1. 배경 및 문제 정의
로봇 비전-운동 정책(Visuomotor Policy) 학습은 시각적 관측값을 로봇의 제어 명령으로 변환하는 모방 학습(Imitation Learning)의 핵심 과제입니다. 하지만 로봇 제어 데이터는 인간 시연자의 다양한 의사결정이 섞인 다중 모달리티(Multimodal distribution), 행동 간의 순차적 상관관계(Sequential correlation), 그리고 높은 정밀도(High precision)를 요구한다는 점에서 일반적인 지도 학습보다 훨씬 까다롭습니다.
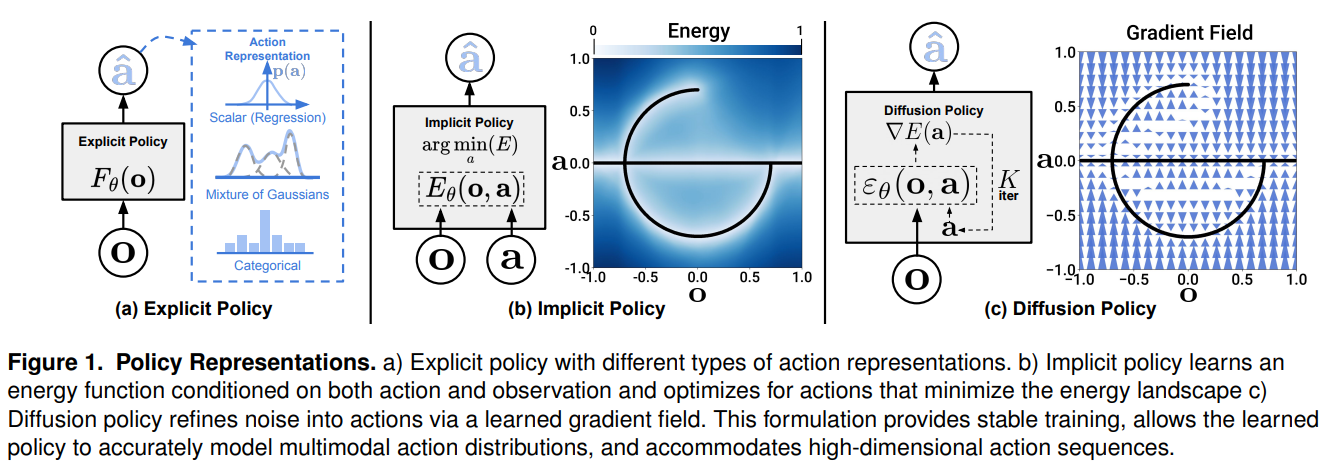
기존 연구들은 주로 두 가지 방향으로 접근했습니다. 첫째, 상태를 행동으로 직접 매핑하는 명시적 정책(Explicit Policy)입니다. GMM(Gaussian Mixture Model)이나 행동 공간을 이산화(Quantization)하는 방식을 사용했으나, 모드 붕괴(Mode collapse)가 발생하거나 고차원 연속 제어에서 정밀도가 떨어지는 한계가 있었습니다. 둘째, 암시적 정책(Implicit Policy)은 관측과 행동의 결합 분포에 대한 에너지 함수(Energy function)를 학습하고 최소 에너지를 갖는 행동을 최적화하여 탐색하는 방식(예: IBC)입니다. 다중 모달리티 표현에는 유리하지만, 에너지를 정규화(Normalization)하기 위해 음성 샘플링(Negative sampling)을 강제해야 하므로 학습의 불안정성이 매우 크다는 치명적인 문제가 있었습니다.
이 논문은 학습의 안정성을 보장하면서도 고차원의 다중 모달 행동 분포를 완벽하게 표현할 수 있는 새로운 접근법인 'Diffusion Policy(확산 정책)'를 제안합니다. 로봇의 행동 생성을 조건부 노이즈 제거 확산 과정(Conditional Denoising Diffusion Process)으로 모델링하여 기존의 한계점들을 근본적으로 해결하고자 합니다.
