논문링크 : DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
주요 요약:
- DeepSeek-R1-Zero은 DeepSeek-V3에 large-scale reinforcement learning(RL)를 적용하여 학습된 모델이다.
- DeepSeek-R1은 RL을 적용하기 전에, cold-start data를 학습 과정에 추가해서 얻는 모델이다.
cold-start data는 초기에 모델이 갈피를 잘 잡을 수 있게 도와주는 데이터다.
1. 선택하게 된 이유
: DeepSeek이 얼마나 대단하길래 그렇게 언급하는지 궁금했습니다.
2. 서론
- openAI's o1 시리즈 모델들은 Chain-of-Thought (CoT) reasoning 과정의 길이를 늘려서 추론 시간 스케일링 (inference-time scaling)을 처음으로 도입했다.
Chain-of-Thought는 문제 해결이나 추론을 수행할 때, 단계별로 사고 과정을 명확하게 나타내는 방법입니다. 이 접근 방식은 복잡한 문제를 해결하기 위해 여러 단계의 논리를 연결하여, 각 단계에서의 생각을 체계적으로 표현합니다. - 하지만, 효과적인 test-time scaling 문제는 여전히 해결되지 않았다.
- 그래서, process-based reward models와 reinforcement learning, search algorithms(Monte Carlo Tree Search, Beam Search, etc)를 도입해봤지만, openAI's o1 시리즈 모델만큼의 성능이 나오지 않는다.
inference-time scaling은 모델이 실제로 데이터를 처리하고 예측하는(inference-time) 동안 성능을 개선하기 위한 기법입니다.
test-time scaling은 모델이 테스트 데이터에 대해 성능을 조정하거나 개선하기 위한 방법입니다.
- 이 논문에서는 supervised data 없이 순수한 reinforcement learning (RL)을 사용한 self-evolution에 집중했다.
- 이전에 소개한 DeepSeek-V3를 base-model로 사용하고, GRPO RL framework를 사용했다.
- 이를 통해서, DeepSeek-R1-Zero를 얻게 된다. (DeepSeek-R1-Zero = DeepSeek-V3 + GRPO)
- 하지만, DeepSeek-R1-Zero는 poor readability와 language mixing 문제가 있다.
- 이를 해결하기 위해서 cold-start data를 추가했다.
- 이를 해결하여 얻은 모델이 DeepSeek-R1이다.
- DeepSeek-R1을 얻기 위한 파이프라인은 다음과 같다.
- cold-start data로 fine-tuning
- RL
- RL에서 얻은 체크포인트로 rejection sampling을 통해 새로운 SFT(supervised fine-tuning) 데이터를 만든다.
- 이를, 기존 DeepSeek-V3의 supervised data와 결합하여 모델을 추가로 학습한다.
- 추가적으로, DeepSeek-R1을 small model에 적용하는 Distillation도 진행하였고, RL까지 적용하니 좋은 성능을 냈다.
- larger base models(like DeepSeek-R1)을 통해서 reasoning patterns을 찾는 것이 중요하다는 것을 확인했다.
- base model에 RL만 적용하니, 복잡한 문제를 풀기 위한 chain-of-thought (CoT)를 모델이 찾을 수 있었다.
- 이는, LLM의 reasoning 능력이 순수하게 강화 학습(RL)을 통해 효과가 있다는 것을 검증한 첫 연구였다.
- DeepSeek-R1의 파이프라인은 two RL stages와 two SFT stages를 합친 것이다.
- 여기서 RL stages는 향상된 reasoning 패턴을 찾는 것과 human preferences에 맞추는 것에 집중하고, SFT stages는 모델의 reasoning하고 non-reasoning한 능력의 기반을 제시한다.
- 작은 모델에 RL한 것보다 큰 모델로부터 distill 받은 작은 모델이 성능이 더 좋다.
- DeepSeek-R1으로 만든 reasoning data로 dense models에 fine-tuning을 진행하니 좋은 성능을 얻었다.
