[논문 리뷰] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
논문 리뷰
1. 논문 정보
- 제목: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 저자: Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi
- arXiv: 2301.12597
- 분야: Multimodal Learning, Vision-Language Pre-training, Foundation Models
- 주요 목표: 기존 대규모 Vision-Language Model(VLM)의 학습 비용을 크게 줄이면서도, 강력한 이미지–언어 이해/생성 능력을 실현하는 방법 제안
2. 배경과 동기
BLIP-2는 기존 Vision-Language Pre-training(VLP) 모델들이 겪는 두 가지 핵심 한계를 해결하려고 한다:
- 비용이 매우 크다는 점
- 기존 VLP 방법은 대규모 데이터와 많은 GPU 자원을 필요로 함.
- 이미지 인코더와 언어 모델 간의 멀티모달 통합이 어렵다는 점
- 시각 정보와 언어 정보를 효과적으로 결합할 수 있는 구조가 필요함.
BLIP-2는 이미지 인코더와 언어 모델(LLM)을 그대로 활용하면서,
그 사이를 “lightweight adapter”로 연결해 효율적이고 강력한 멀티모달 학습을 가능하게 한다는 점이 핵심이다.
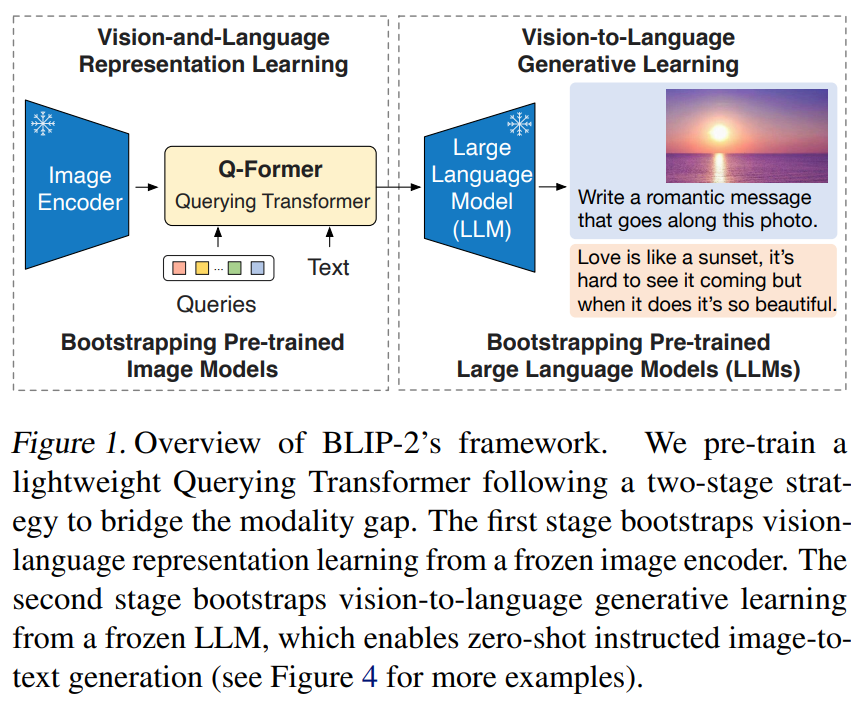
3. 핵심 아이디어
BLIP-2의 중심 전략은 아래 세 가지다:
🔹 3.1 Frozen Image Encoder
이미지 인코더(예: CLIP 비전 백본, ViT 기반)를 훈련 중에 고정(frozen)하여
복잡한 비전 파라미터 업데이트 비용을 제거한다.
🔹 3.2 Frozen Large Language Model (LLM)
언어 모델(예: OPT, FLAN-T5 등)도 미리 훈련된 LLM을 그대로 사용하며
모델 파라미터 대부분을 고정한다.
🔹 3.3 Lightweight Bridge: Q-Former
이미지 인코더와 LLM 사이에 Query-based Transformer (Q-Former) 라는 작은 모듈을 삽입한다.
이 모듈은 learnable queries를 사용해 이미지 표현을 뽑고,
그 출력만 LLM으로 전달하는 역할을 함.
👉 요약하면:
BLIP-2는 “모든 큰 모델을 훈련하지 않고”,
이미지 → 자연어 생성을 위한 표현을 뽑는 작은 모듈만 학습해서 높은 성능을 얻는 방법이다.
