Author: Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, Pavlo Molchanov
Affilation: NVIDIA
Venue: arXiv
Comments: NVIDA Tech Report
Date: November 2025
Paper Link: https://arxiv.org/abs/2511.08923
⭐️ Key Takeaways
1. TiDAR는 확산(Diffusion) 방식의 병렬 초안 작성("Thinking")과 자기회귀(Autoregression) 방식의 고품질 샘플링("Talking")을 단일 모델 순방향 패스 내에서 결합하여 효율성과 품질의 균형을 이룬 하이브리드 아키텍처이다.
2. TiDAR는 GPU 연산 밀도를 극대화하고 정확한 KV 캐시를 지원함으로써, AR 모델 대비 4.71배에서 5.91배의 처리량 속도 향상을 달성하며 품질 격차를 해소한 최초의 아키텍처이다.
3. TiDAR는 투기적 디코딩(speculative decoding)을 효율성 측면에서 능가하는 동시에, 학습 시 구조화된 인과적-양방향 하이브리드 어텐션 마스크를 사용하여 확산 및 자기회귀 손실을 동시에 계산하는 간단하고 효과적인 학습 전략을 채택한다.
Abstract
확산 언어 모델(Diffusion language models)은 빠른 병렬 생성의 가능성을 지니지만, 자기회귀(Autoregressive, AR) 모델은 인과적 구조가 언어 모델링과 자연스럽게 일치하기 때문에 일반적으로 품질 면에서 탁월함을 보인다. 이는 높은 처리량, 더 높은 GPU 활용도, 그리고 AR 수준의 품질을 갖춘 시너지를 달성할 수 있는지에 대한 근본적인 질문을 제기한다. 기존 방법들은 이 두 가지 측면의 균형을 효과적으로 맞추는 데 실패한다. 이들은 순차적 드래프팅을 위해 더 약한 모델을 사용하는 AR을 우선시하여 speculative decoding의 드래프팅 효율성을 낮추거나, 확산 모델에 대해 일종의 좌->우(AR 유사) 디코딩 로직을 사용하여 여전히 품질 저하를 겪고 잠재적인 병렬성을 포기한다.
우리는 TiDAR를 소개한다. TiDAR는 확산(Diffusion) 방식으로 토큰을 초안 작성(Thinking)하고 자기회귀(AutoRegressively) 방식으로 최종 출력(Talking)을 샘플링하는 시퀀스 수준 하이브리드 아키텍처이다. 이 모든 과정은 특별히 설계된 구조화된 어텐션 마스크를 사용하여 단일 순방향 패스(single forward pass) 내에서 발생한다. 이 설계는 무료 GPU 연산 밀도(free GPU compute density)를 활용하여, 초안 작성 및 검증 능력 사이의 강력한 균형을 달성한다. 더욱이, TiDAR는 독립 실행형 모델로서 서빙 친화적으로(오버헤드가 낮게) 설계되었다. 우리는 1.5B 및 8B 규모에서 생성 작업 및 우도(likelihood) 작업을 포괄하여 AR 모델, 투기적 디코딩, 확산 변형 모델들을 상대로 TiDAR를 광범위하게 평가한다. 병렬 초안 작성 및 샘플링뿐만 아니라 정확한 KV 캐시 지원 덕분에, TiDAR는 측정된 처리량(throughput)에서 speculative decoding을 능가하며, Dream 및 Llada와 같은 확산 모델을 효율성과 품질 면에서 모두 뛰어넘는다. 가장 주목할 점은, TiDAR가 AR 모델과의 품질 격차를 해소하면서도 초당 4.71배에서 5.91배 더 많은 토큰을 제공하는 최초의 아키텍처라는 것이다.
1. Introduction
우리가 인공 일반 지능(Artificial General Intelligence, AGI)을 향해 나아가면서, 대규모 언어 모델(LLM)의 놀라운 성공은 폭발적으로 증가하는 GPU의 성능이 제공하는 대규모 컴퓨팅 확장을 활용하는 능력 덕분이라고 할 수 있다. 따라서 학습(training) 및 테스트(testing) 시간 모두에 컴퓨팅 리소스를 최대한 활용하는 방법이 점점 더 중요해진다. 자기회귀(AR) 모델이 주된 접근 방식이지만, 이들은 디코딩 중에 메모리 바운드(memory-bound) 상태를 유지하며, 특히 작은 배치 크기에서는 단계당 하나의 토큰만 생성하기 때문에 하드웨어 컴퓨팅 밀도를 완전히 활용할 수 없다. 이와 대조적으로, 확산 언어 모델(dLMs)은 병렬 토큰 디코딩의 가능성을 제공한다. 그러나 이들은 일반적으로 품질과 병렬화 가능성 사이의 상충 관계에 직면한다. 본 연구에서는 이러한 모델들의 단점을 파악하기 위한 원칙적인 분석을 제공하고, 두 패러다임의 강점을 결합한 간단하면서도 효과적인 하이브리드 아키텍처를 제안한다.
AR 모델에서의 디코딩은 지연 시간(latency)이 연산(compute)보다는 모델 가중치 및 KV 캐시를 로드하는 데 지배되기 때문에 메모리 바운드이다. 만약 단일 순방향 패스(single forward pass)에서 여러 토큰을 디코딩할 수 있다면, 해당 토큰들은 로드된 동일한 가중치와 KV 캐시를 공유할 수 있으며, 이는 연산 바운드 영역으로 전환되기 전까지 종단 간 지연 시간을 증가시키지 않으면서 컴퓨팅 밀도를 증가시킨다. 이것이 바로 dLM이 시스템 관점에서 잠재적인 속도 향상을 제공할 수 있는 이유이다. 구체적으로, prefix 와 모델 함수 가 주어졌을 때, AR 모델은 단일 토큰 슬롯(마지막 프롬프트 토큰)을 추가하고 다음 토큰 하나를 예측하며, 예: 이다. 반면에 masked 디퓨전 모델(예: 단순화된 1단계 디노이징 시나리오를 가진 Block Diffusion)에서는 레이블 시프트가 없기 때문에 여러 토큰을 한 번에 예측하며, 이다. 주어진 에 대해 두 계산 모두 여전히 메모리 바운드인 경우, AR 계산과 확산 계산의 순방향 시간은 유사해야 한다. 우리는 추가적인 토큰 슬롯들()을 무료 토큰 슬롯이라고 부르는데, 이는 단일 순방향 패스를 통해 이들을 전달하는 것이 지연 시간 증가를 최소화하거나 전혀 발생시키지 않기 때문이며, 이는 그림 1의 실제 프로파일링을 통해 검증된다.
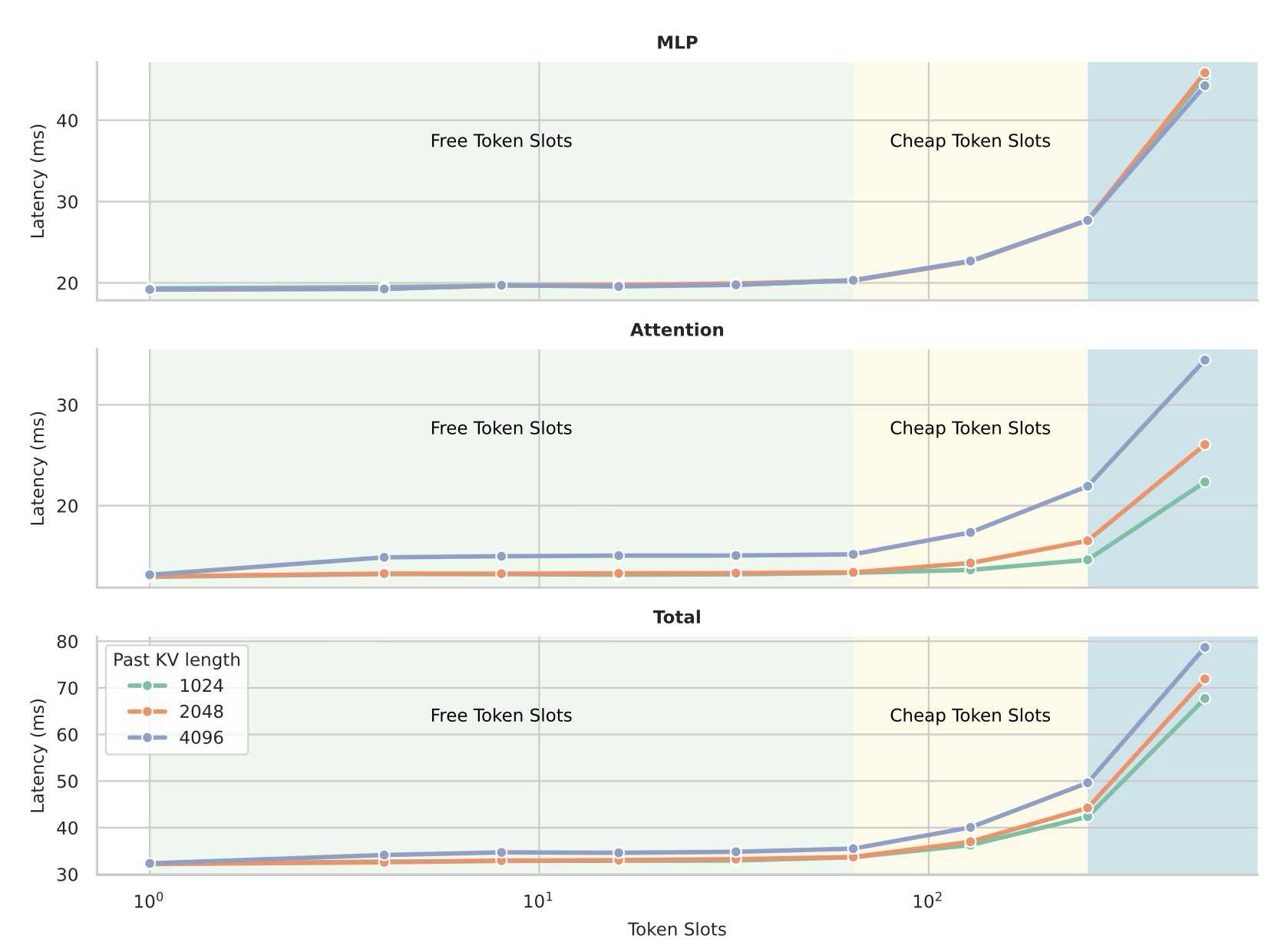
Figure 1: Latency Scaling over Token Slots
그러나 마스크드 확산 모델에는 병렬 디코딩과 출력 품질 사이에 잘 알려진 상충 관계가 존재한다. 최상의 품질은 종종 디노이징 단계당 정확히 하나의 토큰을 디코딩할 때 달성되는 반면, 단계 내 병렬성을 활용하려고 시도하면 품질이 저하되는 경향이 있다. 결과적으로, Dream 및 Llada와 같은 현재의 오픈 소스 SOTA 확산 LLM은 강력한 AR LLM의 속도-품질 결합 프로필에 아직 도달하지 못한다.
