논문링크 : Dual-Channel Deepfake Audio Detection : Leveraging Direct and Reverberant Waveforms
주요 요약
: 환경 요인이 반영된 Dual-channel을 사용해서 DeepFake Audio를 더 잘 구분할 수 있다.
1. 선택하게 된 이유
: 가장 친한 친구가 처음 학회에 올린 논문이어서 선택하게 됐습니다.
2. 서론
- voice 기술이 많이 발전함에 따라 deepfake와 같은 잘못된 사용으로 이어지는 경우가 발생한다.
- 그래서 CNN 구조들을 활용하여 image와 audio의 특징을 잡아내는 많은 deepfake detection이 많이 연구되고 있다.
- 하지만, 최근 기술들은 video 데이터에서 입술의 움직임(영상)과 소리 사이의 차이점들을 정확히 찾아내는 것에 애 먹고 있다.
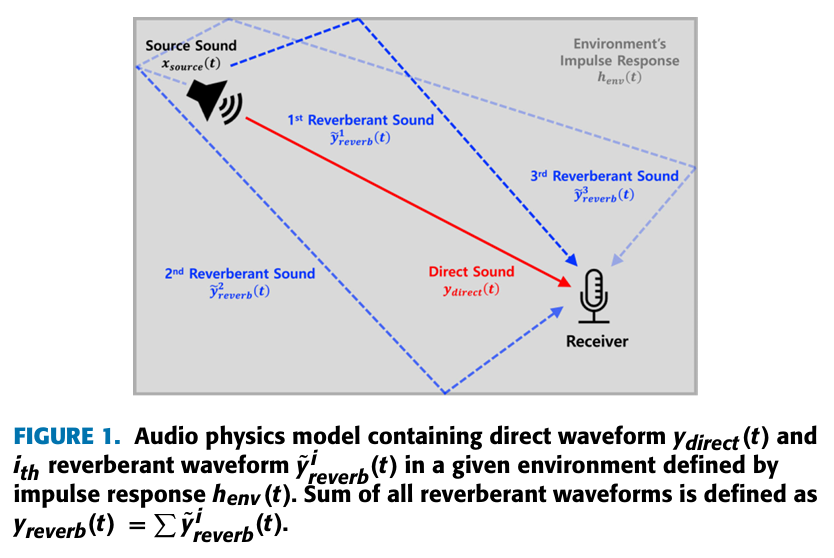
- Deepfake audio는 전형적으로 텍스트를 speech로 바꾸는 형태로 만들어지는데, 이러한 접근은 audio가 만들어지는 물리적 환경에 대해서는 고려하지 않는다는 것이다.
- 그리고, 이전의 Deepfake detection 모델들도 (Figure 1)과 같은 audio가 만들어지는 물리적 환경에 대해서 고려하지 않았다. (single-channel data를 사용했다.)
- (Figure 1)과 같이, 주변 환경에 영향을 받는 direct sounds와 reverberant sounds의 특징을 기반으로, dual-channel deepfake audio detection 방법을 제시한다.
- 이 논문에서는 다음 3가지에 대해서 제시할 예정이다.
- dual channels을 활용한 deepfake audio detection 방법
- 향상된 새로운 SPC(Sports Press Conferencee) dataset
- 효과적인 deepfake detection을 위한 최적의 audio 길이
모델과 데이터셋에 대한 사전 지식 부분은 pass했다.
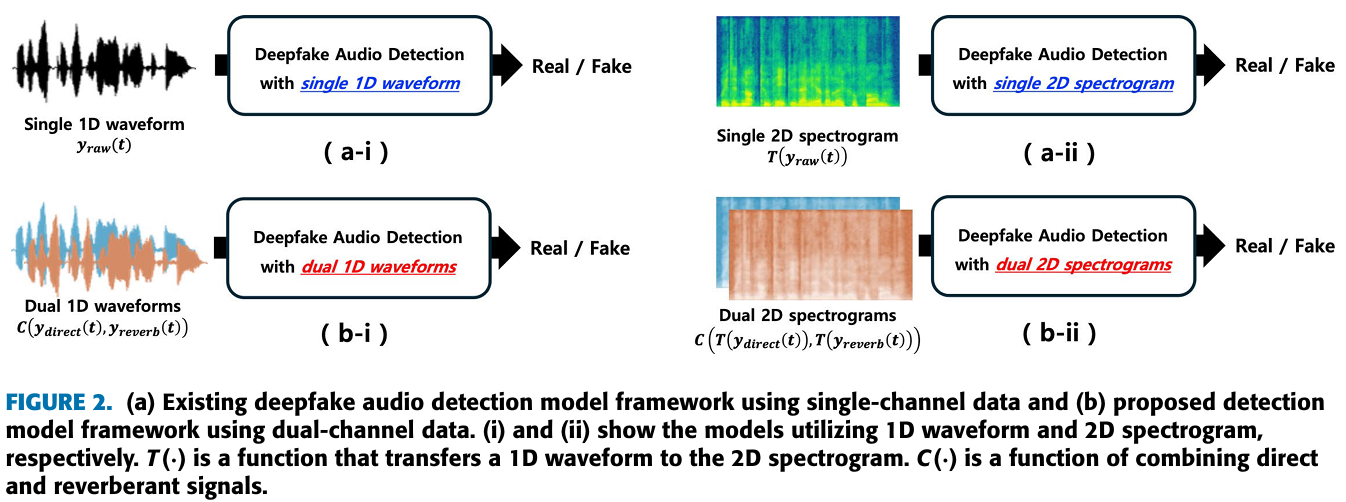
- 이 논문에서 single-channel 학습 데이터를 dual-channel 학습 데이터로 옮겼을 때, 성능이 늘어나는 것을 선보일 것이다.
