1. 왜 이 연구가 필요한가
자율주행 모델은 최근까지 주로 “보고 → 바로 운전하기” 방식으로 발전해왔다. 카메라나 센서로 주변 상황을 입력받으면, 그걸 바로 차량의 움직임(trajectory)으로 바꾸는 방식이다. 이런 방법은 데이터가 많을수록 잘 동작하지만, 예상하지 못한 상황에서는 쉽게 무너지는 문제가 있다. 예를 들어 갑자기 끼어드는 차량, 복잡한 교차로, 애매한 상황에서는 단순히 “패턴을 따라하는 것”만으로는 제대로 대응하기 어렵다. 이는 모델이 단순히 행동을 모방할 뿐, 왜 그런 행동을 해야 하는지 이해하지 못하기 때문이다. 논문은 이 문제를 “reasoning–action gap”, 즉 생각과 행동 사이의 단절이라고 정의한다.
2. 이 논문의 핵심 아이디어
이 논문은 단순히 운전 행동을 예측하는 것이 아니라, 그 전에 “상황을 이해하고 이유를 설명하는 과정”을 추가하자는 아이디어를 제시한다. 즉, 사람이 운전할 때처럼 “앞차가 느려지니까 속도를 줄여야겠다” 같은 판단 과정을 모델 안에 넣는다. 이렇게 해서 최종적으로는 “이유(Reasoning)”를 먼저 만들고, 그 이유를 기반으로 “행동(Action)”을 결정하게 한다. 이 구조를 통해 모델이 단순 암기가 아니라 상황을 이해하는 방향으로 바뀌도록 만든다.
3. 모델이 어떻게 동작하는지
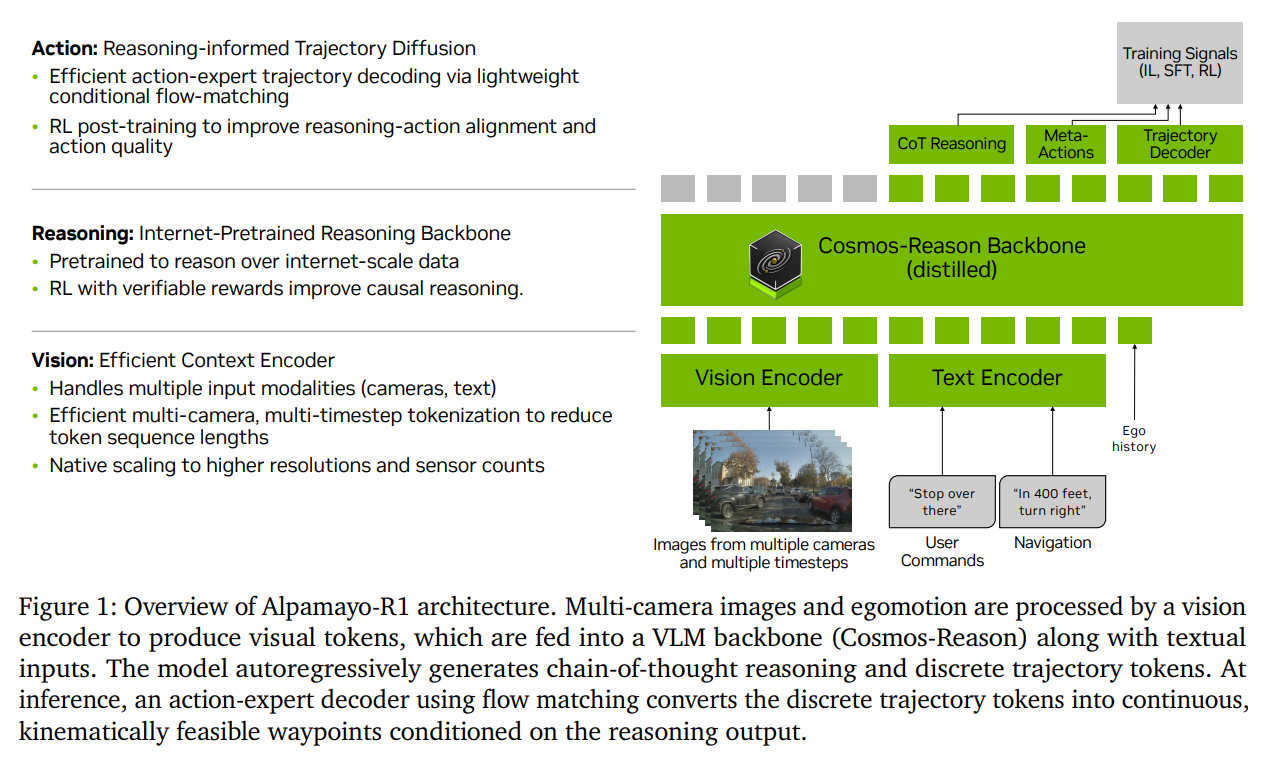
이 모델은 크게 두 단계로 생각하면 이해하기 쉽다. 먼저 입력으로 카메라 영상과 차량 상태를 받으면, 모델이 현재 상황을 해석하고 언어 형태의 reasoning을 생성한다. 예를 들어 “앞 차량이 감속 중 → 안전거리 유지 필요” 같은 형태다. 그 다음 단계에서는 이 reasoning을 참고해서 실제 차량이 움직일 경로를 생성한다. 여기서 중요한 점은 경로를 바로 만드는 것이 아니라, reasoning이 중간에 들어간다는 것이다. 