Author: Qishuo Hua, Lyumanshan Ye, Dayuan Fu, Yang Xiao, Xiaojie Cai, Yunze Wu, Jifan Lin, Junfei Wang, Pengfei Liu
Affilation: STJU, SII, GAIR
Venue: arXiv
Comments:
Date: October 2025
Paper Link: https://arxiv.org/abs/2510.26493
⭐️ Key Takeaways
1. 컨텍스트 엔지니어링은 최근의 LLM 시대의 혁신이 아니라 20년 이상 전으로 거슬러 올라가는 오랜 발전 분야이며, 기계 지능 수준에 따라 4단계(1.0 ~ 4.0)의 뚜렷한 진화 과정을 거쳐 왔음을 강조한다.
2. 이 논문은 컨텍스트 엔지니어링을 기계가 부족한 상황 인식 능력을 보완하기 위해 인간의 의도와 고엔트로피 컨텍스트를 기계가 이해할 수 있는 낮은 엔트로피 표현으로 변환하는 체계적인 과정으로 정의한다.
3. 컨텍스트의 수집, 관리 사용에 대한 핵심 설계 고려 사항을 제공하며, 기계 지능이 인간 수준이나 초인간적 지능에 도달함에 따라 컨텍스트를 명시적으로 관리하는 역할이 인간에게서 기계로 점차 이동하고 기계가 컨텍스트를 적극적으로 구성하게 될 것이라는 미래 궤적을 제시한다.
Abstract
카를 마르크스는 한때 “인간의 본질은 사회적 관계의 총체이다”(Marx, 1845)라고 기술했는데, 이는 개인이 고립된 존재가 아니라 다른 개체들과의 상호작용에 의해 근본적으로 형성되며, 그 안에서 컨텍스트(context)가 구성적이고 본질적인 역할을 수행한다는 것을 시사한다. 컴퓨터와 인공지능의 출현과 함께, 이러한 컨텍스트는 더 이상 순수한 인간-인간 상호작용에만 국한되지 않으며, 인간-기계 상호작용 또한 포함된다. 여기서 핵심적인 질문이 발생하는데, 그것은 바로 기계가 우리의 상황과 목적을 어떻게 더 잘 이해할 수 있는가이다. 이 문제에 대처하기 위해, 연구자들은 최근 컨텍스트 엔지니어링(context engineering)이라는 개념을 ‘개발했다’. 비록 이것이 종종 에이전트 시대의 최근 혁신으로 간주되지만, 실제로는 관련 사례들이 20년 이상 전으로 거슬러 올라갈 수 있다고 우리는 주장한다. 1990년대 초반부터 컨텍스트 엔지니어링은 기계의 지능 수준에 따라 형성된 뚜렷한 역사적 단계를 거쳐 진화해왔다. 이 단계는 원시적인 컴퓨터를 중심으로 구축된 초기 인간-컴퓨터 상호작용(HCI) 프레임워크에서부터, 지능형 에이전트가 주도하는 오늘날의 인간-에이전트 상호작용(HAI) 패러다임, 그리고 잠재적으로는 미래의 인간 수준 또는 초인간적 지능에까지 이른다. 본 논문에서 우리는 컨텍스트 엔지니어링의 컨텍스트를 논하며, 체계적인 정의를 제공하고, 그것의 역사적 및 개념적 지형에 대한 우리의 관점을 제시하며, 실습을 위한 주요 설계 고려 사항들을 검토한다. 이러한 질문들에 답함으로써, 우리는 컨텍스트 엔지니어링을 위한 개념적 토대를 제공하고 그 유망한 미래를 제시하는 것을 목표로 한다. 본 논문은 AI 시스템에서 체계적인 컨텍스트 엔지니어링을 향한 더 넓은 커뮤니티 노력의 발판 역할을 수행한다.
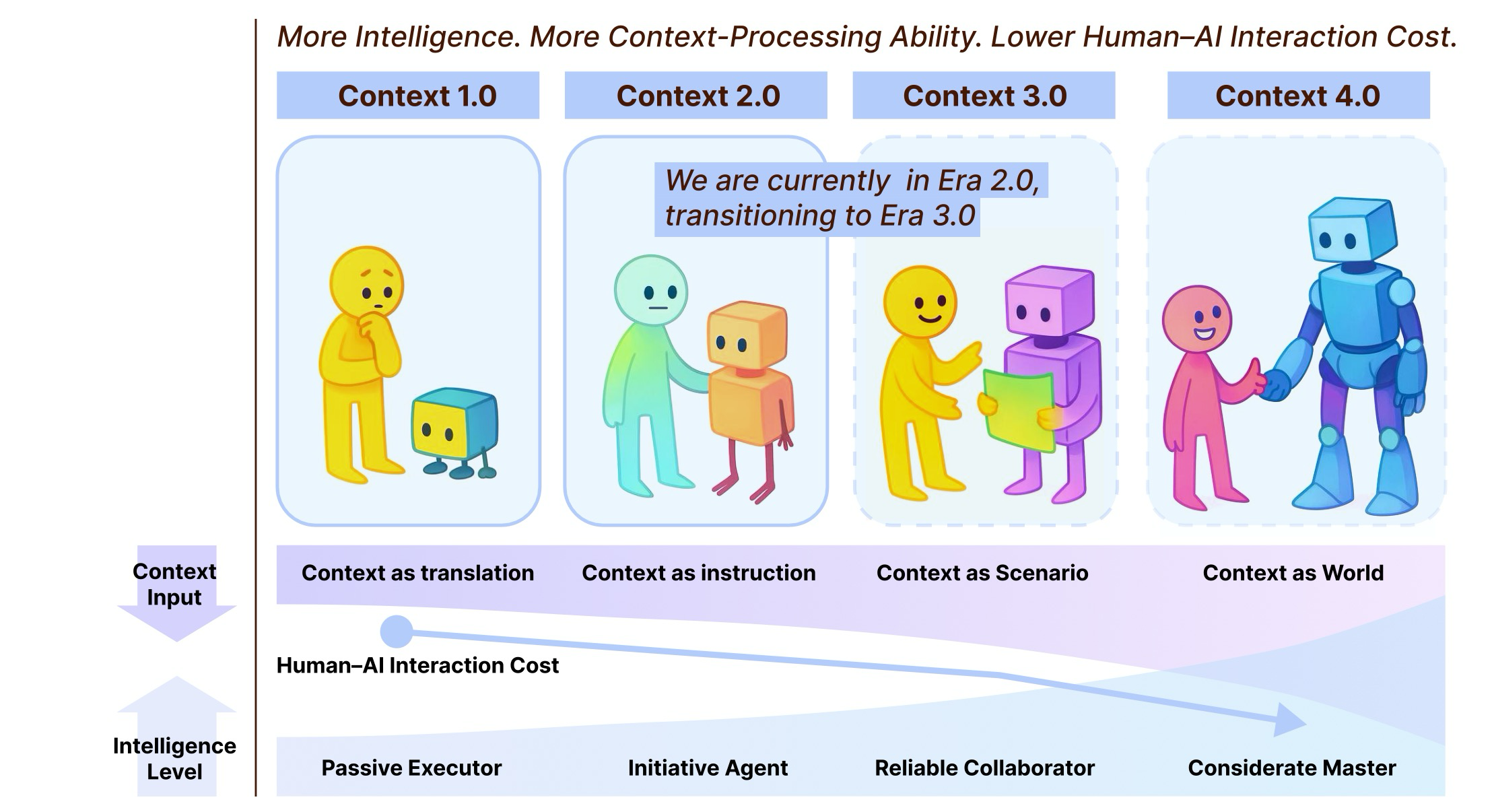
Figure 1: Context Engineering 1.0부터 Context Engineering 4.0까지의 개요
1. Introduction
최근 몇 년간, LLM과 지능형 에이전트의 급부상으로 인해 컨텍스트가 모델 행동에 미치는 영향에 대한 관심이 높아지고 있다. 연구에 따르면 context window 내에 배치된 contents는 모델 성능에 상당한 영향을 미칠 수 있다. 동시에, 다단계 추론과 장기적인 시간 범위에 걸쳐 작동할 수 있는 시스템에 대한 요구가 증가하고 있다. 이러한 추세는 한 가지 핵심 질문을 제기한다: 특히 장기적인 작업에서 효과적인 컨텍스트 메커니즘을 통해 기계가 인간의 의도를 더 잘 이해하고 그에 따라 행동하도록 어떻게 지원할 수 있을까?
이러한 과제를 해결하기 위해, 연구자들은 최근 Context Engineering에 집중해 왔는데, 이는 기계가 인간의 의도에 부합하는 방식으로 행동할 수 있도록 컨텍스트 정보를 설계하고, 조직화하고, 관리하는 실천이다. 최근 몇 년 동안 LLM 및 에이전트 분야에서는 프롬프트 엔지니어링, RAG, 도구 호출, 장기 기억 메커니즘 등 컨텍스트 엔지니어링이 광범위하게 구현되는 것을 목격했다. 이러한 기술들은 기계가 고엔트로피 컨텍스트를 동화하는 능력을 확장시켰으며, 상호 작용 시스템의 설계에 실질적인 영햐을 미쳤다. 이러한 발전에도 불구하고, 이 분야는 종종 오해된다. 컨텍스트 엔지니어링은 일반적으로 최근의 발전으로 인식되며, “컨텍스트”는 종종 대화 기록, 시스템 프롬프트 또는 에이전트 중심의 환경 입력으로 좁게 정의된다. 사실, 컨텍스트는 더 광범위하게 정의될 수 있으며, 컨텍스트 엔지니어링은 20년 이상 동안 실행되어 왔다. 이러한 역사를 인식하는 것은 이 분야의 현재 상태와 미래 잠재력을 모두 이해하는 데 필수적이다.
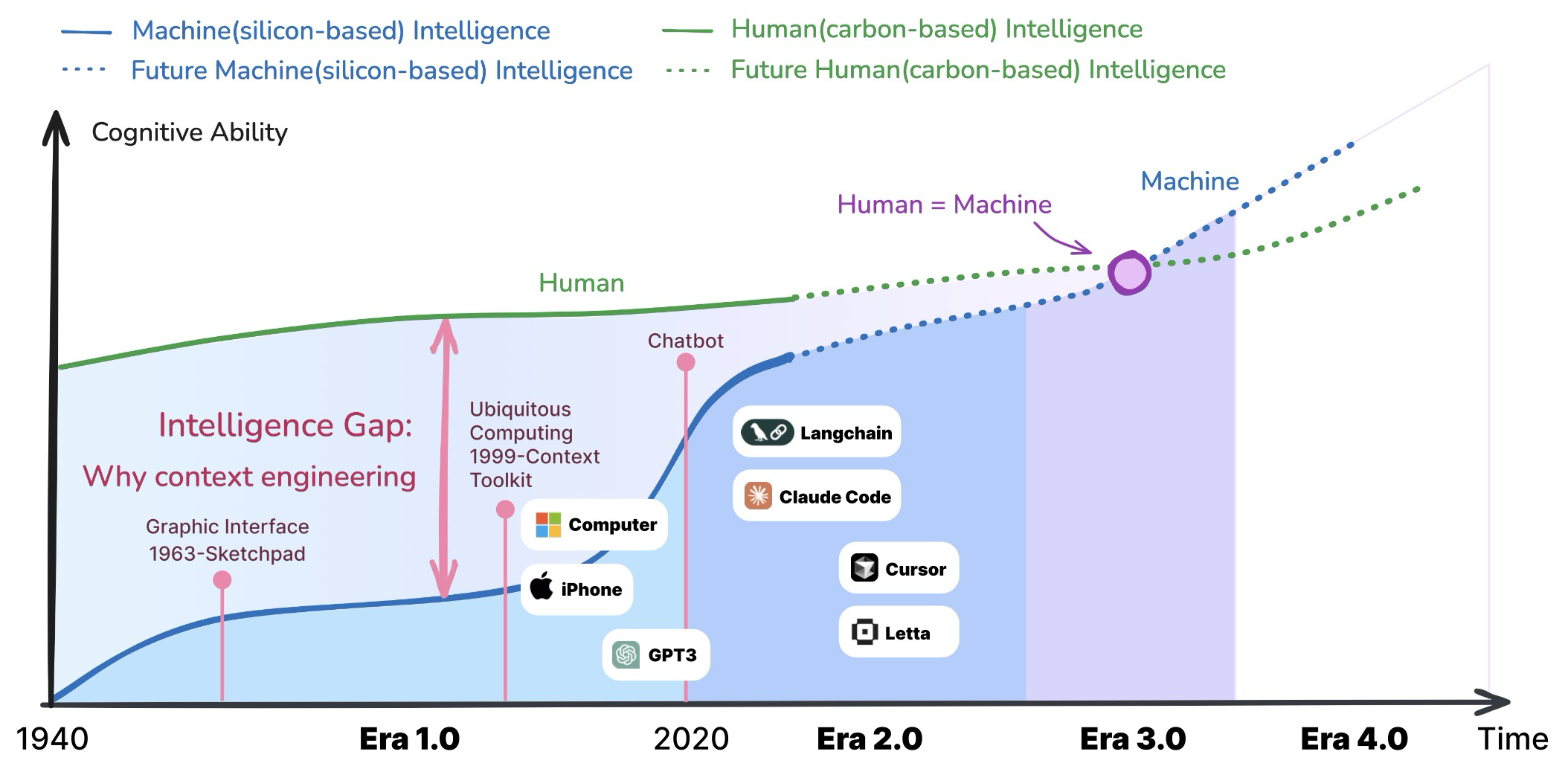
Figure 2: Trajectories of carbon-based and silicon-based cognitive abilities over time
우리는 컨텍스트 엔지니어링의 발전이 최근의 기술적 관행에 국한되기보다는 더 넓은 역사적 관점을 통해 조명되어야 한다고 주장한다. 지난 20년간의 진화를 추적함으로써, 우리는 그 근본적인 원칙에 대한 더 깊은 이해를 얻을 수 있으며, 컨텍스트를 다루는 다양한 접근 방식이 지능형 시스템의 발전에 어떻게 기여했는지 인식할 수 있다. 이러한 관점은 AI 연구가 역사적 궤적을 기반으로 구축되어 강력하고 미래 지향적인 토대를 마련할 수 있도록 한다. 이러한 넒은 관점에서 볼 때, 컨텍스트 엔지니어링은 엔트로피 감소 과정으로 간주될 수 있다. 기계는 인간과 달리 의사소통 중 “빈틈을 효과적으로 채울” 수 없다. 사람들이 상호 작용할 때, 그들은 공유된 지식, 감정적 신호, 상황 인식을 통해 누락된 컨텍스트를 추론하는 능력, 즉 정보 엔트로피를 능동적으로 줄이는 청자의 능력에 의존한다. 현재로선 기계가 이 능력을 가지고 있지 않다. 결과적으로 우리는 기계가 이해할 수 있는 형태로 원래 정보를 압축하여 컨텍스트를 “전처리”해야 한다. 이것이 컨텍스트 엔지니어링의 핵심 “노력”을 나타낸다: 높은 엔트로피 컨텍스트와 의도를 기계가 이해할 수 있는 낮은 엔트로피 표현으로 변환하는 데 투자해야 하는 노력이다. 그림 2에 나타난 바와 같이, 컨텍스트 엔지니어링은 항상 인간 (탄소 기반) 지능과 기계 (실리콘 기반) 지능 사이의 인지적 격차를 해소하기 위해 존재해왔다.
