0. 3줄 요약
- 기본 정보: 본 논문은 "Spatial Forcing: Implicit Spatial Representation Alignment for Vision-Language-Action Model" (Fuhao Li 외, 2025년 10월)으로, 2D 시각 정보에 국한된 VLA 모델의 공간 인지 한계를 극복하기 위해 제안되었습니다.
- 목적 및 방법: 명시적인 3D 센서 데이터(Depth/Point Cloud) 없이, 사전 학습된 3D 파운데이션 모델(VGGT)의 기하학적 표현을 VLA의 중간 시각 임베딩과 정렬(Alignment)함으로써 3D 공간 이해 능력을 암시적으로 강제(Forcing)합니다.
- 성과 및 의의: 추론 시 추가 연산 부하 없이 기존 2D 및 3D VLA를 능가하는 SOTA 성능을 달성했으며, 학습 속도를 3.8배 가속하고 극단적인 데이터 효율성을 입증하여 실제 로봇 환경 적용의 범용성과 확장성을 크게 넓혔습니다.
1. 배경 및 문제 정의
로봇 조작 분야에서는 언어 명령을 이해하고 물리적 제어를 수행하는 Vision-Language-Action (VLA) 모델이 핵심으로 자리 잡고 있습니다. 하지만 현재 대부분의 VLA 모델은 2D 시각 데이터로만 사전 학습된 Vision-Language Model (VLM)을 백본으로 사용하기 때문에, 3D 물리 세계의 동적인 구조와 기하학적 관계를 정확히 추론하는 능력이 결여되어 있습니다.
기존 연구들은 이를 해결하기 위해 두 가지 주요 접근 방식을 취해왔습니다. 첫째는 뎁스 카메라나 라이다(Lidar)를 통해 깊이 맵이나 포인트 클라우드를 모델에 명시적으로 주입하는 방식입니다. 둘째는 2D 이미지 기반의 깊이 추정기(Depth estimator)를 활용해 3D 정보를 추정하는 방식입니다. 그러나 이러한 방식들은 치명적인 한계를 지닙니다. 센서 데이터는 노이즈가 많고 이질적이며, 기존의 거대한 로봇 데이터셋의 상당수는 3D 정보를 포함하고 있지 않아 확장성이 제한됩니다. 또한 깊이 추정기를 사용할 경우 추정기의 제한된 성능이 곧 전체 조작 성능의 병목이 됩니다. 실제로 논문에서 수행한 Depth Probing 실험에 따르면, 기존 VLA의 시각 임베딩은 유의미한 공간 구조를 전혀 형성하지 못하는 것으로 나타났습니다.
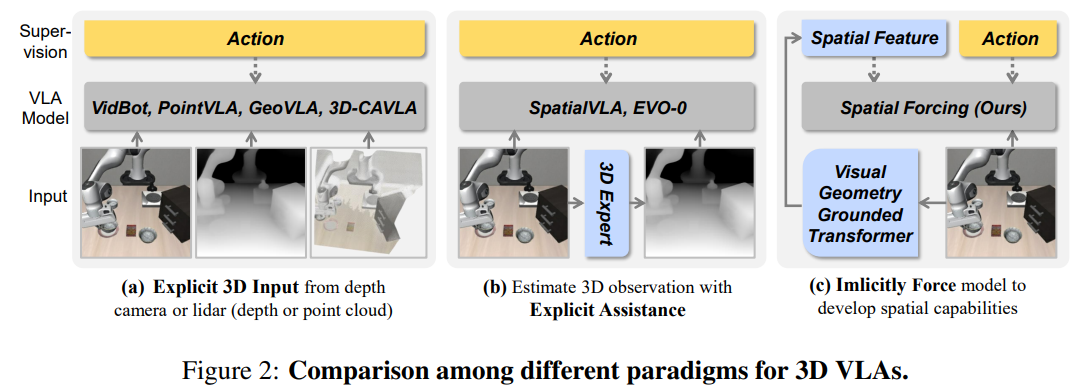
따라서 본 논문은 "외부 3D 센서 데이터나 불안정한 깊이 추정기에 의존하지 않고, VLA 모델 내부의 시각적 표현이 암시적(implicitly)으로 3D 공간 인지 능력을 갖추도록 학습시킬 수 있는가?"라는 핵심 문제를 정의하고 이를 해결하고자 합니다.
