1. 논문 정보
- 제목: Large Scale Transfer Learning for Tabular Data via Language Modeling
- 학회/연도: arXiv 2024 (NeurIPS 2024 제출 추정)
- 내가 정의한 한 줄 요약:
"방대한 20억 개(2.1B)의 테이블 데이터로 Llama-3를 튜닝하여, '학습 없이도(Zero-shot)' 정형 데이터를 예측하는 TABULA-8B의 탄생."
2. 이 논문을 읽게 된 계기 (Problem Definition)
NLP와 Vision 분야는 'Pre-training + Fine-tuning' 또는 'Zero-shot Transfer'라는 거대한 패러다임이 이미 정착했습니다. 하지만 정형 데이터(Tabular Data) 분야는 여전히 데이터셋마다 처음부터 모델을 다시 학습해야 하는 GBDT(XGBoost, LightGBM)가 지배하고 있습니다.
- 문제의식: "왜 정형 데이터는 전이 학습(Transfer Learning)이 안 될까?"
- 해결 지점: 이 논문은 테이블 데이터도 충분히 방대한 양(Scale)으로 학습하면, 마치 언어 모델처럼 새로운 테이블을 보자마자(Zero-shot) 예측할 수 있음을 증명하려 합니다.
3. 처음 읽고 든 인상 (First Impression)
처음 제목을 봤을 땐 "또 텍스트로 바꿔서 LLM에 태우는 뻔한 논문인가?" 싶었습니다. TabLLM 같은 기존 시도들은 추론 속도가 느리고 성능도 GBDT에 미치지 못했으니까요.
하지만 2.1B rows, 4M unique tables라는 압도적인 데이터 스케일(TabLib)을 보고 생각이 바뀌었습니다. "이 정도 규모면 모델이 '테이블의 문법' 자체를 깨우쳤을 수도 있겠다"는 기대감이 들었고, 단순히 텍스트로 변환하는 것을 넘어 Packing과 Attention 구조를 정형 데이터에 맞게 수정한 디테일이 인상적이었습니다.
4. 전체 구조 및 아키텍처 요약 (The Big Picture)
전체 파이프라인은 '데이터 구축'과 '모델 튜닝' 두 단계로 나뉩니다.
- 데이터 구축 (TabLib-T4): GitHub와 Common Crawl에서 수집한 수백만 개의 테이블 중 품질이 높은 400만 개(2.1B 행)를 선별합니다.
- 직렬화 (Serialization): 각 테이블의 행(Row)을 텍스트 템플릿(예: "Column: Value, ...")으로 변환합니다.
- 모델 튜닝 (Fine-tuning): Llama 3-8B를 베이스로 하여, 정형 데이터 예측에 특화된 방식으로 학습합니다.
- 추론 (Inference): 새로운 테이블이 주어지면 추가 학습 없이(Zero-shot) 또는 몇 개의 예시만 보고(Few-shot) 바로 타겟 값을 예측합니다.
5. 주요 구성 요소 상세 설명 (Deep Dive)
(1) Row-Causal Tabular Masking (RCTM)
이 논문의 핵심적인 구조적 변형입니다.
- Why: 일반적인 언어 모델의 Causal Masking은 모든 이전 토큰을 봅니다. 하지만 테이블 데이터에서 1번 행(Row 1)과 2번 행(Row 2)은 서로 독립적이어야 할 때가 많습니다. 서로의 정보를 미리 보면 안 되는 경우(Data Leakage)를 방지해야 합니다.
- How: 같은 배치(Batch) 안에 여러 행을 묶어서 넣을 때, 다른 행끼리는 Attention을 하지 못하도록 마스킹을 씌웁니다. 이를 통해 모델은 오직 "현재 행의 컬럼 간 관계"와 "제공된 Few-shot 예시"에만 집중하게 됩니다.
