1. 비디오 생성 기술의 비약적 발전과 배경
- 기술적 진보: 2022년의 상태(State-of-the-art)와 2024년의 Movie Gen을 비교하면 불과 2년 만에 실사와 구분이 불가능한 수준으로 품질이 비약적으로 향상되었습니다.
- 물리 법칙의 학습: 최신 모델들은 거울에 비친 반사나 조명 효과 등 복잡한 물리 법칙을 데이터로부터 직접 학습하여 구현해냅니다.
- 역사적 흐름:
- 2019년 (GANs): GAN(Generative Adversarial Networks)을 사용하여 흐릿한 이미지나 낮은 품질의 장면을 생성하던 시기였습니다.
- 2022년 (Diffusion): 확산 모델(Diffusion Modeling)의 도입으로 시각적 품질이 크게 향상되었습니다.
- 2024년 (Architecture Unification): 전문화된 구조(CNN, U-Net 등)에서 벗어나 단순하고 확장성이 뛰어난 트랜스포머(Transformer) 구조로의 통합이 이루어졌습니다.
2. Movie Gen: 모델 개요
- Movie Gen은 고품질 1080p HD 비디오와 동기화된 오디오를 생성할 수 있는 파운데이션 모델 패밀리입니다.
- 핵심 사양: 300억 개(30B)의 파라미터를 가진 트랜스포머 모델로, 약 1억 개의 비디오와 10억 개의 이미지를 사용하여 훈련되었습니다.
- 주요 철학: 데이터, 계산량(Compute), 모델 파라미터의 확장(Scaling)이 텍스트(NLP)에서와 마찬가지로 비디오 생성에서도 유효함을 입증하는 것입니다.
3. 핵심 아키텍처 (1): 데이터 표현 (Representation)
- 픽셀 모델링의 한계: 비디오의 원시 픽셀을 직접 모델링하는 것은 계산 비용이 해상도에 따라 이차적으로 증가(quadratically)하기 때문에 64x64와 같은 저해상도에 국한될 수밖에 없습니다.
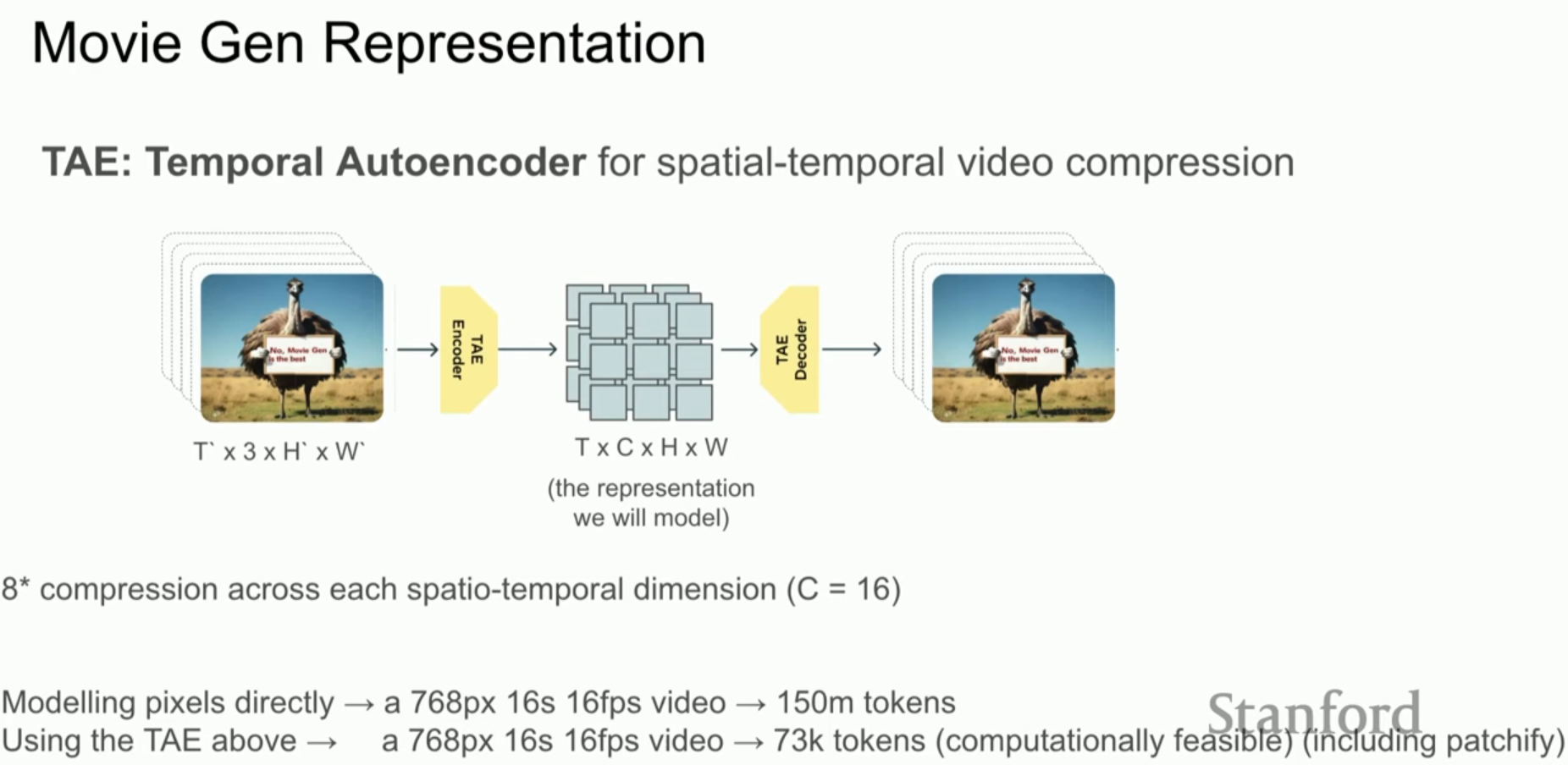
- Temporal Autoencoder (TAE): 데이터의 중복성을 제거하고 효율적인 학습을 위해 고안된 변분 오토인코더(VAE)의 일종입니다.
