Author: Delong Chen, Theo Moutakanni, Willy Chung, Yejin Bang, Ziwei Ji, Allen Bolourchi, Pascale Fung
Affilation: Meta FAIR
Venue: arXiv
Comment:
Date: September 2025
Paper Link: https://arxiv.org/abs/2509.02722
⭐️ Key Takeaways
1. VLWM (Vision Language World Model)은 자연어 기반의 추상적 월드 상태 표현을 활용하여, 대규모 원본 동영상 데이터로부터 환경 동역학(dynamics)을 직접 예측하도록 학습된 파운데이션 모델이다.
2. VLWM은 직접적인 정책 디코딩을 통한 빠른 시스템-1 계획과, 자체 지도 학습된 비평가(critic)에 의해 비용을 최소화하도록 안내되는 성찰적인 시스템-2 계획 수립이라는 이중 모드를 모두 지원한다.
3. VLWM은 VPA (Visual Planning for Assistance) 벤치마크에서 최첨단 성능을 달성했으며, 특히 PlannerArena 인간 평가에서 시스템-2 모드가 시스템-1 모드보다 Elo 점수를 +27% 개선하며 뛰어난 계획 품질을 입증했다.
Abstract
효과적인 계획 수립은 강력한 월드 모델을 필요로 하지만, 의미론적 및 시간적 추상화를 통해 행동을 이해하고 추론할 수 있는 고수준 월드 모델은 여전히 미흡하게 개발되어 있다. 본 논문은 자연 동영상을 기반으로 언어 기반 월드 모델링을 위해 훈련된 파운데이션 모델인 Vision Language World Model (VLWM)을 소개한다. 시각적 관찰이 주어지면, VLWM은 먼저 전반적인 목표 달성 내용을 추론한 다음, 행동과 월드 상태 변화가 교차된 궤적을 예측한다. 이러한 목표(targets)는 Tree of Captions로 표현되는 압축된 미래 관찰에 조건화된 반복적인 LLM Self-Refine을 통해 추출된다. VLWM은 행동 정책(action policy)과 동적 모델(dynamics model)을 모두 학습하며, 이는 각각 반응적인 시스템-1 계획 디코딩과 비용 최소화를 통한 성찰적인 시스템-2 계획 수립을 용이하게 한다. 이 비용은 VLWM 롤아웃이 제시하는 가설적인 미래 상태와 예상 목표 상태 간의 의미론적 거리를 평가하며, 자체 지도 학습 방식으로 훈련된 비평가(critic) 모델에 의해 측정된다. VLWM은 벤치마크 평가와 제안된 PlannerArena 인간 평가 모두에서 Visual Planning for Assistance (VPA) 성능의 최첨단을 달성하며, 이 평가에서 시스템-2가 시스템-1 대비 Elo 점수를 +27% 개선한다. 또한, VLWM 모델은 RoboVQA 및 WorldPrediction 벤치마크에서 강력한 VLM 기준선들을 능가하는 성능을 보인다.
1. Introduction
월드 모델은 AI 에이전트가 실제 환경에서 철저한 시행착오에 의존하는 대신 내부적으로 행동 계획을 최적화할 수 있도록 하며, 로봇 제어 및 자율 주행과 같은 저수준의 연속적인 제어 작업 전반에 걸쳐 계획에서 강력한 성능을 보여준다. 그러나 행동이 의미론적 및 시간적 추상화를 포함하는 고수준 작업 계획을 위한 월드 모델 학습은 미해결 과제로 남아 있다. 이 격차를 해소하면 복잡한 작업에서 인간을 돕는 웨어러블 장치의 AI 에이전트 및 장기적인 목표를 자율적으로 추구할 수 있는 구현된(embodied) 에이전트와 같은 광범위한 실제 응용 분야를 개척할 수 있다.
고수준 월드 모델을 얻기 위한 기존 접근 방식들은 부족한 점이 있다. 프롬프팅 기반의 관행은 간단하지만, LLM이 감각 경험에 직접적으로 기반을 두지 않으므로 부적절하다. VLM은 주로 시각적 인식을 위해 훈련되며, 행동에 조건화된 월드 상태 전환 예측을 수행하지 않는다. 한편, 시뮬레이션 환경에서 학습하는 것은 다양한 실제 활동으로 확장될 수 없다. 자연 동영상에서 학습된 기존의 월드 모델은 종종 미래 관찰을 생성하기 위해 생성 아키텍처(예: 확산 모델)에 의존한다. 이러한 공식화는 부분적인 관찰 가능성 및 불확실성으로 인해 부적절할 뿐만 아니라, 작업과 관련 없는 세부 사항을 포착하고 장기 롤아웃에 높은 계산 비용을 부과하여 비효율적이다. 이러한 한계는 원본 픽셀이 아닌 추상적 표현 공간에서 예측하는 월드 모델의 필요성을 강조한다.