논문에서는 이 과정을 diffusion 모델을 이용해 구현했는데, 쉽게 말하면 여러 가능한 경로를 점진적으로 정제하면서 현실적인 경로를 만들어내는 방식이다. 이때 reasoning이 “어떤 경로가 더 좋은지”를 판단하는 기준 역할을 한다.
4. 데이터가 왜 중요한가

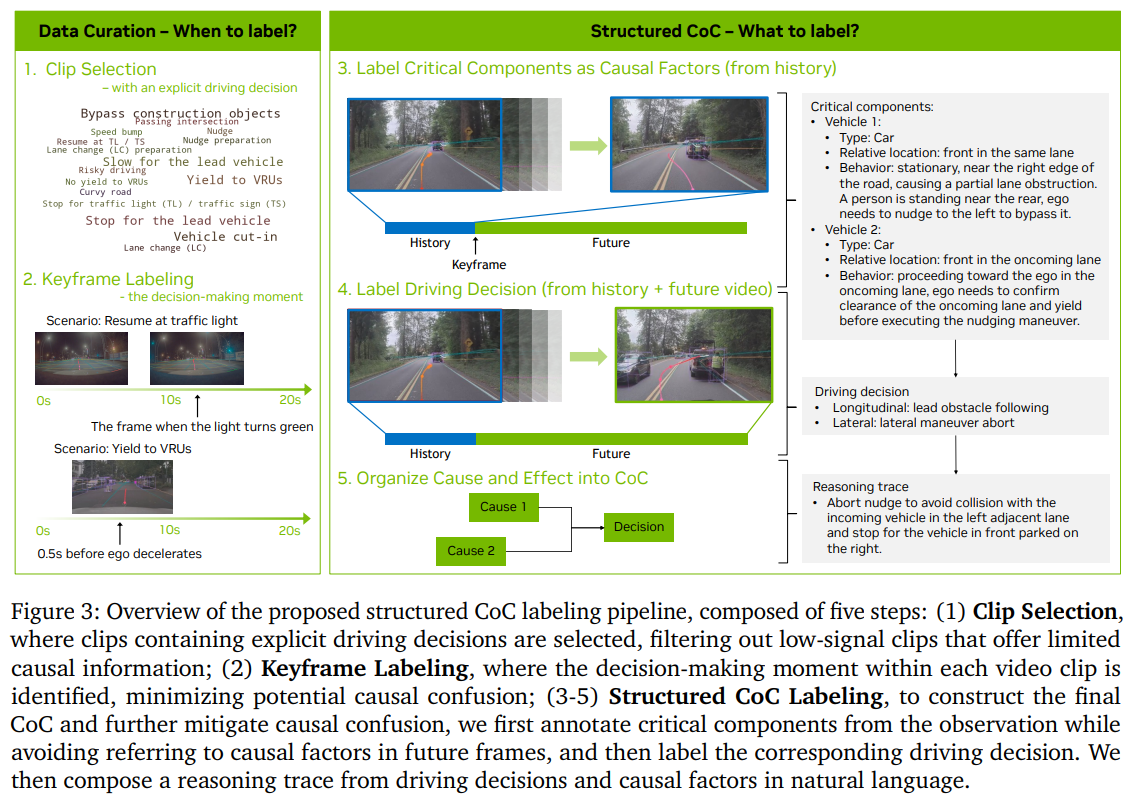
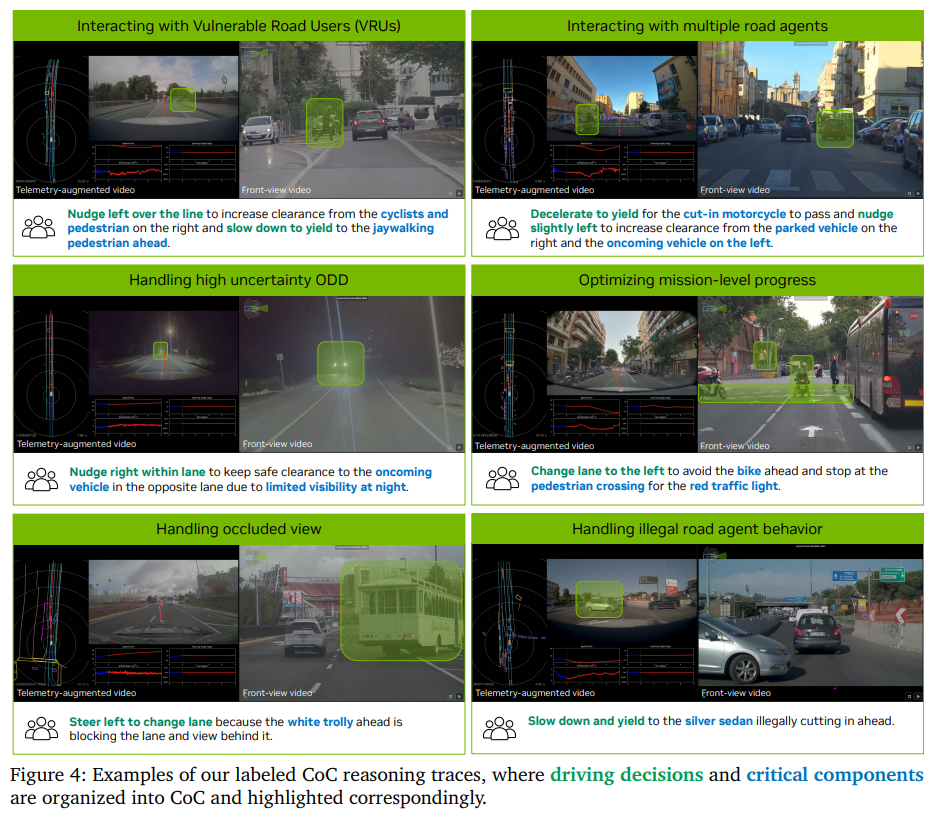
이 모델을 학습시키기 위해서는 단순히 “운전 결과”만 있는 데이터로는 부족하다. 그래서 논문에서는 “Chain-of-Causation(CoC)” 데이터셋을 새롭게 만든다. 이 데이터는 단순히 차량이 어떻게 움직였는지가 아니라, 왜 그렇게 움직였는지까지 포함한다. 예를 들어 “보행자가 나타남 → 감속 → 정지”처럼 원인과 결과가 연결된 형태다. 이런 데이터 덕분에 모델은 단순히 결과를 따라하는 것이 아니라, 상황과 행동 사이의 인과관계를 학습할 수 있다.
