Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens
Paper Translate
Author: Yiming Qin, Bomin Wei, Jiaxin Ge, Konstantinos Kallidromitis, Stephanie Fu, Trevor Darrell, Xudong Wang
Affilation: UC Berkeley, UCLA, Panasonic AI Research
Venue: arXiv
Comments:
Date: November 2025
Paper Link: https://arxiv.org/abs/2511.19418
⭐️ Key Takeaways
1. COVT(Chain-of-Visual-Thought)의 도입은 VLMs가 이산적인 언어 공간의 한계를 넘어 연속적인 시각 토큰을 통해 추론할 수 있도록 하여, 공간 추론 및 기하학적 인식과 같은 조밀한 시각 인지 능력을 향상시킨다.
2. COVT는 분할(Segmentation), 깊이(Depth), 에지(Edge), DINO 특징과 같은 상호 보완적인 속성을 포착하는 경량 시각 전문가들로부터 지식을 증류하며, 이는 모델이 명시적인 시각 맵이나 외부 도구 호출 없이도 정교한 지각 지식을 자체 토큰 공간에 내재화하도록 한다.
3. COVT를 Qwen2.5-VL 및 LLaVA와 같은 강력한 VLMs에 통합한 결과, CV-Bench에서 5.5%의 전체 성능 향상과 깊이 하위 작업에서 14.0%의 향상 등 다양한 시각 중심 벤치마크 전반에서 일관되고 상당한 성능 개선을 입증한다.
Abstract
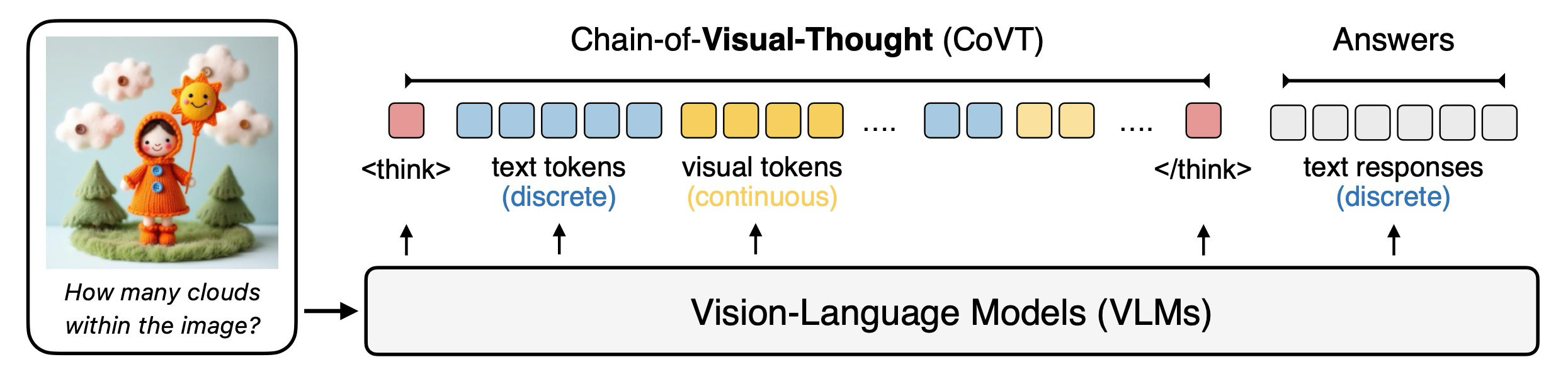
Figure 1: VLM의 추론을 제한된 표현의 이산적 언어 공간에 제한하는 대신, COVT는 visual thought chain을 형성하여 VLM이 연속적 시각 공간에서 추론을 가능하게 한다.
시각-언어 모델(VLMs)은 언어적 공간에서의 추론에 뛰어나지만, 공간 추론 및 기하학적 인식과 같은 조밀한 시각적 인식이 필요한 지각적 이해에는 어려움을 겪는다. 이러한 한계는 현재의 VLMs가 공간 차원에 걸친 조밀한 시각 정보를 포착하는 데 제한적인 메커니즘을 가지고 있다는 사실에서 비롯된다. 본 논문은 VLMs가 단어뿐만 아니라 연속적인 시각 토큰(풍부한 지각적 단서를 인코딩하는 압축된 잠재 표현)을 통해서도 추론할 수 있도록 하는 프레임워크인 Chain-of-Visual-Thought (COVT)를 도입한다. 약 20개의 토큰이라는 작은 예산 내에서, COVT는 2D 외관, 3D 기하학, 공간 배치, 에지 구조와 같은 상호 보완적인 속성을 포착하는 경량 시각 전문가들로부터 지식을 증류(distill)한다. 학습 중에, COVT를 사용하는 VLM은 이러한 시각 토큰들을 자기 회귀적으로 예측하여 조밀한 지도 신호(예: 깊이, 분할, 에지 및 DINO 특징)를 재구성한다. 추론 시에는, 모델이 연속적인 시각 토큰 공간에서 직접 추론하며, 효율성을 유지하는 동시에 해석 가능성을 위해 선택적으로 조밀한 예측을 디코딩한다. CV-Bench, MMVP, RealWorldQA, MMStar, WorldMedQA 및 HRBench를 포함한 10개 이상의 다양한 지각 벤치마크에 걸쳐 평가한 결과, Qwen2.5-VL 및 LLaVA와 같은 강력한 VLM에 COVT를 통합하면 성능이 일관되게 3%에서 16%까지 향상되며, 압축된 연속적 시각적 사고가 보다 정밀하고, 근거 있으며, 해석 가능한 멀티모달 지능을 가능하게 한다는 것을 입증한다.
1. Introduction
시각-언어 모델(Vision-Language Models, VLMs)은 현대 멀티모달 지능의 초석이 되었으며, 텍스트와 시각 전반에 걸친 이해와 추론에서 놀라운 발전을 달성한다. VLMs는 시각적 입력을 언어 중심의 토큰 공간으로 투사(project)함으로써, 대규모 언어 모델(LLMs)이 가진 강력한 합성(compositional) 및 논리적 추론 능력을 계승하며, 자연어를 통한 통일된 멀티모달 상호작용을 가능하게 한다. 텍스트 기반의 사고의 연쇄(Chain-of-Thought, CoT) 추론에 대한 최근의 발전은 이러한 패러다임을 더욱 확장하여, 구조화된 중간 추론 단계가 논리, 수학, 지식 기반(knowledge grounding)과 관련된 작업에서 성능을 크게 향상시킬 수 있음을 보여준다. 하지만 이러한 성공에도 불구하고, 이러한 추론은 근본적으로 언어에 묶여 있다. 연속적인 시각 정보가 이산적인 텍스트 공간으로 투사될 때, 경계, 레이아웃, 깊이, 기하학적 구조와 같은 풍부한 지각적 단서들은 손실되거나 제대로 표현되지 못한다. 하지만 이것들은 바로 인간이 시각적 세계에 대해 추론할 때 의존하는 정교한 신호들이다. 결과적으로, 현재의 VLMs는 강력한 시각 인코더를 갖추었음에도 불구하고, 개수 세기(counting), 공간 대응(spatial correspondence), 상대 깊이 추정과 같은 지각 집중적인 작업에서 종종 어려움을 겪는다(그림 2 참조). 더욱이, 시각적 추론을 이산적인 텍스트 병목 현상(discrete text bottleneck)을 통해 강제함으로써, 모델은 연속적인 공간적 및 기하학적 관계를 말로 표현(verbalize)해야만 한다. 그 결과, 텍스트 전용 CoT는 시각적 추론 성능을 오도하거나 심지어 저하시킬 수 있다. 실제로 Qwen3-VL-Thinking이 언어 CoT를 사용하여 공간 이해 벤치마크(예: V*, HRBench8k, VSI-Bench)에서 Qwen3-VL-Instruct보다 5% 이상 낮은 성능을 보이는 것으로 나타난다. 이는 근본적인 한계를 드러낸다: 시각 정보는 본질적으로 연속적이고 고차원적이지만, 기존 모델들은 복잡한 지각적 추론의 충실성(fidelity)이 부족한 상징적 언어 토큰을 사용하여 이를 추론한다.
