[논문 리뷰] Binning as a Pretext Task: Improving Self-Supervised Learning in Tabular Domains
논문 리뷰
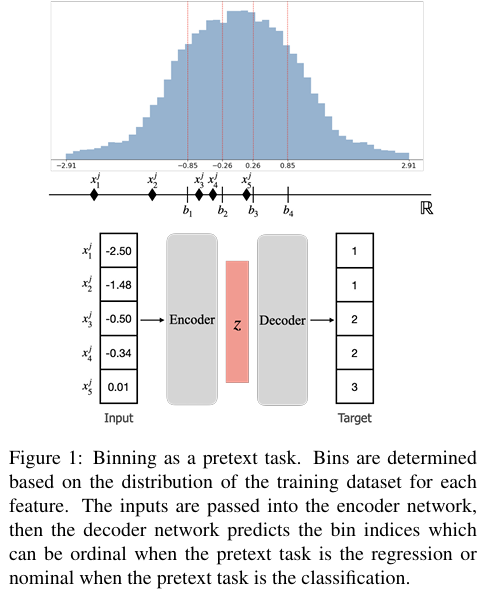
1. 논문 정보
-
분야: Machine Learning, Self-Supervised Learning, Tabular Representation Learning
-
주요 주제: Tabular 데이터에서 효과적인 자기학습(pretext task) 설계
-
핵심 키워드: Self-Supervised Learning, Binning, Quantization, Tabular Data, Representation Learning
-
한 줄 요약:
“이 논문은 tabular 데이터에서 자기학습이 실패해온 원인을 ‘연속값 회귀 복원’이라는 잘못된 문제 정의로 보고, binning을 통해 의미 있는 분류 기반 자기지도 학습 문제로 재정의한 연구이다.”
2. 이 논문이 출발한 질문
이 논문은 단순히 “tabular 데이터에서 SSL 성능을 올리자”가 아니라,
더 근본적인 질문에서 출발한다.
“왜 tabular 데이터에서는 자기학습이 잘 작동하지 않는가?”
이미지나 텍스트에서는 자기학습이 자연스럽다.
가리기(masking), 변형(augmentation), 대조(contrastive) 같은 기법이
의미를 크게 훼손하지 않기 때문이다.
하지만 tabular 데이터는 다르다.
- feature마다 의미가 전혀 다르고
- 공간적·순서적 구조가 없으며
- 값 하나의 변화가 의미 자체를 바꿔버릴 수 있다
이 때문에 기존 SSL 기법을 그대로 적용하면
“무엇을 배워야 하는지 애매한 문제”가 된다.
3. 기존 접근의 핵심 가정과 그 한계
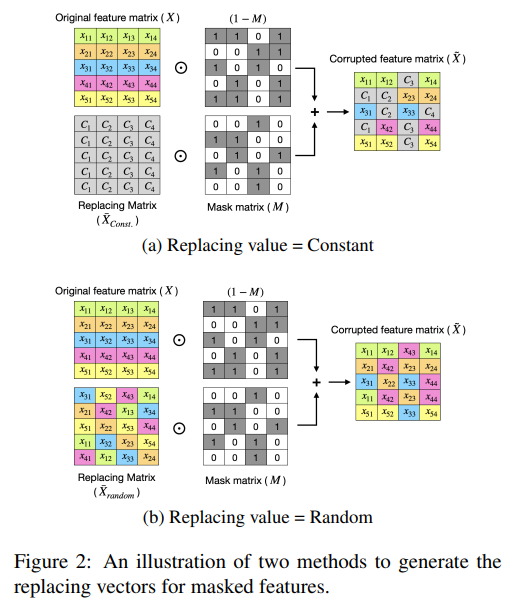
기존 tabular SSL의 전형적인 접근은 다음과 같다.
- 일부 feature를 가리고
- 나머지 feature를 이용해
- 원래의 연속값을 회귀로 복원
이 접근은 암묵적으로 다음을 가정한다.
“연속값을 정확히 복원하는 것이
의미 있는 표현 학습 목표다.”
논문은 이 가정을 정면으로 부정한다.
연속값 회귀는:
- 노이즈에 민감하고
- 의미 없는 미세 차이에 집착하게 만들며
- 구조를 배우기보다 숫자를 복사하게 만든다
즉, 문제가 너무 어렵고 잘못 정의돼 있다는 것이다.