5. 학습 방법의 특징
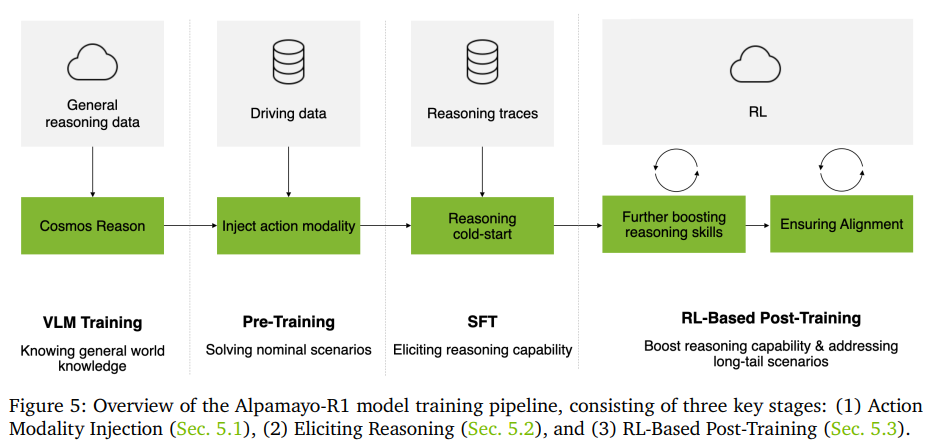
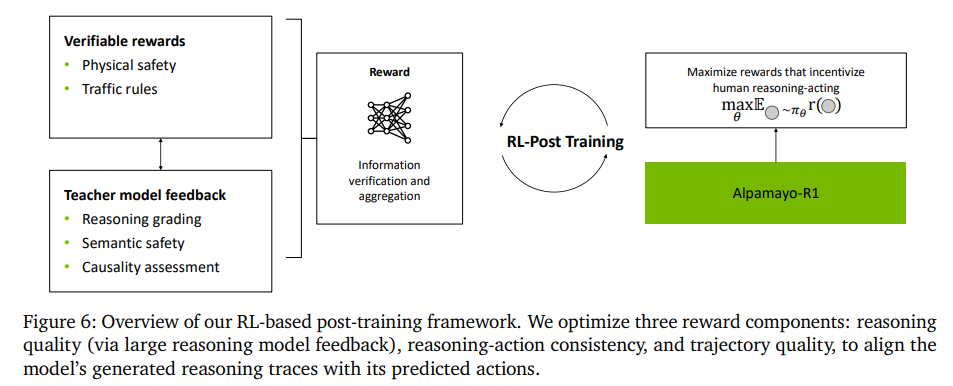
이 모델은 한 번에 끝나는 것이 아니라 단계적으로 학습된다. 처음에는 일반적인 지도학습으로 reasoning과 trajectory를 동시에 학습한다. 하지만 이 단계에서는 reasoning과 행동이 완전히 잘 맞지 않는 문제가 남는다. 그래서 두 번째 단계에서는 강화학습을 사용해 reasoning이 더 “그럴듯하고 일관되게” 나오도록 조정한다. 쉽게 말하면, reasoning이 실제로 좋은 운전으로 이어지는지를 기준으로 보상을 주는 방식이다. 이 과정을 통해 reasoning의 품질과 행동과의 연결성이 크게 개선된다.