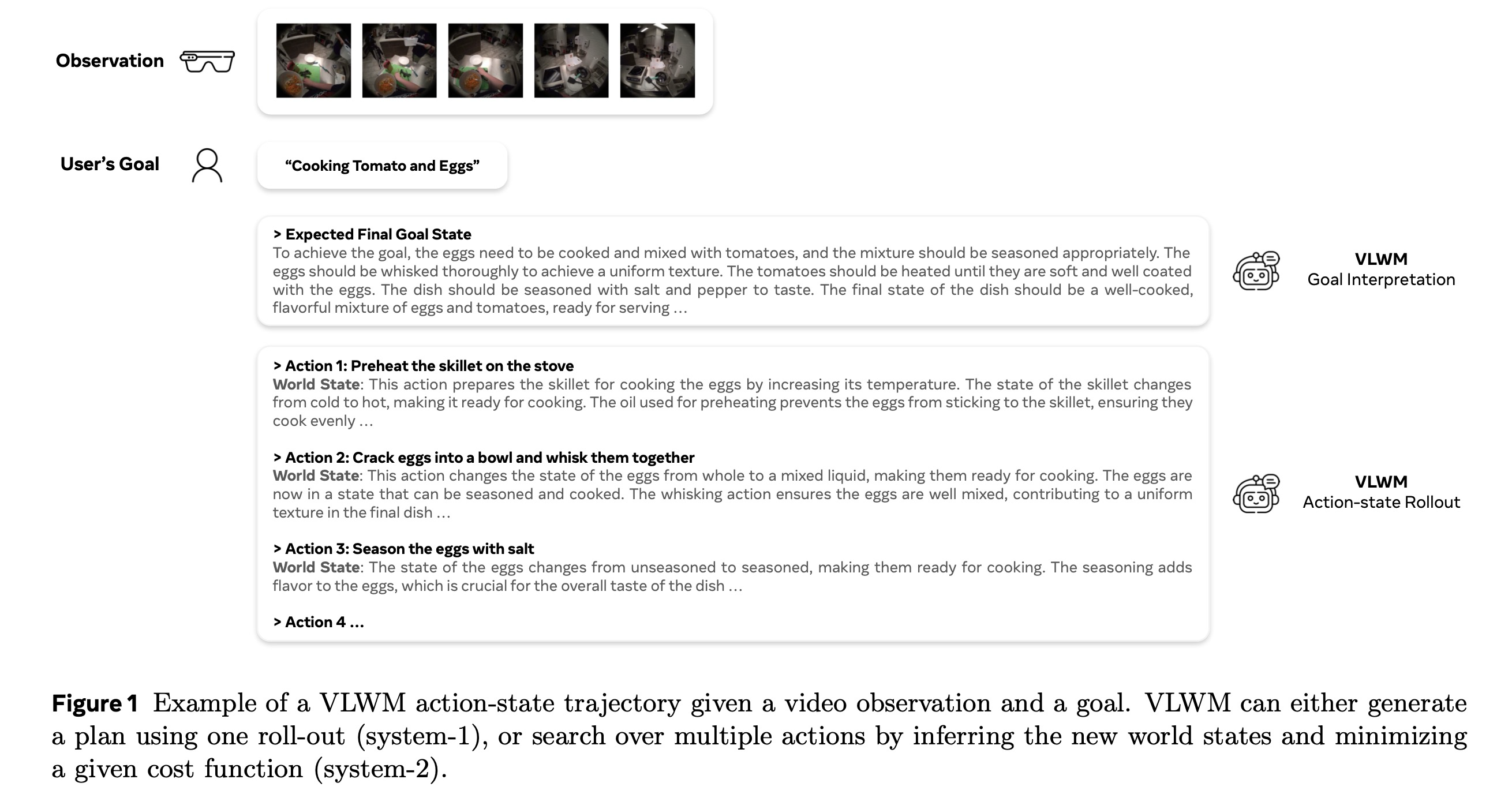
본 연구에서는 자연어를 추상적인 월드 상태 표현으로 활용하는 월드 모델을 학습할 것을 제안한다. 본 논문은 시각적 관찰을 통해 환경을 인식하고 언어 기반 추상화를 사용하여 월드의 진화를 예측하는 Vision Language World Model (VLWM)을 소개한다 (Figure 1). 언어는 본질적으로 의미론적 추상화를 제공하며, 원본 감각 관찰과 비교하여 생성하는 데 계산적으로 훨씬 더 효율적이다. Joint Embedding Predictive Architecture (JEPA) 기반 월드 모델의 잠재 임베딩과 비교할 때, 언어 기반 추상화는 직관적이고 해석 가능하며, 사전 지식 및 LLM/VLM을 위해 개발된 광범위한 엔지니어링 생태계와의 원활한 통합을 가능하게 한다. 주로 인식, 행동 복제(SFT) 또는 검증 가능한 보상을 통한 강화 학습에 초점을 맞춘 현재의 LLM/VLM 패러다임과 비교하여, 본 논문은 방대한, 선별되지 않은 동영상, 즉 보상이 없는 오프라인 데이터를 기반으로 직접적인 월드 모델링을 목표로 수행할 것을 제안한다.
