GenRL: Multimodal-foundation world models for generalization in embodied agents
Paper Translate
Author: Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, Sai Rajeswar
Affilation: Ghent University, VERSES AI Research Lab, University of Montreal, ServiceNow Research
Venue: NeurIPS 2024
Comment:
Date: October 2024
Paper Link: https://arxiv.org/abs/2406.18043
⭐️ Key Takeaways
1. GenRL은 오직 시각 데이터만을 사용하여 파운데이션 VLM의 표현을 생성적 월드 모델의 잠재 공간에 연결하고 정렬하는 멀티모달-파운데이션 월드 모델(MFWM)을 도입하여 구현된 RL 도메인의 멀티모달 데이터 부족 문제를 해결한다.
2. GenRL 프레임워크는 에이전트가 시각 및/또는 언어 프롬프트를 통해 작업을 명시하고, 이를 구현된 도메인의 역학에 기반을 둔 후, 상상 속에서 해당 행동을 학습하여 광범위한 다중 작업 일반화를 가능하게 한다.
3. GenRL은 사전 훈련 후 데이터에 전혀 접근하지 않고 오직 상상 속에서 정책을 학습하여 새로운 작업에 일반화할 수 있는 데이터 비의존적 정책 학습 패러다임을 확립함으로써, 구현된 RL 도메인에서 파운데이션 정책 학습의 기반을 마련한다.
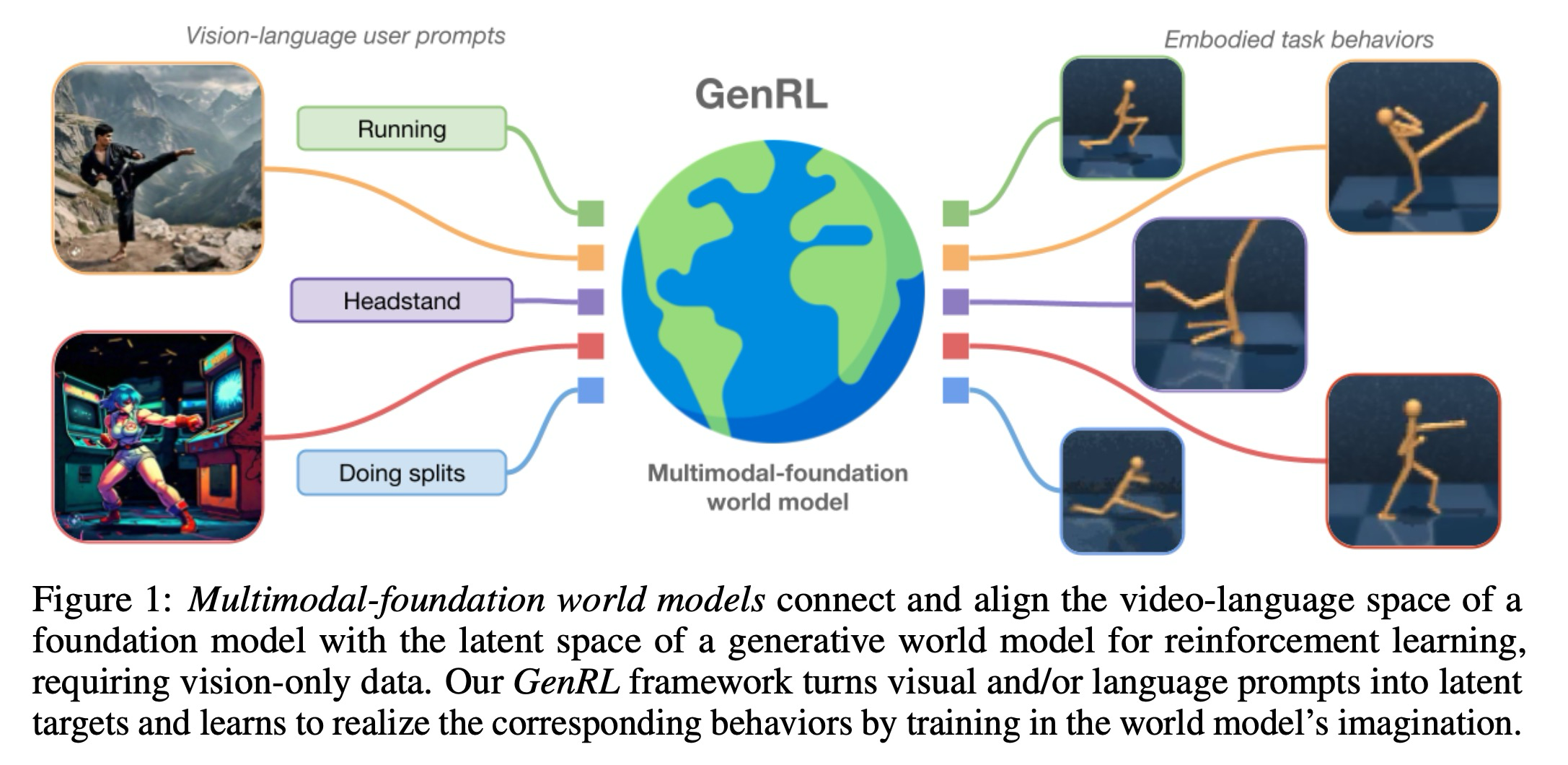
Abstract
다양한 도메인에서 수많은 작업을 해결할 수 있는 범용 구현 에이전트(generalist embodied agents)를 학습하는 것은 오래된 문제이다. 강화 학습(RL)은 각 작업마다 복잡한 보상 설계가 필요하기 때문에 확장하기 어렵다. 이와 대조적으로, 언어는 작업을 더 자연스러운 방식으로 명시할 수 있다. 현재의 파운데이션 시각-언어 모델(VLMs)은 상당한 도메인 격차(domain gap)로 인해 구현된(embodied) 환경에 적용되기 위해서는 일반적으로 미세 조정(fine-tuning) 또는 기타 적응 과정이 필요하다. 그러나 이러한 도메인에서 멀티모달 데이터가 부족하다는 점은 구현된 애플리케이션을 위한 파운데이션 모델 개발에 장애물로 작용한다. 본 연구에서는 언어 주석 없이 파운데이션 VLM의 표현(representation)을 RL을 위한 생성적 월드 모델의 잠재 공간(latent space)과 연결하고 정렬(align)할 수 있는 멀티모달-파운데이션 월드 모델을 제시함으로써 이러한 문제들을 극복한다. 그 결과로 탄생한 에이전트 학습 프레임워크인 GenRL은 시각 및/또는 언어 프롬프트를 통해 작업을 명시하고, 이를 구현된 도메인의 역학(dynamics)에 기반을 두며, 상상 속(imagination)에서 해당 행동을 학습하도록 허용한다. 이동(locomotion) 및 조작(manipulation) 도메인에서의 대규모 다중 작업 벤치마킹을 통해 평가한 결과, GenRL은 언어 및 시각 프롬프트로부터 다중 작업 일반화를 가능하게 한다. 더욱이, 데이터 비의존적 정책 학습 전략(data-free policy learning strategy)을 도입함으로써, 본 접근 방식은 생성적 월드 모델을 활용한 파운데이션 정책 학습의 기반을 마련한다.
1. Introduction
파운데이션 모델(Foundation models)은 세상에 대한 광범위한 지식을 갖춘 대규모 사전 훈련 모델이며, 주어진 작업에 즉시 적용될 수 있다. 이 모델들은 광범위한 시각 및 언어 작업에서 뛰어난 일반화 능력을 입증했다. 에이전트가 환경 내에서 객체 및 다른 에이전트와 물리적으로 상호작용하는 구현된 애플리케이션(embodied applications)으로 이 패러다임을 확장하고자 함에 따라, 이러한 상호작용에 대해 추론하고 이 설정 내에서 행동 시퀀스를 실행할 수 있는 범용 에이전트(generalist agents)가 필요하다.