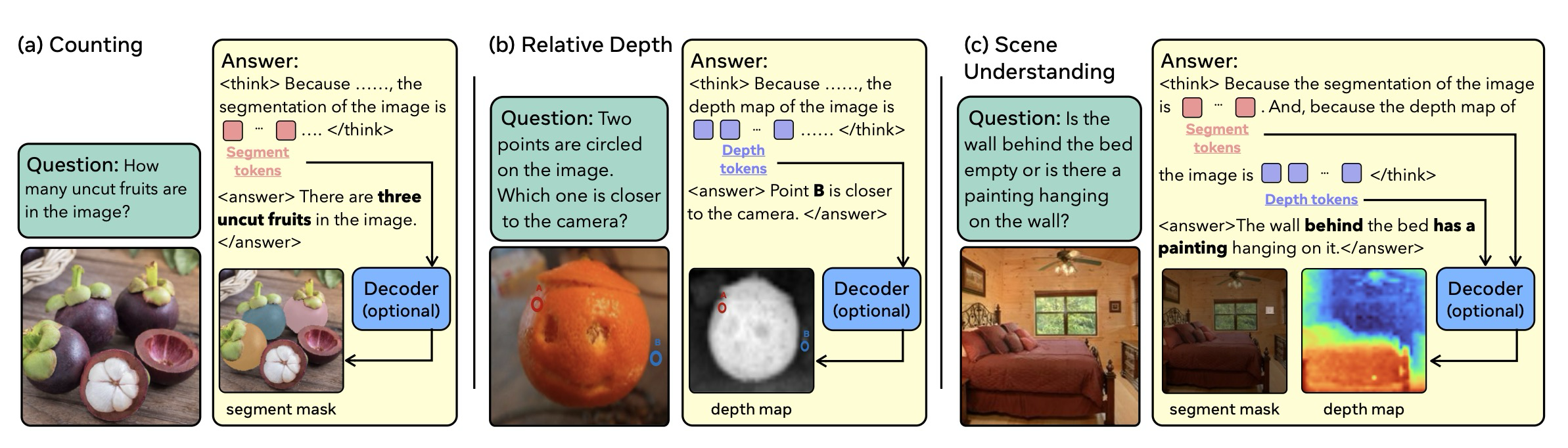
Figure 2: Continuous visual thinking with COVT
자연스러운 해결책은 외부 시각 도구로 VLMs를 보강하여, 미리 구축된 전문 모델을 활용해 정교한 지각을 복구하는 것이다. 이 접근 방식은 공간적 및 기하학적 정보를 부분적으로 복원할 수 있지만, 다음과 같은 중대한 단점을 초래한다: 지각이 외부 도구에 위임되며, 그 결과는 도구의 능력에 의해 제한된다. 또한 더 높은 GPU 비용을 발생시킨다. 또 다른 해결책은 사고 과정에서 이미지를 생성하거나 자르는 것인데, 이러한 해결책들 역시 이미지를 텍스트 공간으로 투사하여 조밀한 시각 정보를 잃는다. 이러한 한계들은 다음과 같은 중심적인 질문을 야기한다: VLMs는 모든 것을 단어로 번역하는 대신, 시각적으로 생각함으로써 인간처럼 추론하는 것을 배울 수 있는가? 더 구체적으로 말해, 효율성을 유지하고 자체 포함된(self-contained) 상태를 유지하면서, 정교한 시각 신호를 VLM의 추론 과정에 직접 주입하여 모델이 동시에 "보고" "생각"하도록 할 수 있는가? 그렇다! 우리는 Chain-of-Visual-Thoughts (COVT)를 제안한다.
COVT는 연속적인 시각 토큰 공간에 VLMs를 기반(grounding)하여 풍부한 지각적 단서에 대해 추론할 수 있게 한다. 각 시각 토큰 그룹은 특정 시각적 특징을 인코딩하는 경량 지각 전문가(예: 분할(segmentation), 깊이(depth), 에지 감지(edge detection), 또는 자체 지도 표현 학습(self-supervised representation learning))에 해당한다. 학습하는 동안, VLM은 추론 체인 내에서 이러한 연속적인 시각 토큰을 예측하도록 요청받으며, 풍부한 지각 정보를 압축된 잠재 공간으로 압축한다. 그런 다음 이 잠재 토큰들은 작업별 경량 디코더(task-specific lightweight decoders)에 의해 디코딩되어 해당 전문가 목표(예: 분할 마스크, 조밀한 깊이 맵, 에지 맵, 또는 DINO 특징)를 재구성한다. 우리는 재구성 및 증류(distillation) 손실을 연속적인 토큰을 통해 역전파(back-propagate)하며, 모델의 내부 잠재 표현을 전문가 지침과 정렬(align)시킨다. 이 과정은 COVT가 명시적인 시각 맵이나 외부 도구 호출 없이도 정교한 지각 지식을 자체 토큰 공간에 직접 내재화하도록 한다.
더 구체적으로, 우리는 정교한 시각적 추론의 다양한 측면을 강조한다. 우리는 작업 중심 전문가 (예: SAM, DepthAnything v2, PIDINet)와 표현 기반 전문가 (예: DINO, 대조 학습 인코더(contrastive encoders))를 모두 통합하며, 각각에 맞춘 정렬 전략을 사용한다. 작업 중심 신호는 프롬프트 수준에서 정렬되는 반면, 표현 기반 신호는 투사(projection) 후 특징 공간에서 정렬된다. 학습은 이해(comprehension), 생성(generation), 추론(reasoning), 효율적인 추론(efficient reasoning)의 네 단계를 통해 진행되며, 모델에게 시각적 사고를 사용하여 효과적으로 추론하는 방법을 점진적으로 가르친다.