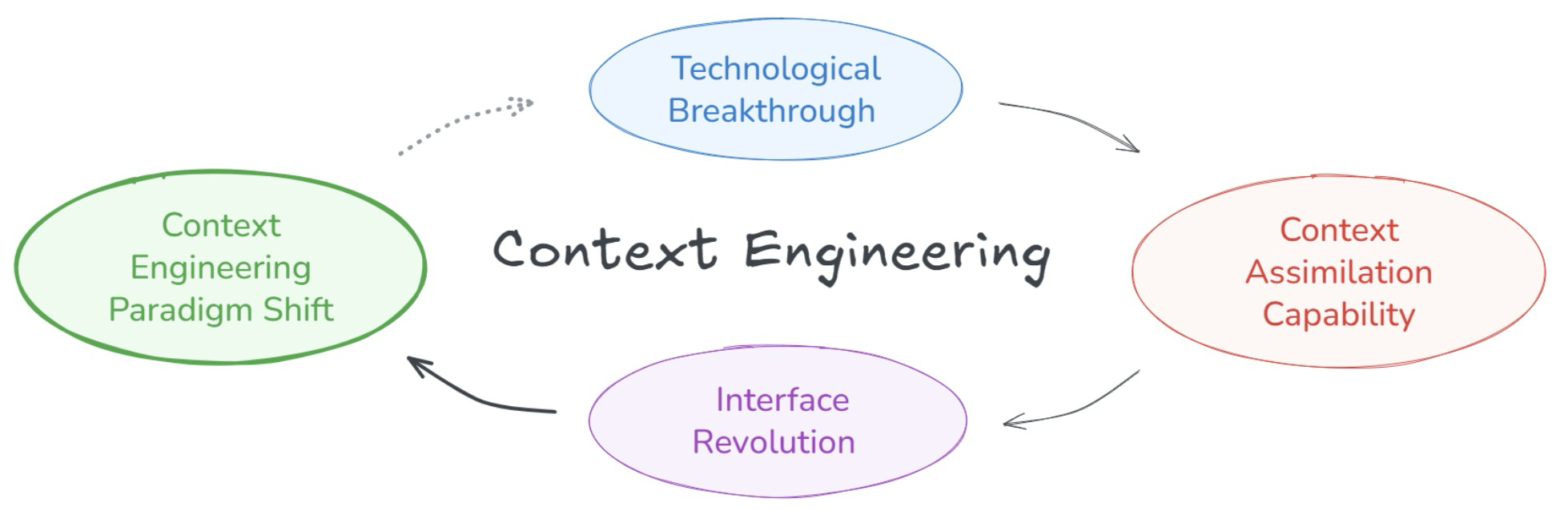
Figure 3: Evolutionary process in context engineering
탄소 기반 지능은 비교적 느리게 발전하는 반면, 실리콘 기반 지능은 훨씬 빠른 속도로 반복된다. 따라서 패러다임 전환의 주요 동인은 기계 지능의 급속한 발전에 있다. 기계가 더 지능적일수록, 컨텍스트 엔지니어링은 더 자연스러워지고, 인간-기계 상호 작용 비용은 더 낮아진다. 기계 지능의 각 질적 도약은 인간-기계 인터페이스에 근본적인 혁명을 촉발한다. 그림 3에 나타난 바와 같이, 기술적 돌파구는 컨텍스트 동화 능력의 급증으로 이어지고, 이는 인터페이스 혁명을 주도하며, 궁극적으로 컨텍스트 엔지니어링의 패러다임 전환을 초래한다. 이러한 전환은 점진적인 개선이 아니라 인간과 기계가 소통하는 방식을 근본적으로 재편하는 일련의 패러다임 변화이다. 이 반복되는 패턴을 기반으로, 우리는 컨텍스트 엔지니어링 진화를 네 가지 뚜렷한 단계의 진행으로 개념화할 수 있다.
- Context Engineering 1.0: 구조화된 낮은 엔트로피 입력이 있는 원시 컴퓨팅
- 2.0: 자연어를 해석하고 모호성을 처리할 수 있는 지능형 에이전트
- 3.0: 미묘한 의사소통과 원활한 협업을 가능하게 하는 인간 수준의 지능
- 4.0: 기계가 선제적으로 컨텍스트를 구성하고 인간이 명시적으로 표현하지 않은 필요를 드러낼 수 있는 초인적 지능.
각 단계는 질적으로 다른 설계 절충을 수반하며 인간과 기계의 변화하는 역할을 강조한다. 이 논문의 핵심 기여는 다음과 같다.
- 첫째, 우리는 컨텍스트 엔지니어링은 더 넓은 역사적 관점에 위치시키고, 현대 지능형 에이전트 이전의 기원을 추적한다.
- 둘째, 엔트로피 감소 관점에서 컨텍스트 엔지니어링의 본질과 기술적 발전을 반영하는 4단계 진화 모델을 포함하여, 체계적이고 광범위하게 정의된 이론적 프레임워크를 제시한다.
- 마지막으로, 우리는 일반적인 관행을 비교하여 일반적인 설계 고려 사항을 제안하고, 미래 지능형 시스템 개발을 위한 지침을 제공한다.
이 논문의 나머지 부분에서는, 먼저 컨텍스트 엔지니어링에 대한 우리의 정의를 제시하고, 우리의 분석의 기반이 되는 이론적 프레임워크를 설명할 것이다. 그런 다음, 우리는 분야의 역사적 진화를 추적할 것이며, 특히 1.0 시대와 2.0 시대의 특징에 주목할 것이다. 이 토대를 바탕으로, 우리는 세 가지 핵심 차원 (컨텍스트 수집, 컨텍스트 관리, 컨텍스트 사용)을 중심으로 구성된 설계 고려 사항을 논의할 것이다. 우리는 현재의 관행을 분석하고, 고유한 과제를 식별하며, 미래의 발전을 형성할 수 있는 새로운 접근 방식을 탐구할 것이다.
2. Theorectical Framework
컨텍스트를 더 잘 이해하기 위해, 우리는 컴퓨팅 시스템에서 컨텍스트를 정의하는 근본적인 구성 요소를 공식화하는 것부터 시작한다. Dey의 컨텍스트에 대한 기초적인 정의를 바탕으로, 우리는 이러한 구성 요소를 수학적으로 표현하여 컨텍스트의 정밀한 표상을 제공한다. 이러한 공식화를 기반으로, 우리는 컨텍스트 엔지니어링을 정의하고, 그것이 기계 지능의 여러 단계를 거치며 어떻게 진화해왔는지 살펴본다.
2.1 Formal Definition
Definition 1 (Entity and Characterization). 를 모든 개체 (사용자, 애플리케이션, 객체, 환경 등)의 공간이라 하고, 를 모든 가능한 특성화 정보의 공간이라고 하자. 를 의 멱집합이라고 표시한다. 임의의 개체 에 대해, 상황 특성화 함수를 다음과 같이 정의한다: - (식 1). 여기서 는 개체 를 특성화하는 정보의 집합을 반환한다. 예를 들어, 사용자가 Gemini CLI에 “나를 위해 관련 문서를 검색해줘”라고 입력할 때, 관련 개체 집합에는 사용자, Gemini CLI application, 터미널 환경, 외부 도구, 메모리 모듈, 그리고 백엔드 모델 서비스가 포함될 수 있다. 여기서 는 사용자(입력 프롬프트), 애플리케이션(시스템 명령), 환경(작업 디렉토리), 외부 도구(플러그인, 검색 도구), 단기 또는 장기 메모리 모듈(세션 기록), 그리고 모델 서비스(응답 형식)를 설명할 수 있다.
Definition 2 (Interaction). 상호 작용은 사용자와 애플리케이션 간의 모든 관찰 가능한 참여를 의미하며, 계산 시스템에 영향을 미치거나 영향을 받을 수 있는 명시적 행동 (클릭)과 암시적 행동 (주의 패턴)을 모두 포함한다. Gemini CLI의 예에서, 명시적 상호 작용은 사용자의 명령 입력이며, 암시적 측면에는 터미널 상태, 이전에 검색된 컨텍스트, 메모리 모듈 사용 또는 도구 호출 상태가 포함될 수 있다.
Definition 3 (Context). 주어진 사용자-애플리케이션 상호 작용에 대해, 컨텍스트 는 다음과 같이 정의된다: - (식 2). 여기서 은 해당 상호 작용과 관련이 있다고 간주되는 개체의 집합이다. 이는 컨텍스트를 “사용자와 애플리케이션 간의 상호 작용과 관련이 있다고 간주되는 개체의 상황을 특성화하는 데 사용될 수 있는 모든 정보”로 포착한다. 동일한 예에서, 에는 사용자, Gemini CLI 애플리케이션 등이 포함될 수 있으며, 일반적인 컨텍스트 는 이러한 특성화의 aggregation이다.
Definition 4 (Context engineering). 컨텍스트 엔지니어링은 기계의 이해와 작업 성능을 향상시키기 위해 컨텍스트 수집, 저장, 관리 및 사용을 설계하고 최적화하는 체계적인 프로세스이다. 공식적으로 이는 다음과 같이 정의될 수 있다: - (식 3). 여기서 는 식 (2)에서 정의된 원시 컨텍스트 정보를 나타내고, 는 대상 작업 또는 애플리케이션 도메인을 나타낸다. 그리고 는 향상된 작업 성능을 위해 컨텍스트 표현을 변환하고 최적화하는 결과 컨텍스트 처리 함수이다. 는 컨텍스트 처리 작업의 유연한 합성을 포함한다: - (식 4). 여기서 는 다양한 컨텍스트 엔지니어링 작업 를 결합하는 합성 함수를 나타낸다. 합성 는 병렬 처리, 반복적 개선, 조건부 분기 또는 특정 애플리케이션 요구 사항에 맞춰진 모든 작업 조합을 포함할 수 있다. 실제로 컨텍스트 엔지니어링 2.0의 작업 집합에는 다음이 포함될 수 있다: (1) 센서 또는 기타 채널을 통해 관련 컨텍스트 정보 수집, (2) 효율적인 저장 및 관리, (3) 일관되고 상호 운용 가능한 형식으로 표현, (4) 텍스트, 오디오 또는 비전의 다중 모드 입력 처리, (5) 과거 컨텍스트 통합 및 재사용 (”self-baking”), (6) 가장 관련성 높은 컨텍스트 요소 선택, (7) 에이전트 또는 시스템 간 컨텍스트 공유, (8) 피드백 또는 학습된 패턴을 기반으로 컨텍스트 동적 조정.
The Scope of Context Engineering 이 정의는 컨텍스트 엔지니어링을 특정 기술이나 시대로 제한하는 것을 의도적으로 피한다. 수신하는 개체가 1990년대의 GUI를 가진 원시 컴퓨터든 2025년의 에이전트든, 컨텍스트와 의도를 정확하게 이해하도록 만드는 근본적인 과제는 동일하게 유지된다. 컨텍스트 엔지니어링에 사용되는 특정 기술과 형식은 기술과 함께 진화하지만, 인간의 의도와 기계의 이해 사이의 격차를 해소하는 핵심 과제는 일정하게 유지된다.
Why This Definition Matters? 이 정의가 중요한 이유는 다음과 같다. 첫째, 현재의 프롬프트 엔지니어링 관행을 인간-컴퓨터 인터페이스 설계의 풍부한 역사와 연결하여 수십 년 동안 축적된 지식으로부터 배울 수 있도록 한다. 둘째, 다양한 기술과 시대를 통틀어 특정 컨텍스트 설계가 작동하는 이유를 설명할 수 있는 이론적 틀을 제공한다. 셋째, 기계의 이해 능력이 계속 발전함에 따라 컨텍스트 엔지니어링이 어떻게 진화할지 예측할 수 있는 토대를 제공한다. 컨텍스트 엔지니어링을 좁은 기술적 관행이 아닌 인간-기계 통신의 근본적인 측면으로 이해함으로써, 우리는 그 역사적 발전과 미래 궤적을 모두 더 잘 파악할 수 있다. 이러한 관점은 컨텍스트 엔지니어링이 최근의 발명이 아니라 인간-기계 상호 작용의 본질 자체가 변화함에 따라 계속 적응할 진화하는 분야임을 보여준다.
2.2 Stage Characterization
컨텍스트 엔지니어링을 더 잘 이해하기 위해, 우리는 현재의 순간을 넘어 수십 년 동안 지속적으로 진화해 온 인간-기계 통신의 근본적인 측면으로 인식해야 한다. 이러한 지속적인 진화는 네 가지 단계로 특정지어질 수 있으며, 각 단계는 기계 지능의 주요 발전과 일치한다. 구체적으로, 기계 지능은 다음 단계를 통해 진행된다고 간주될 수 있다: (i) 원시 컴퓨팅, (ii) 에이전트 중심 지능, (iii) 인간 수준 지능, 그리고 (iv) 초인적 지능.
Era 1.0: Primitive Computation (1990s-2020) 이 단계에서 기계는 컨텍스트를 해석하는 능력이 매우 제한적이었다. 구조화된 입력을 처리하고 간단한 환경 단서를 인식할 수 있었지만, 의미나 의도에 대한 더 깊은 이해는 부족했다. 인간-기계 상호 작용은 메뉴에서 선택하거나 단순한 센서 데이터를 입력으로 사용하는 것과 같은 엄격하고 미리 정의된 형식에 의존했다. 이 시대는 이진 수준 명령을 넘어섰지만, 모든 컨텍스트는 여전히 기계가 직접 처리할 수 있는 형식으로 명시적으로 준비하고 번역되어야 했다.
