Author: Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, Xuantang Xiong, Lei Han, Zhiyuan Liu, Maosong Sun
Affilation: Tsinghua University, Sanghai Jiao Tong University, Beijing University of Posts and Telecommunications, Siemens, Tencent Robotics X
Venue: NeurIPS 2025
Comments:
Date: May 2025
Paper Link: https://arxiv.org/abs/2505.19591
⭐️ Key Takeaways
1. 이 논문은 기존의 정적인 다중 에이전트 구조의 비효율성을 해결하기 위해 중앙 집중식 '퍼피티어' 오케스트레이터가 진화하는 작업 상태에 따라 에이전트 활동을 동적으로 지시하는 새로운 '인형극 스타일' 협업 패러다임을 제안한다.
2. 이 프레임워크는 강화 학습(RL)을 사용하여 오케스트레이터의 정책을 지속적으로 학습하고 업데이트함으로써, 에이전트의 순서와 우선순위를 적응적으로 조정하여 유연하고 진화 가능한 집단 추론을 가능하게 한다.
3. 실험 결과, 제안된 방법은 계산 비용을 줄이면서 우수한 솔루션 품질을 달성하며, 성능 향상은 오케스트레이터의 진화로 인해 더욱 간결하고 순환적인(cyclic) 추론 구조가 나타나는 데서 비롯됨을 밝힌다.
Abstract
대규모 언어 모델(LLMs)은 다양한 다운스트림 작업에서 놀라운 결과를 달성했지만, 그들의 단일적인 특성은 복잡한 문제 해결에서의 확장성 및 효율성을 제한한다. 최근 연구에서 LLM 간의 다중 에이전트 협업을 탐구하고 있지만, 대부분의 접근 방식은 작업 복잡성과 에이전트 수가 증가함에 따라 적응하기 어려운 정적인 조직 구조에 의존하며, 이는 조정 오버헤드와 비효율성을 초래한다. 이러한 문제 해결을 위해, 우리는 중앙 집중식 오케스트레이터("puppeteer", 즉 꼭두각시 조종자)가 진화하는 작업 상태에 반응하여 에이전트("puppets", 즉 꼭두각시)를 동적으로 지휘하는 LLM 기반 다중 에이전트 협업을 위한 꼭두각시 조종자 스타일의 패러다임을 제안한다. 이 오케스트레이터는 강화 학습을 통해 훈련되어 에이전트들의 순서를 적응적으로 지정하고 우선순위를 부여하며, 유연하고 진화 가능한 집단적 추론을 가능하게 한다. 폐쇄형 및 개방형 도메인 시나리오에 대한 실험은 이 방법이 줄어든 계산 비용으로 우수한 성능을 달성함을 보여준다. 분석 결과는 주요 개선 사항들이 오케스트레이터의 진화 아래에서 더욱 간결하고 순환적인 추론 구조가 출현하는 것에서 일관되게 비롯된다는 것을 추가로 밝혀낸다. 코드는 https://github.com/OpenBMB/ChatDev/tree/puppeteer에서 이용 가능하다.
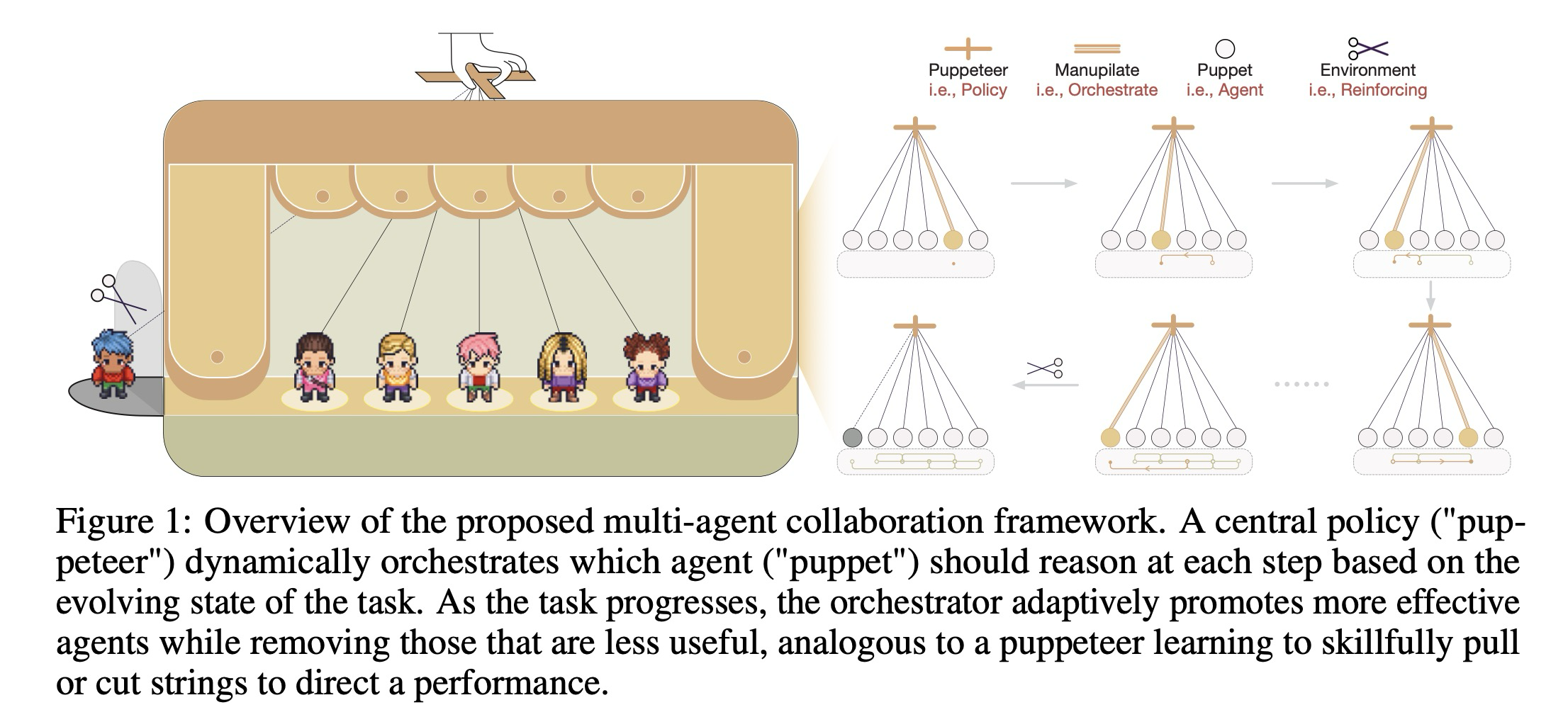
1. Introduction
대규모 언어 모델(LLMs)은 다양한 자연어 처리 작업에서 놀라운 발전을 이루었으며, 계획 수립, 추론, 그리고 의사 결정에서 강력한 능력을 입증한다. 도구 증강 추론 및 개방된 환경에서의 협력적 문제 해결과 같이 더욱 복잡하고 다면적인 문제들을 해결하려는 열망이 계속 커짐에 따라, 단일체적 LLM의 한계가 점점 더 명확해지고 있다,.
이러한 과제들을 해결하기 위해, 최근 연구는 인간의 팀워크에서 영감을 얻어 전문화된 기술, 개인화된 추론 패턴, 그리고 외부 도구 통합을 갖춘 다양한 LLM 기반 에이전트로 구성된 다중 에이전트 시스템(MAS)을 탐구한다. 그러나 많은 기존 접근 방식들은 유연성과 확장성이 부족한 미리 정의되거나 정적으로 생성된 에이전트 토폴로지에 의존한다. 이러한 경직성은 작업의 다양성과 에이전트 수가 확장됨에 따라 종종 조정 오버헤드 증가, 시스템 성능 저하, 그리고 비효율성을 초래한다. 특히 대규모 시나리오에서는, 원칙적이고 동적인 조정의 부재가 불필요한 계산, 비효율적인 통신, 그리고 집단적 문제 해결 효과 감소를 더욱 초래할 수 있다.