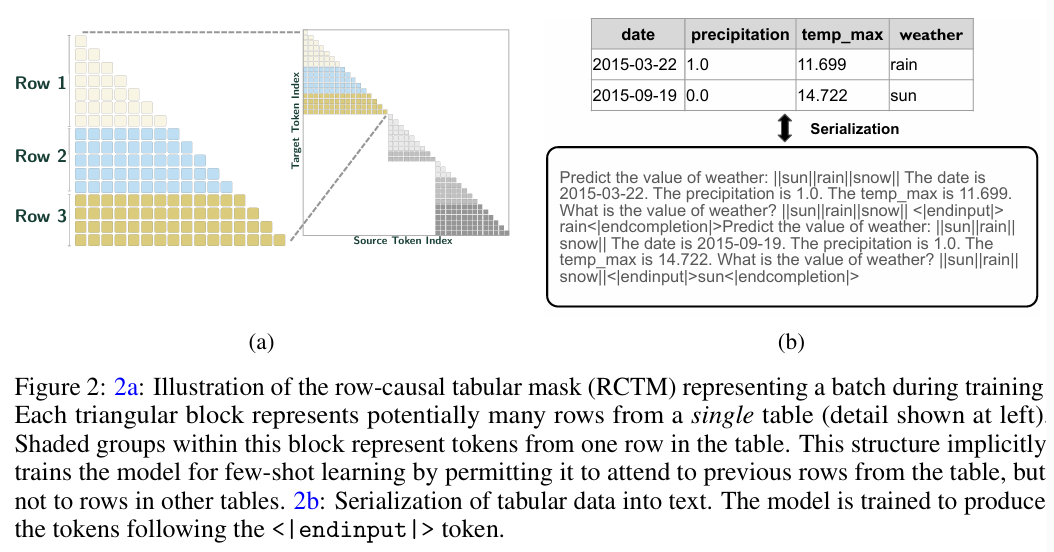
(2) Novel Packing Scheme
- 효율성을 위해 길이가 제각각인 테이블들을 하나의 긴 시퀀스로 꽉 채워(Packing) 학습합니다. 이때 RCTM 덕분에 서로 다른 테이블이 섞여도 간섭이 일어나지 않습니다.
6. 핵심 아이디어: 내가 이해한 방식 (Intuition)
저자들의 가설은 "테이블 데이터도 결국 하나의 언어(Language)다"라는 것입니다.
- 기존: 테이블은 숫자와 카테고리의 집합일 뿐이다.
- TABULA-8B: 테이블에는 '스키마(Schema)'라는 문법과 '값(Value)'이라는 단어가 있다. 수백만 개의 테이블을 보면, "Age가 30이면 Income이 높을 확률이 크다" 같은 범용적인 패턴(Prior Knowledge)을 학습할 수 있다.
결국 이 논문은 [테이블별 개별 학습] 대신 [범용 테이블 모델 하나로 모든 테이블 처리]를 하자는 것입니다.
7. 기존 방법과의 비교 (Comparative Analysis)
| 비교 항목 | GBDT (XGBoost) | TabPFN | TABULA-8B |
|---|---|---|---|
| 학습 방식 | 타겟 데이터로 매번 학습 | 사전 학습됨 (Transformer) | 사전 학습됨 (LLM 기반) |
| 데이터 스케일 | N/A (데이터별 상이) | 작음 (합성 데이터 위주) | 초거대 (2.1B Rows) |
| Zero-shot | 불가능 | 가능 (작은 데이터 한정) | 가능 (매우 강력함) |
| 속도 | 매우 빠름 | 빠름 | 느림 (LLM 추론 비용) |
TabPFN이 "작은 데이터의 강자"라면, TABULA-8B는 "데이터 크기에 상관없이 범용적으로 작동하는 거인"입니다.