2. 제안 방법 (Method)
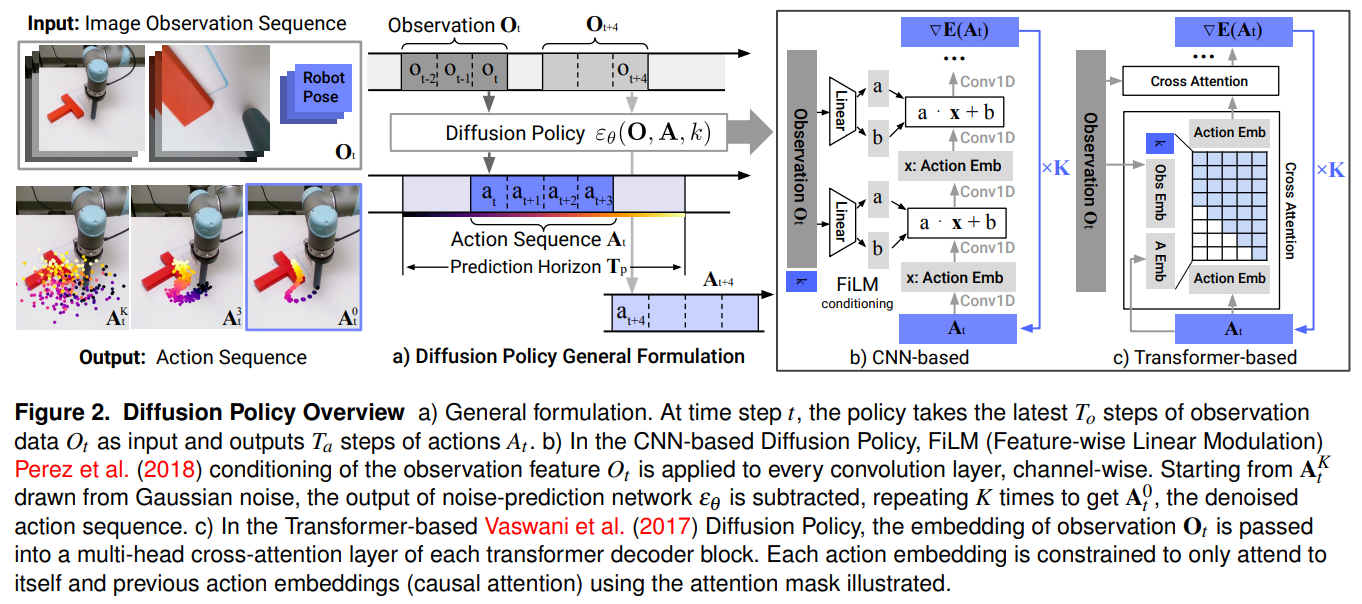
Diffusion Policy의 핵심 아이디어는 정책이 특정 행동(Action)을 직접 출력하거나 에너지 값을 예측하는 대신, 시각적 관측값에 조건화된 행동 분포의 스코어 함수 기울기(Gradient of the action-score function)를 학습하는 것입니다. 이후 완전한 노이즈 상태에서 시작하여 확률적 랑주뱅 동역학(Stochastic Langevin Dynamics)을 통해 점진적으로 노이즈를 제거하며 유효한 행동 궤적을 생성합니다.
입력 데이터 표현 및 전처리 방식
입력 데이터는 특정 시점 를 기준으로 최근 시점 동안의 관측값 (이미지 및 로봇 상태)와 예측할 시점 동안의 행동 시퀀스 로 구성됩니다. 이미지 데이터는 각각 분리된 시각 인코더(ResNet-18)를 통과하여 하나의 잠재 표현(Latent embedding)으로 결합됩니다. 이때 공간 정보를 유지하기 위해 Global Average Pooling 대신 Spatial Softmax를 사용하며, 확산 모델의 EMA(Exponential Moving Average)와 충돌하지 않도록 BatchNorm 대신 GroupNorm을 적용합니다. 모든 행동 데이터는 DDPM의 클리핑 안정성을 위해 각 차원별로 범위를 갖도록 독립적으로 정규화(Normalization)되어 네트워크에 주입됩니다.