동적인 오케스트레이션이 협업 효율성과 계산 효율성을 동시에 극대화할 수 있을까? 이 질문에 답하는 것은 복잡한 실제 환경에 적합한 확장 가능하고, 견고하며, 실용적인 집단 지성을 구축하는 데 매우 중요한다. 이를 위해, 우리는 유연하고 지속적으로 진화하는 다중 에이전트 시스템을 구축하기 위한 새로운 패러다임을 제안한다. 중앙의 꼭두각시 조종자가 무대 뒤에서 여러 꼭두각시를 능숙하게 지휘하는 꼭두각시 인형극에서 영감을 얻어, 우리는 다중 에이전트 협업을 진화하는 작업 상태에 기반하여 에이전트 활성화를 동적으로 선택하고 순서를 정하는 중앙 집중식 꼭두각시 조종자에 의해 오케스트레이션되는 추론 과정으로 재개념화한다. 작업이 진행됨에 따라, 오케스트레이터는 효율적인 에이전트를 우선시하고 덜 효율적인 에이전트를 억제하는 것을 학습하며, 지속적으로 시스템을 더 높은 전반적인 성능과 효율성으로 이끈다.
구체적으로, 우리의 프레임워크는 두 가지 주요 혁신을 도입하여 다중 에이전트 추론을 발전시킨다. (i) 동적 오케스트레이션: 정적인 협업 패턴을 넘어, 우리는 현재 컨텍스트에 기반하여 각 단계에서 에이전트를 라우팅하는 동적 오케스트레이터를 사용한다. 이 과정은 순차적 결정 문제로 공식화되어, 효과적으로 암묵적인 추론 그래프를 생성하고 유연하며 확장 가능한 에이전트 조정을 지원한다. (ii) 적응적 진화: 효율성을 극대화하고 중복성을 최소화하기 위해, 우리는 완료된 작업으로부터의 피드백을 활용하여 오케스트레이터의 정책을 지속적으로 업데이트하기 위해 강화 학습을 활용한다. 시간이 지남에 따라, 오케스트레이터는 강력한 에이전트 궤적을 강조하고 덜 효과적인 궤적을 가지치기하는 것을 학습하며, 시스템이 점진적으로 더 큰 효율성으로 진화할 수 있도록 한다.
폐쇄형 및 개방형 도메인 시나리오에 대한 실험 결과는 우리의 접근 방식이 더 적은 계산 오버헤드로 지속적으로 더 효과적인 솔루션을 산출함을 입증한다. 분석 결과는 진화된 토폴로지가 다른 작업들에서 고정적이지 않음에도 불구하고, 핵심 개선 사항들은 더욱 간결하고 순환적인 추론 구조의 출현으로부터 일관되게 비롯된다는 것을 추가로 밝힌다.
2. Method
우리는 중앙 집중식 정책을 사용하여 다양한 LLM 기반 에이전트들의 협업을 동적으로 오케스트레이션하고, 강화 학습을 통해 그들의 협업 과정을 지속적으로 최적화하는 다중 에이전트 추론을 위한 통합 프레임워크를 제안한다.
LLM 기반 에이전트는 최소한의 형태로 로 추상화될 수 있는데, 여기서 은 기반 모델을 나타내고, 은 추론 패턴 또는 프롬프트 전략을 나타내며, 는 사용 가능한 외부 도구들의 집합이다. 에이전트 공간 는 이러한 구성 요소들의 조합으로 형성된 모든 가능한 에이전트들을 나열하며, 즉 이며, 이는 본질적인 추론과 도구 증강 추론을 모두 포함한다. 따라서 각 에이전트는 작업 해결에 참여하는 원자적인 추론 행동을 나타낸다.
다중 에이전트 협업을 위해, "Scaling Large Language Model- based Multi-Agent Collaboration.”를 따라, MAS는 자연스럽게 방향성 그래프 로 공식화된다. 여기서 각 노드 는 에이전트 에 해당하며, 각 방향성 에지 는 의존성 또는 정보 흐름을 인코딩하여 중간 컨텍스트를 에이전트 에서 에이전트 로 전달한다. 일반적으로 이 그래프는 단일 소스, 단일 싱크 구성을 제시하는데, 소스 노드는 입력 작업을 나타내고, 싱크 노드는 통합된 작업 출력(즉, 결과물)을 산출한다. 이 공식화는 LLM 기반 추론 시스템을 위한 통합적이고 시간적인 모델링 프레임워크의 기초를 이루며, 깊은 사고 과정을 포착하는 "사고의 그래프(graph-of-thought)"와 유사하다.
2.1 Dynamic Orchestration
Centralized Puppeteer. 다중 에이전트 추론에서 태스크 복잡성과 에이전트 다양성이 증가함에 따라 효율적인 오케스트레이션을 달성하는 것은 도전 과제가 된다. 이전 접근 방식들에서 각 에이전트는 자율적으로 협력자를 선택했지만, 이는 특히 에이전트가 증가하거나 변경될 때 조정 오버헤드와 낮은 확장성을 초래한다. 대신, 중앙 집중식 조정(예: 여러 꼭두각시를 관리하는 꼭두각시 조종자)에서 영감을 받아, 우리는 시스템이 중앙 집중식 오케스트레이터에 의해 구동되는 것으로 모델링한다. 이 오케스트레이터는 동적인 태스크 상태를 기반으로 각 단계에서 어떤 에이전트를 활성화할지 동적으로 선택하고, 선택된 에이전트에게 추론을 위임한다. 이러한 집중화는 에이전트 선택을 내부 에이전트 동작과 분리하여, 광범위한 매개변수 재훈련 없이도 적응성과 확장성을 크게 향상시킨다.
Serialized Orchestration. 또 다른 도전 과제는 에이전트 간에 가능한 협업 토폴로지의 조합적으로 방대한 공간에서 비롯된다. 완전 탐색은 불가능하므로, 이전 연구는 정식 그래프(예: 체인, 트리, 그래프)에만 초점을 맞춘다. 대신, 우리는 협업 추론 프로세스를 직렬화할 것을 제안한다. 즉, 전체 토폴로지 공간을 탐색하는 대신, 오케스트레이터는 토폴로지 순회 전략에 의해 유도되는 추론 시퀀스로 그래프를 "전개한다". 토폴로지 순서를 유지함으로써, 추론 단계는 문제 의존성에 의해 암시되는 부분 순서를 따른다. 에이전트의 오케스트레이션이 직렬화되고 "전개되는" 것처럼 보일지라도, 이 에피소드가 접힘을 통해 복원될 때, 이는 방향성 그래프(에이전트를 노드로, 오케스트레이션 부분 순서 관계를 엣지로 가짐)로 재구성될 수 있다는 점에 주목하는 것이 중요하다.
위의 두 개념을 바탕으로, 우리는 다중 에이전트 협업을 중앙 집중식 정책 에 의해 지배되는 순차적 결정 프로세스로 공식화한다. 각 시간 단계 에서, 오케스트레이터는 현재 전역 시스템 상태 와 태스크 사양 에 따라 활성화할 단일 에이전트 를 선택한다. 전역 상태 는 단계 까지의 모든 관련 에이전트 상태 및 통합된 문맥 정보로 구성된다:
여기서 정책 는 관찰 가능한 문맥(예: 현재 상태 및 태스크 설명)을 후보 에이전트들의 분포로 매핑하는 함수이다.
활성화 시, 에이전트 는 자신의 상태 를 (에서 추출되어) 수신하고 생성적 추론 매핑 를 통해 출력을 생성하며, 이후 시스템 상태는 다음과 같이 업데이트된다 ():
이 과정은 반복적으로 계속된다. 각 단계에서 오케스트레이터는 업데이트된 시스템 상태 를 관찰하고, 다시 와 에만 조건화된 정책 를 사용하여 활성화할 다음 에이전트 를 선택한다. 이 순차적인 에이전트 선택 프로세스는 명시적으로 마르코프 속성을 충족한다:
이 프로세스는 정지 기준이 충족될 때 종료된다 (예: 선택된 에이전트가 지정된 종료자이거나 태스크 해결 자원이 소진되었을 때). 그 시점에서 최종 집계 함수 는 전체 솔루션을 산출하기 위해 모든 시간 단계에 걸친 모든 에이전트 출력들을 결합한다:
여기서 는 전체 추론 단계의 총 횟수를 나타낸다.
