1. 논문 정보
- 제목: TabTransformer: Tabular Data Modeling Using Contextual Embeddings
- 학회/연도: arXiv 2020 (Amazon AWS)
- 한 줄 요약:
범주형 변수를 단순 숫자로 바꾸지 말고, Transformer를 통해 피처 간 맥락(Context)을 입힌 뒤 섞자는 시도.
2. 이 논문을 읽게 된 계기
정형 데이터(Tabular data)를 다룰 때마다 마주치는 벽이 있었다.
- "왜 딥러닝은 정형 데이터에서 트리 모델(GBDT)을 압도하지 못할까?".
- 이미지나 텍스트는 딥러닝이 이미 정복했는데, 테이블 데이터는 왜 여전히 수동적인 임베딩에 머물러 있나?.
- 트리 모델은 좋지만, 실시간 스트리밍 데이터 학습이나 이미지/텍스트가 섞인 멀티모달 환경에서는 확실히 한계가 느껴졌다.
기존 MLP의 "맥락 없는(Context-free)" 임베딩 방식을 Transformer로 해결했다는 이 논문이 그 해답의 실마리가 될 것 같았다.
3. 처음 읽고 든 인상
솔직히 처음엔 "이제 정형 데이터에도 그냥 BERT를 갖다 붙이는구나" 싶었다.
- "이미 검증된 Transformer 구조를 그대로 쓴 거 아냐?".
- "정형 데이터에 순서(Position)가 없는데 Attention이 의미가 있나?".
그런데 재독을 하면서 Column Embedding이라는 정밀한 설계와, 라벨이 부족한 상황을 타개하기 위한 준지도 학습(Semi-supervised) 전략을 보며 생각이 달라졌다. 이 논문은 단순히 구조를 가져온 게 아니라, 정형 데이터의 '피처 간 관계'를 어떻게 정의할 것인가를 치열하게 고민한 결과물이다.
4. 전체 구조 및 아키텍처 요약
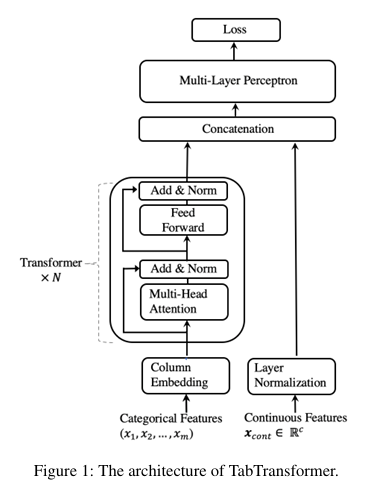
전체 파이프라인은 정밀하게 분리되어 있다.
- 입력 분리: 범주형과 수치형 변수를 나누어 받는다.
- Column Embedding: 각 범주형 피처를 고유한 식별자와 함께 임베딩한다.
- Transformer Layers: 피처들끼리 서로 Attention을 주고받으며 맥락적 임베딩(Contextual Embedding)을 생성한다.
- Concatenation: '똑똑해진' 범주형 임베딩과 레이어 정규화를 거친 수치형 변수를 하나로 합친다.
- Final MLP: 최종 예측(Target )을 수행한다.
즉,
Tabular → feature별 고유 임베딩 → Transformer 기반 관계 학습 → 수치형 변수 결합 → 최종 예측.
5. 주요 구성 요소 상세 설명
(1) Column Embedding
이 모델의 기초 공사다.
- 핵심: 단순히 값을 바꾸는 게 아니라, "이 값이 몇 번째 열(Column)에서 왔는가"를 임베딩에 포함한다.
- Why: 정형 데이터는 텍스트와 달리 열의 순서가 중요하지 않으므로, Positional Encoding 대신 열 자체의 고유 ID를 부여하는 방식을 택했다.