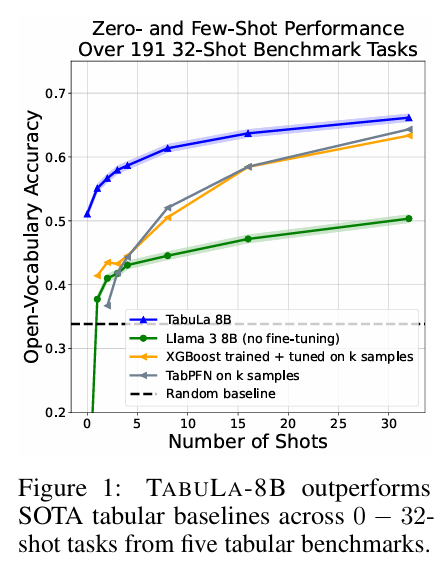
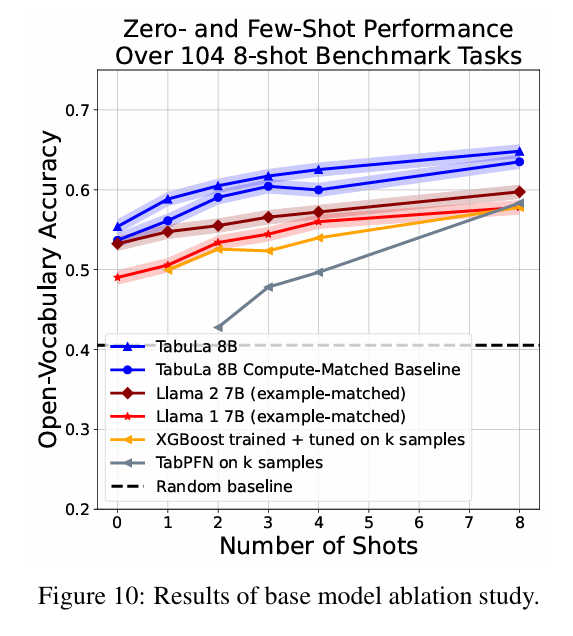
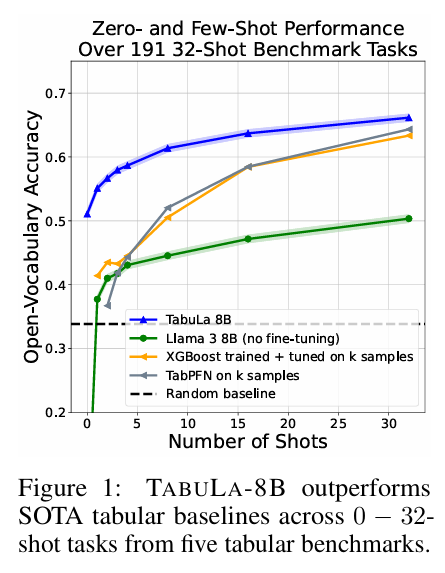
8. 실험 결과에 대한 해석 (Insights from Experiments)
가장 놀라운 결과는 Zero-shot 및 Few-shot 성능입니다.
- Zero-shot: 학습 데이터 없이도 랜덤 추측(Random Guessing)보다 15% 포인트 이상 높은 정확도를 보였습니다. 이는 모델이 이미 세상의 데이터를 어느 정도 이해하고 있음을 의미합니다.
