Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Paper Translate
Author: Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, Kunle Olukotun
Affilation: Stanford University, SambaNova Systems, UC Berkeley
Venue: arXiv
Comments: ICLR Submitted
Date: October 2025
Paper Link: https://arxiv.org/abs/2510.04618
⭐️ Key Takeaways
1. ACE는 컨텍스트를 간결한 요약이 아닌, 구조화된 '진화하는 플레이북'으로 취급하여, 기존 컨텍스트 적응 방법의 한계인 간결성 편향과 컨텍스트 붕괴 문제를 해결한다. ACE(Agentic Context Engineering) 프레임워크는 생성, 반영, 큐레이션의 모듈식 프로세스를 통해 전략을 축적, 다듬고 조직하는 방식으로 컨텍스트를 다루며, 이는 세부 지식을 보존하고 긴 컨텍스트 모델에 맞춰 확장되는 구조화되고 점진적인 업데이트를 통해 컨텍스트 붕괴를 방지한다.
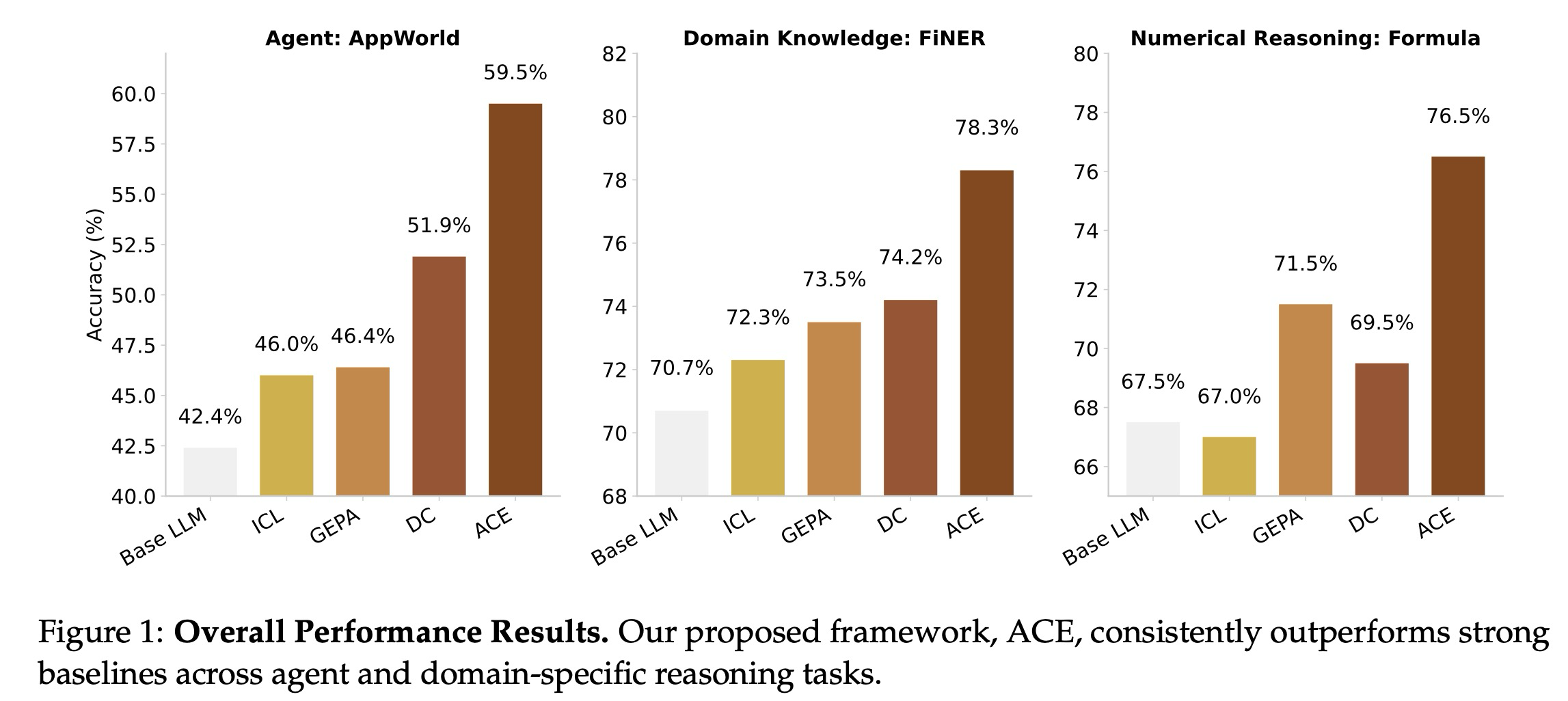
2. ACE는 LLM 에이전트 및 도메인별 추론 벤치마크 전반에 걸쳐 강력한 성능 향상을 제공하며, 레이블이 지정된 감독 없이도 효과적으로 자가 개선을 달성할 수 있다. ACE는 에이전트에서 평균 10.6%, 금융 분야에서 8.6%의 일관된 성능 향상을 보였고, 정답 레이블(ground-truth labels) 없이도 자연스러운 실행 피드백을 활용하여 컨텍스트를 엔지니어링함으로써 자가 개선하는 에이전트를 가능하게 한다.
3. ACE는 '점진적 델타 업데이트'와 효율적인 설계 덕분에 기존 적응형 방법 대비 현저히 낮은 오버헤드로 확장 가능하고 효율적인 LLM 시스템을 구현한다. ACE는 비용이 많이 드는 전체 컨텍스트 재작성 대신 국소화된 편집인 점진적 델타 업데이트를 사용하며, 그 결과 기존 적응형 방법 대비 평균 86.9% 낮은 적응 지연 시간을 달성하고 롤아웃 및 토큰 달러 비용을 크게 줄인다.