4. BLIP-2 아키텍처
BLIP-2는 세 가지 주요 모듈로 구성된다:
Input Image
↓
Vision Encoder (frozen)
↓
Q-Former (학습됨)
↓
Large Language Model (frozen)
↓
Multimodal Output💡 Vision Encoder (Frozen)
이미지나 비디오 프레임을
- low-level 시각 특징 →
- 고수준 표현으로 변환
→ 학습하지 않고 그대로 바닥 feature를 추출한다.
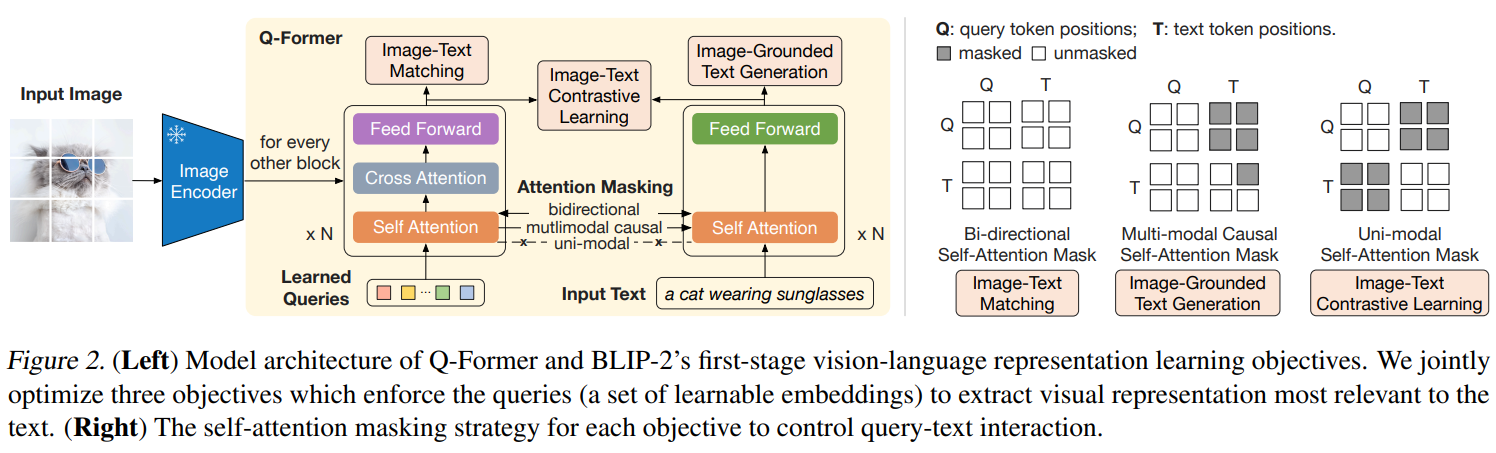
💡 Q-Former (Adapter)
핵심 역할은 “시각 정보를 언어가 볼 수 있는 형태로 바꾸는 것”.
- learnable query set을 이미지 feature에 attention으로 적용
- 이미지 feature를 요약하여 고수준 시각 representation 생성
- transformer 계열 구조지만 매우 가볍고 학습 가능
💡 Large Language Model (Frozen)
Q-Former로부터 나온 표현(feature tokens)을 입력받아
- 이미지 캡션 생성
- 비주얼 질문 응답
- 멀티모달 추론/생성 등 수행 가능
LLM 자체 학습 없이도 visual grounding된 언어 생성을 실현한다.
5. 학습 전략
BLIP-2는 다음과 같은 두 단계로 학습한다:
✏️ Stage 1: Q-Former Pre-training
Vision Encoder의 feature에 Learnable Queries를 적용하여
이미지 표현을 뽑는 방법을 학습.