- Few-shot (1~32 shots): 타겟 데이터로 학습한 XGBoost나 CatBoost보다 5~15% 포인트 더 높은 성능을 기록했습니다.
"고작 데이터 10개를 보여줬을 때, XGBoost는 과적합으로 헤매지만 TABULA-8B는 이미 정답을 알고 있다."
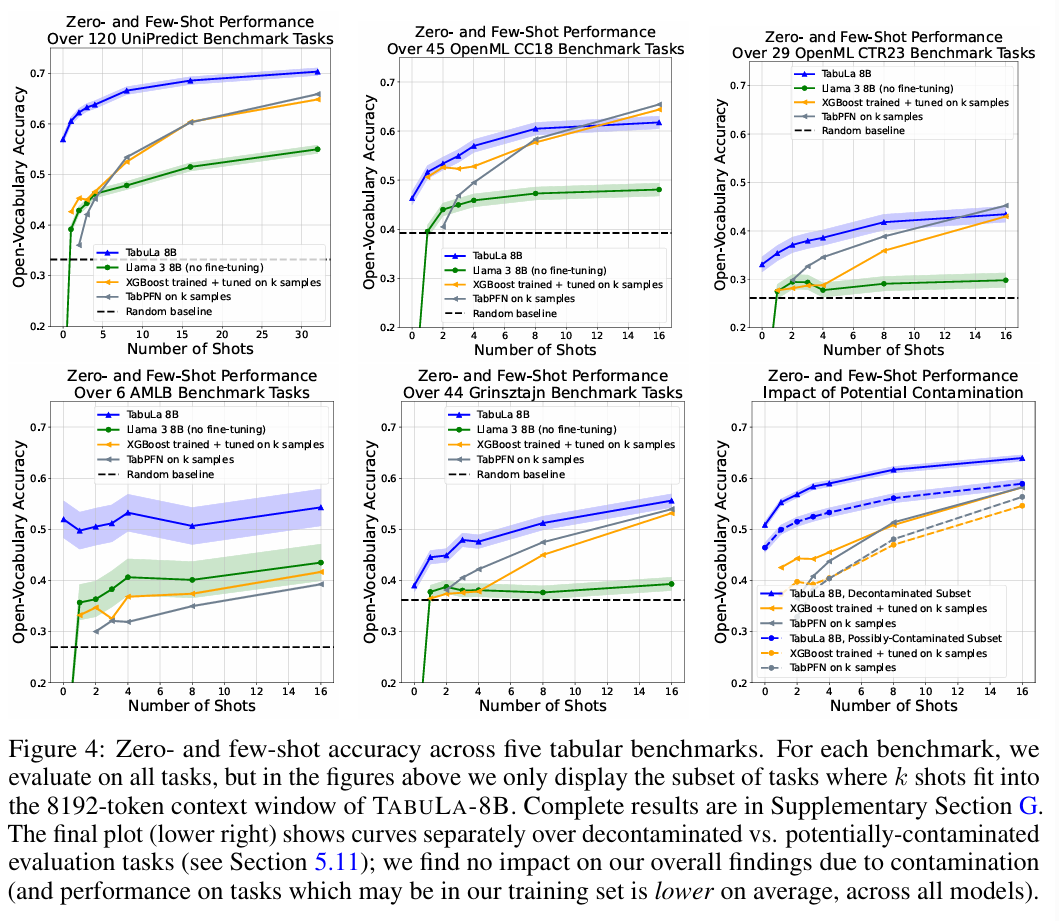
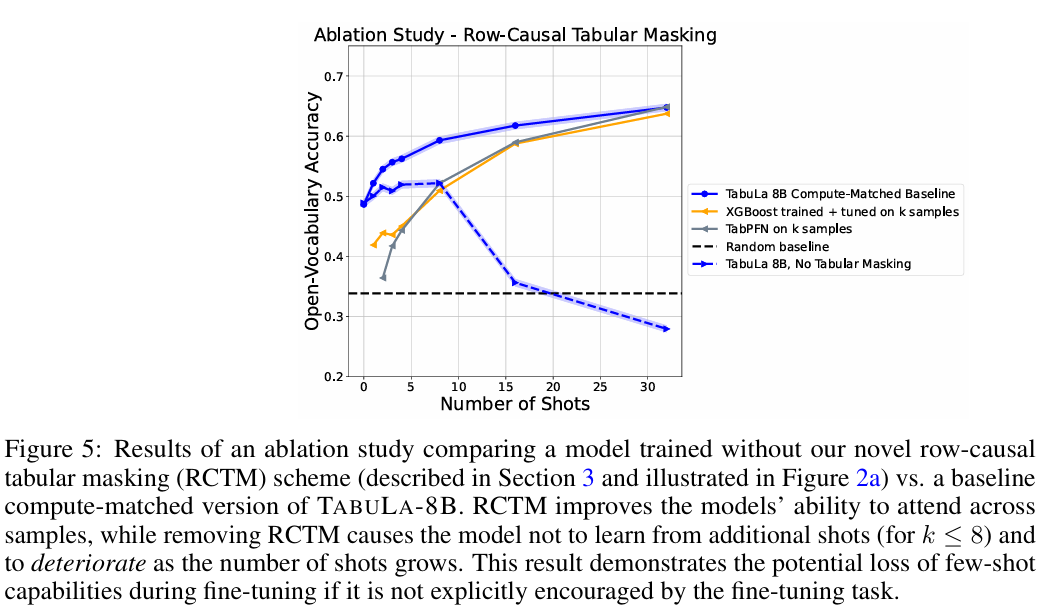
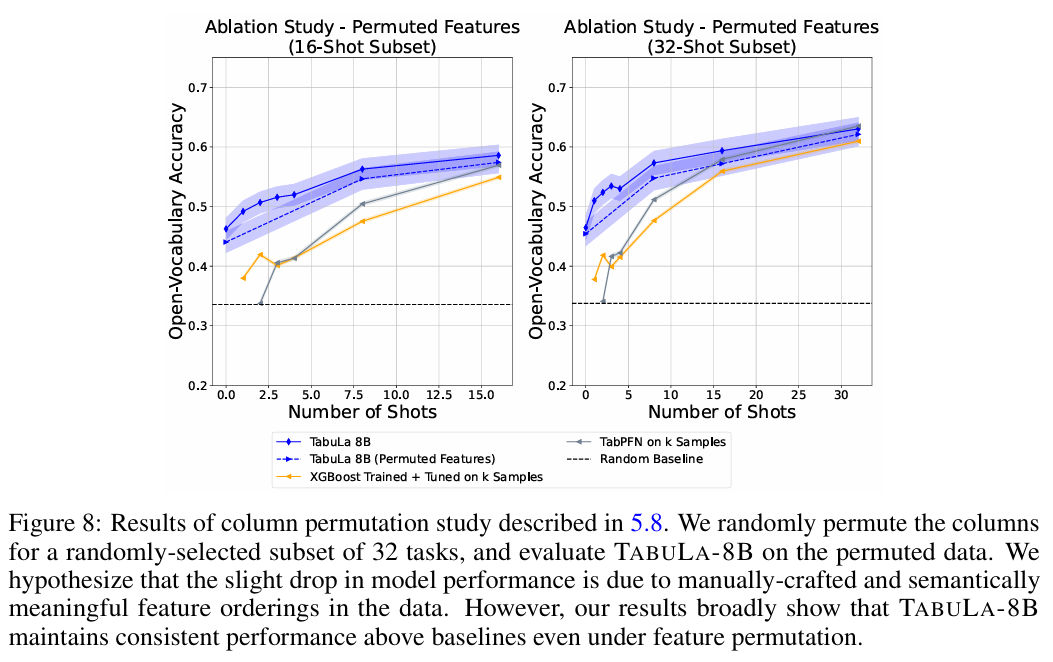
9. 추가 분석 또는 설계 검증 (Ablation Study 등)