Era 2.0: Agent-Centric Intelligence (2020-Present) 2020년 GPT-3 출시로 대표되는 LLM의 출현은 컨텍스트 엔지니어링과 에이전트 중심 지능의 전환점을 표시한다. 이 단계는 기계는 자연어 입력을 이해하고 일부 암시적 의도를 추론하는 능력으로 특정지어지는 적당한 지능을 보여준다. 사용자가 대화식으로 자신의 필요를 표현할 수 있고 시스템이 근본적인 의미의 상당 부분을 해석할 수 있으므로, 인간-기계 협업은 점점 더 실현 가능해진다. 컨텍스트는 더 이상 명시적으로 정의된 신호에 국한되지 않으며, 모호성과 불완전한 정보를 포괄할 수 있다. 에이전트는 고급 언어 이해 및 인컨텍스트 학습을 사용하여 컨텍스트적 격차에 대해 능동적으로 추론함으로써 더 적응적이고 반응적인 상호 작용을 제공한다.
Era 3.0: Human-Level Intelligence (Future) 예상되는 돌파구와 함께, 지능형 시스템은 인간 수준의 추론 및 이해에 접근할 것으로 예상된다. 이 단계에서 컨텍스트 엔지니어링은 현재의 패턴을 초월하여, 에이전트가 인간처럼 컨텍스트를 감지하고 고엔트로피 정보를 동화할 수 있게 한다. 해석 가능한 컨텍스트의 범위는 사회적 단서, 감정 상태, 더 풍부한 환경 역학과 같은 것으로 크게 확장된다. 이러한 발전은 AI가 지식이 풍부하고 효과적인 동료 역할을 하면서 진정으로 자연스러운 인간-기계 협업을 가능하게 한다.
Era 4.0: Superhuman Intelligence (Speculative) 지능형 시스템이 인간의 능력을 초월함에 따라, 그들은 신의 시야를 소유하게 시작하며, 인간 스스로보다 인간의 의도를 더 깊이 이해한다. 이 단계에서는 전통적인 주체-객체 관계가 역전된다. 기계가 인간이 정의한 컨텍스트에 수동적으로 적응하는 대신, 인간을 위한 새로운 컨텍스트를 능동적으로 구성하고, 숨겨진 필요를 발견하며, 인간의 사고를 안내한다. 이러한 변화의 징후는 이미 나타나고 있는데, 예를 들어 바둑에서 프로 선수들은 AI로부터 새롭고 초안적인 전략을 배우고 있다. 이러한 방식으로, 기계는 통찰력과 영감의 원천이 되며, 인간-기계 협업의 본질을 근본적으로 재정의한다.
3. Historical Evolution
컨텍스트 엔지니어링이 어떻게 진화해왔는지 더 잘 이해하기 위해, 우리는 두 가지 주요 시대에 걸쳐 그 핵심 특징들을 비교한다. 다음 섹션들에서는 초기 개발 단계에서의 컨텍스트 엔지니어링의 기반과 현재의 환경을 정의하는 중요한 발전 (2.0 시대)을 살펴본다.
| Aspect | Context Engineering 1.0 | Context Engineering 2.0 |
|---|---|---|
| 기간 | 1990년대-2020 | 2020-현재 |
| 기술적 배경 | 유비쿼터스 컴퓨팅, 컨텍스트 인식 시스템, HCI | LLM, Agent, Prompt Engineering |
| 대표적인 시스템 | Context Toolkit, Cooltown, ContextPhone | ChatGPT, LangChain, AutoGPT, Letta |
| 컨텍스트 양상 | 위치, 신원, 활동, 시간, 환경, 장치 상태 | 토큰 시퀀스, 검색된 문서, 도구 API, 사용자 기록 |
| 핵심 메커니즘 | 센서 융합, 규칙 트리거 | 프롬프팅, RAG, CoT, 메모리 에이전트 |
| 컨텍스트 허용도 | 비교적 낮음 | 비교적 높음 |
| 인간 유사성 | 비교적 낮음 | 비교적 높음 |
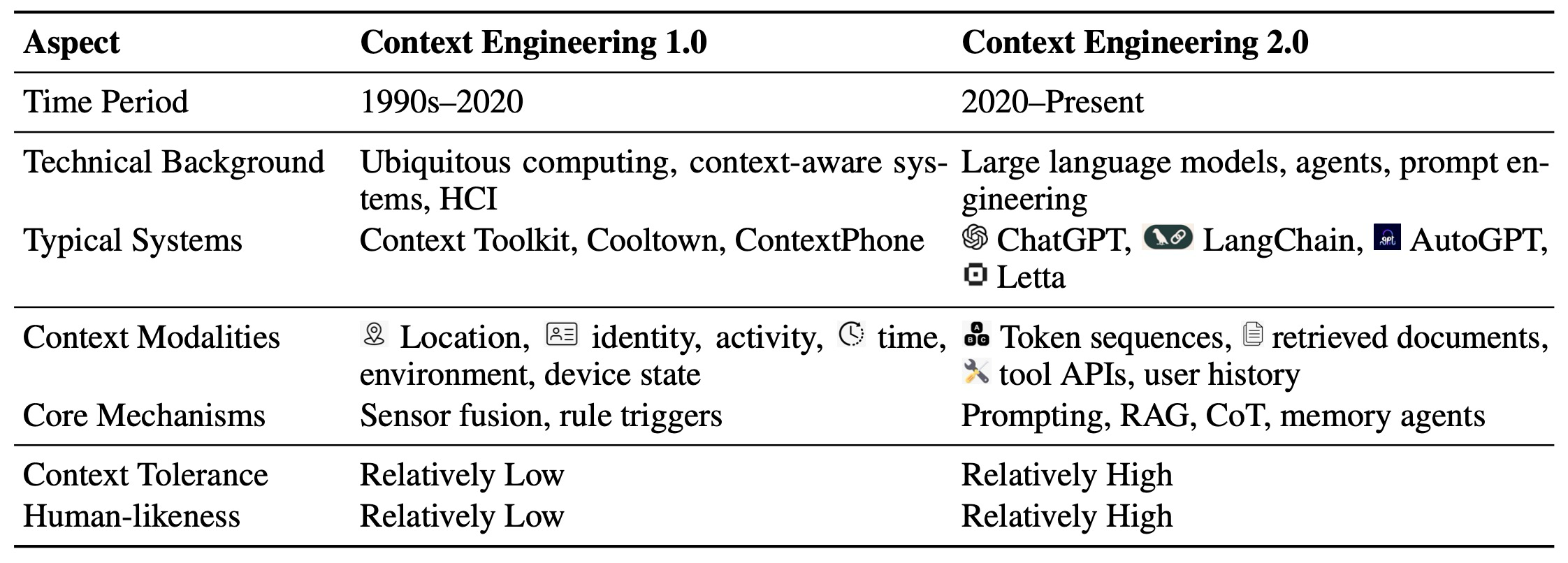
Table 1: Comparison between context engineering 1.0 and 2.0 across representative dimensions
3.1 Over 20 Years Ago: Era 1.0
우리는 컨텍스트 엔지니어링을 인간과 기계 사이의 효과적인 이해와 소통을 가능하게 하는 실천으로 정의한다. 컨텍스트 엔지니어링 1.0 시대(주로 1990년대부터 2020년까지)에는 인간이 컨텍스트를 제공하는 책임이 있었고, 원시 컴퓨터는 정보를 수신했다. 이 시대에는 인간이 기계에 적응하기 위해 노력했으며, 설계자는 복잡한 인간의 의도를 구조화된, 기계가 읽을 수 있는 형식으로 변환하는 "의도 번역가" 역할을 했다. 이는 비정형적이고 고엔트로피 정보를 자율적으로 해석할 수 있는 현대 AI 시대와는 대조된다.
3.1.1 Technological Landscape
컨텍스트 엔지니어링 1.0을 이해하려면 먼저 1980년대와 1990년대의 기술적 환경을 고려해야한다. 이 시기는 명령줄 인터페이스(CLI)에서 그래픽 사용자 인터페이스(GUI)로의 전환을 특징으로 하며, 컴퓨터가 일반 대중에게 더 접근하기 쉬워졌다. 그러나 이러한 변화는 사용자에게 가해지는 인지 부하를 제거하지 못했고, 대신 인간이 당시 기술의 한계에 정확히 적응하도록 상호 작용을 재정의했다. 1991년, Mark Weiser는 컴퓨팅이 일상 환경에 매끄럽게 통합되는 것을 구상하는 유비쿼터스 컴퓨팅 개념을 도입했다. 이 비전은 장치가 사용자의 능동적인 입력 없이 서비스를 제공할 수 있음을 시사했다. 이 아이디어를 기반으로, 시스템이 사용자 상태, 환경, 작업을 감지하여 동작을 동적으로 조정할 수 있는지 탐구하기 위한 프레임워크인 컨텍스트 인식 컴퓨팅이 등장했다.
이러한 개념적 발전에도 불구하고, 당시의 기술적 한계는 상당했다. 기계는 미리 정의된 프로그램 로직만 실행할 수 있었고, 자연어 의미를 이해하거나, 문제에 대해 추론하거나, 오류를 효과적으로 처리하는 능력이 부족했다. 이는 인간의 사고와 기계의 처리 능력 사이에 상당한 격차를 만들었다. 이 격차를 해소하기 위해 컨텍스트 엔지니어링은 복잡한 목표를 기계가 처리할 수 있는 간단하고 구조화된 구성 요소로 분해하고, 명확한 상호 작용 경로를 설계하며, 피드백 메커니즘을 구현하는 전략을 제공했다.
3.1.2 Theorectical Foundations
2000년대 초에는 컨텍스트 엔지니어링을 위한 견고한 이론적 프레임워크가 등장했다. 그중에서도 Anind K. Dey의 2001년 컨텍스트 정의가 초석으로 두드러졌다.
“컨텍스트는 개체의 상황을 특성화하는 데 사용될 수 있는 모든 정보이다. 개체는 사용자 및 애플리케이션 자체를 포함하며, 사용자와 애플리케이션 간의 상호 작용과 관련이 있다고 간주되는 사람, 장소 또는 객체이다.
이 정의는 컨텍스트의 다차원적 특성을 강조했다. 이 시대의 이론적 작업은 광범위하고 깊이 있었으며, 컨텍스트에 대한 총체적인 이해를 강조했는데, 이는 종종 채팅 기록과 같은 컨텍스트의 특정 측면을 고립시키는 오늘날의 좁은 초점과 대조된다. 컨텍스트 엔지니어링 1.0의 기초 이론을 재검토하는 것은 이러한 퇴보를 해결하고 컨텍스트 인식 시스템에 대한 더 포괄적인 접근 방식을 고취하는 데 도움이 될 수 있다.
3.1.3 Core Practices
컨텍스트 엔지니어링 1.0 시대의 핵심 혁신은 키보드와 마우스 같은 전통적인 입력 장치에서 분산된, 센서 중심의 패러다임으로 전환한 것이었다. 이는 사용자 및 주변 환경으로부터 더 풍부한 컨텍스트 신호를 지속적으로 포착해야 하는 새로운 필요성을 반영했다. Anind Dey는 이 세대를 위한 개념적 및 아키텍처적 기반을 제공하는 컨텍스트 인식 시스템을 위한 일반 프레임워크를 도입했으며, 이 프레임워크는 Context Toolkit을 통해 구체화되었다. Context Toolkit은 컨텍스트의 획득, 해석 및 전달을 지원하는 모듈식의 재사용 가능한 프레임워크를 정의했다. 이는 Context Widgets, Interpreters, Aggregators, Services, Discoverers라는 다섯 가지 핵심 추상화를 중심으로 조직되었다. 이러한 아키텍처적 우려 사항의 분리는 확장 가능하고 적응 가능한 컨텍스트 인식 시스템을 위한 실질적인 토대를 확립했으며, 초기 컨텍스트 엔지니어링 실천의 공식화에 결정적인 단계가 되었다. 요약하면, 컨텍스트 엔지니어링 1.0은 반응형 시스템 구축을 위한 기초적인 사고방식과 아키텍처적 패러다임을 확립했다. 비록 표현력과 확장성에는 한계가 있었지만, 이 단계는 컨텍스트 엔지니어링 2.0 시대에 이어진 더 진보된 설계를 위한 필수적인 기반을 제공했다.
3.2 20 Years Later: Era 2.0
컨텍스트 엔지니어링 1.0에서 2.0으로의 진화는 원시 컴퓨팅에서 지능형 에이전트로 이동하는 기계 지능의 중대한 도약을 나타낸다. 규칙 기반 추론과 구조화된 센서 입력이 지배적이었던 1.0 시대와 비교하여, 에이전트는 컨텍스트 파이프라인 전반에 걸쳐 중요한 발전을 도입한다. 이러한 개선 사항은 컨텍스트가 획득되는 방식부터 원시 신호가 허용, 해석되고 궁극적으로 지능적인 행동에 사용되는 방식까지 걸쳐 있다. 다음과 같은 변화들이 이 진화를 특징짓는다:
Acquisition of Context: Advanced Sensors 2.0 시대에도 센서는 컨텍스트 획득의 중심이지만, 스마트폰, 웨어러블, 주변 장치와 같은 센싱 기술의 발전이 사용 가능한 컨텍스트의 다양성과 범위를 크게 확장했다. 컨텍스트 엔지니어링 2.0은 더 광범위한 센서 다양성뿐만 아니라, 각 개별 센서에서 다양한 컨텍스트 신호를 추출하는 능력 또한 강조한다.
Tolerance for Raw Context: From Structured Inputs to Human-Native Signals 인간 수준 지능에 도달하기 전, 시스템의 지능은 주로 원시 컨텍스트에 대한 허용도, 즉 고엔트로피 정보 입력을 소비하고 처리하는 능력으로 측정되는 인간 유사성(human-likeness)의 정도에 의해 좌우된다. 1.0 시대에는 입력이 GPS 좌표, 시간과 같이 단순하고 구조화된 신호로 제한되었고, 개발자가 의미 있는 컨텍스트를 미리 정의해야 했다. 대조적으로, 2.0 시대의 현대 시스템은 자유 형식 텍스트, 이미지, 비디오와 같은 자연적인 인간 표현을 닮은 신호에서 컨텍스트를 해석할 수 있다. 이 변화는 지저분하고, 모호하며, 불완전한 데이터를 이해하는 시스템 능력의 더 깊은 개선을 반영한다. 기초 모델과 다중 모드 인식의 발전 덕분에, 시스템은 이제 입력을 고유한 형태 그대로, 많은 사전 처리 없이 직접 수집할 수 있다. 이는 컨텍스트 해석의 인간 수준 유연성으로 나아가는 근본적인 단계이다.