- 쉽게 생각해서, single-channel 데이터에서 direct waveform과 reverberant waveform을 분리해내서 dual-channel 데이터로 사용하겠다는 것이다.
- 여기서 direct waveform은 어떤 반사도 없이 다이렉트로 receiver에 도착한 소리이고, reverberant waveform은 주변 환경에 반사된 소리를 말한다.
- 결국, 주변 환경이 반영된 reverberant waveform을 사용한다는 것이 핵심이다.
3. 방법론(a) : Mathematical Preliminaries
3-1. Direct and Reverberant waveforms
- direct waveform과 reverberant waveform은 다음과 같이 나타낸다.
Equation 1
Equation 2
는 convolution operation이다.
는 다양한 표면에 따른 반사를 포함한 주변 환경의 impluse response function이다.
impulse response function은 특정 환경이 특정 입력에 대해 어떻게 반응하는지를 나타내는 함수입니다. 쉽게 말해서, 소리가 특정 환경에서 어떻게 반사되고 전파되는지 설명합니다.
Equation 3
과 는 총 반사 수와 번째 반사의 감쇠 계수를 말한다.
은 Dirac delta function이다.
는 딜레이된 시간을 말한다.
Dirac delta function은 특정한 점에서만 정의된 무한한 값과 그 외의 모든 점에서는 0인 함수이다. (에를 들면, x=0에서만 무한대 값을 가지고, 나머지는 0을 가짐)
Equation 4
이고, 로 스케일된 번째 reverberant sound이다.
-
그래서 는 다음과 같이 나타내질 수 있다.
Equation 5
-
결국, 는 source waveform인 과 delayed source waveform에 가중합인 의 조합으로 정의될 수 있다.
3-2. Relationship between real and fake samples and the Direct-To-Reverb ratio
-
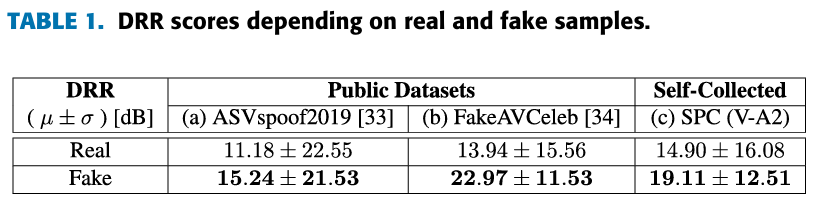
impulse response 의 효과를 살펴보기 위해 DRR(direct-to-reverberant ratio) 수치를 파악해보고자 한다.
-
DRR은 direct speech energy 와 reverberant speech 의 비율로 나타낸다.
Equation 6
DDR =
는 총 speech 프레임 수이다. -
(Table 1)을 보게 되면, fake samples에서가 real samples보다 DRR 수치가 큰 것을 알 수 있다.
-
이를 통해, fake samples가 수치가 적다. 즉, 다양한 환경 변수가 반영되지 않았다는 것을 알 수 있다.