(2) Transformer 기반 Contextual Embedding
| 구분 | 설명 [Why & How] |
|---|---|
| 작동 원리 | Multi-head Self-attention을 통해 "직업" 피처가 "교육 수준" 피처와 어떤 연관이 있는지 스스로 계산한다. |
| 결과물 | 단순한 고정 벡터가 아니라, 다른 피처들과의 관계가 반영된 '살아있는' 벡터가 된다. |
(3) Pre-training (준지도 학습)
라벨이 없는 대규모 데이터를 활용하는 필살기다.
- MLM (Masked Language Modeling): 피처 일부를 가리고 원래 값을 맞추게 학습한다.
- RTD (Replaced Token Detection): 피처 값을 가짜로 바꾸고, 이게 "진짜인지 가짜인지" 맞추게 한다.
6. 핵심 아이디어 (내가 이해한 방식)
저자들이 던지는 근본적인 질문은 이것이다.
"데이터셋에 라벨이 부족할 때, 우리는 어떻게 피처들의 의미를 미리 학습시킬 수 있을까?".
👉 내가 이해한 한 문장 요약:
정형 데이터 학습의 핵심은 피처 하나하나의 값보다, 피처들이 서로 '어떤 맥락'으로 연결되어 있는지를 찾아내는 것이다.
7. 기존 방법과의 개인적인 생각
- 기존 MLP
- 구현은 쉽지만 피처 간의 고차원적인 상호작용을 잡기엔 너무 단순하다 (Context-free).
- GBDT (XGBoost 등)
- 여전히 강력하지만, 신경망처럼 유연한 확장성(멀티모달 등)이 부족하다.
- TabTransformer
- Transformer를 통해 MLP의 단점을 보완하면서 GBDT의 성능에 근접했다.
- 다만, 수치형 Feature는 Transformer에 넣지 않고 나중에 합친다는 점이 실무적으로는 아쉬우면서도 효율적인 선택으로 보인다.
8. 실험 결과에 대한 해석
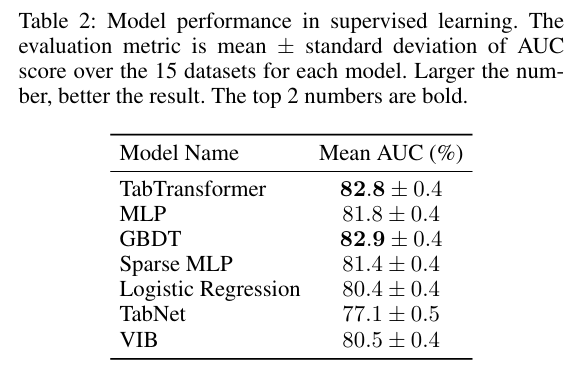
가장 인상적인 수치는 "GBDT와 대등한 성능"과 "노이즈에 대한 강건성"이다.
- 15개 데이터셋에서 평균 AUC 82.8%로 GBDT(82.9%)와 거의 차이가 없다.
- 노이즈가 섞여도 성능 하락폭이 MLP보다 훨씬 적다.
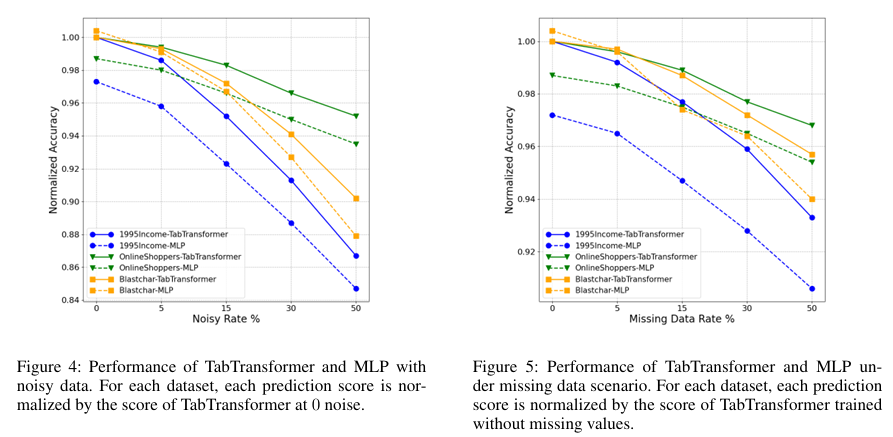
"주변 피처들이 살아있다면, 하나의 피처가 노이즈로 오염되어도 모델은 길을 잃지 않는다".
