0. 3줄 요약
- 본 논문은 대형 언어 모델(LLM)의 강화학습 과정에서 발생하는 극단적 샘플(전체 정답 또는 전체 오답)의 기울기 소실 및 비효율적 탐색-활용 딜레마를 해결하기 위한 DiPO(Disentangled Perplexity Policy Optimization)를 제안한다.
- 퍼플렉서티(PPL)와 정답 확률의 통계적 상관관계를 분석하여 탐색/활용 공간을 분리(PSD)하고, 기존 검증 보상의 분포를 해치지 않으면서 특정 샘플의 보상만을 미세 조정하는 양방향 보상 재할당(BRR) 메커니즘을 도입했다.
- 수학적 추론 및 함수 호출 태스크에서 기존 GRPO 및 DAPO 대비 일관되고 우수한 성능 향상을 달성하였으며, 특히 학습 후반부의 탐색 정체 현상을 방지하여 모델의 추론 능력을 극대화하는 학술적 의의를 지닌다.
1. 배경 및 문제 정의
강화학습 기반의 LLM 튜닝, 특히 검증 가능한 보상을 사용하는 RLVR(Reinforcement Learning with Verifiable Rewards)은 모델의 추론 능력을 비약적으로 향상시켰다. 이 중 GRPO(Group Relative Policy Optimization) 패러다임은 가치 네트워크(Value Network) 없이 그룹 내 상대적 이점을 계산하여 효율성을 극대화했다.
그러나 기존 GRPO 기반 방법론은 탐색-활용 상충 관계(Exploration-Exploitation Trade-Off)에서 두 가지 치명적인 한계를 지닌다.
첫째, 극단적 샘플의 기울기 소실 문제다. 학습이 진행됨에 따라 다수의 샘플 그룹이 모두 오답인 Hard 그룹(보상 0)이거나 모두 정답인 Easy 그룹(보상 1)으로 양극화된다. 이 경우 그룹 내 보상 편차가 0이 되므로 Advantage 산출값 역시 0이 되어, 더 나은 방향으로의 학습(탐색 및 활용)을 이끌어낼 Gradient가 소실된다.
둘째, 비효율적인 탐색과 활용이다. 샘플의 생성 확률(Perplexity, PPL) 분포를 보면, PPL이 높은(탐색적) 정답 샘플이나 PPL이 낮은(활용적) 오답 샘플이 혼재한다. DACE나 CDE 등 기존 연구들은 PPL을 직접적인 보상으로 사용하여 이를 해결하려 했으나, 이는 검증 보상의 본래 분포를 크게 훼손하여 추가적인 학습 불안정성을 초래하는 문제가 발생한다.