3. 방법론(a) : DeepSeek-R1-Zero : Reinforcement Learning on the Base Model
- supervised data 없이 순수한 강화학습을 통한 self-evolution에 집중했다.
3-1. Reinforcement Learning Algorithm
- GRPO RL framework를 사용했다.
- 각 질문 에 대해서, GRPO는 이전 정책 에서 outputs 집단 를 샘플링하고, 다음 식을 최대화하는 쪽으로 정책 model 를 최적화한다.
쉽게 말해, GRPO는 정책을 update방식으로 작동한다.Equation 1
Equation 2
와 는 하이퍼파라미터이고, 는 reward들로 계산한 advantage이다.Equation 3
A는 보상들을 정규분포화 시켰다.
3-2. Reward Modeling
-
rule-based reward system을 적용해서 DeepSeek-R1-Zero를 학습했다.
-
rule-based reward system의 다음 2가지로 이루어져 있다.
- Accuracy rewards
Accuracy rewards은 문제에 맞는 형식에 맞게 response가 정확한지를 평가한다.
- Format rewards
Format rewards은 사이의 thinking 과정을 넣는 형식을 모델에 강요하는 역할을 한다.
- Accuracy rewards
-
추가적으로, neural reward model은 reward 해킹과 재학습의 어려움으로 적용하지 않았다.
3-3. Training Template

- 특정 명령을 적용하기 위해 학습 template을 만들었다.
- 그리고, Content-specific bias를 피하기 위해 (Table 1)과 같은 형식으로 제한했다.
3-4. Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
3-4-a. Performance of DeepSeek-R1-Zero
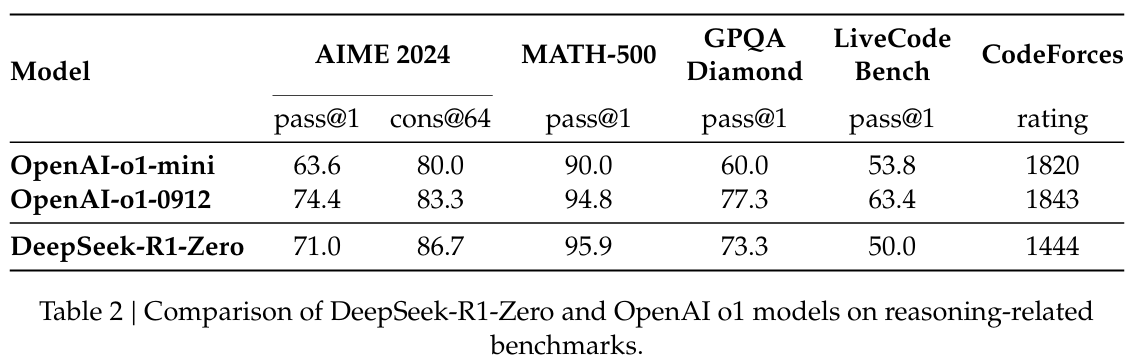
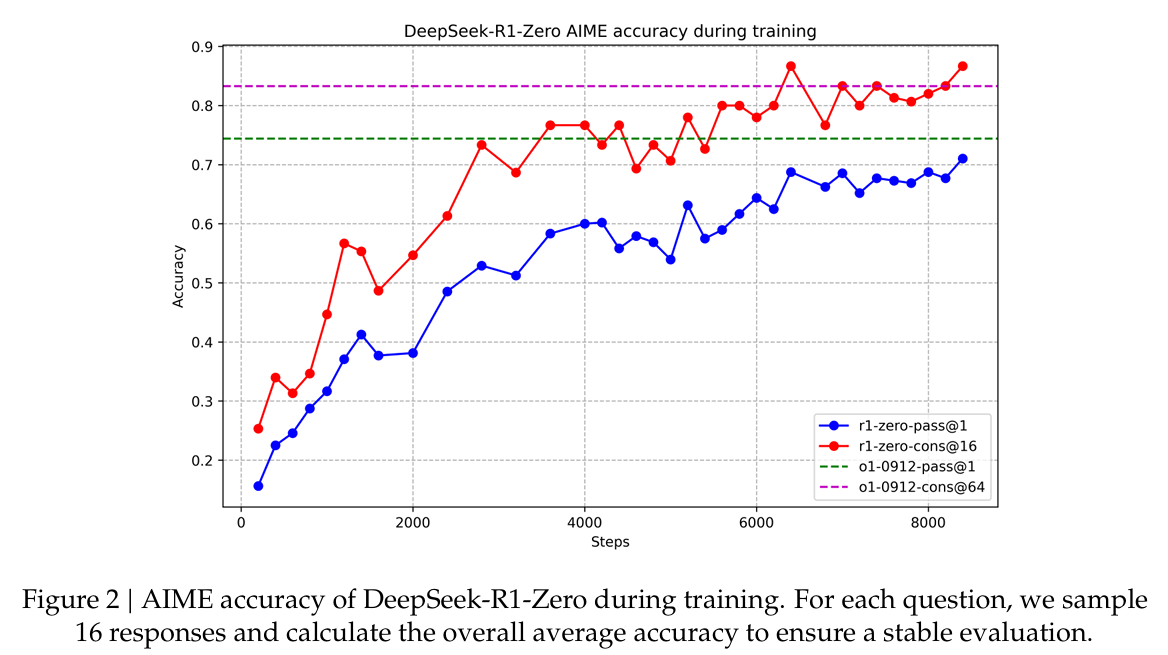
3-4-b. Self-evolution Process of DeepSeek-R1-Zero
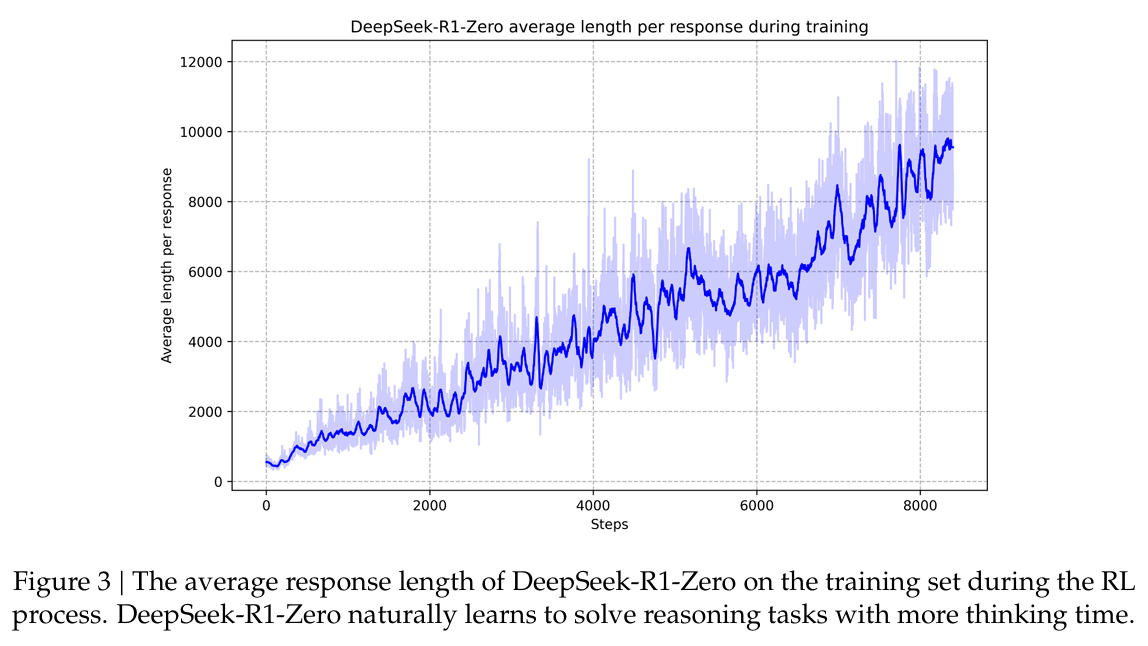
- self- evolution 과정은 어떻게 RL이 자동적으로 resoning 능력을 높이는 지를 나타낸다.