- 압축률: 높이, 너비, 시간 차원에서 각각 8배씩 압축하여 총 512배의 압축 효율을 보여줍니다.
- 토큰화 효율: 16초 분량의 768p 비디오를 픽셀 단위로 펼치면 1억 5천만 개의 토큰이 되지만, TAE를 통과하면 73,000개로 줄어들어 현재의 인프라로 처리가 가능해집니다.
4. 핵심 아키텍처 (2): 학습 목표 (Learning Objective)
- Flow Matching: 기존의 확산 모델(Diffusion)을 보다 단순화하고 일반화한 학습 방식입니다.
- 특징: 확산 모델보다 더 견고한(robust) 훈련이 가능하며, 샘플링 경로가 직선에 가까워 더 효율적이고 빠른 추론이 가능합니다.


- 특징: 확산 모델보다 더 견고한(robust) 훈련이 가능하며, 샘플링 경로가 직선에 가까워 더 효율적이고 빠른 추론이 가능합니다.
- 수학적 개념 및 수식:
- 선형 보간(Linear Interpolation): 훈련 샘플 를 생성하기 위해 데이터 샘플 과 가우시안 노이즈 사이를 시간 에 따라 섞습니다.
- 학습 목표 함수: 모델은 속도(Velocity) 를 예측하도록 학습됩니다.
여기서 는 텍스트 프롬프트 와 시간 에 조건화된 모델의 예측값이며, 는 실제 데이터 분포로 향하는 정답 속도입니다.
5. 핵심 아키텍처 (3): 모델 구조
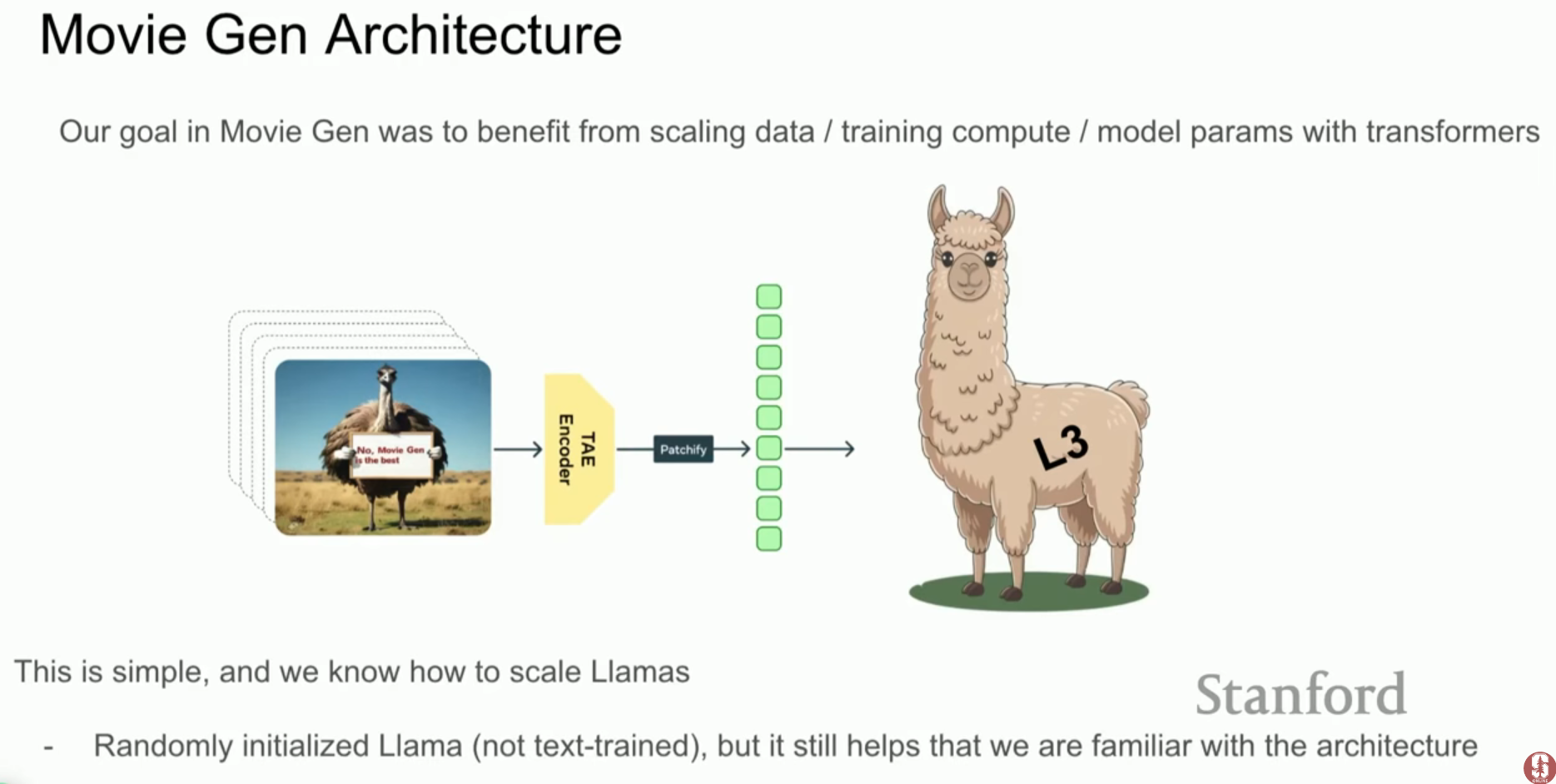
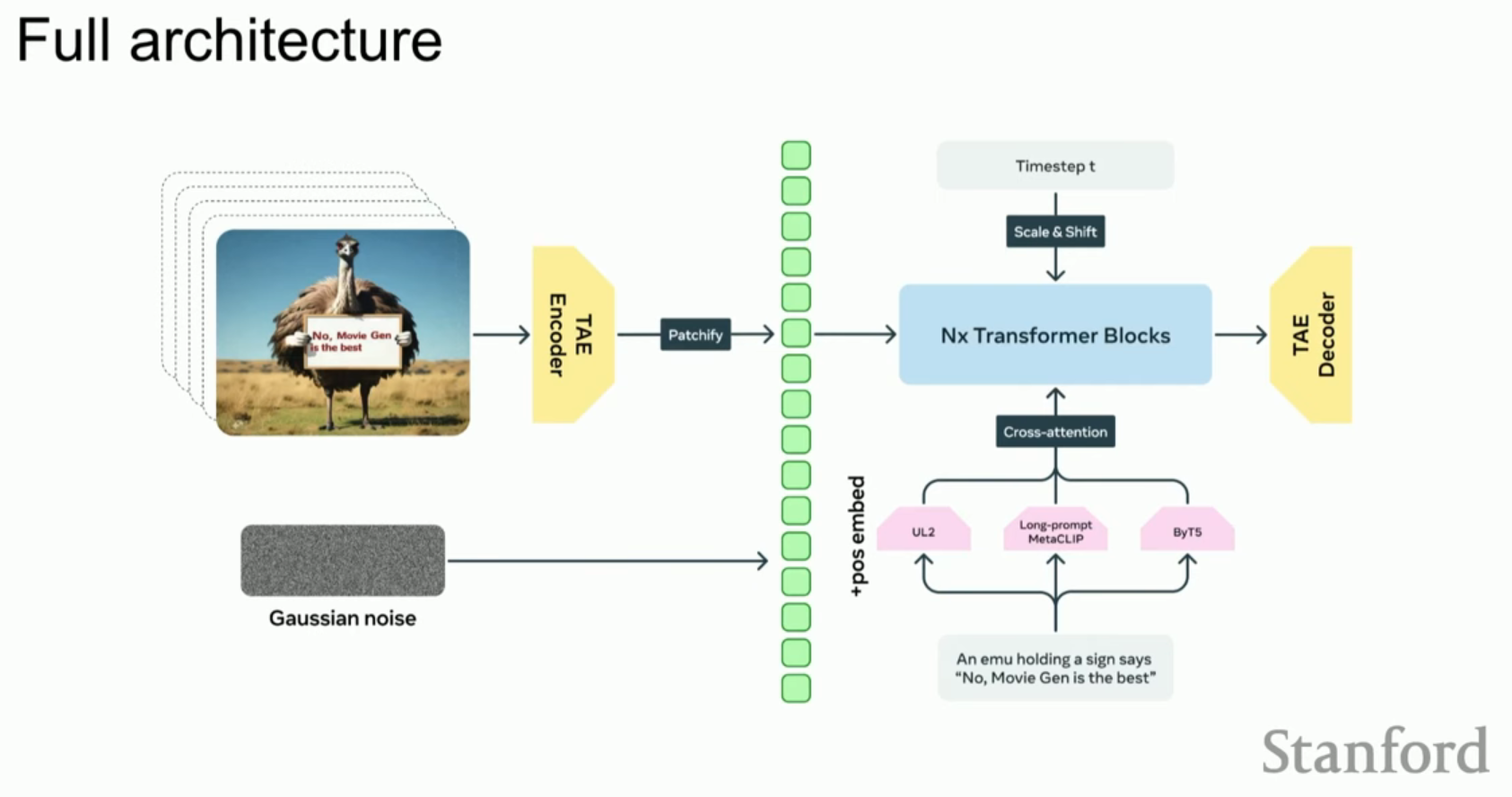
- Llama 3 기반: Meta의 오픈 소스 LLM인 Llama 3의 아키텍처를 그대로 가져와 비디오 토큰 시퀀스를 처리하는 데 사용했습니다.
