뒤, 얕은 MLP를 통과시킵니다.
- 초기화 전략: 각 트랜스포머 블록을 Identity block으로 초기화하여 학습 안정성을 높입니다. 이는 배치 정규화의 베타 파라미터를 0으로 초기화하는 기법에서 영감을 받았습니다.
5. 효율성 및 성능 최적화 모델: PixArt-alpha & SANA
단순한 DiT를 넘어, 실제 서비스 수준의 효율성을 달성하기 위한 시도들이 이어졌습니다.
PixArt-alpha: T2I로의 확장
- 구조: Flan-T5 XXL 인코더를 사용하여 자연어 설명 능력을 강화했습니다,.
- adaLN-single: 매 블록마다 MLP를 계산하는 대신 임베딩 테이블을 사용하여 연산량을 27% 절감했습니다.
- 심화: T5와 같은 대형 언어 모델을 사용하면 77개 토큰 제한이 있는 CLIP보다 훨씬 긴 프롬프트를 처리할 수 있어 상세한 묘사가 가능해집니다.

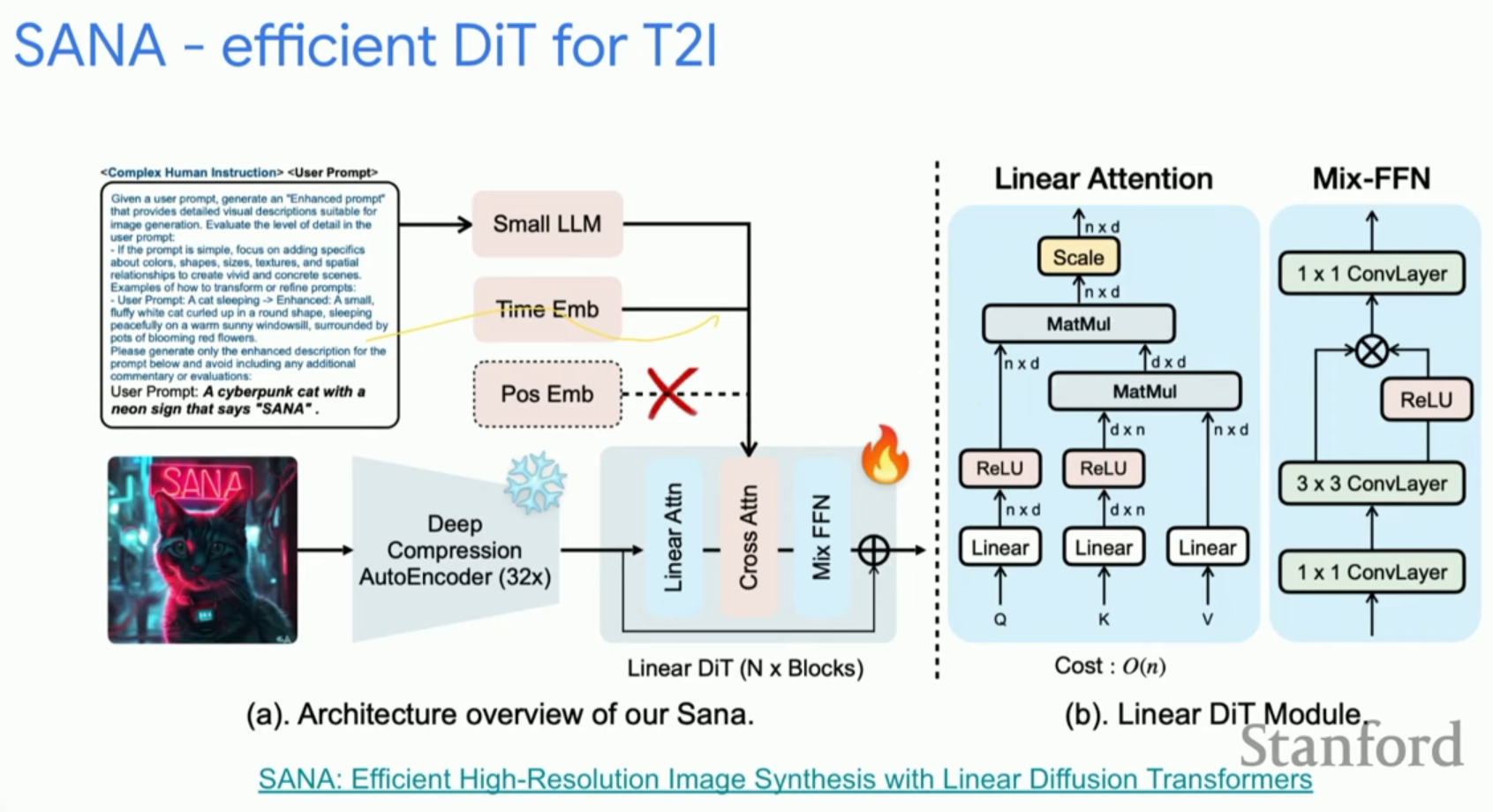
SANA: 극도의 효율성
- 선형 어텐션(Linear Attention): 의 복잡도를 으로 줄여 4K와 같은 고해상도 이미지 생성을 가능하게 합니다.