4. 방법론(b) : Model Design
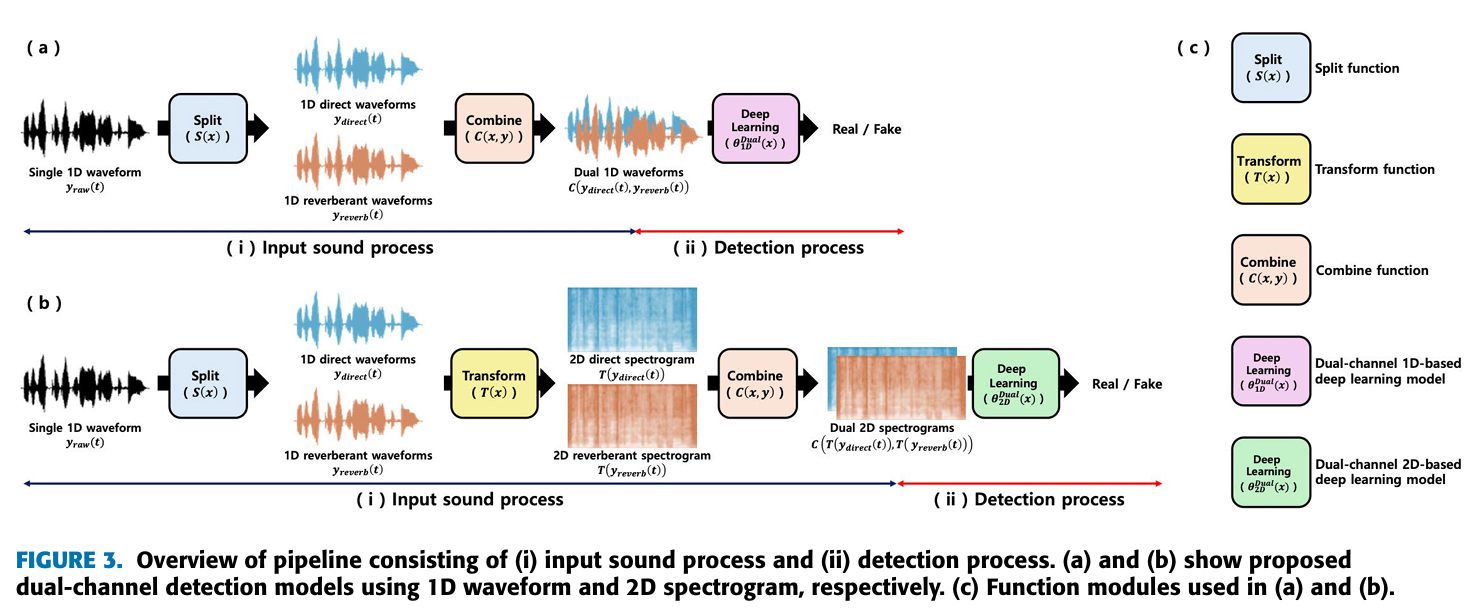
- 이 논문에서는 (Figure 3)에서 알 수 있듯이, 2가지 pipline을 제시한다.
- input sound process
- detection process
4-1. Waveform splitting
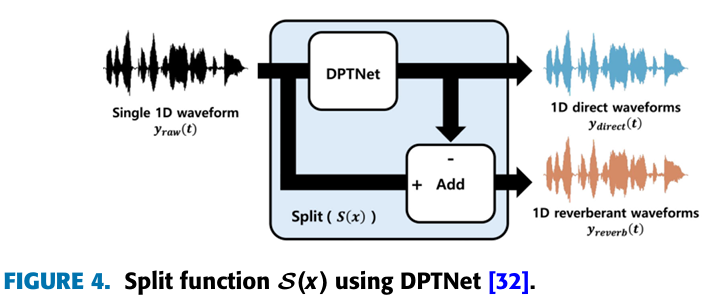
- DPTNet을 활용한, split function 를 통해서 에서 를 추출한다. (왜냐하면, DPTNet이 direct waveform만 output으로 제공하기 때문이다.)
- 는 를 통해서 구한다.
4-2. Feature transformation and combination
- waveform에서 만들어진 특징들의 최적의 조합을 찾기 위해서, 다음과 같은 3가지 feature transformation 방법과 2가지 feature combination 방법을 준비했다.
Feature Transformation 방법
- 1D wave
- 2D MFCC
- 2D LFCC
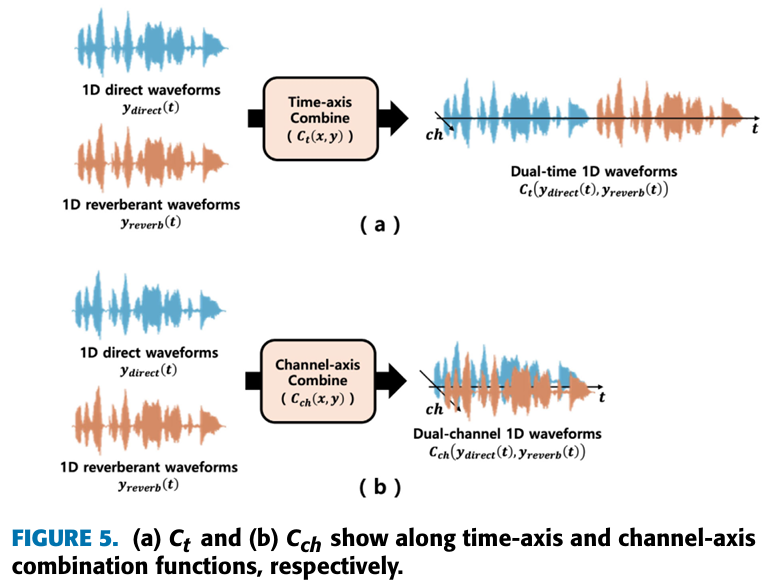
Feature Combination 방법
1. time-axis combination
