1. 배경 및 문제 정의
연구가 등장한 배경
최근 로봇 공학 분야에서는 복잡한 시각적 환경을 이해하고 정밀한 제어를 수행하기 위해 시각-언어-행동(Vision-Language-Action, VLA) 모델이 핵심 패러다임으로 자리 잡았습니다. 대규모 시각-언어 모델(VLM)을 백본으로 사용하여 다중 모달 데이터를 잠재 표현(Latent Representation)으로 압축하고, 이를 확산(Diffusion) 또는 플로우 매칭(Flow-matching) 기반의 행동 헤드(Action Head)를 통해 연속적인 모터 명령으로 변환하는 방식입니다.
기존 방법들의 핵심 접근 방식 및 한계
기존의 최첨단 VLA 모델(예: , OpenVLA 등)은 우수한 일반화 성능을 보이지만, 실제 배포 시 막대한 연산 비용과 지연 시간(Latency)이라는 치명적인 한계에 직면합니다. 최근 연구들은 양자화(Quantization), 희소성(Sparsity), 조기 종료(Early-exit) 등을 통해 VLM 백본의 지연 시간을 줄이려 시도했습니다. 그러나 VLM이 최적화되더라도, 행동 헤드에서 요구하는 반복적인 디노이징(Denoising) 과정(일반적으로 10~20단계)이 새로운 병목 현상을 유발합니다. 즉, 상용 하드웨어에서 실시간 제어를 구현하기에는 여전히 과도한 컴퓨팅 자원이 소모됩니다.
핵심 문제 정의
본 논문은 "어떻게 하면 조작 성공률을 희생하지 않으면서 VLM 백본과 반복적인 행동 헤드 모두의 연산 비용을 동시에 절감할 수 있는가?"라는 문제를 제기합니다. 이를 해결하기 위해 백본과 행동 헤드를 통합적으로 가속화하는 예산 인식형 적응형 추론(Budget-aware adaptive inference) 프레임워크인 'A1'을 제안합니다.
2. 제안 방법 (Method)
전체 방법의 핵심 아이디어
A1 모델의 핵심 철학은 "행동 예측에 변화를 줄 때만 연산을 수행한다"는 것입니다. 플로우 매칭 모델이 적은 단계 내에 올바른 행동 궤적에 수렴한다는 점, 연속적인 제어 단계에서 행동 변화가 부드럽다는 점, 그리고 VLM의 중간 레이어(Layer)만으로도 행동 생성을 위한 충분한 공간 및 시각적 특징이 인코딩된다는 관찰에 기반합니다. 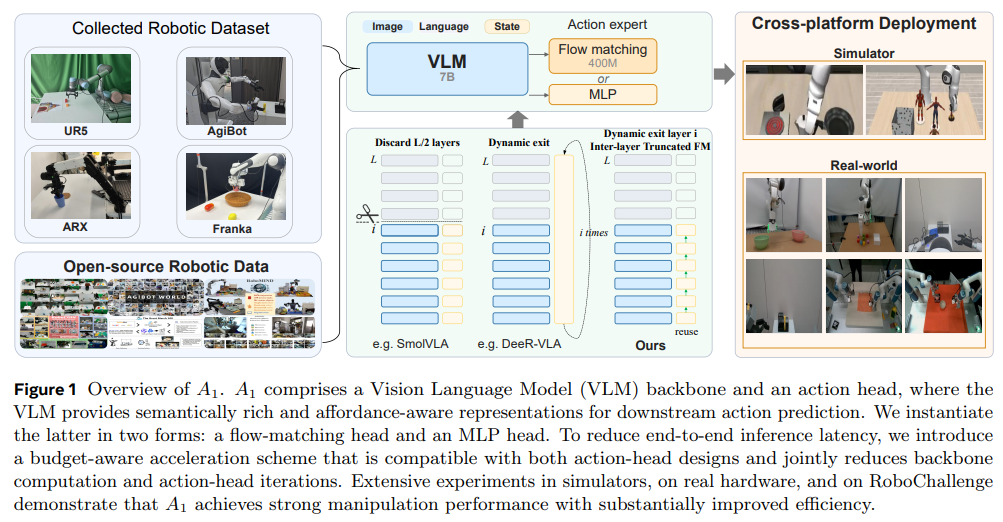
모델 및 알고리즘 구조
A1은 사전 학습된 Molmo VLM 백본에 플로우 매칭(FM) 또는 MLP 기반 행동 헤드를 결합한 구조를 가집니다. 추론 효율성을 극대화하기 위해 다음 두 가지 핵심 메커니즘을 도입했습니다.