추론 시, 모델은 시각적 사고의 연쇄를 형성하고, 양식을 가로질러 추론하여 의미적으로 일관되고 지각적으로 기반이 탄탄한(perceptually grounded) 답변을 생성한다. 이 자체 포함적이고 미분 가능한(self-contained, differentiable) 프로세스는 VLM이 연속적인 시각 공간에서 직접 "생각"하도록 하여, 내부 추론과 지각적 이해 사이에 더욱 충실한 다리를 제공한다. 또한, 이 설계는 해석 가능한 멀티모달 지능을 지원하며, 사용자가 원할 경우 모델의 시각적 사고 과정을 시각화할 수 있도록 한다. 시각화가 필요하지 않은 경우, COVT는 조밀한 예측으로 디코딩하지 않고도 연속적인 시각 토큰만으로 작동할 수 있으므로 효율성을 유지한다.
다양한 지각 벤치마크에 걸쳐 평가된 COVT는 정교한 시각적 추론을 일관되게 향상시키며, 일반(비시각 중심) 벤치마크에서는 경쟁적인 성능을 유지하면서 시각 중심 작업에서 강력한 VLM 기준선보다 우수한 성능을 보인다. 예를 들어, COVT는 CV-Bench에서 5.5%의 전체 성능 향상을 달성하며, 깊이 하위 작업에서는 14.0%라는 상당한 개선을 보여주고, HRBench에서는 4.5%의 전체 성능 향상을 이룬다. 또한, COVT는 유연한 해석 가능성을 제공한다: 연속적인 시각 토큰은 인간이 읽을 수 있는 조밀한 예측으로 디코딩될 수 있으며, 사용자가 원할 때 모델의 기저 시각적 추론 과정에 대한 창을 제공한다. 종합적으로, 이러한 결과들은 압축된 연속적인 시각적 사고가 더욱 정확하고, 기반이 탄탄하며, 해석 가능한 멀티모달 지능을 가능하게 함을 입증한다.
우리의 주요 기여는 다음과 같다:
- 우리는 VLMs에게 멀티모달 사고의 구성 요소 역할을 하는 압축된 지각 표현인 연속적인 시각 토큰을 통해 추론할 수 있는 능력을 부여하는 프레임워크인 Chain-of-Visual-Thought를 제안한다.
- 우리는 VLMs가 연속적인 시각 공간 내에서 효과적으로 학습, 해석 및 추론할 수 있도록 하는 맞춤형 정렬 전략과 학습 파이프라인 (이해, 생성, 추론, 효율적인 추론)을 개발한다.
- 우리는 다양한 벤치마크에서 일관된 성능 향상을 입증하며, 연속적인 시각 토큰이 지각적 기반(perceptual grounding)과 해석 가능성을 모두 향상시킨다는 것을 보여준다.
2. Related Work
Tool-Augmented Reasoning
VLMs에 외부 도구를 장착하면 대상 시각 작업을 위해 전문화된 시각 모델을 사용할 수 있게 한다. 이는 성능을 향상시키지만, 계산 오버헤드 또한 발생시킨다. 더욱이, 도구 사용은 본질적으로 제약이 있으며, 최종 성능은 추론 과정 자체가 아닌 각 도구의 능력에 의해 제한된다. 본 연구에서 우리는 유연하게 추론을 수행하고 외부 시각 도구에 의존하지 않는, 자체 포함된(self-contained) 시각적 추론을 고려한다.
Text Space Reasoning
사고의 연쇄(Chain-of-Thought, CoT)와 같은 텍스트 공간 추론 방법들은 언어 추론에서 큰 성공을 거두었으며, 수학, 과학, 논리적 추론과 같은 문제들을 해결한다. CoT 능력을 가진 LLM의 강력한 성능은 DeepSeek-R1과 같은 모델에서 광범위하게 채택되고 성공하는 결과를 낳는다. 텍스트 CoT의 성공과 함께, 많은 연구들이 추론을 시각 양식(modality)으로 확장했다. 한 가지 직접적인 접근 방식은 조밀한 캡션(dense captions)을 생성한 다음 언어 공간에서 추론하는 것이지만, 이 과정은 본질적으로 정보 손실을 수반한다. 우리는 COVT를 표 1에서 최근의 멀티모달 추론 패러다임들과 비교한다.
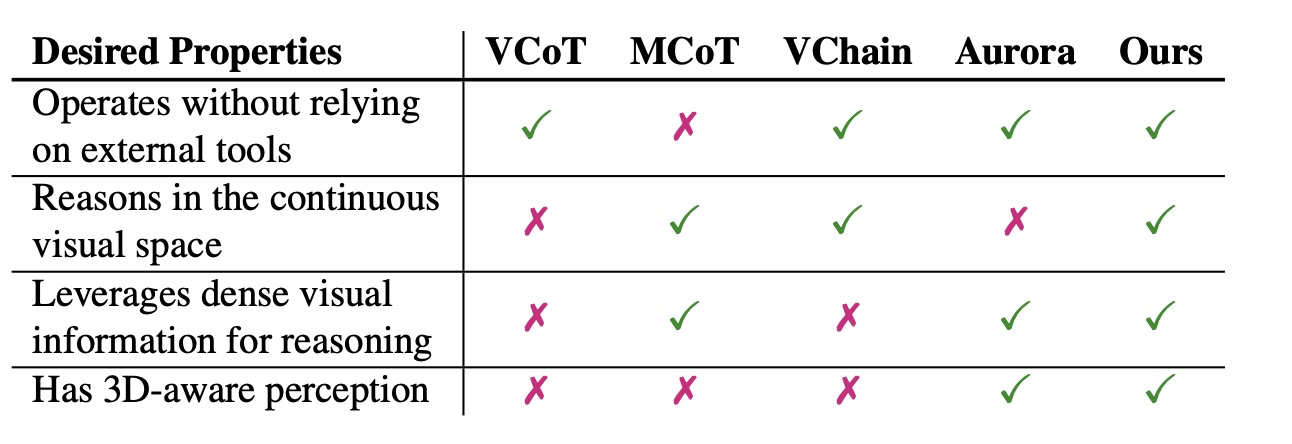
Table 1: Comparison of key properties with prior multimodal reasoning methods
Visual CoT는 이미지의 텍스트적 해석에 의존하며, 추론을 이산적인 텍스트 공간으로 제한한다. MCoT는 보조 이미지를 편집하거나 생성함으로써 연속적인 시각적 추론을 가능하게 하지만, 상당한 계산 자원을 요구하며 유연성이 부족하다. VChain은 추론 체인에 이미지와 텍스트를 교차 삽입하지만, 여전히 이미지를 텍스트 공간으로 투사함으로써 시각 정보를 손실한다. VCoT, MCoT, VChain, Aurora와 같은 이전 방법들과 달리, COVT는 모든 바람직한 속성(연속적인 시각 공간에서 추론하고, 조밀한 시각적 단서를 활용하며, 3D 인식을 유지하고, 외부 도구 없이 완벽하게 작동하는 것)을 고유하게 만족시킨다. COVT는 연속적인 시각적 추론, 조밀한 지각적 단서, 그리고 3D 인식 이해를 단일한 자체 포함된 프레임워크 내에서 고유하게 결합한다.