2. channel-axis combination
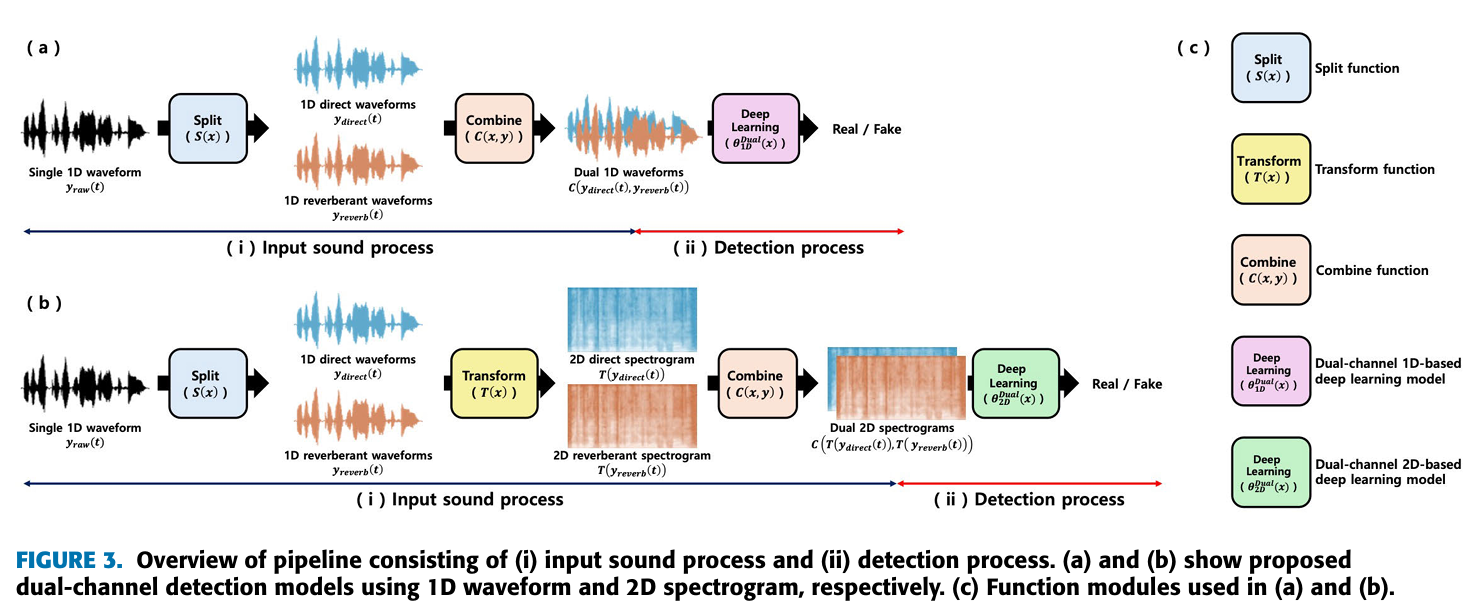
- 3가지 Feature transformation 방법들은 모든 형태의 waveform에 적용된다.
- 2가지 combination 방법들은 dual-channel data에만 적용된다. (single-channel data에는 적용되지 않는다.)
4-3. Model architectures
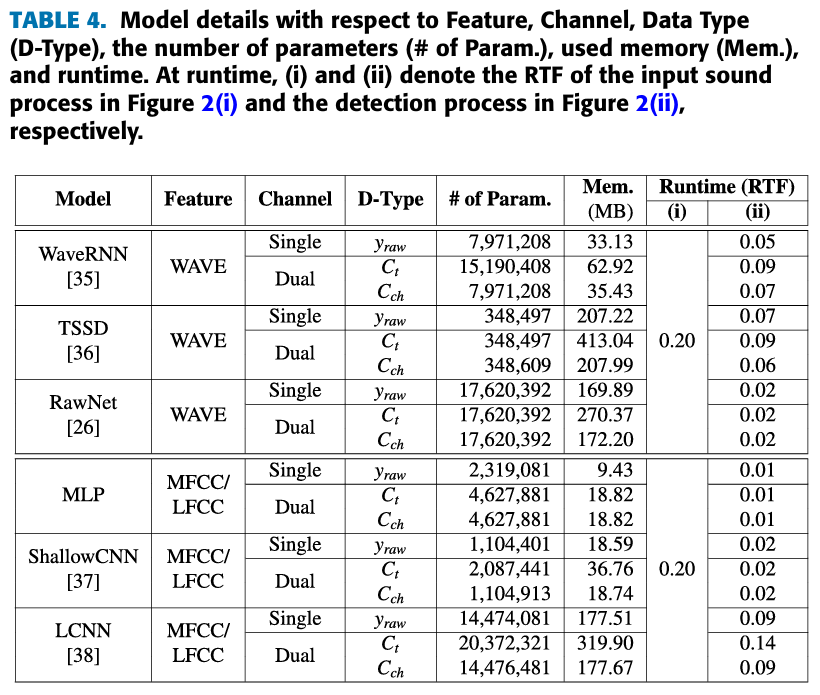
- 모델들은 잘 알려진 deepfake audio detection(WaveRNN, TSSD, RawNet, ShallowCNN, LCNN)을 사용했다.
- 하지만, WaveRNN과 RawNet, LCNN에서는 dual-channel data를 처리하지 못하기 때문에 때문에, channel-axis combination()을 적용한 데이터가 문제가 된다.
- 특히, WaveRNN에서는 Channel-axis 데이터 처리가 문제고, RawNet은 dual-channel format이 문제고, LCNN은 Max-Feature-Map 층이 문제이다.
- 그래서, dual-channel 데이터를 single-channel data로 바꾸는 convolutional layer를 추가했다.