Abstract
에이전트 및 도메인별 추론과 같은 대규모 언어 모델(LLM) 애플리케이션은 모델 가중치 업데이트 대신 지침, 전략 또는 증거를 통해 입력을 수정하는 컨텍스트 적응(context adaptation)에 점점 더 의존한다. 이전 접근 방식들은 사용 편의성을 향상하지만, 간결한 요약을 위해 도메인 통찰력을 생략하는 간결성 편향(brevity bias)과, 반복적인 재작성으로 시간이 지남에 따라 세부 정보가 침식되는 컨텍스트 붕괴(context collapse)로부터 종종 고통받는다. Dynamic Cheatsheet에 의해 도입된 적응형 메모리를 기반으로, 우리는 생성, 반영(reflection), 그리고 큐레이션의 모듈식 프로세스를 통해 전략을 축적하고, 다듬고, 조직하는 진화하는 플레이북(playbook)으로 컨텍스트를 취급하는 프레임워크인 ACE (Agentic Context Engineering)를 소개한다. ACE는 상세한 지식을 보존하고 긴 컨텍스트 모델에 맞춰 확장되는 구조화되고 점진적인 업데이트를 통해 붕괴를 방지한다. 에이전트 및 도메인별 벤치마크 전반에 걸쳐, ACE는 오프라인(예: 시스템 프롬프트) 및 온라인(예: 에이전트 메모리) 환경 모두에서 컨텍스트를 최적화하며, 강력한 기준선보다 일관되게 우수한 성능을 보인다: 에이전트에서 +10.6%, 금융 분야에서 +8.6% 향상되며, 동시에 적응 지연 시간과 롤아웃 비용을 크게 줄인다. 특히, ACE는 레이블이 지정된 감독 없이도 자연스러운 실행 피드백을 활용하여 효과적으로 적응할 수 있다. AppWorld 리더보드에서 ACE는 더 작은 오픈 소스 모델을 사용했음에도 불구하고 전체 평균에서 최고 순위의 프로덕션 수준 에이전트와 동등한 성능을 보이며, 더 어려운 테스트-챌린지 분할에서는 이를 능가한다. 이러한 결과는 포괄적이며 진화하는 컨텍스트가 낮은 오버헤드로 확장 가능하고, 효율적이며, 자가 개선하는 LLM 시스템을 가능하게 함을 보여준다.
1. Introduction
LLM 에이전트 및 복합 AI 시스템과 같은 대규모 언어 모델(LLM) 기반의 현대 AI 애플리케이션들은 컨텍스트 적응(context adaptation)에 점점 더 의존한다. 컨텍스트 적응은 모델 가중치를 수정하는 대신, 명확하게 정리된 지침, 구조화된 추론 단계, 또는 도메인별 입력 형식을 모델의 입력에 직접 통합함으로써 모델 훈련 후 성능을 향상한다. 컨텍스트는 다운스트림 작업을 안내하는 시스템 프롬프트, 과거 사실 및 경험을 전달하는 메모리, 그리고 환각을 줄이고 지식을 보충하는 사실적 증거를 포함하여 많은 AI 시스템 구성 요소의 기반이 된다.
가중치가 아닌 컨텍스트를 통한 적응은 몇 가지 주요 이점을 제공한다. 컨텍스트는 사용자 및 개발자에게 해석 가능하고 설명 가능하며, 런타임에 새로운 지식을 신속하게 통합할 수 있도록 허용하고, 복합 시스템 내의 모델이나 모듈 간에 공유될 수 있다. 한편, 긴 컨텍스트 LLM 및 KV 캐시 재사용과 같은 컨텍스트 효율적인 추론의 발전은 컨텍스트 기반 접근 방식을 배포에 점점 더 실용적으로 만들고 있다. 결과적으로, 컨텍스트 적응은 유능하고, 확장 가능하며, 자가 개선하는 AI 시스템을 구축하기 위한 중심 패러다임으로 부상하고 있다.
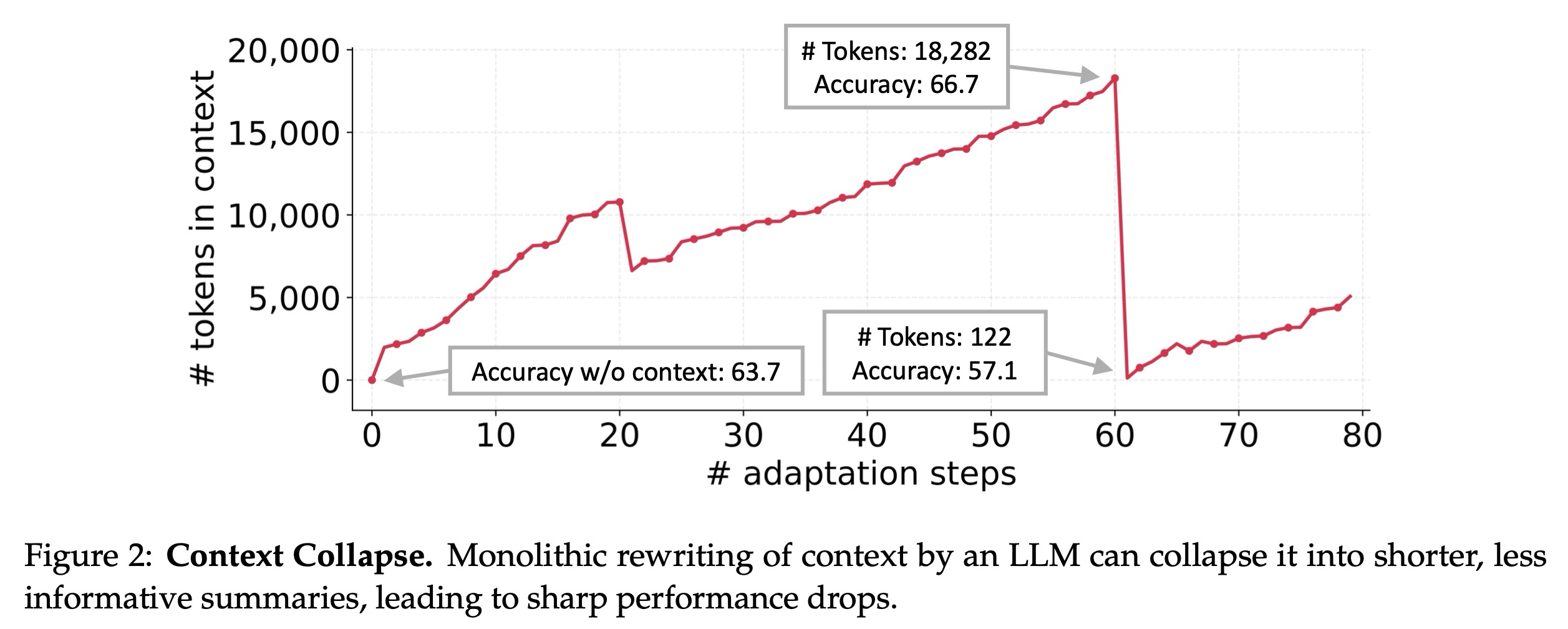
이러한 발전에도 불구하고, 기존의 컨텍스트 적응 접근 방식은 두 가지 주요 한계에 직면한다. 첫째, 간결성 편향(brevity bias)이 있다: 많은 프롬프트 최적화 도구는 포괄적인 축적보다는 간결하고 광범위하게 적용 가능한 지침을 우선시한다. 예를 들어, GEPA는 간결성을 강점으로 강조하지만, 이러한 추상화는 실제 적용에 중요한 도메인별 휴리스틱, 도구 사용 지침 또는 일반적인 실패 모드를 생략할 수 있다. 이러한 목표는 일부 환경에서 검증 지표와 일치하지만, 에이전트 및 지식 집약적 애플리케이션에 필요한 상세한 전략을 포착하지 못하는 경우가 많다. 둘째, 컨텍스트 붕괴(context collapse)가 발생한다: LLM에 의한 모놀리식 재작성(monolithic rewriting)에 의존하는 방법들은 시간이 지남에 따라 더 짧고 정보가 적은 요약으로 저하되는 경향이 있으며, 이는 급격한 성능 저하를 초래한다 (그림 2). 상호 작용 에이전트, 도메인별 프로그래밍, 금융 또는 법률 분석과 같은 도메인에서는 강력한 성능이 상세하고 작업별 지식을 압축하는 대신 유지하는 데 달려있다.
