[논문 리뷰] TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization
논문 리뷰
1. 논문 정보
- 제목: TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization
- 저자: Anay Majee, Maria Xenochristou, Wei-Peng Chen
- 소속: Fujitsu Research of America, The University of Texas at Dallas
- arXiv: 2502.18847
- 분야: Machine Learning, Tabular Representation Learning
한 줄 요약
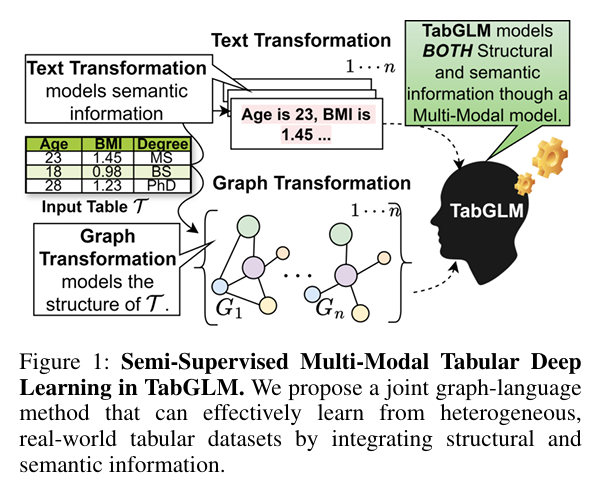
TabGLM은 tabular 데이터를 ‘구조적 그래프’와 ‘의미적 텍스트’라는 두 개의 뷰로 변환하고, 이 두 표현을 멀티모달 일관성 학습(MuCOSA)으로 정렬하여 전이 가능하고 일반화 성능이 높은 tabular representation을 학습하는 모델이다.
2. 이 논문을 읽게 된 계기
-
Tabular 데이터는
- 구조적 정보 (feature interaction, correlation)
- 의미적 정보 (feature name, categorical semantics)가 명시적으로 분리되지 않은 채 혼재
-
기존 DL 접근은
- 벡터화된 입력만 보고
- 구조와 의미를 암묵적으로 학습하도록 강제
👉 TabGLM은 이 문제를 “표현 공간을 분리해서 보자”는 멀티뷰/멀티모달 관점으로 재정의한 논문입니다.
3. 첫 인상에 대한 재해석
“Tabular을 graph나 text로 변환하는 것이 정말 일반적인가?”
TabGLM의 핵심은
❌ “Tabular는 원래 graph/text다”