Understanding and Utilization of Context: From Passive Sensing to Active Understanding and Collaboration 1.0 시대의 컨텍스트 인식 시스템은 일반적으로 단순한 조건-행동 규칙 하에 작동했다. 즉, 미리 정의된 신호를 감지하고 고정된 반응을 유발했다. 이러한 시스템은 사용자가 '어디에 있는지'에 따라 반응했지만, '무엇을 하고 있는지'에 대해서는 반응하지 않았다. 대조적으로, 2.0 시스템은 사용자가 무엇을 하고 있는지 능동적으로 해석하고 공유된 목표를 달성하기 위해 협력하는 것을 목표로 한다. 예를 들어, 사용자가 연구 논문을 작성할 때, 시스템은 이전 단락과 현재 작성 의도를 분석하여 적절한 다음 섹션을 제안할 수 있다. 이 시스템은 단순히 환경을 감지하는 것이 아니라, 사용자의 작업 흐름에 통합된다. 이것이 바로 저자들이 컨텍스트 인식(context-aware)에서 컨텍스트 협력(context-cooperative) 시스템으로 발전했다고 부르는 것이다.
Figure 4: Design considerations of context engineering across different eras
4. Context Collection and Storage
컴퓨팅 환경이 더욱 복잡해짐에 따라, 향상된 컨텍스트 수집 능력에 대한 필요성이 증가하고 있다. 이에 대응하여, 센싱 기술과 AI의 발전으로 인해 이제 더 풍부한 소스(또는 센서)로부터 컨텍스트를 수집하는 것이 가능해졌다. 저장 방식 또한 로컬 장치, 네트워크 서버, 클라우드 플랫폼 등 다양한 곳으로 다각화되었으며, 각각 대기 시간(latency), 용량, 확장성, 보안 측면에서 다른 절충점(trade-offs)을 가진다. 이 과정은 두 가지 근본적인 설계 원칙에 의해 안내된다. 최소 충분성 원칙 (Minimal Sufficiency Principle)은 시스템이 작업을 지원하는 데 필요한 정보만을 수집하고 저장해야 한다고 명시한다. 컨텍스트의 가치는 볼륨이 아닌 충분성에 있다. 의미 연속성 원칙 (Semantic Continuity Principle)은 컨텍스트의 목적이 단순히 데이터의 연속성이 아니라 의미의 연속성을 유지하는 데 있음을 강조한다. 이러한 원칙들은 지능적이고 신뢰할 수 있는 시스템에서 컨텍스트가 수집되고 보존되어야 하는 방식을 형성한다.
4.1 Typical Strategies in Era 1.0 and 2.0
초기 단계에서 컨텍스트는 주로 데스크톱 컴퓨터나 초기 스마트폰과 같은 단일 장치에서 제한된 센서(GPS, 시계, 키보드/마우스 이벤트) 또는 사용 패턴 및 사용자 상호 작용을 기록하는 애플리케이션 로그를 사용하여 수집되었다. 이 시기의 저장 관행은 대체로 로컬 기반이었다. 컨텍스트 데이터는 일반적으로 로컬 파일 시스템 내의 로그 파일이나 구조화된 문서로 기록되거나 간단한 로컬 데이터베이스에 저장되었다. 최근 사용자 입력이나 창 활동과 같은 임시 상태는 종종 메모리 캐시나 임시 폴더에 보관되었다가 시스템이 종료될 때 삭제되었다. 일부 시스템이 중앙 집중식 서버에 컨텍스트를 업로드하려고 시도했지만, 이러한 노력은 높은 대기 시간과 불안정한 네트워크 연결로 인해 제약을 받았다. 일반적으로 이 시대의 저장 전략은 교차 장치 동기화나 보안 데이터 보호보다 단일 장치에서의 독립적인 가용성을 우선시했다.
기술 발전과 함께, 컨텍스트 수집은 스마트폰, 웨어러블, 가정용 센서, 클라우드 서비스 및 타사 API를 포함한 다양한 엔드포인트에 걸쳐 분산되었다. 에이전트는 다중 모드 신호를 연속적인 컨텍스트 스트림으로 통합했다. 이 시기의 저장 관행은 일반적으로 계층화된 아키텍처를 채택했으며, 저장 전략은 데이터의 의도된 사용법에 따라 결정되었다. 예를 들어, 수명이 짧거나 자주 액세스되는 데이터는 대기 시간을 최소화하기 위해 빠른 액세스 메모리나 엣지 노드에 캐시될 수 있다. 활동 기록이나 사용자 선호도와 같이 중기적인 보존이 필요한 데이터는 로컬 임베디드 데이터베이스(예: SQLite, LevelDB, RocksDB)에 저장되거나, 보안이 가장 중요한 경우 OS 지원 보안 저장소 또는 하드웨어 보안 모듈 내에 저장될 수 있다. 장기적인 지속성, 확장성 및 교차 장치 동기화를 위해서는 클라우드 저장 플랫폼 및 원격 서버 데이터베이스가 사용될 수 있다.
코드 에이전트의 경우, 많은 작업이 장기간 실행되거나 여러 세션에 걸쳐 실행될 수 있으므로, 단기적이며 용량이 제한된 컨텍스트 창에만 의존하는 것은 비실용적이다. 이를 해결하기 위해, 시스템은 작업 상태와 진행 상황을 장기 기억(long-term memory)에 주기적으로 저장하여, 에이전트가 중단 후 관련 컨텍스트를 복원함으로써 작업을 재개할 수 있도록 한다. 이러한 장기 기억은 로컬 데이터베이스나 보안 저장소에 유지될 수 있으며, 교차 장치 동기화를 위해 클라우드나 원격 서비스의 지원을 받을 수도 있고, 경우에 따라 더 안정적인 연속성과 장기적인 적응성을 제공하기 위해 모델 매개변수에 내장될 수도 있다. 예를 들어, Claude Code는 구조화된 메모를 유지하는 실용적인 접근 방식을 보여주는데, 여기서 핵심 정보는 주기적으로 컨텍스트 창에서 외부 메모리로 기록되고 필요할 때 검색된다. 이 전략은 경량(lightweight)이지만 영구적인 형태의 메모리를 제공하여, 에이전트가 복잡한 작업에서 진행 상황을 추적하고 정보 손실을 방지할 수 있도록 한다. 이러한 방식으로, 구조화된 외부 메모리는 에이전트의 계획 수평선을 짧고 일시적인 컨텍스트 창의 한계를 훨씬 넘어 확장시킨다.
4.2 Human-Level Context Ecosystem
3.0 시대에는 AI 시스템이 인간의 인식에 필적하는 컨텍스트 인식을 달성한다. 이들은 촉각 정보(예: 질감, 압력, 온도)를 매끄럽게 수집하여 인간의 촉각 경험을 재현할 수 있다. 후각과 미각을 통해 환경 조건을 해석하여, 연기를 위험 신호로 감지하거나 음식 신선도를 평가할 수 있다. 또한, 목소리 톤, 멈춤, 눈 맞춤, 심지어 침묵으로부터 의도와 감정을 포착하여, 인간 상호 작용을 정의하는 미묘한 사회적 컨텍스트를 이해한다. 인간 수준의 지능을 가진 시스템은 컨텍스트를 장기적인 개인 디지털 메모리로 통합한다. 저장은 더 이상 단순한 데이터 보존이 아니라, 시나리오 전반과 시간 경과에 따른 지속적인 추론 및 상호 작용을 지원하기 위해 컨텍스트를 자율적으로 조직하고 다듬을 수 있으며, 인간과 유사한 "망각(forgetting)" 및 "회상(recalling)" 능력을 달성하는 동적 인지 인프라 역할을 한다. 데이터는 로컬 환경과 클라우드 환경 사이에서 안전하게 흐르며, 사용자가 민감한 정보에 대한 절대적인 통제권을 유지하면서도 글로벌 지식 및 컴퓨팅 리소스로부터 이점을 얻을 수 있도록 보장하여, 자연스러운 인간-기계 공생을 가능하게 한다.
5. Context Management
5.1 Textual Context Processing
효과적인 컨텍스트 엔지니어링은 단순히 원시 컨텍스트를 수집하는 것만이 아니라, 그것을 어떻게 처리하는가에 달려 있다. 잘 설계된 처리 접근 방식은 해석, 압축, 검색 등 이후 모든 작업의 기반을 형성한다. 이는 시스템이 중요한 것에 집중하고, 과거 경험으로부터 학습하며, 지속적인 장기적 이해를 구축하도록 돕는다. 본 절은 원시 텍스트 컨텍스트를 처리하여 최상의 결과를 얻는 방법이라는 근본적인 질문을 탐구한다. 다중 턴 대화와 같은 원시 컨텍스트를 단순히 저장하는 것을 넘어, 일반적으로 사용되는 몇 가지 설계 방식과 그 장단점을 검토한다.
Mark Context with Timestamp 일반적인 설계 방식은 각 정보에 타임스탬프를 첨부하여 정보가 생성된 순서를 보존하는 것이다. 이 방법은 단순성과 낮은 유지보수 비용으로 인해 챗봇 및 사용자 활동 모니터링에서 인기가 있다. 그러나 이 접근 방식에는 여러 가지 한계가 있다. 타임스탬프는 시간적 순서는 보존하지만, 의미론적 구조를 제공하지 않아 장거리 의존성을 포착하거나 관련 정보를 효율적으로 검색하기 어렵게 만든다. 상호 작용이 누적됨에 따라 시퀀스가 선형적으로 증가하여 저장 및 추론 모두에서 확장성 문제를 야기한다.
Tagging Context by Functional and Semantic Attributes 이 접근 방식은 각 항목에 "목표(goal)", "결정(decision)", "행동(action)"과 같은 기능적 역할을 명시적으로 태그하여 컨텍스트 정보를 조직함으로써 각 항목을 더 쉽게 해석할 수 있도록 한다. 최근 시스템은 우선순위 수준, 소스 정보 등 다차원에서 태깅을 가능하게 하여 보다 효율적인 검색 및 컨텍스트 관리를 지원한다. 비록 이것이 각 정보 조각의 의미를 명확히 하는 데 도움이 되지만, 다소 엄격할 수 있으며 보다 유연한 추론이나 창의적인 합성을 제한할 수 있다.
Compression with QA Pairs 이 방법은 특히 검색 엔진이나 FAQ 기반 시스템과 같은 애플리케이션에서 검색 효율성을 개선하기 위해 컨텍스트를 명확한 질문-답변 쌍으로 재구성한다. 그러나 이 방식은 원래 아이디어의 흐름을 방해하여, 요약이나 추론과 같이 컨텍스트에 대한 포괄적인 이해가 필요한 작업에는 덜 적합하다.
Compression with Hierarchical Notes 이 방법은 광범위한 개념이 점차 구체적인 하위 요점으로 분기되는 트리형 구조로 정보를 조직한다. 이 구조는 아이디어를 명확하게 제시하는 데 도움이 되지만, 주로 아이디어가 논리적으로 연결되는 방식보다는 정보가 그룹화되는 방식을 반영한다. 인과 관계 또는 증거와 결론과 같은 관계는 종종 표현되지 않는다. 또한, 이 설계는 새로운 통찰력이 나오거나 기존 아이디어가 수정될 때와 같이 시간이 지남에 따라 이해가 어떻게 발전하는지를 포착하지 못한다.
5.2 Multi-Modal Context Processing
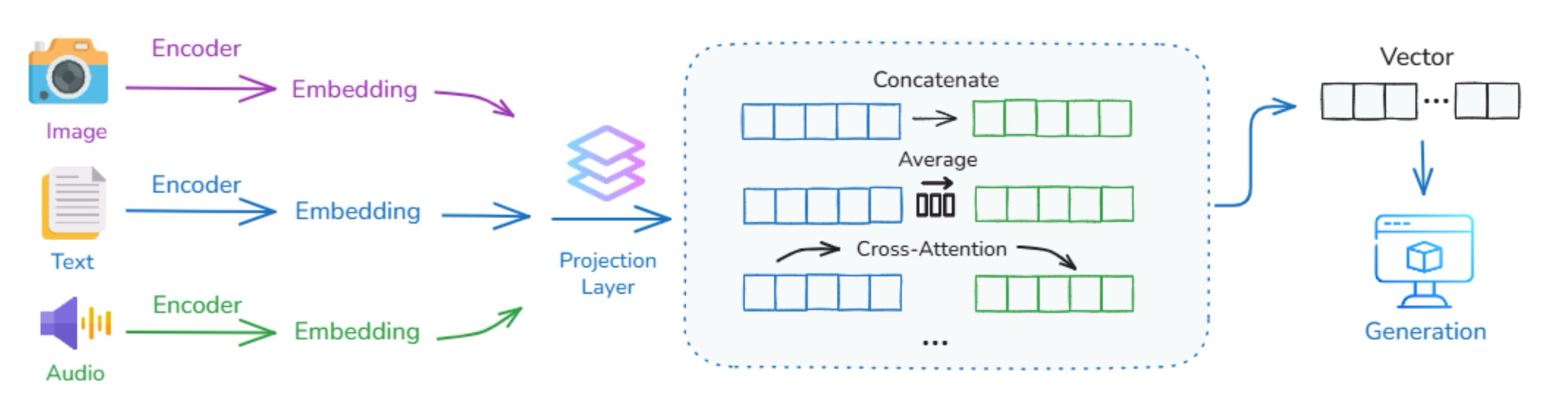
Figure 5: An example workflow for processing multimodal context with hybrid strategies
LLM 기반 시스템의 컨텍스트는 텍스트, 이미지, 오디오, 비디오, 코드, 센서 데이터, 심지어 환경 상태를 포함하는 점점 더 다중 모드가 되고 있다. 기계가 실제 환경이나 시뮬레이션 환경과 상호 작용할 때, 각 양상을 개별적으로 처리하는 대신, 양상 전반의 정보를 일관되고 통합된 표현으로 통합할 수 있어야 한다. 핵심 과제는 이러한 양상의 이질성에 있다. 즉, 구조, 정보 밀도, 시간적 역학이 다르다는 점이다. 예를 들어, 텍스트는 이산적이고 순차적이다. 이미지는 고차원적이고 공간적이다. 오디오는 연속적이며 시간이 지남에 따라 전개된다. 이러한 요소들을 어떻게 공동으로 인코딩하고, 비교하며, 추론할 수 있을까? 2.0 시대에는 몇 가지 일반적인 전략을 식별한다.
Mapping Multimodal Inputs into a Comparable Vector Space 이 방법은 텍스트, 이미지, 비디오와 같은 서로 다른 모달리티의 입력을 공유 벡터 공간으로 변환하여 그 의미를 직접 비교할 수 있도록 한다. 각 모달리티은 먼저 자체 인코더로 처리된다. 이 벡터들은 처음에는 서로 다른 통계적 속성을 가진 개별 표현 공간에 존재하므로, 각각은 고정된 차원의 공유 임베딩 공간으로 매핑하는 학습된 투영 레이어를 통과한다. 이 공간에서 서로 다른 모달리티에서 온 의미론적으로 관련된 콘텐츠는 가깝게 배치되고, 관련 없는 콘텐츠는 멀어지게 된다.