- Q-Former의 query vectors만 학습
- 이미지 ↔ text pairs로 multimodal pre-training
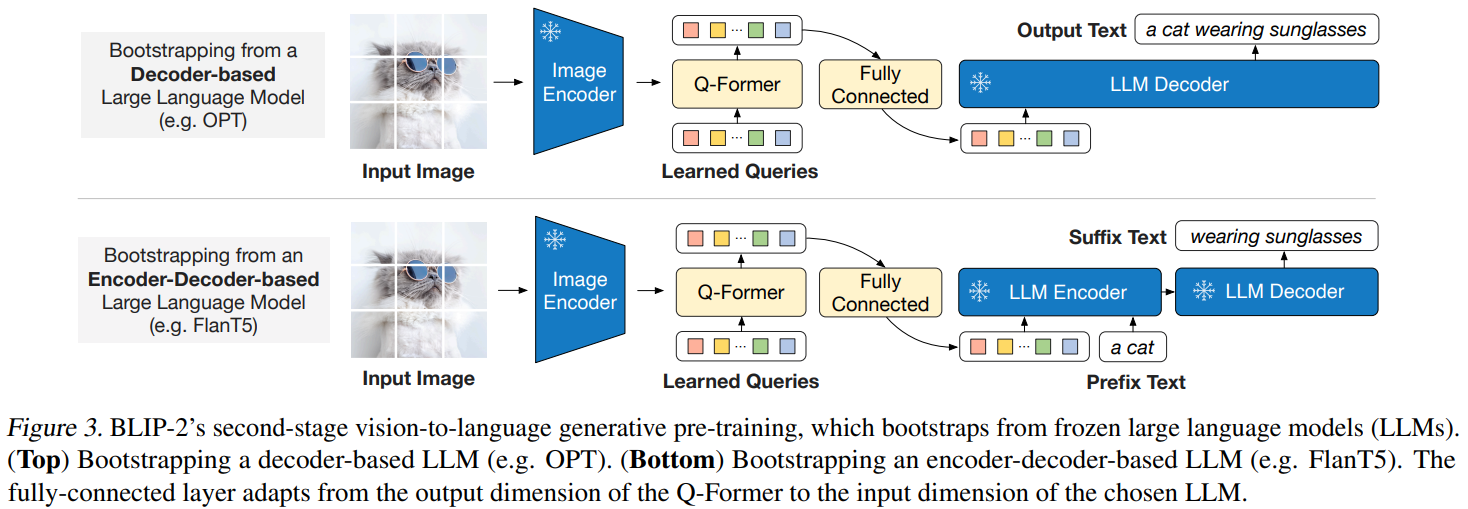
✏️ Stage 2: Target Task Fine-tuning
Q-Former를 통해 생성된 vision tokens를 LLM에 입력하고
영어 caption 생성, VQA(visual question answering), image retrieval 등 target task에 맞게 fine-tuning 진행