모델링 관점에서 이들의 차이점을 공식화하면, AR 모델은 연쇄적으로 인과 관계가 고려된 결합 분포(chain-factorized joint distribution) 에서 샘플링한다. 반면에 확산 모델은 분포에서 샘플링한다. 일반적으로 단계당 개의 토큰 {} 대신 하나의 토큰 를 디코딩하도록 선택할 때 품질이 가장 잘 유지되는데, 이는 이 경우 가 다음 디노이징 단계를 위한 조건으로 디코딩된 토큰을 가지기 때문이다. 한 단계에서 개의 토큰을 디코딩하면 가 주변 분포(marginals)의 곱 으로 추가 분해된다. 도입된 토큰 독립성 가정은 샘플링 중에 더 많은 병렬성을 제공함에도 불구하고 품질을 저하시킨다. 이상적으로, 우리는 로 계산하고 병렬 샘플링을 위해 그 독립성 가정을 활용하기를 희망하지만, 동시에 언어 모델링에 부합하는 인과적 분해 특성과 조건에서의 더 많은 컨텍스트 때문에 로부터 품질을 얻기를 원한다.
이러한 목적을 위해, 우리는 TiDAR를 제안하는데, 이는 확산을 통해 주변 분포로부터 병렬 토큰 계산(thinking)을 가능하게 하고, 자기회귀를 통해 연쇄적으로 인과 관계가 고려된 결합 분포로부터 고품질 샘플링(talking)을 가능하게 하는 새로운 아키텍처이다. 구체적으로, 각 생성 단계(단일 순방향 패스)에서 우리는 토큰을 세 섹션(접두사 토큰, 이전 단계에서 제안된 토큰, 그리고 다음 단계를 위해 미리 초안 작성된 토큰)으로 나눈다. 우리는 지난 단계의 접두사 토큰의 KV 캐시를 재사용한다. 지난 단계에서 제안된 토큰들은 현재 단계에서 계산된 에 의해 가이드되는 거부 샘플링(rejection sampling)을 통해 자기회귀적으로 샘플링된다. 동시에, 우리는 rejection sampling의 모든 가능한 접두사 결과에 조건화된 로부터 제안을 미리 초안 작성하며, 그들 중 하나의 미리 초안 작성된 제안이 선택되어 다음 단계로 전달된다. 이 모든 것은 단일 순방향 패스 내에서 간단하고 잘 설계된 어텐션 마스크를 사용하여 발생한다. 마지막 두 섹션에 있는 토큰들이 "무료 토큰 슬롯"에 잘 맞을 수 있는 한, 오버헤드는 거의 무시할 수 있는 수준이다. Figure 2는 상세한 아키텍처를 보여준다.
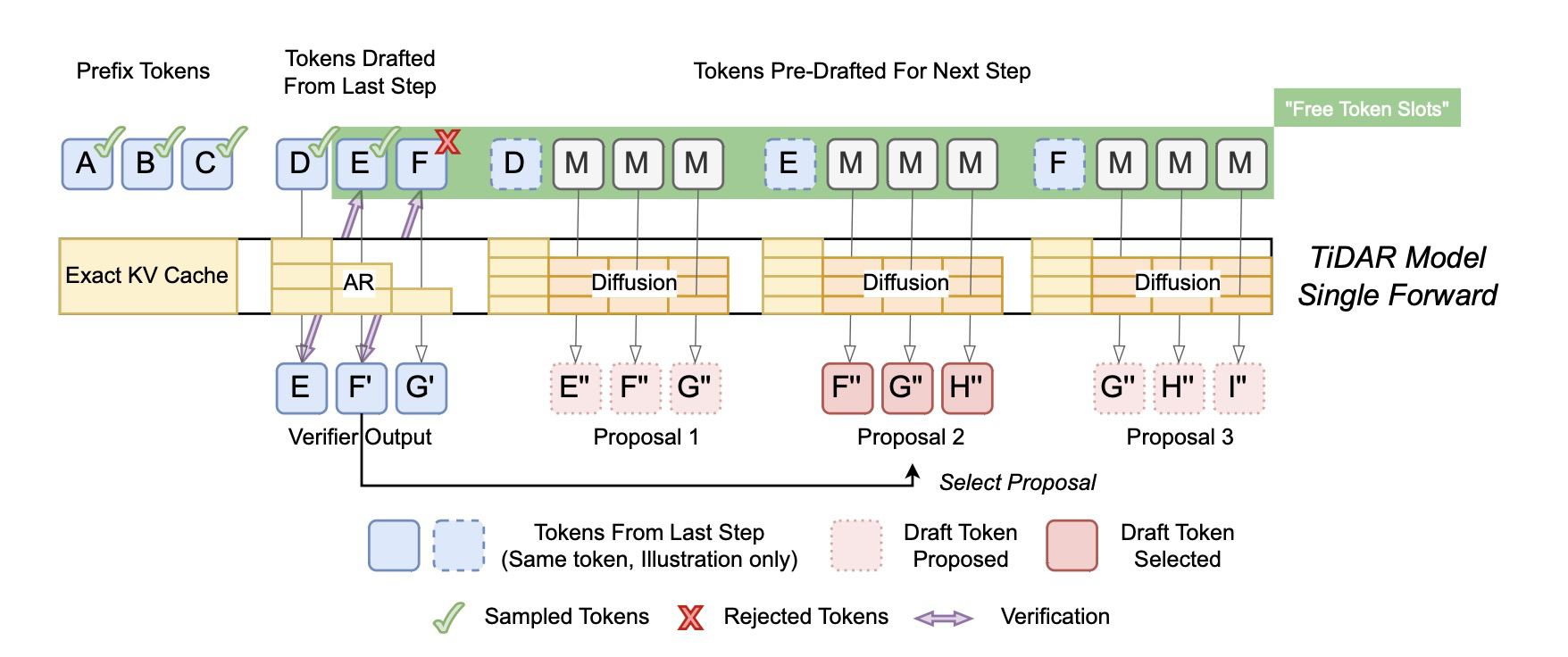
Figure 2: TiDAR Architecture
TiDAR의 학습은 간단하고 데이터 효율적인데, 이는 입력 시퀀스에 걸쳐 구조화된 인과적-양방향 하이브리드 어텐션 마스크를 사용하며, 단일 모델과 순방향 패스 내에서 과 로부터 학습하고 샘플링하는 것을 가능하게 한다. 결과적으로, 자기회귀 및 확산 손실 모두 동일한 데이터 샘플에서 계산될 수 있다. 학습 중에는 확산 섹션의 모든 토큰이 마스크 토큰으로 설정되는데, 이는 마스킹 전략을 단순화하고, 확산 손실 신호를 강화하며, 학습-테스트 일관성을 증진시키고, 자기회귀 및 확산 목적을 균형 있게 맞춘다.
우리의 기여는 다음과 같이 요약할 수 있다:
- 우리는 TiDAR라고 불리는 시퀀스 수준 하이브리드 아키텍처를 제안하는데, 이는 "무료 토큰 슬롯"을 활용하여 확산을 통한 병렬 토큰 초안 작성과 자기회귀를 통한 샘플링을 수행하며, 이로써 두 패러다임의 속도 및 품질 이점을 결합한다.
- 우리는 다른 아키텍처에 대한 TiDAR의 우수성을 입증하기 위해 학습 레시피뿐만 아니라 우도(likelihood) 및 생성 다운스트림 작업 모두에 대한 포괄적인 평가를 제공한다.
- 우리는 핵심 설계 선택 및 유연성의 효과를 입증하기 위해 상세한 절제 연구(ablation)를 수행하며, diffusion 및 speculative 디코딩의 관점에서 TiDAR를 분석하여, 우리 방법이 매력적인 이유에 대한 명확한 이해를 제공한다.
- TiDAR 1.5B의 경우, 우리는 AR 모델에 비해 품질 손실 없이 생성하면서도 토큰/초당 처리량에서 4.71배의 상대적 속도 향상을 달성할 수 있음을 보여준다. TiDAR 8B의 경우, 최소한의 손실로 5.91배의 인상적인 상대적 처리량 속도 향상을 달성한다.
2. Background and Related Work
TiDAR 모델은 Diffusion Language Models과 Speculative Decoding이라는 두 가지 연구 계열과 관련이 있으며 이들의 이점을 모두 활용한다. 이 섹션에서는 TiDAR를 이 두 범주와 연결하고, 다양한 관점에서 이해하는 방법과 이전 연구를 어떻게 개선하는지 강조한다.