강화 학습(RL)은 지정된 보상 함수를 최대화함으로써 에이전트가 시각 및/또는 고유 수용 입력으로부터 복잡한 행동을 학습할 수 있도록 한다. 그러나 보상 함수를 설계하는 것은 전문가 지식이 필요하고 원치 않는 행동을 초래할 수 있는 오류가 발생하기 쉬운 복잡한 프로세스이므로, RL을 다중 작업 및 구현된 환경으로 확장하는 것은 여전히 어려운 문제이다. 최근 연구는 에이전트의 입력 이미지와 텍스트 프롬프트 간에 CLIP이 계산한 유사성 점수를 사용하는 것과 같이, 언어를 사용하여 시각적 환경에 대한 보상을 지정하기 위해 시각-언어 모델(VLM)을 채택할 것을 제안한다. 하지만 이러한 접근 방식은 대부분 VLM의 미세 조정을 요구하며, 그렇지 않으면 몇몇 시각적 설정에서만 안정적으로 작동하는 경향이 있다.
대부분의 RL 설정에서는 에이전트 상호작용에 레이블을 지정하는 비용 및/또는 일부 구현된 상황이 본질적으로 언어로 변환되기에 부적합하기 때문에 도메인별 파운데이션 모델을 훈련하거나 미세 조정할 다중 모달 데이터가 부족하다. 예를 들어, 로봇 공학에서 작업의 언어 설명을 모터 전류나 관절 토크와 같은 하드웨어 수준 제어인 에이전트의 행동으로 변환하는 것은 쉽지 않다. 이러한 어려움은 현재의 기술을 대규모 일반화 설정으로 확장하는 것을 어렵게 하며, 다음과 같은 질문을 남긴다:
구현된 도메인에서의 일반화를 위해 파운데이션 모델을 어떻게 효과적으로 활용할 수 있는가?
이 논문에서 GenRL을 제시하는데, 이는 언어 주석을 전혀 필요로 하지 않는 새로운 접근 방식으로, 에이전트가 시각 또는 언어 프롬프트로부터 여러 작업을 해결하도록 훈련할 수 있도록 한다. GenRL은 멀티모달-파운데이션 월드 모델(MFWM)을 학습하며, 이 모델에서는 파운데이션 시각-언어 모델의 공동 임베딩 공간이 오직 시각 데이터만을 사용하여 RL을 위한 생성적 월드 모델의 표현과 연결되고 정렬된다. MFWM은 언어 또는 시각 프롬프트를 구현된 도메인의 역학에 기반을 둠으로써 작업 사양을 가능하게 한다. 그런 다음, 이 논문은 잠재 공간에서 프롬프트와 일치시켜 상상 속에서 지정된 작업을 완수하는 학습을 가능하게 하는 RL 목표를 도입한다.
월드 모델 및 RL을 위한 VLM에 대한 이전 연구와 비교할 때, GenRL의 하나의 두드러지는 특성은 완전히 데이터에 구애받지 않는(data-free) 방식으로 새로운 작업에 일반화할 수 있는 가능성이다. MFWM 훈련 후, 이 모델은 환경의 역학에 대한 강력한 사전 지식과 대규모 멀티모달 지식을 모두 보유한다. 이러한 조합은 에이전트가 매우 다양한 작업 사양을 해석하고 해당 행동을 학습할 수 있도록 한다. 따라서 시각 및 언어를 위한 파운데이션 모델과 유사하게, GenRL은 추가 데이터 없이 새로운 작업에 대한 일반화를 허용하며 구현된 RL 도메인에서 파운데이션 모델을 위한 기반을 마련한다.
2. Preliminaries and background
추가 관련 연구는 부록 A에서 찾을 수 있다.
Problem setting. 에이전트는 환경으로부터 관찰(observations) 를 받고 행동(actions) 를 통해 환경과 상호작용한다. 본 연구에서는 시각 강화 학습에 초점을 맞추므로, 관찰은 환경의 이미지이다. 에이전트의 목표는 특정 작업 를 달성하는 것이다. 이 작업은 이미지나 비디오를 통한 관찰 공간 또는 가능한 모든 문장의 공간을 나타내는 언어 공간 로 명시될 수 있다. 결정적으로, 표준 RL 설정과 비교하여, 이 논문은 작업을 해결하기 위해 보상 신호가 이용 가능하다고 가정하지 않는다. 대신, 보상 함수가 존재하는 경우 에이전트의 성능을 평가하는 데 사용된다.
Generative world models for RL. 모델 기반 RL에서, 에이전트 행동의 최적화는 환경 역학에 대한 (학습된) 모델을 사용하여 상상의 궤적을 롤아웃하고 점수를 매김으로써 효율적으로 수행된다. 최근 몇 년 동안, 이 패러다임은 에이전트의 입력을 자체적으로 예측함으로써 잠재 역학(latent dynamics)을 학습하는 생성적 월드 모델의 채택 덕분에 성공적으로 성장했다. 월드 모델은 시각 기반 환경에서 인상적인 성능을 보여주었으며, 복잡하고 개방형 작업을 해결하는 능력을 향상시킨다. 생성적 월드 모델은 탐색, 기술 학습, 장기 기억 작업 해결, 그리고 로봇 공학과 같은 많은 애플리케이션으로 성공적으로 확장되었다.
Foundations models for RL. 대규모 언어 모델(LLMs)은 언어를 사용하여 행동을 명시하는 데 사용되어 왔지만, 이는 일반적으로 환경과의 텍스트 인터페이스가 가능하거나 관찰 및/또는 행동이 언어 도메인으로 번역될 수 있다고 가정한다. 시각-언어 모델(VLMs)의 채택은 행동을 시각 공간에서 평가할 수 있게 하므로 이러한 가정을 완화한다. 그러나 이 접근 방식은 일반적으로 VLM의 미세 조정, 프롬프트 해킹 기술 또는 환경에 대한 시각적 수정을 요구하기 때문에 아직 견고한 성능을 보이지 못한다.
Vision-language generative modeling. 이미지-언어 생성 모델의 큰 성공을 고려할 때, 최근 커뮤니티의 노력은 시간적 차원이 시간적 일관성 및 증가된 계산 비용과 같은 새로운 도전 과제를 도입하는 비디오 도메인으로 그러한 성공을 복제하고 확장하는 데 초점을 맞추고 있다. 비디오 생성 모델은 RL을 위한 월드 모델과 유사하지만, 생성 모델의 출력이 일반적으로 행동에 조건화되지 않고, 오히려 언어 또는 아무것도 아닌 것(즉, 무조건 모델)에 조건화된다는 차이가 있다.