-
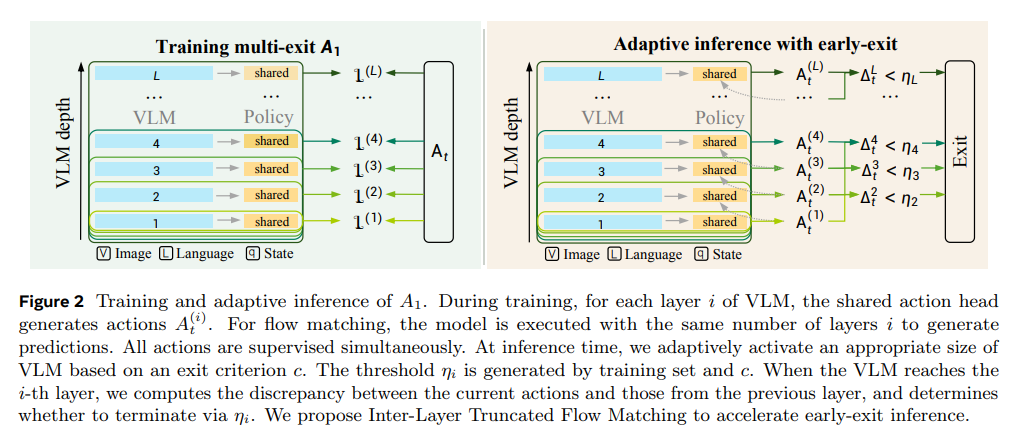
행동 일관성 임계값을 통한 조기 종료 (Early-Termination Inference)
VLM의 모든 레이어를 통과하는 대신, 중간 레이어에서 예측된 행동 궤적이 안정화되면 연산을 조기 종료합니다. 조기 종료 조건은 이전 레이어와의 행동 차이가 특정 임계값보다 작을 때 트리거됩니다.여기서 는 번째 레이어에서 생성된 행동 청크, 는 거리 측정 지표, 는 오프라인에서 보정된 레이어별 임계값입니다.
-
레이어 간 절단된 플로우 매칭 (Inter-Layer Truncated Flow Matching)
조기 종료를 사용하더라도 각 레이어에서 행동 헤드가 매번 전체 디노이징 단계를 거친다면 연산량이 폭증합니다. A1은 훈련 시 플로우 매칭 손실 함수를 사용하여 디노이징 벡터 필드를 학습합니다.추론 시에는 각 레이어에서 극소수의 디노이징 단계(예: )만 수행합니다. 가장 중요한 점은 현재 레이어의 출력을 무작위 노이즈가 아닌 다음 레이어 디노이징의 초기 조건으로 재사용(Warm-start)한다는 것입니다.
이를 통해 생성된 벡터 필드 를 바탕으로 다음 오일러 적분 단계를 밟습니다.
기존 방법과의 차별성 강조
기존의 DeeR-VLA와 같은 조기 종료 모델은 단순히 VLM의 연산만 줄이는 데 그쳤습니다. 반면, A1은 '레이어 간 절단된 플로우 매칭'을 통해 VLM 계층을 통과함에 따라 디노이징 과정을 전파(Propagate)시킵니다. 결과적으로 백본의 연산을 줄이는 동시에 행동 헤드의 반복 연산 병목까지 완벽하게 제거하여 추론 속도를 비약적으로 향상시킵니다.
3. 실험 결과 (Experiments)
사용된 데이터셋 및 환경
시뮬레이션 환경인 LIBERO와 VLABench, 그리고 Franka, AgiBot 등 4종의 실제 로봇 플랫폼에서 테스트를 진행했습니다. 또한, 다중 로봇 작업 벤치마크인 RoboChallenge를 통해 일반화 성능을 평가했습니다.
비교 대상 (Baseline)
최신 모델인 , , OpenVLA, Octo, RDT-1B 등과 비교를 수행했습니다.
핵심 성능 결과
- 정량적 지표: A1은 RoboChallenge에서 평균 성공률 29.00%를 기록하며 (28.33%), X-VLA(21.33%)를 뛰어넘는 SOTA(State-of-the-art)를 달성했습니다. 실제 로봇 실험에서도 평균 56.7%의 성공률로 기준 모델들을 압도했습니다. 시뮬레이션(LIBERO)에서도 96.6%의 높은 성공률을 유지했습니다.
- 연산 효율성: A1-FM은 설정 시 추론 시간을 4.44초에서 0.73초로 대폭 단축했습니다. 에피소드당 지연 시간은 최대 72%, 백본 연산량은 76.6% 감소하면서도 성능 저하는 미미했습니다.