5. 주요 결과
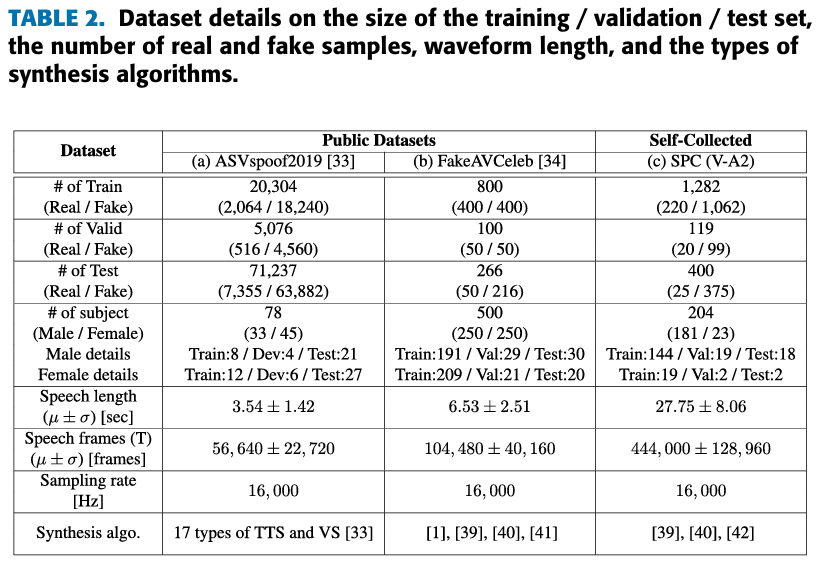
-
데이터 셋은 ASVspoof2019과 FakeAVCeleb, 직접 수집한 데이터를 사용했다.
-
직접 수집한 데이터 셋은 다음과 같은 3가지 기준으로 데이터를 선별하여 수집했다.
- Single speaker of English
- 명백히 얼굴 식별이 가능한 High-qulity video
- 대략 30초의 영상 길이
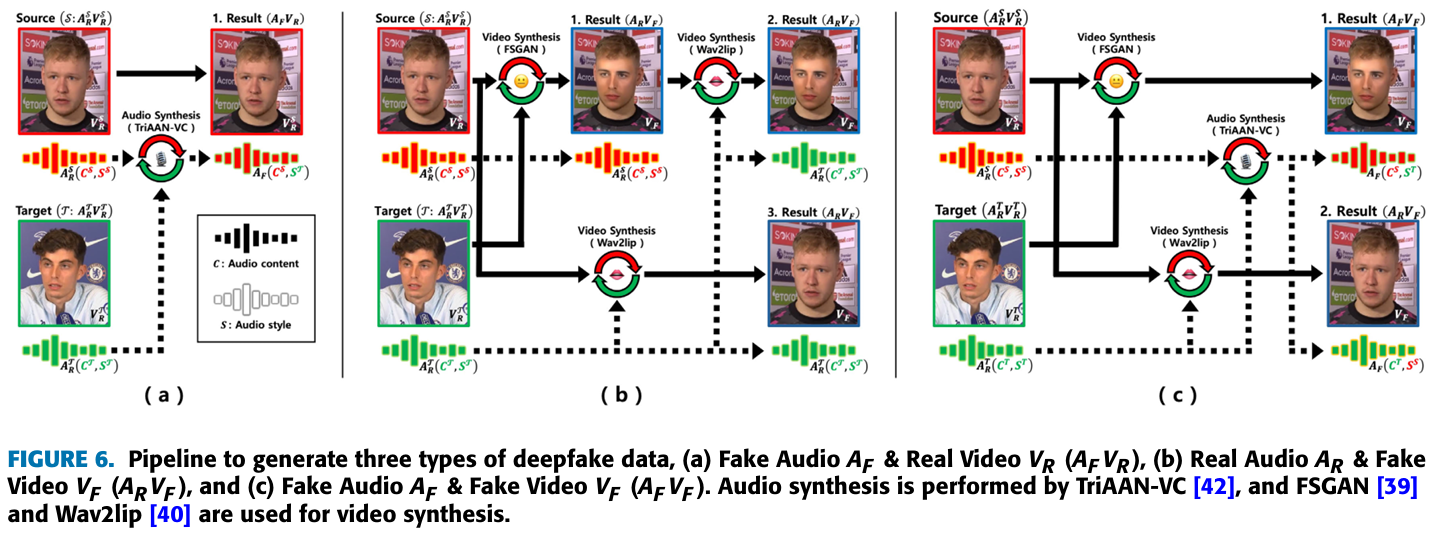
- 수집한 데이터를 (Figure 6)과 같은 방법으로 다음 3가지 형태의 데이터셋을 만들어 냈다.
- Fake audio & real video
- Real audio & fake Video
- Fake audio & fake video
- BCE loss 함수를 다음과 같이 사용했다.
- N은 총 samples 수, 와 는 번째 sample의 true label과 예측 확률을 나타낸다.
- 는 real과 fake 샘플들 수의 불균형 문제를 해결하기 위한 positive 가중치다.
- 그래서, 는 (number of positive samples) / (number of negative samples)로 사용한다.