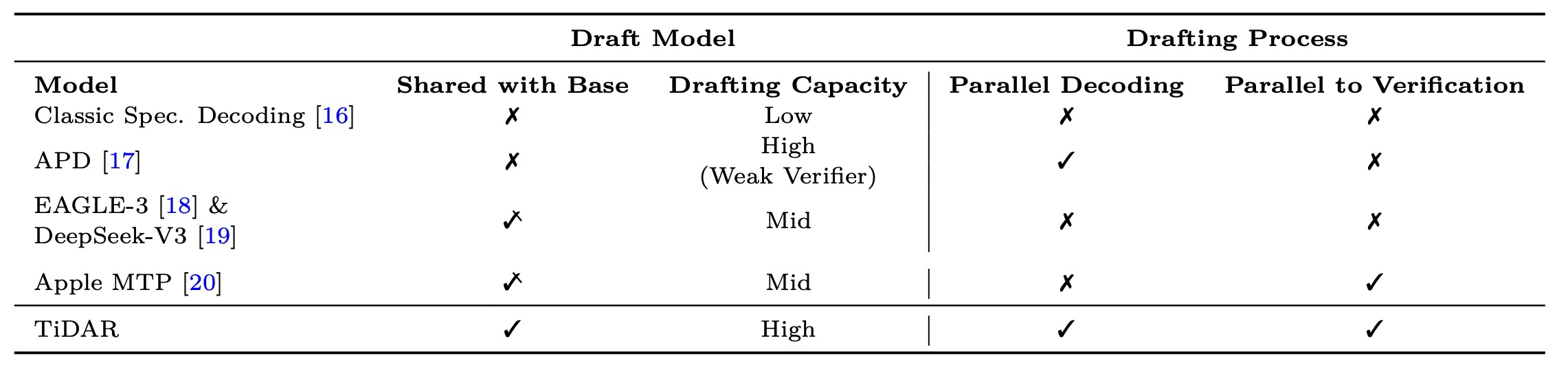
Table 1: Comparison among Speculative Frameworks
2.1 Diffusion Language Models
확산 언어 모델(dLMs)은 각 단계에서 여러 토큰의 병렬 생성을 허용함으로써 순전히 순차적인 자기회귀 모델 생성에 대한 유망한 대안을 제공하며, 생성 속도를 상당히 높일 수 있는 경로를 제공한다. 하지만 dLLM은 이론적으로 매력적임에도 불구하고 병렬화 가능성과 생성 품질 사이의 상충되는 문제에 직면한다. Llada 및 Dream과 같은 오픈 소스 dLLM이 예시로 보여주듯이, 최고의 생성 품질은 종종 한 번의 모델 기능 순방향 패스당 한 번에 하나의 토큰을 디코딩할 때 달성된다. APD에서 보고된 바와 같이, 단계당 병렬로 생성할 토큰 수가 증가함에 따라 생성 품질이 저하되는 뚜렷한 경향이 있다. 구체적으로, 엔트로피 기반 샘플링 전략을 사용하는 Dream-7B의 경우, 단계당 1개에서 2개 토큰으로 증가할 때 GSM8K 정확도가 10% 감소한다. 단계당 여러 토큰을 디코딩할 때, dLM은 일반적으로 주변 분포(marginal distribution)에서 각 토큰을 독립적으로 샘플링하며, 이는 단계 내 토큰 독립성 가정(intra-step token independence assumption)을 도입하여 시퀀스 수준의 일관성 및 정확도에 해를 끼칠 수 있다. 최근 연구들은 확산 모델과 AR 모델의 생성 품질 격차를 해소하고 처리량-품질 트레이드오프를 개선하려고 시도했다. E2D는 인코더-디코더 아키텍처를 채택하여 토큰 유형별 FLOPs 처리를 분리할 수 있게 한다. 여기서 큰 인코더가 깨끗한 토큰을 처리하고 경량 디코더가 노이즈가 있는 토큰을 디코딩하는 작업을 담당한다. EDLM은 잔여 에너지 기반 접근 방식(residual energy-based)을 도입하여 학습 및 샘플링 분포 간의 불일치를 줄여 생성 품질을 개선한다.
dLM을 확장하는 또 다른 과제는 양방향 어텐션(bidirectional attention)의 결과로 정확한 KV 캐싱 지원이 부족하다는 점이다. Fast-dLLM은 현재 블록의 노이즈 제거 과정에서 접두사와 선택적으로 접미사가 캐시되는 블록 병렬 디코딩(block parallel decoding)을 수행할 것을 제안한다. d-KV cache는 품질 전하를 최소화하기 위해 지연된 방식으로 단계별로 특정 토큰을 선택적으로 캐시하는 보다 동적인 경로를 택한다. Block Diffusion(반자기회귀 모델로도 알려짐)은 이산 확산과 자기회귀 모델 사이를 보간하여 이 문제를 해결하려고 시도한다. 구체적으로, 이 모델은 블록 전체에 걸친 자기회귀 확률 분포를 정의하며, 이전 블록이 주어졌을 때 블록 내 토큰의 조건부 확률은 노이즈 제거 이산 확산 모델에 의해 지정된다. 정확한 캐싱이 갖춰져 있음에도 불구하고, 블록 확산은 여전히 품질 저하 및 블록 내 토큰 병렬화 가능성이라는 동일한 딜레마를 겪는다.
2.2 Speculative Decoding
TiDAR는 또한 Speculative Decoding과도 밀접하게 관련되어 있다. 이 방법은 더 빠른 초안 모델을 먼저 사용하여 후보 토큰 시퀀스를 생성한 다음, 수정된 rejection sampling 전략을 사용하여 기본 모델의 목표 분포에 대해 이 토큰들을 검증함으로써 생성을 가속화한다. 드래프팅 속도를 높이기 위해 일반적으로 더 작은 초안 모델이 사용된다. 그러나 드래프팅 품질 저하가 너무 심하면, 낮은 수용률(acceptance rate)로 인해 전반적인 생성 속도가 느려질 수 있다. 드래프팅 속도와 품질을 모두 높이기 위해, 이전 연구들은 기본 모델에서 초안 작성기로 은닉 상태(hidden states)를 전달할 것을 제안한다. Medusa는 효율적인 트리 검증 패턴을 사용하여 가능한 경로를 확장하며, 기본 모델의 은닉 상태에 추가 다중 선형 디코딩 헤드를 추가하여 미래 토큰을 예측한다. EAGLE 시리즈와 DeepSeek-V3 Multi-Token Prediction (MTP)은 기본 모델의 은닉 상태에 추가적인 자기회귀 계층을 사용하여 미래 토큰을 예측한다. 하지만 이들 방법은 드래프팅 프로세스가 기본 모델을 완전히 활용하지 못하며, 더 낮은 초안 모델 용량(drafter capacity)으로 인해 최대 속도 향상이 저해된다. 또한, EAGLE 및 DeepSeek-V3의 MTP 모듈은 여전히 자기회귀적이고 기본 검증에 순차적이다. 이 두 요소는 이들이 계산 밀도(compute density)를 효과적으로 증가시키고 병렬 생성의 잠재력을 완전히 발휘할 수 없음을 보여준다.
TiDAR를 Speculative Decoding 관점에서 볼 때 (표 1에 비교가 요약됨), TiDAR의 주요 이점은 단일 모델만을 가지며 단일 순방향 패스 내에서 드래프팅과 샘플링을 동시에 완료할 수 있다는 점이다. 이는 세 가지 장점을 가진다: 1) 초안 모델 자체가 기본 모델이므로, 기본 모델의 가중치와 연산을 재사용하여 높은 용량을 가진다. 2) 드래프팅 프로세스가 확산 접근 방식을 따르므로, 완전히 병렬화될 수 있다. 이는 자기회귀 MTP 방식에서처럼 마지막 토큰에만 국한되는 대신, 모든 입력 마스크 토큰에 걸쳐 전체 계산 능력을 활용할 수 있음을 의미한다. 3) 드래프팅 및 검증 프로세스가 단일 순방향 패스 내에서 병렬화되어, 순차적인 드래프팅 및 검증의 오버헤드를 더욱 제거한다.
3. Method
이 섹션에서는 제안된 아키텍처인 TiDAR에 대해 설명한다. 우리는 단일 모델 순방향 내에서 결합 분포(i.e., AR 모드)와 주변 분포(i.e., 확산 모드)를 모두 모델링할 수 있도록 하는 백본(backbone) 학습부터 시작한다. 그 후, 우리는 병렬화된 자체 투기적 생성(self-speculative generation)을 위해 이중 모드를 어떻게 사용하는지 상세히 설명한다. 이 과정은 모델이 효율성을 위해 확산("thinking") 방식으로 초안을 작성하고, 품질을 위해 자기회귀("talking") 방식으로 샘플링할 수 있도록 한다. 마지막으로, 우리는 학습 및 추론 최적화에 대해 논의하며 마무리한다.
3.1 Diffusion-AR Dual-mode Backbone Training
우리의 목표는 확산(diffusion) 모드와 자기회귀(AR) 모드라는 이중 모드를 모두 지원하는 모델을 학습시키는 것이다. 더욱 중요한 것은, 여유 토큰 슬롯을 활용하기 위해 이 이중 모드가 단일 모델 순방향 패스(single model forward) 내에서 발생하도록 하는 것이다. 이를 달성하기 위해, 시퀀스 수준의 인과적(causal) 및 양방향(bidirectional) 어텐션 혼합(hybridization)이 가장 자연스러운 선택이 된다. 유사한 아이디어가 블록 확산 모델(Block Diffusion models)의 맥락에서 탐색되었지만, 이들의 주된 목표는 이중 모드 작동을 지원하는 것이 아니라, 특히 확산 구성 요소에 대해 KV 캐싱을 가능하게 하고 생성 품질을 개선하는 것이었다. 블록 확산의 결과적인 어텐션 마스크는 블록 내(intra-block)에서는 양방향이고 블록 간(inter-block)에는 인과적이다. 우리는 블록 확산에 수정을 가하여, 디코딩 블록인 마지막 블록만을 양방향으로 유지하고 나머지(즉, 접두사, prefix)는 인과적으로 유지한다. 이렇게 하는 이점은 두 가지이다. 첫째, 이를 통해 우리는 AR 모델에서와 같이 연쇄적으로 요인화된 결합 분포(chain-factorized joint distribution)를 계산할 수 있다. 이는 3.2절에서 보여주듯이, 높은 품질을 보장하면서 결합 분포를 사용하여 기각 샘플링(rejection sampling)을 수행하고, 효율성 측면에서 AR과 동일한 방식으로 우도(likelihood)를 평가할 수 있게 한다. 둘째, 모델 사전 학습 및 미세 조정(finetuning) 시 접두사(prefix)에 대한 다음 토큰 예측(Next Token Prediction, NTP) 손실 계산이 가능해진다. 블록 확산은 블록 내 양방향 어텐션의 레이블 누출(label leakage) 문제 때문에 접두사에 대해 이 손실을 계산할 수 없다. 또한, NTP 신호는 순수 확산 손실보다 훨씬 조밀한데, 이는 후자가 마스크 토큰에만 적용되기 때문이다. 우리 모델 학습에서는 이 두 가지 유형의 손실을 동시에 활용하여 학습 데이터를 더 잘 활용할 수 있다.