에이전트 및 지식 집약적 추론과 같은 애플리케이션들이 더 큰 신뢰성을 요구함에 따라, 최근 연구는 긴 컨텍스트 LLM의 발전 덕분에 컨텍스트를 풍부하고 잠재적으로 유용한 정보로 채우는 방향으로 전환되었다. 우리는 컨텍스트가 간결한 요약이 아니라, 상세하고 포괄적이며 도메인 통찰력으로 풍부한 포괄적이고 진화하는 플레이북(evolving playbooks) 역할을 해야 한다고 주장한다. 간결한 일반화로부터 종종 이점을 얻는 인간과 달리, LLM은 길고 상세한 컨텍스트가 제공될 때 더 효과적이며 추론 시간에 관련성을 자율적으로 추출할 수 있다. 따라서 컨텍스트는 도메인별 휴리스틱과 전술을 압축하여 제거하는 대신, 그것들을 보존하여 모델이 추론 시점에 무엇이 중요한지 결정하도록 허용해야 한다.
이러한 한계들을 해결하기 위해, 우리는 오프라인 환경(예: 시스템 프롬프트 최적화)과 온라인 환경(예: 테스트 시간 메모리 적응) 모두에서 포괄적인 컨텍스트 적응을 위한 프레임워크인 ACE (Agentic Context Engineering)를 소개한다. ACE는 컨텍스트를 정제된 요약으로 압축하는 대신, 시간이 지남에 따라 전략을 축적하고 조직하는 진화하는 플레이북으로 취급한다. Dynamic Cheatsheet의 에이전트 아키텍처를 기반으로 구축된 ACE는 생성(generation), 반영(reflection), 그리고 큐레이션(curation)의 모듈식 워크플로우를 통합하며, 성장 및 정제 원칙(grow-and-refine principle)에 의해 안내되는 구조화되고 점진적인 업데이트를 추가한다. 이 설계는 상세한 도메인별 지식을 보존하고, 컨텍스트 붕괴를 방지하며, 적응 과정 전반에 걸쳐 포괄적이고 확장 가능한 컨텍스트를 산출한다.
우리는 포괄적이고 진화하는 컨텍스트로부터 가장 큰 이점을 얻는 두 가지 범주의 LLM 애플리케이션에서 ACE를 평가한다: (1) 다중 턴 추론, 도구 사용 및 환경 상호 작용이 필요하며 축적된 전략을 에피소드 전반에 걸쳐 재사용할 수 있는 에이전트, 그리고 (2) 전문화된 전술 및 지식을 요구하는 도메인별 벤치마크(우리는 금융 분석에 중점을 둔다)이다. 우리의 주요 결과는 다음과 같다:
- ACE는 오프라인 및 온라인 적응 설정 모두에서 강력한 기준선보다 일관되게 우수한 성능을 보이며, 에이전트에서 평균 10.6%, 도메인별 벤치마크에서 8.6%의 향상을 달성한다.
- ACE는 레이블이 지정된 감독 없이도 효과적인 컨텍스트를 구축할 수 있으며, 대신 실행 피드백 및 환경 신호를 활용한다—이는 자가 개선 LLM 및 에이전트의 핵심 요소이다.
- AppWorld 벤치마크 리더보드에서, ACE는 더 작은 오픈 소스 모델(DeepSeek-V3.1)을 사용했음에도 불구하고, 전체 평균에서 최고 순위의 프로덕션 수준 에이전트인 IBM-CUGA (GPT-4.1 기반)와 동등한 성능을 보이며, 더 어려운 테스트-챌린지 분할에서는 이를 능가한다.
- ACE는 기존 적응형 방법보다 상당히 적은 롤아웃과 낮은 비용을 필요로 하며, 평균 86.9% 더 낮은 적응 지연 시간을 달성한다. 이는 확장 가능한 자가 개선이 더 높은 정확도와 더 낮은 오버헤드로 모두 달성될 수 있음을 입증한다.
2. Background and Motivation
2.1 Context Adaptation
컨텍스트 적응(context adaptation) (또는 컨텍스트 엔지니어링)은 LLM의 가중치를 변경하는 대신, LLM에 대한 입력을 구성하거나 수정함으로써 모델의 행동을 개선하는 방법들을 일컫는다. 현재의 최신 기술은 자연어 피드백을 활용한다. 이러한 패러다임에서 언어 모델은 실행 추적, 추론 단계 또는 검증 결과와 같은 신호와 함께 현재 컨텍스트를 검사하고, 컨텍스트가 어떻게 수정되어야 하는지에 대한 자연어 피드백을 생성한다. 이 피드백은 그 후 컨텍스트에 통합되어 반복적인 적응을 가능하게 한다. 대표적인 방법으로는 실패에 대해 반성하여 에이전트 계획을 개선하는 Reflexion, 경사도와 같은 텍스트 피드백을 통해 프롬프트를 최적화하는 TextGrad, 실행 추적을 기반으로 프롬프트를 반복적으로 정제하여 일부 설정에서는 강화 학습 접근 방식을 능가하는 강력한 성능을 달성하는 GEPA, 그리고 추론 중에 과거의 성공과 실패로부터 전략 및 교훈을 축적하는 외부 메모리를 구성하는 Dynamic Cheatsheet가 포함된다. 이러한 자연어 피드백 방법들은 모델 가중치 업데이트를 넘어 LLM 시스템 개선을 위한 유연하고 해석 가능한 신호를 제공하는 주요 진보를 나타낸다.