본 논문은 기존 보상 체계의 안정성을 유지하면서도, PPL을 기준으로 '어떤 오답 샘플을 더 탐색하게 할 것인지', '어떤 정답 샘플의 엔트로피를 낮춰 활용하게 할 것인지'를 세밀하게 제어하는 것을 핵심 문제로 정의한다.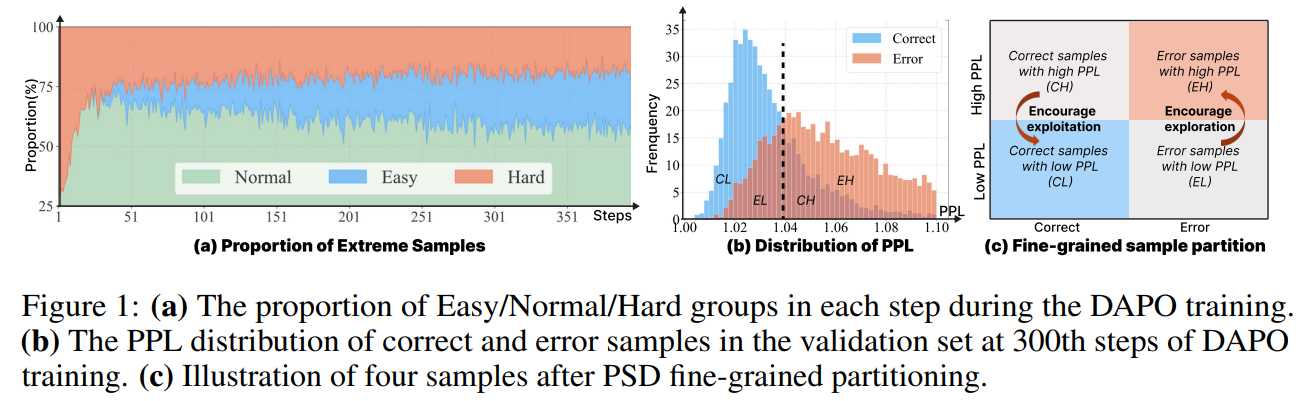
2. 제안 방법 (Method)
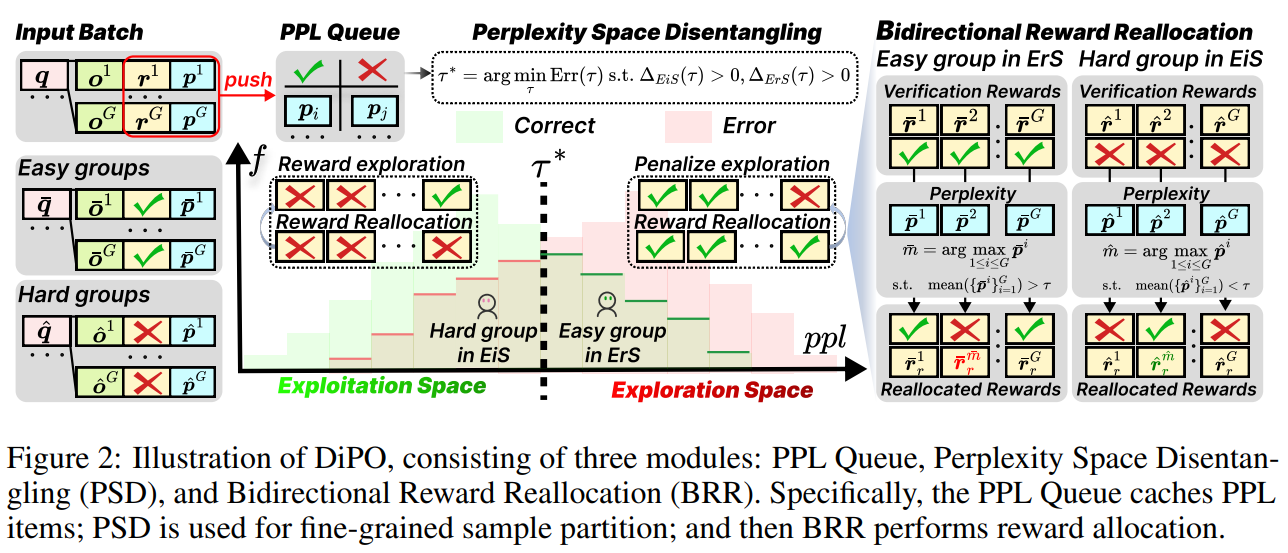
DiPO의 핵심 아이디어는 생성된 응답들의 PPL 공간을 통계적으로 분리하여 탐색과 활용이 필요한 대상을 명확히 식별하고, 원래의 학습 안정성을 훼손하지 않는 선에서 핀포인트로 보상을 재할당하는 것이다.
입력 데이터 표현 및 전처리 (PPL Queue)
모델은 주어진 쿼리 에 대해 개의 응답 를 샘플링한다. 각 응답에 대해 환경으로부터 얻은 이진 검증 보상 와 모델의 내부 토큰 생성 확률 기반의 PPL 값 를 산출한다. 이 데이터 쌍 는 PPL Queue에 지속적으로 캐싱되어, 온라인 학습 과정에서 PPL과 정답률 간의 동적 통계 확률을 추정하는 데 사용된다.
Perplexity Space Disentangling (PSD)
동적 통계를 바탕으로 전체 샘플 공간을 탐색 공간(Exploration Space, )과 활용 공간(Exploitation Space, )으로 분리하는 최적의 임계값 를 찾는다.
단순히 특정 임계값을 고정하는 것이 아니라, 다음의 엔지니어링 파이프라인을 거친다.
- Advantage Judgment: 특정 임계값 를 기준으로, 탐색 공간에서의 '오답 우위'와 활용 공간에서의 '정답 우위'가 통계적으로 유의미한지 판단한다. 노이즈를 제어하기 위해 95% 신뢰구간(Wald approximation)의 하한값과 상한값을 교차 검증하여, 두 공간이 확실하게 분리될 수 있는 후보군 를 필터링한다.
- Minimizing Classification Errors: 필터링된 후보군 중, PPL만으로 정답/오답을 분류했을 때 오차가 가장 적은 최적의 임계값 를 다음 수식을 통해 계산한다.이 과정을 통해, PPL이 높음에도 정답인 샘플(CH)이나 PPL이 낮음에도 오답인 샘플(EL) 등 미세 조정이 필요한 타겟이 명확히 정의된다.
Bidirectional Reward Reallocation (BRR)
PSD를 통해 기준점 를 찾았다면, 이를 바탕으로 보상을 재할당한다. BRR의 핵심은 모든 샘플의 보상을 건드리는 것이 아니라, 기울기가 0인 Hard/Easy 그룹 내에서 오직 '최대 PPL'을 가진 단일 샘플의 보상만 반전시킨다는 점이다.