6. 성능 결과가 의미하는 것
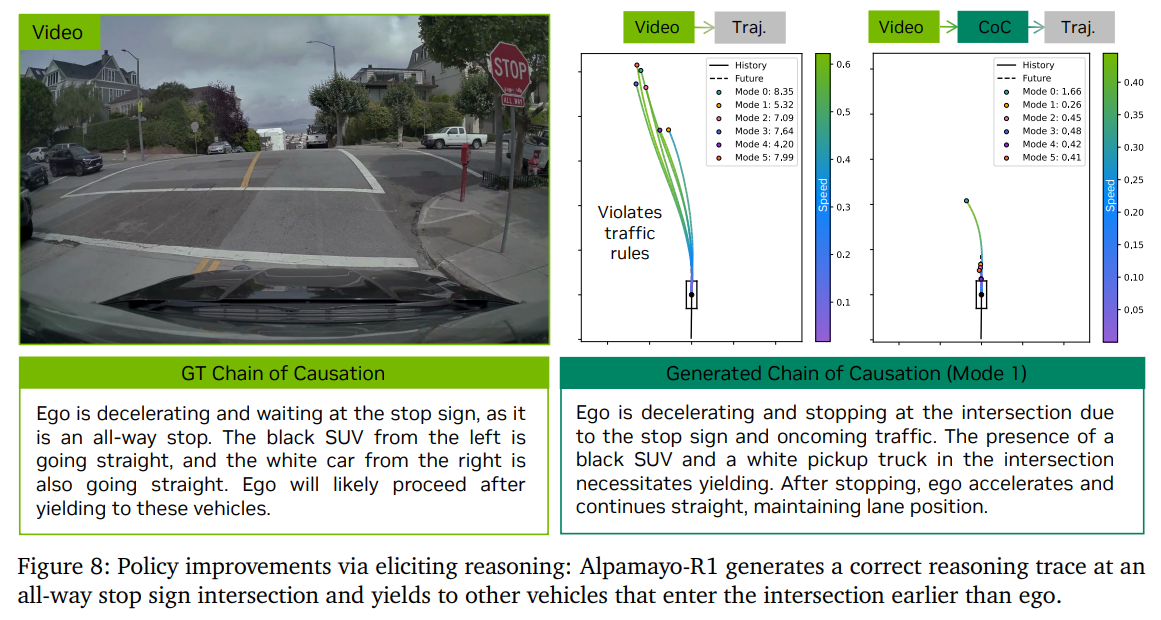

실험 결과를 보면 기존 방식보다 더 안전하고 안정적인 운전을 수행하는 것으로 나타난다. 특히 어려운 상황에서 경로 예측 정확도가 향상되고, 도로를 벗어나는 경우나 위험한 상황이 줄어든다. 이는 단순히 데이터를 더 많이 본 것이 아니라, 상황을 “이해하고 판단”하는 구조가 추가되었기 때문이라고 볼 수 있다. 또한 실제 차량에서도 약 100ms 수준의 지연으로 동작하여, 연구용이 아니라 실제 적용 가능성도 보여준다.
7. 이 논문의 진짜 의미
이 논문의 핵심은 성능 향상 자체보다 방향성에 있다. 기존 자율주행은 “패턴을 많이 보면 해결된다”는 접근이었다면, 이 논문은 “이해하고 판단하는 구조가 필요하다”는 방향을 제시한다. 특히 language 기반 reasoning을 중간에 넣었다는 점에서, 최근 LLM과 로보틱스가 결합되는 흐름과 맞닿아 있다. 즉, 자율주행을 단순한 제어 문제가 아니라 “인지 + 추론 + 행동” 문제로 확장한 것이다.
8. 하지만 남아 있는 한계
이 접근이 항상 필요한지는 아직 명확하지 않다. reasoning이 실제로 성능을 올린 것인지, 아니면 단순히 설명을 붙인 것인지 완전히 증명된 것은 아니다. 또한 시스템이 복잡해지면서 학습 비용과 유지 비용이 크게 증가한다. 강화학습 단계에서는 외부 모델의 평가에 의존하기 때문에 편향이 생길 가능성도 있다. 마지막으로 실제 도로 환경은 훨씬 더 다양하기 때문에, 현재 결과만으로 완전한 자율주행 수준이라고 보기는 어렵다.
9. 한 줄 정리
이 논문은 자율주행에서 “그냥 잘 운전하는 모델”이 아니라 “왜 그렇게 운전하는지 설명하고 판단하는 모델”로 넘어가는 중요한 전환점을 보여준다.