2. 제안 방법 (Method)
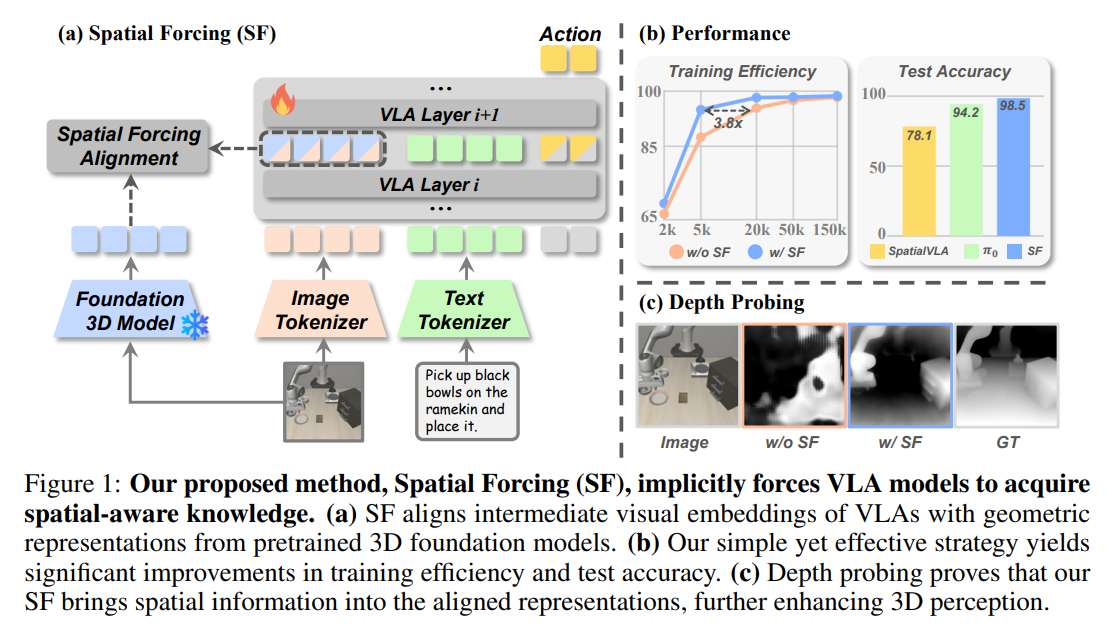
본 논문의 핵심 아이디어는 외부의 강력한 3D 파운데이션 모델이 추출한 정교한 3D 기하학적 표현을 정답지(Supervision signal)로 삼아, VLA 모델 내부의 중간 시각 토큰들이 이를 모방하도록 강제(Forcing)하는 것입니다. 이를 통해 VLA는 자기회귀(Auto-regressive) 생성 과정에서 공간 정보가 풍부하게 담긴 시각 토큰을 바탕으로 더욱 정밀한 행동(Action) 토큰을 생성할 수 있습니다.
데이터 표현 및 전처리 방안
로봇이 수집한 다중 시점(Multi-view) 2D 이미지 는 학습 과정에서 두 갈래의 네트워크로 입력됩니다. 첫째, 입력 이미지 는 사전 학습된 3D 파운데이션 모델인 VGGT()를 통과하여 픽셀 수준의 공간 표현인 를 생성합니다. 이때 VLA의 자기회귀 특성상 공간적 위치 순서가 매우 중요하므로, 타겟 공간 표현에 위치 임베딩(Positional embedding) 를 더하여 최종 정답 신호 를 구축합니다.
둘째, 동일한 이미지가 VLA 내부의 시각 인코더(SigLIP, DINOv2 등)를 거쳐 개의 시각 토큰 으로 변환되며, 이 토큰들은 후속 트랜스포머 레이어를 통과하며 언어 토큰과 함께 연산됩니다.
아키텍처의 세부 구조 및 핵심 수식
VLA 모델의 는 단순히 얕은 층이 아닌, 충분히 깊은 특정 트랜스포머 중간 층(본 논문에서는 32개 층 중 24번째 층이 최적)에서 추출됩니다. 시각 특성이 모달리티에 종속되지 않는 수준으로 융합되기 직전의 층을 활용하는 것이 핵심 엔지니어링 디테일입니다. 추출된 시각 토큰 는 타겟 공간 표현과 피처 차원(Feature dimension)을 맞추기 위해 배치 정규화(Batch Normalization, )와 2-Layer MLP를 차례로 통과합니다.
이후 VLA의 임베딩과 VGGT의 3D 공간 표현 간의 코사인 유사도(Cosine Similarity, )를 최대화하는 정렬 손실(Alignment Loss)을 다음과 같이 계산합니다.