2.2 Limitations of Existing Context Adaptation Methods
The Brevity Bias. 컨텍스트 적응 방법의 반복적인 한계는 간결성 편향이다: 이는 최적화가 짧고 일반적인 프롬프트로 붕괴(collapse)되는 경향을 말한다. Gao 등은 테스트 생성(test generation)을 위한 프롬프트 최적화에서 이러한 효과를 문서화한다. 여기서 반복적인 방법은 다양성을 희생하고 도메인별 세부 정보를 생략하면서 반복적으로 거의 동일한 지침("메서드가 예상대로 작동하는지 확인하기 위해 단위 테스트를 만드세요" 등)을 생성한다. 이러한 수렴은 탐색 공간을 좁힐 뿐만 아니라, 최적화된 프롬프트가 종종 시드와 동일한 오류를 상속하기 때문에 반복적으로 발생하는 오류를 전파한다. 더 광범위하게, 이러한 편향은 다단계 에이전트, 프로그램 합성 또는 지식 집약적 추론과 같이 상세하고 컨텍스트가 풍부한 지침을 요구하는 도메인에서 성능을 저해하며, 여기서는 작업별 통찰력을 압축하는 대신 축적하는 데 성공이 달려있다.
Context Collapse. AppWorld 벤치마크에 대한 사례 연구에서, 우리는 컨텍스트 붕괴라고 부르는 현상을 관찰한다. 이는 LLM이 각 적응 단계에서 축적된 컨텍스트를 완전히 재작성하도록 지시받을 때 발생한다. 컨텍스트가 커짐에 따라, 모델은 컨텍스트를 훨씬 더 짧고 정보가 적은 요약으로 압축하는 경향이 있으며, 이는 극적인 정보 손실을 야기한다. 예를 들어, 60단계에서 컨텍스트는 18,282개의 토큰을 포함했으며 66.7의 정확도를 달성했지만, 바로 다음 단계에서는 122개의 토큰으로 붕괴되었고 정확도는 57.1로 떨어지는데, 이는 적응을 하지 않은 기준선 정확도인 63.7보다도 나쁜 수치이다. 우리는 Dynamic Cheatsheet을 통해 이 문제를 강조하지만, 이 문제는 특정 방법에 국한되지 않는다. 오히려 이는 LLM을 사용한 종단 간 컨텍스트 재작성(end-to-end context rewriting)의 근본적인 위험을 반영하며, 여기서 축적된 지식은 보존되는 대신 갑작스럽게 지워질 수 있다.
3. Agentic Context Engineering (ACE)

우리는 오프라인 환경(예: 시스템 프롬프트 최적화)과 온라인 환경(예: 테스트 시간 메모리 적응) 모두에서 확장 가능하고 효율적인 컨텍스트 적응을 위한 프레임워크인 ACE (Agentic Context Engineering)를 소개한다. 지식을 간결한 요약이나 정적인 지침으로 압축하는 대신, ACE는 컨텍스트를 시간이 지남에 따라 전략을 지속적으로 축적, 정제하고 조직하는 진화하는 플레이북으로 취급한다. Dynamic Cheatsheet의 에이전트 설계를 기반으로 구축된 ACE는 세 가지 역할(그림 4)에 걸쳐 구조화된 노동 분담을 도입한다: 추론 궤적을 생성하는 생성기(Generator), 성공과 오류에서 구체적인 통찰력을 추출하는 반영기(Reflector), 그리고 이러한 통찰력을 구조화된 컨텍스트 업데이트로 통합하는 큐레이터(Curator)이다. 이는 인간이 배우는 방식(실험, 반영, 통합)을 반영하는 동시에, 단일 모델에 모든 책임을 과부하하는 병목 현상을 피한다.
2.2절에서 논의된 이전 방법의 한계(특히 간결성 편향과 컨텍스트 붕괴)를 해결하기 위해, ACE는 세 가지 핵심 혁신을 도입한다: (1) 큐레이션으로부터 평가 및 통찰력 추출을 분리하여 컨텍스트 품질과 다운스트림 성능을 개선하는 전용 반영기(Reflector)(4.5절), (2) 비용이 많이 드는 모놀리식 재작성을 국소화된 편집으로 대체하여 지연 시간과 계산 비용을 모두 줄이는 점진적 델타 업데이트(3.1절)(4.6절), 그리고 (3) 꾸준한 컨텍스트 확장과 중복 제어의 균형을 맞추는 성장 및 정제 메커니즘(3.2절)이다.
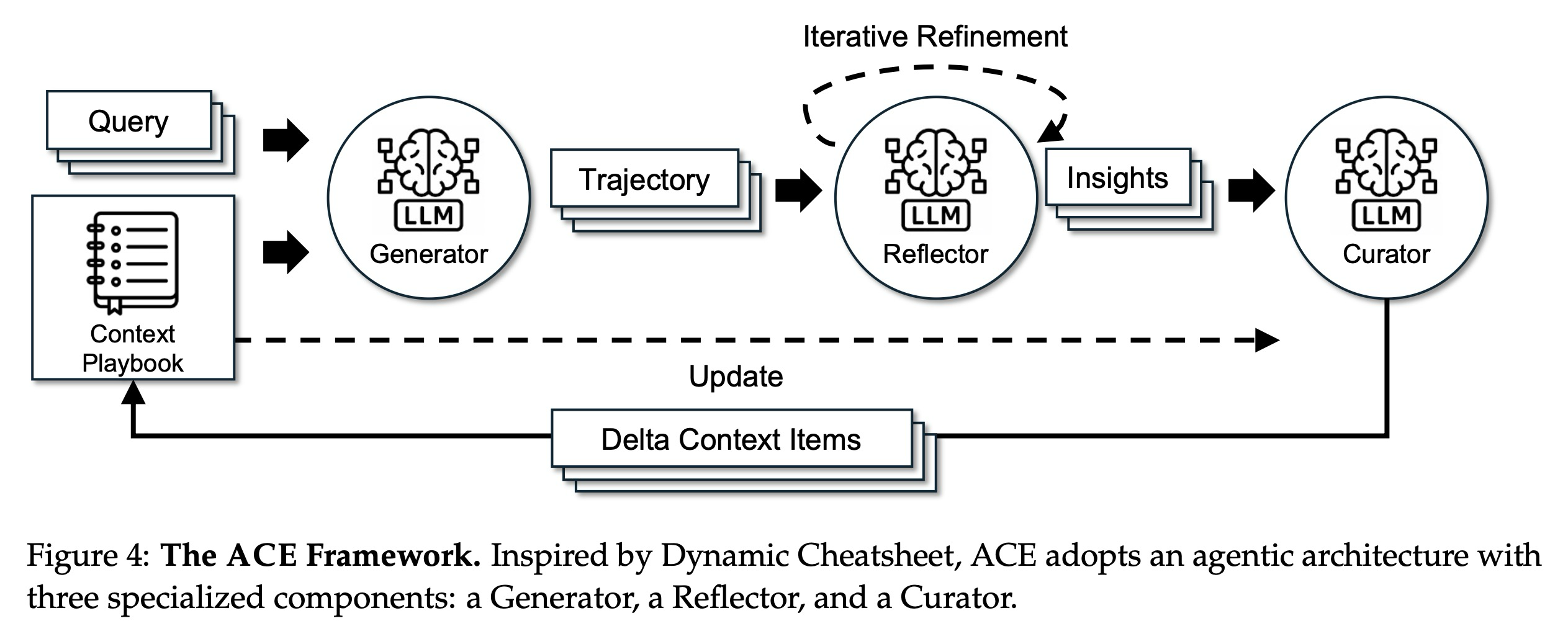
그림 4에 표시된 것처럼, 워크플로우는 생성기가 새로운 쿼리에 대한 추론 궤적을 생성하는 것으로 시작하며, 이는 효과적인 전략과 반복되는 함정 모두를 드러낸다. 반영기는 이러한 궤적을 비판적으로 검토하여 교훈을 추출하며, 선택적으로 여러 반복에 걸쳐 이를 정제한다. 그런 다음 큐레이터는 이러한 교훈을 압축된 델타 엔트리로 종합하며, 이는 경량의 비-LLM 로직에 의해 기존 컨텍스트로 결정론적으로 병합된다. 업데이트는 항목화되고 국소화되어 있기 때문에, 여러 델타를 병렬로 병합할 수 있어 규모에 맞는 배치 적응을 가능하게 한다. ACE는 또한 동일한 쿼리를 다시 방문하여 컨텍스트를 점진적으로 강화하는 다중 에포크 적응(multi-epoch adaptation)을 지원한다.