- (Figure 3)와 같이, 학습 중 thinking time(Average length per response을 말하는 것 같다.)이 일관된 향상을 보였다.
- 이러한 향상은 외부 조정의 결과가 아니라, 모델 내부에서의 발전이다.
- DeepSeek-R1-Zero은 긴 test-time computation을 활용해서, 자연스레(자동적으로) 복잡한 문제 해결 능력을 얻었다.
- 왜냐하면, 이 computation은 수백수천 reasoning 토큰을 생성하는 것에서 시작하여, 모델이 모델의 생각 과정을 깊게 생각하고 수정할 수 있도록 한다.
- self-evolution의 두드러진 점은 정교한 행동들(response)이 등장한다는 것이다.
행동들의 예시로는, 이전 과정을 다시 확인하거나 다시 평가하는 것과 문제를 풀기 위한 대안적인 접근을 시도한다는 것이 있다. - 이러한 행동은 RL 과정에서 모델의 상호작용의 결과이다.
3-4-c. Aha Moment of DeepSeek-R1-Zero

- (Table 3)에서 알 수 있듯이, 'aha moment'은 모델의 중간 버전에서 발생한다.
- 이 단계에서 DeepSeek-R1-Zero는 처음 접근을 재평가하므로써 더 많은 thinking time을 문제에 할당하는 것을 학습한다.
- 이러한 행동은 모델의 향상되는 reasoning 능력에 대한 증거(testment)이자, 어떻게 RL이 예상치 못하고 정교한 결과를 낼 수 있는지를 나타낸다.
- 이를 통해, RL의 강점을 확인할 수 있다.
- RL은 모델에 문제를 어떻게 푸는지에 대한 외적인 teaching을 하기보다, 단순히 옳바른 인센티브와 함께 문제를 제공하고, 자동적으로 문제해결전략을 발전시키도록 한다.
3-4-d. Drawback of DeepSeek-R1-Zero
- 하지만, DeepSeek-R1-Zero에는 아직 poor readability(가독성 저하)와 language mixing(언어 혼합) 문제가 존재하므로, DeepSeek-R1에서는 human-friendly한 cold-start data와 함께 RL를 적용하도록 했다.
4. 방법론(b) : DeepSeek-R1 : Reinforcement Learning with Cold Start
- DeepSeek-R1-Zero부터 2가지 의문을 가지게 됐다.
- 소량의 고품질 데이터(cold start data)를 포함시킴으로써 reasoning performance(추론 능력)이 향상되거나 수렴이 가속화될 수 있는가?
- 깨끗하고 일관된 CoT(Chains of Thought)를 만들어 내고 강한 일반화 능력을 나타내는, 사용자 친화적 모델을 어떻게 학습할 수 있는가?
4-1. Cold Start
-
base model로부터 early unstable cold start RL 학습단계를 막은 DeepSeek-R1-Zero와 달리, DeepSeek-R1은 RL 초반에 fine-tuning을 위해 소량의 long CoT data을 모으고 구축했다.
-
이 데이터를 다음과 같은 방식으로 모았다.
- example로 long CoT와 함께 few-shot prompting을 사용했다.
- reflection과 verification와 함께 정교한 답을 만들기 위해 직접적으로 모델을 prompting했다.
- readable format에서 DeepSeek-R1-Zero 결과들을 모았다.
- human annotator로부터 후처리해서 결과를 개선했다.