Combining Different Modalities for Self-Attention 공유 임베딩 공간에 투영된 후, 양상별 토큰은 단일 트랜스포머 아키텍처에 의해 공동으로 처리된다. 이 통합된 Self-Attention 메커니즘에서 텍스트 토큰과 시각적 토큰은 모든 레이어에서 서로에게 주의를 기울여, 독립적인 임베딩을 얕게 연결하는 대신 세밀한 교차 모드 정렬 및 추론을 가능하게 한다. 이러한 접근 방식은 최신 Multi-modal LLM에 의해 채택되었으며, 모델이 어떤 구문이 이미지의 어느 영역을 참조하는지와 같은 상세한 대응 관계를 포착할 수 있도록 한다.
Using One Modality to Attend to Another via Cross-Attention 이 방법은 Cross Attention 레이어를 사용하여 한 모달리티(예: 텍스트)이 다른 모달리티(예: 이미지)의 특정 부분에 직접 집중할 수 있도록 한다. 구체적으로, 한 모달리티의 특징은 쿼리로 사용되는 반면, 다른 모달리티의 특징은 Attention 메커니즘에서 키와 값으로 처리된다. 이 설정은 모델이 대상화되고 유연한 방식으로 모달리티 전반에서 관련 정보를 검색할 수 있도록 한다. Cross Attention 메커니즘은 전체 시스템 설계에 따라 메인 트랜스포머 아키텍처 이전에 전용 모듈로 유연하게 구현되거나 트랜스포머 블록 자체 내에 내장될 수 있다. 그러나 전통적인 설계는 일반적으로 어떤 양상이 상호 작용하는지 지정해야 하는 반면, 인간의 뇌는 그러한 고정된 매핑에 의존하지 않고 감각 및 기억 채널 전반에서 정보를 유연하게 통합할 수 있다.
5.3 Context Organization
5.3.1 Layered Architecture
서로 다른 시간 규모에 걸쳐 정보를 효과적으로 관리하는 것은 AI 시스템의 근본적인 과제이다. Andrej Karpathy의 말처럼, LLM은 운영 체제 유추를 통해 볼 수 있다. 즉, 모델은 CPU처럼 작동하고, 컨텍스트 창은 빠르지만 용량이 제한된 작업 기억인 RAM과 유사하다. 운영 체제가 RAM에 로드할 데이터를 결정하는 것처럼, 컨텍스트 엔지니어링은 효과적인 추론을 위해 어떤 정보가 컨텍스트 창에 들어가야 하는지를 결정한다. 시스템에서 했던 것처럼, AI 아키텍처는 시간적 관련성과 중요도에 따라 메모리를 별개의 레이어로 분리함으로써 이점을 얻는다. 이 계층적 접근 방식은 시스템이 최근에 관련 있는 정보에 빠르게 액세스할 수 있도록 유지하는 동시에, 보다 안정적인 장기 저장소에 귀중한 지식을 보존할 수 있도록 한다. 예를 들어, LeadResearcher 시스템은 초장기 컨텍스트 (>200k 토큰)를 처리할 때 연구 계획을 영구 메모리에 저장하여, 컨텍스트 창 제한으로 인해 핵심 정보가 손실되는 것을 방지한다. 핵심 통찰은 서로 다른 유형의 정보에 서로 다른 보존 전략이 필요하다는 것이다. 최근 컨텍스트는 빠른 검색이 필요하지만 빠르게 관련성을 잃을 수 있으며, 중요한 패턴과 학습된 지식은 세션 전반에 걸쳐 지속되어야 한다. 메모리를 계층적으로 조직함으로써 시스템은 응답성과 저장 효율성을 모두 최적화할 수 있다. 여기서 제시하는 프레임워크는 명확성을 위해 2계층 모델에 초점을 맞추지만, 그 원칙은 더 복잡한 아키텍처로 자연스럽게 확장된다. 실제 구현에는 종종 능동적 처리를 위한 작업 기억, 최근 이벤트를 위한 일화적 버퍼, 또는 서로 다른 도메인을 위한 전문화된 캐시와 같은 추가적인 중간 레이어가 포함되며, 각각 고유한 시간적 특성과 선택 기준을 가진다.
Definition 5.1 (Short-term Memory) 단기 메모리는 높은 시간적 관련성을 가지며 처리 함수에 의해 선택되는 컨텍스트의 부분 집합으로 정의된다.
여기서 는 컨텍스트 요소 의 시간적 관련성 가중치 함수이고, 는 단기 메모리를 위한 시간적 관련성 임계값이며, 는 인간의 판단, 발견적 필터링 또는 시스템 수준 작업을 포함할 수 있는 처리함수이다.
Definition 5.2 (Long-term Memory) 장기 메모리는 높은 중요성을 가지며 처리되고 추상화된 컨텍스트의 부분 집합으로 정의된다.
여기서 는 컨텍스트 요소 의 중요성 가중치이고, 은 장기 메모리를 위한 중요성 임계값이며, 은 안정적인 표현을 생성하기 위해 선택, 추상화 및 압축을 결합할 수 있는 복합 함수이다.
Definitino 5.3 (Memory Transfer) 단기 메모리에서 장기 메모리로의 전송은 다음과 같이 정의된다.
이 전송 함수는 단기 메모리에서 자주 액세스되거나 매우 중요한 정보가 처리되어 장기 메모리의 일부가 되는 통합 프로세스를 나타낸다. 이 전송은 반복 빈도, 감정적 중요성 및 기존 지식 구조와의 관련성과 같은 요인에 의해 좌우된다.
5.3.2 Context Isolation
Subagent 서브에이전트는 컨텍스트 제한을 우회하는 동시에 컨텍스트 오염 위험을 줄이는 대안을 제공하며, 기능적 컨텍스트 격리를 통한 효과적인 컨텍스트 관리를 위한 새로운 전략을 대표한다. Claude Code 서브에이전트 시스템은 이 원칙을 잘 보여준다. 각 서브에이전트는 자체적으로 격리된 컨텍스트 창, 사용자 지정 시스템 프롬프트 및 제한된 도구 권한을 가진 전문화된 AI 비서이다. 작업이 서브에이전트의 전문 지식과 일치할 때, 메인 시스템은 해당 단위를 위임할 수 있으며, 이 단위는 대화의 주 컨텍스트를 오염시키지 않고 독립적으로 작동한다. 이 원칙은 기능적 차원(예: 분석, 실행, 검증) 또는 계층적 레이어(예: 계획, 구현, 검토)를 따라 분리를 구현하여 컨텍스트 선택에 적용될 수 있으며, 각 격리된 단위는 특정 책임에 필요한 최소한의 권한만 수신하여 시스템 신뢰성과 해석 가능성을 모두 향상시킨다. RAG와 같은 정적 검색 접근 방식과 달리, LeadResearcher는 먼저 계획을 세운다. 사용 가능한 정보가 불충분하면 추가 검색을 발행하거나, 키워드를 조정하거나, 새로운 하위 작업을 생성할 수 있다. 서브에이전트는 병렬로 작업할 수 있으며, LeadResearcher는 중간 결과를 요약하고 다음 단계를 결정한다. 이러한 피드백 루프는 시스템이 고품질 답변으로 수렴하는 데 도움을 준다.
Lightweight References 컨텍스트 격리는 종종 대규모 정보를 외부에 저장하고 모델의 창에 경량 참조만 노출하는 것에 의존한다. HuggingFace의 CodeAgent에서 사용되는 샌드박스 접근 방식에서는, 부피가 큰 출력은 별도의 샌드박스에 저장되고 필요할 때만 검색된다. 이러한 방식으로 모델은 간결한 참조와만 상호 작용하는 반면, 샌드박스는 전체 데이터를 보관하고 요청 시 제공한다. 유사한 원칙이 스키마 기반 상태 객체에도 적용되며, 파일이나 로그와 같은 무거운 요소는 외부 저장소에 남아 있고 선택된 필드만 표면화된다. 두 접근 방식 모두 토큰 오버헤드를 줄이는 동시에 필요할 때 전체 컨텍스트에 대한 액세스를 유지한다.
5.4 Context Abstraction
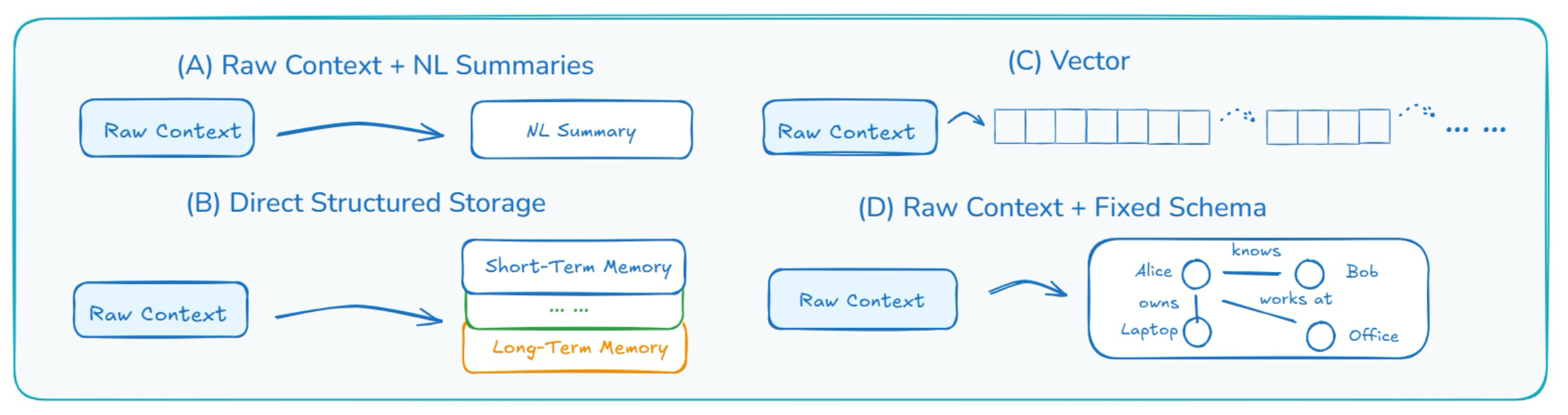
Figure 6: Representative designs for self-baking in Era 2.0
대화 턴, 도구 출력, 검색된 문서와 같은 원시 컨텍스트는 빠르게 누적될 수 있다. 처리되지 않은 상태로 방치되면 증가하는 기록은 시스템을 압도하여 향후 추론이나 의사 결정에 진정으로 중요한 것이 무엇인지 식별하기 어렵게 만들 수 있다. 이를 관리하기 위한 확장 가능한 에이전트의 중요한 능력은 컨텍스트 추상화이다. 이는 원시 컨텍스트를 더 압축되고 구조화된 표현으로 변환하는 것이다. 우리는 이 프로세스를 자기 베이킹(self-baking)이라고 부른다. 즉, 에이전트가 자체 컨텍스트를 영구적인 지식 구조로 선택적으로 소화하는 것이다. 이는 일화적 기억이 의미적 기억을 낳거나, 반복적인 행동이 습관으로 추상화되는 인간의 인지 과정을 반영한다. 궁극적으로, 자기 베이킹은 메모리 저장과 학습을 분리하는 요소이다. 자기 베이킹이 없으면 에이전트는 단순히 회상하지만, 자기 베이킹을 통해 지식을 축적한다.
Using Hierarchical Memory Architectures 현재 시스템은 일반적으로 아키텍처 원칙인 계층적 메모리 조직을 채택한다. 계층적 메모리는 서로 다른 추상화 수준에서 정보를 조직하여 증가하는 컨텍스트를 관리하는 원칙적인 방법을 제공한다. 기본 레이어에는 세부 정보에 액세스할 수 있도록 원시 컨텍스트가 저장된다. 컨텍스트의 볼륨이 증가함에 따라, 이러한 원시 항목은 점진적으로 더 추상적인 표현으로 요약된 다음 다음 레이어로 전달된다. 새로운 정보는 일반적으로 가장 낮은 레이어에 진입하며 점차 위로 "베이킹"되어, 컨텍스트 창을 압도하지 않으면서도 원본 세부 정보로 검색 가능한 링크를 유지하면서 시스템이 확장될 수 있도록 한다. 이러한 의미에서 계층적 메모리는 단기 메모리와 장기 메모리 간의 구분을 보완한다. 즉, 원시 컨텍스트는 일반적으로 낮은 단기 메모리에 상주하는 반면, 더 추상적인 표현은 장기 메모리에 대응하는 경향이 있다.
Add Natural-Language Summaries 이 패턴에서 시스템은 전체 컨텍스트를 원래의 비구조화된 형태로 저장한다. 또한, 지금까지 발생한 일에 대한 압축된 보기를 제공하는 요약을 주기적으로 생성한다. 일반적으로 자연어로 작성된 이 요약은 최근 이벤트에 대한 빠른 개요를 제공하며 수동 또는 자동으로 생성될 수 있다. 예를 들어, 챗봇은 전체 대화 기록을 저장하고 최근 대화를 요약하는 짧은 단락을 생성할 수 있다. 요약 수가 증가함에 따라 시스템은 다단계 요약(오래된 요약을 더 높은 수준의 개요로 요약)을 적용하거나 시간 또는 중요도에 따라 덜 유용한 요약을 삭제하는 특정 전략을 사용할 수 있다. 이러한 요약은 시스템이 핵심 정보에 집중하는 데 도움이 되는 동시에 필요할 경우 전체 세부 정보를 계속 사용할 수 있도록 한다. 이 방법은 간단하고 유연하다. 그러나 요약이 단순한 텍스트이기 때문에 구조가 부족하다. 이로 인해 시스템이 이벤트 간의 연결을 이해하거나 컨텍스트에 대한 더 깊은 추론을 수행하기 어렵게 만든다.
Extract Key Facts Using a Fixed Schema 이 패턴은 구조화된 해석을 추가하여 첫 번째 패턴을 확장한다. 시스템은 원시 컨텍스트를 저장할 뿐만 아니라, 더 쉽게 액세스하고 추론할 수 있도록 미리 정의된 형식으로 핵심 정보를 추출한다. 스키마는 다양한 형태를 취할 수 있다. 예를 들어, 핵심 엔터티(사람, 항목 또는 장소)를 노드로 나타내는 엔터티 맵일 수 있다. 각 노드는 엔터티의 속성(예: 이름, 유형), 현재 상태(예: 위치, 상태) 및 다른 엔터티에 대한 링크(예: "소유", "함께 작업", "위치")를 유지한다. 또는 이벤트를 다양한 측면으로 분류하는 템플릿 역할을 하는 이벤트 기록일 수 있다. 또한 복잡한 목표가 계층적 구조로 하위 작업으로 분류되는 작업 트리일 수도 있다. 구체적인 예로, CodeRabbit은 코드 검토 전에 구조화된 사례 파일을 구축하여, 파일 간 종속성, 과거 PR 정보 및 팀별 규칙을 명시적 스키마로 인코딩함으로써 AI가 격리된 파일 변경이 아닌 전체 시스템 컨텍스트에 대해 추론할 수 있도록 한다. 이 접근 방식은 시스템이 명시적 스키마 내에서 특정 사실을 검색, 분석 및 연결할 수 있도록 하여 원시 요약보다 더 효과적인 추론을 가능하게 한다. 그러나 여러 레이어를 유지 관리하면 불일치가 발생할 수 있으며, 이러한 스키마를 안정적으로 채우기 위한 좋은 추출기를 설계하는 것은 여전히 상당한 과제로 남아 있다.