3.1 Incremental Delta Updates
ACE의 핵심 설계 원칙은 컨텍스트를 단일의 모놀리식 프롬프트 대신, 구조화되고 항목화된 글머리 기호(bullets) 모음으로 표현하는 것이다. '글머리 기호'의 개념은 Dynamic Cheatsheet 및 A-MEM과 같은 LLM 메모리 프레임워크의 메모리 항목 개념과 유사하지만, 이를 기반으로 구축되며 다음 요소들로 구성된다: (1) 메타데이터: 고유 식별자(unique identifier)와 해당 항목이 도움이 되었는지(helpful) 또는 해로웠는지(harmful) 추적하는 카운터를 포함한다. (2) 콘텐츠: 재사용 가능한 전략, 도메인 개념, 또는 일반적인 실패 모드와 같은 작은 단위의 정보를 담는다.
이러한 항목화된 설계는 세 가지 핵심 속성을 가능하게 한다: (1) 국소화(localization), 관련 글머리 기호만 업데이트되도록 한다. (2) 세밀한 검색(fine-grained retrieval), 생성기가 가장 적절한 지식에 집중할 수 있도록 한다. (3) 점진적 적응(incremental adaptation), 추론 중에 효율적인 병합, 가지치기(pruning), 및 중복 제거를 허용한다.
ACE는 컨텍스트 전체를 재생성하는 대신, 점진적으로 압축된 델타 컨텍스트를 생성한다. 델타 컨텍스트는 반영기에 의해 증류되고 큐레이터에 의해 통합되는 작은 후보 글머리 기호 세트이다. 이는 전체 재작성의 계산 비용과 지연 시간을 피하면서, 과거 지식이 보존되고 새로운 통찰력이 꾸준히 추가되도록 보장한다. 컨텍스트가 증가함에 따라, 이 접근 방식은 장기적인 또는 도메인 집약적인 애플리케이션에 필요한 확장성을 제공한다.
3.2 Grow-and-Refine
점진적인 성장을 넘어, ACE는 주기적이거나 지연된 정제(refinement)를 통해 컨텍스트가 간결하고 관련성 있게 유지되도록 보장한다. 성장 및 정제(grow-and-refine) 메커니즘에서는 새로운 식별자(identifiers)를 가진 글머리 기호(bullets)가 추가되며, 기존 글머리 기호는 제자리에 업데이트된다(예: 카운터 증가). 그런 다음, 의미론적 임베딩(semantic embeddings)을 통해 글머리 기호들을 비교하여 중복을 제거하는 중복 제거 단계(de-duplication step)가 가지치기(prunes)를 수행한다. 이러한 정제는 애플리케이션의 지연 시간 및 정확도 요구 사항에 따라 사전에(각 델타 이후) 수행되거나 지연되어(컨텍스트 창을 초과할 때만) 수행될 수 있다.
점진적 업데이트와 성장 및 정제 메커니즘은 함께 컨텍스트를 적응적으로 확장하고, 해석 가능하게 유지하며, 모놀리식 컨텍스트 재작성으로 인해 발생할 수 있는 잠재적인 분산(variance)을 방지한다.
4. Results
ACE에 대한 우리의 평가는 다음을 보여준다:
- 고성능의 자가 개선 에이전트 구현 가능. ACE는 에이전트가 입력 컨텍스트를 동적으로 정제함으로써 자가 개선할 수 있도록 한다. 이는 정답 레이블(ground-truth labels) 없이 실행 피드백만으로부터 더 나은 컨텍스트를 엔지니어링하는 방법을 학습함으로써 AppWorld 벤치마크에서 정확도를 최대 17.1% 향상한다. 이러한 컨텍스트 기반 개선은 더 작은 오픈 소스 모델이 리더보드에서 최고 순위의 독점 에이전트 성능과 대등하게 만든다. (§4.3)
- 도메인별 벤치마크에서의 큰 이점. 복잡한 금융 추론 벤치마크에서, ACE는 도메인별 개념 및 통찰력을 포함하는 포괄적인 플레이북을 구축함으로써 강력한 기준선 대비 평균 8.6%의 성능 향상을 제공한다. (§4.4)
- 설계에 따른 효율성. 요소 연구(Ablation studies)는 우리의 설계 선택이 성공의 핵심임을 확인하며, 반영기(Reflector)와 다중 에포크 정제(multi-epoch refinement)와 같은 구성 요소들이 각각 상당한 성능 향상에 기여한다. (§4.5)
- 더 낮은 비용 및 적응 지연 시간. ACE는 이러한 성능 향상을 효율적으로 달성하며, 적응 지연 시간을 평균 86.9% 줄이는 동시에 더 적은 롤아웃과 더 낮은 토큰 달러 비용을 요구한다. (§4.6)
4.1 Tasks and Datasets
우리는 포괄적이고 진화하는 컨텍스트로부터 가장 큰 이점을 얻는 두 가지 범주의 LLM 애플리케이션에 대해 ACE를 평가한다: (1) 다중 턴 추론, 도구 사용, 그리고 환경 상호 작용이 필요하며 에이전트가 에피소드 및 환경 전반에 걸쳐 전략을 축적하고 재사용할 수 있는 에이전트 벤치마크, 그리고 (2) 전문화된 개념과 전술 숙달을 요구하는 도메인별 벤치마크로, 사례 연구로 금융 분석에 중점을 둔다.