-
Column Name의 중요성: 컬럼 이름을 무작위로 섞거나 지웠을 때(x1, x2...), 성능이 떨어지긴 했지만 여전히 높았습니다. 이는 모델이 컬럼 이름의 의미(Semantic)뿐만 아니라, 값들의 분포와 관계(Syntactic)만으로도 추론할 수 있음을 증명합니다.
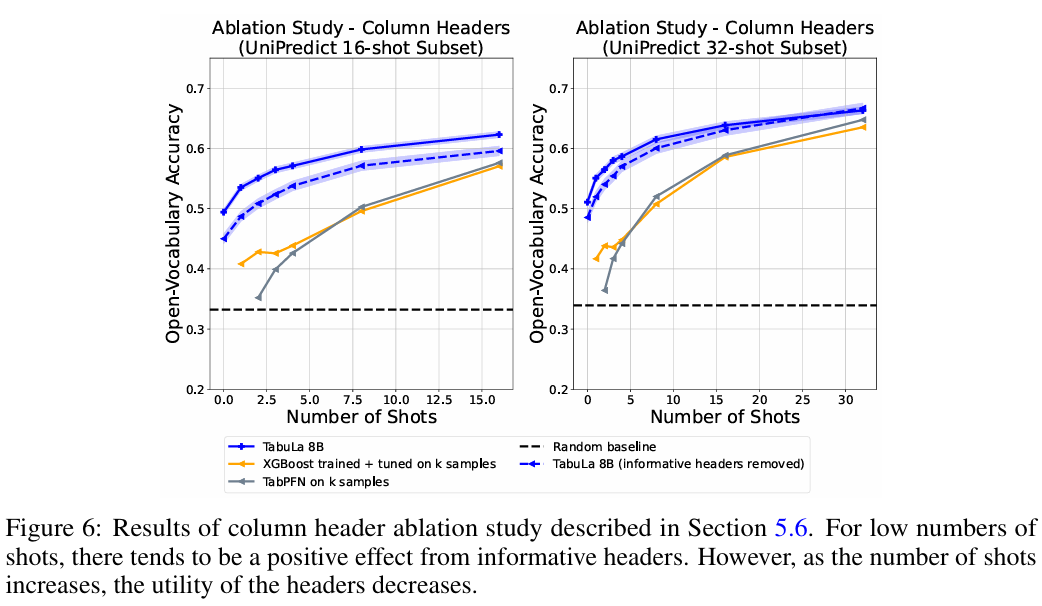
-
Data Scale: 학습 데이터 양을 줄이면 성능이 비례해서 급격히 떨어집니다. 결국 'Scale is all you need'가 정형 데이터에서도 통한다는 것을 보여줍니다.