- ASVspoof2019와 FakeAVCeleb 데이터 셋은 대부분 6초 정도 된다.
- 그래서 waveform을 6초 정도의 길이로 추출하는 전처리 과정을 거쳤다.
- 6초보다 크면, 6초 정도의 길이를 랜덤한 시작점으로 추출한다.
- 6초보다 작으면, 6초를 초과할 때까지 반복해서 늘리고, 6초 정도의 길이를 랜덤한 시작점으로 추출한다.
- 그리고, 데이터 정규화와 resampling 전처리 과정을 가졌다.
- 평가 지표는 EER과 AUC를 사용했다.
- EER은 FAR(false acceptance rate)과 FRR(false rejcetion rate)이 같을 때의 error rate를 말한다.
EER = FAR(threshold) = FRR(threshold)
threshold*는 FAR과 FRR이 같을 때의 value이다.FAR = (Number of False Acceptances) / (Number of Imposter Attempts)
FRR = (Number of False Rejections) / (Number of Genuine Attempts)
- RTF(real-time factor)은 real-time capabilities를 확인한다.
RTF = (Processing time) / (Audio duration)
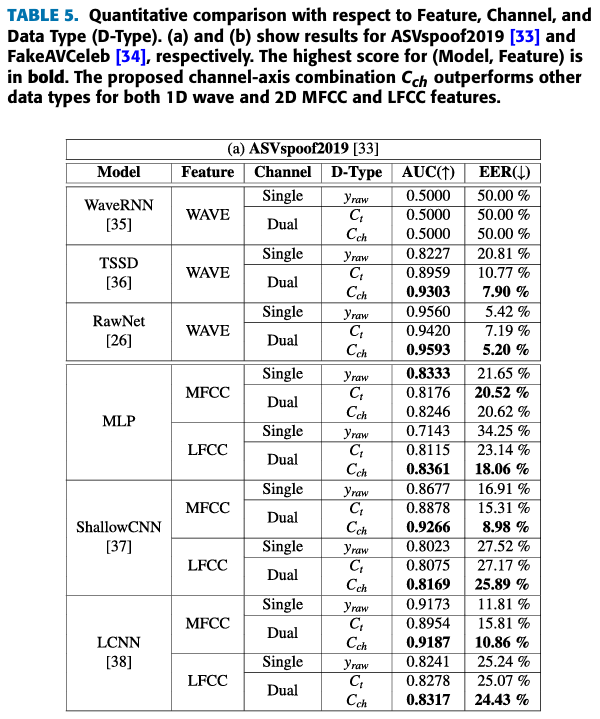
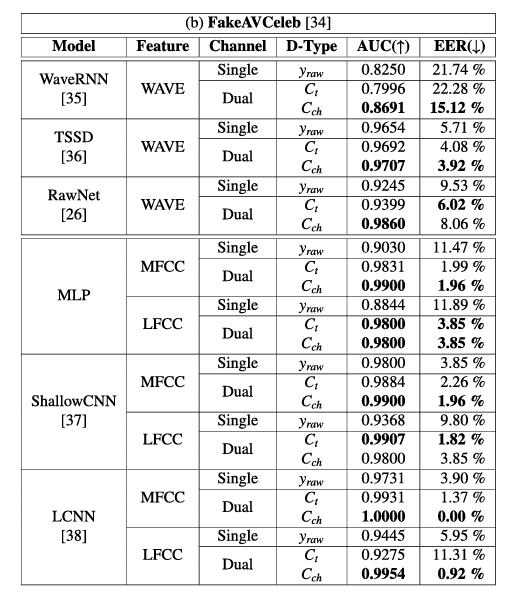
- (Table 5)을 통해서 dual-channel 데이터를 활용할 때 가 보다 더 적합하다는 것을 알 수 있다.