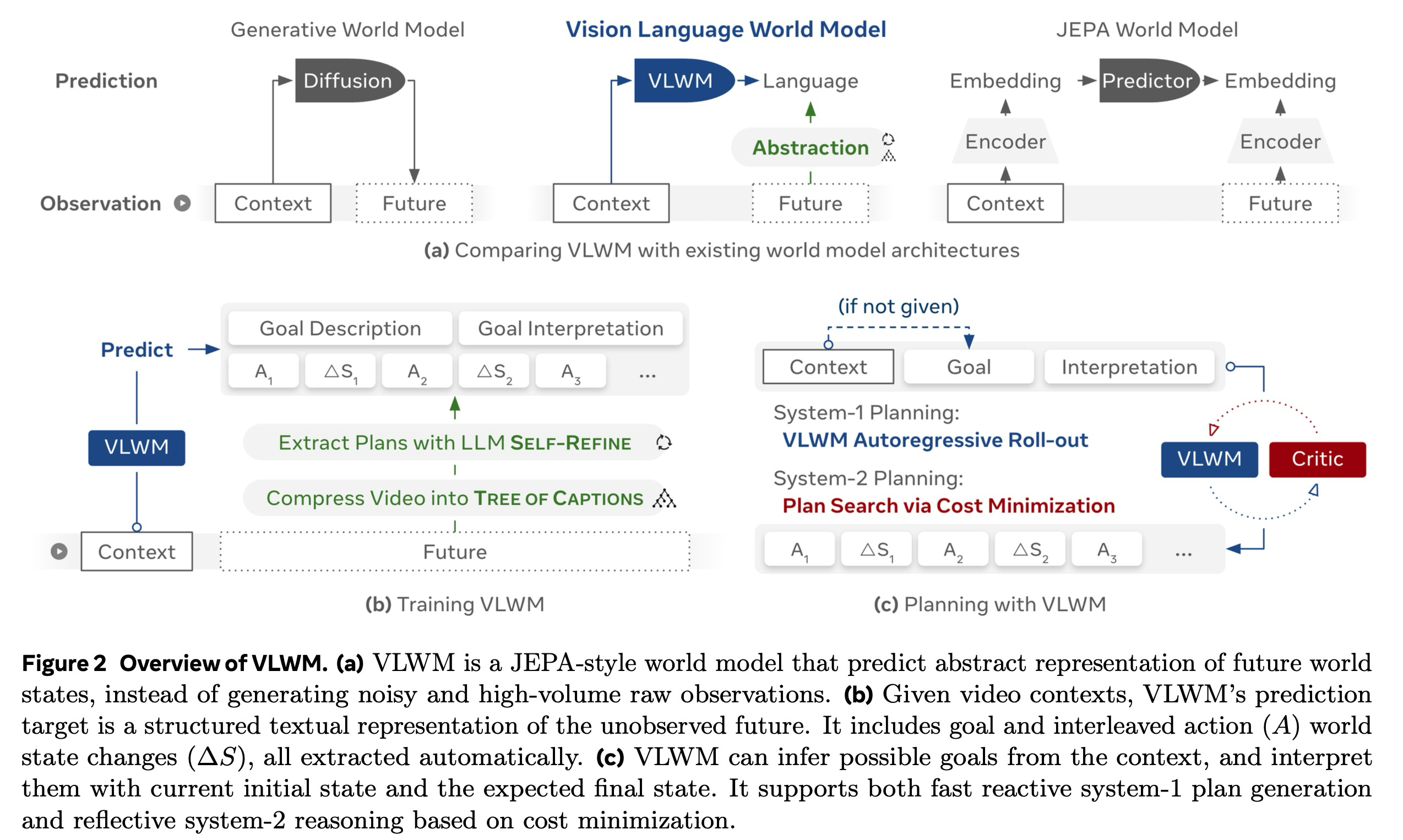
프레임워크의 개요는 Figure 2에 제시되어 있다. 훈련 예측 목표를 구성하기 위해, VLWM은 먼저 원본 동영상을 계층적 Tree of Captions로 압축한 다음, LLM 기반 Self-Refine을 사용하여 구조화된 목표-계획 설명으로 정제하는 효율적인 추상화 파이프라인을 사용한다. 모델은 과거 관찰로부터의 시각적 맥락에 조건화되어 목표 설명, 목표 해석, 행동 () 및 월드 상태 변화 ()를 포착하는 이러한 추상화를 예측하도록 훈련된다. 이를 통해 예측 월드 모델 ()과 행동 정책 ()이 모두 학습된다. 이는 제안된 행동을 정책으로 직접 사용하여 텍스트 완성을 통한 간단한 계획 생성을 가능하게 한다. 본 논문은 이 접근 방식을 시스템-1 계획 수립이라고 명명한다. 그러나 토큰 디코딩의 자기회귀적 특성은 각 행동 결정이 일단 이루어지면 되돌릴 수 없게 되므로, 선견지명과 성찰을 제한한다. 또한, 일반적으로 불완전한 시연을 포함하는 대규모의 실제 동영상 데이터셋으로 훈련할 경우, 결과 정책 역시 데이터에 존재하는 그러한 차선책 행동을 복제하게 된다.
VLWM의 잠재력을 최대한 발휘하기 위해, 본 논문은 성찰적인 시스템-2 "추론을 통한 계획 수립" 모드를 도입한다. 이 모드에서 VLWM은 먼저 행동 후보(자체적으로 제안되거나 외부에서 제공됨)를 기반으로 다중 롤아웃을 생성하고 결과적인 월드 상태를 예측한다. 그런 다음 본 논문은 후보 계획의 적절성을 평가하는 비평가 모듈에 의해 평가되는 스칼라 비용을 최소화하는 후보 행동 시퀀스를 탐색한다. 이 비평가는 자체 지도 학습 목표를 통해 훈련된 언어 모델이다. 이 모델은 목표를 향한 유효한 진행에는 더 낮은 비용을 할당하고, 반사실적이거나 관련 없는 행동에는 더 높은 비용을 할당하도록 학습하며, 각 후보 행동이 원하는 목표 상태와 얼마나 밀접하게 일치하는지를 효과적으로 측정한다. 비용 최소화 후보를 탐색하여 행동 계획을 최적화하는 과정은 추론의 한 형태이다. 이는 에이전트가 학습된 월드 모델을 사용하여 내부적으로 시행착오를 수행하고 최적의 행동 계획을 얻을 수 있도록 한다.