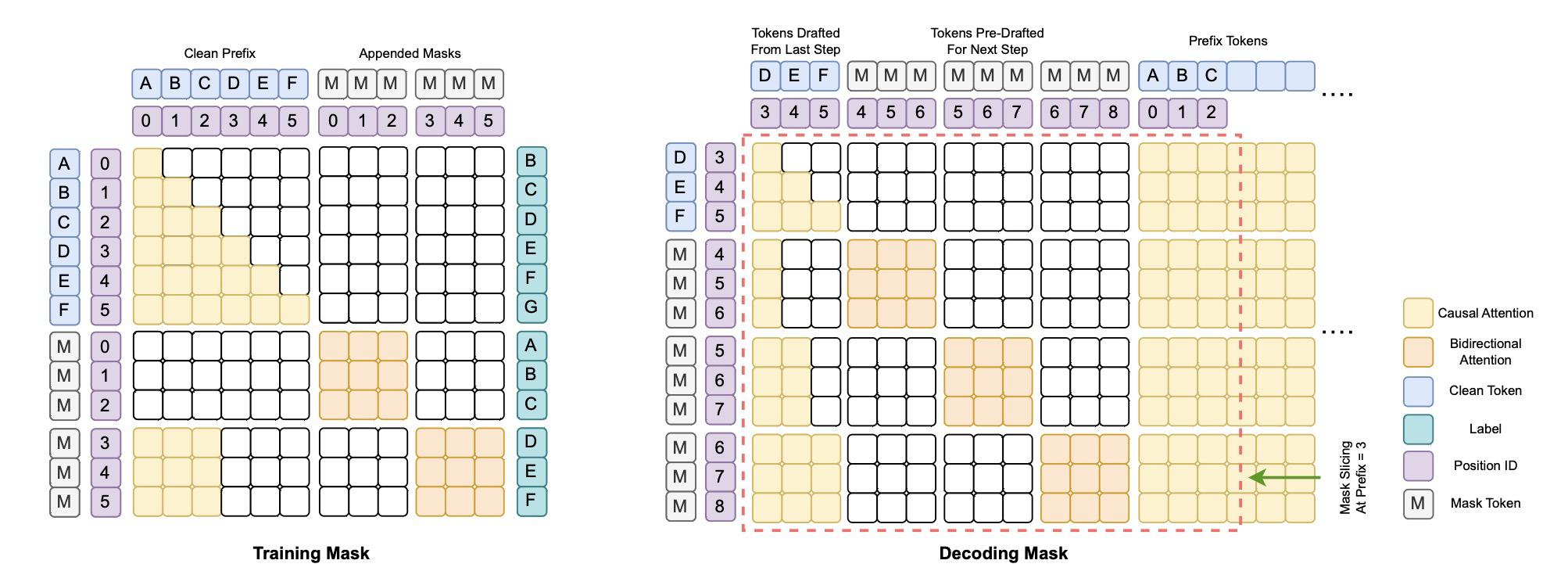
Figure 3: TiDAR Attention Masks
그림 3 (왼쪽)은 학습 중 어텐션 마스크를 시각화한 것이다. 블록 확산 및 SBD(Set Block Decoding)와 유사하게, 우리는 원래 입력 시퀀스에 변형된 토큰을 추가함으로써 시퀀스 길이를 두 배로 늘려야 한다. 인과적(자기회귀) 섹션의 경우, 대상 레이블은 NTP 목적에 맞게 한 위치만큼 이동되는 반면, 양방향(확산) 섹션의 경우 레이블은 입력 위치와 정렬된 상태를 유지한다. 확산 부분의 경우, 블록 확산 및 SBD는 기존의 확산 언어 모델링 접근 방식을 따라 특별한 분포에서 샘플링된 무작위 마스크를 적용하여 입력 시퀀스에 노이즈를 추가한다.
우리는 확산 섹션의 모든 토큰을 마스크 토큰으로 설정하는 더 간단하고 효과적인 학습 전략을 제안한다. 이는 최적의 마스킹 전략을 결정하는 번거로움을 제거한다. 그리고 더 중요하게는, 확산 부분의 모든 토큰에 대해 손실을 계산할 수 있게 되어 세 가지 주요 이점을 가져온다: (1) 이전처럼 변형된 토큰에만 적용되던 것과 비교하여 확산 손실이 훨씬 더 조밀해진다. (2) 확산 손실과 NTP 손실의 균형을 맞추는 것이 훨씬 간단해진다. 기존 확산 접근 방식에서는 손실 항의 수가 마스킹된 토큰 수에 따라 샘플마다 달라지는 반면, 다음 토큰 예측 손실은 항상 동일한 수의 토큰에 대해 계산되었다. 이 불일치 때문에 두 손실의 균형을 맞추기가 어려웠다. 모든 토큰을 마스킹함으로써, 두 가지 유형의 손실 모두에서 손실 항의 수가 일관성을 유지하며(시퀀스 길이와 동일), 사용자가 정의한 가중치 인수를 사용하여 간단하게 균형을 맞출 수 있게 된다. (3) 추론 중에 1단계 확산(one-step diffusion)을 수행할 수 있게 되어, 다단계 노이즈 제거보다 초안 작성 프로세스가 더 효율적이게 된다. 이에 대한 상세한 내용은 4.4.4절의 실험을 통해 다룬다.
따라서, TiDAR의 학습 목적은 다음과 같이 단순화된다:
여기서 는 손실 균형 인자이며, 는 길이 의 입력 시퀀스이다. 와 는 교차 엔트로피 손실로, 서로 다른 어텐션 패턴을 사용하여 깨끗한 시퀀스(clean sequences)와 마스킹된 시퀀스(masked sequences)에서 계산된 로짓을 기반으로 한다.
3.2 Fully Parallelizable Self-Speculative Generation
모델의 생성 효율성을 추론하려면 총 순방향 단계의 수, 단계당 디코딩(또는 샘플링)되는 토큰의 수, 그리고 단계당 지연 시간과 같은 여러 측면을 고려해야 한다. 확산 언어 모델, 다중 토큰 예측(MTP), 투기적 디코딩 범주에 속하는 많은 기존 기술들은 이 중 일부를 최적화하려고 시도한다. 그러나 그 결과는 종종 지연 시간, 품질 및 연산 밀도 사이의 상충 관계(trade-off)로 나타난다. 본 연구에서 우리는 확산의 병렬성과 자기회귀(AR)의 품질을 단일 모델에 통합함으로써 이 전역 최적화 문제에 대한 해답을 제시하고자 한다.
우리는 병렬 드래프팅(drafting) 및 샘플링 절차를 제안한다. 이 방법은 모델이 먼저 주변 분포(marginal distribution)에서 병렬적으로 투기적 토큰들을 초안 작성한 다음, 자기회귀(autoregressive) 방식으로 거부 샘플링(rejectively sampled)을 통해 이 토큰들을 검증하여 생성 품질을 확보하는 투기적 프레임워크를 중심으로 한다. 생성 시작 시, 모델은 프롬프트를 인과적(causally)으로 인코딩하고 양방향 어텐션을 사용하여 토큰 블록을 병렬로 초안 작성한다 (마스크는 부록 그림 7에 설명되어 있다). 이후의 각 디코딩 단계에서, 이전 단계에서 초안 작성된 토큰들은 현재 단계에서 인과적 어텐션을 사용하여 계산된 자기회귀 결합 분포()의 예측과 일치하는지 확인하는 방식으로 거부 샘플링된다. 동시에, Apple의 MTP 연구에서 영감을 받아, 우리는 거부 샘플링의 가능한 모든 결과를 조건으로 하여 주변 분포로부터 다음 단계의 토큰들을 병렬로 사전 초안 작성(pre-draft)한다. 이를 통해 현재 단계에서 수용하는 토큰 수에 관계없이 다음 단계에 해당하는 드래프트를 얻을 수 있다. 그림 2는 이러한 생성 과정을 자세히 보여준다.
효율성을 더욱 개선하기 위해, 우리는 단일 단계 확산 드래프팅(one-step diffusion drafting)을 채택한다. 우리는 단일 단계만으로도 높은 수용률을 확보하기에 충분히 좋은 품질의 초안 토큰을 생성할 수 있음을 발견했다. 이에 따라, 3.1절에서 논의된 바와 같이 학습 중에는 확산 섹션의 모든 토큰을 마스크 토큰으로 설정한다.
3.3 Training and Inference Optimization
3.1절에서 논의했듯이, 우리의 변형된 시퀀스는 완전히 마스킹되어 있으며, 이는 자기회귀(AR) 및 확산(diffusion) 로짓에서 계산된 손실 스케일의 분산이 동일하기 때문에 손실 균형을 맞추는 것을 더 쉽게 만든다. 우리는 대부분의 경우 로 설정하고, 4.4.3절에서 다른 값들의 차이점을 상세히 다룬다.
추론 중에는 매 순방향 패스마다 모델에 보내는 토큰의 수가 동일하고 동일한 어텐션 패턴을 가진다는 사실을 활용한다. 우리는 드래프트 부분과 접두사(prefix)를 재정렬하여, 크기가 ()인 하나의 블록 어텐션 마스크를 초기화하고, Flex Attention을 위해 각 단계에서 이 캐시된 마스크를 재계산 없이 슬라이스하여 사용할 수 있게 한다 (그림 3 오른쪽). 기존 확산 모델과 달리, TiDAR는 블록 확산(Block Diffusion)처럼 정확한 KV 캐시를 지원한다. 그림 2에서, 우리는 생성 과정을 보여준다. 이 과정에서 인과적 어텐션으로 계산된 모든 토큰의 KV 캐시를 먼저 저장하고, 샘플링 길이가 드래프트 길이보다 짧을 경우에 나중에 해당 KV 캐시를 축출(evict)한다. 어떠한 토큰의 KV 캐시도 재계산하여 낭비하지 않는다는 점은 주목할 만하며, 이는 블록 확산(Block Diffusion), SBD, 그리고 순수 확산 모델에서 사용되는 캐시 방법(예: Fast-dLLMs 및 d-KV Cache)에 비해 우리 방법을 극도로 효율적으로 만든다.
기존 확산 모델과 달리, TiDAR는 추론 중에 튜닝할 하이퍼파라미터가 없다. 그럼에도 불구하고, 4.4.2절과 4.4.3절에서 자세히 설명하듯이, 다양한 시나리오에 맞출 수 있는 유연성을 제공한다.