주의: Vision Encoder와 LLM은 이 entire process에서 동결된다.
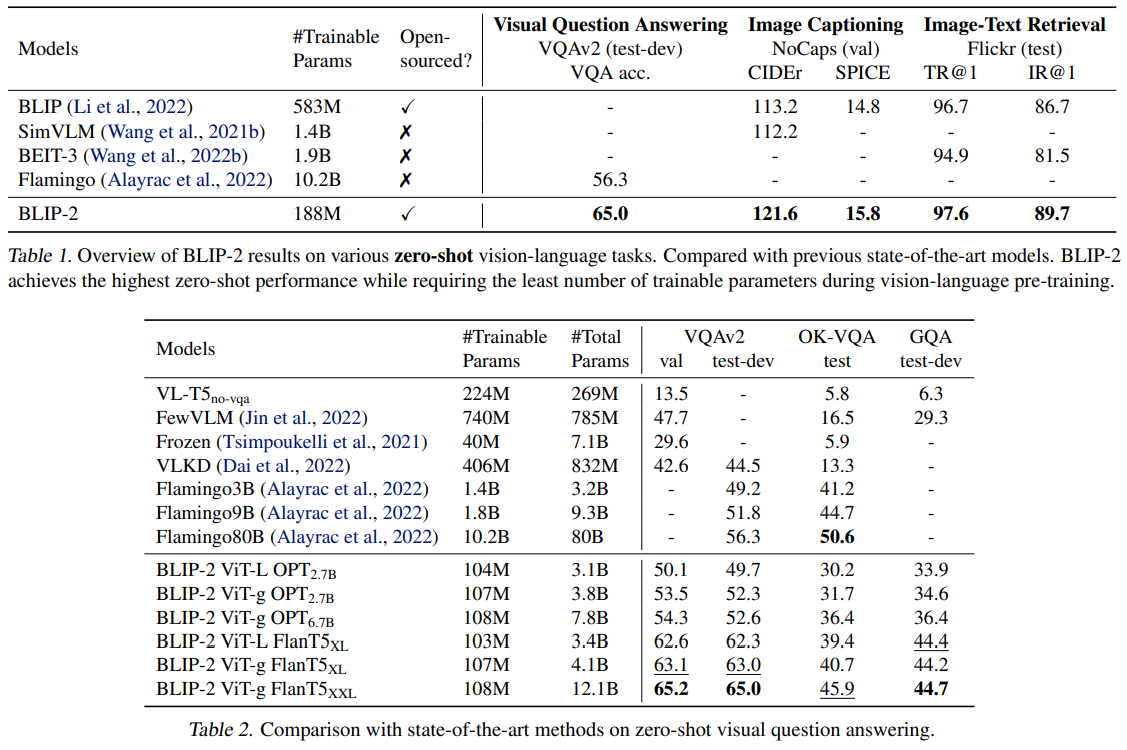
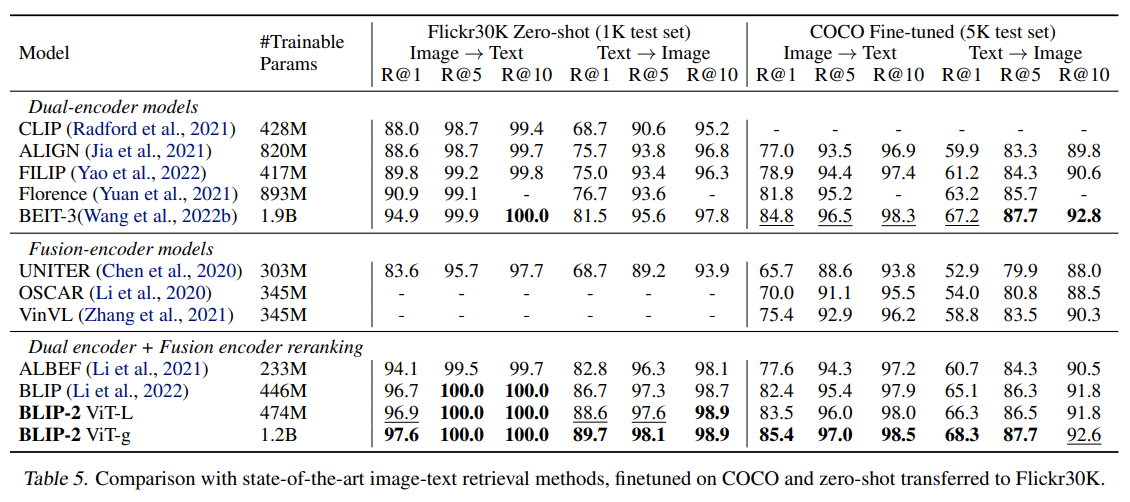
6. 주요 실험 결과

BLIP-2은 다음과 같은 멀티모달 벤치마크에서 좋은 성능을 보였다:
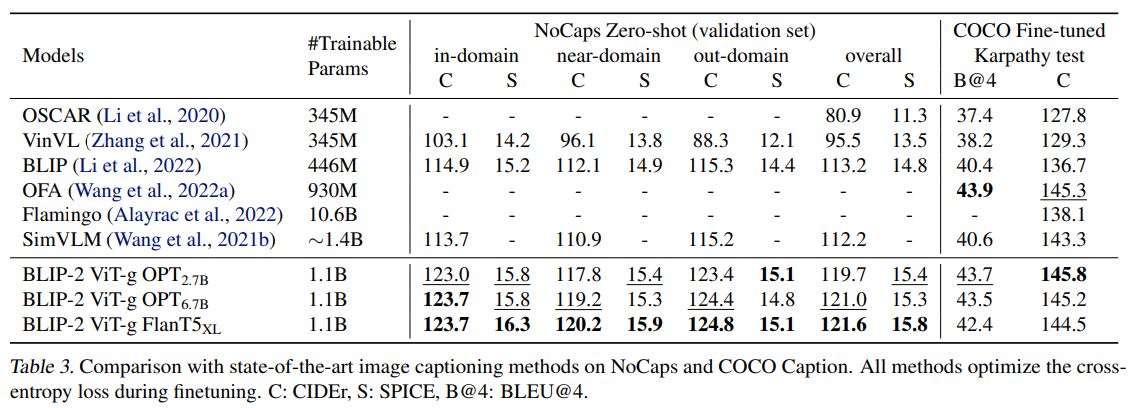
📊 Zero-Shot Captioning
- BLIP-2는 NoCaps(zero-shot 캡션ing) 등 이미지 → 문장 생성에서 우수한 성능을 보였음.