⭕ “Tabular를 다른 inductive bias를 가진 표현 공간으로 투영하면 더 많은 정보를 끌어낼 수 있다”
즉, 입력 변환이 목적이 아니라 표현 정렬이 목적입니다.
4. 전체 구조 및 아키텍처
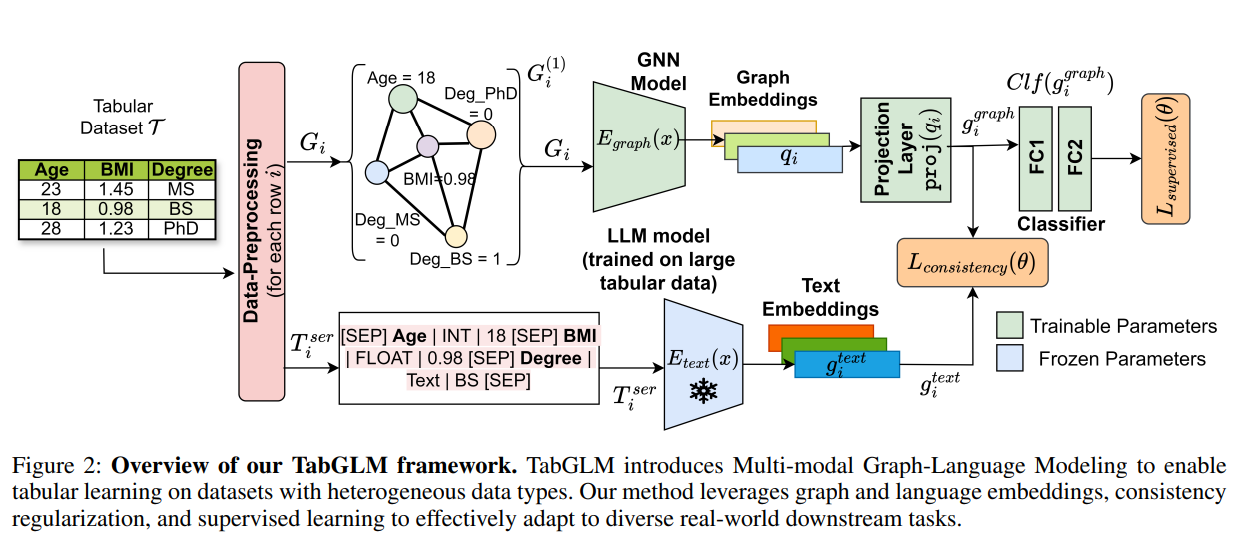
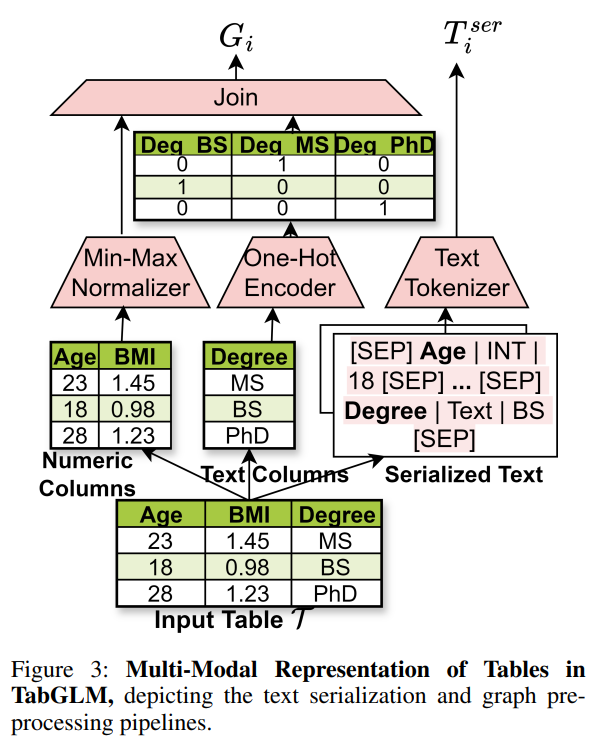

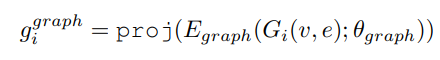
(1) 입력 변환: Multi-View Construction
🔹 구조적 변환 → Graph View
- 각 row(record) → fully connected graph
- 노드: feature
- 엣지: feature 간 관계 (학습 가능)
- 결과: 각 레코드가 하나의 그래프 ( G_i )
이 뷰는 feature interaction과 구조적 의존성을 명시적으로 모델링
🔹 의미적 변환 → Text View
-
각 row를 자연어로 직렬화
"Age is 45, Income is high, Job is engineer, ..." -
Feature name + value를 포함
-
사전학습된 tabular-aware text encoder (TAPAS/TAPEX) 사용
이 뷰는 feature의 의미, 범주적 맥락, 언어적 prior를 활용
(2) 모달리티별 Encoder
| 모달리티 | 인코더 | 역할 |
|---|---|---|
| Graph | GNN | 구조적 상호작용 학습 |
| Text | Frozen pretrained LM | 의미적 정보 주입 |
- 텍스트 인코더를 동결(frozen)한 점이 중요
→ TabGLM의 성능은 “LLM 미세조정”이 아니라 정렬 학습 효과임을 강조
(3) Multi-Modal Consistency Minimization (MuCOSA)
핵심 목적:
“같은 레코드를 설명하는 두 표현이 의미적으로 일치하도록 하자”
좋은 포인트야.