4. Experiments
4.1 Setup
Model initialization and tasks. 본 논문에서 우리는 자기회귀(AR) 모델(Qwen2.5 1.5B, Qwen3 4B, Qwen3 8B)로부터의 지속적인 사전 학습(continual pretraining) 설정에 중점을 둔다. 우리는 생성 태스크 및 우도(likelihood) 태스크에 대한 품질 평가를 포함하며, 이는 코딩(HumanEval, HumanEval+, MBPP, MBPP+), 수학(GSM8K, Minerva Math), 사실 지식(MMLU), 그리고 상식 추론(ARC, Hellaswag, PIQA, Winogrande)을 포함한다. 모든 평가는 lm_eval_harness를 사용하여 수행된다. 상세한 태스크 구성은 부록 A에서 확인할 수 있다. 효율성 측면에서는, 단일 모델 순방향 패스(NFE, Network Function Evaluation)가 생성할 수 있는 평균 토큰 수와 배치 크기 1에서 측정한 벽시계 초당 토큰 수(token per wall-clock second)로 본 벽시계 속도 향상을 보고한다.
Baseline. 우리는 Llama3.2, SmolLM2, Qwen2.5, Qwen3와 같이 유사한 모델 크기를 가진 오픈 소스 AR 모델들을 포함한다. 확산 모델의 경우, Dream 및 Llada와 비교하며, 또한 동일한 학습 레시피로 학습시킨 자체 Block Diffusion과도 비교한다. 모든 Qwen2.5 및 Qwen3 모델의 결과는 명시적으로 지정되지 않은 한 기본 모델(base model)을 나타낸다.
Training and inference. TiDAR 1.5B 모델의 경우, 우리는 4, 8, 16의 블록 크기(block sizes) 하에서 50B 토큰으로 지속적으로 사전 학습을 수행했으며, 전역 배치 크기(global batch size)는 2M 토큰(DDP)이었다. 8B 모델의 경우, 150B 토큰을 사용했고 블록 크기는 16으로 유지했으며, 나머지 설정은 동일하게 유지했다. 코사인 스케줄링(cosine scheduling)을 채택했으며, max_lr=1*e*−5, min_lr=3*e*−6이고 웜업 단계 비율은 1%로 설정했다. 최대 시퀀스 길이는 4096으로 설정되었으며, Distributed Adam 옵티마이저를 사용했고, 8B 모델에 대해서는 Gradient Checkpointing을 활성화했다. 전체 학습 프레임워크는 Torchtitan를 지원하는 수정된 Megatron-LM이다. 학습 및 추론 모두 표준 BFloat 16 정밀도로 수행된다. 주요 결과 측면에서, 우리는 TiDAR 1.5B 및 TiDAR 8B의 성능을 보고하며, 절제 연구(ablation studies)를 위해서는 1.5B 모델 사용에 중점을 둔다.
4.2 Main Results
4.2.1 Generative Task Evaluation
이 섹션에서는 TiDAR가 고품질 샘플을 효율적으로 생성하는 능력을 조사하는 것부터 시작한다. 우리는 코딩 및 수학 태스크에 중점을 두는데, 이는 이들의 지표가 훨씬 더 견고하기 때문이다. 표 2에서, 우리는 먼저 TiDAR를 두 가지 모델 크기에 걸쳐 여러 자기회귀(AR) 모델 및 인기 있는 확산 변형 모델인 블록 확산(Block Diffusion)과 비교한다.
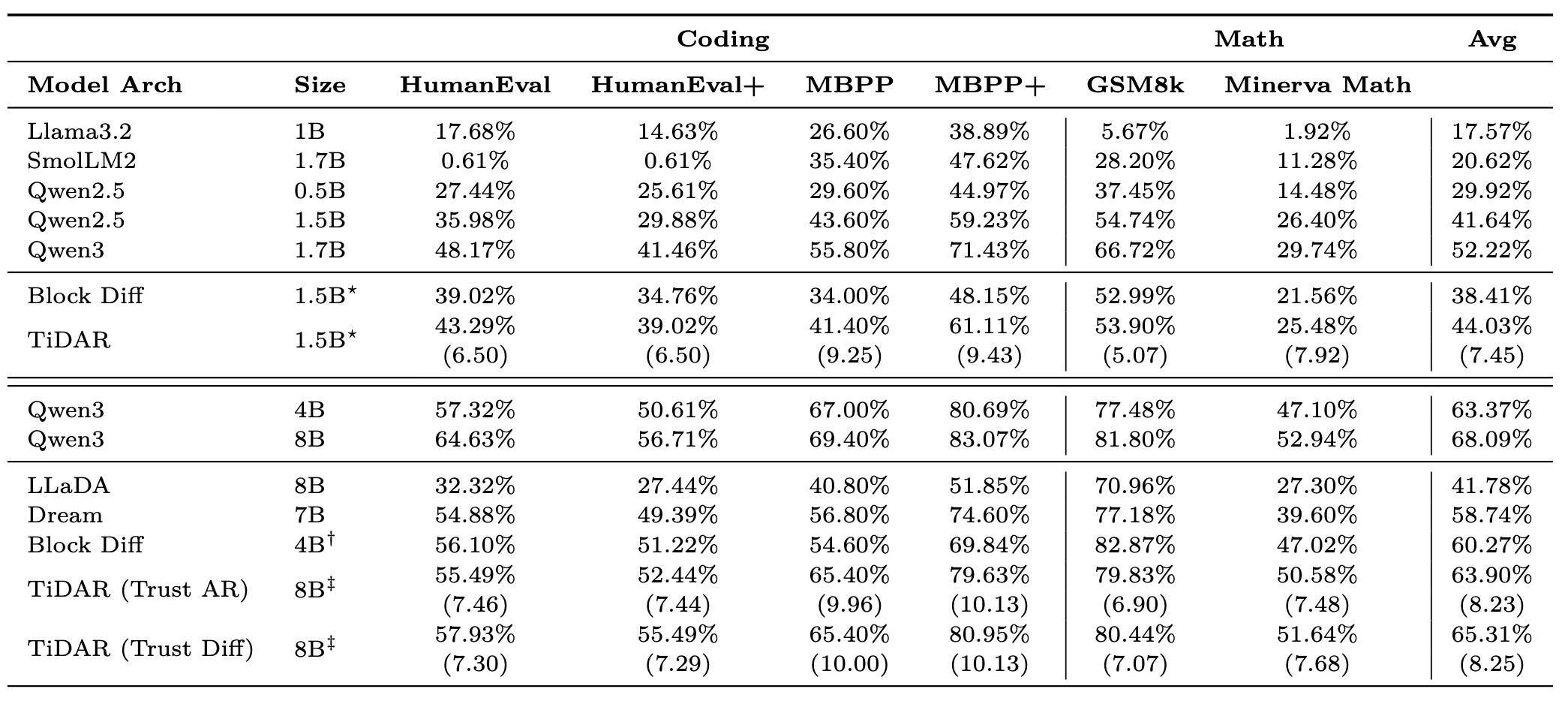
Table 2: Generative Evaluation Results
1.5B–1.7B 크기 범위의 경우, TiDAR는 모델 순방향 패스당 평균 7.45개의 토큰(NFE)을 생성하면서도 품질 면에서 매우 경쟁력이 있다. 8B 모델의 경우, TiDAR는 생성 효율성을 NFE당 8.25개 토큰으로 증가시키면서도 간단한 학습 레시피로 최소한의 손실만을 발생시킨다. 우리는 또한 "AR 신뢰(trusting AR)" 대 "확산 신뢰(trusting diffusion)"라는 두 가지 다른 생성 모드를 테스트했으며, 이는 더 큰 모델의 경우 확산 예측을 신뢰하는 것이 대부분의 경우, 특히 수학 태스크에서 유익함을 보여준다. 이러한 선택 차이는 4.4.3절에서 더 자세히 논의한다.
확산 대규모 언어 모델(LLM)과 비교했을 때, TiDAR는 Dream 및 Llada와 같은 공개 모델과, 동일한 학습 레시피로 학습된 자체 블록 확산 모델보다 일관되게 뛰어난 성능을 보인다. 여기서 우리는 NFE당 하나의 토큰을 디코딩하는데, 이는 대부분의 태스크에서 최고의 달성 가능한 품질을 보장하기 때문이다. 다양한 디코딩 전략에 대한 논의와 비교는 4.4.2절로 미룬다.
요약하자면, 는 위에서 언급된 여러 설계 덕분에 생성 품질과 효율성 사이의 훌륭한 균형을 맞추고 있으며, 엄격한 지연 시간 요구 사항이 있는 많은 중요 애플리케이션 시나리오에서 매우 매력적인 선택이 된다.