4. 논문의 핵심 아이디어
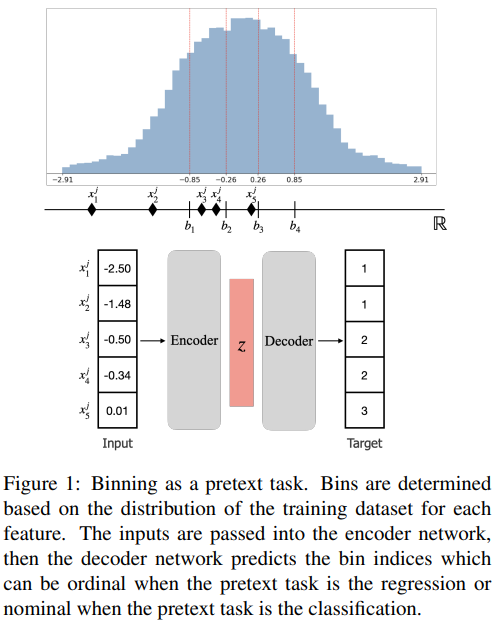
이 논문의 핵심 아이디어는 놀랄 만큼 단순하다.
“연속값을 그대로 맞추지 말고,
binning으로 양자화된 ‘구간’만 맞추게 하자.”
연속 feature를 K개의 bin으로 나누고,
자기학습의 목표를 “정확한 값”이 아니라
“어느 구간에 속하는가”로 바꾼다.
이 순간, 회귀 문제는 분류 문제로 재정의된다.
중요한 점은,
이 binning이 단순한 전처리 트릭이 아니라는 것이다.
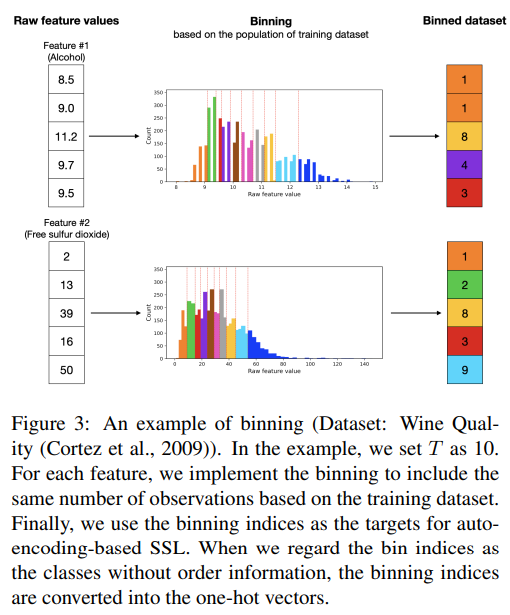
5. binning의 역할: 양자화된 문제 정의와 로스의 의미
binning은 이 논문에서 단순한 데이터 전처리 기법이 아니라,
자기학습에서 무엇을 맞추고 무엇을 무시할지를 정의하는 핵심 장치다.
이는 binning 자체뿐 아니라, 그 위에 얹힌 로스 함수 설계를 통해 완성된다.
1) 노이즈 제거: 미세한 차이를 의미에서 제외
37.1과 37.2의 차이는 대부분의 경우 의미가 없다.
binning은 이러한 미세한 연속값 차이를 같은 구간으로 묶어,
모델이 집착할 필요가 없는 정보를 구조적으로 제거한다.
이는 단순히 입력을 거칠게 만드는 것이 아니라,
어떤 차이는 학습 대상이 아니라는 판단을 사람이 대신 내려주는 것에 가깝다.
2) feature 간 문제의 통일: 값이 아니라 ‘문제 타입’을 맞춘다
스케일과 의미가 제각각인 tabular feature들은
binning 이후 모두 “bin index를 예측하는 분류 문제”로 통일된다.
이는 feature 값을 정규화하는 것과 다르다.
중요한 것은 값의 범위를 맞추는 것이 아니라,
모든 feature를 동일한 형태의 예측 문제로 정의함으로써
모델이 개별 값보다 feature 간 관계와 공동 구조에 집중하도록 만든다는 점이다.
3) 자기학습에 적절한 난이도: 로스가 강제하는 학습 수준
기존 tabular SSL에서 사용되던 연속값 회귀 로스(MSE)는
모델에게 “숫자를 최대한 정확히 복사하라”고 요구한다.
이 경우, 의미 없는 미세 차이까지 동일하게 벌점이 부과되며
모델은 구조를 배우기보다 값 복사에 가까운 행동을 하게 된다.
반면, binning 이후의 로스는 다음과 같이 문제를 재정의한다.