2.2 Adaptive Evolution
동적 오케스트레이션은 유연한 에이전트들의 장기 추론을 가능하게 하지만, 순진하게 구현할 경우 중복되거나 도움이 되지 않는 에이전트를 호출하여 용인할 수 없는 비효율성을 초래할 수 있다. 이러한 문제를 해결하기 위해, 마르코프 속성 덕분에 학습 가능한 정책이 에이전트 선택 결정을 적응적으로 학습하도록 지속적으로 고려된다. 각 추론 에피소드 후, 시스템은 솔루션 품질과 자원 소모를 공동으로 평가하는 피드백을 받으며, 이로 인해 정책은 실시간 태스크 상태를 기반으로 가장 가치 있는 에이전트를 학습할 수 있게 된다.
실제적으로, 이것은 에이전트의 동적 가지치기를 촉진한다: 오케스트레이션 프로세스는 증분적 이득이 거의 없거나 과도한 비용을 발생시키는 에이전트에 대한 의존도를 줄여서 점점 더 간결한 추론 체인을 선호하도록 적응한다. 시간이 지남에 따라, 오케스트레이터 정책은 더 효과적인 에이전트 시퀀스를 조직하도록 진화하며, 표현력이 풍부한 협업과 계산 효율성 사이의 균형을 맞춘다. 따라서, 진화 가능한 꼭두각시 조종자는 에이전트 협업을 오케스트레이션할 뿐만 아니라, 추론 프로세스를 가장 필수적인 구성 요소로 증류(distill)하여 견고하고 확장 가능한 성능을 가능하게 한다.
Policy Optimization. 협업의 효과성과 효율성을 체계적으로 최적화하기 위해, 우리는 기반 최적화 프레임워크로 REINFORCE, 즉 강화 학습(RL) 기술을 활용한다. 이를 통해 오케스트레이션 정책은 이전 실행으로부터 학습하고, 에이전트 선택 및 가지치기 전략을 적응적으로 개선하여 더 견고하고 비용 효율적인 다중 에이전트 추론을 달성한다.
구체적으로, 최적화 목표는 전체 추론 궤적에 대한 기대 보상을 최대화하는 것이며, 여기서 보상은 전반적인 효과성과 추론 효율성을 모두 반영한다:
여기서 는 궤적 에 대해 누적된 총 보상을 나타내며, 는 상태 에서 에이전트 에 의해 생성된 출력, 은 표본 크기, 는 한 궤적의 총 추론 단계 수이다. 오케스트레이터의 매개변수 는 학습률 를 사용하여 경사 상승법을 통해 반복적으로 업데이트된다: . 이러한 RL 기반 최적화를 통해 오케스트레이터는 축적된 교차 태스크 경험을 활용하여 에이전트 선택을 개선하고, 불필요하거나 비용이 많이 드는 에이전트를 동적으로 억제하며, 더욱 간결하고 성능이 높은 협업 구조로 수렴한다.
Reward Design. 오케스트레이터의 최적화를 효과적으로 안내하기 위해, 우리는 솔루션 품질과 계산 효율성을 모두 고려하는 보상 함수를 설계한다. 각 태스크 궤적이 완료되면, 종료 보상 이 할당된다: 정답이 있는 태스크의 경우 은 정확도를 나타내고, 개방형 태스크의 경우 은 답변 품질을 정량화한다. 전체 보상은 시간 단계에 걸쳐 재귀적으로 정의된다. 종료 상태 에서 누적 보상은 솔루션 품질과 총 계산 비용을 모두 통합한다:
여기서 는 정확도와 효율성 사이의 균형을 제어하며, 은 할인 계수(discount factor)이다. 경제적인 추론을 장려하기 위해, 우리는 과도한 계산 지출에 불이익을 준다. 구체적으로, 각 추론 단계 에 대해, 우리는 FLOPs 또는 토큰 수준 메트릭(F)을 기반으로 단계별 비용 를 정의하며, 이는 최대 단계 예산 로 정규화된 단계 계수 를 포함한다. 이 복합적인 보상 공식은 오케스트레이터가 불필요한 계산을 최소화하면서 정확하고 고품질의 솔루션을 달성하도록 장려하며, 궁극적으로 MAS가 효과적이고 비용 효율적인 추론 구조를 발견하도록 유도한다.
3. Experiments
Datasets and Metrics. 우리 프레임워크를 철저히 평가하기 위해, 우리는 폐쇄형 및 개방형 도메인 추론 작업을 모두 포괄하는 다양한 공개적으로 이용 가능하고 논리적으로 까다로운 데이터셋을 사용한다:
- Closed-domain Tasks: 이 작업들은 정확하고 객관적인 추론과 명확한 답변을 요구하며, 핵심 추론 정확도와 수학적 엄격함을 평가하는 데 적합하다. GSM-Hard는 비정상적으로 큰 숫자와 복잡한 다단계 계산을 포함하는 산술 문제를 특징으로 하며, 모델의 고급 수학적 추론 능력과 오류 없는 실행 능력에 도전한다. MMLU-Pro는 다양한 주제와 난이도를 아우르는 종합적인 벤치마크로, 객관식 질문을 사용하여 사실적 지식과 논리적 추론 능력을 모두 평가한다. 두 벤치마크 모두 수학적 및 상식 추론 및 추론 능력을 평가하도록 설계되었으며, 평가 지표로는 정확도(accuracy)를 사용한다.
- Open-domain Tasks: 이 작업들은 본질적으로 창의적이며 개방적이며, 다차원적인 정성적 평가를 요구한다. 이들은 정보 통합, 맥락 이해, 그리고 새로운 솔루션 생성 능력을 엄격하게 평가한다. SRDD는 실제 텍스트 소프트웨어 요구 사항으로 구성되며, 에이전트에게 해당하는 소프트웨어를 구축하도록 요구하며, 요구 사항 이해, 시스템/설계 추론, 코드 생성 및 테스트 능숙도를 필요로 한다. 그 공식 평가 지표는 완전성, 실행 가능성, 그리고 일관성을 결합하며, 실제 소프트웨어 개발 워크플로우의 실질적인 요구 사항을 반영한다. CommonGen-Hard는 에이전트가 겉보기에는 관련이 없는 개념들을 연결하는 일관성 있는 문장을 생성하도록 도전하며, 상식 추론, 맥락적 이해, 그리고 창의적 표현 능력을 강조한다. 평가는 문법, 관련성, 논리적 일관성, 그리고 개념 포괄성을 통합하는 종합 지표를 기반으로 하며, 생성 품질에 대한 미묘한 평가를 제공한다.
Baselines. 성능 간섭(강한 모델이 약한 모델의 기여를 가릴 수 있는 상황)을 완화하고 다양한 역량을 가진 에이전트에 대한 우리 방법의 적응성을 평가하기 위해, 우리는 기반 모델의 매개변수 규모에 기반하여 에이전트 풀을 분할한다. 구체적으로, 우리는 Mimas 서브스페이스(더 작은 모델: Qwen-2.5-7B, Qwen-2.5-14B, LLaMA-3.1-8B, LLaMA-3.2-3B, Mistral-7B, Mistral-Nemo-12B)와 Titan 서브스페이스(더 큰 모델: GPT-4-Turbo, GPT-4o-Mini, Gemini-1.5-Pro, Gemini-1.5-Flash, Claude-3-Sonnet, Claude-3-Haiku, Qwen-2.5-72B, LLaMA-3.1-405B)를 정의하며, 이는 폐쇄형 및 개방형 소스 계열을 모두 포괄한다. 모든 실험은 Titan 및 Mimas 서브스페이스 설정 하에서 수행된다. 실험 연구의 엄격함과 신뢰성을 보장하기 위해, 우리는 단순한 LLM 생성부터 고급 에이전트 패러다임까지의 스펙트럼을 포괄하는 일련의 대표적이고 최근의 기준선(baselines)을 선택한다.