- 비디오 생성을 위한 주요 수정 사항:
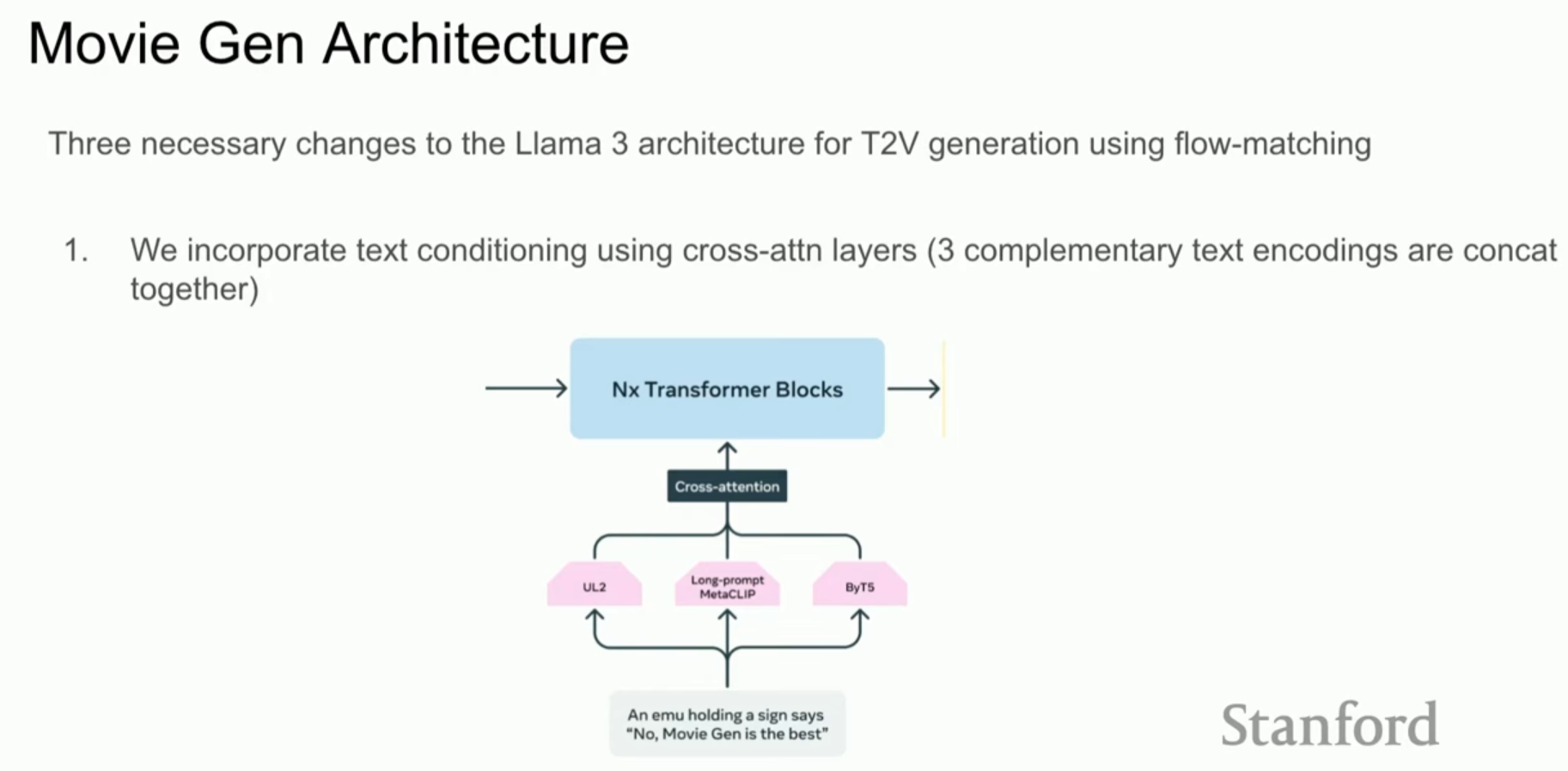
- 텍스트 조건화 (Cross-Attention): 비디오 토큰과 텍스트 정보를 결합하기 위해 교차 주의 집중 레이어를 추가했습니다.
- 시간 단계 조건화 (Adaptive Layer Norm): Diffusion Transformer(DiT)에서 대중화된 방식으로, 시간 단계 정보를 모델에 주입합니다.
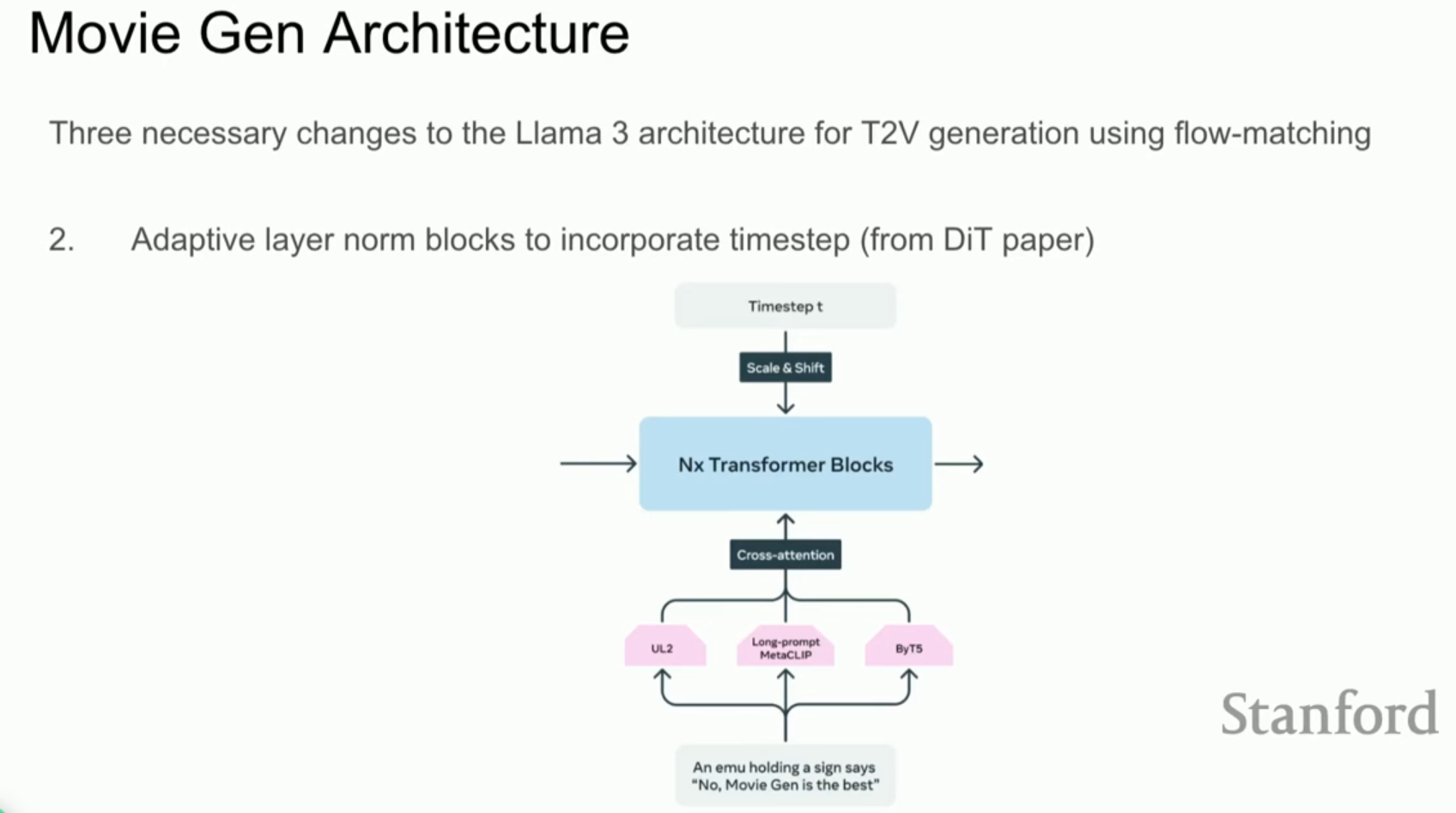