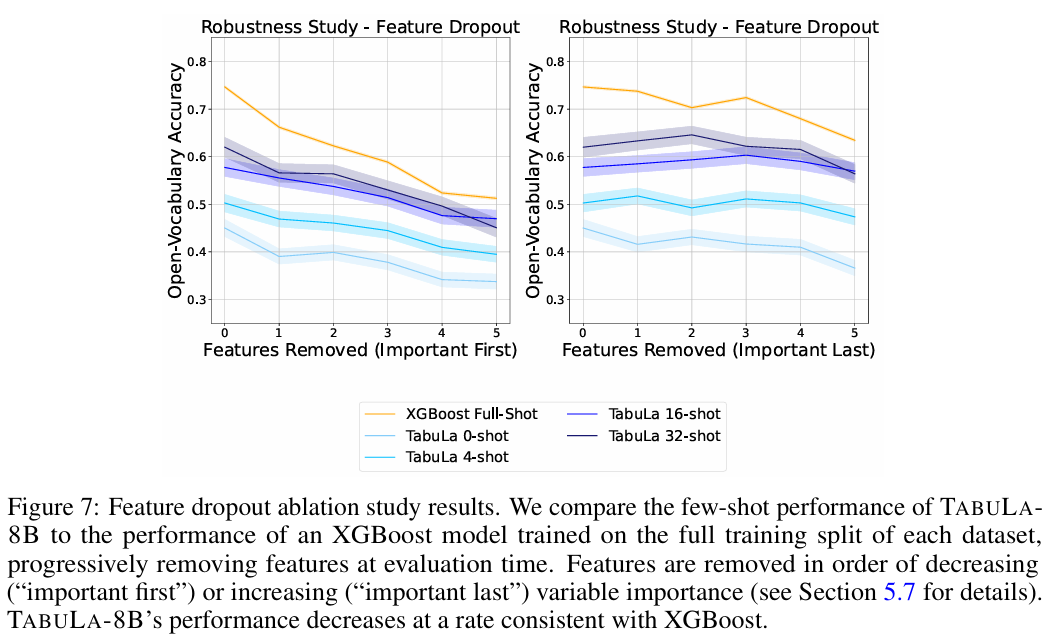

10. 해석 가능성 / 분석 관점 (Interpretability)
LLM 기반이라 명시적인 Feature Importance를 뽑기는 어렵지만, In-Context Learning 과정을 통해 모델이 어떤 예시를 참고했는지 역추적할 수 있습니다. 또한, 컬럼 헤더를 가렸을 때의 성능 변화를 통해 모델이 '도메인 지식'에 의존하는지 '통계적 패턴'에 의존하는지 파악할 수 있는 가능성을 열었습니다.
11. 개인 프로젝트 및 실무 적용 아이디어
이 논문의 아이디어를 제 도메인에 적용한다면 다음과 같은 시도를 해볼 것 같습니다.
- Cold-Start 추천 시스템: 신규 유저나 신규 상품처럼 로그 데이터(History)가 전혀 없는 상황에서, GBDT는 무용지물입니다. 이때 TABULA-8B의 Zero-shot 능력을 활용해 초기 추천 리스트를 생성하는 프로젝트에 적용해 보고 싶습니다.
- 자동화된 데이터 전처리/결측치 채우기: 모델이 컬럼 간의 관계를 이미 알고 있으므로, 값이 비어있는(Missing) 테이블을 입력했을 때 LLM이 가장 그럴듯한 값으로 채워주는 똑똑한 Imputer로 활용해 볼 수 있습니다. (실제 실험에서는 단순 평균 대치보다 훨씬 자연스러울 것입니다.)
12. 장점과 한계 정리
- Strong Point (결정적 한 수): 압도적인 Few-shot 성능. 데이터가 적은 환경(Low-resource setting)에서 GBDT를 이길 수 있는 유일한 대안이 등장했다는 점.
- Weak Point (아쉬운 점): 추론 비용. 8B 모델을 테이블 예측 하나 하려고 띄우는 건 실무(특히 실시간 시스템)에서는 가성비가 매우 떨어집니다. 또한, 수치형 데이터(Regression)에서의 정밀도는 여전히 트리 모델이 우세할 수 있습니다.
13. 현재 시점에서의 정리 (공부 기록 결론)
정형 데이터에서도 드디어 "Foundational Model"의 시대가 열리고 있음을 느꼈습니다.
가장 인상 깊었던 관점:
"테이블 데이터 학습의 핵심은 특정 데이터셋을 잘 맞추는 게 아니라, 수많은 테이블을 통해 '데이터의 일반적인 문법'을 배우는 것이다."
이어서 읽어보고 싶은 논문/키워드:
- 작은 데이터셋에서 Transformer의 가능성을 보여준 TabPFN
- LLM을 정형 데이터에 적용하는 또 다른 접근인 UniPredict