Latent Space Reasoning
동시 진행 중인 연구들은 잠재 공간에서의 추론이 복잡한 다단계 작업에서 LLM을 강화할 수 있음을 보여준다. Coconut은 연속적인 잠재 임베딩이 명시적인 CoT보다 더 효율적이라는 것을 발견하며, CCoT는 더 조밀한 추론을 위해 CoT를 연속적인 토큰으로 압축한다. 다른 연구들은 특수화된 추론 토큰을 탐색하거나 은닉 상태를 암시적인 추론 경로로 사용한다. 잠재 추론은 VLMs로도 확장되었다. Aurora는 깊이 및 탐지 신호의 VQ-VAE 잠재 요소를 사용하여 깊이 추정 및 개수 세기를 향상시키는 반면, Mirage는 시각적 추론 작업을 위해 잠재적 상상(latent imagination)을 사용한다. 본 연구인 COVT는 이러한 이전 기여들을 기반으로 한다: 우리는 연속적인 잠재 공간에 직접 내재된 도구 사용의 형태를 도입하며, 여기서 암시적인 '도구'들은 특정 지각 전문가들과 연결된 시각적 사고 토큰들이다.
3. Chain-of-Visual-Thought
우리는 먼저 3.1절에서 머리말(preamble)을 소개한다. 그 후 3.2절에서 COVT의 전반적인 파이프라인을 보여준다. 또한 시각 토큰 카테고리를 선택하는 방법과 서로 다른 시각 토큰들이 정렬(align)되는 방식을 3.3절에서 논의한다. 마지막으로, 3.4절에서 모델 훈련 파이프라인, 예를 들어 훈련 손실 공식과 데이터 프레임워크 설계를 제시한다.
3.1 Preamble
기존의 시각-언어 모델(VLMs)은 정교한 시각적 추론에 있어 두 가지 핵심적인 한계에 직면한다. 1) 텍스트 전용 사고의 연쇄(Text-only CoT)는 오류를 축적한다. 텍스트 전용 CoT는 긴 사고의 연쇄를 실행하며, 이는 초기 단계에서 오류를 발생시킬 수 있다. 이러한 실수들은 누적되어 궁극적으로 부정확한 최종 결과로 이어진다. 따라서 우리는 짧고 효과적인 추론이 필요하다. 2) 감독(Supervision)이 텍스트 응답에 지배된다. 이는 모델이 에지, 깊이 또는 영역과 같은 저수준 지각 단서를 포착하도록 하는 동기를 거의 제공하지 않는다. 우리는 VLMs 자체에 이미지로부터 정교한 시각 정보를 추출하는 능력을 부여할 필요가 있으며, 이 정보는 시각 디코더를 통해 추가적으로 디코딩될 수 있다. COVT는 언어와 시각 양쪽에서 자체 포함적이고 해석 가능한 방식으로 유연하게 사고할 수 있는 차세대 멀티모달 추론 시스템을 위한 토대를 제공하고자 한다.
3.2 COVT Overall Pipeline
우리는 시각적 사고의 연쇄로 VLM을 확장하는 프레임워크인 COVT를 제안한다. 그림 3은 COVT 파이프라인의 개요를 보여준다. 본질적으로, 이 프레임워크는 VLM에 연속적인 시각 토큰 공간 내에서 정교한 시각적 표현을 출력할 수 있는 능력을 부여하며, 이를 통해 모델은 풍부한 지각 정보에 대해 직접 추론하고 추론 과정 전반에 걸쳐 공간적 및 기하학적 일관성을 유지하도록 한다.
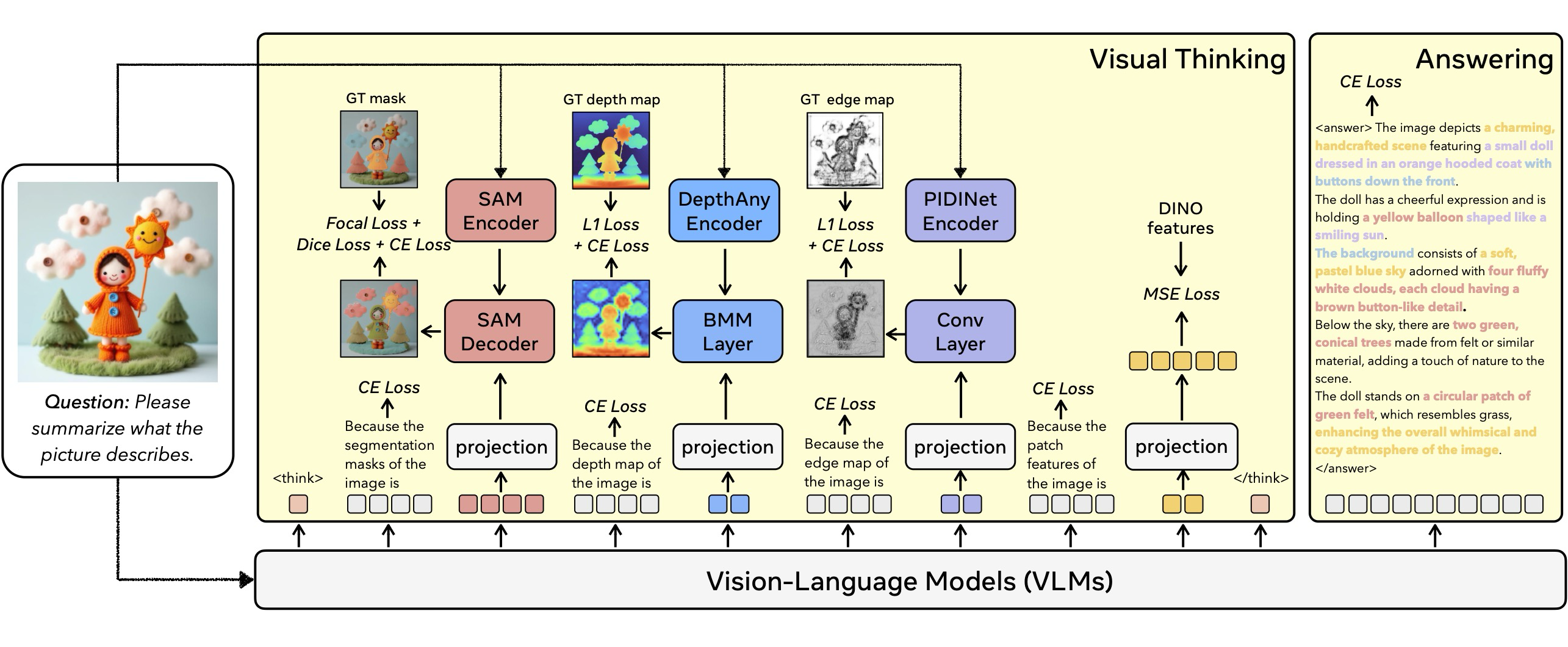
Figure 3: The training pipeline of COVT.
핵심적으로, COVT는 표준 next token prediction 패러다임을 유지한다. 표준 VLM의 경우, frozen 시각 인코더로부터 추출된 시각 특징 와 언어 인코더로부터 추출된 텍스트 특징 가 주어질 때, VLM은 다음과 같이 수열 을 생성할 확률을 추정한다
그림 3에 나타난 바와 같이, COVT는 시각적 사고의 연쇄 토큰(Chain-of-Visual-Thought tokens)을 도입함으로써 이 공식을 확장하며, 이때 각 토큰 는 시각 토큰 또는 텍스트 토큰을 나타낼 수 있다.