VLWM은 COIN, CrossTask, YouCook2, HowTo100M, Ego4D, EgoExo4D, EPIC-KITCHENS-100을 포함하여 웹 기반 교육 동영상과 1인칭 녹화물 모두의 대규모 코퍼스에서 광범위하게 훈련된다. 총합하여 800일 이상의 기간에 걸친 180,000개의 동영상이 있다. 본 논문은 각 동영상에 대해 Tree of Captions를 생성하여 총 2,100만 개의 고유한 상세 동영상 캡션 노드(2.7조 단어)를 생성한다. 반복적인 LLM Self-Refine을 통해, 본 논문은 570만 단계의 행동 및 상태로 구성된 120만 개의 목표-계획 쌍 궤적을 추출했다. 또한, 본 논문은 NaturalReasoning의 텍스트 전용 사고 연쇄 추론 경로를 행동-상태 궤적으로 재구성하여 추가로 110만 개의 목표-계획 쌍을 확보한다.
본 논문의 평가는 계획 선호도에 대한 인간 평가와 Visual Planning for Assistance (VPA) 벤치마크에서의 정량적 결과를 모두 다루며, SR에서 +20%, mAcc에서 +10%, mIoU에서 +4%의 상대적 개선을 달성한다. 본 논문이 제안한 PlannerArena를 사용한 인간 평가를 기반으로, VLWM 시스템-2 모드에 의해 생성된 절차적 계획이 프롬프팅 기반 방법보다 더 선호된다. RoboVQA 벤치마크에서 VLWM은 74.2의 BLEU-1 점수를 달성하여 강력한 VLM 기준선을 능가한다. 본 논문은 또한 목표 달성 감지를 위해 비평가 모델을 평가하며, 훈련된 비평가는 도메인 내 및 OOD 시나리오 모두에서 기준선 의미론적 유사성 모델보다 뛰어난 성능을 보인다. 또한 WorldPrediction 절차적 계획 작업에서 45% 정확도로 최첨단 성능을 확립한다. 모델과 데이터는 오픈 소스로 공개될 예정이다.
2. Methodology
우리는 행동이 물리적 월드 상태에 어떻게 영향을 미치는지 이해하고 예측하는 월드 모델을 훈련하고, 월드 모델이 핵심 구성 요소로 기능하는 추론 및 계획을 위한 프레임워크를 개발하는 것을 목표로 한다. 우리의 접근 방식은 LeCun (2022) (JEPA)에 의해 소개된 에이전트 아키텍처를 기반으로 하며, 이 아키텍처에서는 보상에 무관한(reward-agnostic) 월드 모델이 후보 행동 계획이 주어지면 롤아웃을 수행한다. 그리고 에이전트는 각 롤아웃이 현재 상태를 원하는 목표로 얼마나 가깝게 진전시키는지 평가하며, 이 거리(즉, 비용)를 최소화하는 계획을 선택한다.
다음 섹션들에서, §2.1은 효율성 고려 사항과 품질 최적화 전략을 위한 의미론적 압축 기술을 포함하여, 우리가 미래 월드 상태 추상화로서 구조화된 언어 기반 표현을 추출하는 방법을 상세히 설명한다. 이어서, §2.2는 비평가(critic)가 자체 지도 학습 방식으로 비용을 평가하도록 훈련되는 방법과 비용 최소화를 기반으로 하는 시스템-2 계획 탐색을 설명한다.
2.1 Vision-Language World Modeling
동영상이 주어지면, 우리는 목표(설명 및 해석)와 절차적 계획(행동-상태 시퀀스)으로 구성된, 그림 2 (b)에 나타난 구조화된 언어 표현을 추출하는 것을 목표로 한다. 이러한 비디오-텍스트 추출 작업의 경우, 한 가지 간단한 접근 방식은 전체 동영상을 VLM에 제공하고 언어 표현을 추출하도록 프롬프트를 사용하는 것일 수 있다. 그러나 불가능한 삼각 관계가 발생하는데, 실용적인 컴퓨팅 및 메모리 예산 내에서 1) 미세한 인식을 위한 높은 공간 해상도, 2) 많은 절차적 단계를 포괄하는 긴 시간적 범위, 그리고 3) 복잡한 명령을 따를 수 있는 크고 스마트한 VLM의 사용, 이 세 가지를 동시에 달성하는 것은 실현 가능하지 않다.
이 문제를 해결하기 위해, 우리는 2단계 전략을 제안한다. 첫째, 입력 동영상을 먼저 조밀한 Tree of Captions로 압축하며, 이는 필수적인 의미론적 정보를 보존하는 동시에 데이터 볼륨을 현저히 줄인다(§2.1.1). 그런 다음, 이러한 캡션으로부터 LLM을 사용하여 구조화된 목표-계획 표현을 추출한다. 두 번째 단계는 순전히 텍스트로 작동하기 때문에, 이는 대규모 LLM을 사용한 효율적인 처리를 가능하게 하며 Self-Refine을 통한 반복적인 품질 개선을 허용한다(§2.1.2).