- 양방향 주의 집중 (Full Bidirectional Attention): 텍스트의 인과적 마스킹(Causal Masking)을 제거하여 모든 비디오 토큰이 서로를 참조할 수 있게 했습니다.
- 텍스트 조건화 (Cross-Attention): 비디오 토큰과 텍스트 정보를 결합하기 위해 교차 주의 집중 레이어를 추가했습니다.
6. 데이터 및 훈련 레시피
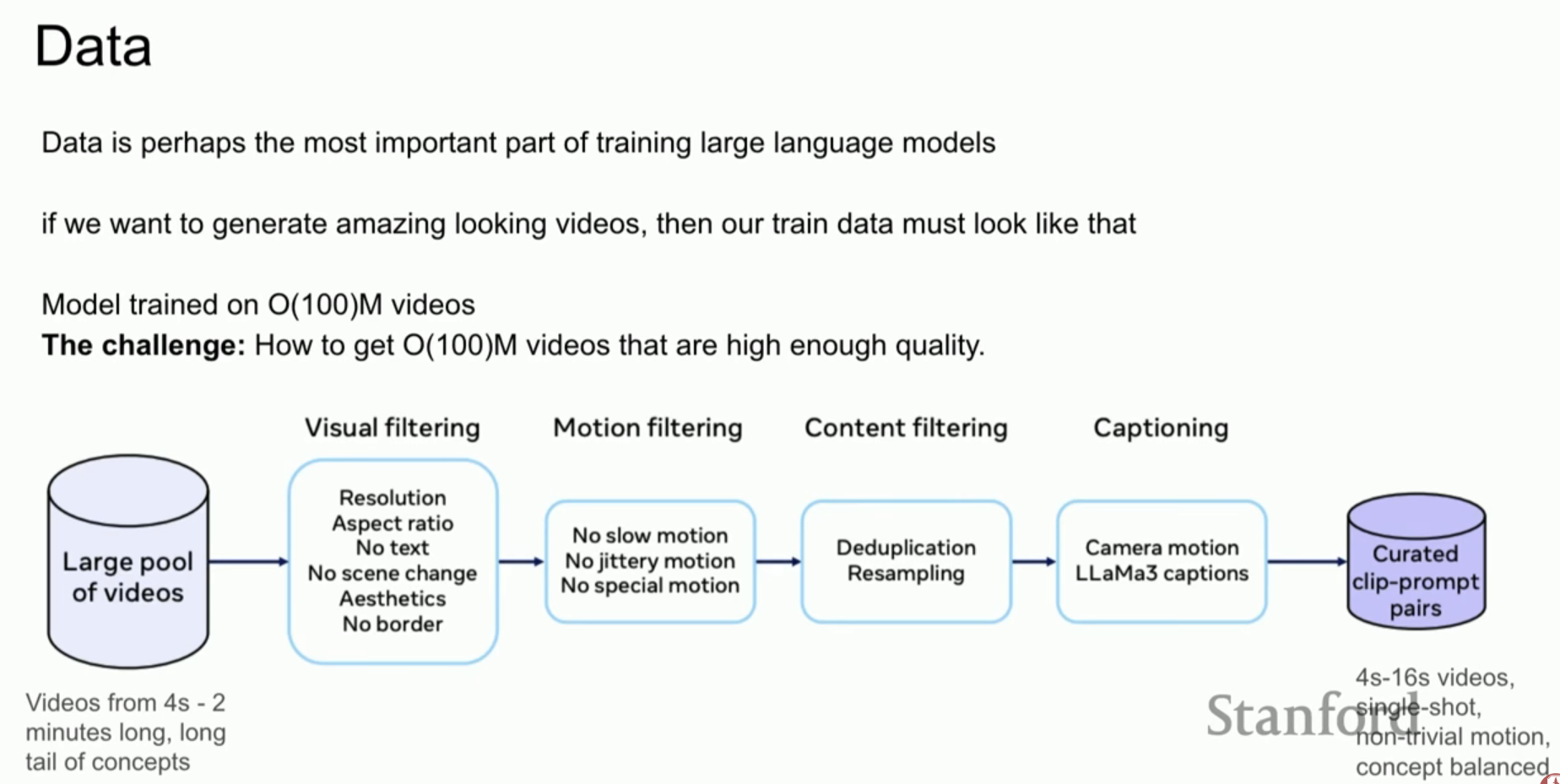
- 데이터 품질의 중요성: 대규모 모델에서는 데이터의 양보다 청결도(Cleanliness)가 스케일링 법칙(Scaling Laws)을 유지하는 데 결정적입니다.