- Pure Models: 이 범주는 명시적인 에이전트 구조화나 워크플로우 오케스트레이션이 없는 상태에서 기반 모델을 평가하며, 생성 추론 성능의 기준선 역할을 한다. Mimas의 경우, 경쟁력 있는 오픈 소스 모델에는 LLaMA-3.1-8B, Mistral-Nemo-12B 및 Qwen-2.5-14B가 포함된다. Titan의 경우, LLaMA-3.1-405B, GPT-4o-mini 및 GPT-4-turbo와 같은 옵션이 고려된다.
- Single-Agent Methods: 이 범주는 특정 추론 패턴이나 워크플로우를 사용하여 단일 에이전트에 의해 추론이 수행되는 패러다임을 탐색한다. Self-refine은 피드백 루프 내에서 반복적인 자체 수정 추론을 예시하며, AFlow는 Monte Carlo Tree Search를 활용하여 코드 기반 에이전트 워크플로우를 최적화함으로써 에이전트 추론 효율성을 향상시킨다.
- Multi-Agent Methods: 우리는 최신 다중 에이전트 추론 시스템을 기준으로 벤치마킹하며, 에이전트 이질성 및 동적 협업을 활용하는 최첨단 역량을 보여준다. MacNet은 토폴로지적으로 정적인 유향 비순환 그래프 내에서 에이전트를 오케스트레이션하여, 추론 성능을 향상시키기 위해 하나의 기반 모델에 의해 구동되는 집단 지성을 촉진한다. EvoAgent는 수동 개입 없이 협업 및 성능을 적응적으로 개선하기 위해 진화 알고리즘을 채택하여 다양한 다중 에이전트 시스템을 자동으로 생성하고 최적화한다.
Implementation Details. 다른 에이전트들은 태스크 분해, 반성, 개선, 비평, 수정, 요약 및 종료와 같은 별개의 추론 패턴을 갖추고 있어 유연한 문제 해결을 가능하게 한다. WebViewer, WikiSearch, BingSearch, arXivSearch, Code Interpreter 및 File Reader와 같은 외부 도구들도 통합된다. 동적 협업은 출력 통합을 위해 다수결 투표를 사용한다. 정책은 Llama-3.1의 변형으로 초기화되며, 기본 설정은 에피소드 길이 4, 병렬 탐색 최대 3, , 를 사용한다. 모든 기준선은 동일한 설정 하에서 재실행된다.
3.1 Does Our Method Lead To Elevated Performance?
다중 에이전트 시스템에 대한 많은 이전 연구들은 에이전트 동작을 구동하기 위해 동일한 기본 모델을 사용한다. 더 의미 있는 비교를 가능하게 하고 모델 이질성을 설명하기 위해, Puppeteer라고 불리는 우리의 방법은 각 에이전트 서브스페이스 내에서 두 가지 별개의 구성을 도입한다. 모든 에이전트가 동일한 모델에 의해 구동되는 Mono 설정(우리는 Titan 서브스페이스에 대해 LLaMA-3.1-405B를 사용하고 Mimas 서브스페이스에 대해 LLaMA-3.1-8B를 사용한다)과, 에이전트가 다양한 모델 세트에 의해 구동되는 기본 설정이다. Puppeteer가 온라인 강화 학습을 거치므로, 우리는 그 학습 과정을 두 가지 별개의 단계로 분류한다: 다듬어지지 않은 동작을 특징으로 하는 초기 단계(initial phase)와, 강화된 성능을 특징으로 하는 진화된 단계(evolved phase)이다.
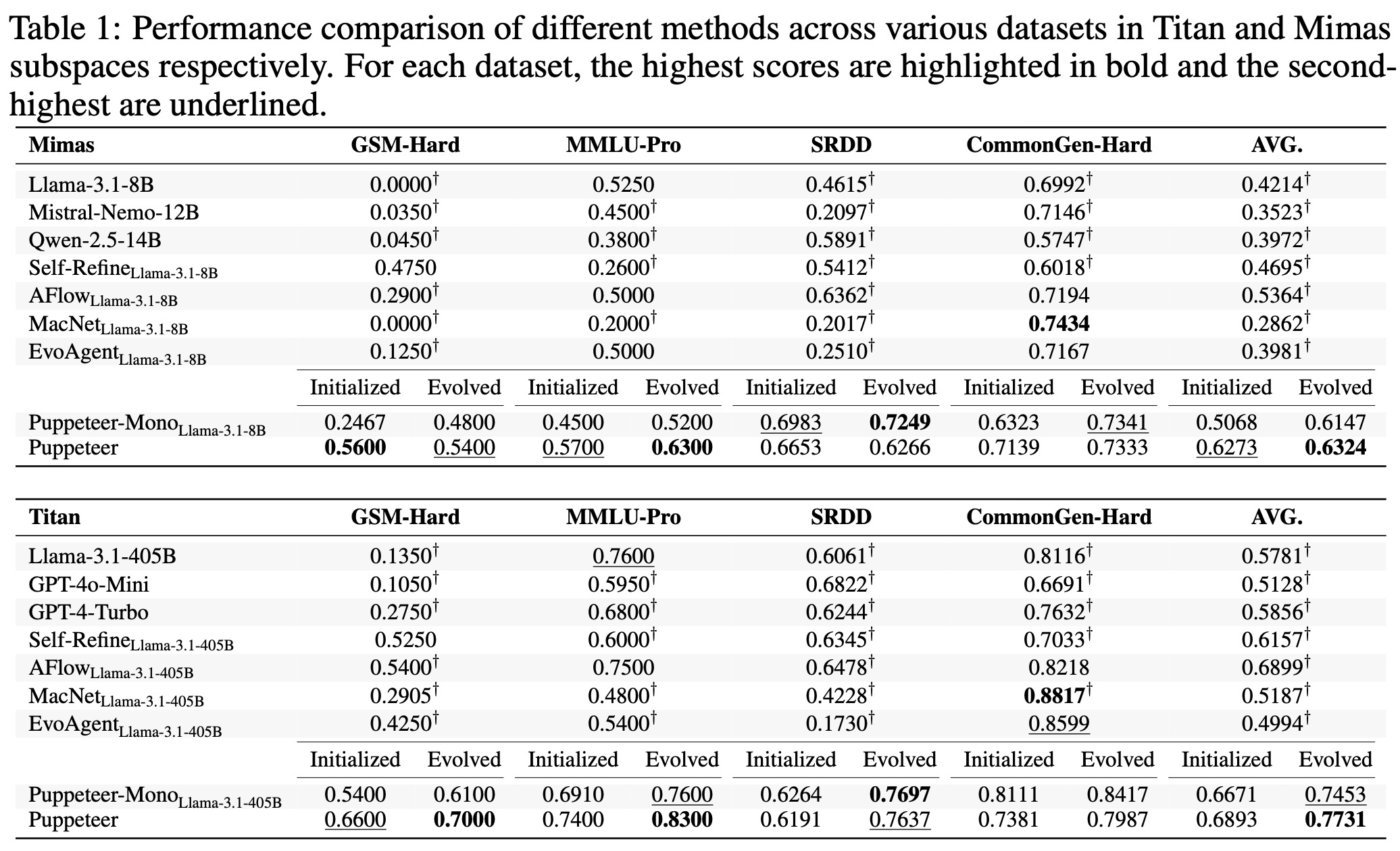
표 1에 상세히 설명된 바와 같이, Puppeteer는 도메인 유형이나 모델 공간 크기에 관계없이 모든 평가된 작업에서 진화된 단계 동안 지속적으로 우수한 평균 성능을 달성한다. 마찬가지로, Puppeteer-Mono는 대규모 및 소규모 모델 모두에서 견고한 성능을 보여준다. 이러한 결과들은 우리의 중앙 집중식 오케스트레이터가 이질적인 에이전트와 단일 모델 기반 에이전트 모두를 조정하여 매우 효과적인 다중 에이전트 시스템(MAS)을 형성하는 탁월한 능력을 강조하며, 다양한 에이전트 구성을 관리하는 데 있어서 그 견고성을 부각한다.