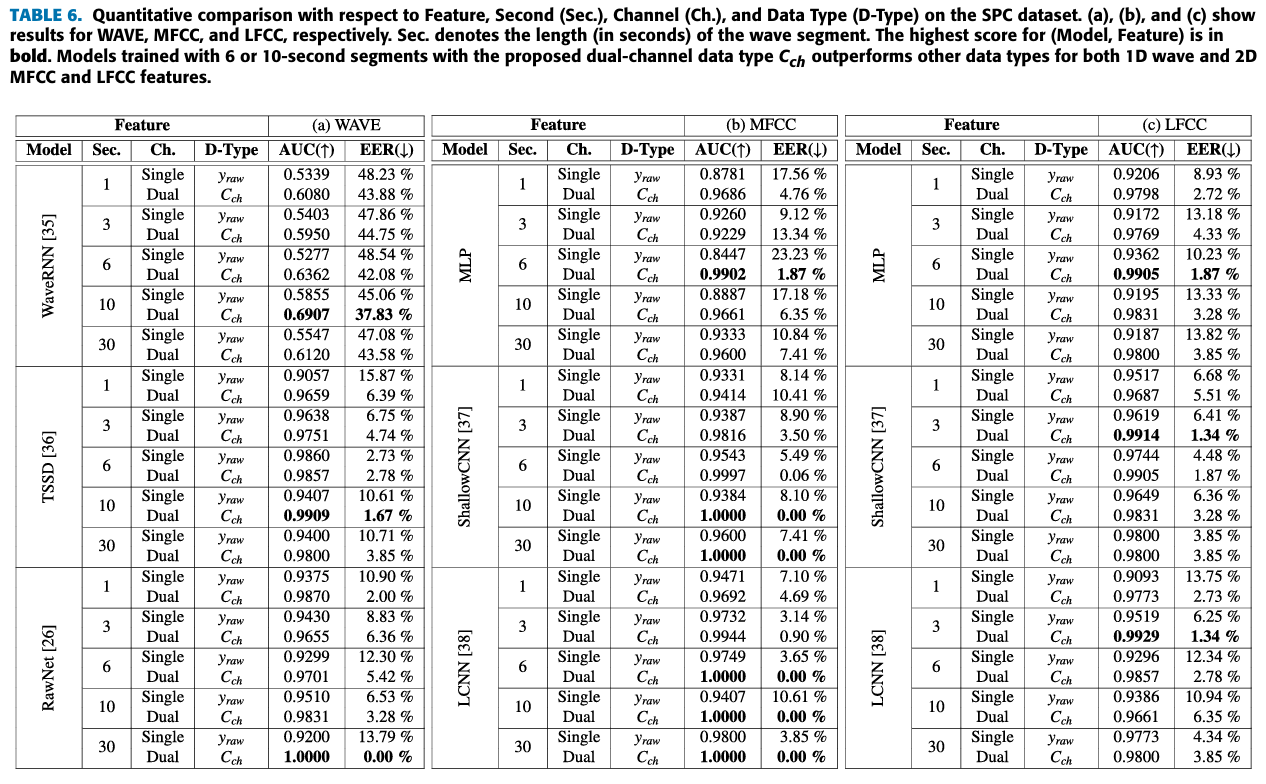
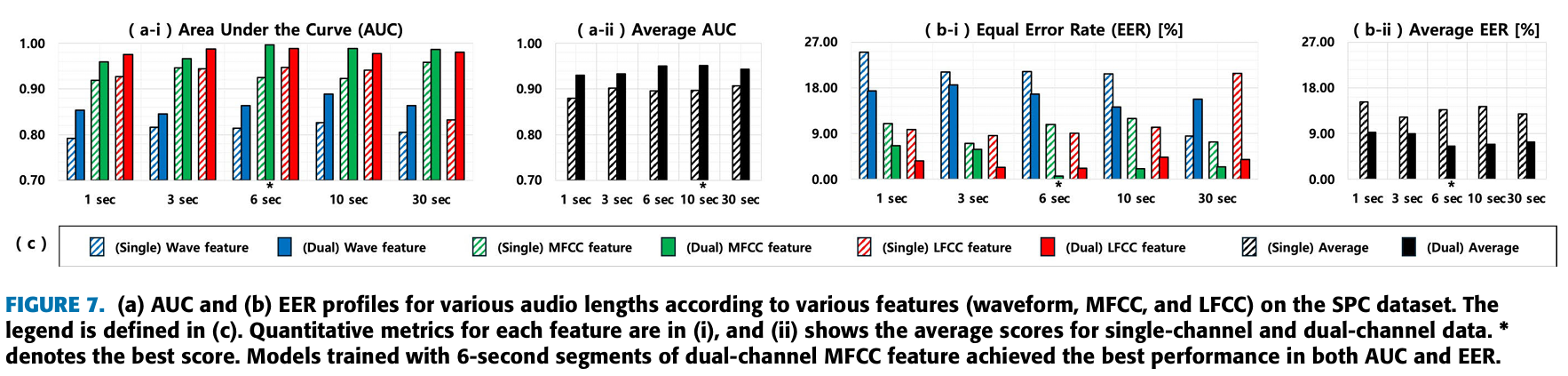
- (Figure 7)를 통해서 6초 혹은 10초 데이터가 가장 deepfake audio detection models의 성능을 높일 때, 효과적인 것을 알 수 있다.
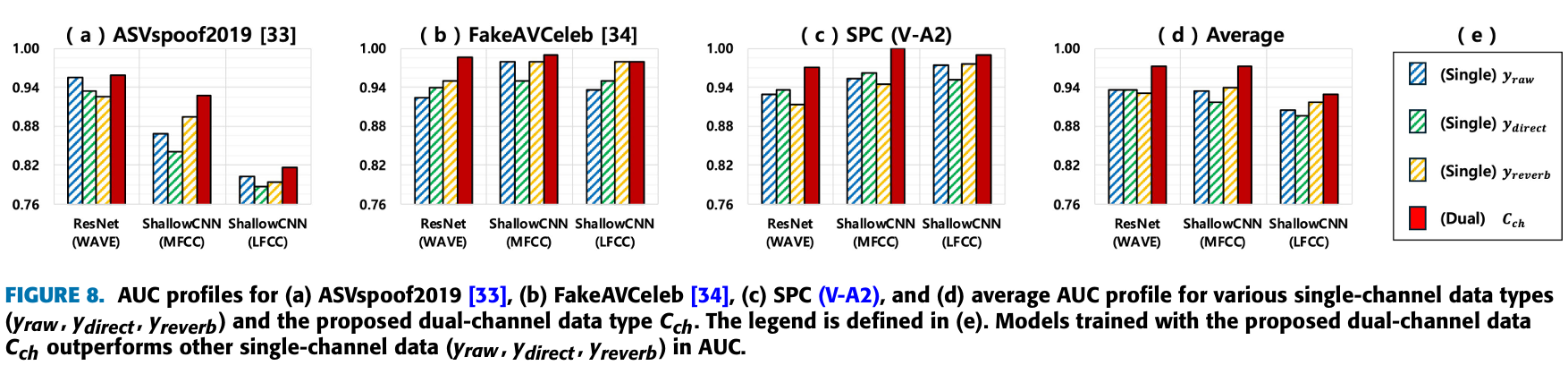
- (Figure 8)을 통해서 를 활용하는 것이 중요하다는 것을 다시 한번 확인할 수 있다.