- 데이터 파이프라인: 1억 개의 비디오를 선별하기 위해 복잡한 필터링 과정을 거쳤습니다.
- 시각적 필터링: 저해상도, 장면 전환, 품질이 낮은 움직임을 제거합니다.
- 개념 재샘플링 (Resampling): 특정 개념에 편향되지 않도록 데이터 분포를 균일하게 맞춥니다.
- 자동 캡셔닝: Llama 3를 기반으로 비디오에 상세한 설명을 자동으로 생성하여 훈련에 사용했습니다.
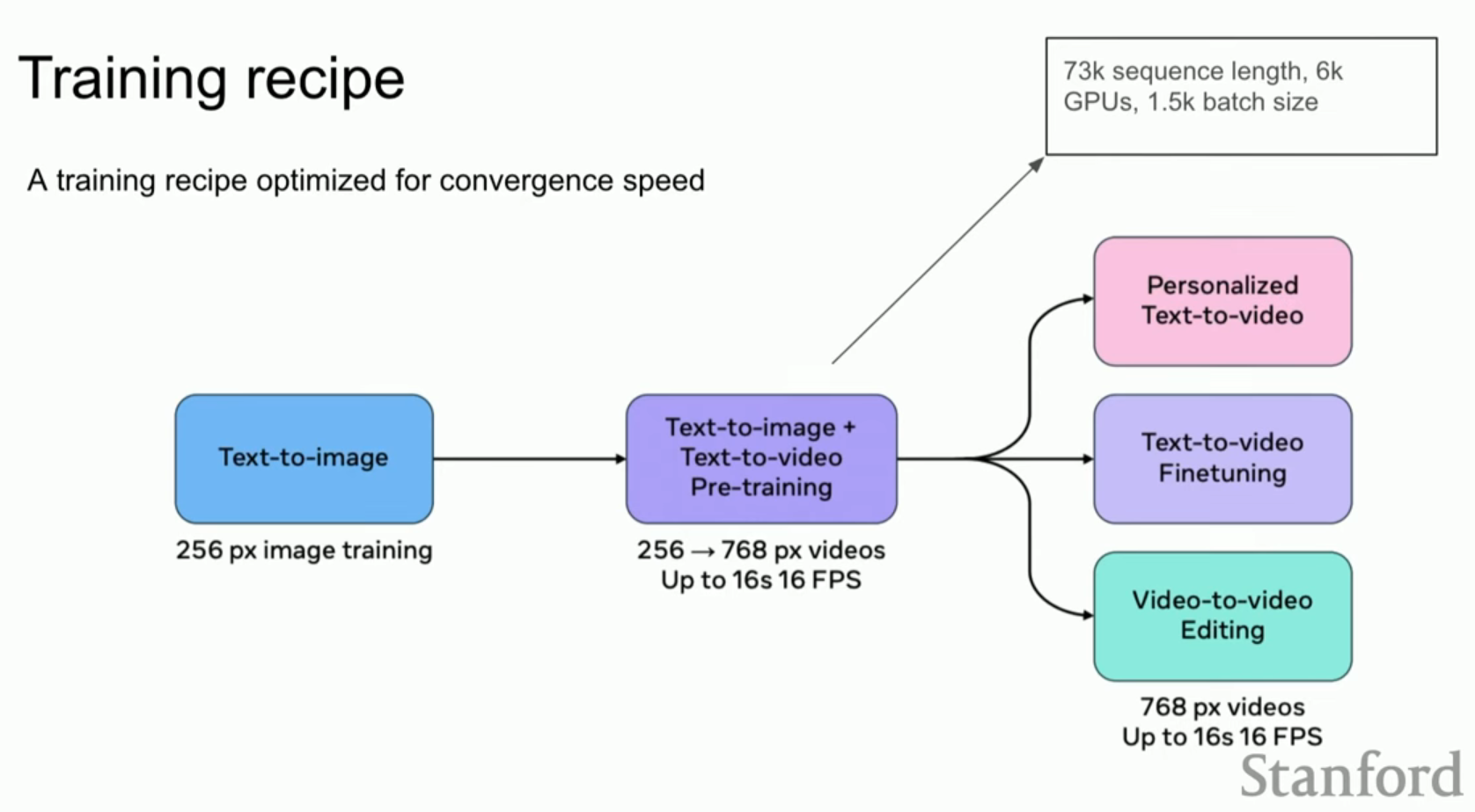
- 훈련 단계: 256p 이미지 생성 → 256p~768p 비디오/이미지 공동 훈련 → 고품질 비디오 미세 조정(SFT) 순으로 진행하며, 최대 6,000대의 GPU를 사용했습니다.
