1. 문서 정보
- 제목: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 저자: Jacob Devlin et al. (Google AI Language)
- 형식: 학술 논문 (NAACL 2019)
- 발행: 2018 (arXiv), 2019 (NAACL)
한 줄 요약
BERT는 언어를 양방향 Transformer 인코더로 사전학습하여, 문장을 과제별로 해석하지 않고도 ‘이해 가능한 표현’으로 인코딩할 수 있음을 보인 연구로, 이후 모든 인코더 중심 AI 모델의 출발점이 되었다.
2. 배경 및 동기
BERT 이전 NLP의 주류는 다음과 같았다:
- task-specific architecture
- task-specific supervision
- feature engineering or shallow pretraining
대표적으로:
- LSTM / GRU
- left-to-right language model
- 태스크마다 다른 head 설계
문제는 명확했다:
“언어를 task마다 다르게 ‘처리’해야 하는가,
아니면 한 번 ‘잘 이해’해두면 되지 않는가?”
BERT의 핵심 문제의식은 바로 이것이다:
“문장의 의미를 범용적으로 인코딩할 수 있다면,
이후의 태스크는 얇은 head만으로 해결 가능하지 않을까?”
3. 아키텍처 및 기술 구성
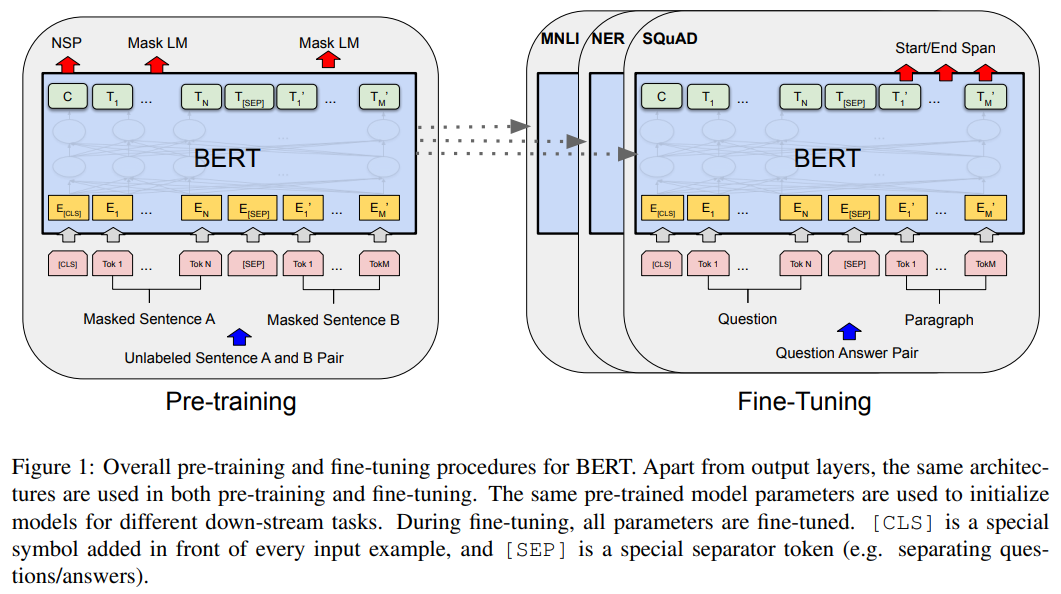
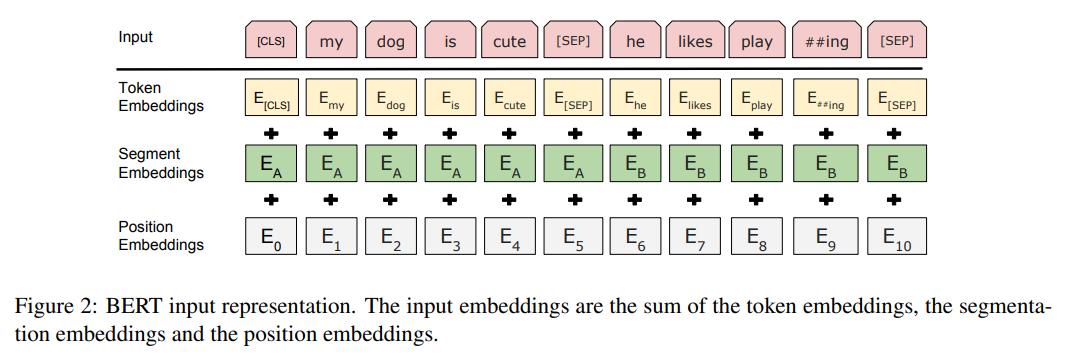
3.1 전체 구조 개요
BERT는 Transformer Encoder만으로 구성된 모델이다.