- Flamingo 같은 이전 모델 대비 경쟁력 있는 결과를 보임
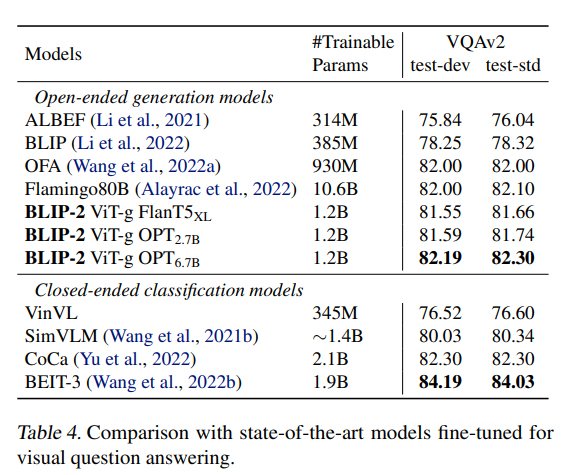
📌 Few-Shot & Fine-Tuned VQA
-
Q-Former + frozen LLM 구조 하나로
- 질문답변
- 이미지 인식
- 텍스트 생성
까지 다양한 작업에 적용 가능
👉 trainable parameters은 매우 적지만, 멀티모달 이해/생성 성능은 견고하게 유지됨.
7. 장점
✔ 효율적인 사전학습
- full vision-language 통합 모델을 pre-train하는 대신,
시각/언어 backbone을 모두 고정→Q-Former만 학습
→ pre-training 비용과 데이터 필요량 감소
✔ 모듈 간 명확한 분리
- Vision Encoder + Adapter + LLM
→ 구조가 모듈식(modular)으로 설계되어
→ 개별 모듈을 교체/업그레이드가 용이
✔ 여러 멀티모달 태스크에서 범용성
- 이미지 캡션, VQA, instruction 등 다양한 태스크에 적용 가능
✔ Zero/Few-Shot 능력
- Frozen LLM을 활용하기 때문에 언어 생성 범용성(fluent language) 유지
8. 한계 및 아쉬운 점
⚠ 모듈 고정의 한계
- Vision Encoder와 LLM을 동결하는 구조는 joint representation learning의 융통성을 어느 정도 포기하는 것임
→ 멀티모달 상관관계를 완전히 최적화할 수는 없음
⚠ 데이터/기술 격차 문제
- 매우 큰 LLM + big vision encoder 조합을 쓰는 것은 여전히 계산 자원이 많이 필요한 구조
→ “frozen” 방식이 비용을 줄이긴 했지만, 여전히 heavy backbone이 부담스러울 수 있음
⚠ 정확도 한계
- 완전히 end-to-end fine-tune된 VLM 대비 특정 세부 인식(예: 초소형 사물 또는 fine-grained 시각 reasoning)에서는 성능 격차가 있을 수 있음
9. 의의 및 위치
BLIP-2는
“현실적인 멀티모달 시스템에서 대규모 비전-언어 사전학습을 효율적으로 정복하기 위한 실용적 접근법”이라고 할 수 있다.
즉,
- Vision encoder와 LLM을 그대로 살리면서
- 작은 adapter만 학습함으로써
- 이미지–언어 멀티모달 능력을 유지하는 것
이 구조는 이후의 여러 멀티모달 모델(예: InstructBLIP, VideoBLIP, LLava 계열)에도 영향을 주었다는 평가를 받는다.
10. 한 줄 요약
BLIP-2는 frozen vision encoders와 frozen LLM 사이에 lightweight Q-Former를 두어 멀티모달 능력을 효율적이고 강력하게 끌어내는 새로운 VLP 패러다임을 제시한 연구다.