-
DeepSeek-R1-Zero와 달리, DeepSeek-R1을 위한 cold-start data를 만들 때, 각 응답 마지막에 summary를 포함하고 가독성이 떨어지는 응답은 거르는 readable pattern을 만들었다.
-
'|special_token| <reasoning_process> |special_token|
'와 같은 output format을 정의했다. -
여기서, reasoning_process는 질문에 대한 CoT이고, summary는 추론 결과를 요약한 것이다.
4-2. Reasoning-oriented Reinforcement Learning
- DeepSeek-V3-Base에 cold start data로 fine-tuning을 한 후, large-scale RL 학습과정을 적용했다.
- 학습 과정 중, 특히 RL prompts가 다양한 언어를 포함할 때, CoT에 종종 다양한 언어가 섞인 채로 나타는 것을 확인했다.
- 이를 해결하기 위해, language consistency reward를 적용했다.
- 이 reward는 CoT에서 target language의 단어들의 비율을 계산한다.
- 비교 실험 결과 human preference에 맞추는 것이 모델의 성능을 약간 저하시키지만, 더 높은 가독성을 제공한다.
- 최종 reward를 만들기 위해, reasoning tasks의 정확도와 language consistency의 reward를 더한다.
- 그리고 RL 학습과정을 reasoning tasks에 수렴할 때까지 적용한다.
4-3. Rejection Sampling and Supervised Fine-Tuning
- reasoning-oriented RL이 수렴할 때, 다음 단계를 위해 SFT 데이터를 모으는 resulting checkpoint를 사용했다.
- 초기 cold-start data와 달리, 이 단계에서는 모델의 능력을 높이기 위해 다른 domains으로부터의 데이터를 포함한다.
- 특히, 다음 내용들과 같이, data를 만들고 모델에 fine-tuning을 진행했다.
Rejection sampling은 원하는 분포에서 샘플을 생성하기 어려운 경우, 대체 분포에서 샘플을 생성하고 이 중 특정 기준을 만족하는 샘플만 선택하는 방식이다.
4-3-a. Reasoning data
- RL 과정에서 체크포인트를 사용하여 rejection sampling을 수행함으로써 얻은 reasoning 데이터로 reasoning prompts를 선별하고 reasoning trajectories(경로)를 생성한다.
이 문장은 reasoning data의 중요성에 대해 언급하기 위한 문장이라고 합니다. 이 문장에 왜 들어왔는지는 정확하게 인지하지는 못했습니다. - 이전 단계에서는 rule-based rewards를 통해 평가 가능한 데이터만 포함했다.
- 하지만, 이 단계에서는 ground-truth와 model predictions를 DeepSeek-V3에 판단을 위해 제공함으로써 generative reward model을 사용하는 데이터를 추가했다.
- 추가적으로, 모델의 결과가 종종 읽기 복잡하고 어렵기 때문에, mixed languages, long paragraphs, code blocks와 같은 CoT는 제거했다.
- 위와 같은 방법으로, 각 prompt에 대해서 다양한 response를 샘플링하고 오직 옳은 하나만 유지시켰다.
4-3-b. Non-Reasoning data
- writing, factual QA, self-cognition, translation와 같은 Non-Reasoning data에 대해서는, DeepSeek-V3 파이프라인을 채택하고 DeepSeek-V3의 SFT 데이터 셋의 일부를 재사용했다.
- 특정 Non-Reasoning data에 대해서는 DeepSeek-V3가 대신 CoT를 생성하도록 했다.
- 하지만, 'hello'와 같은 간단한 query들에 대해서는 response에 CoT를 제공하지 않았다.
- 이렇게 얻은 Reasoning data의 600k samples와 Non-Reasoning data의 200k samples로 DeepSeek-V3-Base를 2 epochs동안 fine-tuning한다.
4-4. Reinforcement Learning for all Scenarios
- human preference에 모델을 맞추기 위해, 모델의 helpfulness와 harmlessness를 높이는데 집중하는 부수적인 RL stage을 적용했다.