여기서는 “loss가 왜 필요한지 / 각 loss가 표현 공간에서 무슨 역할을 하는지”를 분명히 해주면 글의 밀도가 확 올라가.
아래는 네가 쓴 구조를 최대한 유지하면서,
loss의 의미·역할·효과가 드러나도록 다듬은 버전야.
손실 구성
-
Consistency Loss (Multi-Modal Consistency Loss)
-
동일한 레코드에 대해 생성된
그래프 임베딩 ( ) 과
텍스트 임베딩 ( ) 이
표현 공간에서 서로 가깝도록 유도하는 손실 -
목적은 단순한 거리 감소가 아니라,
- 그래프가 포착한 구조적 관계(feature interaction) 와
- 텍스트가 담고 있는 의미적 prior(feature semantics) 가
같은 의미를 설명하도록 정렬(alignment) 하는 것
-
이 손실은 그래프 표현에 대해
“의미적으로도 말이 되는 구조 표현” 이 되도록 정규화(regularization) 역할을 수행함
-
-
Downstream Task Loss (supervised loss)
-
정렬된 표현이 실제 분류/회귀 목표에 유용하도록 보장하는 지도 손실
-
Consistency Loss만 사용할 경우 발생할 수 있는
- 표현 붕괴(representation collapse)
- task-irrelevant alignment
를 방지하고,
task-discriminative information을 유지하도록 함
-
👉 두 손실의 결합은
- Contrastive learning 관점에서는
“서로 다른 모달리티에서 같은 샘플을 positive pair로 묶는 효과”를 가지며, - Representation regularization 관점에서는
“그래프 기반 표현이 LLM의 의미적 공간에서 벗어나지 않도록 제약을 거는 역할”을 수행한다.
즉, TabGLM의 학습 목표는
그래프와 텍스트 표현을 단순히 합치는 것이 아니라,
서로 의미적으로 일관된 하나의 표현 공간으로 수렴시키는 것이다.
한 줄로 정리
Consistency Loss는 그래프 표현을 의미적으로 정제하고,
Task Loss는 그 정제된 표현이 실제 예측에 유용하도록 고정한다.



5. 핵심 아이디어 재정의
당신의 이해를 연구적 언어로 재정리하면:
TabGLM은 tabular 데이터를 단일 표현으로 압축하지 않고,
구조적 inductive bias(GNN) 와 의미적 inductive bias(LLM) 를 각각 최대한 활용한 뒤,
두 표현을 정렬함으로써 modality-invariant representation을 학습한다.
이는 다음 흐름에 위치합니다:
- Multi-view learning
- Cross-modal alignment
- Self-supervised regularization for tabular DL
6. 기존 방법 대비 위치 정리
| 관점 | 기존 Tabular DL | TabGLM |
|---|---|---|
| Input bias | 벡터 | 구조 + 언어 |
| Feature interaction | 암묵적 | GNN으로 명시적 |
| Semantics | 약함 | LLM prior 활용 |
| Generalization | dataset-specific | transfer-friendly |
| 학습 전략 | 단일 loss | consistency + task |
👉 “모델 구조 혁신”보다는 “표현 학습 패러다임 전환”에 가깝다는 점이 중요합니다.
