1. 논문 정보
- 제목: DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description
- 저자: Adrienne Deganutti, Simon Hadfield, Andrew Gilbert
- 소속: University of Surrey, UK
- arXiv: 2503.24096
- 분야: Computer Vision, Natural Language Processing, Multimodal Learning
- 핵심 주제: 장편 영상에서의 맥락 기반 오디오 설명(AD) 생성
한 줄 요약
DANTE-AD는 frame-level과 scene-level의 두 가지 시각 표현을 동시에 활용하는 dual-vision attention 구조를 도입하여, 긴 영상 시퀀스에서도 일관된 맥락 기반 Audio Description을 생성하는 모델이다.
2. 연구 배경 및 문제 정의
Audio Description(AD)이란?
Audio Description은 시각 장애인/저시력자가 영상 콘텐츠를 더 잘 이해할 수 있도록,
화면에서 벌어지는 장면·행동·상황 등을 음성 내레이션으로 서술하는 작업을 의미한다.
기존 접근의 한계
기존 Video Captioning 또는 짧은 클립 기반 설명 생성 방법들은:
- 장면 간 맥락 유지가 어려움
- FRAME 수준의 특징만으로는 긴 영상의 스토리텔링을 포착하기 힘듦
- Narrative 구조 및 지속적 시간적 연결성을 반영하지 못함
즉, 긴 영상 전체를 포괄하는 깊이 있는 설명 생성(AD)이 기존 모델에게는 큰 도전이었음.
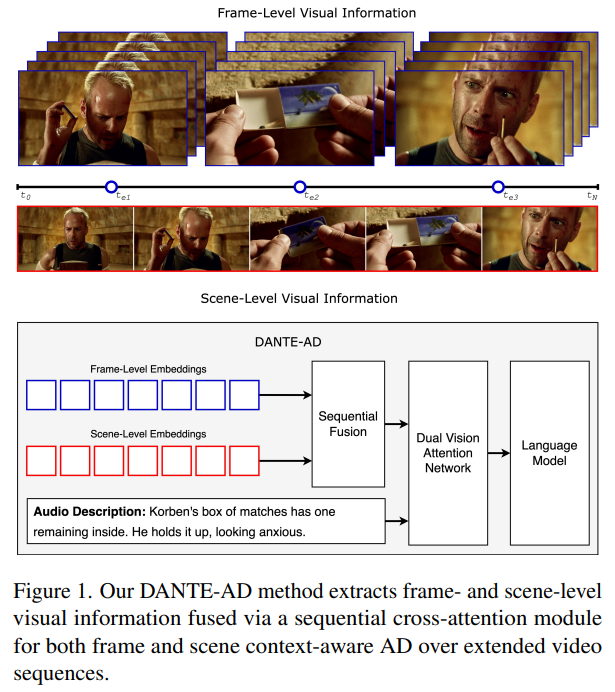
좋아, 그럼 지금까지 우리가 정리한 정확한 이해(8 frame-level vs 8 scene-level segment, 역할 분리, 설계 의도)를 반영해서
## 3. 주요 기여를 더 탄탄한 논문 리뷰용 문단으로 전체 수정본을 줄게.
아래는 형식은 유지하면서 내용 밀도만 높인 버전이야. 그대로 써도 되고, 일부만 가져가도 돼.
