1. 개요 및 문제 정의
ARC (Abstraction and Reasoning Corpus) 은 적은 수의 입력-출력 짝 (보통 2–4)만을 통해 보이지 않는 변환 규칙을 추론해야 하는 추상적 추론 문제 집합이다. 각 과제는 격자 기반의 색 패턴으로 표현되며, 새로운 입력에 대해 정확한 출력을 생성해야 한다. 기존 접근법은 주로 언어적 시퀀스 처리 / LLM 중심이었으나, 본 논문은 ARC를 이미지-to-이미지 변환 문제로 재정의한다.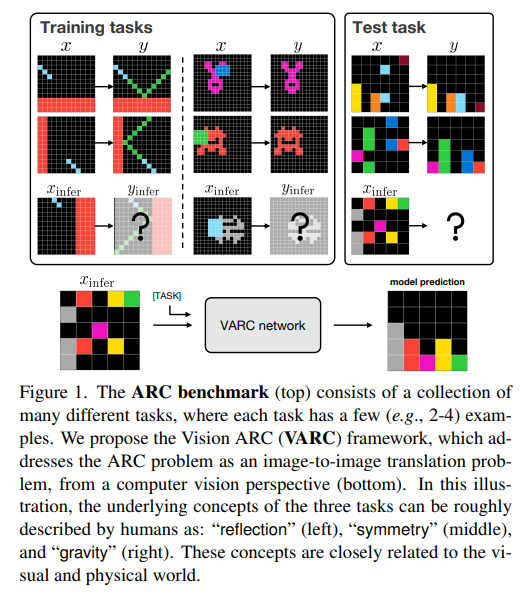
ARC 문제의 형식화
ARC의 각 작업 는 다음과 같이 정의된다:
- 입력–출력 예시 집합:
여기서 은 RGB 유사 2D 격자. - 테스트 입력:
- 목표: 의 출력을 생성하는 함수 학습.
본 연구는 이를 이미지-to-이미지 픽셀 수준 분류 문제로 취급하며, 최종 출력을 다음과 같이 예측한다:
여기서 는 신경망 파라미터 로 정의되고, 에 대한 학습된 태스크 토큰으로 조건화된다.
2. 이미지-to-이미지 번역으로의 재정의
ARC를 이미지 문제로 다루기 위해, 입력 격자를 고정 크기 캔버스에 배치한다. 캔버스는 자연 이미지 처리와 동일한 입력 구조를 제공하며, 다음과 같은 변환을 포함한다:
캔버스 표현
- 캔버스 크기: (예: ).
- 원래 입력 는 정수 배수 축소/확대(scale) 및 임의 이동(translation)을 적용하여 캔버스에 삽입된다.
- 캔버스 배경은 추가 색 (예: 번 색) 으로 채워진다.
- 변환된 캔버스를 라 정의.
이 표현은 시각적 사전지식 (visual priors) — 2D 공간적 국소성, 이동 불변성, 스케일 불변성 — 을 모델에 부여한다. 예를 들어, 로 업스케일 시 입력 패치 공간은
가 되어 고차 구조 학습이 촉진된다.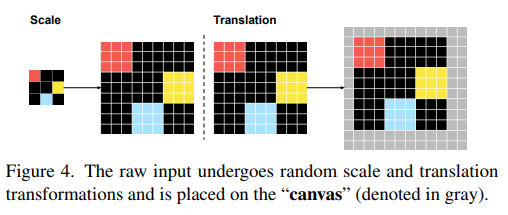
3. 모델 아키텍처
논문은 Vision Transformer (ViT) 기반 구조를 채택하며, 다음 구성 요소로 이루어진다.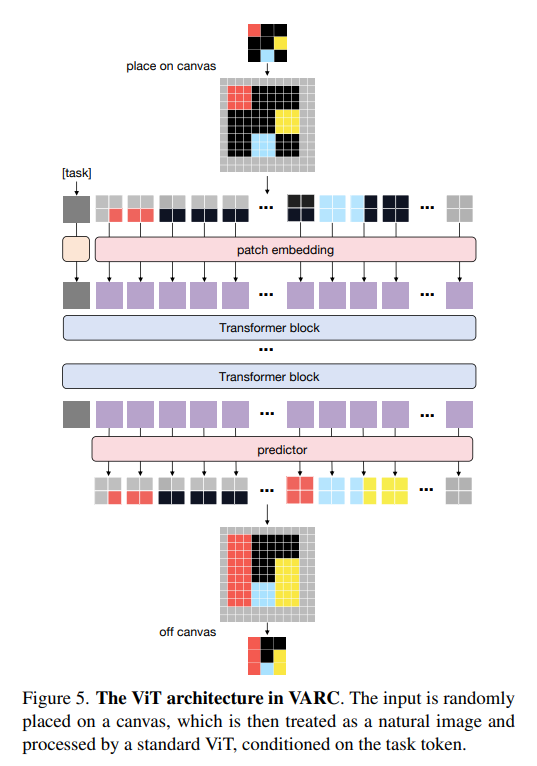
패치화 및 임베딩
캔버스를 패치로 분해:
- 패치 토큰 생성:
- 태스크 토큰: 임베딩 테이블에서
- 2D 위치 임베딩:
- 입력 토큰 에 2D 위치 정보 를 추가.