성능 향상의 원인 해석
실제 조작 시 로봇 팔의 그리퍼 편차로 인해 물체의 포즈가 크게 변하는 상황에서도 A1은 목표를 정확히 인식하고 작업을 완수했습니다. 이는 VLM이 제공하는 강력한 행동 유도성(Affordance) 사전 지식과, 조기 종료 메커니즘이 불필요한 과적합(Overfitting)이나 노이즈 증폭을 방지하며 가장 안정적인 행동 궤적을 신속하게 도출해 내기 때문으로 해석됩니다.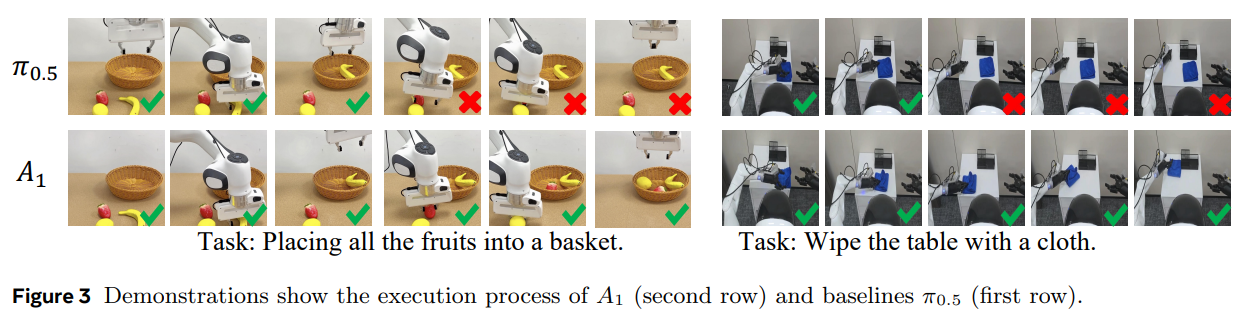
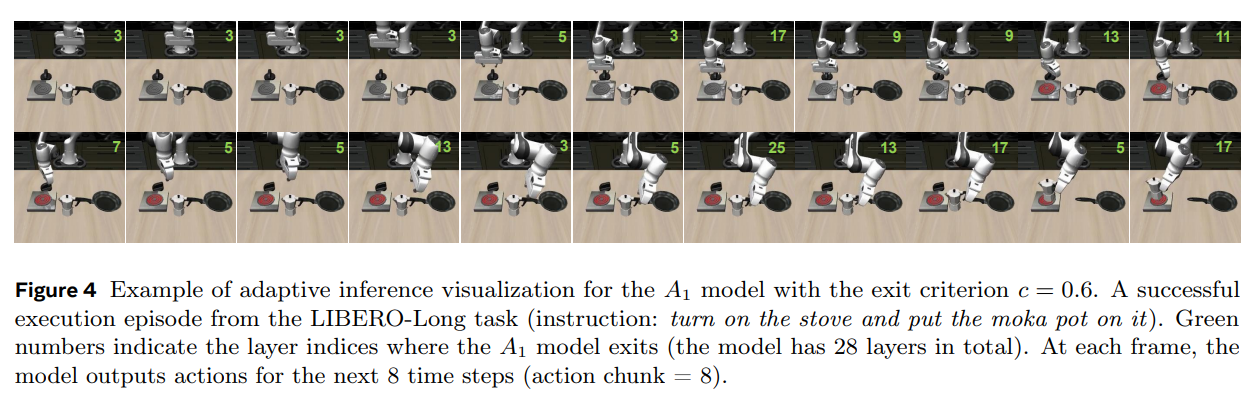
4. 한계점 및 시사점
방법의 한계
- 정적 임계값의 한계: 조기 종료를 결정하는 임계값 가 훈련 데이터를 기반으로 오프라인에서 보정(Calibrate)됩니다. 따라서 OOD(Out-of-Distribution) 데이터나 이전에 보지 못한 복잡한 작업 환경에서는 고정된 임계값이 최적의 종료 시점을 찾지 못할 가능성이 있습니다.
- 초기 레이어의 노이즈 전파: 레이어 간 플로우 매칭은 이전 레이어의 출력을 다음 레이어의 입력으로 사용합니다. 만약 아주 얕은 초기 레이어에서 심각하게 잘못된 특징(Feature)이 추출될 경우, 이 노이즈가 디노이징 과정 전반에 누적되어 잘못된 행동으로 이어질 위험이 존재합니다.
실제 적용 시 고려사항
대상 로봇의 하드웨어 컴퓨팅 파워에 맞춰 디노이징 스텝 와 허용 예산 분포를 세밀하게 튜닝해야 합니다. 지연 시간이 중요한 동적 환경에서는 를 낮추고, 정밀 조작이 필요한 환경에서는 이를 높이는 동적 할당 전략이 필요합니다.
연구가 가지는 의미
A1은 성능과 효율성의 트레이드오프를 극복한 실용적인 대규모 VLA의 표본을 제시합니다. 특히 모델 가중치, 훈련/추론 코드, 데이터 파이프라인 전체를 오픈소스로 공개하여 재현성을 확보했다는 점에서 커뮤니티에 기여하는 바가 큽니다. 거대 언어 모델과 생성형 확산/플로우 모델의 구조적 결합을 깊이 단위(Depth-wise)로 최적화할 수 있음을 증명하였으며, 향후 엣지 디바이스 기반의 온디바이스(On-device) 로봇 지능 연구를 가속화할 중요한 기반이 될 것입니다.