3. 주요 기여
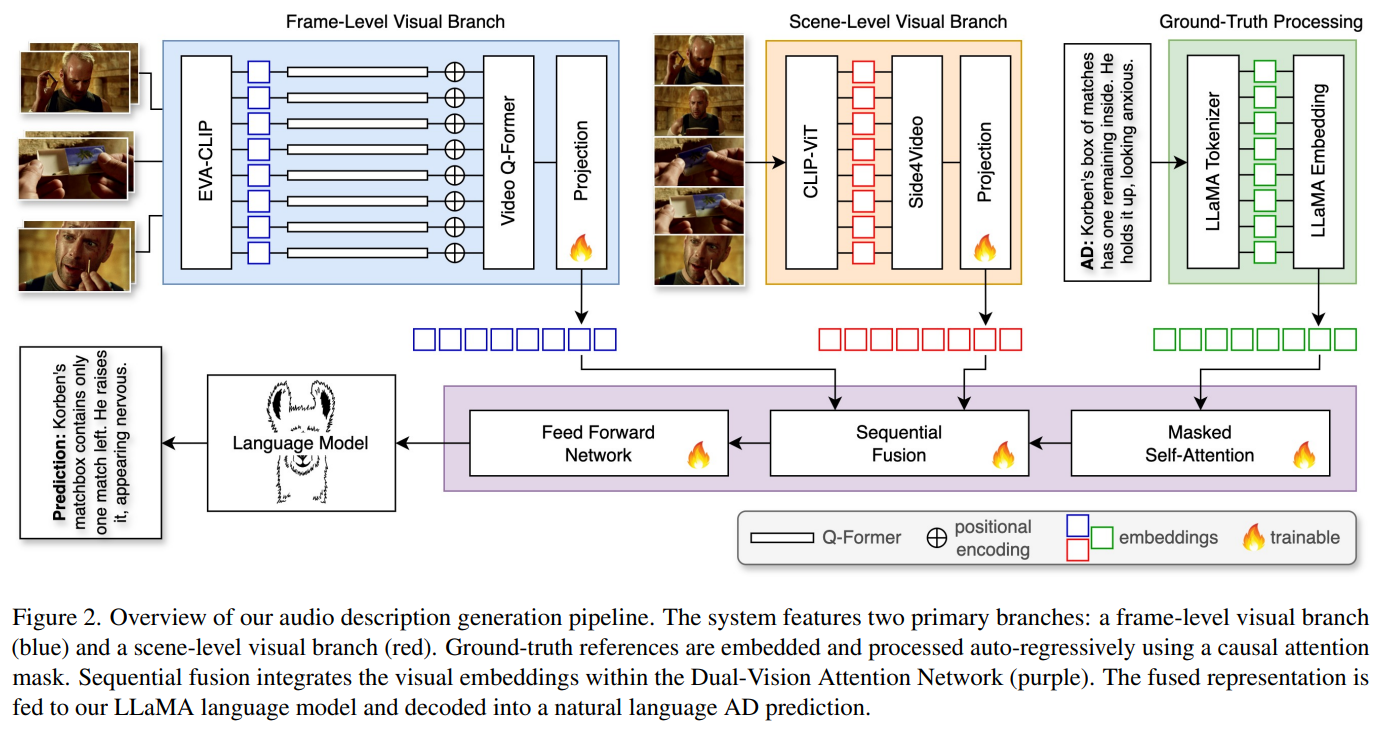
DANTE-AD 논문이 제시하는 핵심 기여는 다음 세 가지로 정리할 수 있다.
1. Dual-Vision Representation: 시간 스케일 분리 기반 시각 표현
DANTE-AD는 영상 정보를 단일 시각 표현으로 처리하지 않고,
서로 다른 시간 스케일을 갖는 두 가지 시각 표현을 명시적으로 분리하여 모델링한다.
-
Frame-level representation
- 비디오 클립 전체에서 서로 다른 시점의 8개 프레임을 균등 샘플링
- 각 프레임을 정지 이미지로 처리하여
객체, 행동, 공간적 관계 등 순간적인 시각적 디테일(spatial evidence)을 포착
-
Scene-level representation
- 동일한 비디오 클립을 시간적으로 균등한 8개의 temporal segment로 분할
- 각 segment 내부의 여러 프레임을 video encoder를 통해 집계하여
장면의 흐름, 사건의 진행, 서사적 맥락(narrative context)을 요약한 representation 생성
중요한 점은, scene-level에서 사용되는 8개의 출력은
개별 프레임이 아니라 각 시간 구간을 대표하는 요약 토큰이라는 것이다.
이를 통해 모델은 시각적 사실과 장기적 맥락을 서로 다른 표현 공간에서 동시에 학습할 수 있다.