동일한 기본 모델을 사용하는 다양한 에이전트 워크플로우 및 다중 에이전트 기준선과 비교할 때, Puppeteer-Mono는 거의 모든 평가된 작업에서 경쟁 방법보다 지속적으로 우수한 성능을 보인다. 이 결과는 최적화된 추론 전략과 전략적 도구 활용을 통해 단일 모델 기반 에이전트를 조정하는 우리의 중앙 집중식 오케스트레이터의 효능을 강조하며, 대체 프레임워크를 능가한다. 이는 우수한 성능이 정교한 조직 설계와 상황 인식적인, 동적으로 구성된 다중 에이전트 토폴로지에서 비롯됨을 강조한다. 특히, Puppeteer-Mono가 해당 서브스페이스 내에서 거의 최적인 모델을 활용함에도 불구하고, Puppeteer는 이질적인 모델에 의해 구동되는 에이전트 간의 상호 보완적인 상호 작용으로부터 이점을 얻어 지속적으로 우수한 성능을 달성한다. 또한, Puppeteer의 확장된 공간은 솔루션 환경에 대한 더 광범위한 탐색을 가능하게 하여 최적화 기회를 향상시킨다.
효과적인 MAS를 조직하는 Puppeteer의 능력을 보여주기 위해, 우리는 초기 단계와 진화된 단계 사이의 성능을 비교한다. 그 결과는 지속적인 최적화가 상당한 이득을 산출함을 보여준다—예를 들어, Titan 서브스페이스의 Puppeteer는 평균적으로 0.6893에서 0.7731로 향상되며, Mimas 서브스페이스에서도 유사한 경향이 관찰된다. 이러한 발견들은 조정 및 태스크 전문화를 향상시키는 데 있어 지속적인 최적화의 중요한 역할을 강조하며, 전통적이고 정적인 에이전트 패러다임을 넘어 보다 적응적이고 협력적인 에이전트 시스템으로 나아가는 유망한 방향을 제시한다.
3.2 Does Performance Gain Come at the Expense of Efficiency?
비학습형 다중 에이전트 시스템에 대한 최근 연구에서는 에이전트 협업을 통해 달성되는 성능 향상이 종종 전체 토큰 소비 증가를 동반한다는 트레이드오프(trade-off)를 강조한다. 우리의 접근 방식이 유사한 패턴을 보이는지 조사하기 위해, 우리는 훈련 과정 전반에 걸쳐 평균 토큰 소비량과 오케스트레이션된 에이전트 수를 시각화한다.
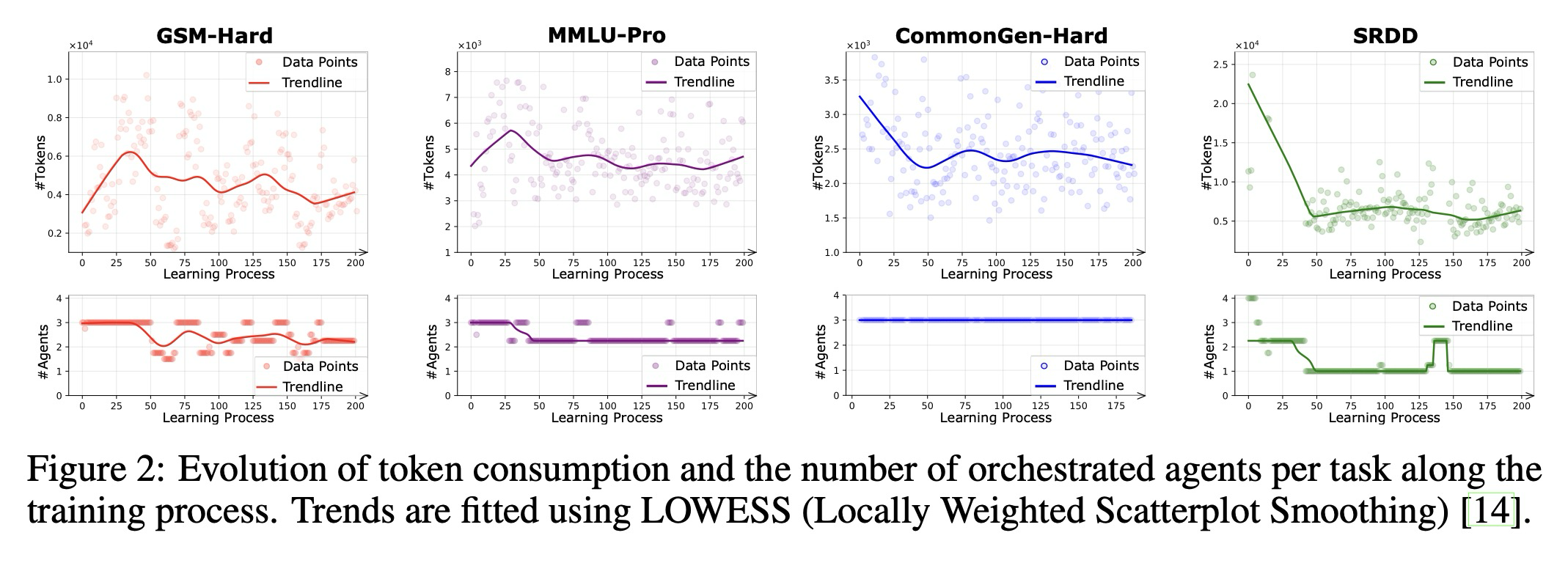
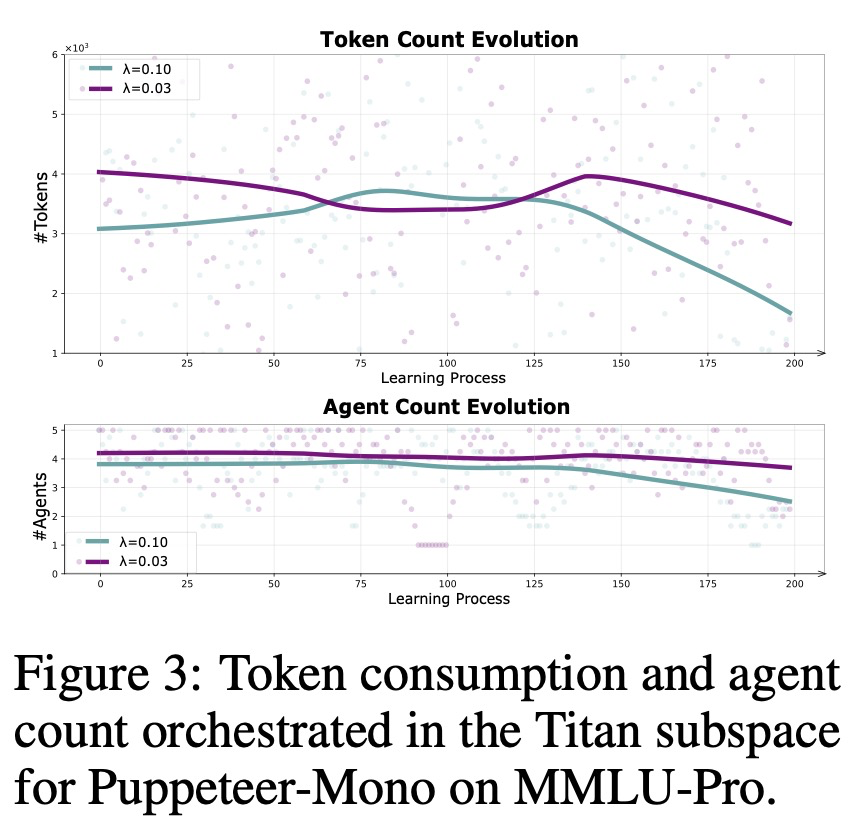
그림 2에 나타난 바와 같이, 토큰 메트릭은 거의 모든 설정에서 학습 과정 동안 일관되게 감소한다. 이는 우리 시스템의 성능 향상이 계산 오버헤드 증가를 대가로 오지 않음을 입증하며, 오히려 효과성과 효율성 모두에서 동시적인 진전을 달성한다는 것을 보여준다. 이러한 결과는 주로 조정 가능한 가중치 계수 를 통해 정확도와 효율성의 균형을 맞추는 우리의 보상 설계 덕분이며, 이는 다양한 애플리케이션 요구에 맞춘 적응 가능한 트레이드오프를 가능하게 한다. 특히, 값이 높을수록 비용 최소화에 더 큰 중점을 둔다 (Figure 3). 구체적으로, 보상은 오케스트레이터가 다음을 수행하도록 장려하도록 설계된다: (i) 성능을 유지하면서 토큰 사용량을 줄여 태스크를 완료하는 에이전트를 우선시하고, (ii) 종결자 에이전트(Terminator agent)를 호출하여 추론을 조기에 종료함으로써, 중복되거나 기여도가 낮은 에이전트를 제외하여 효율성을 촉진한다. 이 메커니즘은 오케스트레이터가 전반적인 성능과 자원 소비를 모두 최적화할 수 있도록 한다. 극단적인 경우, 보상 설계에서 효율성 요소가 완전히 생략되면, 시스템은 잠재적으로 추가적인 성능 향상을 가져오지만, 자연스럽게 전통적인 대규모 협업 프레임워크로 퇴화한다.