Progressively Compress Context into Vectors that Capture The Meaning 원시 컨텍스트를 저장하는 것 외에도, 이 접근 방식은 입력의 의미를 반영하는 밀집된 숫자 벡터(임베딩으로 알려져 있음)로 정보를 인코딩한다. 이러한 벡터는 압축 가능하여, 서로 다른 규모에서 컨텍스트를 추상화하는 다단계(계층적) 메모리를 구축할 수 있다. 이 벡터들은 자기 베이킹을 거치는데, 여기서 오래된 임베딩은 주기적으로 압축된 표현으로 요약되거나(일반적으로 풀링을 통해) 기존의 장기 상태와 융합되어 점진적으로 더 추상적이고 안정적인 의미 기억을 형성하기 위해 재인코딩된다. 이 방법은 간결하고 유연하며, 특히 의미 검색이나 유사한 쿼리 일치에 유용하다. 그러나 결과 표현은 사람이 읽을 수 없으므로 메모리의 특정 부분을 편집하거나 검사하기 어렵다.
6. Context Usage
6.1 Intra-System Context Sharing
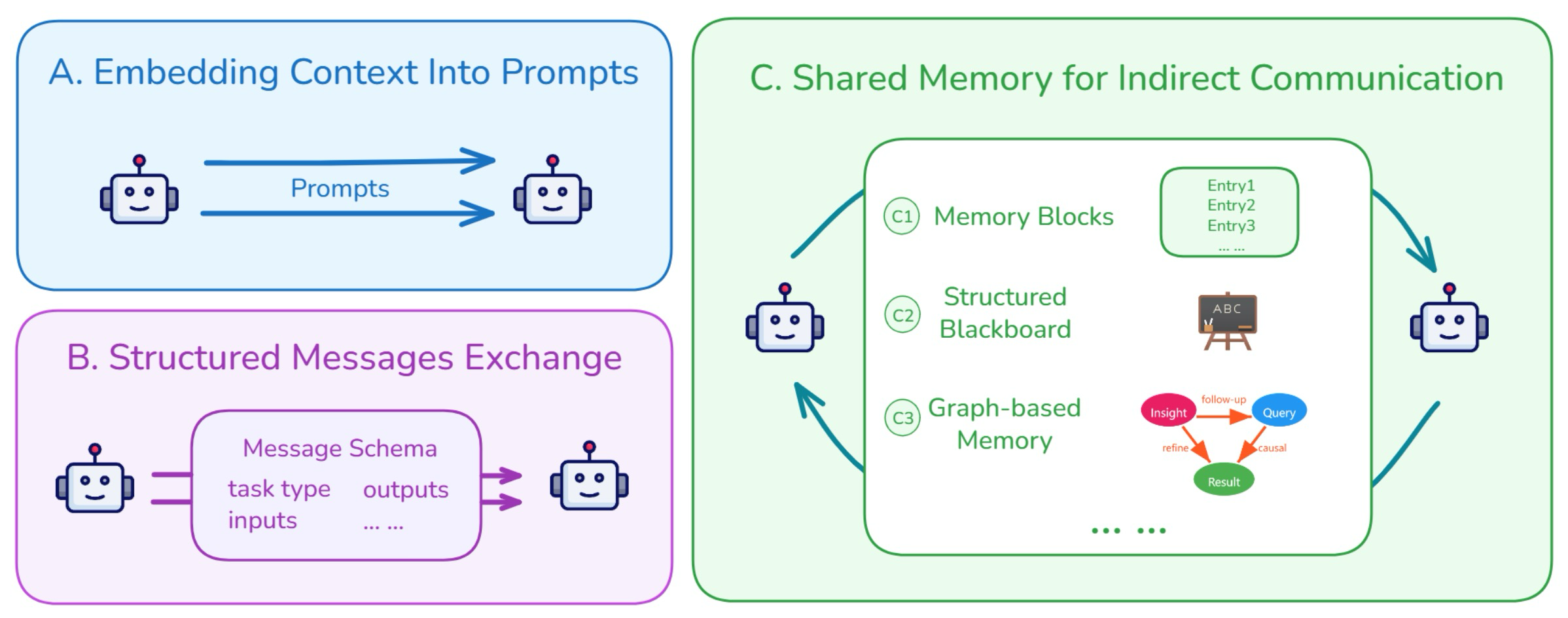
Figure 7: Common patterns of cross-agent context sharing
현대 LLM 애플리케이션은 종종 다수의 에이전트로 구성되며, 각 에이전트는 더 큰 추론 작업 흐름의 일부를 담당한다. 다중 에이전트 시스템이 작동하는 실질적인 이유는 단일 에이전트가 처리할 수 있는 것보다 더 많은 토큰을 시스템이 소비할 수 있게 하여, 전체 프로세스의 용량을 효과적으로 확장하기 때문이다. 이러한 시스템에서 중요한 과제가 발생한다: 이 에이전트들이 어떻게 컨텍스트를 공유하여 일관성 있고 협력적인 행동을 달성할 수 있을까? 단일 에이전트 프롬프팅과 달리, 다중 에이전트 시스템은 에이전트 간에 정보를 전달하기 위한 명확하고 구조화된 방법을 필요로 한다. 한 에이전트가 부분적인 답변이나 중간 결과를 생성하면, 다음 에이전트가 이를 이해하고 사용해야 한다. 이를 지원하기 위해, 공유되는 정보는 정확하고, 해석하기 쉬우며, 다음 단계에 직접 사용 가능해야 한다. 우리는 에이전트 간 컨텍스트 공유의 몇 가지 일반적인 패턴을 식별한다.
Embedding Previous Context into Prompts 이 방법은 다음 에이전트의 입력 프롬프트에 이전 컨텍스트를 직접 포함하여 정보를 전달한다. 종종 정보는 더 명확하도록 재구성된다. 예를 들어, 한 에이전트가 자신의 사고 과정을 일반 텍스트로 요약하면, 다음 에이전트가 이를 읽고 작업을 계속한다. 이러한 컨텍스트 전달 방식은 프롬프트를 통신 채널로 사용하여 에이전트가 순차적으로 작업하는 AutoGPT (Team, 2025c)와 ChatDev (Liu and Kumar, 2025; Qian et al., 2024)와 같은 시스템에서 흔히 사용된다.
Exchanging Structured Messages between Agents 에이전트들은 고정된 형식을 사용하여 구조화된 메시지를 교환함으로써 통신한다. 이 메시지들은 일반적으로 작업 유형, 입력 데이터, 출력 결과 및 추론 단계와 같은 필드를 가진 미리 정의된 스키마를 따른다. 수신 에이전트는 이 메시지를 읽고 작업을 계속한다. Letta (Team, 2024)와 MemOS (Han et al., 2025)와 같은 시스템은 에이전트 간에 정보를 전달할 때 명확성과 일관성을 유지하기 위해 이 접근 방식을 사용한다.
Using Shared Memory for Indirect Communication 에이전트들은 공유 메모리 공간에 읽고 쓰는 방식으로 간접적으로 통신하는 경우가 많으며, 이는 중앙 집중식 외부 저장소 또는 개별 에이전트 메모리 내의 공용 영역으로 구현될 수 있다. 메시지를 직접 보내는 대신, 에이전트들은 이 공유 공간(종종 메모리 블록으로 조직됨)에 정보를 남기고, 나중에 업데이트를 받기 위해 이를 확인한다. 각 블록은 하나의 컨텍스트 단위를 저장할 수 있으며, 일반적으로 누가 추가했는지, 언제, 어떤 유형의 데이터를 포함하는지와 같은 기본 메타데이터로 레이블이 지정된다. MemGPT (Team, 2024) 및 A-MEM (Chen et al., 2024a)과 같은 시스템은 에이전트 간의 간접 통신 및 조정을 지원하기 위해 이 접근 방식을 채택한다. 또 다른 방법은 메모리를 더 구조화하는 것이다. 원시 데이터를 일반 풀에 배치하는 대신, 정보는 주제, 작업 또는 목표를 기반으로 세그먼트로 조직된 공유 "블랙보드"에 기록된다. 각 에이전트는 자신의 전문 분야와 관련된 세그먼트만 모니터링하고 그에 따라 항목을 추가하거나 수정한다. 이 모듈식 구조는 혼란을 줄이는 동시에 에이전트가 비동기적으로 협력할 수 있도록 한다. 메모리는 그래프로도 조직될 수 있다. 예를 들어, Task Memory Engine (TME) (Ye, 2025)는 에이전트의 추론 프로세스를 작업 그래프로 나타낸다. 각 노드는 입력, 출력 및 실행 상태를 포함한 단일 단계를 인코딩하며, 엣지는 단계 간의 종속성을 포착한다. 이러한 구조는 에이전트가 다단계 추론을 신뢰할 수 있고 해석 가능한 방식으로 추적, 재사용 및 재개할 수 있도록 한다. 유사하게, G-Memory (Zhang et al., 2025)는 메모리를 의미 그래프로 모델링하는데, 여기서 노드는 통찰력, 사용자 쿼리 및 중간 결과를 나타내고, 엣지는 후속 조치, 정제 또는 인과 관계와 같은 관계를 반영한다. 이러한 그래프 구조화된 메모리는 더 풍부한 컨텍스트 표현과 다단계 또는 다중 작업 전반에서 더 효과적인 추론을 가능하게 한다.
6.2 Cross-System Context Sharing
다중 에이전트 환경의 컨텍스트에서, 시스템은 작업을 수행하기 위해 자체 컨텍스트 또는 상태를 유지하는 모든 독립적인 플랫폼, 모델 또는 애플리케이션으로 이해될 수 있다. 서로 다른 시스템은 규모와 기능이 다를 수 있지만, 각각은 자체 경계 내에서 정보를 관리한다. 시스템 간에 컨텍스트를 공유하면 이러한 개별 엔터티가 관련 정보에 액세스하거나 교환할 수 있어 더 나은 조정 또는 추론이 가능해진다. 예를 들어, Cursor와 ChatGPT 간의 컨텍스트 공유는 이러한 종류의 시스템 간 상호 작용을 보여준다. 컨텍스트가 단일 시스템 내에서 공유될 때, 구성 요소들이 상호 운용되도록 설계되었기 때문에 일반적으로 더 쉽다. 그러나 서로 다른 시스템 간에 컨텍스트를 공유할 때, 각 시스템은 자체 형식, 구조 및 논리를 사용할 수 있으며, 과제는 공유된 컨텍스트를 경계 전반에서 해석 가능하게 만드는 것이다. 이 과제를 해결하기 위한 일반적인 접근 방식은 다음과 같다:
Use Adapters to Convert Context 각 시스템은 자체 형식을 계속 사용하고, 컨텍스트를 다른 시스템이 읽을 수 있는 것으로 변환하는 변환기(어댑터)를 추가한다. 이는 시스템에 더 많은 자유를 제공하지만, 연결마다 별도의 어댑터를 구축해야 함을 의미한다.
Using a Shared Representation Across Systems 모든 시스템이 처음부터 동일한 표현을 사용하기로 동의하여, 각 시스템이 직접 읽고 쓸 수 있도록 보장한다. 이는 모든 시스템 쌍 간의 번역 필요성을 피하고 통합을 훨씬 간단하게 만든다. 공유 표현은 다음과 같은 다양한 형태를 취할 수 있다:
Using a Shared Data Format such as JSON or an API 시스템들은 공유 JSON 스키마 또는 잘 정의된 API와 같이 컨텍스트에 대한 고정된 형식에 합의할 수 있다. 이를 통해 각 시스템은 일관된 방식으로 컨텍스트를 읽고 쓸 수 있으며, 사용자 지정 번역 로직의 필요성을 피할 수 있다.
Sharing Context via Human-Readable Summaries 공식적인 데이터 구조에 의존하는 대신, 시스템들은 자연어의 짧은 설명을 교환할 수 있다. 이 요약들은 인간이 이해하기 쉽고, 필요할 때 언어 모델에 의해서도 해석될 수 있다.
Representing Context as Semantic Vectors 컨텍스트는 정보의 의미를 포착하는 숫자 벡터로도 표현될 수 있다. 이 방법은 유연하고 시스템 독립적이지만, 올바르게 해석하기 위해 종종 기계 학습 모델을 필요로 한다.
각 방법에는 절충점(trade-offs)이 있다. 표준 스키마는 정확성을 제공하지만, 엄격한 조정을 필요로 한다. 자연어는 유연하고 생성하기 쉽지만, 안정적으로 구문 분석하기는 더 어렵다. 의미 벡터는 간결하고 일반화 가능하지만, 해석 가능성이 낮다.
6.3 Context Selection for Understanding
컨텍스트 창이 확장되었음에도 불구하고, LLM은 여전히 조건으로 삼을 수 있는 입력 토큰의 품질에 의해 병목 현상을 겪는다. 따라서 사용 가능한 컨텍스트 중 어떤 하위 집합을 현재 단계에 대해 선택해야 하는지가 중요한 질문으로 제기된다. 관련 없거나 노이즈가 많은 메모리 조각은 추론을 방해하거나 추론 비용을 증가시킬 수 있다. 경험적으로, 컨텍스트 창이 약 50%를 초과하여 채워지면 AI 코딩 성능이 종종 감소하는데, 이는 과도한 컨텍스트와 불충분한 컨텍스트 모두 효율성을 저하시킬 수 있음을 시사한다. 효과적인 컨텍스트 선택은 attention before attention 형태가 된다. 즉, 주의를 기울일 가치가 있는 것을 선택하는 것이다. LLM-powered 에이전트의 부상으로 인해, 컨텍스트 엔지니어링 2.0 시대는 동적이고 목표 지향적인 상호 작용으로 전환되었으며, 컨텍스트 필터링은 사용자의 현재 의도와 가장 관련성이 높은 정보를 동적으로 선택하는 적응형 프로세스가 되었다. 메모리 선택 시 고려해야 할 몇 가지 요소는 다음과 같다:
Semantic Relevance 이는 현재 쿼리 또는 목표와 의미가 가장 유사한 메모리 항목을 선택하는 것을 의미하며, 일반적으로 벡터 기반 검색을 통해 구현된다. 이 접근 방식은 RAG 파이프라인과 Letta와 같은 시스템에서 흔히 사용된다.