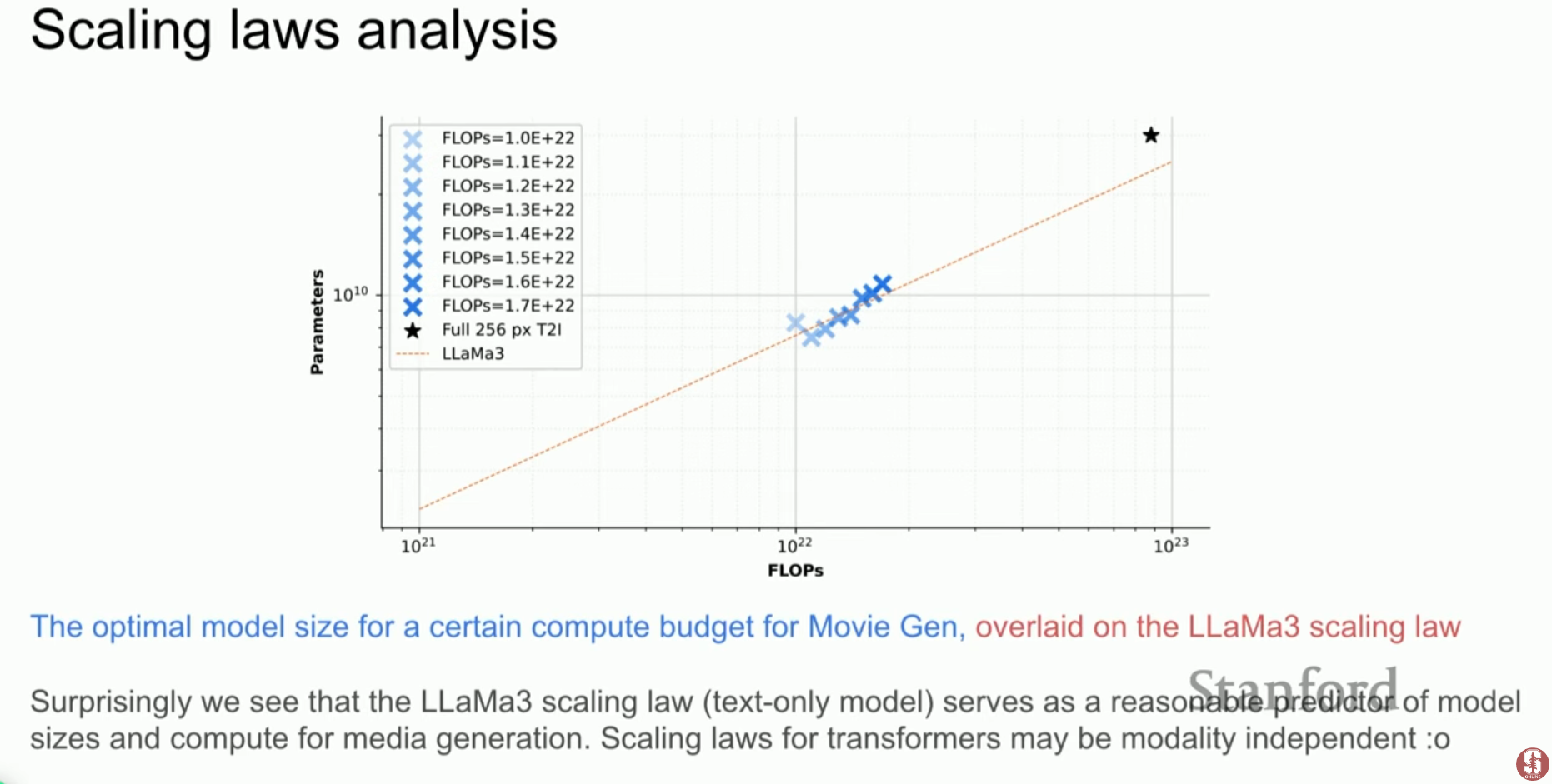
7. 스케일링 법칙과 그 의미
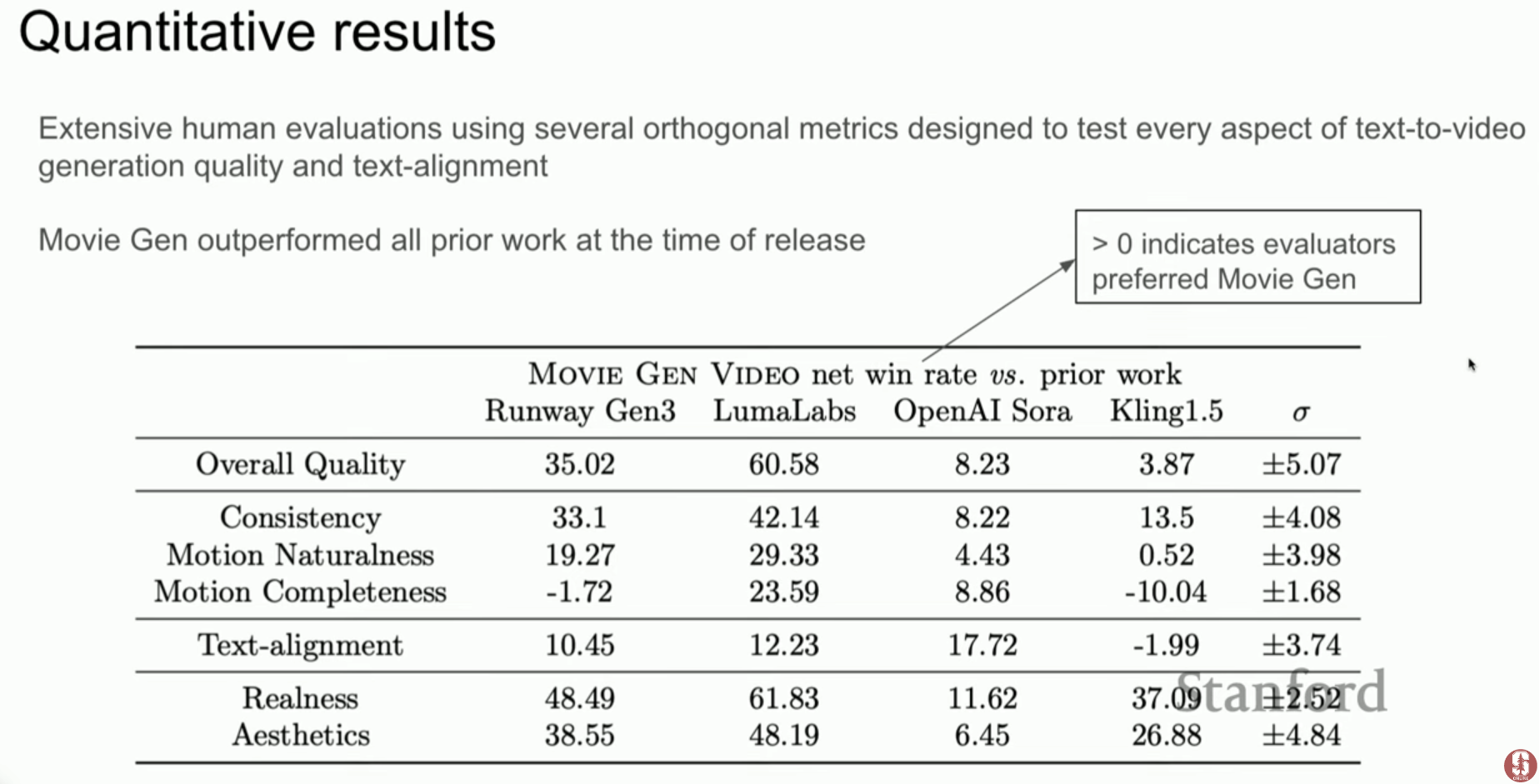
- 모달리티 독립성: 연구 결과, Llama 3 텍스트 모델의 스케일링 법칙이 비디오 생성 모델의 성능 예측에도 유사하게 적용됨을 발견했습니다.
- 기술적 배경: 이는 트랜스포머라는 아키텍처가 데이터의 종류(텍스트, 이미지, 비디오)와 관계없이 정보를 처리하는 보편적인 계산 엔진임을 시사합니다.
- 한계점: 여전히 복잡한 상호작용(예: 자동차 충돌 시 차체 붕괴 오류)이나 아주 긴 시간의 일관성을 유지하는 데에는 한계가 있습니다.
8. 향후 전망 및 연구 방향
- 추론 능력(Reasoning) 도입: 모델이 비디오를 생성하기 전 스스로 생각하고 오류를 수정하는 'Chain of Thought' 기능을 결합하여 비약적인 품질 향상을 꾀할 수 있습니다.
- 네이티브 멀티모달리티: 텍스트, 이미지, 비디오를 구분 없이 동시에 이해하고 생성하는 통합 모델로의 발전이 예상됩니다.
- 데이터 확장: 고품질 비디오 데이터의 고갈 문제에 대비해 더 스마트한 데이터 선별 방식이나 합성 데이터의 활용이 중요해질 것입니다.

9. Q&A (강의 중 주요 질의응답)
- Q1: 16초 이상의 더 긴 비디오를 생성하는 데 방해 요소는 무엇인가요?
- A: 가장 큰 문제는 시퀀스 길이에 따른 계산 비용입니다. 이를 해결하기 위해 더 높은 압축률을 가진 인코더를 사용하거나, 이전 장면을 조건으로 다음 장면을 생성하는 순차적 방식(Iterative Generation)을 사용할 수 있습니다.