더 구체적으로, Titan 설정에서는 학습 과정 동안 활성화된 에이전트의 수가 눈에 띄게 감소하는데, 이는 오케스트레이터가 보다 효율적인 문제 해결을 위해 추론 프로세스를 점진적으로 더 일찍 종료하는 것을 학습한다는 것을 시사한다. 이와 대조적으로, Mimas 설정(결과는 부록 참조)에서는 오케스트레이션된 에이전트의 수가 상대적으로 안정적으로 유지되며, 이는 에이전트의 비교적 제한된 역량 때문에 오케스트레이터가 추론 프로세스를 성급하게 중단하는 데 신중함을 나타낸다. 이 경우, 토큰 소비량 감소는 주로 더 짧은 추론 체인을 통해서가 아니라 더 낮은 비용의 에이전트를 우선적으로 선택함으로써 달성된다. Titan과 Mimas 간의 이러한 대비는 에이전트 역량의 근본적인 차이에서 발생한다. Titan 에이전트는 작업을 더 효율적으로 해결할 수 있어 품질 손실 없이 조기 중단이 가능하지만, Mimas 에이전트는 안정적인 완료를 보장하기 위해 종종 더 길고 정교한 추론 프로세스를 필요로 한다.
3.3 How Does Organizational Topology Evolve During Reinforcement?
다중 에이전트 협업의 출현하는 조직화를 명확히 하기 위해, 우리는 학습 과정 전반에 걸쳐 에이전트 상호작용 토폴로지의 진화를 체계적으로 조사한다. 다중 에이전트 추론은 우리의 중앙 집중식 오케스트레이터에 의해 지배되는 동적 오케스트레이션으로 추상적으로 모델링될 수 있지만, 경험적 증거는 훈련되지 않은 "초기화된" 다중 에이전트 시스템(MAS)이 종종 고도로 정교하고 적응적인 조직 구조를 초래한다는 것을 보여준다. 정적인 구조에 의존하는 대신, 우리의 꼭두각시 조종자는 현재 추론 상태에 기반하여 각 추론 단계에서 활성화할 다음 에이전트를 선택함으로써 트리, 그래프 및 주기(cycles)와 같은 복잡한 토폴로지 모티브를 동적으로 구성한다. 따라서 토폴로지는 추론 중에 점진적으로 출현하며, 유연하고 상황 인식적인 조직 패러다임을 구현한다.
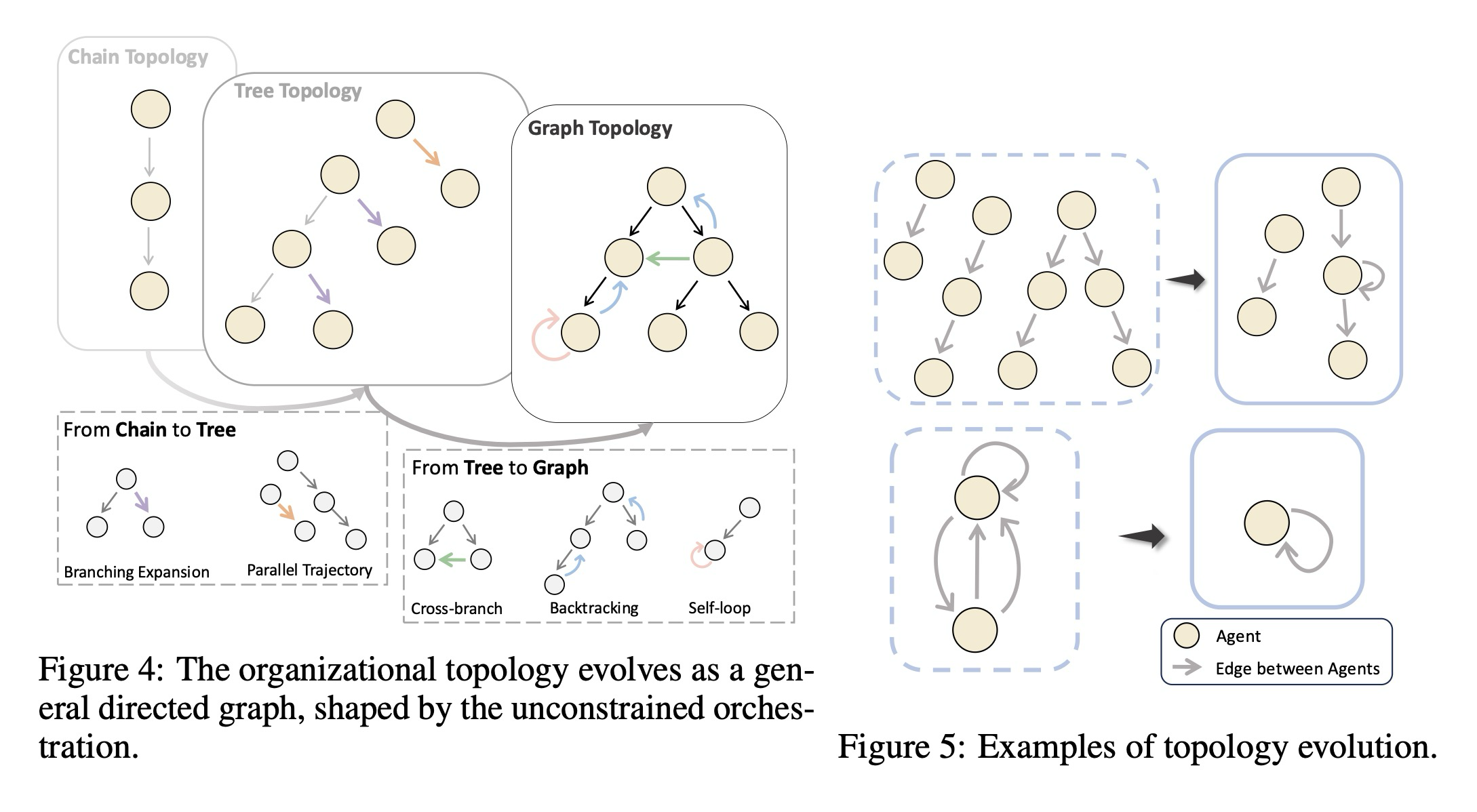
다중 에이전트 협업의 가장 단순한 형태는 종종 체인 구조로 표현되지만, 꼭두각시 조종자의 동적 오케스트레이션은 각 단계에서 하나 또는 여러 에이전트의 선택을 가능하게 함으로써 트리 구조의 상호 작용을 자연스럽게 조성한다. 이 메커니즘은 분기 행동과 병렬 경로를 지원하며, 에이전트 수가 증가함에 따라 확장성을 향상시킨다. 그러나 분기에 의해 주도되는 트리와 유사한 확장과의 초기 유사성에도 불구하고, 결과적인 토폴로지는 본질적으로 그래프 구조를 가진다. 이러한 특성은 반복적인 에이전트 활성화를 허용하여 주기 및 피드백 루프로 이어지는 유연한 오케스트레이션에서 발생한다. 더욱이, 교차 분기 연결(cross-branch connections)이 유기적으로 출현하며, 풍부하고 표현력이 뛰어나며 적응적인 상호 작용 패턴을 생성하는 시스템의 능력을 강조한다. 주기, 백트래킹(backtracking), 및 교차 분기 링크를 포함하는 이러한 출현하는 모티브의 대표적인 예는 그림 4에 설명되어 있다.