3. GenRL
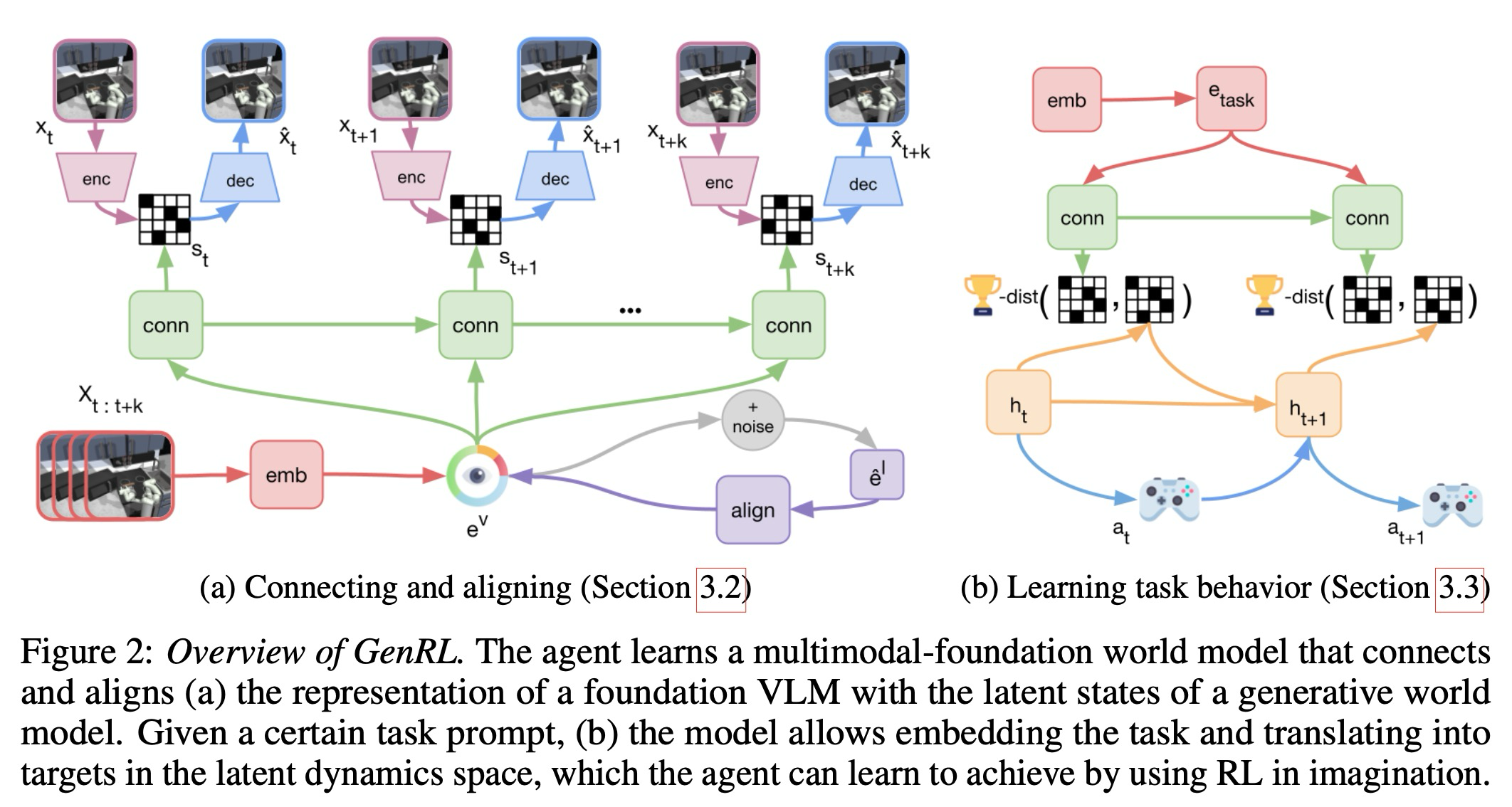
3.1 World models for RL
GenRL은 압축된 이산 잠재 공간 에서 환경의 순차적 역학을 모델링함으로써 작업에 구애받지 않는(task-agnostic) 월드 모델 표현을 학습한다. 잠재 상태 는 독립적인 범주형 분포에서 샘플링된다. 모델 훈련을 위한 그래디언트는 스트레이트-쓰루 추정(straight-through estimation)을 사용하여 샘플링 프로세스를 통해 전파된다.
월드 모델은 다음 구성 요소들로 이루어져 있다:
- Encoder: ,
- Decoder: ,
- Sequence model: ,
- Dynamic predictor:
이 모델은 다음 손실 함수로 훈련된다.
여기서 는 에 대한 약어이다. 시퀀스 모델은 선형 GRU 셀로 구현된다. 순환 상태 공간 모델(RSSM)과 다르게, 이 논문의 프레임워크에서 인코더 및 디코더 모델은 시퀀스 모델에 존재하는 정보에 조건화되지 않는다. 이는 잠재 상태가 단일 관찰에 대한 정보만을 포함하도록 보장하며, 시간적 정보는 시퀀스 모델의 hidden state에 저장된다. 이 논문의 모델의 더 단순한 인코더-디코더 전략을 고려할 때, 인코더는 목표 구현 환경에 기반을 둔 확률적 시각 토크나이저로 볼 수 있다.
3.2 Multimodal-foundation world models
멀티모달 VLM은 다음과 같은 구성 요소를 갖춘 대규모 사전 훈련 모델이다:
- Vision embedder: ,
- Language embedder:
여기서 는 시각 관찰의 시퀀스이고 는 텍스트 프롬프트이다. 비디오-언어 모델의 경우, 는 일반적으로 프레임의 상수(예: 프레임)이다. 이미지-언어 모델은 시각 임베더가 단일 프레임을 입력으로 받기 때문에 인 특수한 경우이다. 이 논문의 구현을 위해, InternVideo2 비디오-언어 모델(을 사용)을 채택한다.
멀티모달 파운데이션 VLM의 표현을 월드 모델 잠재 공간과 연결하기 위해, 이 논문은 두 가지 모듈, 즉 잠재 커넥터(latent connector)와 표현 정렬기(representation aligner)를 인스턴스화한다:
- Connector: ,
- Aligner: ,
- ,
여기서 는 그래디언트 전파를 멈추도록 지시한다.
커넥터는 VLM의 표현 공간에 있는 임베딩으로부터 월드 모델의 잠재 상태를 예측하는 방법을 학습한다. 커넥터의 목표는 그 예측과 월드 모델의 인코더 분포 사이의 KL 발산(KL divergence)을 최소화하는 것으로 구성된다. 트랜스포머 또는 상태 공간 모델과 같은 더 표현력이 풍부한 아키텍처가 채택될 수 있지만, 이 논문은 비디오 모델링을 위해 더 단순한 GRU 기반 아키텍처를 선택한다. 이로써 이 방법은 단순하게 유지되며 커넥터의 아키텍처는 월드 모델의 구성 요소에 대해 대칭적이다.
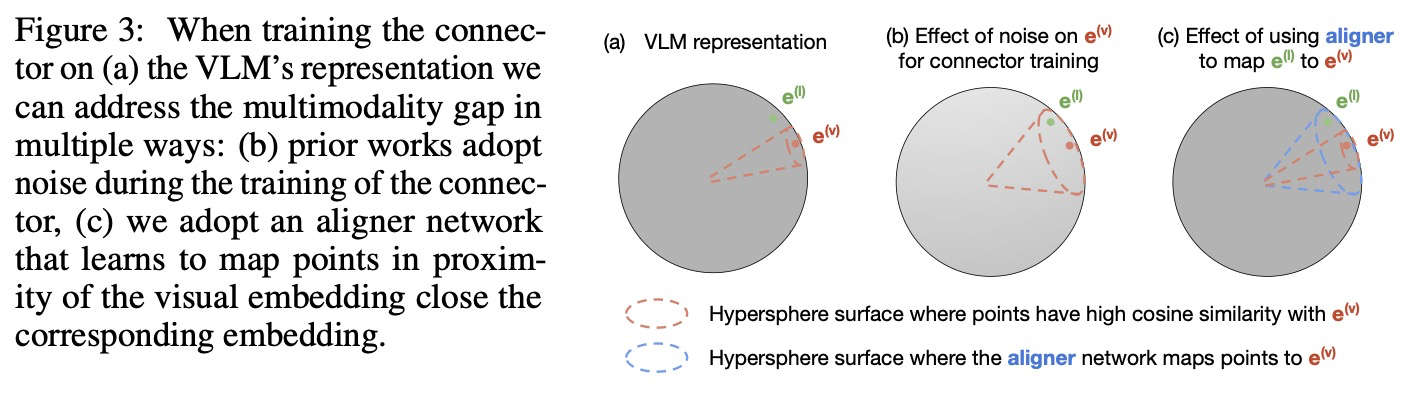
Aligning multimodal representations. 커넥터는 사전 훈련된 VLM의 시각 임베딩을 월드 모델의 잠재 상태에 매핑하는 방법을 학습한다. 시각 임베딩 로부터 커넥터를 학습할 때, 이 논문은 두 임베딩 사이의 각도 가 충분히 작으면 커넥터가 (이론적인) 해당 언어 임베딩 로 일반화할 수 있다고 가정한다 (그림 3). 이는 또는 로 표현될 수 있으며, 여기서 는 작은 양의 상수이다.
