1. 논문 정보
- 제목: MultiTab: A Scalable Foundation for Multitask Learning on Tabular Data
- 저자: Dimitrios Sinodinos, Jack Yi Wei, Narges Armanfard
- 소속: McGill University, Mila — Quebec AI Institute
- arXiv: 2511.09970
- 학회: AAAI 2026 (예정)
- 분야: Machine Learning, Tabular Representation Learning, Multitask Learning
한 줄 요약
MultiTab은 다수의 관련 태스크를 동시에 학습하기 위해, feature 토큰과 task 토큰을 결합한 Transformer 기반 아키텍처와 멀티태스크 마스크드 어텐션을 통해 tabular multitask learning의 확장성과 성능을 동시에 개선한 모델이다.
2. 연구 동기
Tabular 데이터는 실제 산업 환경에서 가장 널리 쓰이지만, 멀티태스크 학습(MTL) 관점에서는 상대적으로 연구가 부족했습니다. 기존 접근들은 주로:
- 추천 시스템과 같은 특정 도메인에 국한되거나
- 단순한 MLP 기반 구조에 의존하여
- feature interaction을 충분히 포착하지 못하고
- 태스크 간 경쟁(task interference)을 효과적으로 제어하지 못함
MultiTab은 이러한 한계를 해결하기 위해
Transformer 기반 구조를 tabular MTL에 본격적으로 도입하고,
태스크 간 정보 공유와 분리를 조절할 수 있는 메커니즘을 제안합니다.
3. 전체 아키텍처 개요: MultiTab-Net
MultiTab-Net은 다음 세 가지 핵심 설계로 구성됩니다.
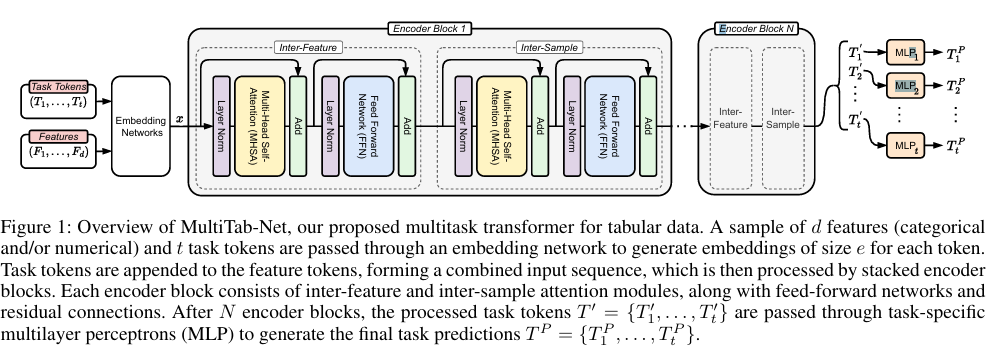
3.1 입력 구조: Feature Token + Task Token
- 각 샘플의 feature 토큰
- 각 예측 목표에 대응하는 task 토큰
을 하나의 입력 시퀀스로 결합하여 Transformer에 전달합니다.
이 설계의 핵심 의도는:
- 각 태스크가 같은 feature를 보되
- 서로 다른 관점에서 feature와 상호작용하도록 만드는 것
즉, 단순한 파라미터 공유가 아니라
task-conditioned representation learning을 가능하게 합니다.
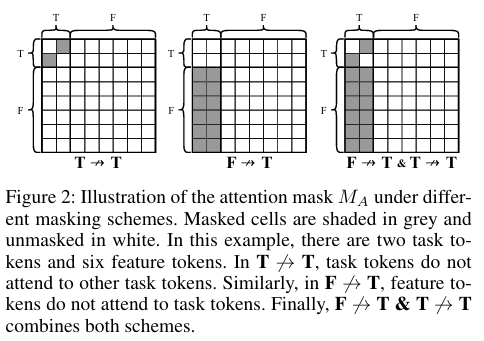
3.2 Multitask Masked Attention
기존 Transformer에서 task token과 feature token이 자유롭게 attention을 주고받을 경우,
태스크 간 불필요한 간섭(task interference)이 발생할 수 있습니다.
MultiTab은 이를 해결하기 위해 멀티태스크 마스크드 어텐션을 제안합니다.
마스킹 설계 예시
- Feature → Task attention 차단
- Task → Task (다른 태스크) attention 차단
- 위 두 가지를 동시에 차단하는 설정 등
이를 통해:
- 태스크 간 경쟁을 완화하고
- 각 태스크가 필요한 feature 정보에 더 집중하도록 유도합니다.



3.3 Inter-Feature & Inter-Sample Attention
MultiTab-Net은 두 가지 상호작용을 동시에 모델링합니다.
- Inter-Feature Attention
→ feature 간 상관관계 및 조합 효과 학습 - Inter-Sample Attention
→ 샘플 간 정보 공유를 통한 일반화 성능 향상
이 두 개는 독립적인 모듈이 아니라,
하나의 attention 연산을 서로 다른 축에서 해석한 개념적 구분입니다.
이를 통해 tabular 데이터에서 중요한
feature interaction + 데이터 분포 구조를 동시에 반영합니다.