Logical Dependency 이는 현재 작업이 이전 단계에서 생성된 정보(예: 이전 계획 결정, 도구의 출력)에 직접 의존하는 경우를 의미한다. MEM1과 같은 시스템은 실행 중에 추론 추적을 명시적으로 기록하여, 메모리 항목 전반에 걸쳐 구조화된 종속성 그래프를 형성하고, 이를 탐색하여 작업의 논리적 흐름에 있는 컨텍스트만 검색한다.
Recency and Frequency 최근에 사용되었거나 자주 액세스된 항목이 다시 검색될 가능성이 더 높다는 발견적 방법에 기반한다. 시스템은 일반적으로 최신 메모리 항목에 더 높은 우선순위를 할당하고, 반복적으로 액세스되는 항목은 더 높은 중요도를 축적한다.
Overlapping Information 여러 정보 조각이 동일한 의미를 전달하는 경우, 더 오래되거나 덜 상세한 정보는 필터링될 수 있다. 현대 시스템에서는 이 프로세스가 능동적인 메모리 관리를 통해 중복 항목을 병합, 업데이트 또는 제거할 시기를 능동적으로 결정한다.
User Preference and Feedback 시간이 지남에 따라 AI 에이전트는 사용자가 중요하게 여기는 정보 유형을 학습하여 습관에 적응할 수 있다. 자체 진화 메모리와 같은 일부 시스템 (Jin et al., 2024; Zhao and Kim, 2025)은 사용자가 정보와 상호 작용하는 방식을 추적하고 이를 사용하여 메모리 항목의 중요도나 가중치를 조정한다.
메모리 선택시 적절성이 주된 고려 사항이다. 이는 다음과 같은 여러 요소로 평가될 수 있다: 의미적 유사성, 논리적 의존성, 최신성, 언급빈도. 예를 들어, 많은 시스템은 유사성 점수를 사용하여 현재 입력 내용을 저장된 콘텐츠와 비교하고, 유사성이 더 높은 정보에 더 높은 적절성을 부여한다. 또는 명시적인 태그나 메타데이터를 통합하여 특정 데이터의 중요성이나 기능을 표시하거나 핵심 사실을 나타낼 수 있다. 적절성 외에도, 중복되는 정보를 최소화하고 사용자 습관에 적응하는 것이 중요하다. 이러한 기준들을 통합함으로써, 시스템은 가장 관련성 높은 데이터를 유지하고, 불필요한 노이즈를 줄이며, 컨텍스트 선택의 효율성을 높일 수 있다.
이러한 요소를 고려하여 시스템은 다양한 필터링 전략을 채택한다. RAG 파이프라인에서, 소스를 관리 가능한 덩어리(chunks)로 분할한다. 이는 AST 기반 분할과 같이 의미적 일관성을 보존하는 구조화된 접근 방식으로 수행될 수 있다. 의미론적 검색은 임베딩 기반 검색을 사용하고 (Chen and Xu, 2024), 비의미론적 검색은 문자열 일치를 사용하는 Grep처럼 직접적일 수 있으며, 구조화된 검색은 지식 그래프를 활용한다. 이러한 방법들은 종종 중복되거나 노이즈가 많은 후보를 반환하기 때문에, 많은 시스템은 정확성 향상과 효율성 간의 절충을 하면서 관련성을 정제하기 위해 재순위 지정 단계(때로는 LLM에 의해 구동됨)를 도입한다.
6.4 Proactive User Need Inference
컨텍스트의 대부분의 현재 사용은 반응적이지만, 컨텍스트 엔지니어링은 에이전트가 능동적으로 행동할 수 있도록 해야 한다. 즉, 명시적으로 언급되지 않은 잠재적인 사용자 필요, 선호도 및 목표를 추론하고, 그에 따라 도움이 되는 상호 작용을 시작하는 것이다. 2.0 시대에는 능동적인 선호도 채굴의 몇 가지 일반적인 형태를 식별한다:
Learning and Adapting to User Preferences 현대 AI 에이전트는 주로 대화 기록과 저장된 개인 데이터를 분석하여 통신 스타일, 관심사 및 의사 결정 접근 방식의 패턴을 식별함으로써 사용자 선호도를 학습하고 적응한다. 이들은 또한 사용자 반응 및 완료된 작업에 대한 만족도와 같은 간접적인 신호를 관찰하여 학습한다.
Inferring Hidden Goals from Related Questions 시스템은 사용자 쿼리의 순서를 분석하여 숨겨진 목표를 추론할 수 있다. 시스템은 현재 컨텍스트를 인코딩하고 이를 LLM에 입력하여 사용자의 잠재적 필요를 예측할 수 있으며 (Anthropic, 2025a), 사고의 연쇄 추론 기법을 통해 깊은 의도를 추론할 수 있다.
Proactively Offering Help Based on User Stuggles 시스템은 사용자가 망설이거나 여러 대안을 시도하는 것과 같이 어려움을 겪고 있을 때를 감지하고, 시각화 또는 체크리스트와 같은 유용한 도구를 능동적으로 제공한다.
6.5 Lifelong Context Preservation and Update
개인은 근본적으로 다른 개체와의 상호 작용, 즉 자신의 컨텍스트에 의해 형성된다. 이러한 변화를 고려할 때, 핵심적인 과제가 자연스럽게 발생한다: 컨텍스트가 평생의 형태를 띠게 되었을 때, 인간과 기계 모두에게 일관성 있고, 적응적이며, 사용 가능한 방식으로 어떻게 보존하고 업데이트해야 할까? 평생 컨텍스트의 지속적인 보존 및 업데이트는 확장 가능한 저장 이상의 것을 요구한다. 이는 동적이고, 의미론적으로 강력하며, 시간적으로 인식하는 메모리 시스템의 설계가 필요하다. 이는 복잡한 기술적 과제를 제기하며, 현재 메모리 아키텍처의 단순한 확장은 실제 컨텍스트의 규모, 유동성 및 복잡성 앞에서 무너진다. 스토리라인은 다음과 같다: "정상적인" 컨텍스트 엔지니어링이 평생 컨텍스트 엔지니어링이 될 때, 문제가 발생한다. 의미론적 일관성을 유지하는 신뢰할 수 있는 저장 메커니즘을 어떻게 구현할까? 게다가, 단순한 저장만으로는 충분하지 않다. 데이터가 대규모로 확장됨에 따라, 시스템은 이 정보를 정확하게 처리하고 관리할 수 있어야 한다. 새로운 설계가 제안되면, 정확성과 성능을 모두 검증하기 위한 종단 간(end-to-end) 평가 프레임워크가 필수적이다. 그러나 이러한 메커니즘은 여전히 대부분 미개발 상태이다. 완전한 파이프라인이 구축되면, 안정성을 유지하는 것이 가장 중요해진다. 이 워크플로우 내의 각 단계는 특히 평생 컨텍스트 시스템 영역에서 뚜렷한 과제를 제시한다.
Challenge : Storage Bottlenecks 첫 번째 과제는 엄격한 리소스 제약 하에서 가능한 한 많은 관련 컨텍스트를 유지하는 방법이다. 우리는 현재 통일된 해결책이 부족하다. 가능한 한 많은 컨텍스트를 보존하고, 나의 모든 컨텍스트가 손실 없이 효과적으로 유지되도록 보장하려면 어떻게 해야 할까? 어떤 종류의 인프라나 인터페이스가 우리의 컨텍스트를 최대한 기록하는 것을 용이하게 할까? 그리고 저장 시스템이 대규모에서 고압축, 고정밀 검색 및 저지연 액세스를 동시에 지원할 수 있을까?
Challenge : Processing Degradation 또 다른 과제는 대규모에서 Attention 메커니즘의 붕괴에서 발생한다. 대부분의 트랜스포머 기반 모델은 전역 주의(global attention)에 의존하며, 그 복잡성은 추론 지연 시간의 급격한 증가, 높은 GPU 메모리 사용량 및 느린 I/O 처리량으로 이어진다. 이러한 리소스 병목 현상은 대규모 컨텍스트를 실시간으로 처리하는 것을 비실용적으로 만든다. 한편, 추론의 품질이 저하된다. 더 긴 입력에서 Attention이 얇아짐에 따라, 모델은 관련 정보에 대한 집중을 유지하는 데 어려움을 겪고, 장거리 종속성을 포착하는 데 어려움을 겪는다. 또한, 검색 시스템은 의미론적으로 유사하지만 관련 없는 많은 정보 조각에 압도되어, 종종 유용한 증거 대신 방해 요소를 반환한다. 게다가, 컨텍스트의 볼륨이 증가함에 따라, 검색된 세그먼트 간의 불일치와 충돌을 감지하고 조정하기가 더 어려워진다. 이 모든 문제는 매우 큰 컨텍스트를 다룰 때 취약한 추론으로 이어진다.
Challenge : System Instability 메모리가 시간이 지남에 따라 축적됨에 따라, 작은 실수라도 시스템의 더 많은 부분에 영향을 미칠 수 있다. 한때 영향이 제한적이었던 오류는 이제 광범위하게 퍼져 예상치 못한 또는 불안정한 동작으로 이어질 수 있다. 명확한 경계나 유효성 검사 메커니즘이 없으면, 특히 장기간 실행되거나 높은 안전성이 요구되는 작업에서 시스템 관리가 더 어려워진다. 이러한 경우, 이는 신뢰성을 높이는 대신 시스템을 더 취약하게 만들 수 있다.
Challenge : Difficulty of Evaluation 메모리가 축적됨에 따라, 시스템이 올바르게 추론하고 있는지 판단하기가 더 어려워진다. 오늘날 대부분의 벤치마크는 시스템이 정보를 검색할 수 있는지 여부만 테스트할 뿐, 정보가 여전히 관련성이 있는지, 정확한지, 또는 유용한지 여부를 확인하지 않는다. 시스템은 모순을 확인하거나, 잘못된 업데이트를 취소하거나, 결론으로 이어진 추론 단계를 추적하는 기능을 거의 포함하지 않는다. 이러한 가시성 부족은 특히 평생 컨텍스트 엔지니어링에서 시스템을 신뢰하거나 개선하기 어렵게 만든다.
Toward a Semantic Operating System for Context Lifelong Context Engineering의 과제는 더 이상 단순히 "컨텍스트 창을 확장"하거나 "검색 정확도를 개선"하는 것만으로는 해결될 수 없다. 이는 인간의 마음처럼 시간이 지남에 따라 성장할 수 있는 의미론적 운영 체제(semantic operating system)의 구축을 요구한다. 한편으로, 이러한 시스템은 자체 메모리 뱅크로서 대규모의 효율적인 의미론적 저장을 지원해야 하며, 지식을 능동적으로 추가, 수정 및 망각하는 진정한 인간과 유사한 메모리 관리 능력을 보여야 한다. 다른 한편으로, 이는 트랜스포머의 평면적인 시간적 모델링을 대체할 새로운 아키텍처를 요구하며, 이를 통해 더 강력한 장거리 컨텍스트 추론 및 동적 적응을 가능하게 한다. 결정적으로, 시스템은 추론 체인의 각 단계를 추적, 수정 및 해석함으로써 스스로를 설명할 수 있어야 하며, 따라서 실용적 및 안전 필수 시나리오에서 신뢰와 신뢰성을 향상시킬 수 있다. 이 접근 방식은 컨텍스트 엔지니어링의 근본적인 원칙을 강조하며 패러다임 전환을 반영한다: 컨텍스트는 더 이상 수동적으로 축적되지 않고, 인지(cognition)를 위한 핵심 요소로서 능동적으로 관리되고 진화한다.
6.6 Emerging Engineering Practices
KV Caching 새로운 엔지니어링 관행 하에서, 키-값(KV) 캐싱의 사용은 에이전트의 효율적인 배포에 핵심적이 되었다. KV 캐싱은 과거 토큰의 주의 상태(키와 값)를 저장하여 새로운 토큰이 생성될 때 다시 계산할 필요가 없도록 작동한다. 캐시 적중률은 대기 시간과 비용 모두에 강력하게 영향을 미친다. 적중률을 개선하기 위해 몇 가지 관행이 필수적이다: 첫째, 접두사 프롬프트를 안정적으로 유지해야 한다. 왜냐하면 시스템 프롬프트 시작 부분의 타임스탬프와 같은 사소한 변형조차도 전체 캐시를 무효화할 수 있기 때문이다. 둘째, 추가 전용(append-only) 및 결정론적 업데이트를 시행해야 한다. 왜냐하면 과거 콘텐츠를 변경하거나 일관성 없이 직렬화하면 재사용이 깨지기 때문이다. 셋째, 서빙 프레임워크가 auto-incremental prefix 캐싱을 지원하지 않는 경우, 캐시 체크포인트를 수동으로 삽입하고 신중하게 배치하는 것이 필요하다. 또한, 캐시 워밍업을 위해 예측 로딩이 자주 사용된다. 이는 시스템이 다음에 필요할 가능성이 있는 컨텍스트를 예상하여 사전에 캐시에 로드하는 방식이다. 이러한 기술들은 효율성이 컨텍스트가 관리되는 방식에 의해 점점 더 많이 결정되고 있음을 보여준다.
Tool Designing 도구 설계에서 중요한 요소는 설명과 규모이다. Description에서, 도구는 정확한 목적과 명확한 정의가 필요하다. 모호하거나 중복되는 설명은 종종 실패를 유발하는 반면, 잘 구조화된 설명은 모호성을 줄이고 신뢰성을 향상시킨다. 모델은 이러한 설명을 스스로 다듬을 수도 있으며(프롬프트 엔지니어로 작용), 이는 자기 개선을 가능하게 한다. Scale에서, 대규모 도구 세트는 에이전트의 신뢰성을 떨어뜨린다. 상호 작용 중에 도구를 동적으로 로드하면 종종 KV-캐시 일관성을 깨고 이전 행동에 대한 참조를 혼란스럽게 한다. 경험적 관찰에 따르면, 과도하게 큰 도구 세트는 성능을 저하시킬 수 있다. 왜냐하면 중복되는 도구 설명과 증가된 선택 복잡성으로 인해 올바른 도구를 선택하는 것이 더 어려워지기 때문이다. DeepSeek-v3의 경우, 30개 이상의 도구에서 성능이 저하되었고 100개를 초과하면 거의 실패가 보장되었다. 도구 목록을 안정적으로 유지하고 디코딩 수준에서 제약 조건을 시행하는 것(예: 유효하지 않은 선택을 차단하기 위해 토큰 로짓을 마스킹하는 것)이 더 강력한 접근 방식이다. 이 관행은 액션 공간을 변경함으로써 발생하는 오류를 줄이는 동시에 효율성을 유지한다.