대조 학습으로 훈련된 멀티모달 VLM은 구형 임베딩(spherical embeddings)이 정렬되지 않는 멀티모달 격차(multimodality gap)를 나타낸다. 비전-언어 데이터셋이 주어지면 이 투영 함수를 학습할 수 있다. 그러나 구현된 도메인에서는 일반적으로 비전-언어 데이터를 사용할 수 없으므로, 언어 주석을 사용하지 않고 표현을 정렬할 방법을 찾아야 한다.
이전 방법들은 훈련 중에 비전 임베딩에 노이즈를 주입한다. 이는 노이즈와 함께 가 더 커지는 상황으로 이어진다. 이를 통해 언어 임베딩이 해당 시각 임베딩에 충분히 가까워질 수 있다.
이 논문은 대신 정렬기 네트워크를 학습하는데, 이는 주변의 지점들을 에 더 가깝게 매핑한다. 이 방식으로 는 변경되지 않지만, 정렬기는 을 에 충분히 가깝게 매핑한다. 주변의 지점을 샘플링하기 위해 노이즈를 사용하므로, 정렬기 모델은 시각 전용 데이터(vision-only data)를 사용하여 훈련될 수 있으며, 따라서 언어 주석이 필요 없다.
정렬기는 노이즈가 없는 커넥터를 훈련할 수 있게 하며, 이는 두 가지 주요 이점을 제공한다: (i) 언어 임베딩 입력에 대해 유사한 정렬을 유지하면서 시각 임베딩 입력에 대해 더 높은 예측 정확도를 제공한다. (ii) 더 유연하다. 정렬기 모듈만 재훈련하면 되므로 다른 노이즈 수준에 대해 재훈련/적응하기가 더 쉬우며, 불필요한 경우 사용을 피할 수 있다.
3.3 Specifying and learning tasks in imagination
월드 모델은 순차 및 역학 모델을 사용하여 잠재 공간에서 궤적(trajectory)을 상상하는 데 사용될 수 있다. 이를 통해 모델 기반 강화 학습(RL) 방식으로 행동 정책을 훈련할 수 있다. 시각 또는 언어 프롬프트를 통해 작업이 명시되면, 이 논문의 MFWM은 임베더의 출력 를 잠재 상태 시퀀스 로 변환하여 해당 잠재 상태를 생성할 수 있다 (디코딩된 예시는 그림 1에 제시되어 있다). 그러면 정책 모델 의 목표는 궤적 일치(trajectory matching)를 수행하여 사용자가 지정한 목표와 일치하는 것이다.
궤적 일치 문제는 정책 가 방문한 상태 분포와 사용자가 명시한 프롬프트로부터 정렬기-커넥터 네트워크를 사용하여 생성된 궤적 간의 발산(divergence) 최소화 문제로 해결될 수 있다:
KL 발산(KL divergence)이 거리 함수에 대한 자연스러운 후보이지만, 실제로는 잠재 상태의 선형 투영 간의 코사인 거리(cosine distance)를 사용하는 것이 학습 속도를 눈에 띄게 높이고 안정성을 향상시킨다는 것을 발견한다. 그런 다음 이 논문은 식 (2)의 목표를 RL 보상으로 바꿀 수 있다:
여기서 는 월드 모델 디코더의 첫 번째 선형 레이어를 나타낸다. 이 논문은 이 보상을 최대화하고 사용자가 지정한 작업을 달성하도록 액터-크리틱 모델을 훈련한다. 추가 구현 세부 사항은 부록 B에 제공한다.
Temporal alignment. 궤적 일치의 한 가지 문제점은 에이전트가 방문한 상태 분포가 목표 분포와 동일한 상태에서 시작한다고 가정한다는 것이다. 그러나 커넥터에 의해 생성된 초기 상태는 현재 정책이 위치한 초기 상태와 다를 수 있다. 예를 들어, 그림 1의 오른쪽에 있는 스틱맨(Stickman) 에이전트를 고려할 때, 에이전트가 땅에 누워 있고 달리도록 지시받는다면, 일어나서 달리는 상태에 도달하는 데 걸리는 단계의 수가 VLM이 인식하는 시간적 범위(예: 이 논문의 경우 8프레임)를 초과할 수 있으며, 이는 보상의 불일치를 야기한다.
이러한 초기 조건 정렬 문제(initial condition alignment issue)를 해결하기 위해, 이 논문은 음성 인식에서의 최적 경로 디코딩(best path decoding)에서 영감을 받은 최적 일치 궤적 기법(best matching trajectory technique)을 제안한다. 이 논문의 기법은 두 단계로 구성된다:
- 이 논문은 목표 궤적의 처음 개 상태를 시간 축을 따라 슬라이딩하면서 에이전트가 상상한 궤적에서 얻은 개 상태와 비교한다. 이를 통해 궤적이 가장 잘 정렬되는 타임스텝 를 찾을 수 있다 (비교는 가장 높은 보상을 제공한다).
- 이 논문은 두 가지 가능한 맥락에서 시간적 시퀀스를 정렬한다: (a) 에이전트 시퀀스의 상태가 이전에 오는 경우, 보상은 목표 시퀀스의 초기 상태를 사용한다; (b) 상태가 이후 단계 후에 오는 경우, 목표 시퀀스의 상태와 비교된다.
모든 실험에서 이 논문은 로 고정하는데 (이 논문이 사용하는 VLM의 프레임 수), 이는 초기 상태만 비교하는 것()과 정렬을 전혀 수행하지 않는 것() 사이에서 좋은 절충점을 찾는다는 것을 발견한다. 절제 연구(ablation study)는 부록 E에서 찾을 수 있다.
4. Experiments
전반적으로, 이 논문은 총 35개의 작업에 대해 4개의 이동(locomotion) 환경(Walker, Cheetah, Quadruped, 그리고 새롭게 도입된 Stickman 환경)과 1개의 조작(manipulation) 환경(Kitchen)을 사용하며, 에이전트는 보상 없이 시각 또는 언어 프롬프트만을 사용하여 훈련된다. 사용된 데이터셋, 작업 및 프롬프트에 대한 자세한 내용은 부록 C에서 확인할 수 있다.
4.1 Offline RL
오프라인 RL에서, 에이전트의 목표는 주어진 고정된 데이터셋으로부터 특정 작업 행동을 추출하는 방법을 학습하는 것이다. 에이전트의 성능은 일반적으로 데이터셋에서 올바른 행동을 '검색'하고 그 행동들 사이를 보간하는 능력에 달려 있다. 오프라인 RL의 인기 있는 기술에는 TD3와 같은 오프-폴리시 RL 방법, IQL과 같은 장점-가중치 행동 복제(advantage-weighted behavior cloning), 그리고 CQL 또는 TD3+BC와 같은 행동-정규화 접근 방식이 포함된다.
이 논문은 VLM을 사용하여 보상을 설계하기 위한 다양한 접근 방식의 다중 작업 능력을 평가하고자 한다. 이 논문은 평가된 각 도메인에 대해 대규모 데이터셋을 수집했으며, 이는 구조화된 데이터(예: 일부 작업을 수행하도록 학습하는 에이전트의 리플레이 버퍼)와 비구조화된 데이터(예: 탐색 데이터를 사용하여 수집된 탐색 데이터)의 혼합을 포함한다. 이 데이터셋에는 궤적에 대한 보상 정보나 텍스트 주석이 포함되어 있지 않다. 주어진 작업을 위한 훈련 보상은 에이전트에 의해 추론되어야 하는데, 예를 들어 관찰과 주어진 프롬프트 사이의 코사인 유사성을 사용하거나, 이 논문의 GenRL의 경우 이 논문의 보상 공식(식 3)을 사용한다.