- LLM 에이전트: AppWorld는 API 이해, 코드 생성, 환경 상호 작용을 포함하는 자율 에이전트 태스크 모음이다. 이는 일반적인 애플리케이션 및 API(예: 이메일, 파일 시스템)와 두 가지 난이도 수준(일반 및 챌린지)의 태스크를 포함하는 현실적인 실행 환경을 제공한다. 공개 리더보드는 성능을 추적하며, 제출 시점에 최고의 시스템이 평균 정확도 60.3%만을 달성하여 이 벤치마크의 난이도와 현실성을 강조한다.
- 금융 분석: FiNER 및 Formula는 XBRL(eXtensible Business Reporting Language)에 의존하는 금융 추론 태스크에 대해 LLM을 테스트한다. FiNER는 규제된 도메인에서 금융 정보 추출의 핵심 단계인 XBRL 재무 문서 내의 토큰에 139개의 세분화된 엔터티 유형 중 하나로 레이블을 지정해야 한다. Formula는 구조화된 XBRL 파일링에서 값을 추출하고 금융 쿼리에 응답하기 위한 계산을 수행하는 것, 즉 수치 추론에 중점을 둔다.
Evaluation Metrics. AppWorld의 경우, 우리는 공식 벤치마크 프로토콜을 따르며 테스트-일반(test-normal) 및 테스트-챌린지(test-challenge) 분할 모두에서 태스크 목표 완료(Task Goal Completion, TGC) 및 시나리오 목표 완료(Scenario Goal Completion, SGC)를 보고한다. FiNER 및 Formula의 경우, 우리는 원래 설정을 따르며 정답과 정확히 일치하는 예측된 답변의 비율로 측정된 정확도(accuracy)를 보고한다.
모든 데이터셋은 원래의 훈련/검증/테스트 분할을 따른다. 오프라인 컨텍스트 적응의 경우, 방법들은 훈련 분할에서 최적화되고 통과율@1 정확도(pass@1 accuracy)로 테스트 분할에서 평가된다. 온라인 컨텍스트 적응의 경우, 방법들은 테스트 분할에서 순차적으로 평가된다: 각 샘플에 대해 모델은 먼저 현재 컨텍스트로 예측한 다음, 해당 샘플을 기반으로 컨텍스트를 업데이트한다. 동일하게 섞인(shuffled) 테스트 분할이 모든 방법에서 사용된다.
4.2 Baselines and Methods
Base LLM. 기반 모델은 데이터셋 저자들이 제공한 기본 프롬프트를 사용하여, 어떠한 컨텍스트 엔지니어링 없이 각 벤치마크에서 직접 평가한다. AppWorld의 경우, 저자들은 벤치마크 저자들이 공개한 공식 ReAct 구현을 따르며, 다른 모든 기준선 및 방법들을 이 프레임워크를 기반으로 구축한다.
In-Context Learning (ICL). ICL은 모델에게 입력 프롬프트에 태스크 시연(few-shot 또는 many-shot)을 제공한다. 이를 통해 모델은 가중치 업데이트 없이 태스크 형식과 원하는 출력을 추론할 수 있다. 저자들은 모델의 컨텍스트 창에 맞으면 모든 훈련 샘플을 제공하고, 그렇지 않으면 가능한 한 많은 시연으로 창을 채운다.
MIPROv2. MIPROv2는 베이지안 최적화를 통해 시스템 지침 및 컨텍스트 내 시연을 공동으로 최적화하여 LLM 애플리케이션을 위한 인기 있는 프롬프트 최적화 도구이다. 저자들은 최적화 성능을 극대화하기 위해 공식 DSPy 구현을 사용하며 auto="heavy"로 설정한다.
GEPA. GEPA(Genetic-Pareto)는 반영적 프롬프트 진화(reflective prompt evolution)를 기반으로 하는 샘플 효율적인 프롬프트 최적화 도구이다. 이는 실행 추적(추론, 도구 호출, 중간 출력)을 수집하고 자연어 반영을 적용하여 오류를 진단하고, 공을 할당하며, 프롬프트 업데이트를 제안한다. 유전적 파레토 탐색(genetic Pareto search)은 높은 성능을 내는 프롬프트의 경계를 유지하여 지역 최적화 문제를 완화한다. 경험적으로 GEPA는 GRPO와 같은 강화 학습 방법과 MIPROv2와 같은 프롬프트 최적화 도구보다 우수한 성능을 보이며, 최대 35배 적은 롤아웃으로 10~20% 더 높은 정확도를 달성한다. 저자들은 최적화 성능을 극대화하기 위해 공식 DSPy 구현을 사용하며 auto="heavy"로 설정한다.
Dynamic Cheatsheet (DC). DC는 재사용 가능한 전략 및 코드 스니펫에 대한 적응형 외부 메모리를 도입하는 테스트 시간 학습(test-time learning) 접근 방식이다. 새로 마주친 입력 및 출력으로 이 메모리를 지속적으로 업데이트함으로써, DC는 모델이 지식을 축적하고 태스크 전반에 걸쳐 재사용할 수 있도록 하며, 이는 정적 프롬프트 방법보다 상당한 개선을 가져오는 경우가 많다. DC의 주요 장점은 정답 레이블(ground-truth labels)이 필요 없다는 것이다: 모델은 자신의 생성물로부터 자체 메모리를 큐레이션할 수 있으므로, 이 방법은 매우 유연하고 광범위하게 적용 가능하다. 저자들은 저자들이 공개한 공식 구현을 사용하며 누적 모드(DC-CU)를 사용하도록 설정한다.
ACE (ours). ACE는 에이전트 컨텍스트 엔지니어링 프레임워크를 통해 오프라인 및 온라인 적응 모두에 대해 LLM 컨텍스트를 최적화한다. 공정성을 기하기 위해, 저자들은 Generator, Reflector 및 Curator에 동일한 LLM(DeepSeek-V3.1의 비-사고 모드)을 사용하며, 이는 더 강력한 Reflector 또는 Curator로부터 더 약한 Generator로의 지식 전파를 방지한다. 이는 컨텍스트 구축 자체의 이점을 분리한다. 저자들은 배치 크기를 1로 채택하며(각 샘플로부터 델타 컨텍스트를 구축), Reflector 정제 라운드의 최대 횟수와 오프라인 적응에서의 최대 에포크 수를 5로 설정한다.