2. Dual-Vision Attention Network: Sequential Cross-Attention 기반 융합
이렇게 분리된 frame-level과 scene-level 표현은
Dual-Vision Attention Network를 통해 통합된다.
-
두 시각 표현은 Sequential Cross-Attention 구조로 연결되며,
- frame-level의 세부 시각 정보가
- scene-level의 장기 맥락 안에서 재해석되도록 설계된다.
이 방식은 단순한 feature concatenation이나 pooling과 달리,
- 시각적 디테일은 유지하면서
- 장면 간 시간적 연결성과 이야기 흐름을 자연스럽게 반영
할 수 있도록 한다.
결과적으로 모델은
“무엇이 보였는가”와 “그것이 어떤 맥락에서 발생했는가”를 동시에 고려하는 표현을 학습하게 된다.
3. Sequential Fusion 이후 FFN–LLM Interface 설계
DANTE-AD는 시각–언어 융합을 LLM 내부에서 수행하지 않고,
시각 표현의 융합을 LLM 이전 단계에서 완결하는 구조를 채택한다.
Sequential Cross-Attention을 거친 출력은
frame-level과 scene-level 정보가 정렬된 연속적인 시각 의미 임베딩이며,
아직 자연어 토큰에 대응되는 표현은 아니다.
이를 위해 모델은 FFN 기반 projection layer를 두어,
융합된 시각 임베딩을 LLM의 토큰 임베딩 공간으로 투사한다.
이 FFN은 시각 정보를 단어 ID로 변환하는 것이 아니라,
LLM이 조건(context)으로 해석할 수 있는 continuous visual tokens를 생성하는 역할을 한다.
이렇게 생성된 visual tokens는
LLM 입력 시퀀스의 prefix로 제공되며,
LLM은 이를 기반으로 오디오 설명을 autoregressive하게 생성한다.
이 설계를 통해 DANTE-AD는
- LLM의 언어 생성 능력을 유지하면서
- 긴 영상의 시각적 맥락을 효과적으로 반영하는
안정적이고 확장 가능한 vision-to-language 연결 방식을 제시한다.
4. 장편 영상(Audio Description)에 특화된 설명 품질 향상
Dual-Vision 구조와 attention 기반 융합 덕분에
DANTE-AD는 기존 단일 시각 표현 기반 AD 모델 대비 다음과 같은 개선을 보인다.
- 장면 간 맥락 단절 감소
- 시각적 세부 묘사 정확도 향상
- 서사적 일관성(narrative coherence) 강화
특히 긴 영상에서 흔히 발생하는:
- 설명의 단편화
- 장면 전환 시 의미 손실
- 반복적이고 피상적인 묘사
문제를 효과적으로 완화하며,
장편 영상에 적합한 Audio Description 생성 모델로서의 가능성을 실험적으로 입증한다.
요약 한 문장
DANTE-AD의 핵심 기여는 시각 정보를 frame-level과 scene-level로 시간 스케일에 따라 분리하고, 이를 sequential cross-attention으로 결합함으로써 장편 영상 Audio Description의 정확성과 서사적 일관성을 동시에 향상시킨 데 있다.
4. 아키텍처 개요
전체 파이프라인은 아래 다층 구조로 구성돼 있어.
Input Video (전체 장편 영상)
↓
┌──────────────────────────────────┐
│ Dual-Vision Feature Extractor │
├──────────────────┬───────────────┤
│ Frame-Level │ Scene-Level │
│ Branch │ Branch │
└──────────────────┴───────────────┘
↓
Dual-Vision Attention Network (Sequential Cross-Attention)
↓
Fused Visual Representation
↓
Frozen LLaMA2-7B Language Model
↓
Audio Description Text4.1 Frame-Level Visual Branch

- 영상에서 일정 간격으로 sampling한 자세한 frame들을 개별적으로 처리
- CLIP 기반 비전 인코더 + Q-Former로 공간적·시각적 특징을 추출
- 프레임 간 상대적 위치 정보를 positional embedding으로 반영
이 부분은 세부 묘사(물체·행동·상호작용)에 초점을 맞춰.