최종 목적 함수는 로봇의 원래 과제인 행동 예측 손실()에 정렬 손실을 결합하여 최적화합니다.
학습 및 추론 파이프라인의 차별성
- 학습(Training) 단계: VGGT 모델은 가중치가 동결된(Frozen) 상태로 작동하며, VLA 모델만이 기존의 과 을 동시에 최소화하도록 가중치를 업데이트합니다. 즉, 2D 행동 궤적 데이터를 학습하는 동시에 3D 공간 지식을 흡수합니다.
- 추론(Inference) 단계: 가장 강력한 기술적 차별성을 지니는 부분입니다. 학습이 종료된 후 실제 로봇에 모델을 배포할 때, VGGT 모델이나 피처 매핑을 위한 MLP 모듈 등은 완전히 제거됩니다. 오직 학습된 VLA 단일 모델만 동작하므로, 기존 2D VLA와 연산량 및 추론 속도가 100% 동일하며 명시적인 3D 센서 입력이 일절 필요하지 않습니다.
3. 실험 결과 (Experiments)
- 평가 환경 및 세팅: LIBERO 벤치마크 (Spatial, Object, Goal, Long 시나리오) 및 다양한 환경 변수(조명, 레이아웃 등)가 포함된 RoboTwin (Real-to-Sim 벤치마크)에서 평가되었습니다. 실제 로봇 평가는 다관절 AgileX 플랫폼에서 수행되었습니다. 베이스라인으로는 OpenVLA-OFT, 와 같은 최신 2D VLA뿐만 아니라, Depth나 Point Cloud를 사용하는 명시적 3D VLA(GeoVLA, 3D-CAVLA) 모델들이 포함되었습니다.
- 핵심 성능 결과: Spatial Forcing(SF)을 적용한 모델은 LIBERO 평균 성공률 98.5%를 기록하며 외부 3D 센서를 활용하는 모델들의 성능을 압도하는 SOTA를 달성했습니다. 특히 장기 의존성을 요구하는 Long-horizon 과제와 복잡성이 높은 RoboTwin의 Hard 세팅에서 압도적인 향상 폭을 보였습니다.
- 학습 및 데이터 효율성: 중간 표현을 3D 구조로 직접 가이드함으로써 최적화 공간을 좁혀, 베이스라인 모델과 동일한 성능에 도달하는 데 걸리는 학습 반복 횟수(Iterations)를 3.8배 가속했습니다. 또한 전체 훈련 데이터의 5%만으로도 75.8%의 성공률을 달성하여, 동일 데이터량 대비 5.9배의 데이터 효율성을 보였습니다.
- 해석 (t-SNE 시각화): SF 적용 후 VLA의 시각적 특징 분포는 타겟 3D 모델의 공간적 관계성(Distribution Shape)을 완벽히 모방하면서도, 군집의 중심(Cluster center)은 독립적으로 유지되었습니다. 이는 VLA가 고유의 시각적 식별 능력을 잃지 않으면서 물리적 차원의 기하학적 매니폴드(Manifold)만 정밀하게 정렬했음을 증명합니다.
4. 한계점 및 시사점
- 이론 및 엔지니어링적 한계: 본 방법론은 정답을 제공하는 특정 사전 학습 모델(VGGT)의 공간 이해 한계에 성능이 종속될 수밖에 없습니다. 또한, 손실 가중치 를 지나치게 높게 설정하면 VLA의 본래 행동 토큰 생성 능력이 손상되는 표현 붕괴(Representational collapse) 현상이 발생할 위험이 있습니다. 최적의 중간 레이어를 찾기 위해 네트워크 구조에 따른 수동적인 분석(예: 32개 층 중 24번째 층 선택)이 요구된다는 점도 한계로 작용합니다.
- 실제 적용 시 과제: 학습 파이프라인에서 VGGT 모델을 메모리에 동시에 올려야 하므로, 학습 단계에서의 VRAM 요구량 및 연산 오버헤드가 다소 증가합니다.
- 시사점: 이 연구는 로봇 모델이 3D 세계를 이해하기 위해 반드시 물리적인 3D 센서가 필요한 것은 아니라는 패러다임 전환을 제시합니다. 막대한 양의 저품질 2D 비디오 데이터에 내재된 공간 정보를 발굴하여 VLA에 주입하는 이 방식은, 현재 심각한 병목을 겪고 있는 '고품질 3D 로봇 데이터셋 부재' 문제를 소프트웨어적으로 타개할 수 있는 강력한 대안적 훈련 프로토콜로 확장될 수 있습니다.
