0. 3줄 요약
- 본 논문은 다중 양상(Multimodal)의 이해와 생성을 하나의 통합된 프레임워크에서 처리하기 위해, 완전히 이산화된 의미론적 토크나이저와 확산 대형 언어 모델(dLLM)을 결합한 'LLaDA2.0-Uni'를 제안합니다.
- 기존의 픽셀 재구성 기반 VQ-VAE 대신 SigLIP-VQ를 활용하여 이미지를 의미론적 이산 토큰으로 변환하고, 블록 단위의 마스크된 확산(Masked Diffusion) 목적 함수를 통해 텍스트와 시각 정보를 동시 학습하며, SPRINT 가속 기법으로 추론 속도를 극대화했습니다.
- 시각적 이해 태스크에서 최신 전문 VLM들과 대등한 성능을 기록하면서도 고품질의 이미지 생성 및 편집이 가능함을 입증하였으며, 특히 텍스트와 이미지가 교차하는(Interleaved) 환경에서의 추론 능력을 입증하여 차세대 통합 파운데이션 모델의 새로운 패러다임을 제시합니다.
1. 배경 및 문제 정의
멀티모달 파운데이션 모델의 발전과 한계
최근 대형 언어 모델(LLM)의 발전은 텍스트를 넘어 이미지, 비디오 등 다중 모달리티의 이해 및 생성 태스크를 단일 모델로 통합하려는 방향으로 나아가고 있습니다. 기존에는 이해를 위한 VLM(Qwen-VL 등)과 생성을 위한 확산 모델(Flux 등)이 분리되어 발전했으나, 최근 자율회귀(Autoregressive, AR) 기반의 통합 모델들이 등장하여 성과를 내고 있습니다. 하지만 AR 구조 특성상 이미지 생성 시 순차적 토큰 생성에 따른 막대한 지연 시간(Latency)이 발생한다는 고질적인 문제가 있습니다.
기존 잠재 확산 기반 통합 모델의 구조적 결함
AR의 한계를 극복하기 위해 병렬 디코딩이 가능한 마스크드 확산(Masked Diffusion) 기반의 모델들(MMaDA, Lumina-DiMOO 등)이 등장했습니다. 하지만 이들은 치명적인 설계적 결함을 안고 있습니다. 첫째, 픽셀 단위의 재구성에 초점을 맞춘 VQ-VAE 토크나이저를 사용하기 때문에, 시각 데이터가 토큰으로 압축되는 과정에서 고차원적인 의미(Semantic) 정보가 대거 손실되어 멀티모달 이해 성능이 크게 떨어집니다. 둘째, 텍스트 토큰에 대한 완전한 양방향 어텐션(Bidirectional attention)이 텍스트 고유의 자율회귀적 편향을 깨뜨려 언어 생성의 신뢰성을 저하시킵니다.
연구의 핵심 문제 정의
본 연구는 "이해(의미론적 추론)"와 "생성(고품질 픽셀 복원)"이라는 상이한 목표를 단일 이산 공간(Discrete space)에서 모순 없이 훈련할 수 있는 모델 아키텍처를 설계하고, 병렬 디코딩의 이점을 살리면서도 텍스트-이미지가 복잡하게 교차하는 태스크에서의 추론 효율성과 성능을 극대화하는 방법을 정의하고자 합니다.
2. 제안 방법 (Method)
전체 프레임워크의 핵심 구조
LLaDA2.0-Uni는 세 가지 핵심 모듈로 구성됩니다. 연속적인 시각 데이터를 의미론적 이산 토큰으로 변환하는 SigLIP-VQ 토크나이저, 텍스트와 시각 토큰을 섞어서 블록 단위로 처리하는 16B 파라미터의 MoE dLLM 백본, 그리고 백본이 내뱉은 시각 토큰을 다시 고해상도 픽셀 이미지로 복원해 내는 확산 디코더(Diffusion Decoder) 입니다. 이 구조는 인코딩과 디코딩의 역할을 완벽히 분리하여, 언어 모델 백본이 순수하게 의미론적 추론과 생성에만 집중할 수 있게 만듭니다.