9. 추가 분석 / 설계 검증 실험
Ablation 실험이 설계의 정당성을 뒷받침한다.
- Column Embedding 유무 → 식별자가 없을 때 성능이 가장 낮았다.
👉 정형 데이터에서도 "어디서 온 정보인가"라는 위치 정보가 핵심임을 확인.
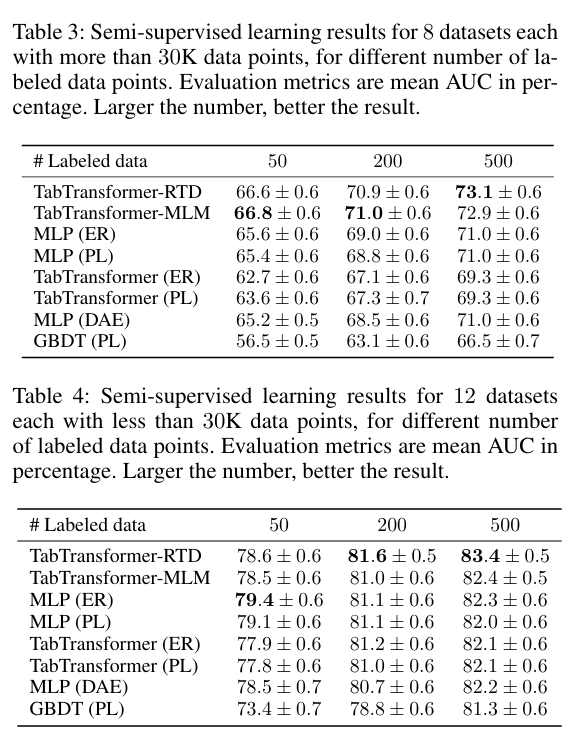
- Pre-training 방식 비교 → 데이터가 많을 땐 MLM/RTD 둘 다 좋지만, 적을 땐 RTD가 미세하게 유리했다.
👉 이진 분류(진짜/가짜 판별)가 멀티 클래스 예측보다 학습하기 쉽기 때문.
10. 해석 가능성 / 분석 관점
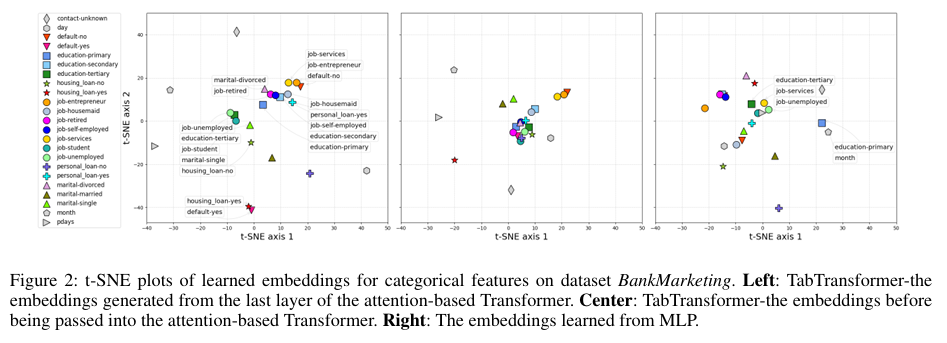
t-SNE 시각화 결과가 꽤 놀랍다.
- Bank Marketing 데이터셋에서 '학생', '미혼', '주택 대출 없음' 같은 클래스들이 임베딩 공간에서 자동으로 군집을 이룬다.
- 사람이 알려주지 않아도 모델이 "아, 이 피처들은 사회경제적으로 비슷한 의미구나"를 스스로 파악했다는 뜻이다.