- Hard 그룹 업데이트 (탐색 유도): 그룹 내 보상이 모두 0이면서 평균 PPL이 보다 낮은(EiS에 위치한) 경우, 그룹 내에서 가장 PPL이 높은 샘플 의 보상을 로 재할당한다. 이는 모델이 기존의 낮은 엔트로피 상태에서 벗어나 더 큰 불확실성(탐색)을 갖는 방향으로 정책을 업데이트하도록 유도한다.
- Easy 그룹 업데이트 (활용 유도): 그룹 내 보상이 모두 1이면서 평균 PPL이 보다 높은(ErS에 위치한) 경우, 그룹 내에서 가장 PPL이 높은 샘플 의 보상을 으로 재할당한다. 이는 이미 정답을 맞추는 그룹에 대해 과도한 탐색을 억제하고 엔트로피를 낮추는 방향으로 유도한다.
학습 및 추론 파이프라인
기존 검증 보상 과 재할당된 보상 은 직교성(Orthogonality)을 갖는다. 즉, BRR은 기울기가 0인 그룹만 활성화하므로 기존 RL 업데이트를 간섭하지 않는다.
최종 학습(Training) 목적 함수는 두 보상 체계에 대한 손실을 선형 결합하여 구성된다.
여기서 는 재할당된 보상의 반영 비율을 조절하는 하이퍼파라미터다.
추론(Inference) 단계에서는 별도의 추가 연산 없이, 강화학습이 완료된 정책 모델을 사용하여 일반적인 그리디 디코딩이나 샘플링을 수행한다.
3. 실험 결과 (Experiments)
- 실험 세팅: 수학적 추론 능력 평가를 위해 DAPO-17K 데이터셋으로 학습하고 AIME24/25, MATH500 등 6개 벤치마크를 활용했다. 함수 호출 태스크는 ToolRL 프레임워크와 BFCLv3 벤치마크를 사용했다. 비교군(Baseline)으로는 GRPO, DAPO, DAPO w/ EL(Entropy Loss), CDE가 사용되었다.
- 수학적 추론 결과: Qwen3-4B, 8B, Qwen2.5-7B 모델에서 모두 DiPO가 가장 높은 평균(AVG) 성능을 기록했다. 특히 Qwen3-8B-Base 모델 기준 AIME24에서 35.00%를 기록하며 기존 DAPO(30.08%) 대비 큰 폭의 상승을 보였다.
- 함수 호출 결과: 다턴(Multi-Turn) 추론과 복잡한 환경이 요구되는 세팅에서 DiPO가 최고 성능(Qwen2.5-7B 기준 전체 정확도 62.51%)을 달성하여 태스크 범용성을 입증했다.
- 해석 및 어블레이션: 실험 후반부의 성능 곡선(Learning Curve)을 분석한 결과, 기존 DAPO는 학습 후반부에 탐색을 멈추고 성능이 정체되는 반면, DiPO는 Hard 샘플에 대한 탐색 신호를 계속 제공하여 성능 한계치를 지속적으로 돌파했다. 또한, PPL을 직접 보상으로 사용하는 방식(CDE 유사 형태)은 오히려 베이스라인보다 성능이 하락하는 현상을 보여, BRR을 통한 직교적 보상 조정 설계가 학습 안정성에 필수적임이 증명되었다.
4. 한계점 및 시사점
한계점
- 명확한 검증 보상의 의존성: 본 방법론은 RLVR 환경, 즉 0 또는 1이라는 명확한 검증 보상(Verification Reward)이 존재하는 태스크(수학, 코딩, 특정 툴 사용)를 전제로 설계되었다. 정답이 명확하지 않은 오픈엔드 텍스트 생성이나 창의적 글쓰기 태스크에는 직접 적용하기 어렵다.
- 추가적인 메모리 및 연산 오버헤드: 매 스텝 PPL Queue를 유지하고, 를 계산하며 통계적 유의성을 판별하는 작업은 표준 GRPO 대비 훈련 단계에서 미세한 연산/메모리 병목을 유발할 수 있다.
이론적 과제 및 시사점
- 하이퍼파라미터 민감도 완화: 기존의 단순 엔트로피 손실(Entropy Loss) 기법은 계수 변화에 따라 학습이 붕괴될 정도로 극도로 민감하지만, DiPO는 값 변화에 대해 훨씬 넓은 유효 범위를 가지며 안정성을 보였다.
- 학술적/실무적 확장 가능성: 이 연구는 LLM의 RL 파인튜닝 과정에서 발생하는 '보상 분포의 파괴 없이 탐색 능력을 주입하는 메커니즘'의 우수 사례를 보여준다. 향후 오프라인(Offline) 데이터에 대한 PPL 사전 분석과 결합하거나, 가치 네트워크가 포함된 PPO 환경으로 이식하는 등 강화학습의 안정성과 탐색 범위를 넓히는 후속 연구로의 확장 가능성이 높다.