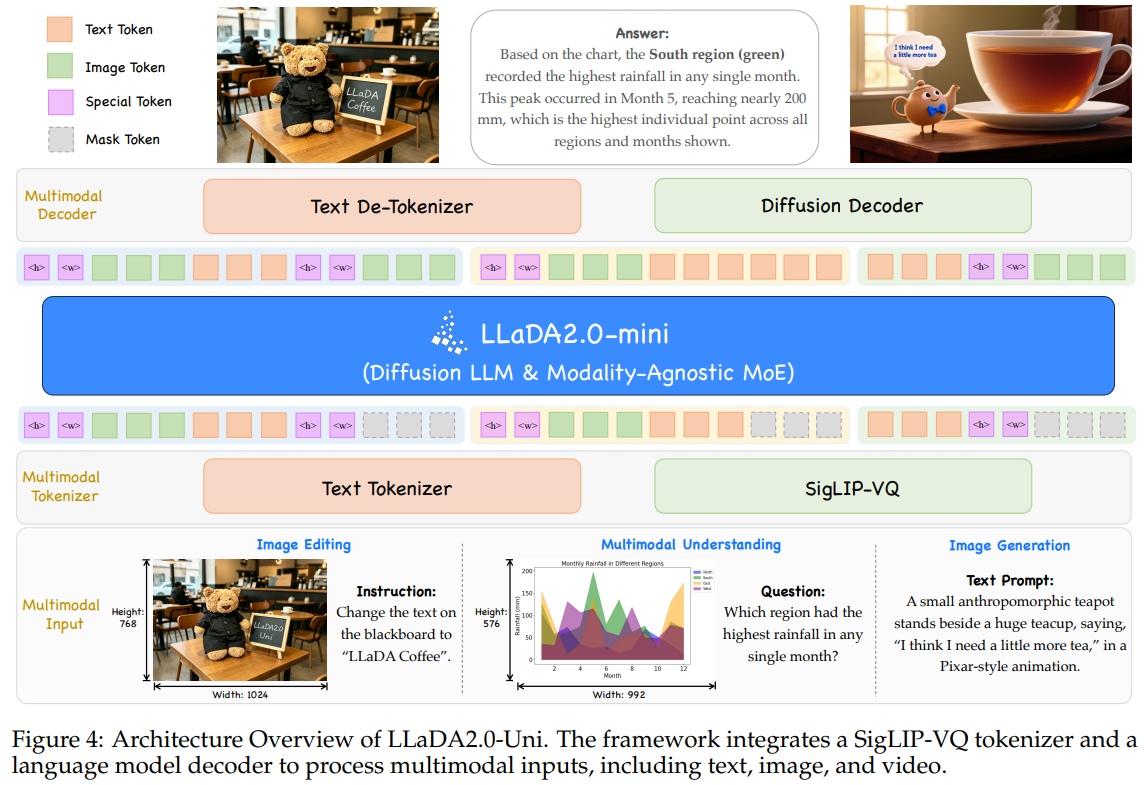
데이터 전처리 및 입력 변환 메커니즘
시각 데이터는 픽셀 재구성이 아닌 의미론적 정렬을 위해 훈련된 SigLIP2-g ViT를 통과한 후, 16,384개의 어휘 크기를 가진 코드북에 매핑되어 완전히 이산화된 토큰으로 변환됩니다. 공간적 배열을 언어 모델에 인식시키기 위해 복잡한 2D RoPE 대신 기존의 1D RoPE를 유지하며, 이미지 시퀀스 앞에 동적 해상도를 나타내는 특수 토큰(예: <|image_size:512x512|>)을 부착합니다. 이를 통해 모델 구조 변경 없이 임의의 해상도(Arbitrary Resolution)를 입력받을 수 있습니다. 변환된 시각 토큰은 텍스트 토큰과 함께 동일한 시퀀스로 결합되어 백본에 주입됩니다.
네트워크 구조와 블록 확산 모델링
백본인 LLaDA2.0-mini는 Modality-agnostic MoE 구조를 띄고 있어, 텍스트와 시각 정보의 밀도 차이에 따라 전문가 네트워크의 용량을 동적으로 할당합니다. 특히 텍스트의 자율회귀적 편향을 보호하기 위해 블록 단위 어텐션(Block-wise Attention) 을 적용합니다. 이는 전체 시퀀스에 대한 무분별한 풀 어텐션을 방지하고 안정적인 디코딩을 보장합니다.