이 논문은 GenRL을 두 가지 주요 범주의 접근 방식과 비교한다:
- 이미지-언어 보상: 이전 연구를 따라서, 언어 프롬프트에 대한 임베딩과 에이전트의 시각적 관찰에 대한 임베딩 사이의 코사인 유사성이 보상으로 사용된다. VLM으로는 원래 CLIP보다 우수한 성능을 보고한 SigLIP-B 모델을 채택한다.
- 비디오-언어 보상: 이미지-언어 보상과 유사하지만, 시각 임베딩이 이전 연구에서 수행된 것처럼, 지난 k 프레임의 기록 비디오로부터 계산된다는 차이가 있다. VLM으로는 GenRL에 사용된 것과 동일한 InternVideo2 모델을 사용한다.
이 평가는 GenRL을 문헌의 다양한 오프라인 RL 방법, 즉 IQL, TD3+BC, TD3와 비교한다. 또한 모델 기반 베이스라인인 WM-CLIP을 도입한다. 이 베이스라인은 GenRL의 정반대인데, 커넥터와 정렬기를 학습하는 대신 "역방향 커넥터(reversed connector)"를 학습한다. 이 모듈은 월드 모델 상태로부터 VLM 임베딩을 예측하는 방법을 학습한다 (GenRL은 그 반대를 수행한다). 이를 통해 상상된 상태에서 예측된 시각 임베딩과 작업의 언어 임베딩 사이의 코사인 유사성을 계산함으로써 모델-프리 베이스라인과 유사한 방식으로 상상 속에서 보상을 계산할 수 있게 된다.
모든 방법은 500k 그래디언트 단계 동안 훈련되며, 20개의 에피소드에서 평가된다. 각 작업에 대해, 모델-프리 에이전트는 시각 인코더, 액터, 그리고 크리틱 네트워크를 포함하여 전체 데이터셋에서 처음부터 에이전트를 재훈련해야 한다. 모델 기반 에이전트는 도메인별로 모델을 한 번 훈련한 다음, 각 작업에 대해 액터-크리틱을 훈련해야 한다. 기타 훈련 및 베이스라인 세부 정보는 부록 D에 보고되어 있다.
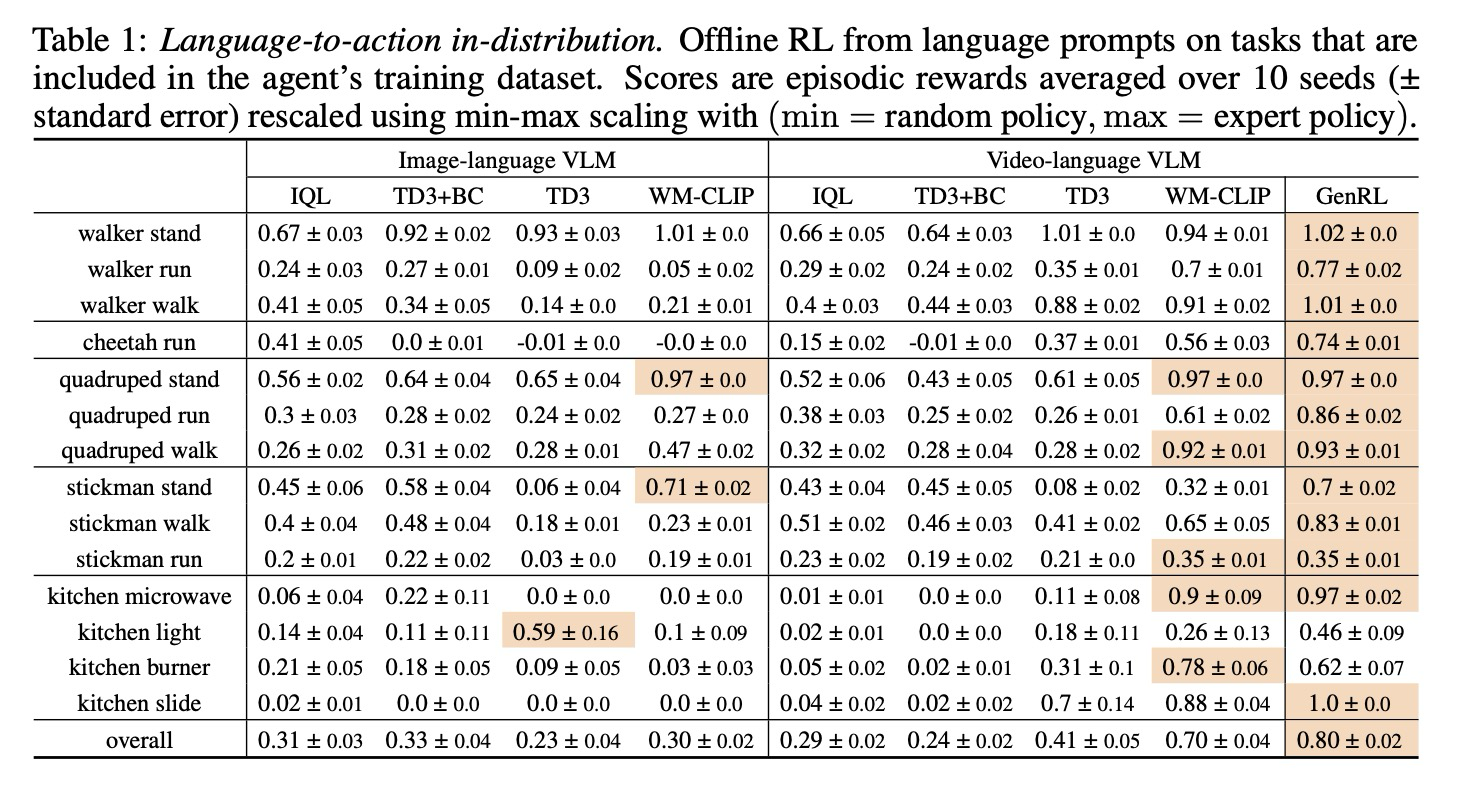
Language-to-action in-distribution. 이 논문은 언어만을 통해 작업을 명시할 때, 해당 방법들이 훈련 데이터에 확실히 존재하는 작업 행동을 검색할 수 있는지 확인하고자 한다. 결과는 표 1에 제시되어 있으며, 에피소드 보상은 무작위 에이전트의 성능이 0이고 전문가 에이전트의 성능이 1이 되도록 최소-최대 스케일링을 사용하여 재조정되었다.
GenRL은 모든 도메인과 작업에서 전반적인 성능이 뛰어나며, 특히 사족보행 및 치타 도메인에서 걷기와 달리기와 같은 동적 작업에서 다른 방법을 능가한다. 그러나 주방 도메인의 일부 정적 작업에서는 다른 방법들이 때때로 GenRL을 능가한다. 이는 프롬프트에서 GenRL이 추론한 목표 시퀀스가 정적 상황에서도 종종 약간 움직이는 경향이 있다는 사실로 설명될 수 있다. 이 문제를 해결하기 위해 정적 프롬프트에 대해 목표 시퀀스 길이를 1로 설정할 수도 있지만, 이 논문은 방법의 단순성과 일반성을 유지하기로 선택하며, 이를 사소한 한계로 인정한다.
예상대로, 비디오-언어 보상은 동적 작업에서 이미지-언어 보상보다 더 나은 성능을 보이는 경향이 있다. 덜 보수적인 접근 방식인 TD3는 대부분의 작업에서 다른 모델-프리 베이스라인보다 더 나은 성능을 보이는데, 이는 이전 연구에서 나타난 바와 유사하다. 모델 기반 베이스라인인 WM-CLIP-V의 성능은 GenRL의 성능에 가장 가깝다.