- Q2: 학계 연구자들이 수천 대의 GPU 없이 비디오 생성 연구에 기여할 수 있는 방법은?
- A: 대규모 사전 훈련은 어렵지만, Flow Matching과 같은 새로운 학습 알고리즘이나 사후 훈련(Post-training) 기법에 대한 연구는 소규모로도 가능하며 산업계에 큰 영감을 줄 수 있습니다.
- Q3: 캡션의 품질이 실제 생성 성능에 미치는 영향은?
- A: 매우 큽니다. 텍스트 이미지 연구에서도 캡션 품질이 높을수록 이미지 품질이 향상되는 결과가 있었으며, 비디오에서도 상세하고 정확한 캡션이 모델의 정렬(Alignment) 성능을 결정합니다.
- Q4: VAE/TAE 학습 시 GAN 손실(Adversarial Loss)을 사용하는 이유는?
- A: 픽셀 단위의 L1 손실만 사용하면 압축 시 결과물이 흐릿해지는 경향이 있습니다. GAN 손실을 추가하면 모델이 더 실제 같은(realistic) 세부 사항을 생성하도록 유도하여 더 높은 압축률을 달성할 수 있습니다.
- Q5: 비디오와 오디오를 동시에 생성하지 않은 이유는 무엇인가요?
- A: 비디오와 오디오는 상관관계가 높지만, 고품질 오디오가 포함된 비디오 데이터를 대량으로 확보하는 것이 매우 어렵기 때문에 이번 프로젝트에서는 별도의 오디오 모델을 학습시키는 방식을 택했습니다.
비유로 이해하기: Movie Gen의 비디오 생성 과정은 마치 조각가가 거대한 대리석 덩어리(가우시안 노이즈)에서 불필요한 부분을 깎아내어 정교한 조각상(비디오)을 찾아가는 과정과 같습니다. 이때 트랜스포머는 조각가의 정교한 손놀림이 되고, Flow Matching은 가장 효율적으로 조각상을 완성하기 위한 직선적인 경로를 안내하는 지도가 됩니다.

AI 공부합니다