꼭두각시 조종자가 시간이 지남에 따라 진화함에 따라, 그 오케스트레이션 행동도 그에 따라 변화하며, 결과적인 MAS에서 구별되는 행동으로 이어진다. 여기서 우리는 출현하는 최적화 효과를 보여주기 위해 초기 단계와 진화된 단계 모두에서 선택된 특정 샘플을 제시한다. 그림 5에서 볼 수 있듯이, 초기 단계는 탐색적 조직화를 반영하는 다수의 분리된 체인들을 특징으로 한다. 진화 후에는 경로가 줄어들고 주기가 나타나며, 이는 더 안정적이고 조정된 상호 작용을 나타낸다. 또한, 초기 단계는 더 높은 오버헤드를 가진 두 에이전트 통신을 특징으로 한다. 진화가 진행됨에 따라, 구조는 지속적인 추론을 처리하는 단일 에이전트로 응축되며, 이는 더 효율적인 조정 및 의사 결정을 반영한다.
경험적 관찰은 다양한 에이전트 간 연결을 가진 그래프 구조 토폴로지를 조성하는 꼭두각시 조종자의 동적 오케스트레이션이 두 가지 주요 구조적 현상인 압축(compaction)과 주기성(cyclicality)을 발생시킨다는 것을 보여준다. 밀집하게 군집된 에이전트와 빈번한 통신 주기 사이의 진화하는 상호 작용은 다중 에이전트 시스템에서 느슨하게 조직된 탐색적 상호 작용에서 긴밀하게 조정된 전문화된 집단으로의 전환이라는 중요한 변화를 나타낸다.
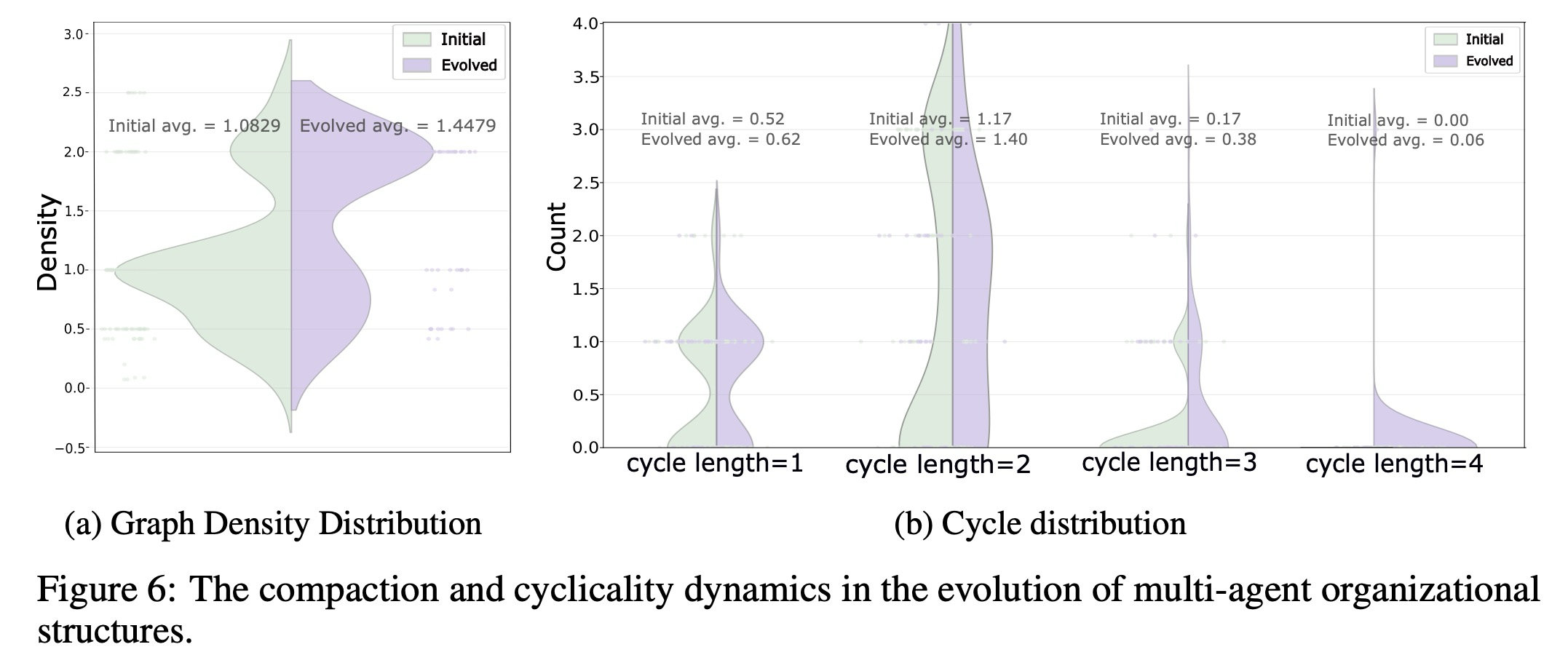
- Compaction. 우리는 학습 과정에서 구조적 압축을 향한 현저한 경향을 관찰한다 (그림 6a). 최적화가 진행됨에 따라, 에이전트 간 연결 정도를 정량화하는 그래프 밀도(graph density)는 꾸준히 증가하며, 조직 구조는 고도로 상호작용적이고 긴밀하게 연결된 서브 네트워크(subnetworks)를 향해 진화한다. 통신은 반복적으로 활성화되는 '허브' 에이전트의 하위 집합 사이에서 점진적으로 집중되며, 빈번하고 집중적인 정보 교환을 특징으로 하는 밀집된 서브 그래프를 형성한다. 이 현상은 오케스트레이터가 강력한 에이전트의 작은 집단을 통해 결정을 우선적으로 라우팅하여 반복적인 추론과 협력적 합의 형성을 강화하는 Titan(대형 모델) 서브스페이스에서 특히 두드러진다. 궁극적으로, 시스템은 확산적이고 탐색적인 상호 작용 패턴에서 고도로 시너지 효과를 내고 집중된 다중 에이전트 추론으로 전환한다.
- Cyclicality. 압축과 함께, 우리는 학습이 진행됨에 따라 주기 형성(cycle formation)이 크게 증가함을 기록한다 (그림 6b). 에이전트가 폐쇄 루프 경로를 통해 이전 협력자를 반복적으로 다시 방문하는 주기적 토폴로지는 중간 결과의 재순환, 상호 검증 및 지속적인 개선을 용이하게 한다. 엄격하게 계층적이거나 비순환적인 네트워크와 달리, 이 주기적 구조는 재귀적인 비판과 지속적인 내부 토론을 지원하며, 이는 반성적 다중 에이전트 패러다임에서 보이는 것과 매우 유사하다. 주기가 더욱 만연해짐에 따라, 시스템은 더 깊은 내부 피드백, 정보의 더 효율적인 재사용, 그리고 증가된 복원력을 보여주는데, 이는 성숙하고 자체 참조적인 협력적 추론의 특징이다.