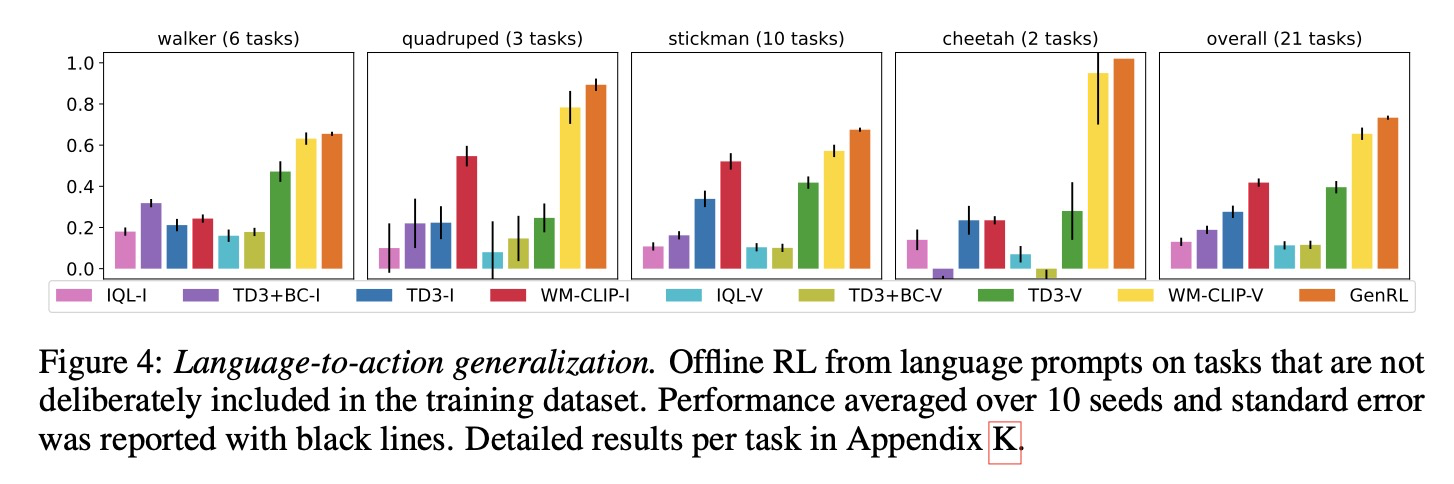
Language-to-action generalization. 다중 작업 일반화를 평가하기 위해, 이 논문은 훈련 데이터에 의도적으로 포함되지 않은 작업 세트를 정의했다. 에이전트가 전문가 모델의 성능과 일치할 것으로 예상하지는 않지만, 이 벤치마크에서 더 높은 점수는 다양한 방법의 일반화 능력을 측정하는 데 도움이 된다. 이 논문은 각 도메인에 대한 다양한 작업에서 성능을 평균화하고 그 결과를 그림 4에 요약했으며, 자세한 작업별 결과는 부록 K에서 확인할 수 있다.
전반적으로, 분포 내 결과와 유사한 경향이 관찰된다. GenRL은 모든 모델-프리 접근 방식을 크게 능가하며, 특히 사족보행 및 치타 도메인에서 성능이 전문화된 에이전트의 성능에 가깝다. 이미지-언어(그림에서 -I)와 비디오-언어(그림에서 -V) 모두에 대해 IQL 및 TD3+BC와 같은 더 보수적인 접근 방식은 더 나쁜 성능을 보이는 경향이 있다. 이는 작업이 훈련 데이터에 존재하지 않기 때문에 궤적 세그먼트를 모방하는 것이 고수익 궤적으로 이어질 가능성이 낮다는 사실과 관련될 수 있다.
Video-to-action. 언어는 작업 명시를 강력하게 단순화하지만, 일부 경우에는 작업의 시각적 예시를 제공하는 것이 더 쉬울 수 있다. 언어 프롬프트와 유사하게, GenRL은 시각적 프롬프트(짧은 비디오)를 구현된 도메인의 역학에 기반을 두고 해당 행동을 학습할 수 있도록 한다.
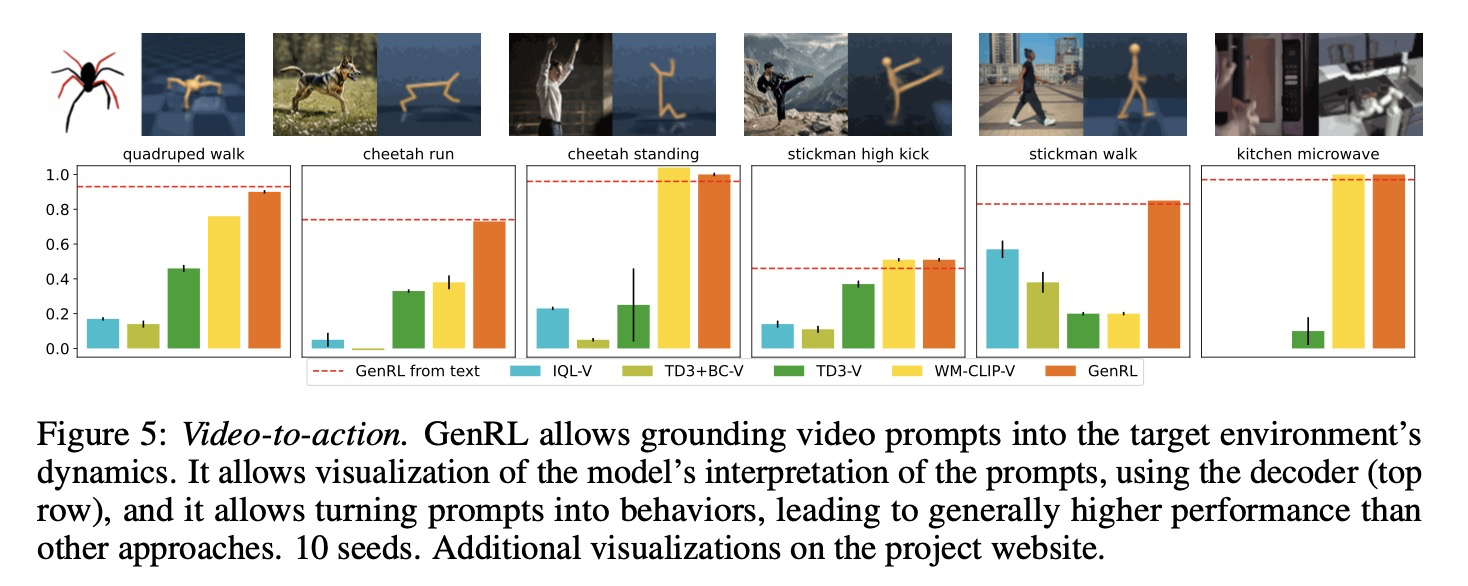
그림 5에서 이 논문은 비디오 프롬프트로부터의 행동 학습 결과를 제공한다. 포함된 작업들은 정적 및 동적 특성을 가지며 4개의 다른 도메인에 걸쳐 있다. 프롬프트로 사용된 비디오의 시각화는 프로젝트 웹사이트에서 볼 수 있으며, 여기에는 프롬프트를 사용하여 모델이 생성한 "기반 비디오(grounded videos)" 세트도 제시되어 있다. 이 비디오는 시각적 프롬프트에 해당하는 잠재 목표를 추론한 다음, 디코더 모델을 사용하여 재구성된 이미지(그림 5의 오른쪽 이미지)를 디코딩하여 얻을 수 있다.
결과는 언어 프롬프트 실험과 유사한 경향을 보이며, 비디오 프롬프트를 사용할 때의 성능은 동일한 작업에 대한 언어-행동 성능과 일치한다. 일반적으로, 이 논문은 VLM이 매우 다른 시각적 스타일(드로잉, 사실적, AI 생성), 매우 다른 카메라 시점(사족보행, 전자레인지), 그리고 다른 형태(치타 작업)로 일반화할 수 있다는 점이 흥미롭다는 것을 발견한다.
Summary. 제시된 실험들은 GenRL의 더 강력한 성능에 기여하는 주요 요소들을 더 명확하게 확립할 수 있도록 한다: (i) 비디오-언어 모델은 동적 작업에 도움이 된다, (ii) 모델 기반 알고리즘은 더 높은 성능을 가져온다, (iii) 제시된 연결-정렬 시스템은 일반적으로 두 표현을 연결하는 "역방향" 방식보다 우수하다.