4.3 Results on Agent Benchmark
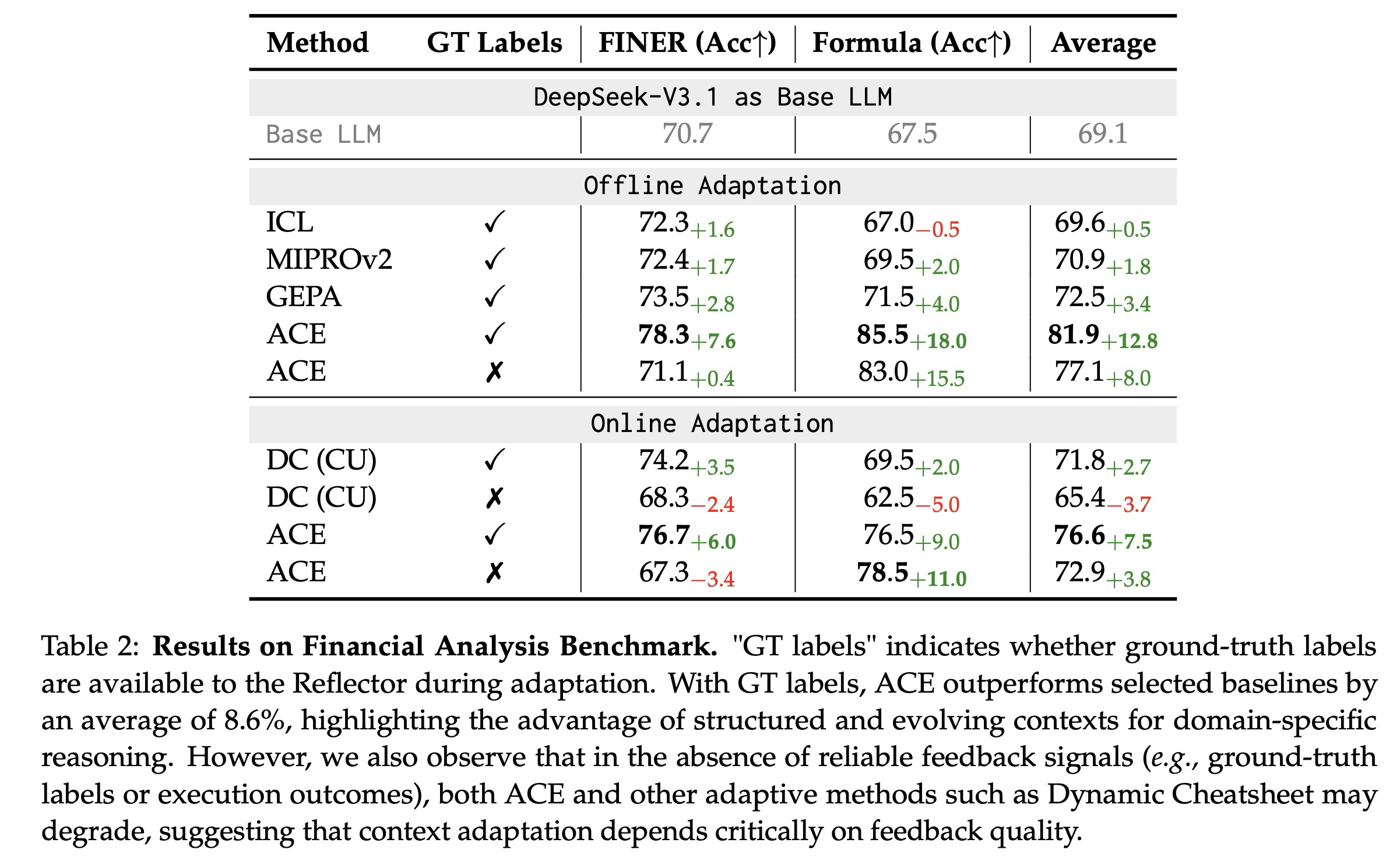
Analysis. 표 2에서 볼 수 있듯이, ACE는 금융 분석 벤치마크에서 강력한 개선을 제공한다. 오프라인 설정에서, 훈련 분할로부터 정답(ground-truth answers)이 제공될 때, ACE는 ICL, MIPROv2, GEPA를 명확한 차이(평균 10.9%)로 능가하며, 이는 구조화되고 진화하는 컨텍스트가 정확한 도메인 지식(예: 금융 개념 및 XBRL 규칙)을 요구하는 태스크에서 특히 효과적임을 보여준다. 이는 고정된 시연이나 모놀리식으로 최적화된 프롬프트를 넘어선다. 온라인 설정에서, ACE는 DC와 같은 이전 적응형 방법보다 평균 6.2% 더 우수한 성능을 지속적으로 보이며, 이는 전문화된 도메인 전반에 걸쳐 재사용 가능한 통찰력을 축적하기 위한 에이전트 컨텍스트 엔지니어링의 이점을 더욱 확인한다.
더욱이, 정답 감독(ground-truth supervision)이나 신뢰할 수 있는 실행 신호가 없을 때, ACE와 DC 모두 성능이 저하될 수 있음을 관찰한다. 이러한 경우, 구성된 컨텍스트는 허위적이거나 오해의 소지가 있는 신호로 오염될 수 있으며, 이는 신뢰할 수 있는 피드백 없이는 추론 시간 적응에 잠재적인 한계가 있음을 강조한다. 이는 ACE가 풍부한 피드백(예: 에이전트 태스크에서의 코드 실행 결과 또는 공식 정확도) 하에서 강력하지만, 그 효과는 반영기(Reflector)와 큐레이터(Curator)가 건전한 판단을 내릴 수 있도록 하는 신호의 가용성에 달려 있음을 시사한다. 저자들은 이 한계에 대해서는 부록 B에서 다시 논의한다.