- 회귀(MSE): 너무 어렵고, 의미 없는 차이까지 학습
- 단순 binary 분류: 너무 쉽고, 구조 학습이 제한됨
- bin classification (cross-entropy):
→ “어느 의미 구간에 속하는지만 맞춰라”
즉, 로스 함수는 연속값의 거리 오차를 벌주는 대신,
의미적으로 다른 구간을 혼동했는지 여부만을 벌점으로 삼는다.
이는 자기학습에 필요한 “적당히 거친 목표”를 정확히 구현한 것이다.
4) binning은 ‘불변성(invariance)’을 로스 수준에서 강제한다
binning 기반 로스의 가장 중요한 효과는
같은 bin에 속하는 값 변화에 대해
모델이 의도적으로 무감각해지도록(invariant) 만든다는 점이다.
이는 단순한 노이즈 완화가 아니라,
“이 정도 범위의 변화는 의미가 없다”는 가정을
자기학습의 목표 함수에 직접 주입하는 설계다.
그 결과, 모델이 학습하는 표현 공간에서는
같은 bin에 속한 샘플들이 자연스럽게 가까워지고,
bin 경계를 넘는 샘플들은 명확히 분리된다.
즉, 표현 공간 자체가 binning으로 정의된 의미 구조를 닮게 된다.
5) 로스 함수의 역할: 값을 맞추는 것이 아니라 구조를 맞추게 한다
결국 이 논문에서 로스 함수의 역할은 명확하다.
연속값을 얼마나 정확히 복원했는지를 평가하는 것이 아니라,
binning으로 정의된 의미 단위를 혼동하지 않았는지를 평가한다.
따라서 bin prediction은 그 자체가 목적이 아니라,
feature 간 상관 구조와 잠재적인 데이터 생성 패턴을
학습하기 위한 수단에 불과하다.
이 점에서 binning과 로스 함수는 분리된 요소가 아니라,
함께 ‘배울 수 있는 문제’를 정의하는 하나의 설계로 이해해야 한다.

6. 이 논문이 말하는 ‘자기학습’의 의미
이 논문에서 자기학습은 다음과 같이 구성된다.
-
사람이 하는 일
→ 연속값을 어떤 해상도로 볼 것인지(= binning 규칙)를 정한다 -
데이터가 하는 일
→ 값에 따라 bin index를 자동으로 생성한다 -
모델이 하는 일
→ 다른 feature들을 보고 해당 feature의 bin을 예측한다
즉, 레이블은 사람이 직접 달지 않지만
완전히 규칙적이고 자동으로 생성된다.
이것이 이 논문에서 말하는
“모델이 스스로 레이블을 만든다”의 정확한 의미다.
7. 모델이 실제로 배우는 것
중요한 점은,
모델의 목적은 bin을 잘 맞추는 것 자체가 아니다.
bin을 맞추기 위해 모델은 내부적으로
- feature 간의 상관 구조
- 공통 패턴
- 잠재적인 데이터 생성 구조
를 학습하게 된다.
즉, bin prediction은 목표가 아니라 수단이며,
그 결과로 얻어진 표현이 downstream task에서 유용해진다.
8. 이 논문의 위치와 의의
이 논문은 다음과 같이 평가할 수 있다.
“Tabular 데이터에서 자기학습이 실패해온 이유를
모델의 한계가 아니라 ‘문제 정의의 실패’로 보고,
binning이라는 양자화를 통해
‘배울 수 있는 문제’를 새로 정의한 연구.”
복잡한 모델이나 새로운 네트워크를 제안하기보다,
무엇을 예측하게 할 것인가라는
자기학습의 본질적인 질문으로 돌아갔다는 점에서 의미가 크다.