- Mix-FFN: 선형 어텐션 사용 시 손실되는 지역성(Locality)을 보완하기 위해 합성곱 레이어가 포함된 FFN 블록을 사용합니다.
6. Stable Diffusion 3와 MM-DiT
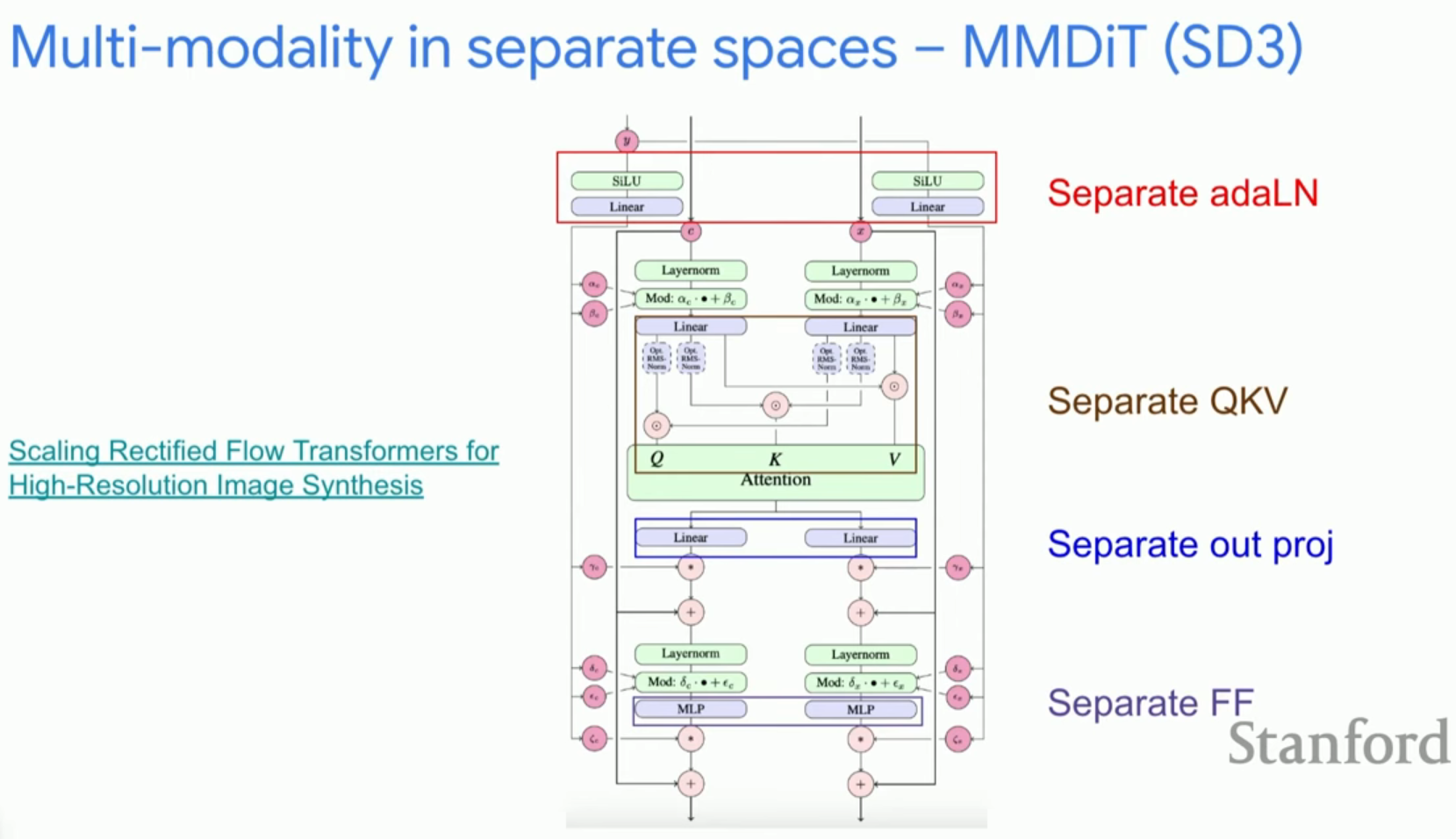
Stable Diffusion 3(SD3)는 텍스트와 이미지라는 서로 다른 모달리티를 더욱 정교하게 처리하기 위해 MM-DiT(Multi-modal Diffusion Transformer)를 도입했습니다.