4.2 Data-free policy learning
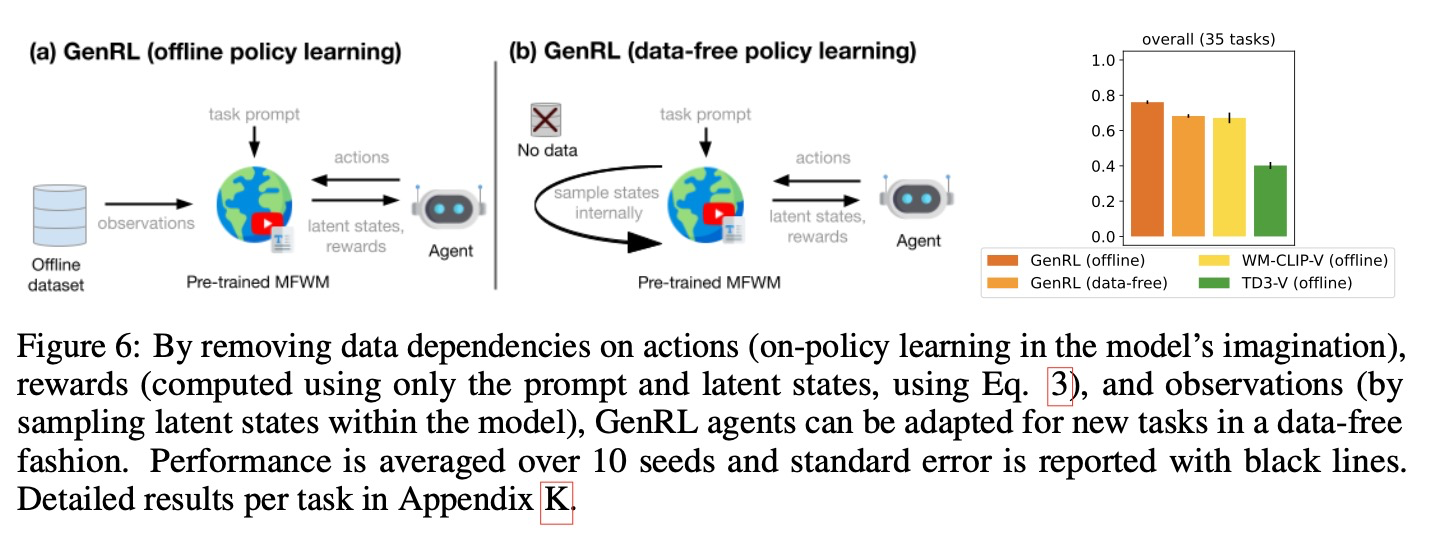
이전 절에서 이 논문은 파운데이션 VLM을 사용하여 보상을 설계하는 여러 접근 방식을 평가한다. 분명히 모델-프리 RL 접근 방식은 액터-크리틱을 훈련하고 새로운 작업 전반에 걸쳐 일반화하기 위해 지속적으로 데이터셋에 접근해야 한다. 모델 기반 RL은 상상 속에서 액터-크리틱을 학습할 수 있다. 그러나 이전 연구에서는 행동을 학습하기 위해 시퀀스를 상상하는 과정이 먼저 실제 데이터 시퀀스를 처리하는 것을 필요로 한다. 이 데이터는 역학 모델을 초기화하고 상상 속에서 정책을 롤아웃하기 위한 시작 상태를 나타내는 잠재 상태를 얻는 데 사용된다. 더욱이, 새로운 작업을 학습하기 위해서는 보상 레이블이 지정된 데이터가 필요하며, 이는 작업 학습 과정 동안 에이전트에게 보상을 제공하는 보상 모델을 학습하는 데 사용된다.
파운데이션 모델은 일반적으로 새로운 작업에 일반화하기 위해 방대한 데이터셋에서 훈련된다. 모델 사전 훈련에 사용된 데이터셋은 다운스트림 애플리케이션에 필수가 아니며, 때로는 이러한 데이터셋이 공개적으로 이용 가능하지 않을 수도 있다. 이 절에서 이 논문은 시각 및 언어를 위한 파운데이션 모델과 동일한 원칙을 따르는 RL의 파운데이션 모델을 위한 새로운 패러다임을 확립하고자 한다. 이 논문은 이 패러다임을 데이터 비의존적 정책 학습(data-free policy learning)이라고 부르며, 이는 사전 훈련 후 데이터에 전혀 접근하지 않고 (심지어 사전 훈련 데이터셋에도 접근하지 않고) 오직 상상 속에서 정책을 학습하여 새로운 작업에 일반화할 수 있는 능력을 정의한다.
GenRL은 두 가지 주요 이유 덕분에 데이터 비의존적 정책 학습을 가능하게 한다: 에이전트는 사전 훈련 중에 크고 다양한 데이터셋에서 작업에 구애받지 않는(task-agnostic) MFWM을 학습하며, MFWM은 어떤 데이터도 필요 없이 잠재 공간에서 작업을 직접 명시할 수 있는 가능성을 부여한다. 따라서 상상 속에서 행동을 학습하기 위해 에이전트는 다음을 수행할 수 있다: (i) 월드 모델 표현의 무작위 잠재 상태를 샘플링하고, (ii) 정책의 행동을 따라 상상 속에서 시퀀스를 롤아웃하며, (iii) 커넥터-정렬기 네트워크로 주어진 프롬프트를 처리하여 얻은 목표를 사용하여 보상을 계산한다 (식 3).
그림 6에서 이 논문은 오프라인 방식과 데이터 비의존적 정책 학습 방식으로 GenRL을 훈련하는 것 사이의 차이점을 더 명확히 하는 다이어그램을 제공한다. 이어서 이 논문은 데이터 비의존적 정책 학습을 4.1절에서 논의된 오프라인 RL 베이스라인과 비교하는 결과를 제시한다. 데이터 비의존적 정책 학습은 전반적인 성능에서 약간의 감소를 보이지만, 원래의 GenRL 성능에 가깝게 유지되며 여전히 다른 접근 방식들을 능가한다. 부록 K에서는 성능 차이가 대부분의 도메인에서 미미하며, 주방 도메인에서는 데이터 비의존적 정책 학습이 심지어 더 나은 성능을 보인다는 것을 추가로 보여준다.
사전 훈련 후 데이터 비의존적 학습을 채택함으로써 에이전트는 데이터 없이 새로운 작업을 숙달할 수 있다. 또한 데이터 비의존적 정책 학습은 데이터의 CPU-GPU 메모리 전송을 필요로 하지 않기 때문에 정책 훈련 시간을 단축시키며, 종종 훈련 시작 후 30분 이내에 수렴을 가능하게 한다. 행동 학습을 위한 파운데이션 모델을 확장함에 따라, 데이터 비의존적 학습 능력은 매우 중요해질 것이다. 비록 미래의 파운데이션 모델을 훈련하기 위해 매우 큰 데이터셋이 사용되겠지만, GenRL은 독점적이거나 라이선스가 있거나 사용할 수 없는 데이터에 직접 접근할 필요 없이 잘 적응하여 유연성을 제공한다.