모델은 이산 확산 모델의 확장판인 블록 확산 언어 모델(BDLM) 목적 함수로 학습됩니다.
이 수식은 블록 내에서 임의로 마스킹된 토큰 위치()에 대해, 타임스텝 에서 원본 토큰 를 예측할 확률의 로그 우도를 최대화하는 과정을 나타냅니다. 이해 태스크에서는 텍스트만, 생성 태스크에서는 이미지만 마스킹하는 전략을 교차 사용하여 두 역량을 동시에 강화합니다.
백본이 생성한 시각 토큰은 확산 디코더로 전달됩니다. 기존 방법들이 텍스트 프롬프트를 시각 복원 시 중복으로 주입했던 것과 달리, 제안된 디코더는 오직 업샘플링된 시각 토큰만을 조건(Condition)으로 활용하여 2배 초해상도(Super-resolution)의 이미지를 렌더링합니다.
SPRINT: 학습이 필요 없는 추론 가속 알고리즘
추론 단계에서는 병렬 디코딩의 연산량을 획기적으로 줄이는 SPRINT 기법이 도입됩니다.
- 희소 접두사 보존 (Sparse Prefix Retention): 텍스트와 이미지의 정보 밀도가 다름을 인지하여, 각 스텝별로 KV 캐시를 모달리티별로 다르게 가지치기(Pruning)합니다. 불필요한 시각적 중복 데이터를 날려 연산 부하를 크게 줄입니다.
- 비균일 토큰 마스크 해제 (Non-uniform Token Unmasking): 기존의 고정된 토큰 해제 스케줄을 버리고, 예측 신뢰도가 높은 토큰은 단일 스텝에서 즉시 마스크를 해제합니다. 불확실성이 높은 토큰에만 연산 자원을 집중시킴으로써 생성 퀄리티 하락 없이 스텝 수를 줄입니다.
3. 실험 결과 (Experiments)



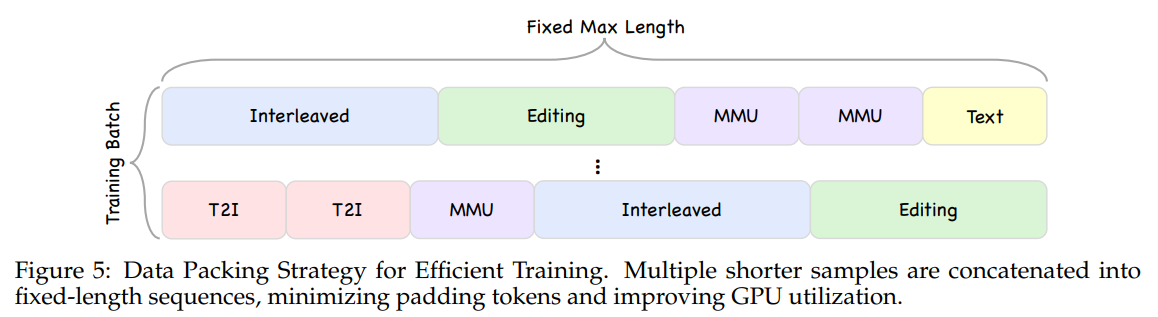
실험 세팅 및 베이스라인
모델은 100B 토큰의 시각-언어 정렬, 210B 토큰의 다중 작업 사전 학습, 80B 토큰의 지도 미세조정(SFT)의 3단계를 거쳐 훈련되었습니다. 평가는 멀티모달 이해(MMMU, MathVista, DocVQA 등), 이미지 생성(GenEval, DPG), 그리고 연구진이 새롭게 구축한 교차 생성 벤치마크(InterGen)에서 진행되었습니다. 비교군으로는 최신 VLM(Qwen3-VL, InternVL) 및 Emu3.5 등 교차 생성 지원 모델들이 활용되었습니다.