COVT 토큰을 VLM에 효과적으로 통합하기 위해, 우리는 모델을 다양한 정교한 지각적 단서를 포착하는 다중 시각 토큰을 생성할 수 있는 조밀한 시각 인코더로서 기능하도록 훈련한다. VLM은 재구성 감독(reconstruction supervision) 하에 작업별 디코더를 통해 시각적 결과물을 재구성하는 CoVT 토큰을 생성하도록 훈련받는다. 이러한 과정을 통해, COVT는 사고의 연쇄 내에서 다중 지각 차원에 걸쳐 풍부하고 정교한 시각 정보를 생성하도록 진화한다.
3.3 COVT Tokens
Token selection based on core perception ability. From Perception to Cognition 논문에서 제안하는 바와 같이, 시각-언어 모델의 시각 중심 지각 능력은 (i) 인스턴스 인식, (ii) 2D 및 3D 공간 관계, (iii) 구조 감지, 그리고 (iv) 의미 정보의 심층 탐색으로 요약될 수 있다. 이러한 분류를 기반으로, 우리는 네 가지 시각 모델을 사용하여 COVT 토큰이 각 능력을 학습하도록 감독한다. (1) 분할(Segmentation) 토큰은 인스턴스 수준의 위치 및 모양 정보를 제공하며, VLMs에 인스턴스 인식 신호와 2D 공간 지각 능력을 부여한다. (2) 깊이(Depth) 토큰은 픽셀 수준의 깊이 정보를 제공하여, VLMs가 3D 공간 관계를 파악하는 능력을 갖추도록 한다. (3) 에지(Edge) 토큰은 기하학적 수준의 세부 정보를 제공하며, 모델이 구조적 단서를 감지하고 2D 공간 정보를 부분적으로 제공하는 데 도움을 준다. (4) DINO 토큰은 이미지의 패치 수준 표현을 제공하여, 풍부한 의미 정보를 전달한다.
Tokens alignment based on granularity of visual models. 작업 지향 모델(Task-oriented models)과 표현 기반 모델(representative models)은 서로 다른 세분성 수준의 결과물을 생성한다. 일반적으로, 작업 지향 모델은 더 세밀한 경향이 있는 반면, 표현 기반 모델은 보통 덜 세밀하다. 우리는 이러한 서로 다른 세분성을 기반으로 각 토큰 유형을 시각 모델과 정렬하기 위해 다른 전략을 채택한다. 핵심적으로, 우리는 두 가지 주요 정렬 방법을 채택한다. 세밀한 작업 지향 모델의 경우, 시각 토큰은 프롬프트 공간으로 투사(project)된 후 디코더와 함께 프롬프트 수준에서 정렬된다. 반면, 표현 기반 모델의 경우, 투사 후 특징 수준에서 인코더와 정렬된다. 투사 레이어(projection layer)는 하나의 멀티 헤드 어텐션 레이어와 두 개의 완전 연결 레이어로 구성된다.
- 분할 토큰: 분할 토큰은 조밀한 시각 특징을 포함하는 작업 지향 모델인 SAM에 의해 감독된다. 우리는 LISA를 따라 분할 토큰을 SAM 디코더와 정렬시키며, 8개의 분할 토큰은 프롬프트 수준에서 정렬된다. 각 토큰은 SAM 디코더에 제공되는 프롬프트 역할을 수행한다. 훈련 과정 동안, 예측된 마스크와 정답 마스크를 매칭하기 위해 헝가리안 매칭 알고리즘이 사용되며, Dice 손실 및 Focal 손실이 적용된다.
- 깊이 토큰: 깊이 토큰은 작업 지향 모델인 DepthAnything v2에 의해 감독된다. 이 토큰들이 조밀한 정보를 포함하므로, 이들 역시 프롬프트 수준에서 디코더와 정렬된다. 우리는 4개의 깊이 토큰을 사용하여 DepthAnythingv2 인코더에서 추출된 조밀한 특징과 배치 행렬 곱셈(BMM)을 통해 상호작용함으로써 깊이 맵을 재구성한다. 최종 깊이 맵은 4개의 재구성된 깊이 맵의 평균이며, 깊이 토큰을 정렬하기 위해 L1 재구성 손실이 사용된다.
- 에지 토큰: 에지 토큰은 PIDINet과 정렬된다. 4개의 에지 토큰 각각은 1 × 1 합성곱 커널로 기능하며, PIDINet 인코더의 조밀한 특징에 적용되어 에지 맵을 재구성한다. 최종 에지 맵은 4개의 재구성된 에지 맵을 평균낸 것이며, L1 손실 함수를 통해 정렬된다.
- DINO 토큰: DINO 토큰은 패치 수준 특징을 추출하는 대표 기반 모델인 DINOv2에 의해 감독된다. 따라서, 4개의 DINO 토큰은 투사 레이어를 사용하여 DINO 특징과 동일한 모양으로 매핑되며, MSE 목표 하에 정렬된다.
3.4 COVT Training
Training Loss. 학습 중에, joint loss function은 다음과 같이 정의한다:
여기서 는 VLMs의 일반적인 교차 엔트로피 손실이며, 는 시각적 손실의 계수이고, 모든 계수들은 해당 시각 작업의 손실에 대한 가중치 인자이다. 추론 과정 중에는 시각적 사고 토큰들을 디코딩하지 않는다.
또한, 이 프레임워크는 새로운 시각 토큰 유형의 유연한 통합을 지원한다. 파이프라인이 깔끔한 다음 토큰 예측 패러다임을 따르기 때문에, 추가적인 토큰들을 최소한의 수정만으로 통합할 수 있다.

Figure 4: Four-stage data formatting for COVT
Training Data. VLMs가 텍스트 공간에서의 능력을 잃지 않으면서 시각 토큰들을 점진적으로 학습할 수 있도록 하기 위해, COVT는 그림 4에 나타난 바와 같이 네 가지 데이터 포맷 단계를 도입한다. 이는 VLMs가 다음 순서를 통해 점진적으로 학습하도록 안내한다:
1) 이해 단계에서는 <image> 뒤에 시각 토큰들을 삽입하여 VLMs에게 시각 토큰들의 기본적인 의미론을 학습하도록 가르친다. 2) 생성 단계에서는 그림 4에 나타난 바와 같이 질문과 답변을 수정하여 VLMs가 시각 토큰들을 정확하게 생성하도록 안내한다. 3) 추론 단계는 시각 토큰들이 사고 과정 내에서 사용되는 시각적 사고의 연쇄 형식을 도입한다. 이는 모델이 시각 토큰들을 활용하여 최종 답변을 도출하도록 가르친다. 4) 효율적인 추론 단계에서는 시각 토큰 유형의 일부 세트(0에서 k 범위, k는 토큰 유형의 수)를 무작위로 제거(drop out)한다. 시각 토큰 유형의 일부만 사용함으로써, COVT는 고정된 출력 패턴에 의해 제한되는 대신 모든 특징을 효과적으로 활용하는 방법을 학습한다.