2.1.1 Compress Video into Tree of Captions
각 캡션 트리는 동영상의 서로 다른 국소 창(local windows)에서 독립적으로 생성된 캡션들로 구성되며, 이들은 전체적인 세부 국소 정보와 장기적인 전역 정보를 모두 포착하는 것을 목표로 계층적 트리 구조를 형성한다. 핵심 과제는 캡션 생성을 위한 다양한 수준의 창 배열, 즉 트리 구조를 적응적으로 결정하는 데 있다. 이상적으로, 각 노드 또는 리프(leaf)는 응집성 있는 단일 의미 단위(monosemantic unit)에 해당해야 하며, 의미론적 경계를 넘어 확장되는 것을 피해야 한다. 기존의 시간적 행동 지역화 및 분할 모델은 폐쇄된 어휘 행동 분류법(closed-vocabulary action taxonomies)에 대한 인간 주석에 의존하고 일반적으로 좁은 동영상 도메인에서 훈련되므로 개방성(openness)에 한계가 있다.
우리는 계층적 군집화(hierarchical feature clustering)를 통해 트리 구조를 생성할 것을 제안한다. 구체적으로, 를 트림되지 않은(untrimmed) 동영상이라고 하고, 그 특징 스트림을 라고 하자. 여기서 각 는 동영상 인코더 에 의해 생성된 -차원 특징 벡터이다. 우리는 계층적 병합 군집화(hierarchical agglomerative clustering)를 사용하여 특징 스트림 와 그 기초 동영상 를 분할한다. 가장 세밀한 단위—각 항목 를 개별 클러스터로 취급—에서 시작하여, 이 알고리즘은 세그먼트 내 특징 분산(within-segment feature variance)의 가장 작은 증가(즉, 다중 의미성(polysemanticity)의 척도)를 가진 인접 세그먼트를 반복적으로 병합한다. 이 병합 절차는 단일 루트 노드만 남을 때까지 계속되며, 전체 추적은 각 노드가 동영상의 한 세그먼트에 해당하는 계층적 구조를 제공한다.
의 선택은 분할의 동작을 결정한다. 본 논문에서는 동영상에서 장면 및 행동 정보 추출에 탁월한 최첨단 모델인 Perception Encoder를 채택한다. 계층적 트리 구조가 구축되면, 우리는 5초보다 짧은 짧은 세그먼트를 제외하고 각 동영상 세그먼트에 대한 상세 캡션을 생성한다. 상세 동영상 캡션 생성을 위해 PerceptionLM을 사용한다. 결과적으로 생성된 캡션 트리는 상당한 압축을 달성한다. 예를 들어, Ego4D의 1.1 TB 동영상 파일은 900MB 미만의 캡션 파일로 압축될 수 있다.
2.1.2 Extract Plans with LLM Self-Refine
동영상에서 추출된 압축된 Tree of Captions가 주어지면, 다음 목표는 VLWM을 위한 예측 목표로 사용될 구조화된 텍스트 표현을 도출하는 것이다. 이 표현은 다음 네 가지 구성 요소로 이루어진다:
- 목표 설명 (Goal description): 전체적인 달성 내용에 대한 고수준 요약이다 (예: "토마토와 달걀 요리하기"). 하위 응용 프로그램에서 사용자로부터 주어지는 목표 설명은 일반적으로 간결하여 (예: 단일 문장), 최종 상태를 총체적으로 정의하는 세부 정보가 생략되는 경우가 많으므로, 명시적인 목표 해석이 필요하다.
- 목표 해석 (Goal interpretation): 도구, 재료, 종속성 등의 현재 상태를 설명하는 초기 월드 상태와 예상되는 최종 월드 상태를 모두 개괄하는 문맥적 설명을 포함한다. 초기 상태는 계획 생성에 필수적인 접지(grounding)를 제공한다. 최종 상태는 시스템-2 계획 수립에서 비용 평가를 용이하게 하기 위해 목표 설명을 구체적으로 해석한다. 예를 들어, "목표를 달성하기 위해, 달걀은 조리되어 토마토와 섞여야 하며, 혼합물은 적절하게 간을 맞춰야 한다. 달걀은 균일한 식감을 얻기 위해 완전히 휘저어야 한다..."와 같다.
- 행동 설명 (Action description): 실행을 위해 하위 구현체(embodiments)에 전달되거나 사용자에게 제시될 시스템의 최종 출력이다 (예: "스토브에 프라이팬 예열하기"). 수신자가 의도된 월드 상태 전환을 이해하고 수행할 수 있도록 명확하고, 간결하며, 충분히 정보적이어야 한다.
- 월드 상태 (World states): 시스템의 내부 요소이며, 추론 및 계획 탐색을 위한 중간 표현 역할을 한다. 이는 정보 병목(information bottleneck) 역할을 해야 하는데, 작업과 관련된 행동의 모든 결과를 충분히 포착하는 동시에 최소한의 중복성을 포함해야 한다. 예를 들어: "이 행동은 프라이팬의 온도를 높여 달걀 요리를 위한 준비를 한다. 프라이팬의 상태는 차가움에서 뜨거움으로 바뀌어 요리 준비가 완료된다. 예열에 사용되는 기름은 달걀이 프라이팬에 달라붙는 것을 방지하여 달걀이 고르게 조리되도록 보장한다..."와 같다.