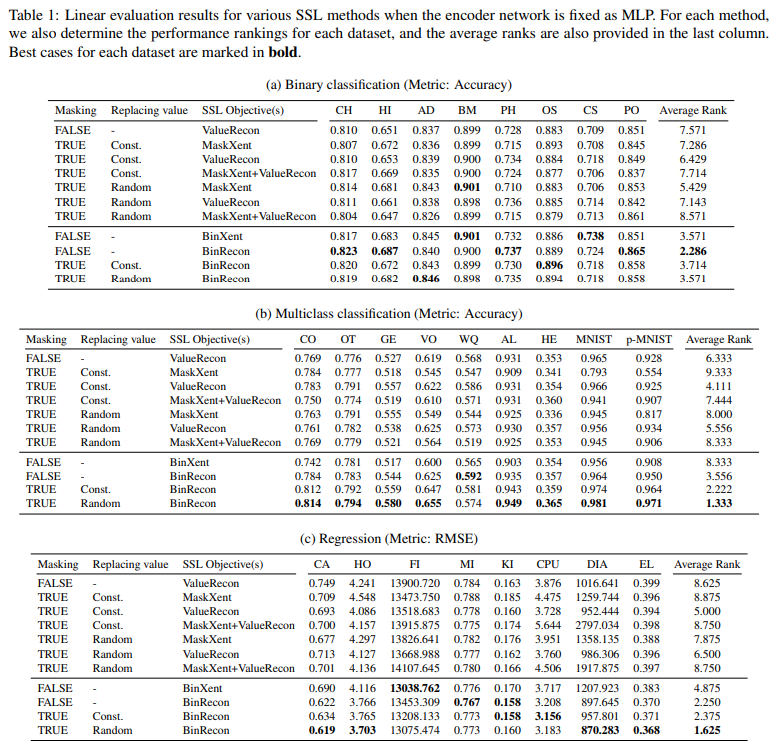
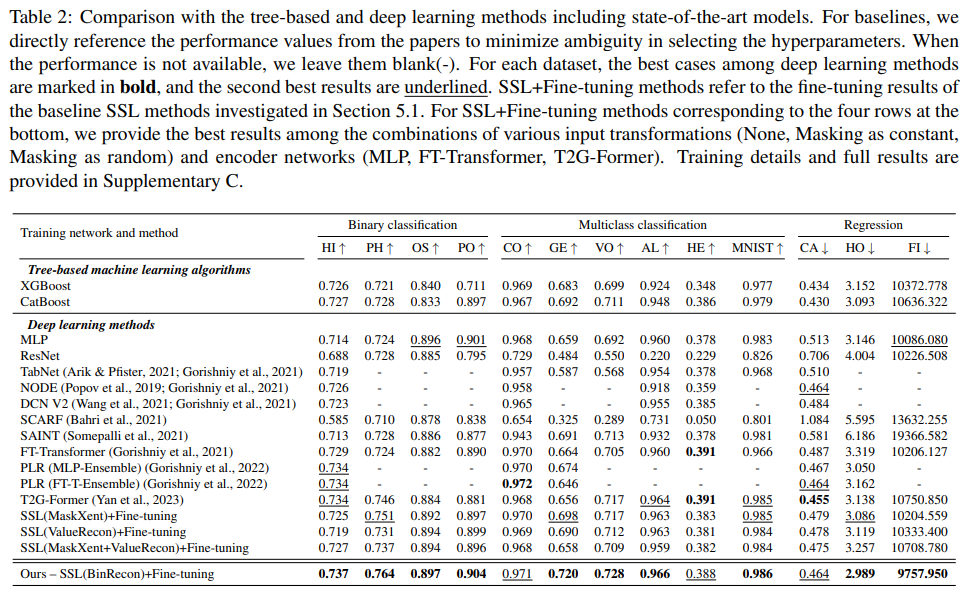
9. 한계와 남는 질문 (통합 버전)
9.1 binning 기반 자기학습의 설계적 한계
binning 기반 자기학습은
연속값 회귀의 불안정성을 해결하는 대신,
의미 해상도를 사람이 직접 선택해야 한다는 전제를 갖는다.
bin 개수 T는 단순한 하이퍼파라미터가 아니라,
“어디까지를 같은 의미로 볼 것인가”를 결정하는 inductive bias에 해당한다.
따라서 T가 데이터의 실제 구조와 맞지 않을 경우,
binning은 오히려 의미를 왜곡할 수 있다.
9.2 실질적인 한계들
-
bin 개수와 binning 방식은 사람이 정해야 한다
-
잘못된 binning은 feature 의미를 왜곡할 수 있다
-
최종 예측 모델이라기보다는 표현 학습용 방법이다
9.3 남는 질문
“어디까지를 같은 의미로 보고,
어디서 끊는 것이 가장 좋은 inductive bias인가?”
10. 한 문장으로 끝내면
“이 논문은 tabular 자기학습의 핵심이
더 정밀한 복원이 아니라,
의미 있는 수준으로 과감히 버리는 데 있음을 보여준다.연속 feature를 사람이 정의한 binning 규칙에 따라 구간으로 나누고,
데이터는 자동으로 bin 레이블을 생성하며,
모델은 다른 feature를 보고 각 feature가 어느 bin에 속하는지 예측하는 방식으로 자기학습이 진행된다.이렇게 학습된 표현은 단순히 bin을 맞추는 것이 아니라,
feature 간 구조적 관계와 의미 있는 패턴을 포착하도록 설계된다.”