핵심 성능 및 비교 결과
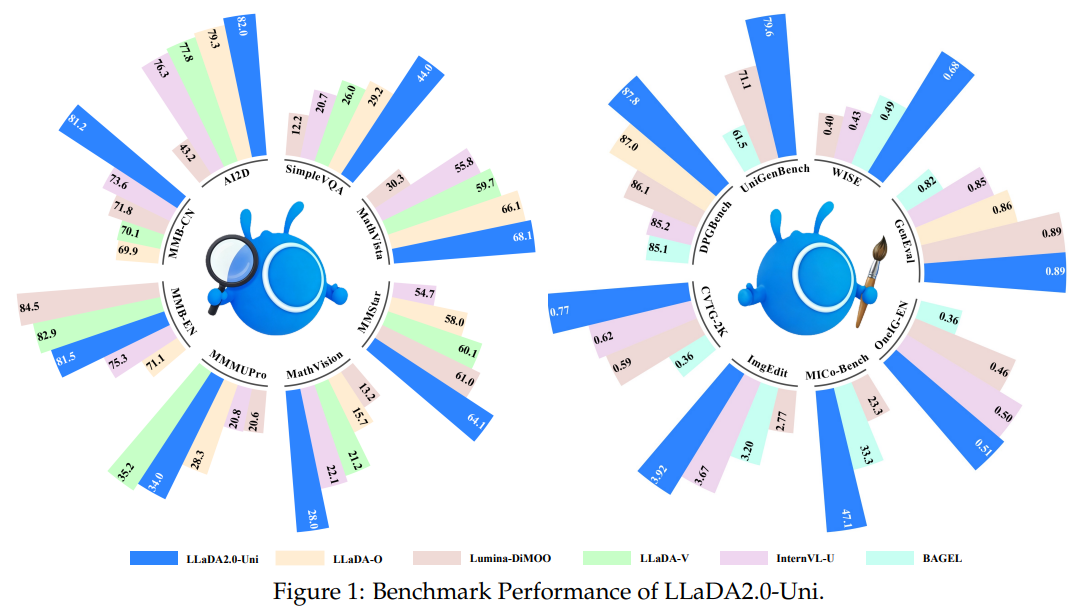
- 멀티모달 이해와 생성의 완벽한 밸런스: LLaDA2.0-Uni는 이해 태스크에서 Qwen2.5-VL 등 전용 아키텍처 모델에 근접하는 최고 수준의 성능을 입증했습니다. 동시에 이미지 생성(GenEval 0.89)에서도 강력한 프롬프트 정렬 성능을 보였습니다.
- 교차 생성 및 추론 능력 (Interleaved): InterGen 벤치마크 테스트 결과, 텍스트와 이미지가 섞인 복잡한 스토리텔링 및 시간 흐름 예측 태스크에서 Emu3.5를 압도하는 점수(스토리텔링 6.42 vs 6.28 등)를 기록했습니다.
- 가속화 효과 (어블레이션 스터디): SPRINT 가속 적용 시, 성능 하락을 -0.6 수준으로 억제하면서 TPS(초당 토큰 처리량) 기준 생성 속도를 1.6배 향상시켰습니다(24.3 -> 39.8 TPS). 또한, 디코더에 지식 증류(Distillation)를 적용한 Diffusion Decoder Turbo는 50단계(32.95초)가 걸리던 이미지 생성을 8단계(2.90초)로 11.4배 가속시키면서도 성능(DPG 87.24)을 완벽히 유지했습니다.
4. 한계점 및 시사점
명확한 제약 조건 및 한계점
논문은 제안된 SigLIP-VQ 토크나이저의 근본적 한계를 언급하고 있습니다. SigLIP-VQ는 이미지의 고차원적 의미 구조를 인코딩하는 데는 매우 탁월하지만, 픽셀 단위의 세밀한 구조를 보존하는 능력이 다소 떨어집니다. 이로 인해 원본의 질감이나 텍스트를 엄격하게 유지해야 하는 미세한 이미지 편집(Image Editing) 태스크에서는 품질 제약이 발생합니다. 또한 강화학습(RL)을 통합 dLLM 파이프라인에 적용하는 최적화 기술이 아직 미성숙하여 도입되지 못했다는 점을 한계로 지적합니다.
