[논문 리뷰] Representation Space Augmentation for Effective Self-Supervised Learning on Tabular Data
논문 리뷰
1. 논문 정보
-
제목: Representation Space Augmentation for Effective Self-Supervised Learning on Tabular Data
(AAAI Conference on Artificial Intelligence 2025) -
학회/연도:
AAAI 2025 (프로시딩스), 2025년 발표 -
내가 정의한 한 줄 요약:
Tabular 데이터의 자기지도 학습(Self-Supervised Learning, SSL)에서 입력 차원이 아닌 ‘표현 공간(Representation Space)’에서 증강(Augmentation) 기법을 설계함으로써 더 효과적인 표현 학습과 downstream 성능 향상을 이끈 연구.
2. 이 논문을 읽게 된 계기
Tabular(정형) 데이터는 이미지나 텍스트보다 구조가 제한적이고 특성(feature) 간 관계가 복잡해 딥러닝 성능이 잘 나오지 않는 영역입니다.
최근 Tabular SSL 연구가 활발해지고 있지만, 적절한 데이터 증강 설계가 어려운 문제가 계속 존재했어요. 이 논문은 그런 한계를 극복하기 위해 증강을 representation space에서 수행하는 독특한 접근을 제안합니다.
3. 처음 읽고 든 인상
처음에는 “Tabular SSL에서 증강이라니, 그게 가능한가?”라는 의문이 들었습니다.
Tabular은 이미지/텍스트처럼 명확한 구조나 spatial invariance가 없기 때문에 전통적인 데이터 증강 연구가 힘들었거든요. 하지만 이 논문은 증강의 대상 자체를 표현 공간으로 옮기는 발상 전환으로 문제를 해결하여 매우 흥미롭게 다가왔습니다.
4. 전체 구조 및 아키텍처 요약
이 연구의 핵심 설계는 “입력을 증강하는 대신, 표현을 만들어내는 함수 자체를 증강한다”는 관점에서 출발합니다.
🔹 문제 정의
Tabular 데이터에서 Self-Supervised Learning(SSL)을 적용하려면
같은 샘플에 대해 여러 의미적으로 일관된 뷰(view)를 생성하는 것이 중요합니다.
하지만 이미지나 텍스트와 달리, Tabular 데이터는 입력 수준에서 의미 있는 증강을 만들기 어렵습니다.
- 개별 feature를 변형하면 전체 구조가 쉽게 깨지고
- feature 간 상호작용이 왜곡되기 쉬움
이로 인해 기존의 input-level augmentation 기반 SSL은
Tabular 도메인에서 불안정하거나 효과가 제한적인 경우가 많았습니다.
🔹 핵심 아이디어: RaTab
논문은 RaTab (Representation Space Augmentation for Tabular Data)을 제안합니다.
RaTab의 핵심은 다음과 같습니다.
입력 데이터를 여러 번 변형하지 않고,
하나의 입력을 서로 다른 encoder view에 통과시켜
여러 개의 representation을 생성한다.
이를 위해 RaTab은
입력 공간이 아닌 표현 공간(representation space),
정확히는 인코더의 마지막 MLP 레이어의 가중치 행렬을 변형합니다.
🔹 전체 파이프라인을 말로 정리하면
-
입력 tabular 데이터 (x)는 고정
-
Encoder는 동일하지만,
- 마지막 MLP 레이어의 가중치를 Truncated SVD로 변형한
- 여러 개의 encoder view를 생성
-
같은 (x)를 서로 다른 encoder view에 통과시켜
- 서로 다른 representation을 획득
-
이 representation들을 이용해
- Contrastive Learning
- Reconstruction 기반 SSL 학습 수행
👉 즉, “데이터를 바꾸는 증강”이 아니라
“표현을 만들어내는 경로를 바꾸는 증강”이라는 점이 RaTab의 구조적 차별점입니다.
5. 주요 구성 요소 상세 설명
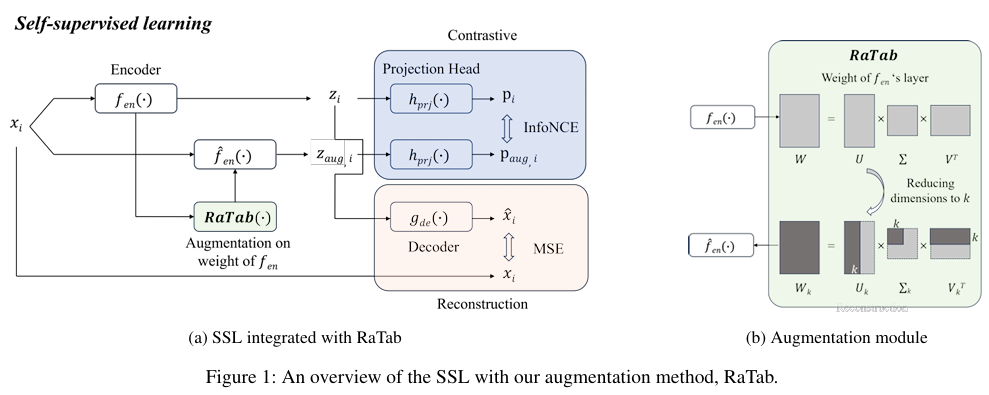



🔹 Representation Space Augmentation (RaTab)
기존 Tabular SSL 방법들은 입력 공간에서 feature masking, noise injection 등을 사용해 왔지만,
이 과정에서 데이터의 핵심 구조나 feature interaction이 훼손될 위험이 컸습니다.