- 특히, reward signals와 다양한 prompt 분포들의 조합을 사용해서 모델을 학습했다.
- reasoning data에서는, DeepSeek-R1-Zero의 방식을 유지했다.
- general data에서는, 복잡하고 미묘한 scenarios에서 human preference를 갖추기 위해 reward models을 다음과 같이 수정했다.
- DeepSeek-V3 파이프라인을 기반으로 preference pairs와 training prompts의 유사한 분포를 채택하는 식으로 수정했다.
- helpfulness를 위해서는, final summary에 초점을 맞췄다.
- 이 summary는 reasoning 과정에 대한 간섭을 최소화하면서, response의 유용성과 관련성이 있는지를 강화학습의 평과 과정에서 중요하게 볼 수 있게 한다.
- harmlessness를 위해서는, reasoning process와 summary를 포함한 모델의 모든 응답을 평가했다.
- 왜냐하면, 응답 생성 과정에서 발생 가능한 모든 잠재적 risks나 편향들, 해로운 content을 식별하고 완화하기 위해서이다.
5. 방법론(c) : Distillation : Empower Small Models with Reasoning Capability
- DeepSeek-R1을 통해 얻은 샘플들로 Qwen 모델과 Llama 모델을 fine-tuning했다.
- 그 결과, reasoning abilities가 향상되는 것을 확인했다.
- Distilled model에는 SFT만 적용하고, RL stage를 포함하지 않았다.
- 왜냐하면, 여기서의 우선적인 목표가 distillation 기술의 효과적임을 파악하는 것이기 때문에, RL stage 개입을 막았다.
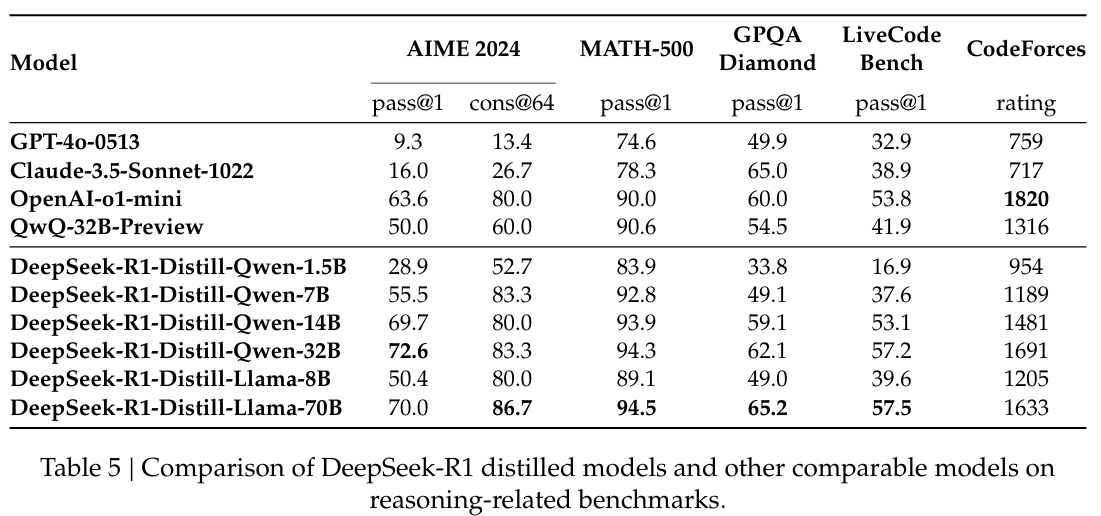
6. 주요 결과
-
최대 generation length을 32,768 토큰으로 정했다.
-
long-output reasoning models을 평가하기 위해 greedy decoding을 사용하면 높은 repetition rates과 상당한 variability을 얻을 수 있다.
-
기본적으로 pass@k evaluation을 사용하고 non-zero temperature를 사용해서 pass@1 결과를 낼 것이다.
pass@1 =
는 번째 응답의 정확성을 말한다. -
64 samples를 사용한 consensus 결과에 대해서는 cons@64를 결과를 낼 것이다.