4. 핵심 기여 정리
4.1 Transformer 기반 Tabular Multitask Learning
-
기존 MLP 기반 multitask learning 대비
- 더 강한 feature interaction modeling
- 태스크 수 증가에 대한 더 나은 확장성
4.2 Multitask Masked Attention 제안
- 태스크 간 과도한 공유로 인한 성능 저하 문제 완화
- 공유와 분리를 attention 수준에서 명시적으로 제어 가능
4.3 MultiTab-Bench 제안
- 태스크 수, 상관관계, 난이도를 조절 가능한 synthetic benchmark
- 멀티태스크 학습 특성 분석에 유용한 평가 환경 제공
5. 실험 결과 해석
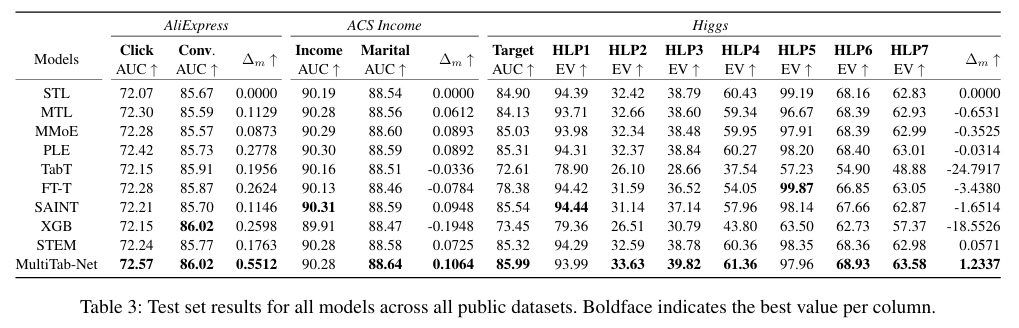
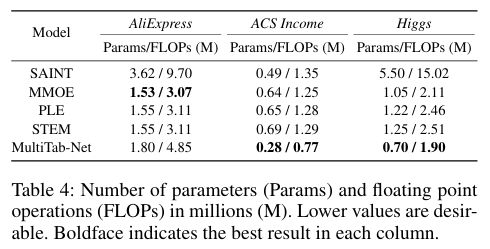
-
다양한 실제 tabular 데이터셋에서
- MLP 기반 multitask 모델 대비 일관된 성능 향상
-
태스크 수가 많거나
-
태스크 간 상관관계가 높을수록 성능 이점이 더욱 뚜렷
-
Synthetic benchmark를 통해
- 태스크 경쟁과 공유 효과를 정량적으로 분석
이 결과들은 단순 성능 향상보다는,
태스크 수 증가에도 표현이 안정적으로 유지됨을 보여줍니다.
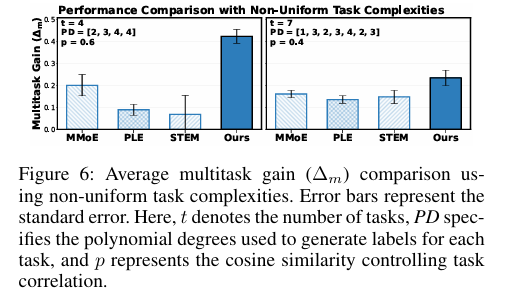
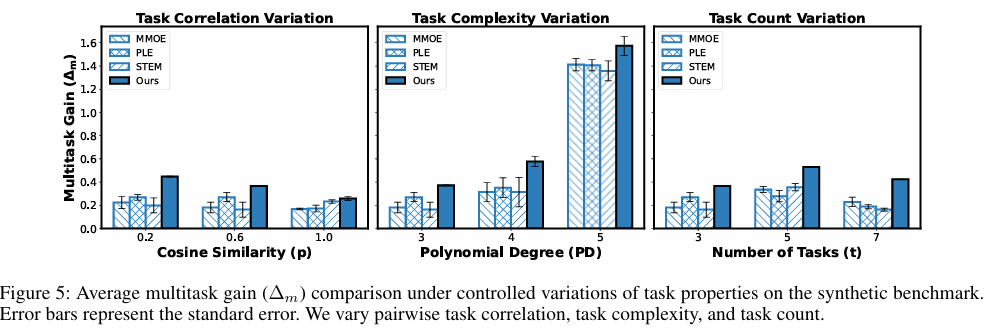
6. 장점과 한계
장점
- Transformer 기반으로 feature interaction 학습 능력 우수
- 태스크 경쟁을 제어하는 명시적 구조적 메커니즘
- 대규모 멀티태스크 환경에 대한 확장성
한계
- Attention 기반 구조로 인한 연산 비용 증가
- Mask 설계가 경험적이며 이론적 일반화 보장은 제한적
- 표준화된 tabular multitask benchmark 부족
7. 개인적 해석 및 위치 정리
MultiTab은
“tabular 데이터를 여러 태스크 관점에서 동시에 해석하기 위한 기반 모델”
로 해석할 수 있습니다.
단일 태스크 성능 극대화보다는,
- 여러 관련 예측 목표가 공존하는 현실적인 환경에서
- 구조적 feature interaction과 태스크 간 경쟁을 함께 고려
하는 방향의 연구입니다.
8. TabGLM과의 관점 차이 (짧은 비교)
| 관점 | TabGLM | MultiTab |
|---|---|---|
| 핵심 문제 | 표현 일반화 | 태스크 경쟁 |
| 접근 방식 | 멀티모달 정렬 | 멀티태스크 구조 제어 |
| 핵심 도구 | Graph + Text consistency | Task token + Masked Attention |
| 초점 | Representation learning | Multitask optimization |
마무리 한 문장
MultiTab은 “얼마나 많이 공유할 것인가”가 아니라
“공유를 어떻게 통제할 것인가”를 처음으로 구조적으로 다룬 tabular multitask Transformer이다.