Text → Token Embedding + Segment Embedding + Position Embedding
→ Transformer Encoder (L layers)
→ Task-specific Head (fine-tuning 시)- Decoder ❌
- Autoregressive generation ❌
- Cross-attention ❌
👉 오직 “이해(encoding)”에만 집중
3.2 핵심 구조적 선택: Encoder Only
BERT의 가장 중요한 선택은 다음이다:
언어 모델을 “생성기”가 아니라
“이해를 위한 인코더”로 정의했다
이는 이후 모든 흐름의 출발점이 된다.
- GPT 계열 → generation 중심
- BERT 계열 → representation 중심
BERT는 다음 질문에 답한다:
“이 문장은 무엇을 의미하는가?”
이지,
“다음 단어는 무엇인가?”
가 아니다.
3.3 Pre-training Objective
BERT는 두 가지 사전학습 과제를 사용한다:
(1) Masked Language Modeling (MLM)
- 입력 토큰의 일부를
[MASK]로 가림 - 양방향 문맥으로 원래 토큰 예측
👉 완전한 bidirectional context 사용
(2) Next Sentence Prediction (NSP)
- 두 문장이 연속되는지 여부 예측
- 문장 간 관계 학습 목적
4. Inductive Bias 관점 분석 (핵심)
4.1 BERT의 inductive bias는 어디에 있는가?
BERT는 언어 구조를 하드코딩하지 않는다.
- syntax tree ❌
- grammar rule ❌
- linguistic feature ❌
대신 다음을 선택한다:
| 요소 | 역할 |
|---|---|
| Tokenization | 언어의 최소 단위 정의 |
| MLM objective | 의미 정렬 강제 |
| Bidirectional attention | 전역 문맥 통합 |
👉 Bias는 구조가 아니라 학습 목표(objective)에 존재
이는 우리가 CLIP에서 본 구조와 정확히 동일하다.
4.2 “이해”란 무엇인가?)
BERT는 언어를 “이해”한다고 말할 수 있을까?
BERT는:
- 논리 추론을 하지 않는다
- 지식을 명시적으로 저장하지 않는다
- 세계 모델을 갖지 않는다
그럼에도 불구하고 BERT는 downstream task에서 강력하다.
이유는 하나다:
BERT의 ‘이해’는
언어를 문제 해결에 유용한
표현 공간으로 인코딩하는 데 있다
즉 BERT는:
- understanding engine ❌
- universal text encoder ⭕
이다.
5. 훈련 전략과 스케일
5.1 사전학습 + 파인튜닝 패러다임
BERT가 바꾼 가장 큰 패러다임은 이것이다:
“모든 태스크를 처음부터 학습하지 않는다”
대신:
- 대규모 말뭉치로 사전학습
- 태스크별로 얇은 head만 fine-tuning
이는 이후:
- ViT
- CLIP
- LLaVA
까지 그대로 계승된다.
5.2 스케일의 중요성
논문은 분명히 보여준다:
- 모델이 커질수록
- 데이터가 많을수록
- 성능은 꾸준히 상승
👉 구조보다 스케일이 더 중요해지는 지점의 시작
6. 실험 결과 및 영향
6.1 성능
BERT는 발표 당시:
- GLUE
- SQuAD
- MNLI
등 거의 모든 NLP benchmark에서 SOTA 달성.
하지만 더 중요한 것은:
“이후 거의 모든 NLP 모델이
BERT 스타일을 기본값으로 채택했다”
는 사실이다.
6.2 파급 효과
BERT 이후 등장한 흐름:
- RoBERTa
- ALBERT
- ELECTRA
- DeBERTa
그리고 더 나아가:
- ViT (Vision에서의 encoderization)
- CLIP (멀티모달 alignment)
- LLaVA (encoder → LLM 연결)
7. 장점 및 한계
✔ 장점
- 범용 언어 표현 학습
- 태스크 독립성
- 강력한 transfer learning
- “인코더 중심 사고” 확립
⚠ 한계
- 생성 능력 없음
- long-range reasoning 제한
- world model 부재
- task를 “이해”하지는 않음
👉 이 한계가 GPT 계열, instruction tuning, LLM으로 이어진다.
8. 한 문장 요약
BERT는 언어를 생성하는 모델이 아니라, 언어를 Transformer 친화적인 의미 표현으로 인코딩하는 모델로, 대규모 사전학습을 통해 ‘이해 가능한 표현’을 만들어낼 수 있음을 증명하며 이후 모든 인코더 기반 AI 모델의 출발점이 된 연구다.
🔑 BERT 논문에서 반드시 가져가야 할 인사이트
- 이해는 생성이 아니라 표현이다
- Inductive bias는 구조보다 objective에 있다
- Encoder 하나만으로도 범용성이 가능하다
- “먼저 인코딩하고, 나중에 사용한다”는 패러다임의 시작
🔗 BERT · ViT · CLIP · LLaVA 연결
| 모델 | 역할 |
|---|---|
| BERT | Text → 의미 표현 |
| ViT | Image → 의미 표현 |
| CLIP | 의미 표현 간 정렬 |
| LLaVA | 의미 표현 → 추론 |
👉 모든 흐름의 시작은 BERT의 “인코더화(encodification)”