- 상대 RoPE 또는 절대 위치를 사용.
모든 토큰 시퀀스는 Transformer 입력으로 결합된다:
Transformer 블록
반복적으로 입력 는 다음과 같은 연산을 거친다:
- Self-Attention:
여기서 는 모두 , , . - Feed-Forward:
- 노멀라이제이션 및 잔차 연결.
이 과정을 여러 레이어 반복하여 최종 토큰 표현 을 얻는다.
출력 예측
마지막 패치 토큰 출력에 선형 분류기를 적용하여 픽셀 출력 확률 맵 를 생성한다:
여기서 은 개의 카테고리 (배경 포함) 확률 분포다.
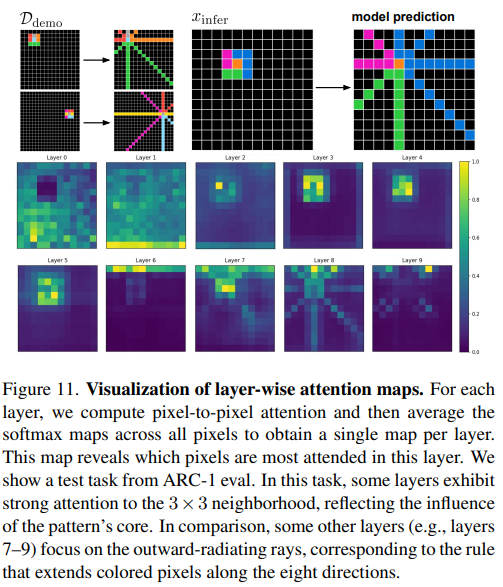
4. 학습 방식
오프라인 훈련
모든 ARC 훈련 태스크에서 공동 학습:
- 데이터: .
- 손실 함수: 픽셀 단위 교차 엔트로피
- 최적화: SGD 또는 Adam 등으로 매개변수 업데이트.
테스트 타임 트레이닝 (TTT)
새로운 작업 에 대해 테스트 시 적응 미세조정:
- 를 난수로 초기화.
- 데이터 증강 (회전, 반전, 색 순열).
- 기반 미세조정 수행.
- 최종 추론에서 finest task-token 사용.
이 단계는 1–5 스텝의 gradient descent 로 이루어지며, end-to-end differentiable 하다.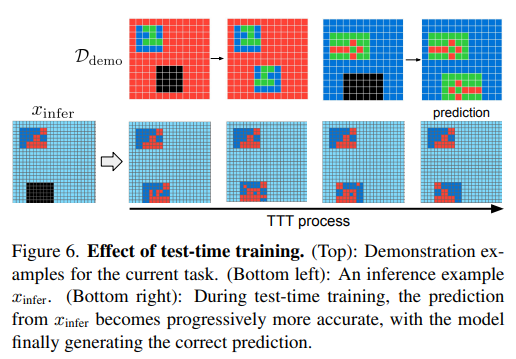
5. End-to-End 특성
- end-to-end 시각적 매핑 학습: 입력 캔버스 → 픽셀 출력.
- 미분 가능성: ViT 구조 전체와 TTT 조정 테스트 시 gradient 경로 존재.
- 모듈 관계: 캔버스 표현 → 패치 임베딩 → Transformer → 픽셀 분류기. 전 단계에서 흐르는 gradient 는 모두 역전파 가능.
6. 실험
- 데이터셋: ARC-1 훈련 (400 tasks) + ARC-1 평가.
- 모델 크기: ViT 기반, 18M 파라미터 규모.
- 성능: 60.4% ARC-1 accuracy (ensemble).
Ablation
- 2D 위치 임베딩은 1D 대비 유의미한 향상.
- 캔버스 + 스케일/이동 증강이 성능 상승에 크게 기여.
- ViT > U-Net 백본 성능 우세.
7. 한계
- 추론 비용: 테스트 타임 트레이닝이 추가적 학습 단계를 필요로 함.
- 논리적 추론: 시각적 변환 중심이므로 고차 논리적 조건에 약할 수 있음.
- 데이터 효율성 한계: 순수 ARC 데이터만으로 학습 시 범용성 제한.
8. 결론
본 논문은 ARC 문제를 시각 변환 문제로 재정의했으며, Vision Transformer 기반 end-to-end 학습과 테스트 시 적응을 통해 기존 언어 중심 접근법을 능가하는 성능을 보였다. 이는 시각적 선험 지식이 추상적 추론 성능을 강화한다는 점을 실험적으로 입증한다.