모델 세부 구조 (Network Architecture, Diffusion Policy)
논문은 두 가지 뼈대(Backbone) 아키텍처(노이즈를 예측하는 두 가지 방법)를 제시합니다.
1. CNN 기반 (1D Temporal CNN): 관측 특징 와 확산 반복 단계 를 FiLM(Feature-wise Linear Modulation) 채널 조건화 기법을 통해 매 합성곱 계층마다 주입합니다. 속도가 빠르고 튜닝이 거의 필요하지 않은 안정성을 지닙니다.
2. Transformer 기반 (Time-series Diffusion Transformer): minGPT 구조를 차용하여 행동의 급격한 변화나 고주파 신호를 포착하는 데 특화되었습니다. 노이즈가 섞인 행동 가 디코더의 입력 토큰으로 들어가며, 확산 단계 는 첫 번째 토큰으로 추가됩니다. 관측값 는 MLP를 거쳐 Multi-head Cross-attention 계층의 키(Key)와 값(Value)으로 작용합니다.
학습(Training) 및 추론(Inference) 파이프라인
- 학습 단계: EBM(Energy-Based Model)의 다루기 힘든 분배 함수 를 계산할 필요 없이, Score Matching을 통해 노이즈를 예측하도록 학습합니다. 데이터셋에서 실제 행동 시퀀스 를 추출하고, 임의의 단계 에 해당하는 가우시안 노이즈 를 더해 오염된 행동 를 만듭니다. 신경망 는 관측값 를 조건으로 이 노이즈를 예측합니다. 손실 함수는 다음과 같이 정의됩니다.
- 추론 단계: 가우시안 노이즈로 채워진 에서 출발합니다. 학습된 를 사용해 번의 반복적인 노이즈 제거 단계를 거칩니다. 업데이트 수식은 다음과 같습니다.추론 시에는 DDIM(Denoising Diffusion Implicit Models)을 적용하여 100번의 학습 스텝을 10~16번의 추론 스텝으로 압축해 실시간성을 확보합니다. 이렇게 생성된 길이의 행동 시퀀스 중 처음 (Action Execution Horizon) 단계만 로봇에 실행하고, 다시 관측값을 받아 전체 궤적을 재계획하는 후퇴 구간 제어(Receding Horizon Control)를 수행합니다.
이러한 구조는 단일 스텝 행동 예측에서 발생하는 지터링(Jittering)을 막고 행동의 시간적 일관성(Temporal consistency)을 보장하며, 기존 암시적 정책 방법 대비 월등히 안정적인 학습 수렴성을 제공합니다.
3. 실험 결과 (Experiments)
평가는 Robomimic, Push-T, Block Pushing, Kitchen 등 4개의 벤치마크에 속한 15개 태스크에서 수행되었습니다. 베이스라인 모델로는 LSTM-GMM, IBC, BET가 사용되었습니다.
실험 결과, Diffusion Policy는 모든 환경과 태스크에서 기존 최고 성능 알고리즘 대비 평균 46.9% 향상된 성공률을 기록했습니다.