- 핵심 개념: 텍스트와 이미지에 대해 별도의 QKV 투영 행렬을 유지합니다. 이는 텍스트 임베딩이 가질 수 있는 단방향 편향(Unidirectionality bias) 등이 이미지 생성 모델에 전이되는 것을 방지합니다.
- Qenom (QK Normalization): 학습의 불안정성을 해결하기 위해 모든 어텐션 블록에 적용되었습니다.
- 심화: SD3는 CLIP 2개와 T5 1개, 총 3개의 인코더를 섞어 사용하며, 추론 시 텍스트 렌더링이 중요하지 않다면 T5를 제거하여 효율을 높일 수 있는 유연성을 제공합니다.
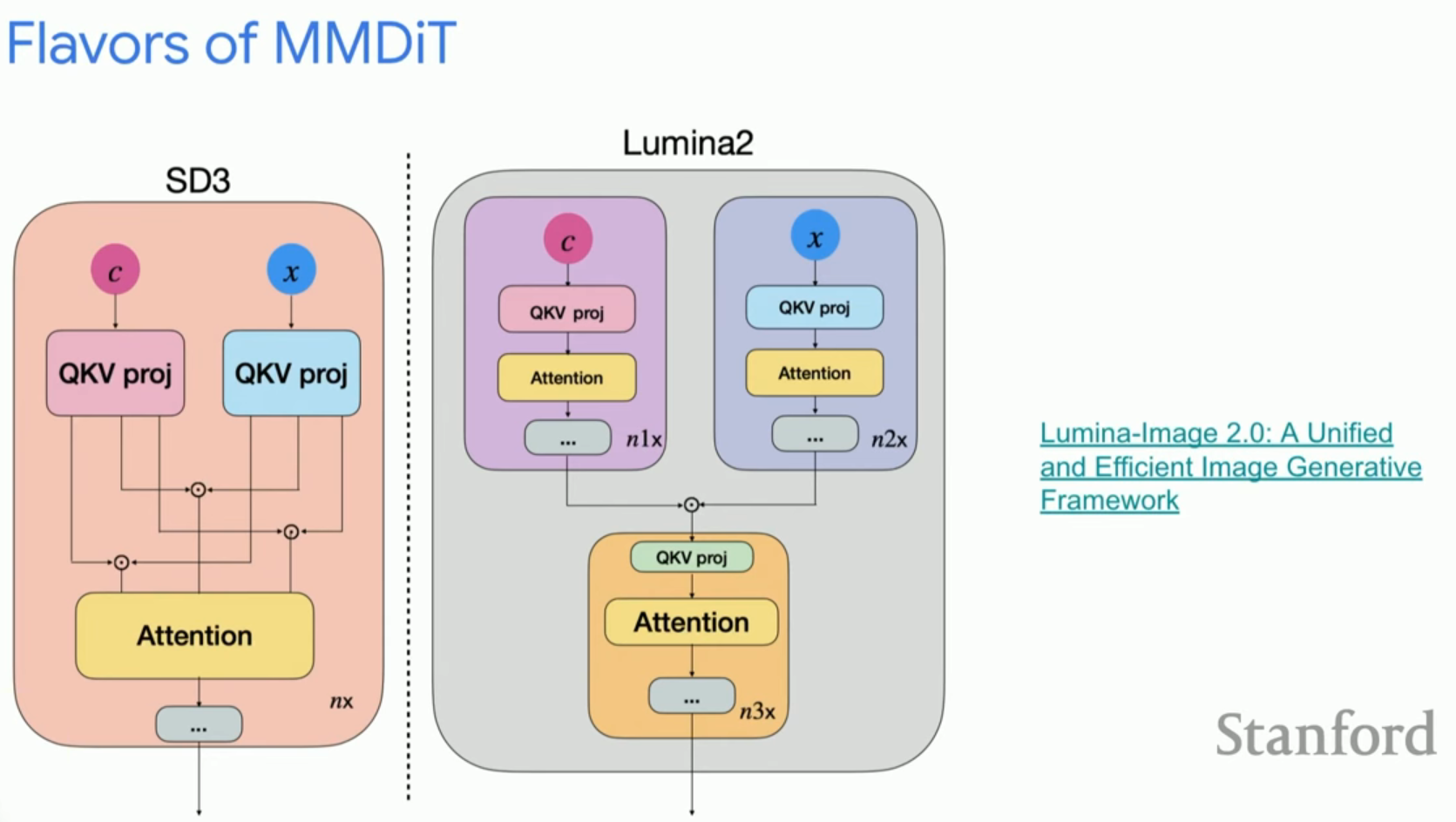
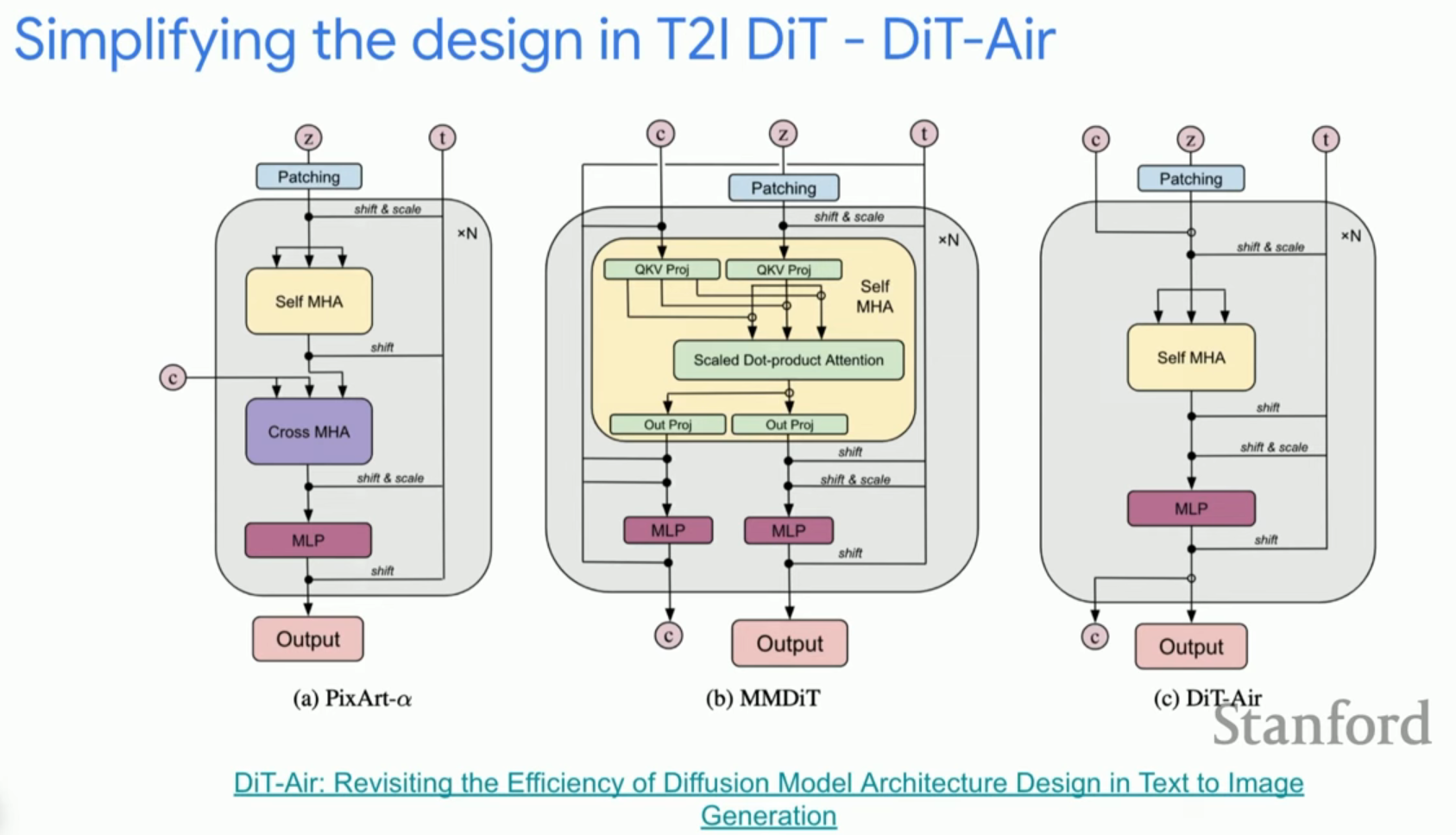