4.2 Scene-Level Visual Branch
- 전체 영상 시퀀스를 관통하는 global context 추출
- Side4Video(S4V) 구조를 parallel로 활용하여
긴 시간적 정보, 상호 연관된 장면 변화 등을 포착
이를 통해 narrative 흐름에 대한 일관성 있는 요약이 가능해짐.

4.3 Dual-Vision Attention Network
이 모듈은 frame별 세부 표현과 scene 수준 글로벌 표현을 Sequential Cross-Attention으로 융합해:
- 먼저 frame-level 표현을 통해 속도감 있는 세부 정보를 캡처
- 이후 그 정보를 scene-level 표현과 결합
→ 긴 시간 맥락이 자연스럽게 녹아있는 표현을 만든다
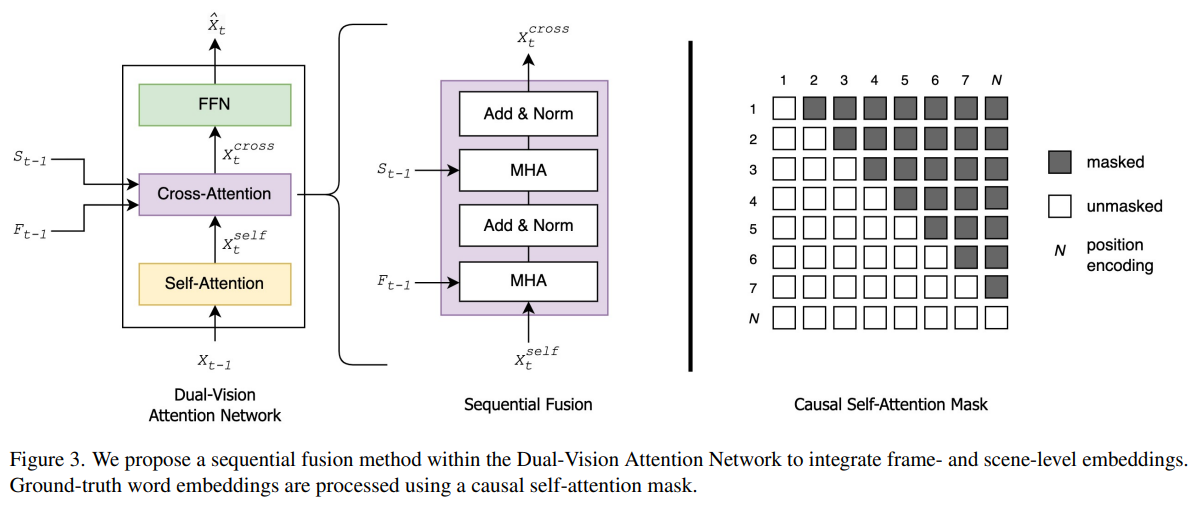
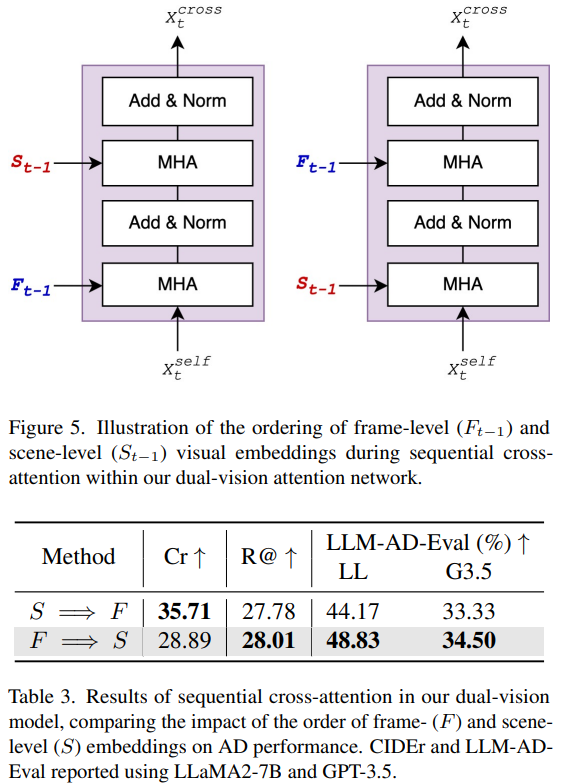
4.4 Language Decoding
- 이중 시각 표현이 결합된 fused vector는
LLaMA2-7B와 같은 사전 학습된 언어 모델로 전달돼
자연어 Auto Description 텍스트로 생성된다. - 언어 모델은 frozen 상태로 유지되어 일반화 능력을 보존함.