RaTab은 이러한 한계를 피하기 위해
encoder의 마지막 MLP 레이어 가중치 행렬 자체를 증강 대상으로 선택합니다.
이 방식의 장점은:
- 입력 데이터의 의미적 구조는 그대로 유지하면서
- 표현 공간에서만 다양한 변형을 생성할 수 있다는 점입니다.
🔹 Truncated SVD 기반 가중치 변형
RaTab은 인코더의 마지막 레이어 가중치 행렬 (W)에 대해
다음과 같이 SVD를 적용합니다.
[
W = U \Sigma V^{T}
]
여기서:
- (U): left singular vectors
- (\Sigma): singular values (중요 정보의 크기)
- (V^{T}): right singular vectors
이후 상위 (k)개의 특이값만 유지하는 Truncated SVD를 적용합니다.
[
W_k = U_k \Sigma_k V_k^{T}
]
- (k)는 전체 랭크 대비 일정 비율(예: 50%, 60%, 70%)로 설정되는 하이퍼파라미터
- (\Sigma_k)는 학습된 representation의 core information을 담고 있음
이렇게 얻은 (Wk)를 사용한 인코더를
(\hat{f}{enc})로 정의하고, 다음과 같이 증강 표현을 생성합니다.
[
z{aug} = \hat{f}{enc}(x)
]
핵심은 특이값 행렬 (\Sigma_k)를 유지한다는 점입니다.
이는 단순한 정보 제거가 아니라,
저차원 근사(low-rank approximation)를 통해 표현의 핵심 구조를 보존하면서 변형을 만드는 과정으로 이해할 수 있습니다.
🔹 Dropout을 통한 표현 다양성 확보
Truncated SVD만 적용할 경우, 표현은 안정적이지만 다양성이 제한될 수 있습니다.
이를 보완하기 위해 RaTab은 Dropout을 추가적으로 적용합니다.
- Truncated SVD: 표현의 “뼈대(core structure)” 유지
- Dropout: 그 위에 미세한 변형을 추가
이를 통해:
- 다양한 representation view 생성
- 특정 패턴에 대한 과적합 방지
- Contrastive Learning 학습 안정성 향상
결과적으로 RaTab은
정보 손실은 최소화하면서도, 충분한 증강 효과를 갖는 표현 공간 증강을 구현합니다.
🔹 Loss 설계
RaTab은 두 가지 목적 함수를 함께 사용합니다.
-
Contrastive Loss
- 같은 샘플에서 나온 서로 다른 representation view는 가깝게
- 다른 샘플 간 representation은 멀어지도록 학습
-
Reconstruction Loss
- Encoder–Decoder 구조를 통해
- 표현이 원본 입력 정보를 유지하도록 유도
이 두 손실을 결합함으로써
표현의 다양성과 정보 보존이라는 두 목표를 동시에 달성합니다.
한 줄 정리
RaTab은 입력을 증강하지 않는다.
대신, 표현을 만들어내는 encoder를 여러 관점으로 변형해
같은 입력을 서로 다른 방식으로 임베딩함으로써
의미적으로 일관된 다양한 representation을 학습한다.
6. 핵심 아이디어
Tabular SSL 증강은 “raw 입력 수준”이 아니라 “표현 공간 수준”에서 작동해야 잘 작동한다.
즉, 데이터 자체를 변형하는 대신, 이미 학습된 feature representation을 변형하여 다양한 뷰를 만드는 것이 핵심입니다.
이는 Tabular이 가진:
- 불균형/비선형 구조
- feature 간 상호작용
- 서로 다른 스케일의 값
같은 특성들에 더 잘 대응할 수 있게 합니다.
7. 기존 방법과의 비교에 대한 개인적인 생각
Tabular SSL에서 전통적으로 쓰인 방법들은 대체로:
- Input-level masking
- Feature corruption
- Random shuffling
같은 방식입니다. 하지만 이런 입력 수준 증강은 실제 의미 있는 학습 신호를 만들기 어렵고 noise만 증가시키는 경우가 많았습니다.