생성된 구성 요소가 이러한 요구 사항을 충족하도록 보장하기 위해, 우리는 LLM을 최적화 도구로 활용하는 반복적인 Self-Refine 절차를 채택한다. 먼저 LLM에게 출력 요구 사항에 대한 상세한 설명, 예상 형식의 예시, 그리고 입력으로서 형식화된 Tree of Captions를 제공하여 초안(initial draft)을 생성하도록 한다. 각 개선 반복(refinement iteration)에서, LLM은 현재 초안에 대한 피드백을 제공하고 그에 따라 수정된 버전을 생성한다. 이 자기 개선(self-refinement) 과정은 미리 정의된 횟수만큼 반복되어 출력 품질을 점진적으로 최적화한다.
Tree of Captions를 LLM에 입력하기 위해, 우리는 깊이 우선 탐색(DFS) 순서를 사용하여 이를 형식화한다. 이 선형화(linearization)는 LLM이 일반적으로 훈련되고 익숙한 텍스트 문서의 계층적 구조와 일치한다. 본 논문에서는 효율적인 추론과 확장된 컨텍스트 길이 지원을 위해 Llama-4 Maverick을 사용한다. Self-Refine 방법론은 특정 LLM 아키텍처에 맞춤화된 것은 아니다. 제공된 피드백 메시지 예시는 다음과 같은 개선 원칙들을 보여줍니다:
"호박 카레를 위한 재료 준비"와 같은 행동은 "호박을 씻고, 껍질을 벗기고, 다지기" 그리고 "양파와 토마토를 다지기"와 같이 더 구체적인 행동으로 나누어질 수 있습니다.
양파, 생강, 마늘, 청양고추를 볶은 후의 상태 변화는 이 단계가 카레의 전반적인 풍미와 식감에 어떻게 영향을 미치는지에 대한 더 많은 세부 정보를 포함해야 합니다.
"호박 카레를 그릇에 담아 전시"하는 행동은 과제 진행을 진전시키는 의미 있는 행동이라기보다는 보여주기 위한 단계이므로, 단계 목록에서 제거되어야 합니다.
2.1.3 Training of Vision Language World Model
VLWM의 훈련 태스크는 식 (1)에 정의된다. 여기서 설정(config)은 시스템 프롬프트 역할을 한다. 문맥(context)은 환경 정보를 제공하며, 시각적, 텍스트적, 또는 둘 다일 수 있다. VLWM은 다음 요소들로 표현되는 미래를 예측하도록 훈련된다: (1) 목표 설명과 그 해석 (즉, 초기 상태 및 예상 최종 상태), (2) 순차적인 행동 () 상태 ( 쌍으로 구성된 궤적. VLWM은 식 (1)의 우변에 있는 다음 토큰 예측에 대한 교차 엔트로피 손실을 최적화한다.
이러한 입출력 공식화는 세 가지 수준의 월드 모델링을 반영한다: 1) 문맥적 목표 추론, 즉 가능한 미래 성과에 대한 예측, 2) 행동 예측, 즉 가능한 다음 행동을 제안하는 것, 그리고 3) 행동에 조건화된 월드 상태 동적 예측이다. 행동과 결과적인 상태 변화가 교차되고 자기회귀적인 방식으로 생성되기 때문에, 이는 직접적인 텍스트 완성을 통한 시스템-1 반응형 계획 수립을 용이하게 한다. 설정, 문맥, 그리고 목표 설명이 주어지면, VLWM은 목표를 해석하고 <eos> 토큰에 도달할 때까지 일련의 행동-상태 쌍을 생성한다. 언어 모델링 관점에서, 월드 상태 설명은 내부적인 사고의 연쇄(chains of thought) 역할을 하며, 이는 각 행동의 결과를 명료하게 표현하여 VLWM이 과제 진행 상황을 추적하고 목표를 향한 적절한 다음 단계를 제안하도록 허용한다. 이 계획 모드는 계산적으로 효율적이며 단기적, 단순하고, 도메인 내의 과제에 적합하다.
식 (1)의 (동영상, 텍스트) → 텍스트 공식화 덕분에, 사전 훈련된 VLM을 사용하여 VLWM을 초기화할 수 있다. 이는 VLWM에 강력한 시각적 인지 능력을 제공하는 동시에, LLM의 언어 이해 및 생성 능력, 그리고 상식 지식(commonsense knowledge)을 상속받을 수 있게 한다.
