1. 문서 정보
- 제목: Visual Instruction Tuning
- 저자: Haotian Liu et al. (UW–Madison, Microsoft Research)
- 형식: 학술 논문 (NeurIPS 2023)
- 발행: 2023 (arXiv)
한 줄 요약
LLaVA는 이미지 인코더가 생성한 시각적 표현을 LLM의 언어 공간에 정렬시켜 입력함으로써, 별도의 복잡한 멀티모달 아키텍처 없이도 이미지 기반 추론과 지시 수행이 가능함을 보인 비전–언어 모델이다.
2. 배경 및 동기
CLIP 이후 비전–언어 분야의 상황은 다음과 같았다:
-
이미지와 텍스트를 정렬(alignment)하는 것은 가능
-
하지만:
- 추론 ❌
- 지시 이해 ❌
- 대화 ❌
즉, 기존 VLM은 대부분:
“보여주고 → 설명하는 모델”
에 머물러 있었다.
반면 LLM은 이미:
- 추론
- 지시 수행
- 대화
- 계획
을 잘 수행하고 있었다.
LLaVA의 핵심 질문은 이것이다:
“이미지를 잘 ‘이해한 표현’만 LLM에게 넘겨주면,
추론은 굳이 새로 만들 필요가 없는 것 아닐까?”
3. 아키텍처 및 기술 구성
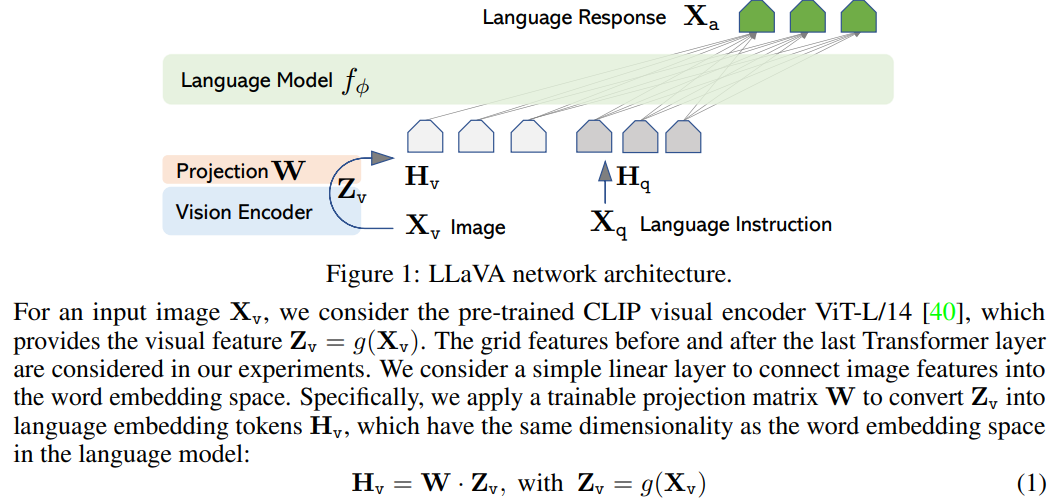
3.1 전체 구조 개요
LLaVA의 구조는 놀라울 정도로 단순하다.
Image → Vision Encoder → Visual Embedding
→ Linear Projection
→ LLM Input Space
Text → Token Embedding ┘
→ LLM (Vicuna / LLaMA)- Cross-attention ❌
- 복잡한 fusion module ❌
- 새로운 Transformer stack ❌
👉 이미지와 텍스트는 LLM 입력 단계에서만 만난다
3.2 Vision Encoder의 역할 (중요)
LLaVA에서 Vision Encoder는 보통:
- CLIP ViT-L/14
가 사용된다.
이 인코더의 역할은 명확하다:
이미지를 “이해”하는 것이 아니라,
LLM이 다룰 수 있는
의미적 표현으로 변환하는 것
즉:
- 이미지 인식 ❌
- 이미지 reasoning ❌
- 이미지 → 의미 표현 ⭕
👉 ViT / CLIP에서 우리가 계속 강조한 역할과 정확히 동일하다.
3.3 Projection Layer: 왜 이것만으로 충분한가?
Vision Encoder 출력은:
- 이미지 의미가 담긴 고차원 벡터
하지만 LLM은:
- 언어 임베딩 공간에서 작동
LLaVA는 이 간극을:
- 단순한 linear projection 하나로 연결한다.
이 설계는 다음 가정을 전제로 한다:
“CLIP이 만든 시각 표현은
이미 충분히 언어 친화적이다.”
그래서 복잡한 구조가 필요 없다.
4. “이해 vs 인코딩” 관점에서의 LLaVA 해석 (핵심)
LLaVA는 이미지를 이해하지 않는다.
정확히 말하면:
- 이미지를 해석하는 주체는 LLM
- Vision Encoder는 전처리기(pre-processor)
이다.
즉 역할 분담은 다음과 같다:
| 구성 요소 | 역할 |
|---|---|
| Vision Encoder | 이미지 → 의미 표현 |
| Projection | 표현 공간 정렬 |
| LLM | 이해, 추론, 지시 수행 |
👉 이해는 전부 LLM에 위임
이 구조는 우리가 계속 이야기한
“강한 인코더 + 강한 추론기” 패턴의 완성형이다.
5. 훈련 전략: 왜 학습이 잘 되는가?
5.1 Two-stage Training