7. 비디오 생성과 차세대 아키텍처
이미지에서 비디오로 넘어가면서 시간적 일관성(Temporal consistency)이라는 새로운 차원의 문제가 등장합니다.
- 비디오의 난제: 프레임 수가 늘어남에 따라 3D 어텐션의 계산 비용이 기하급수적으로 증가합니다. 이를 해결하기 위해 시간적 압축과 효율적인 어텐션 기법이 연구되고 있습니다.
- In-context Learning: 언어 모델처럼 확산 모델에서도 예시를 통한 학습(Zero-shot/Few-shot)을 구현하려는 시도가 있습니다. Transfusion과 같은 모델은 사전 학습된 LLM에 이미지 생성 기능을 융합하여 이를 달성하려 합니다.
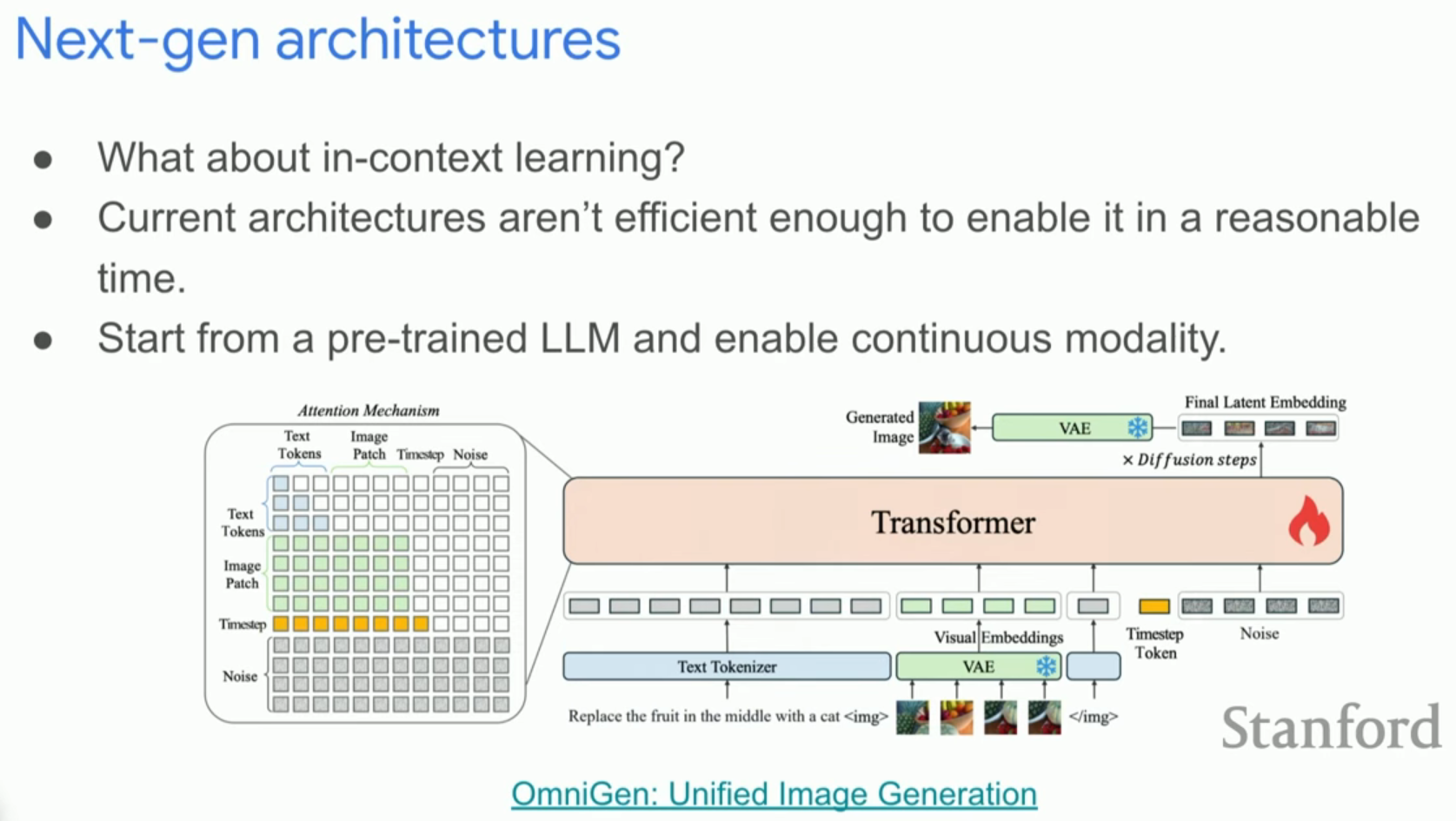
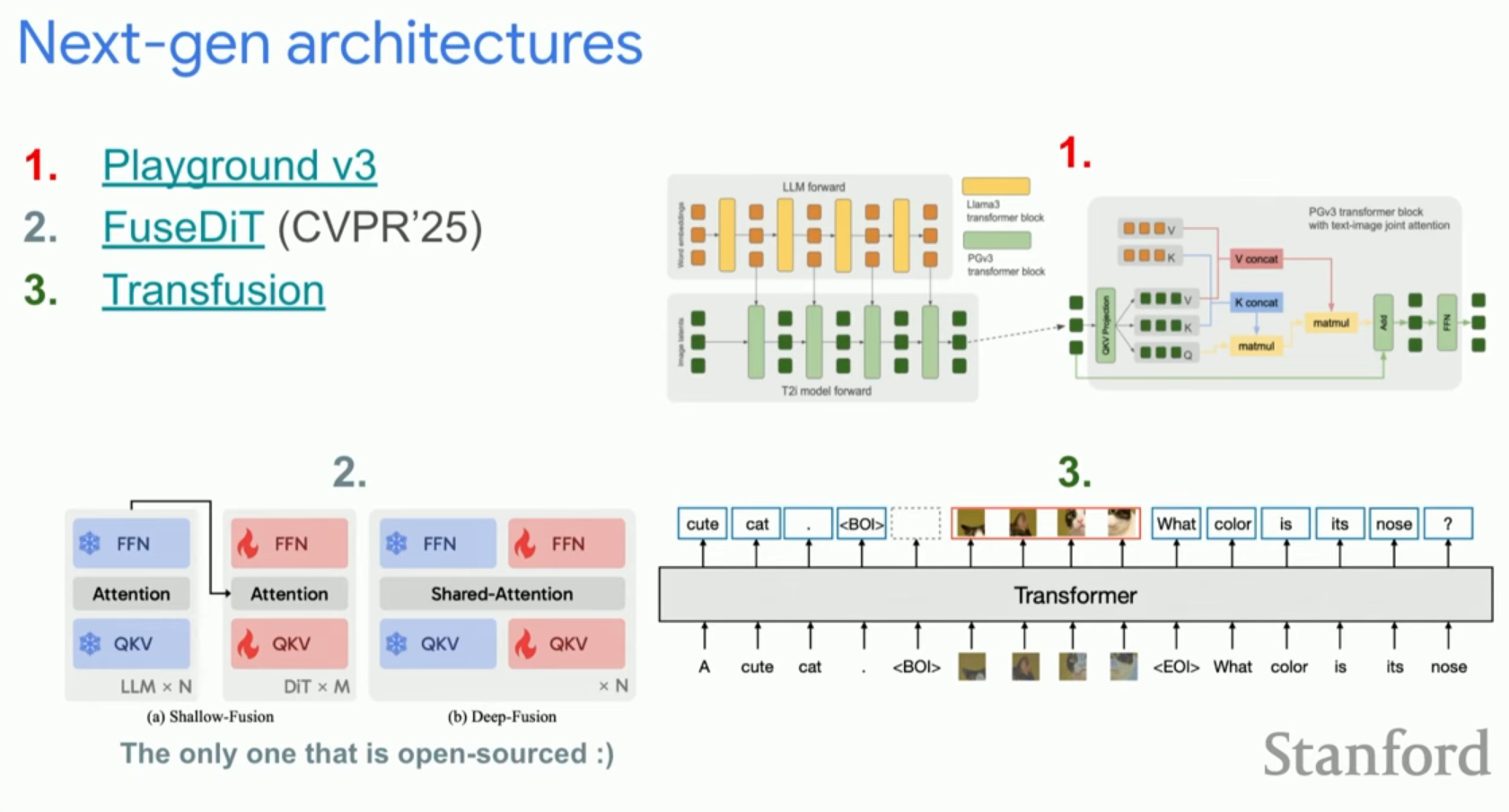
8. QnA 세션 내용 정리
강의 중 나온 주요 질문과 답변을 정리한 섹션입니다.
- Q: 왜 여러 개의 텍스트 인코더를 사용하나요?
- A: CLIP은 대조 학습(Contrastive) 특성을, T5는 상세한 설명 능력을 가집니다. 이처럼 다양한 표현(Representation)을 결합할수록 생성 모델의 성능이 향상되기 때문입니다.