2.2 Planning with Reasoning
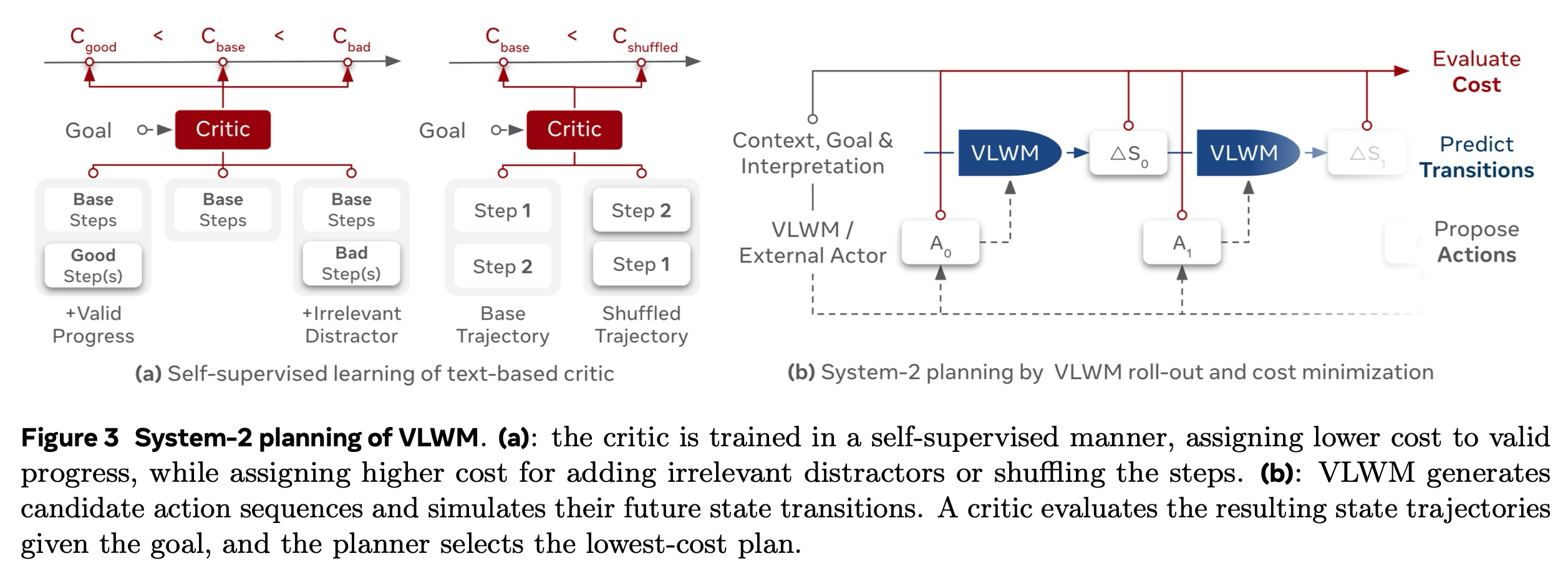
시스템-1 모드는 빠른 계획 생성을 가능하게 하지만, 선견지명(foresight)을 갖거나, 대안을 평가하거나, 차선책 결정을 수정할 수 있는 능력이 부족하다는 한계가 있다. 일단 행동이 방출되면 그것은 고정되어 버리므로, 모델이 오류를 재고하거나 수정하는 것을 방지한다. 이러한 반응적 행동은 특히 장기적인 목표를 갖거나 복잡한 작업에서 오류 누적을 초래할 수 있다. 이러한 한계를 해결하기 위해, 우리는 시스템-2 성찰적 계획 수립(System-2 Reflective Planning)을 도입하는데, 이 방식에서는 월드 모델이 목표가 주어졌을 때 여러 예측된 미래의 바람직함(desirability)을 평가하는 비평가(critic) 모듈과 결합된다. 이는 비용 최소화를 통한 최적의 계획 탐색을 포함하는 추론 과정을 가능하게 한다.
2.2.1 Learning the Critic from Self-supervision
월드 모델 기반 계획 수립에서, 비용 함수는 일반적으로 후보 계획으로부터 발생하는 월드 상태와 원하는 목표 상태 사이의 거리를 정량화한다. 이 비용은 현재 과제 진행 상황이 의도된 목표 및 예상 최종 상태와 얼마나 잘 일치하는지에 대한 추정치를 제공한다. JEPA 월드 모델에서는 이것이 월드 상태의 고정 차원 임베딩 표현 간의 L1 또는 L2 거리로 직접 측정될 수 있다. 그러나 VLWM의 경우, 토큰 공간에서 거리를 계산하는 대신 언어 기반 월드 상태 표현 간의 의미론적 거리를 측정해야 한다.
공식적으로, 식 (1)에 기술된 VLWM 예측이 주어졌을 때, 우리는 을 평가하는 거리 함수인 비용 를 확립하는 것을 목표로 한다. 이상적으로, 예측된 궤적이 목표를 향한 의미 있는 진전을 반영할 때 비용은 낮아야 하며, 무관하거나 오류가 있는 행동으로 인해 궤적이 이탈할 경우 비용은 높아야 한다. 이 동작을 모델링하기 위해, 우리는 자체 지도 학습 방식으로 언어 모델을 훈련하며, 이를 통해 명시적인 주석 없이도 예측된 계획의 의미론적 품질을 평가할 수 있게 한다. 그림 3 (a)에 나타낸 바와 같이, 우리는 비평가를 위한 두 가지 유형의 자체 지도 훈련 신호를 탐구한다:
- 우리는 기본 부분 궤적에서 시작하여 훈련 샘플을 구성하고, 여기에 (i) 과제의 일관된 연속으로부터 발생하는 유효한 다음 단계를 추가하거나, (ii) 무관한 과제에서 샘플링된 방해 단계를 추가한다. 비평가는 세 가지 비용 점수 를 독립적으로 예측하며, 모델은 순위 제약 를 충족하도록 훈련된다. 이는 비평가가 의미 있는 진전을 무관하거나 오해의 소지가 있는 연속과 구별하도록 장려한다.
- 우리는 기본 궤적의 단계를 무작위로 섞어서 부정적인 샘플을 생성하고, 비용 를 가진 손상된 시퀀스를 만든다. 그런 다음 비평가는 를 강제하도록 훈련되며, 이는 절차적 순서와 시간적 일관성에 대한 민감도를 보장한다.