Context Contents 에이전트는 자신의 실수를 숨겨서는 안 된다. 컨텍스트에 오류를 유지하면 모델이 자신의 실패를 관찰할 수 있으며, 이는 교정 행동을 학습하고 전반적인 성능을 개선하는 데 중요하다. 에이전트 환경에서 전통적인 퓨샷 프롬프팅은 역효과를 낼 수 있다. 컨텍스트에 주로 유사한 과거 행동-관찰 쌍이 포함될 경우, 모델은 자신이 보는 패턴을 단순히 따라가며 이전 행동을 반복하는 경향이 있다 (과잉 일반화). 이를 완화하기 위해, 행동 및 관찰에 작은, 구조화된 변형을 도입한다. 예를 들어, 대체 직렬화 템플릿, 다양한 문구, 순서 및 형식의 미묘한 변화 등이 있다. 이러한 통제된 교란은 반복적인 패턴을 깨고 모델의 주의를 재조정하여 견고성을 개선하고 과잉 일반화의 위험을 줄이는 데 도움이 된다.
Multi-agent Systems Claude의 경험에 따르면, 효과적인 다중 에이전트 작업은 몇 가지 반복적인 관행에 달려 있다. 리드 에이전트나 리드 연구원은 쿼리를 하위 작업으로 나누고, 명확한 목표, 출력, 도구 지침 및 경계를 부여하여 할당해야 한다. 왜냐하면 모호한 지침은 혼란이나 격차로 이어지기 때문이다. 에이전트들이 작업 부하를 판단하는 데 어려움을 겪기 때문에, 프롬프트에는 쿼리 복잡도와 관련된 간단한 조정 규칙을 포함할 수 있다. 검색 전략은 광범위한 탐색에서 집중적인 분석으로 이동할 때 가장 잘 작동한다. 에이전트가 자신의 추론 과정을 명시적으로 기록하는 확장된 사고 모드는 전반적인 정확성과 효율성을 향상시킨다.
Tricks 복잡한 작업을 실행할 때, 많은 시스템은 하위 목표를 나열하는 todo.md 파일을 유지하고, 작업이 진행됨에 따라 이를 업데이트하고 완료된 항목을 표시한다. 그러나 모델은 장기 작업에서 이전 목표를 놓칠 수 있다. 실용적인 해결책은 todo 목록을 업데이트할 때 이러한 목표들을 자연어로 암송하여, 핵심 목표를 모델의 즉각적인 주의 내에 유지하도록 최근 컨텍스트에 통합하는 것이다.
7. Applications
7.1 CLI
AI 에이전트를 사용할 때, 개발자들은 종종 지속적인, 프로젝트 지향적 컨텍스트 지원을 필요로 한다. Google의 Gemini CLI는 컨텍스트가 어떻게 엔지니어링될 수 있는지 보여주는 대표적인 사례를 제공한다. 핵심 메커니즘은 프로젝트 배경, 역할 정의, 필요한 도구 및 종속성, 코딩 규칙 등을 기록하는 마크다운 사양인 GEMINI.md 파일이다. 컨텍스트는 파일 시스템 계층 구조를 통해 조직된다. GEMINI.md 파일은 사용자 홈 디렉터리, 프로젝트 루트, 또는 하위 디렉터리 내에 존재할 수 있으며, 이는 정보의 상속 및 격리를 모두 가능하게 한다. 수집의 경우, CLI는 두 가지 유형의 컨텍스트를 수집한다. 시작 시, 시스템 프롬프트, 현재 프로젝트 환경, 그리고 상위 또는 하위 GEMINI.md 파일과 같은 정적 정보를 자동으로 로드한다. 상호 작용 중에는 진행 중인 대화 기록으로부터 동적 컨텍스트를 점진적으로 축적한다. 관리의 경우, 파일 시스템 자체가 경량 데이터베이스 역할을 하며, 긴 상호 작용 기록을 AI가 생성한 요약으로 대체하여 컨텍스트를 압축하는 메커니즘을 갖추고 있다. 이러한 요약은 대화의 핵심 측면(예: 전체 목표, 핵심 지식, 파일 시스템 상태, 최근 행동, 현재 계획)을 보존하는 미리 정의된 형식을 따르며, 일관성을 보장한다. 커뮤니티 논의에서는 컨텍스트의 협업적 관리를 지원하기 위해 인간의 정제를 통해 이 프로세스를 확장할 것도 제안했다.
7.2 Deep Research
심층 연구 에이전트들은 여러 사건과 얽힌 관계를 포함하는 추론 작업과 같이, 지식 집약적인 개방형 질문을 해결하는 데 사용자들을 돕는 것을 목표로 한다. 대표적인 예시로는 Tongyi DeepResearch가 있으며, 이는 네 가지 주요 단계로 작동한다: (1) 사용자의 질문에 기반하여 웹을 검색한다. (2) 관련 웹페이지에서 핵심 정보를 추출한다. (3) 추가 검색을 안내하기 위해 새로운 하위 질문을 생성한다. (4) 마지막으로, 여러 출처에서 얻은 증거를 통합하여 일관성 있는 답변을 생성한다. 이러한 순환 과정은 불확실성이 감소하고 완전한 증거 사슬이 형성될 때까지 종종 여러 차례 반복된다. 단기 대화 에이전트와 달리, 심층 연구는 극도로 긴 상호 작용 기록이라는 도전에 직면한다. 모든 관찰, 사고 과정 및 행동을 컨텍스트 창에 직접 추가하는 방식은 빠르게 컨텍스트 창의 한도를 초과하게 된다. 이러한 한계를 극복하기 위해, Tongyi DeepResearch는 체계적인 컨텍스트 엔지니어링을 채택한다. 탐색 과정 동안, 에이전트는 주기적으로 전문화된 요약 모델을 호출하여 누적된 기록을 압축된 추론 상태로 만든다. 이 압축된 상태는 중요한 증거를 보존할 뿐만 아니라 누락된 정보와 다음 단계 방향을 강조한다. 이후의 검색 및 추론은 전체 원시 기록 대신 이러한 압축된 "컨텍스트 스냅샷"에 기반하여 수행된다. 이러한 방식으로, 시스템은 수집 및 축적, 주기적인 압축 및 추상화, 그리고 요약을 기반으로 한 추론 및 재사용에 이르는 명확한 컨텍스트 수명 주기를 확립하며, 컨텍스트 제약을 돌파하고 확장 가능하고 장기적인 연구 능력을 달성할 수 있도록 한다.
7.3 Brain-Computer Interfaces
뇌-컴퓨터 인터페이스(BCI)는 더 진보된 컨텍스트 수집을 가능하게 함으로써 컨텍스트 엔지니어링을 위한 새로운 경로를 제공한다. BCI는 언어 입력에 의존하는 전통적인 방법과 달리 신경 신호를 직접 포착할 수 있으며, 이는 두 가지 뚜렷한 이점을 가져온다. 더 풍부한 컨텍스트 차원 수집: BCI는 주의 수준, 감정 상태, 인지 부하와 같은 외부 행동만으로는 관찰하기 어려운 요소를 수집할 수 있다. 더 편리한 컨텍스트 수집: BCI는 명시적인 사용자 행동의 필요성을 줄여, 신경 활동을 통해 더 즉각적인 입력을 가능하게 하여 컨텍스트 수집의 편리성을 높인다. BCI는 컨텍스트 엔지니어링이 외부 환경을 넘어 사용자의 내부 인지 상태로 확장될 수 있는 방향을 제시한다. 비록 현재 기술은 뇌 신호에 대한 대략적인 이해만을 제공하고, 노이즈와 불안정성과 같은 문제가 여전히 중요한 과제로 남아 있지만, BCI는 텍스트 기반 입력의 내재적인 한계를 극복할 수 있는 더 풍부한 형태의 컨텍스트 수집이 궁극적으로 나타날 수 있음을 시사한다.
8. Challenges and Future Directions
비록 우리가 컨텍스트 엔지니어링의 역사적, 개념적 틀을 제시했지만, 여전히 많은 해결되지 않은 과제들이 남아 있다. 아래에서는 몇 가지 핵심적인 문제들을 강조하고 향후 탐색을 위한 가능한 방향들을 간략하게 설명한다.
Context collection remains limited and inefficient 대부분의 현재 에이전트 시스템은 컨텍스트를 얻기 위해 여전히 명시적인 사용자 입력에 의존하는데, 이는 번거롭고 비효율적이다. 게다가, 사용자들은 때때로 자신의 의도를 명확하게 표현할 수 없어서, 중요한 컨텍스트 정보가 충분히 명시되지 않은 상태로 남는다. 발전은 더 자연스럽고 다중 모드적인 컨텍스트 수집 방법과 더불어, 사용자 요구를 더 잘 추론하고 누락된 컨텍스트를 채울 수 있는 모델을 요구한다. 유망한 연구 분야 중 하나는 뇌-컴퓨터 인터페이스(BCI)인데, 이는 명시적인 표현보다 더 효율적으로 사용자 상태와 의도를 수집하는 것을 목표로 한다. 이러한 발전은 더 풍부한 형태의 컨텍스트 수집이 궁극적으로 텍스트 기반 입력의 고유한 한계를 극복할 수 있음을 시사한다.
Storage and management of large-scale context 상호 작용이 축적됨에 따라, 컨텍스트의 크기와 복잡성은 빠르게 증가한다. 핵심 과제는 컨텍스트가 어떻게 저장되고 조직되어야 하는지 결정하고, 효과적인 선택과 검색을 지원하면서도 확장 가능하도록 조직하는 방법에 있다. 신중한 설계 없이는, 대규모 컨텍스트는 번거로워지고 후속 작업에 사용하기 어려워질 수 있다.
Limited model understanding of context 현재 시스템은 인간과 동일한 수준의 컨텍스트 이해를 가지고 있지 않다. 예를 들어, 그들은 복잡한 논리와 이미지의 관계형 정보 처리에서 어려움을 겪는다. 이 논문에서 언급했듯이, 낮은 기계 지능은 컨텍스트 엔지니어링에 더 큰 "노력"이 필요하게 만든다. 결과적으로, 사용 가능한 컨텍스트 중 상당 부분이 완전히 이해되거나 활용되지 못하고 있다. 향후 연구는 의미론적 추론, 논리적 해석, 다중 모드 정렬에서 모델의 능력을 강화하는 데 중점을 두어, 시스템이 컨텍스트를 더 잘 이해하고 인간 주도 컨텍스트 엔지니어링에 대한 의존도를 줄일 수 있도록 해야 한다.
Performance bottlenecks with long context 긴 컨텍스트의 처리는 여전히 핵심 과제로 남아 있다. 트랜스포머 기반 아키텍처는 으로 인해 컨텍스트가 증가함에 따라 비효율적이다. Mamba (Gu and Dao, 2024) 및 LongMamba (Ye et al., 2025b)와 같은 최근 대안들은 효율성과 확장성을 개선했지만, 긴 컨텍스트 이해에서는 여전히 약점을 보인다. 예를 들어, 입력 길이가 학습 길이를 훨씬 초과할 때, 또는 관계형 및 논리적 종속성이 전체 컨텍스트에 걸쳐 있을 때 그렇다. LOCOST (Bronnec et al., 2024)는 수십만 개의 토큰 문서를 처리할 수 있지만, 매우 긴 범위에 걸친 세밀한 추론이 필요한 특정 작업에서는 여전히 트랜스포머에 뒤처진다. 앞으로는 긴 컨텍스트를 단순히 확장된 입력으로 취급하는 것이 아니라, 훨씬 더 긴 컨텍스트를 효율적으로 처리하면서도 더 강력하고 신뢰할 수 있는 이해를 제공할 수 있는 새로운 아키텍처에 대한 명확한 필요가 있다.
Selecting relevant and useful context 사용 가능한 모든 컨텍스트가 당면한 작업에 기여하는 것은 아니다. 현재 시스템은 이미 관련성 추정 및 필터링 메커니즘을 사용하고 있지만, 그 성능은 여전히 제한적이다. 유용한 신호가 누락될 수 있고, 노이즈가 많거나 중복되는 정보가 종종 지속된다. 핵심 연구 방향은 무엇을 유지하고, 버리고, 강조할지를 지속적으로 정제하는 더 정확하고 적응적인 컨텍스트 선택 전략을 개발하여, 유지되는 컨텍스트가 작업 목표와 밀접하게 일치하도록 보장하는 것이다.
Digital Presence 카를 마르크스는 한때 "인간의 본질은 사회적 관계의 총체이다"라고 썼다. 컨텍스트 중심 AI 시대에 이 아이디어는 새로운 계산적 의미를 갖는다. 개인은 더 이상 물리적 존재나 의식적인 활동이 아닌, 그들이 생성하는 디지털 컨텍스트, 즉 그들의 대화, 결정, 상호 작용의 흔적으로 점점 더 정의되고 있다. 이러한 컨텍스트는 사람이 떠난 후에도 AI 시스템을 통해 지속되고, 진화하며, 심지어 세상과 계속 상호 작용할 수 있다. 인간의 마음은 업로드되지 않을 수 있지만, 인간의 컨텍스트는 업로드될 수 있으며, 이로써 컨텍스트 자체가 지식, 기억, 정체성의 영구적인 형태가 된다.
9. Conclusion
본 논문에서 우리는 컨텍스트 엔지니어링의 배경을 탐구했으며, 컨텍스트 엔지니어링이 LLM(대규모 언어 모델) 시대에 갑자기 발명된 것이 아니라, 기계의 점진적인 지능에 의해 형성된 오랜 기간 진화해 온 학문 분야임을 주장한다. 우리는 컨텍스트 엔지니어링의 역사적 단계를 추적하고, 그 실행을 지배하는 설계 고려 사항들을 설명함으로써, 핵심 과제가 변화하는 엔트로피 수준 하에서 인간의 의도와 기계의 이해 사이의 격차를 해소하는 데 있다는 점을 강조했다. 우리가 제시한 궤적은 점진적인 인간의 명시적인 컨텍스트 관리로부터의 이탈을 시사하며, 이는 점점 더 지능적인 기계가 컨텍스트를 해석하고, 추론하며, 심지어 구축하는 데 더 큰 책임을 지게 됨에 따라 발생한다. 앞으로, 기계의 이해가 인간의 인지에 근접하고 잠재적으로 이를 능가하여, 우리의 의도에 대한 가능한 "신의 시야(god’s eye view)"로 정점에 달할 때, AI 시스템은 우리를 이해할 뿐만 아니라, 우리 자신에 대한 이해를 조명하고 확장할 수도 있다.