3.4 How to Further Use Hyperparameters to Control Performance and Efficiency?
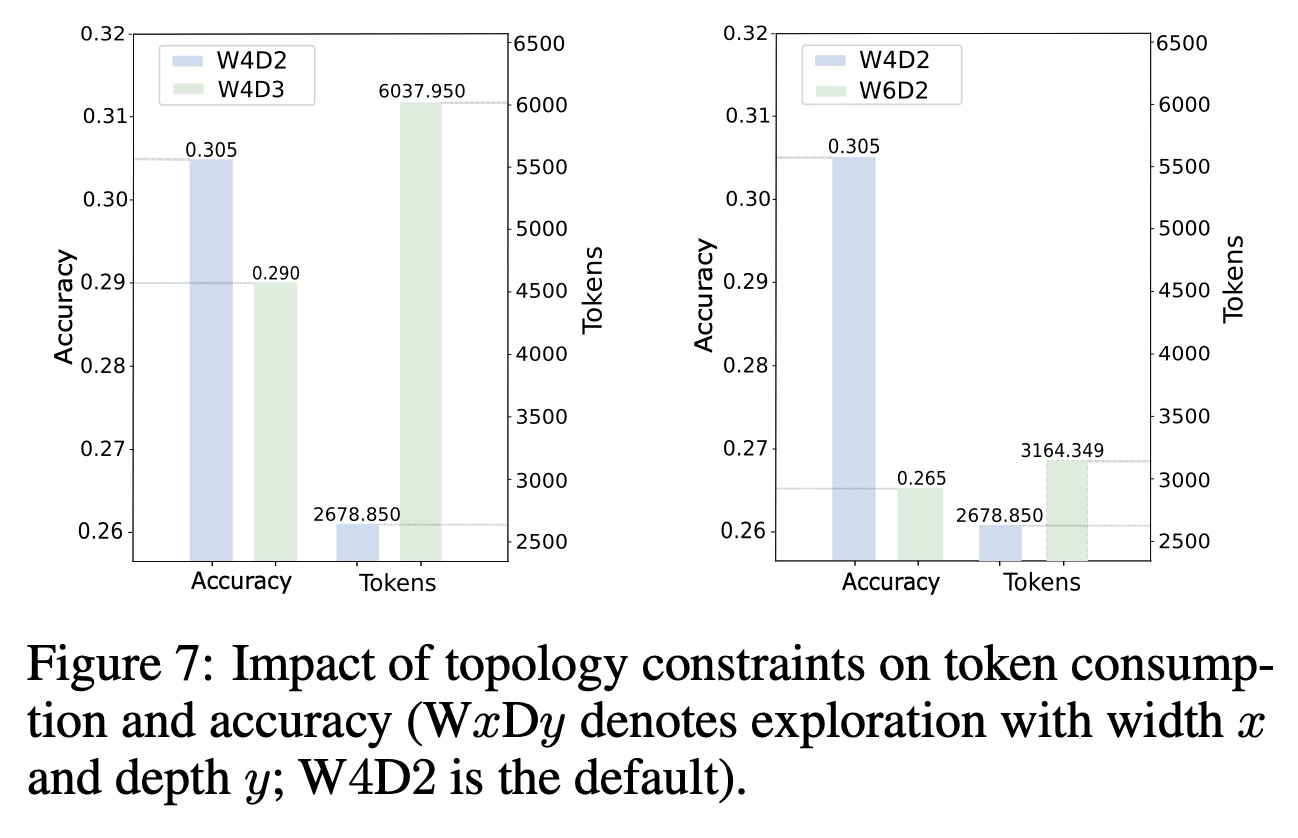
보상 조형(reward shaping)이 효율성 제어를 위한 직접적인 메커니즘을 제공하지만, 협업 구조 자체 또한 매우 중요한다. 오케스트레이터가 에이전트 협업을 조직할 때, 토폴로지에 대한 상한 제약 조건—구체적으로 체인 깊이(chain depth)와 탐색 너비(exploration width)—는 무한한 확장과 비효율성을 방지하는 데 필수적이다. 깊이는 오케스트레이션된 에이전트 체인의 길이를 의미하는 반면, 너비는 병렬 탐색의 수를 포착한다. 그림 7에서 보듯이, 명확한 비단조적 관계가 존재한다. 즉, 기본 설정이 우리의 목적에 가장 적합한 트레이드오프를 달성하는 반면, 깊이나 너비를 증가시키면 중복성, 더 높은 계산 비용, 그리고 성능 저하 가능성으로 이어진다. 일반적으로 정확도를 높이면 토큰 소비가 증가하는 경향이 있으며, 그 반대도 마찬가지이다. 이는 깊이와 너비를 신중하게 균형 있게 맞추는 것이 효율성과 효과성 모두를 유지하는 데 도움이 될 수 있음을 시사한다.
4. Related Work
LLM의 급속한 발전은 자율적인 LLM 기반 에이전트의 개발을 촉진한다. 이 에이전트들은 계획, 메모리, 도구 사용에서 강력한 능력을 보인다. 이러한 에이전트들은 복잡한 작업을 처리하고, 동적인 실제 환경에 적응하며, 협업 및 의사 결정과 같은 인간과 유사한 행동을 보여주는 데 숙련도가 증가하고 있다. 단일 LLM 기반 에이전트가 다양하고 복잡한 실제 작업을 처리하는 데 어려움을 겪을 수 있다는 점을 고려하여, 최근 연구는 소프트웨어 개발, 사회 시뮬레이션, 의료 처치, 과학적 발견을 위한 LLM 기반 다중 에이전트 시스템을 구축하는 데 점점 더 집중하고 있다.
초기 MAS 설계는 폭포수 모델과 같은 소프트웨어 엔지니어링 패러다임을 반영하는 것과 같이 고정된 수작업 구조에 의존한다. 이러한 정적인 접근 방식은 경직된 조정, 제한된 워크플로우 유연성, 그리고 최적화되지 않은 에이전트 구성으로 이어진다. 이러한 문제를 해결하기 위해 보다 적응적인 오케스트레이션 방법들이 등장한다. 예를 들어, 네트워크 스타일 조직은 에이전트를 동적으로 선택하며 (Dylan), 최적화 가능한 그래프는 프롬프트 개선 및 더 나은 협력을 가능하게 한다 (GPT-Swarm, MacNet). 또한 코드 기반 표현은 동적이고 작업별 프로세스 모델링을 허용한다. 최근 접근 방식들은 코드 공간 검색 (ADAS, AFlow)을 사용하거나 LLM이 주문형으로 MAS 구성을 생성하도록 훈련한다 (MAS-GPT). LLM 기반 MAS를 넘어, 고전적인 MARL(다중 에이전트 강화 학습) 작업들은 오랫동안 조정과 역할 특성화를 탐구해 왔으며, 이는 LLM 기반 다중 에이전트 시스템에서 우리의 RL 기반 오케스트레이션에 중요한 영감을 제공한다.
5. Conclusion
우리는 인형극 오케스트레이션에서 영감을 받은 적응형 다중 에이전트 LLM 협업을 위한 새로운 프레임워크를 제안한다. 이 프레임워크에서 중앙 집중식의 학습 가능한 "퍼피티어(puppeteer)" 오케스트레이터는 지향성 사고 그래프(directed graph-of-thoughts) 내에서 에이전트를 동적으로 활성화한다. 정적이거나 수동으로 설계된 토폴로지를 가진 이전 방법과 달리, 우리의 접근 방식은 상황 인식 오케스트레이션과 강화 학습 기반 정책 적응을 통합하여 더욱 체계적이고 효율적인 협업을 가능하게 한다. 다양한 작업에 대한 실험 결과, 우리의 방법은 우수한 솔루션 품질과 감소된 계산 비용을 달성했음을 보여준다. 분석을 통해 오케스트레이터가 압축적이며 순환적인(cyclic) 추론 구조를 촉진함으로써 성능 향상을 뒷받침했음이 추가로 밝혀진다. 우리는 이 연구가 다중 에이전트 협업에서 동적이고 확장 가능한 조정을 향한 가치 있는 단계가 될 수 있기를 희망한다.