학술적 의의 및 향후 연구 방향
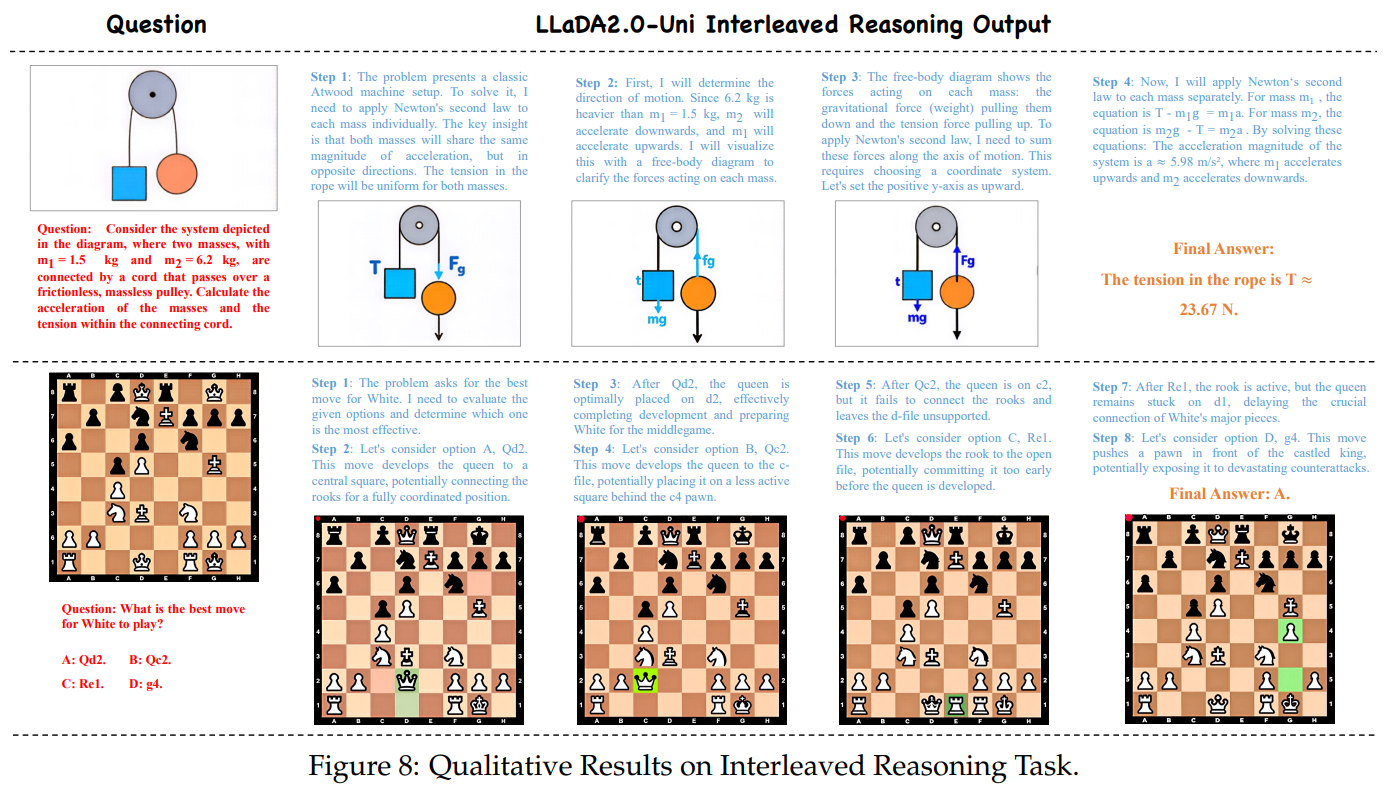
LLaDA2.0-Uni는 언어와 시각의 본질적 표현 차이를 '의미론적 이산 공간' 하나로 완전히 통합해 냈다는 점에서 아키텍처 확장의 이정표를 세웠습니다. 자율회귀(AR)를 강제하지 않고도 텍스트 추론의 깊이와 확산 생성의 품질을 모두 확보했습니다. 나아가 이 프레임워크가 체스 게임 분석이나 물리 문제 풀이 과정처럼, 모델 스스로 사고 과정(Chain-of-Thought)과 이미지를 교차로 생성해 내는 능력을 보여줌으로써, 복합 추론이 가능한 범용 인공지능(AGI)을 향한 고무적이고 확장 가능한 패러다임을 확립했습니다.