7. 실험 결과에 대한 해석
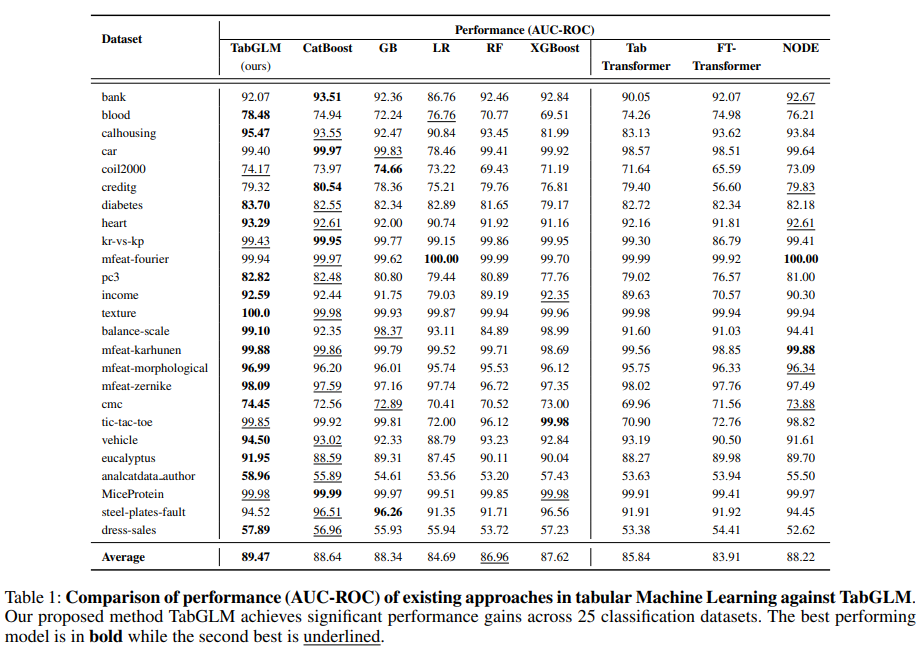
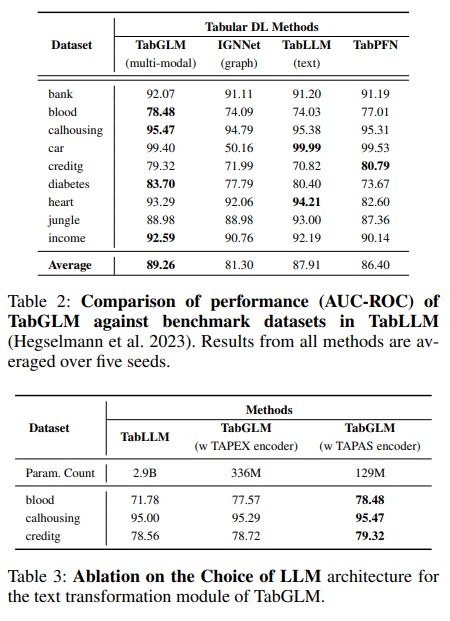
✔ 성과
- 25개 이상 데이터셋에서 평균 AUC-ROC +5% 내외
- 특히 데이터가 작거나 feature 의미가 중요한 경우 강점
⚠ 해석 시 주의점
- Tree-based (CatBoost 등)를 항상 이기지는 않음
- 성능 이득의 상당 부분은
→ “텍스트 prior + 정렬 regularization”
즉, TabGLM은 DL이 약한 tabular 영역을 보완하는 방향이지,
GBDT를 완전히 대체하는 해법은 아님.
8. 장점과 한계
✅ 강점
- 구조 + 의미를 동시에 고려한 가장 명확한 설계
- LLM을 feature generator가 아닌 semantic anchor로 사용
- representation transfer 가능성 높음
⚠ 한계
- Fully-connected graph → high-dimensional feature에서 비용 큼
- Text serialization은 여전히 heuristic
- LLM choice에 성능 의존
9. 개인적 결론 + 연구적 의미
TabGLM은 “tabular 데이터를 어떻게 표현할 것인가”라는 질문을 다시 정의한 논문이다.
-
표를 벡터로 보는 시대 → 표를 다중 시각으로 해석하는 시대
-
이후 연구 방향:
- Sparse / learned graph construction
- Better serialization strategies
- Contrastive rather than distance-based alignment
10. 이어서 보면 좋은 연구 흐름
- Multi-view representation learning
- Graph–Text alignment
- Cross-modal contrastive learning
- Tabular + LLM hybrid models