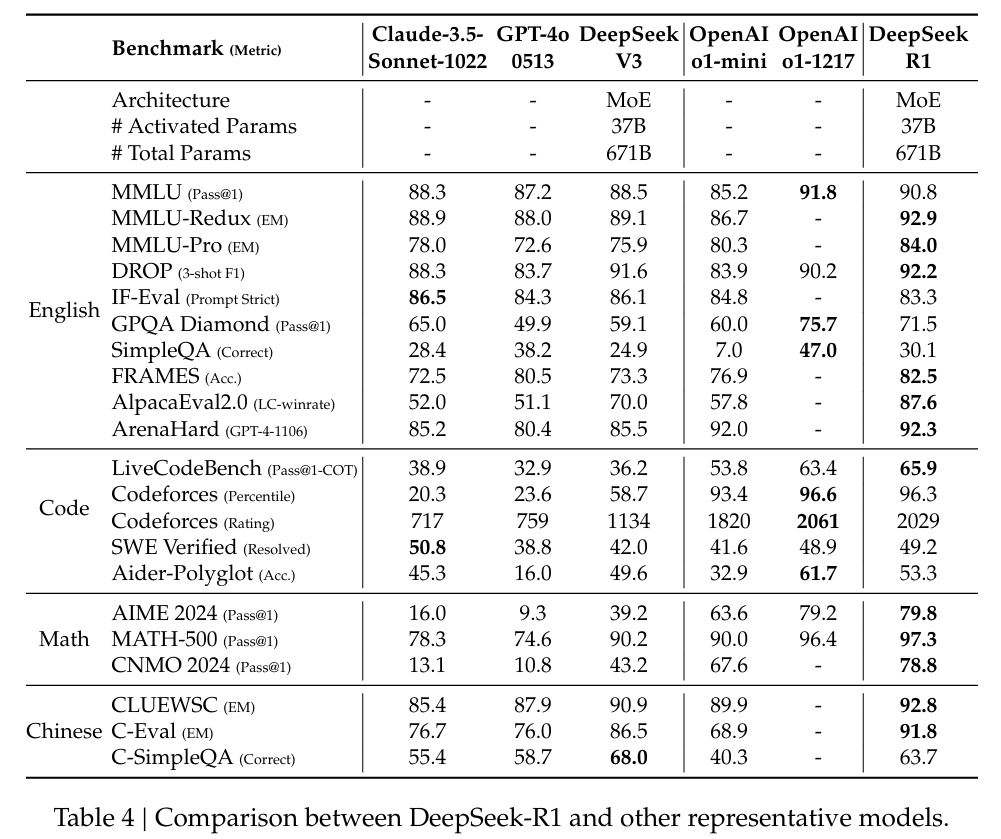
- DeepSeek-V3의 성능은 large-scale RL의 일반화 이점을 강조한다.
- 이는, reasoning capabilities(추론 능력)을 향상시키고, 다양한 domains(분야)에서 성능을 높인다.
- 그리고, DeepSeek-R1에 의해 생성된 summary lengths은 간결하다.
- 이는, DeepSeek-R1가 introducing length bias를 피하고 여러 작업에서 robustness가 있다는 것을 의미한다.
7. Discussion
7-1. Distillation v.s. Reinforcement Learning
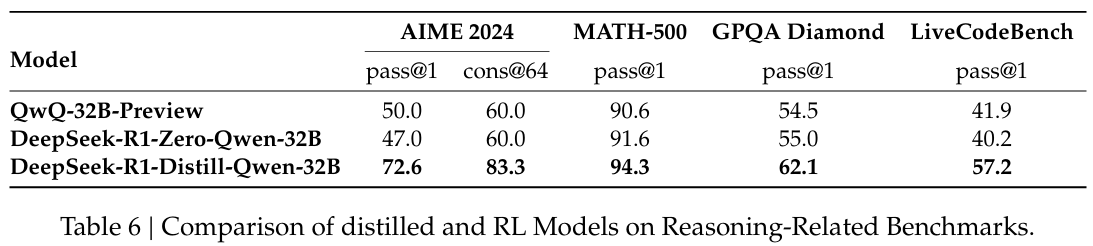
- distillation을 통해 small model이 높은 성능을 얻는 것을 확인했다.