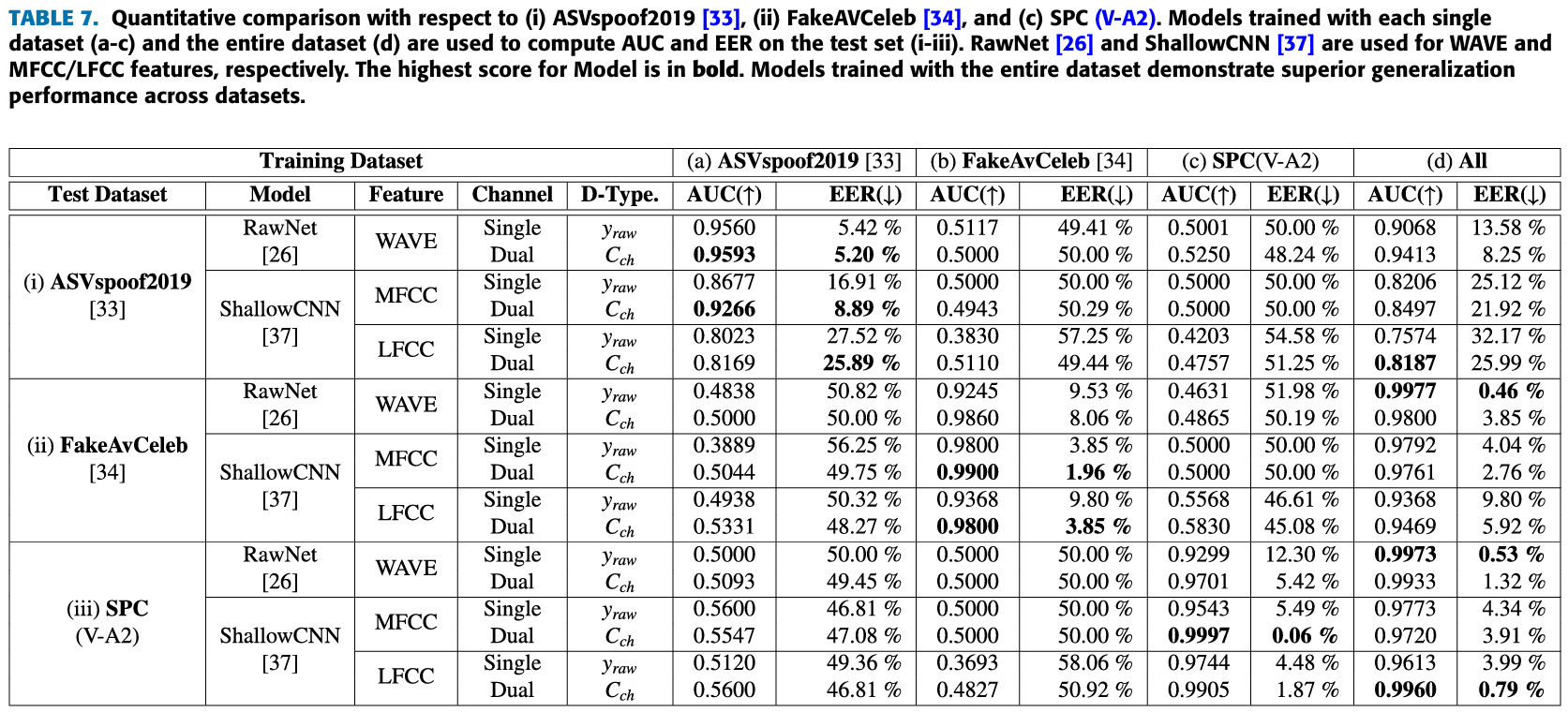
6. Comment
: 왜 이 생각을 못했지? 라는 생각들 정도로 단순하고 하지만, 중요한 아이디어를 활용했다는 점이 좋았다. 무엇보다 친구 논문을 읽는다는게 감회가 새로웠다.
더 자세한 내용은 논문 원본을 참고하시기 바랍니다.
개인의 주관이 반영된 해석이라 논문의 의도와 다를 수 있습니다.
오류가 있다면 댓글로 알려주시면 감사하겠습니다!