훈련에 사용된 데이터셋에는 다음이 포함된다: LLaVA-OneVision 데이터셋의 시각 중심(그리고 실세계) 부분집합, TallyQA 및 ADE20K-Depth를 포함한 공간 지각 데이터.
4. Experiments
실험 섹션에서는 먼저 4.1절에서 시각적 사고의 연쇄(Chain-of-Visual-Thought, COVT)의 실험 설정을 설명한다. 둘째, 4.2절에서 시각 중심 및 비시각 중심 데이터셋 모두에 대한 벤치마크 결과를 소개한다. 셋째, 4.3절에서 COVT의 이점을 입증하는 정량적 결과를 제시한다. 마지막으로, 4.4절에서 연속적인 시각 토큰을 "시각화"하고 4.5절에서 ablation studies를 수행한다.
4.1 Experiment Details
본 실험에서는 Qwen2.5-VL-7B가 주요 baselines로 선정된다. COVT는 LoRA 튜닝 방식을 사용하며, LoRA의 랭크는 16으로, LoRA 알파는 32로 설정된다. LoRA의 학습률은 로 설정되고, projection layer의 학습률은 로 설정된다.
훈련 단계는 다음과 같이 설정된다: 첫 번째 단계(First phase)는 4,000 스텝이다. 두 번째 단계(Second phase)와 세 번째 단계(Third phase)는 각각 3,000 스텝이다. 네 번째 단계(Fourth phase)는 5,000 스텝이다. 배치 크기(Batch size)는 4로 설정된다.
실험은 A100 한장 또는 A6000 4장에서 수행된다. 훈련 손실 공식 (4)에 있는 모든 와 계수들은 1로 설정된다.
4.2 Model Evaluation
모든 평가는 VLMEvalKit을 사용하여 수행한다.
시각 중심 벤치마크. 우리의 주요 초점은 CV-Bench에 맞춘다. 특히, CV-Bench 중에서 우리는 Count, Depth, 그리고 Distance 하위 작업을 강조한다. 이러한 하위 작업들은 우리 방법의 효과를 검증하는 정밀한 지표 역할을 한다. 우리는 추가적으로 BLINK, RealWorldQA (RW-QA), MMT-Bench (MMT), MMStar, MMVP, MME-RealWorld (MME-RW), V Bench* (V*), 그리고 HRBench (HR4K 및 HR8K)를 포함한 다른 시각 중심 벤치마크에서도 평가한다. 이 중에서 MMStar의 경우, 실세계 추론에 더 잘 부합하는 Coarse Perception, Fine-grained Perception, 그리고 Instance Reasoning 부분집합 (MMStar-P)을 특별히 선택한다.
비시각 중심 벤치마크. 이 외에도, 우리는 OCRBench, MME, MUIRBench, HallusionBench, A-OKVQA, TaskMeAnything, WeMATH, 그리고 WorldMedQA-V와 같은 일부 비시각 중심 시각 벤치마크에서도 COVT를 평가한다. MME의 경우, 텍스트 중심 성능 평가를 위해 텍스트 번역이라는 텍스트 중심 하위 작업을 선택한다.
4.3 Quantitative Results
COVT는 시각 중심 벤치마크 전반에서 baselines보다 뛰어난 성능을 보인다. 표 2에 나타난 바와 같이, COVT는 다양한 종류의 시각 토큰을 통합할 수 있다. 우리는 세분화(Segmentation), 깊이(Depth), 그리고 DINO 세 가지 시각 토큰을 주요 결과로 사용한다. 기준선과 비교했을 때, COVT는 주요 시각 중심 벤치마크 전반에서 일관되게 큰 폭의 성능 향상을 달성한다.
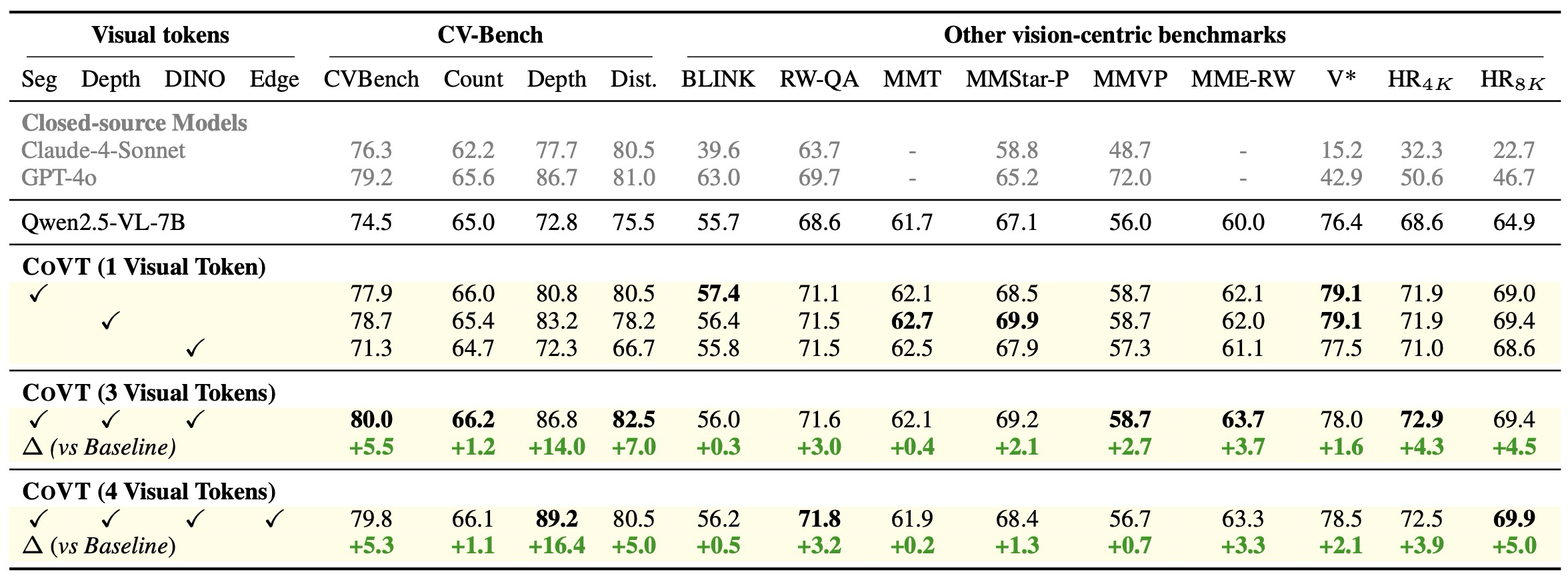
Table 2: Comparison of COVT with the baseline and closed-source models.
COVT는 CV-Bench에서 5.5%의 성능 향상을 보인다. CV-Bench의 하위 작업인 깊이에서는 14.0%의 향상을 이룬다. MME-RealWorld에서는 3.7% 향상된다. HRBench8K에서는 4.5% 향상된다. 이러한 결과들은 시각적 사고의 연쇄를 가진 COVT가 시각 중심 및 미세 조정된 지각 작업 전반에서 성능을 향상시킨다는 것을 나타낸다. 더욱이, 이 결과들은 각 시각 토큰 유형이 그들이 인코딩하는 풍부한 정보와 관련된 작업에 가장 효과적으로 기여한다는 것을 추가적으로 보여준다.