4.5 Ablation Study
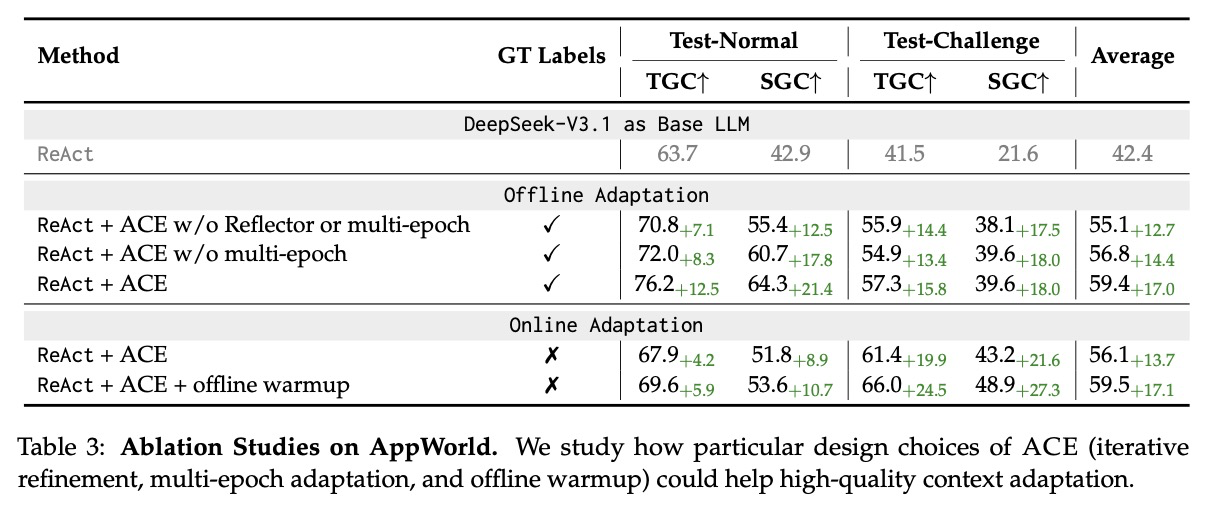
표 3은 AppWorld 벤치마크에 대한 요소 연구 결과를 보여주며, ACE의 개별 설계 선택이 효과적인 컨텍스트 적응에 어떻게 기여하는지 분석한다. 우리는 세 가지 요소를 조사한다: (1) 반영기(Reflector)와 반복적인 정제는 Dynamic Cheatsheet를 넘어서는 에이전트 프레임워크에 추가된 요소이다, (2) 다중 에포크 적응(multi-epoch adaptation)은 훈련 샘플을 통해 컨텍스트를 여러 번 정제하는 것이며, (3) 오프라인 워밍업(offline warmup)은 온라인 적응을 시작하기 전에 오프라인 적응을 통해 컨텍스트를 초기화하는 것이다.
결과를 통해, 반영기 또는 다중 에포크 정제를 제외한 ReAct + ACE는 평균 정확도 55.1%(+12.7% 향상)를 달성하며, 이는 완전한 ReAct + ACE(+17.0% 향상)보다 낮다. 특히, 다중 에포크 정제를 제외하면 평균 정확도가 56.8%(+14.4% 향상)로 떨어지는데, 이는 반복적인 정제가 성능 향상에 상당한 기여를 함을 확인한다.
온라인 적응 설정에서는, 오프라인 워밍업을 사용하지 않은 ReAct + ACE는 평균 정확도 56.1%(+13.7% 향상)를 달성하는 반면, 오프라인 워밍업을 포함한 ReAct + ACE는 59.5%(+17.1% 향상)를 달성한다. 이는 오프라인 워밍업이 강력한 초기 컨텍스트를 제공하여 온라인 적응의 효율성과 최종 성능을 개선하는 데 도움이 됨을 시사한다.
4.6 Cost and Speed Analysis
ACE는 증분적인 "델타" 컨텍스트 업데이트와 비-LLM 기반의 컨텍스트 병합 및 중복 제거에 대한 지원 덕분에, 적응 비용(롤아웃 횟수 또는 토큰 흡수/생성에 대한 달러 비용 측면)과 지연 시간을 줄이는 데 특히 강점을 보인다.
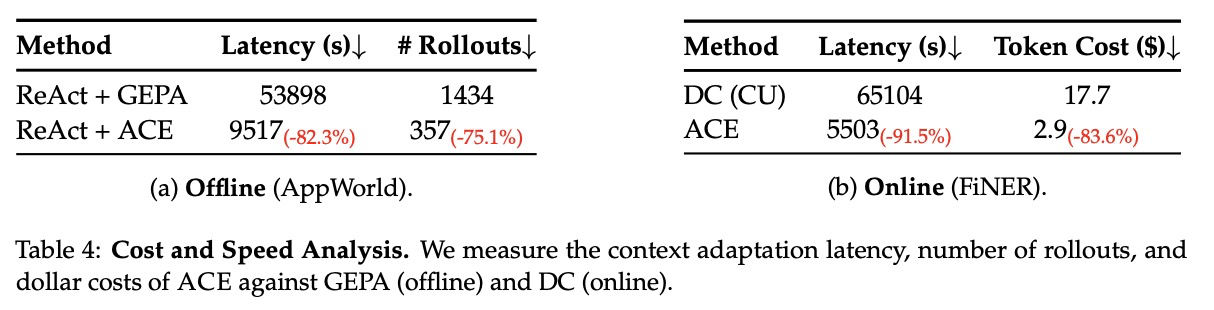
예를 들어, AppWorld의 오프라인 적응에서 ACE는 GEPA와 비교하여 적응 지연 시간을 82.3% 감소시키고 롤아웃 횟수를 75.1% 감소시킨다 (표 4(a)). FiNER의 온라인 적응에서 ACE는 DC(Dynamic Cheatsheet)와 비교하여 적응 지연 시간을 91.5% 감소시키고 토큰 흡수 및 생성에 대한 토큰 달러 비용을 83.6% 감소시킨다 (표 4(b)).
5. Discussion
Long Context ≠ Higher Serving Cost. ACE는 GEPA와 같은 방법보다 더 긴 컨텍스트를 생성하지만, 이것이 선형적으로 더 높은 추론 비용이나 GPU 메모리 사용량으로 이어지지는 않는다. 현대의 서비스 인프라스트럭처는 KV 캐시의 재사용, 압축, 그리고 오프로드와 같은 기술을 통해 긴 컨텍스트 워크로드에 대해 점점 더 최적화되고 있다. 이러한 메커니즘은 자주 재사용되는 컨텍스트 세그먼트를 로컬 또는 원격으로 캐시하여, 반복적이고 비용이 많이 드는 프리필(prefill) 작업을 방지한다. ML 시스템의 지속적인 발전은 긴 컨텍스트를 처리하는 상각 비용(amortized cost)이 계속해서 감소할 것임을 시사하며, 이는 ACE와 같이 컨텍스트가 풍부한 접근 방식을 배포에서 점점 더 실용적으로 만들고 있다.
Implications for Online and Continuous Learning. 온라인 및 지속적 학습은 분포 변화 및 제한된 훈련 데이터와 같은 문제를 해결하기 위한 기계 학습의 핵심 연구 방향이다. 컨텍스트를 조정하는 것이 일반적으로 모델 가중치를 업데이트하는 것보다 저렴하기 때문에, ACE는 기존 모델 미세 조정(fine-tuning)에 대한 유연하고 효율적인 대안을 제공한다. 더욱이, 컨텍스트는 인간이 해석할 수 있으므로, ACE는 개인 정보 보호나 법적 제약 때문이든, 또는 도메인 전문가가 오래되거나 부정확한 정보를 식별할 때든 선택적 망각(selective unlearning)을 가능하게 한다. 이는 ACE가 지속적이고 책임 있는 학습을 발전시키는 데 중심적인 역할을 할 수 있는 유망한 미래 연구 방향이다.