- Q: GAN이 완전히 대체되었나요?
- A: 아닙니다. 확산 모델은 순차적이라 느리지만, GAN은 원샷(One-shot) 생성이 가능하여 실시간성이 중요한 분야나 타임스텝 증류(Distillation) 과정에서 여전히 사용됩니다.
- Q: 데이터가 적은 환경에서도 작동하나요?
- A: 일반적인 생성 모델은 매우 방대한 데이터가 필요합니다. 다만 의료 영상처럼 특정 도메인에 특화된 경우에는 데이터 요구량이 적을 수 있습니다.
- Q: 비디오 생성에서 프레임별로 생성하는 것보다 효율적인 방법은 없나요?
- A: 단순히 2D 모델을 확장하는 것만으로는 공간-시간적 일관성을 유지하기 어렵습니다. 따라서 잠재 시간 수준(Latent temporal level)에서 효과적으로 압축하는 기술이 필수적입니다.
비유로 이해하기: U-Net에서 Transformer로의 전환은 마치 복잡하게 얽힌 수동 기어박스(U-Net)를 버리고, 확장성이 뛰어나고 다른 부품과 조립하기 쉬운 모듈형 전기차 플랫폼(Transformer)으로 갈아탄 것과 같습니다. 이 플랫폼 위에서 우리는 adaLN이라는 정교한 제어 장치를 통해 원하는 스타일의 이미지를 더 효율적으로 뽑아낼 수 있게 되었습니다.

AI 공부합니다