COVT는 다른 baselines에도 일반화된다. Qwen 기반 실험 외에도, COVT는 LLaVA-v1.5-13B를 기반으로도 구현되었으며, 이는 Aurora와 비교하기 위함이다. 표 3에 나타난 바와 같이:
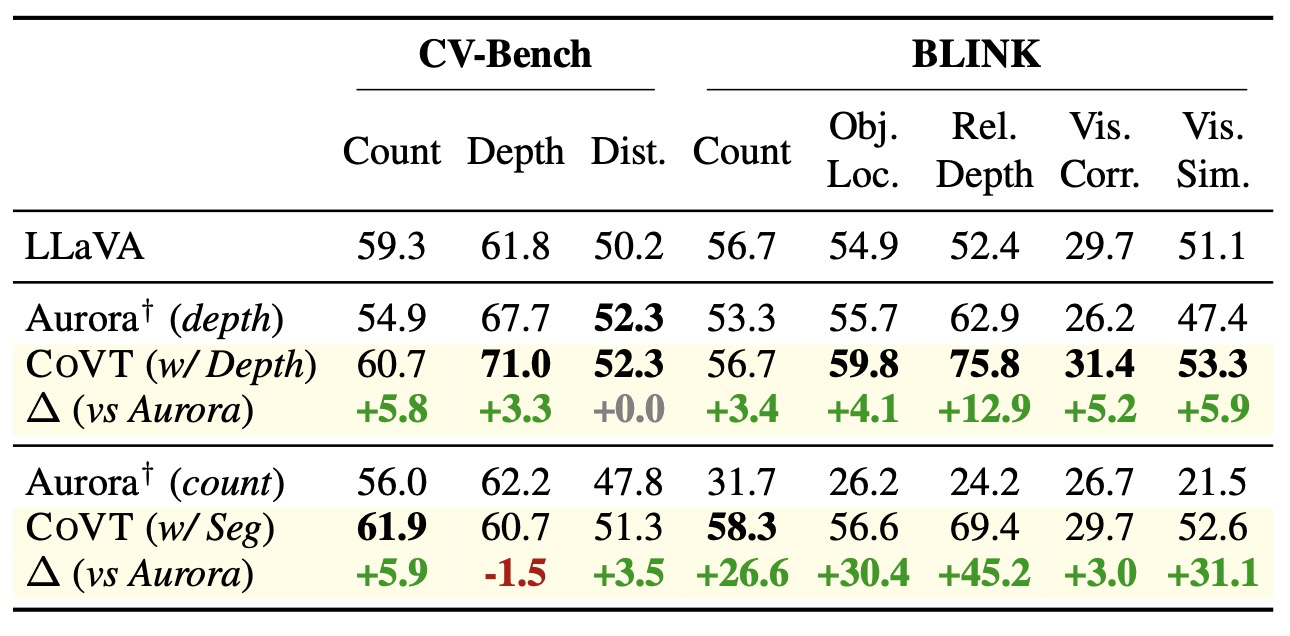
Table 3: Comparison between COVT and Aurora based on LLaVA-v1.5-13B
깊이 토큰을 사용하는 COVT는 BLINK의 상대 깊이(relative-depth)에서 Aurora-depth보다 12.9% 더 뛰어난 성능을 보인다. 분할(segmentation) COVT 토큰을 사용하는 COVT는 BLINK-count 벤치마크에서 Aurora-count보다 26.6% 뛰어난 성능을 보인다.
이 결과들은 COVT가 시각 중심 작업 전반에서 다양한 baselines에 대해 일반화된다는 것을 보여준다.
4.4 Qualitative Results
COVT가 효과적인 이유를 더 잘 이해하기 위해, 우리는 몇 가지 예시를 선택하고 모델 출력에서 COVT 토큰을 디코딩하여 이러한 토큰들이 추론에 유용한 정보를 제공하는지 시각화한다.

Figure 5: Visualization of COVT tokens
그림 5는 다양한 COVT 토큰들이 각기 다르고 풍부한 미세 조정된 정보를 담고 있으며, 그들이 제공하는 단서들이 매우 상호 보완적임을 보여준다. 해석 가능하도록 하기 위해, COVT 토큰들은 미세 조정된 출력물 (예: 마스크, 깊이 맵, 에지 맵)으로 디코딩된다.
왼쪽 예시의 경우, 분할(Segmentation) 토큰은 얼굴의 “점 B”를 지역화하여 2D 지각 단서를 제공하며, 반면 깊이(Depth) 토큰은 3D 정보를 제공하여 얼굴 영역이 주변 영역보다 카메라에 더 가깝다는 것을 나타낸다. 중간 예시의 경우, 깊이 토큰은 깊이 지각을 인코딩하고, 에지(Edge) 토큰은 두 대상 객체에 대한 미세 조정된 경계 단서를 제공한다. 이 예시는 CV-Bench의 깊이 하위 작업에서 가져온 것이며, 이러한 시너지 효과는 COVT가 CVBench-Depth 작업에서 네 가지 시각 토큰을 사용할 때 세 가지 토큰을 사용할 때보다 2.4% 더 높은 성능 향상을 보이는 이유를 설명한다(표 2 참조). 오른쪽 예시의 경우, 분할 토큰은 대상 영역을 지역화하고, 에지 토큰은 미세 조정된 경계를 강조하는데, 이는 분할 토큰에게는 어려운 작업이며, 이로 인해 시각적 사고의 연쇄를 통해 정확한 답을 도출하게 된다.
4.5 Ablation Studies
Text-only CoT vs. CoVT. 연속적인 시각 토큰의 기여를 분리하기 위해, 우리는 텍스트 전용 CoT를 우리의 전체 COVT 프레임워크와 비교하는 어블레이션 연구를 수행한다. 텍스트 전용 설정의 경우, 우리는 LLaVA-CoT 100k 데이터셋에서 사용된 CoT 형식화 패러다임을 따르며, 시각 토큰이 없다는 점을 제외하고 COVT와 완전히 일관되도록 자체 훈련 데이터에 동일한 형식화를 적용한다. 그림 6은 텍스트 전용 CoT가 시각 중심 추론 작업에서 성능을 향상시키지 못할 뿐만 아니라, 종종 성능을 저하시킨다는 것을 보여준다. 이와 대조적으로, COVT는 시각 중심 벤치마크 전반에서 일관되게 성능을 향상시키며, 이는 효과적인 시각적 추론을 위해 연속적인 시각 토큰이 필수적임을 강조한다.