4.2.2 Likelihood Task Evaluation
전통적인 확산 LLM(예: LLaDA, Dream, MDLM)에 대한 우도를 기반으로 모델 성능을 평가하는 것은 우도를 계산하는 다양한 방식 때문에 매우 어려웠다. 예를 들어, 응답 토큰은 학습과 동일한 방식으로 손상(corrupted)되며, 우도는 몬테카를로 샘플 예산으로 평균화된 마스킹된 위치에서만 계산된다. 효율성은 떨어지더라도 객관식 질문에 대한 우도 사용에 대해서는 합의가 이루어졌지만, 이 지표를 사용하여 모델을 직접 비교하는 것은 여전히 논쟁의 여지가 있다. 반면에 TiDAR는 AR 모드가 자기회귀 모델과 동일한 방식으로 우도 계산을 자연스럽게 지원한다는 사실 덕분에 이 문제를 완화한다. 표 3에서 우리는 다음을 보여준다:
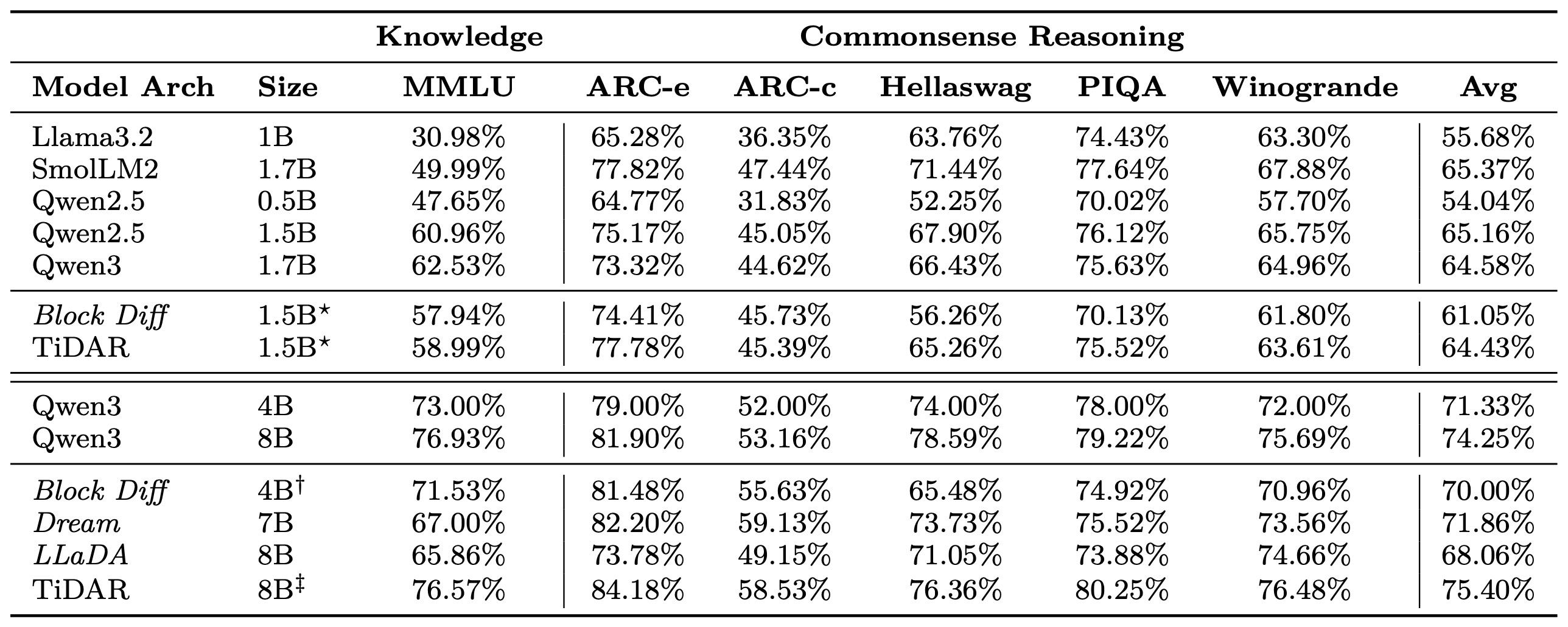
Table 3: Likelihood Evaluation Results
(1) 이 접근 방식이 다른 AR LLM과 매우 잘 일치하여 비교 가능성이 높다는 점. (2) 그 성능이 경쟁력 있고 (자기회귀 샘플링 덕분에) 생성 품질에 충실하다는 점. (3) 단일 NFE로 평가가 극도로 효율적이라는 점.
4.3 Efficiency Benchmarking
마지막으로, 우리는 TiDAR의 벽시계 시간(wall-clock time) 벤치마킹에 중점을 두어 주요 결과를 마무리한다. 비교 대상으로는 자기회귀(AR) 모델, 투기적 디코딩을 위한 EAGLE-3, 그리고 블록 확산(Block Diffusion)을 선정한다. 우리는 이 모델들이 표준 자기회귀 디코딩, 투기적 디코딩, 확산 생성 전반에서 가장 경쟁력 있는 선택지에 속한다고 판단한다. 모든 모델은 정확한 캐시(exact cache)를 지원하며, 단일 H100 GPU에서 다운스트림 생성 태스크의 프롬프트를 사용하여 배치 크기 1로 벤치마킹되었다.
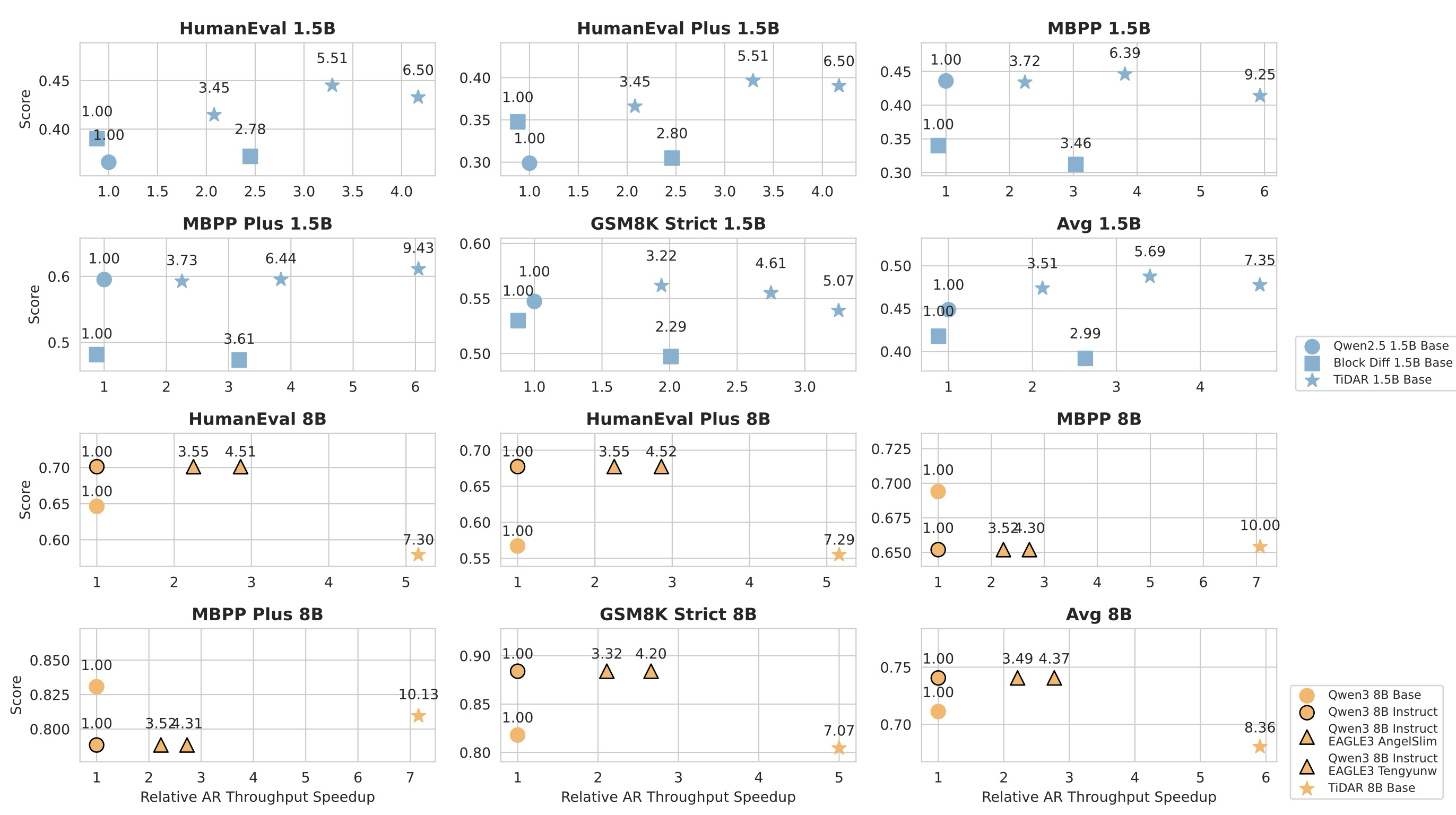
Figure 4: Efficiency-Quality Benchmarking
그림 4에서, 우리는 TiDAR 1.5B가 Qwen2.5 1.5B 대비 디코딩 처리량 측면에서 평균 4.71배의 상대적 속도 향상을 달성하고, TiDAR 8B가 Qwen3 8B 대비 평균 5.91배의 속도 향상을 달성하는 동시에 비교 가능한 성능을 유지함을 보여준다. 블록 확산(Block Diffusion)과 비교했을 때 (두 가지 다른 임계값 설정을 사용), 우리는 테스트한 모든 태스크에서 더 나은 효율성-품질 트레이드오프를 달성할 수 있다. 최신 투기적 디코딩 방법인 EAGLE-3과 비교하기 위해, 우리는 TiDAR를 AngelSlim 및 Tengyunw의 공개 가중치와 테스트했다. 그 결과, 확산 모델이 투기적 디코딩 대비 효율성 이득을 능가할 수 있음을 최초로 보여준다. 그러나 투기적 디코딩은 기본 모델과 정확히 동일한 출력을 보장할 수 있으므로, 투기적 디코딩과 TiDAR는 서로 다른 목적으로 활용되어야 함을 강조한다. 추가적으로, 우리의 순수 수용률(raw acceptance rate, T/NFE)이 EAGLE-3의 공개 가중치보다 높으며, 더 중요한 것은 단일 모델 순방향 패스 내 병렬 드래프팅 및 샘플링 덕분에 변환율(T/NFE에서 T/s로)이 더 높다는 점을 보여준다.
이 모든 방법들이 사용자 정의 커널, 더 효율적인 KV 캐시 관리, 요청 스케줄링과 같은 추가적인 시스템 최적화로부터 상당한 이점을 얻을 수 있다는 점에 주목할 필요가 있다. 따라서 여기서의 목표는 네이티브 PyTorch 환경에서 이들의 성능에 대한 직접적인 아이디어를 제공하는 것이다.
4.4 Ablation Studies
이 섹션의 목적은 성능 향상이 어디에서 비롯되었는지 더 깊이 이해하고, 우리 아키텍처, 학습, 추론의 설계 선택을 정당화하는 것이다.