4.3 Analysis of the training data distribution
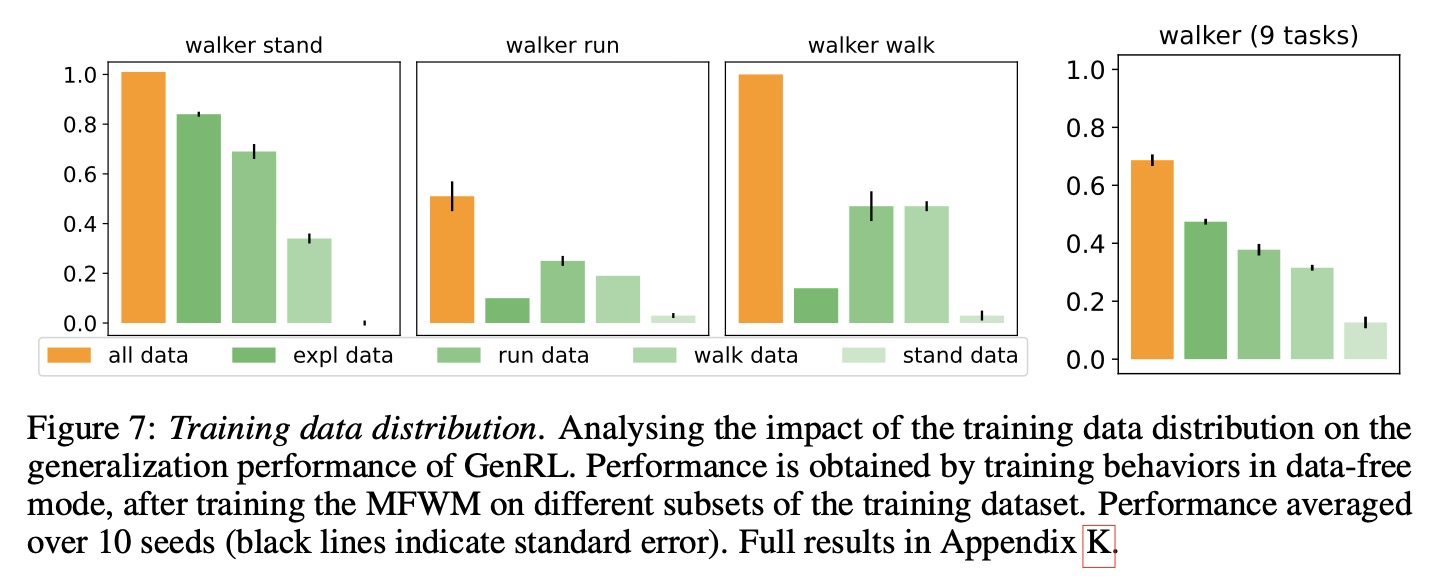
4.1절과 4.2절에서 입증했듯이, 대규모 데이터셋으로 훈련된 후 GenRL 에이전트는 추가 데이터 없이 여러 새로운 작업에 적응할 수 있다. 부록 C에 자세히 설명된 훈련 데이터의 특성은 탐색(exploration) 데이터와 작업별 데이터가 결합되어 있다. 따라서 이 논문은 GenRL 훈련에 가장 중요한 데이터 하위 집합은 무엇인지 자문한다.
GenRL의 핵심 데이터 유형을 식별하기 위해, 이 논문은 다양한 데이터셋 하위 집합에서 서로 다른 MFWM을 훈련한다. 그런 다음, 이 논문은 데이터 비의존적 행동 학습(data-free behavior learning)을 사용하여 모든 작업에 대한 작업 행동을 훈련한다. 이 논문은 그림 7에서 Walker 데이터셋의 하위 집합에 대한 분석을 제시한다.
결과는 다양한 데이터 분포가 작업 성공에 중요하다는 것을 확인하며, 가장 좋은 성능은 전체 데이터셋을 사용했을 때 달성되었고, 그 다음으로는 다양한 탐색 데이터였다. 작업별 데이터의 효과는 작업 복잡성에 따라 달라지는데, 예를 들어, 'run data'는 여러 작업에서 'walk data'나 'stand data'보다 더 유용하고 일반화 가능성이 높다는 것이 입증되었다. 결정적으로, 변동성이 가장 적은 'stand data'는 범용 에이전트 학습을 제한하지만, 부록 K에 자세히 설명된 바와 같이 'lying down' 및 'sitting on knees'와 같은 더 간단한 작업은 여전히 관리할 수 있다.
RL에서 파운데이션 모델을 훈련하는 데 있어 앞으로 나아가기 위해서는, 비정형 데이터로부터 여러 행동을 추출하고 대규모 데이터셋으로부터 복잡한 행동을 정확하게 처리하는 방법을 개발하는 것이 필수적일 것이다. 따라서 GenRL이 주로 비정형 데이터를 활용할 수 있는 능력은 확장성 측면에서 중요한 이점이다.
5. Discussion
이 논문은 시각-언어 프롬프트를 구현된 도메인에 기반을 두고 상상 속에서 해당 행동을 학습하기 위한 월드 모델 기반 접근 방식인 GenRL을 소개한다. GenRL의 멀티모달-파운데이션 월드 모델(MFWM)은 단일 모달 데이터만을 사용하여 훈련될 수 있으며, 구현된 강화 학습(RL) 도메인에서 멀티모달 데이터 부족 문제를 극복한다. GenRL의 데이터 비의존적 행동 학습 능력은 데이터 없이 새로운 작업으로 일반화할 수 있는 RL 분야의 파운데이션 모델을 위한 기반을 마련한다.
A framework for behavior generation. 대규모 언어 모델(LLMs) 및 시각-언어 모델(VLMs)을 사용하는 데 있어 흔한 어려움 중 하나는 특정 작업을 달성하기 위해 프롬프트 튜닝이 필요하다는 것이다. GenRL은 파운데이션 VLM에 의존하기 때문에 이전 접근 방식과 유사하게 이 문제에서 자유롭지 않다. 하지만 GenRL은 특정 프롬프트로부터 얻은 목표를 시각화할 수 있도록 허용하는 독특한 특징을 가지고 있다. MFWM 디코더를 사용하여 잠재 목표를 디코딩함으로써, 해당 행동을 훈련하기 전에 해석된 프롬프트를 시각화할 수 있다. 이는 이전의 (모델-프리) 접근 방식과 비교하여 프롬프트 튜닝을 위한 훨씬 더 설명 가능하고 빠른 반복을 가능하게 하는 프레임워크를 가능하게 하는데, 이전 방식들은 종종 특정 프롬프트에 대해 어떤 행동이 보상을 받는지 식별하기 위해 에이전트를 훈련해야 한다.
Limitations. GenRL은 강점에도 불구하고, 주로 구성 요소의 내재적 약점으로 인해 몇 가지 한계점을 보인다. VLM으로부터, GenRL은 멀티모달 격차 및 프롬프트 튜닝에 대한 의존성과 관련된 문제를 물려받는다. 이 논문은 전자를 완화하기 위해 연결-정렬 메커니즘을 제안했으며, 후자에 대해서는 프롬프트에 해당하는 잠재 목표의 디코딩을 허용하여 프롬프트 튜닝을 용이하게 하는 설명 가능한 프레임워크를 제시했다. 월드 모델로부터, GenRL은 재구성(reconstruction)에 대한 의존성을 물려받는데, 이는 설명 가능성과 같은 장점을 제공하지만, 복잡한 관찰에 대한 실패 모드와 같은 단점도 제공한다. 이 논문은 부록 I에서 이 한계점을 추가로 조사하며, 부록 J에서는 다른 잠재적 한계점들을 제시한다.
Future work. 이 논문은 범용 구현 에이전트를 위한 파운데이션 모델을 개발하기 위해 노력함에 따라, GenRL 프레임워크는 수많은 연구 기회를 열어준다. 한 가지 가능성은 여러 행동을 학습하고, 예를 들어 대규모 언어 모델(LLM)과 같은 또 다른 모듈이 이들을 조합하여 장기적인 작업(long-horizon tasks)을 해결하도록 하는 것이다. 또 다른 유망한 연구 분야는 GenRL 프레임워크의 시간적 유연성을 조사하는 것이다. 이 논문은 정적 작업의 경우 더 큰 시간적 인식이 성능을 향상시킬 수 있다는 것을 확인했다. 이 개념은 VLM의 시간적 이해 범위를 넘어서는 행동에도 적용될 수 있다. 이러한 과제에 대한 일반적인 해결책을 개발하는 것은 프레임워크의 상당한 발전을 이끌 수 있다.