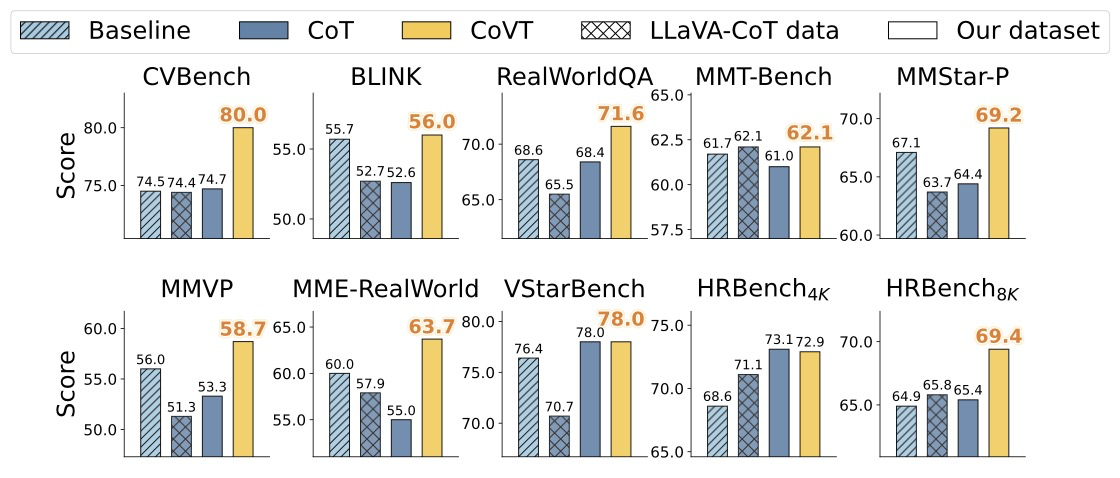
Figure 6: Text-only CoT vs CoVT
Token Numbers. 우리는 표 4에 제시된 바와 같이, 다양한 개수의 분할(segmentation) 시각 토큰에 대한 어블레이션을 수행한다. "0 토큰" 설정은 우리의 데이터셋에서 기본 모델을 직접 미세 조정(fine-tuning)하는 것에 해당한다. "16 빈 토큰(16 empty)" 설정은 우리의 16개의 시각적 사고 토큰을 어떤 시각적 정렬도 없는 16개의 일반 토큰으로 대체하며, 이는 순수한 잠재 추론 기준선 역할을 한다. 1개, 8개, 32개의 분할 토큰을 사용한 설정들은 토큰 개수를 다양하게 하면서 깊이(Depth) 및 DINO 토큰은 각각 4개로 고정한다. 8개 토큰 설정이 우리의 전체 모델에 해당한다.
우리는 너무 적은 분할 토큰을 사용하면 (여전히 "0 토큰" 기준선보다는 낫지만) 성능 저하로 이어진다는 것을 관찰한다. 그러나 토큰 개수를 32개로 늘리는 것 역시 성능에 해를 끼치는데, 이는 많은 수의 분할 토큰을 정렬하는 것의 어려움 때문일 수 있다. "16 빈 토큰" 변형의 저조한 성능은 시각적으로 정렬된 토큰의 중요성을 더욱 강조한다. 전반적으로, 이 결과들은 8개의 분할 토큰이 4개의 깊이 토큰과 4개의 DINO 토큰과 결합될 때 균형 잡히고 효과적인 구성을 형성하며, 시각적 정렬이 VLM에서 시각 중심 지각 능력을 향상시키는 데 필수적임을 입증한다.
Segmentation and Depth Alignment Strategies. 우리는 두 가지 정렬 접근 방식을 어블레이션한다. 우리의 주요 방법은 작업 디코더를 통해 COVT 토큰을 정렬하여, 토큰이 더 풍부하고 미세 조정된 지각 단서를 포착하도록 한다. 이와 대조적으로, 직접 특징 정렬(direct feature alignment)은 시각 토큰과 해당 시각 모델의 인코더 특징 사이에 MSE 손실을 적용하는데, 이는 이미지로부터 중요한 지각적 세부 정보를 필연적으로 손실시킨다. 표 5에 나타난 바와 같이, 직접 특징 정렬은 COVT보다 일관되게 낮은 성능을 보인다. 이러한 결과들은 우리의 맞춤형 정렬 전략의 중요성을 강조하며, 디코더와 시각 토큰을 정렬하는 것이 더 효과적이고 지각적으로 기반이 탄탄한 표현을 생성한다는 것을 보여준다.
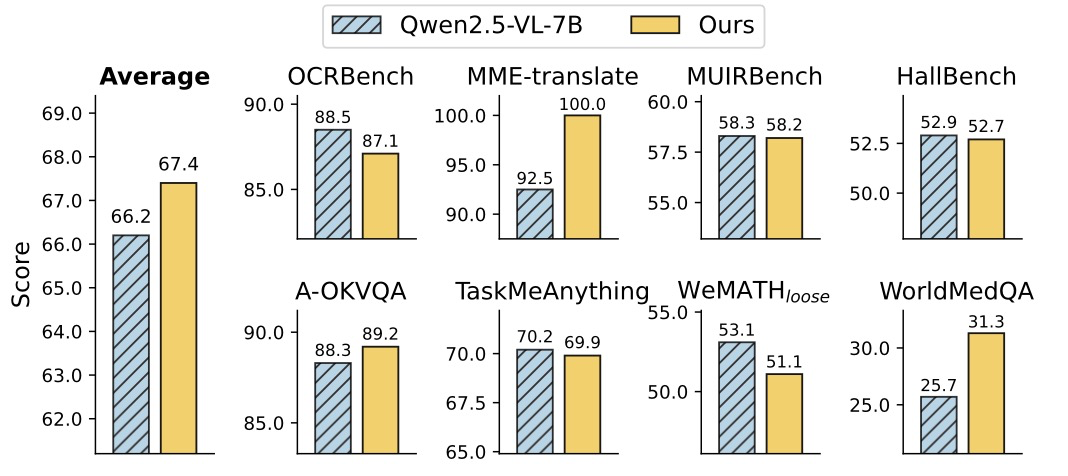
Figure 7: 비시각 중심 벤치마크에서의 성능
COVT는 다양한 비시각 중심 벤치마크 전반에서 경쟁력을 유지한다. 그림 7은 우리의 방법이 8개의 비시각 중심 벤치마크에서 1.2%의 향상을 보이며 비슷한 성능을 유지한다는 것을 보여준다. 이는 COVT가 일반화 능력에서 눈에 띄는 저하를 초래하지 않으며, 전반적으로 향상까지도 이끌어낸다는 것을 입증한다.
5. Conclusion
본 논문에서, 우리는 COVT(Chain-of-Visual-Thought), 즉 연속적인 시각적 사고의 연쇄를 도입한다. COVT는 압축된 조밀한 시각적 표현을 활용하여 시각-언어 모델(VLMs)이 이산적인 언어적 공간을 넘어서 추론할 수 있도록 한다. COVT는 다양한 지각 벤치마크 전반에서 시각 중심 추론 성능을 일관되게 향상시키며, 서로 다른 유형의 시각 토큰이 멀티모달 이해의 상호 보완적인 측면에 기여한다는 것을 밝힌다. 이러한 발견들은 COVT가 정교한 지각적 추론을 더 광범위한 멀티모달 시스템에 통합하기 위한 일반적인 프레임워크로서 기능할 수 있음을 시사한다.