반면 RaTab은 표현 공간을 직접 조작하기 때문에,
- 실제 클래스를 유지하면서
- 다양한 뷰 생성
→ downstream(후속) 과제 성능 향상에 훨씬 유리하게 작동합니다.
8. 실험 결과에 대한 해석
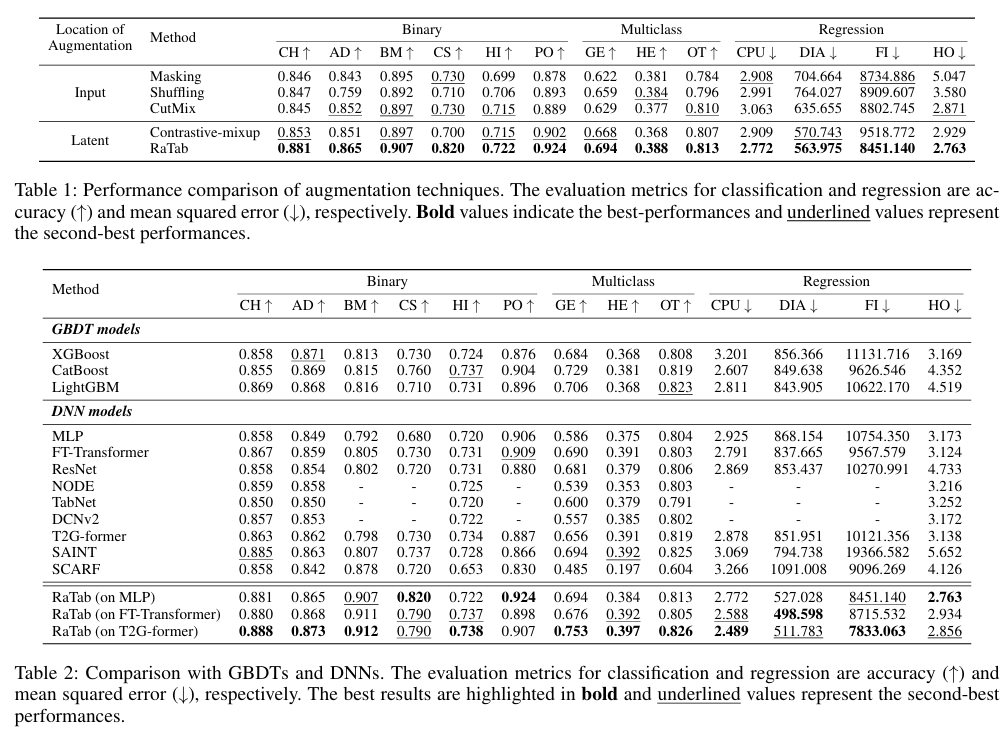
논문 실험은 여러 개의 Tabular 데이터셋(분류/회귀)에서 이루어졌습니다.
핵심 관찰
- RaTab 기반 증강은 기존 Input-level 증강보다 대체로 뛰어난 대표성(representation) 학습 성능을 보여줌
- 다양한 backbone 모델(MLP, Transformer계열)에서도 일관된 성능 향상
- 부가적인 전처리/튜닝 없이도 대부분의 Tabular downstream task에서 경쟁력 확보
즉, 표현 공간 증강이 표준적인 SSL pipeline을 개선하는 데 효과적이라는 실험적 근거가 제시됩니다.
9. 한계 및 아쉬운 점
- SVD 기반 증강은 계산 비용이 있을 수 있음
→ 특히 표현 차원이 매우 큰 경우 - Tabular에 대한 일반성 보장
→ 다양한 feature distribution에 대한 일반화는 여전히 추가 연구 필요 - 표현 공간 증강 설계의 민감도
→ Truncated SVD rank 설정 등 하이퍼파라미터가 민감할 수 있음
10. 개인적인 결론
이 논문은 Tabular SSL의 핵심 장벽인 “증강 기법 설계” 문제를 표현 공간 레벨에서 풀어낸 매우 독창적인 연구입니다.
기존 Tabular 학습에서 흔히 Input-level augmentation이 잘 작동하지 않았던 한계를 직관적이고 체계적으로 극복하고 있으며,
향후 Tabular SSL 및 Foundation Model 수준의 Tabular representation research에 중요한 참고점이 될 수 있다고 봅니다.
11. 이어서 보면 좋은 키워드 / 연구 분야
- Tabular SSL (Self-Supervised Learning)
- Representation-level augmentation 전략
- Contrastive learning + Reconstruction hybrid objective
- Truncated SVD 기반 표현 변화
- Feature interaction 기반 representation learning