(1) Feature Alignment (pretraining)
- 이미지–텍스트 쌍
- Vision Encoder 고정
- Projection + LLM 일부만 학습
👉 시각 표현을 언어 공간에 정렬

(2) Visual Instruction Tuning (핵심)
- 이미지 + 질문 + 답변
- GPT-4로 생성한 instruction 데이터
- LLM은 “이미지에 대해 말하는 법”을 학습
중요한 점:
Vision Encoder는 거의 학습하지 않는다

6. LLaVA는 그래서 무엇을 할 수 있는가?
LLaVA는:
- 이미지 설명
- 이미지 기반 QA
- 시각적 추론
- 멀티턴 대화
를 수행할 수 있다.
하지만 이 능력은:
이미지를 ‘보는 능력’이 아니라
이미지 표현을 조건으로 한
언어적 추론 능력
이다.
즉 LLaVA는:
- Vision model ❌
- Multimodal reasoning system ⭕
7. Inductive Bias 관점 분석
LLaVA의 inductive bias는 구조에 없다.
| 요소 | 역할 |
|---|---|
| CLIP encoder | 시각 의미 압축 |
| Linear projection | 공간 정렬 |
| Instruction tuning | 행동 규칙 학습 |
👉 Bias는 학습 데이터와 objective에 있다.
이는 BERT / CLIP과 완전히 동일한 철학이다.
8. 장점 및 한계
✔ 장점
- 구조적 단순성
- 기존 LLM 능력 최대 활용
- 빠른 확장 가능성
- 멀티모달 instruction의 시작점
⚠ 한계
- Fine-grained spatial reasoning 부족
- 이미지 grounding 불완전
- hallucination 가능성
- Vision Encoder 성능에 강하게 의존
👉 이 한계가 이후:
- LLaVA-1.5
- Qwen-VL
- GPT-4V
로 이어진다.
9. 한 문장 요약 (우리 대화의 결론)
LLaVA는 이미지를 이해하는 모델이 아니라, 이미지를 의미적으로 인코딩한 표현을 LLM의 언어 공간에 주입함으로써, 추론과 지시 수행을 전적으로 LLM에 맡기는 인코더 중심 멀티모달 시스템이다.
🔑 LLaVA 논문에서 반드시 가져가야 할 인사이트
- 멀티모달에서 가장 중요한 것은 fusion(모델 안에서 섞는 것)이 아니라 alignment(같은 의미 공간에 맞추는 것)
- 이미지는 “보는 대상”이 아니라 추론의 조건
- 인코더는 이해하지 않아도 된다
- LLM은 이미 충분히 강력하다
🔗 BERT · ViT · CLIP · LLaVA 한 줄 연결
| 모델 | 핵심 역할 |
|---|---|
| BERT | Text → 의미 표현 |
| ViT | Image → 의미 표현 |
| CLIP | 의미 표현 정렬 |
| LLaVA | 의미 표현 → 추론 |
👉 LLaVA는 이 체인의 ‘사용 단계’를 처음으로 완성한 모델이다.