4.4.1 Pareto Frontier under the Same Training Recipe
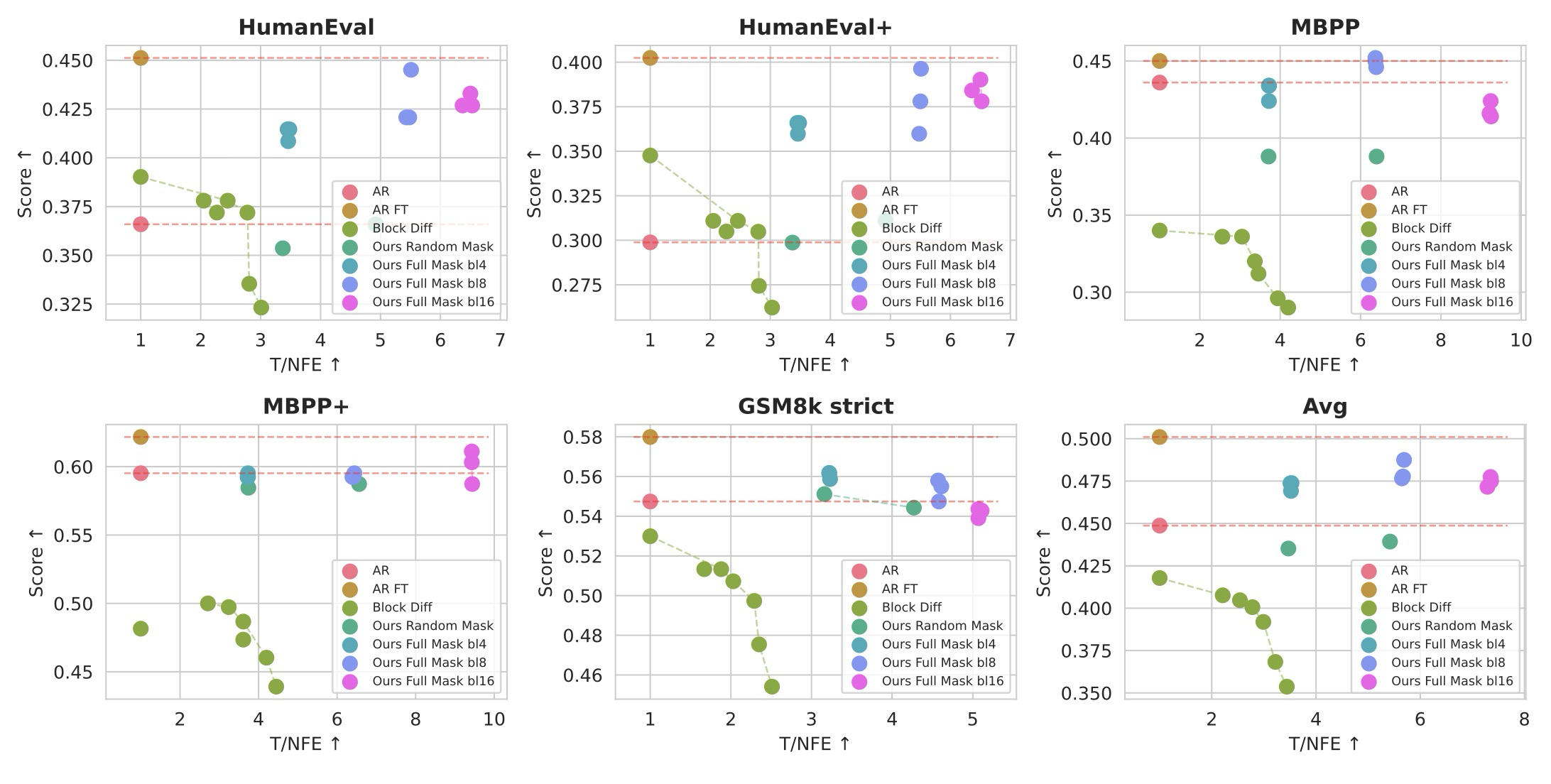
Figure 5: Pareto Frontier of Different Architectures with the Same Recipe
품질과 학습 레시피는 대규모 언어 모델(LLM)의 성능에 극적인 영향을 미칠 수 있다. 따라서 다양한 모델 아키텍처를 공정하게 비교하기 위해, 우리는 Qwen2.5 1.5B 모델에서 시작하여 모든 모델을 동일한 설정으로 학습시킨다. 그림 5에서, 학습된 이 모델들의 파레토 프론티어(Pareto Frontier)는 TiDAR가 기본 자기회귀(AR) 모델, 미세 조정된 AR 모델, 그리고 다양한 디코딩 임계값을 가진 블록 확산(Block Diffusion)과 비교하여 어떻게 수행되는지에 대한 통찰력을 제공한다. 우리는 단 50B의 학습 토큰만으로도, TiDAR가 블록 확산과 비교하여 높은 NFE당 토큰 수(T/NFE)를 유지하면서도 인상적인 품질을 달성할 수 있음을 확인한다. 우리는 또한 미세 조정된 AR 모델과의 품질 격차가 여전히 남아 있음을 확인하며, 이는 TiDAR가 초기 적응 단계로 인해 더 많은 지식을 필요로 할 수 있다는 사실 때문에 더 많은 데이터로 잠재적으로 해소될 수 있다고 믿는다. TiDAR는 NFE당 7배 더 많은 토큰을 생성하면서 미세 조정된 AR의 품질에 근접하고 있다.
4.4.2 Comparing TiDAR with Other Decoding Strategy
확산 언어 모델(dLMs)에서 사용되는 일반적인 전략에는 NFE당 고정된 수의 토큰을 생성하는 방식, 엔트로피 또는 신뢰도 기반 디코딩에 기반한 동적 NFE 수, 그리고 블록 내 좌-우 디코딩(within-block left-to-right decoding)이 포함된다. 많은 이전 연구들이 이러한 이점을 연구했으며, 여기서 우리는 표 4를 통해 우리 방법과 포괄적인 비교를 제공한다.
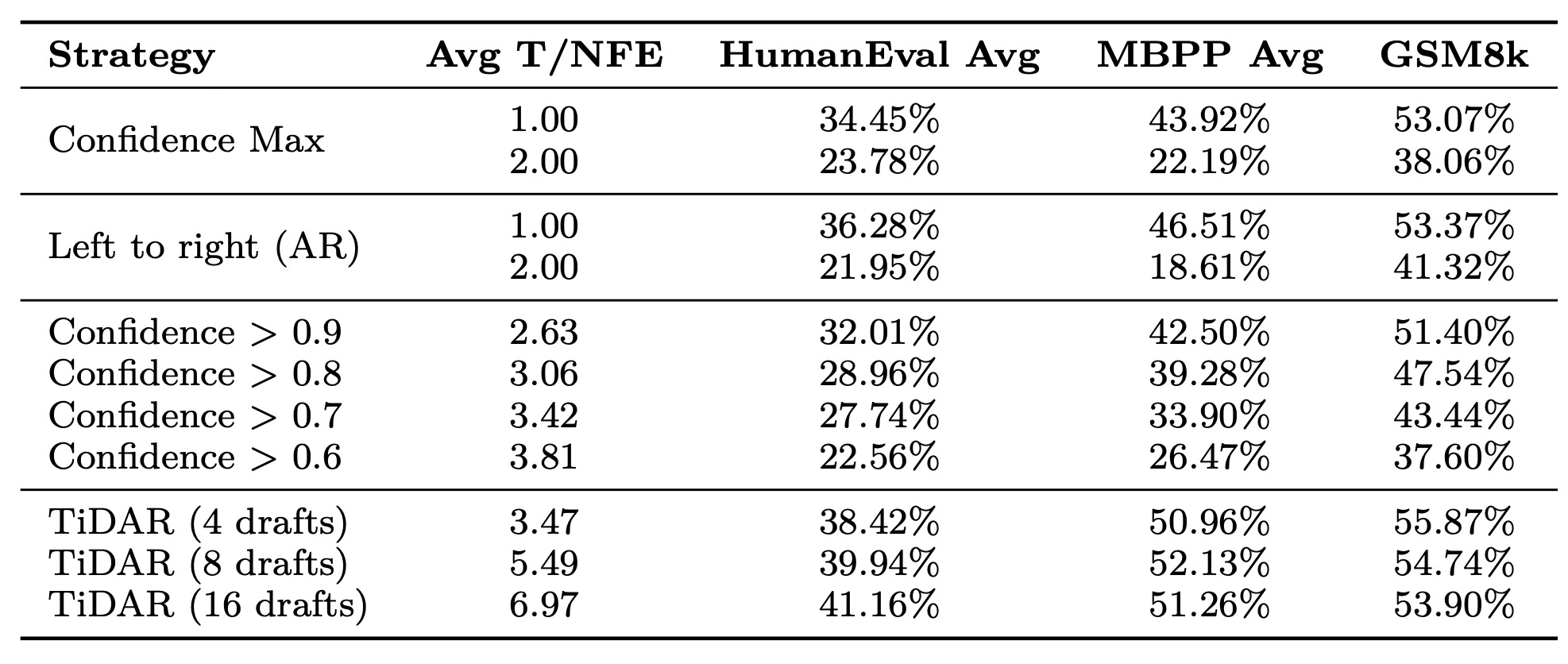
Table 4: Comparing Different Decoding Strategies
우리는 우리 방법이 확산으로부터 오는 효율적인 병렬성과 자기회귀로부터 오는 고품질을 모두 활용하며, 디코딩 중에 하이퍼파라미터를 튜닝할 필요가 없다는 추가적인 이점을 제공함을 입증한다.
4.4.3 Sampling with AR v.s. Diffusion Prediction
그림 2에 나타난 바와 같이, 확산 부분에 레이블 이동(label shifts)을 사용하지 않는 것은 동일 단계에서 자기회귀(AR) 결과를 기다리지 않고도 사전 초안 작성(pre-draft)을 가능하게 하며 시퀀스 일관성을 유지한다. 하지만 이로 인해 AR 출력과 블록 내 모든 첫 번째 위치가 동일한 위치를 예측하게 된다 (예: 를 로, 를 로 등). 이는 검증에 사용할 로짓을 선택하는 잠재적인 결정 문제를 야기한다.
따라서 우리는 토큰을 샘플링하기 전에 로짓을 혼합하기 위해 집계 함수를 적용할 것을 제안하며, 이는 로 표현되고, 이후 제안된 초안 토큰과 비교된다. 이는 샘플링 시 우리가 AR 출력 또는 확산 출력 중 무엇을 더 "신뢰"하는지에 대한 문제로도 이해할 수 있다.