- distillation 없이 large-scale RL 학습을 통해서 small model이 경쟁력 있는 성능을 얻을 수 있는가? 의 의문이 남는다.
- (Table 6)을 통해서 2가지 결론을 얻을 수 있다.
- 더 좋은 모델을 distilling할수록 더 좋은 결과를 얻을 수 있고, large-scale RL에 의존하는 small model은 상당한 computational power가 필요하고 distillation만큼의 성능을 얻지는 못한다.
- distillation 전략은 경제적이고 효율적이지만, 높은 지능을 얻기 위해서는 더 좋은 base model과 large-scale RL이 필요하다.
7-2. Unsuccessful Attempts
- 실험 중 2가지 실패한 실험이 있었다.
- Process Reward Model (PRM)은 상위 N개의 응답을 재정렬하거나 유도 검색을 지원하는 이점이 있지만, 3가지 단점의 비용이 더 크기 때문에 실패했다.
- 3가지 단점은 다음과 같다.
- 일반적인 추론(general reasoning)에서 세부 단계를 명확하게 정의하기가 어렵다.
- 현재 진행 중인 단계의 정확성을 판단하는 것이 어렵다.
- PRM 기반의 모델이 공개되면, reward hacking에 취약하고, reward model을 retraining하는 과정에서 추가 resource가 필요하고, 이는 전체 훈련 파이프라인을 복잡하게 만드는 문제가 있다.
Process Reward Model은 특정 프로세스나 행동의 결과로 얻어지는 보상을 모델링하는 방법입니다. 이 모델은 에이전트가 환경과 상호작용하면서 받는 보상을 예측하고 최적의 행동을 선택하는 데 도움을 줍니다.
- Monte Carlo Tree Search (MCTS)을 사용하면, test-time compute scalability를 향상시킬 수 있지만, 2가지 단점 때문에, 사용하지 못했다.
- 2가지 단점은 다음과 같다.
- 체스와 달리, token generation의 search space가 상당히 크다. 이를 한계를 제한하여 표현할 수 있지만, 이는 local optima로 갈 수 있다.
- value model은 search 과정에서의 각 step을 이끌기 때문에, generation quality에 영향을 미친다. 하지만, 세부적인(fine-grained) value model를 훈련하는 것은 본질적으로 어렵다.
Monte Carlo Tree Search (MCTS)는 결정적이지 않은 게임이나 복잡한 의사결정 문제에서 최적의 행동을 찾기 위해 사용하는 알고리즘입니다
value model은 특정 상태에서 예상되는 보상을 평가하여 어떤 경로가 더 유망한지를 판단하게 합니다. 이로 인해, 검색 과정에서 어떤 노드를 탐색할지를 선택하는 데 도움을 주며, 최적의 결정을 내리기 위한 방향성을 제공합니다.
8. Comment
: 이슈화된 것에 비해서 전반적으로 RL의 장점과 cold-start data와 같은 세부 조정으로 인한 성능 향상하는 부분이라 아쉬웠습니다.(물론, DeepSeek-R1의 장점은 비용대비 성능이라고 합니다.) 그래도, RL의 장점에 대해서 다시 한번 생각하게 되었고, 관심이 가게 되었습니다.
더 자세한 내용은 논문 원본을 참고하시기 바랍니다.
개인의 주관이 반영된 해석이라 논문의 의도와 다를 수 있습니다.
오류가 있다면 댓글로 알려주시면 감사하겠습니다!