5. 학습 방식
-
Frame 및 Scene 비전 인코더 대부분은 pretrained 가중치를 활용
-
모델 중 trainable한 부분은:
- dual-vision attention network
- projection layers
→ 최소한의 추가 파라미터만 학습함
-
트레이닝은 자동 설명 레퍼런스(ground truth)를 기반으로
다음 토큰을 예측하는 Autoregressive 방식으로 진행됨
6. 실험 및 결과
데이터셋
-
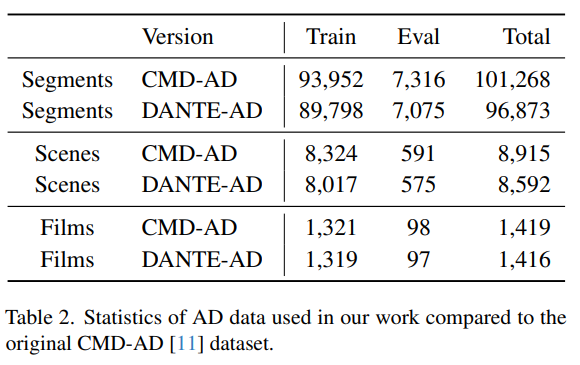
CMD-AD dataset(Condensed Movie Dataset Adapted for AD) 사용
- 영화에서 발췌된 여러 장면에 대해 전문가가 만든 Audio Description이 레퍼런스로 존재.
평가 지표
-
NLP 전통적 지표:
- CIDEr
- Recall@k/N
-
LLM 기반 평가:
- LLM-AD-Eval
→ LLaMA2, GPT-3.5를 이용해 의미적 유사성 및 narrative 질 평가
- LLM-AD-Eval
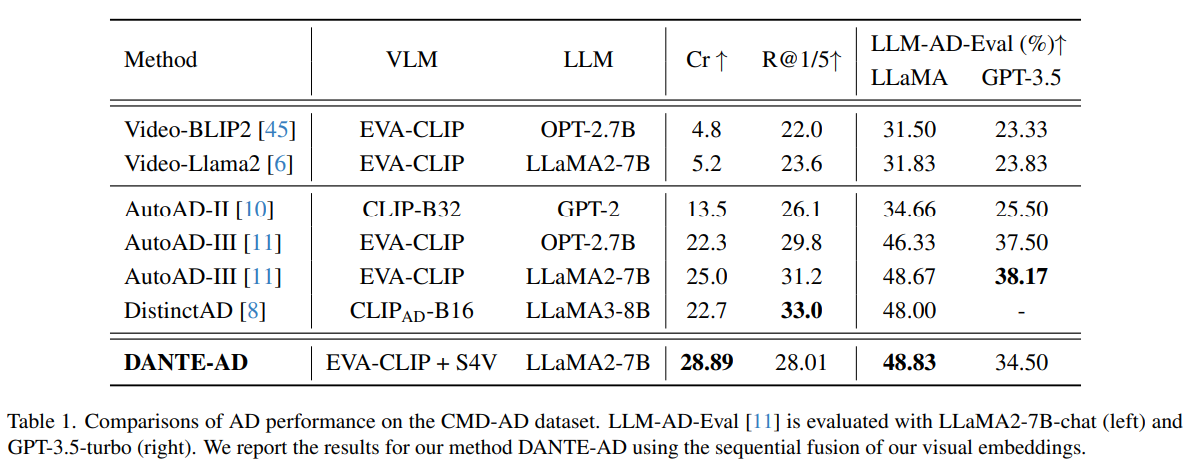
주요 성능
DANTE-AD는 다음과 같은 결과를 보였음:
| 비교 모델 | CIDEr ↑ | LLM-AD-Eval (%) ↑ |
|---|---|---|
| Video-BLIP2 | 낮음 | 낮음 |
| Video-LLaMA2 | 중간 | 중간 |
| AutoAD-II/III | 높음 | 비교적 높음 |
| DANTE-AD (ours) | 최고 수준 | 우수함 |
✔ 특히 CIDEr 및 LLM-AD 평가 모두 기준보다 높음
→ narrative 및 의미적 품질이 향상됨
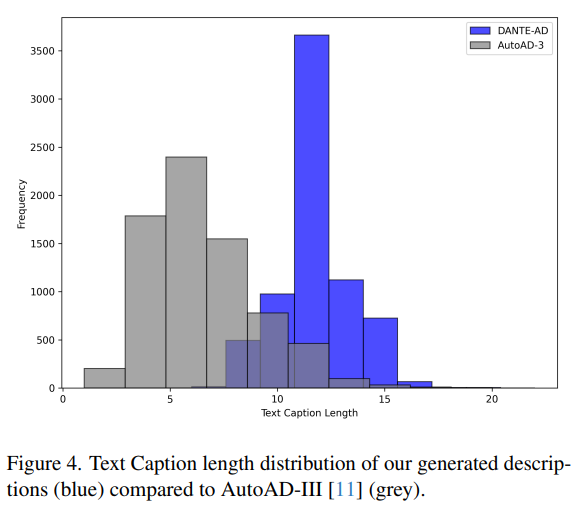
또한 DANTE-AD는 더 긴 설명(텍스트 길이)을 생성하는 경향이 있어
storytelling 요소를 풍부하게 담아냄.

7. 장점