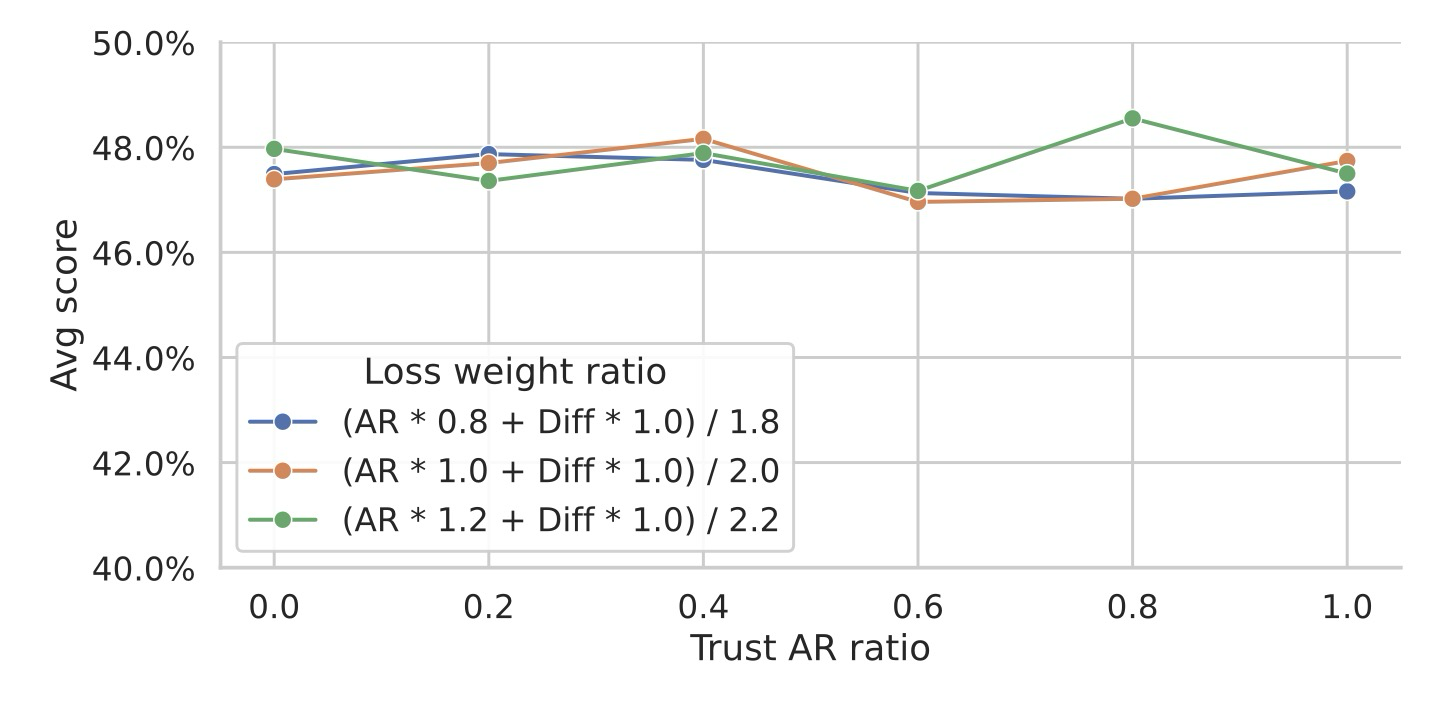
Figure 6: Trusting AR v.s. Diffusion Outputs for Sampling
그림 6에서 우리는 값(다른 손실 균형 인자 에 걸쳐)을 변화시키면서 일관된 성능을 확인한다. 이는 우리 모델이 잘 학습되어 검증을 위해 어떤 로짓을 선택하든 관계없이 품질이 보존된다는 것을 보여주는데, 이상적인 경우(즉, 잘 학습된 경우) 이 두 출력은 엄격하게 동일할 것이기 때문이다. 또한 이는 자기회귀 거부 샘플링(autoregressive rejection sampling)이 품질-속도 향상 상충 관계를 보장하는 요소이지, AR 지식 자체가 아님을 나타낸다.
4.4.4 How useful is the Full Mask Strategy?
모델이 1단계 확산 드래프팅으로 인해 추론 중에 부분적인 깨끗한 입력(partial clean inputs)을 보지 않는다는 사실을 활용하기 위해, 우리는 학습 중에 확산 부분에 대한 입력을 전체 마스크(full masks)로 변형시킨다. 이는 더 나은 학습-테스트 행동 일관성을 촉진할 뿐만 아니라 더 풍부한 확산 손실 신호를 제공하고 정규화 후 손실 균형을 더 쉽게 만든다.
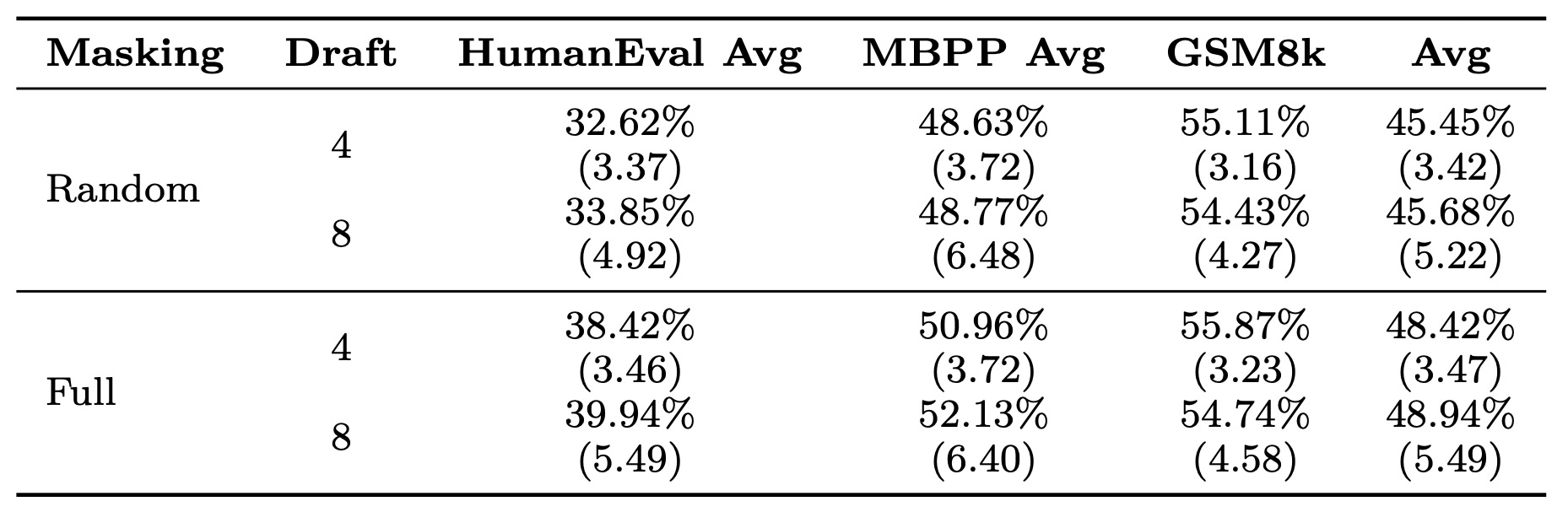
Table 5: Quality-efficiency Improvement from Full Masking
표 5에서 우리는 이 마스킹 전략의 효과를 보여주는데, 이는 특히 코딩 태스크에서 일관된 품질 개선을 보여준다. 또한 이 전략은 4.4.3절에서 논의된 바와 같이 자기회귀 거부 샘플링을 위해 어떤 모듈의 예측을 신뢰할지 결정하는 유연성을 가능하게 한다. 전체 마스킹 전략은 학습-테스트 불일치를 줄이고 더 풍부한 확산 손실 신호를 제공하여 효율성과 품질을 실질적으로 개선한다.
5. Limitations
Batch size. 우리는 배치 크기 = 1 효율성 벤치마킹에 중점을 두었지만, 이것이 TiDAR가 큰 배치 크기를 처리할 수 없다는 것을 의미하지는 않는다. 우리는 제로 샷(zero-shot) 방식으로 디코딩 중 블록(초안) 길이를 조정하여 다양한 연산 프로필에 맞출 수 있을 뿐만 아니라, 토큰당 FLOPs(FLOPs / token) 측면에서도 경쟁력 있는 성능을 달성할 수 있다.
Long context extension. 우리 모델은 표준 자기회귀(AR) 모델과 비교했을 때 본질적으로 긴 문맥 능력에 제한이 있다고는 생각하지 않는다. 그러나 현재 구현은 학습 중에 마스크 토큰이 추가되어 시퀀스 길이를 두 배로 늘려야 하므로, 효율적인 긴 문맥 확장 방법(예: TiDAR를 위해 특별히 설계된 문맥 병렬화)에 대한 탐구는 향후 연구 과제로 미룬다.
System optimization. 우리는 네이티브 PyTorch와 Flex Attention을 사용하여 작성했음에도 불구하고 상당한 처리량 개선을 이미 달성했음을 보여주었다. 우리는 사용자 정의 어텐션 커널과 스케줄링 알고리즘을 작성하는 것이 그림 1에 제시된 것처럼 사용 중인 서빙 하드웨어에 특화된 "여유 토큰 슬롯(free token slots)"의 활용을 극대화할 수 있다고 믿는다.
6. Conclusion
우리는 TiDAR를 소개한다. TiDAR는 특별히 설계된 어텐션 마스크를 사용하여 단일 모델 순방향 패스 내에서 확산(diffusion) 방식으로 초안을 작성하고("thinking") 자기회귀(autoregression) 방식으로 샘플링("talking")하는 시퀀스 수준의 하이브리드 아키텍처이다. TiDAR는 병렬 1단계 확산에서 얻는 효율성 이점과 자기회귀 샘플링을 통해 보장되는 품질 이점을 활용하여, 인상적인 효율성-품질 트레이드오프를 달성한다. 우리는 다양한 다운스트림 태스크에서 TiDAR 1.5B 모델이 NFE(Network Function Evaluation)당 평균 7.45개의 토큰을 출력할 수 있으며, TiDAR 8B 모델은 NFE당 평균 8.25개의 토큰을 출력할 수 있음을 보여준다. 이는 자기회귀(AR) 모델과 비교했을 때 각각 4.71배 및 5.91배 더 많은 토큰/초당 처리량(tokens per second)으로 변환되며, 동시에 경쟁력 있는 품질을 유지한다. 우리는 최신 GPU의 "여유 토큰 슬롯(free token slots)"의 한계를 확장하며, 지연 시간에 민감한 애플리케이션을 위해 투기적 디코딩(speculative decoding)을 능가하는 것이 가능함을 최초로 보여준다. 우리는 이 연구가 하이브리드 LLM 아키텍처 및 추론에 대한 향후 연구를 상당히 촉진할 것이라고 믿는다.