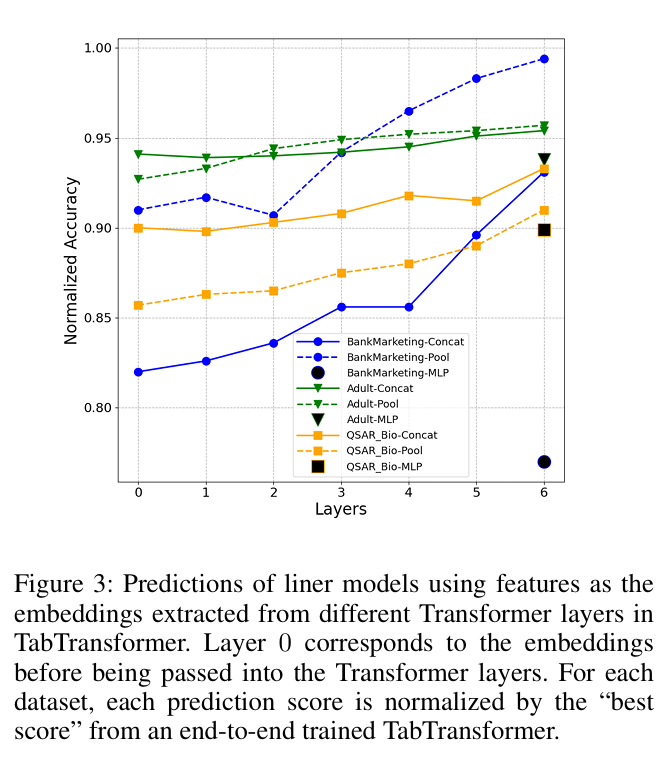
11. 개인 프로젝트 / 실무에의 연결
이 논문의 구조를 참고하여, 실제 개인 프로젝트에서 다음과 같은 변형과 성능 비교 실험을 시도했다.
- Seq 데이터와 LSTM의 결합: 시계열(Seq) 성격이 있는 데이터를 LSTM에 먼저 통과시켜 맥락을 추출했다. 이후 LSTM에서 나온 결과물과 TabTransformer의 범주형 임베딩 결과물을 마지막 Concatenation 단계에서 결합한 뒤, 최종 MLP에 함께 넣어 예측을 수행했다. 이 방식을 통해 정형 데이터의 정적인 상호작용과 시계열 데이터의 동적인 흐름을 동시에 잡아낼 수 있었다.
- 실제 성능 비교 및 아키텍처의 유연성: 하지만 모든 상황에서 트랜스포머가 정답은 아니었다. 일부 실험군에서는 트랜스포머 블록을 거치지 않고 단순히 임베딩하여 Concat 후 넘겼을 때 성능이 더 높게 나오기도 했다. 이는 데이터의 복잡도나 피처 간 상호작용의 깊이에 따라 단순한 모델이 더 효과적일 수 있음을 시사하며, 항상 베이스라인과의 비교가 필수적임을 깨달았다.
- 결측치 대응: 실제 데이터는 노이즈가 많고 누락이 잦은데, TabTransformer의 강건한 특성을 활용해 별도의 복잡한 전처리 없이도 안정적인 모델링이 가능할 것이라는 확신을 얻었다.
12. 장점과 한계 정리
장점
- 범주형 데이터의 맥락적 의미를 딥러닝으로 훌륭하게 해석해냈다.
- 노이즈나 데이터 누락에 매우 강하다.
- 라벨이 적은 환경(준지도 학습)에서 압도적인 효율을 보여준다.
한계 / 의문
- 수치형 변수는 여전히 Transformer의 혜택을 직접적으로 받지 못한다.
- Transformer 특유의 높은 연산 비용(Computational Cost)은 실무 적용 시 고려 대상이다.
13. 현재 시점에서의 정리
이 공부의 결론은 명확하다.
"정형 데이터에서도 이제 '임베딩의 질'이 모델의 성패를 결정한다.".
다음에 더 깊게 파보고 싶은 키워드:
- 수치형 변수까지 Attention에 태우는 FT-Transformer
- 정형 데이터용 Transformer의 끝판왕 격인 SAINT
- ELECTRA의 RTD 구조가 정형 데이터에서 왜 더 효율적인지에 대한 수학적 근거