✅ Dual-Vision 구조가 narrative를 더 잘 포착
- Frame 수준의 세부 묘사 + Scene 수준의 맥락 정보를 순차적 cross-attention으로 통합함으로써
→ 영상의 장기적 이야기 흐름까지 반영 가능해짐
✅ 최소한의 파라미터 학습
- 대부분 모듈은 pretrained backbone 사용 → trainable parameters는 거의 없음
- 효율성과 비용 측면에서 실용적임
✅ 실제 평가에서 높은 설명 품질
- 단순 짧은 설명이 아니라
→ 맥락적 narrative 요소까지 반영된 AD 생성이 향상됨
8. 한계 및 고려할 점
⚠ Scene Branch Complexity
- Scene-level global representation 추출은 background action 인식 등에서 추가 연산이 필요
- 긴 동영상 전체 흐름을 완벽히 캡처하기 위한 학습 데이터/연산량 요구가 있음
⚠ 비교 대상 한정
- 실험에서 비교된 모델은 대부분 단일 시각 표현 기반이었으며
→ 기타 최신 multi-modal narrative 모델과의 비교는 부족할 여지가 있음
9. 결론
DANTE-AD는 긴 영상(extended sequences) Audio Description 생성 문제에서:
Frame-level + Scene-level dual-vision representation을 sequential cross-attention으로 결합함으로써 narrative coherence(맥락 일관성)를 강화한 모델을 보여준다.
이 구조 덕분에 기존 AD/Video Captioning보다 더 풍부하고 맥락적인 설명을 신뢰할 수 있게 생성한다는 것이 핵심 결론이야.
10. 한 문장 요약
DANTE-AD는 frame과 scene 두 방향의 시각 정보를 동시에 활용하는 attention 네트워크로, 긴 영상의 narrative 이해와 Audio Description 생성을 크게 향상시킨 multimodal 모델이다.