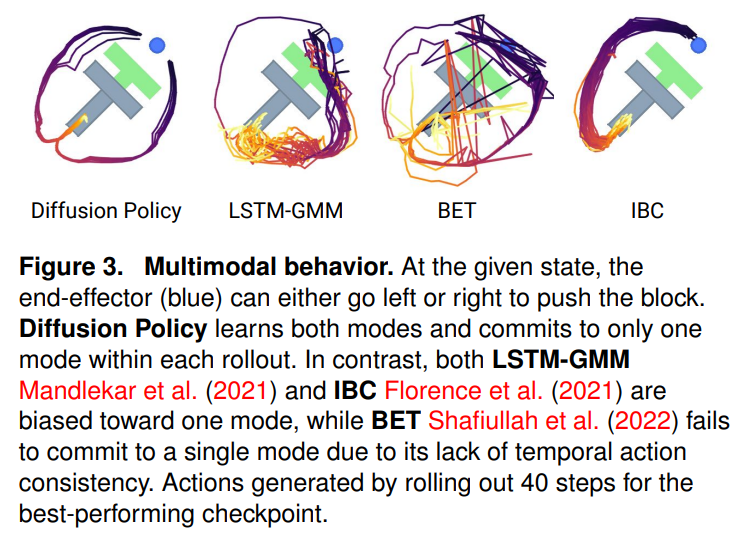
- 다중 모달리티 표현: Push-T 환경과 같은 단기 다중 모달리티(동일한 목표로 가는 여러 경로)는 물론, Kitchen 환경과 같은 장기 다중 모달리티(서브 태스크의 순서가 무작위인 경우)에서도 다른 방법론과 달리 특정 모드에 붕괴되지 않고 유연하게 행동을 결정했습니다.
- 위치 제어(Position Control)와의 시너지: 기존 모델들은 속도 제어에서 성능이 좋았던 반면, Diffusion Policy는 위치 제어 공간에서 압도적인 성능을 보였습니다. 궤적 기반의 시퀀스 예측()을 수행하기 때문에 속도 제어의 고질적 문제인 누적 오차(Compounding error)를 효과적으로 극복할 수 있었기 때문입니다.
- 실제 로봇(Real-world) 실험: 단일 팔(UR5)을 이용한 소스 붓기, 양팔(Franka)을 이용한 셔츠 접기 등의 고난도 태스크에서 인간과 유사한 성공률(최대 95%)을 달성했습니다. 의도적인 시야 가림이나 물체 위치 교란이 발생해도 즉각적으로 궤적을 수정하는 강력한 강건성을 보였습니다.
4. 한계점 및 시사점
한계 및 제약 조건
가장 명확한 한계는 연산량과 추론 지연(Inference Latency)입니다. 단일 전방 전달(Forward pass)로 끝나는 명시적 정책 대비 반복적인 노이즈 제거 과정이 필수적이므로, 컴퓨팅 자원이 제한된 환경이나 초고속 제어 주기(High-rate control)가 필요한 시스템에서는 적용이 어렵습니다. 또한 모방 학습 기반이므로 제공된 시연 데이터의 품질과 양에 성능이 전적으로 의존한다는 근본적 한계를 공유합니다.
엔지니어링적 과제
실제 로봇 환경에 배포할 때는 안전을 위해 확산 모델이 내뱉는 고차원 궤적 명령과 물리적 로봇 관절 사이를 매끄럽게 연결해 주는 미들 레벨 컨트롤러(IK, Collision Avoidance 기능 등)의 설계가 필수적으로 요구됩니다. 또한 Transformer 기반 백본은 하이퍼파라미터(Attention Dropout, Weight Decay 등)에 민감하게 반응하여 정밀한 튜닝이 수반되어야 합니다.
연구의 시사점
이 논문은 이미지 생성 분야에서 증명된 확산 모델의 강력한 분포 모델링 능력이 로봇 제어의 연속적이고 복잡한 행동 공간에서도 완벽하게 동작할 수 있음을 체계적으로 증명했습니다. 향후 Consistency Models 등 최신 샘플링 가속 기법이 도입되거나, 강화학습(RL) 파이프라인과 결합하여 비최적(Suboptimal) 데이터를 활용하게 된다면 실시간 범용 로봇 제어 정책의 표준으로 자리 잡을 수 있는 확장성을 제시합니다.