비평가는 고정된 마진을 가진 다음 순위 손실을 최소화하도록 훈련되며, 작은 상수 로 가중치가 부여된 비용 중심화 정규화 항이 보완된다. 훈련 쌍 를 구성하기 위해, 위에서 설명한 세 가지 유형의 자체 지도 신호 () 전체를 반복한다.
VLWM 진행 데이터 외에도, 비평가 공식은 일반화 향상을 위해 외부 소스의 지도도 지원한다. 예를 들어, 질의(query), 선호되는 (선택된) 응답, 그리고 거부된 응답의 세 쌍으로 구성된 선호도 튜닝 데이터셋은 직접 활용될 수 있다. 마찬가지로, 비평가는 의미론적 거리를 모델링하는 것을 목표로 하므로, 문장 임베딩 학습을 위해 설계된 세 쌍 기반 데이터셋으로부터도 이점을 얻을 수 있다. 이러한 소스들은 비평가의 훈련 데이터를 더욱 보강하는 데 사용될 수 있는 추가적인 긍정/부정 쌍을 제공한다.
2.2.2 System-2 Planning by Cost Minimization
시스템-2 계획 수립은 VLWM, 비평가(critic), 그리고 행위자(actor)라는 세 가지 구성 요소의 조정을 포함한다. 그림 3(b)에 나타난 바와 같이, 행위자는 후보 행동 시퀀스를 제안하고, VLWM은 그 효과를 시뮬레이션하며, 비평가는 그 비용을 평가한다. 최종 계획은 예측된 비용이 가장 낮은 후보 시퀀스를 식별함으로써 선택된다.
행위자는 VLWM 자체로 구현되거나, 특히 행동 공간이나 출력 형식에 대한 추가적인 제약 조건이 준수되어야 하는 경우 외부 모듈(예: LLM)로 구현될 수 있다. 행위자는 탐색 폭을 제어하기 위해 제안되는 후보의 수를 다양화하거나, 더 효율적인 트리 탐색을 가능하게 하기 위해 부분적인 계획을 생성할 수 있다. 비평가가 평가한 비용 외에도, 과제별 패널티(task-specific penalties) 또는 안전 장치(guard-rails)가 비용 함수에 통합될 수 있으며, 이는 계획 수립자가 외부 제약 조건, 안전 규칙 또는 도메인별 선호도를 준수하도록 허용한다.
3. Experiments
3.1 Implementation Details
3.1.1 VLWM-8B
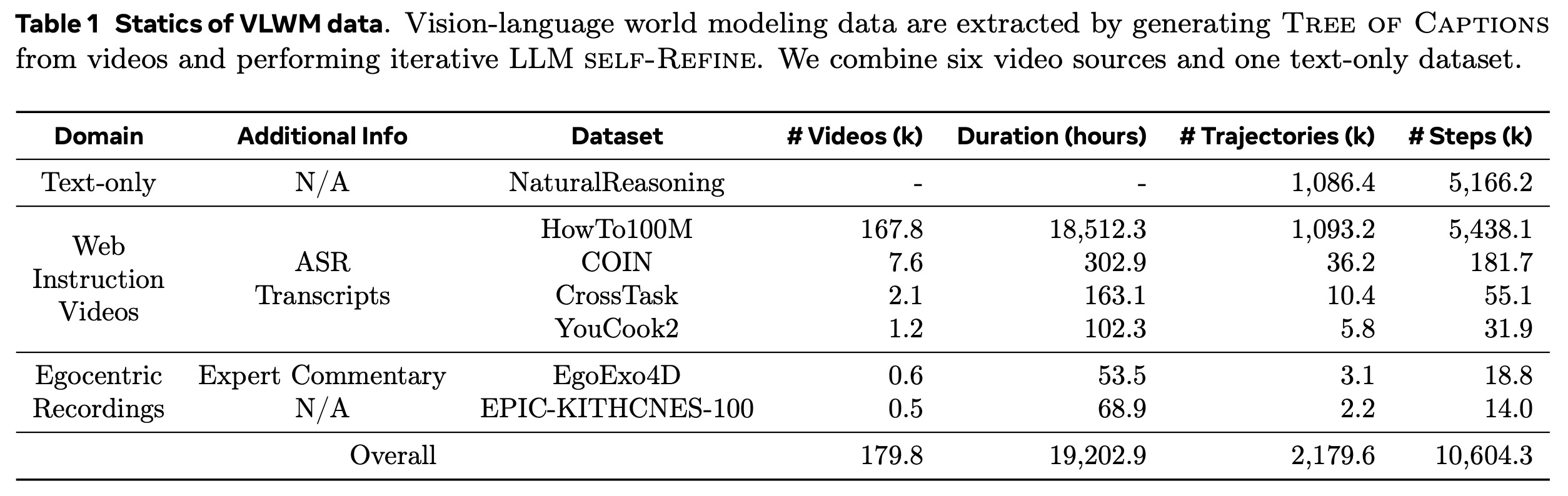
Sources of Videos. 표 1에 요약된 바와 같이, 시각-언어 월드 모델링을 위한 훈련 동영상은 두 가지 주요 도메인에서 가져온다: 1) 웹 교육 동영상: COIN, CrossTask, YouCook2, 그리고 HowTo100M 동영상의 일부이다. 이 동영상들은 다양한 범위의 과제를 다루며 깨끗한 전문가 시연을 제공한다. 2) 1인칭 녹화물 (Egocentric recordings): EPIC-KITCHENS-100 및 EgoExo4D이다. 이 동영상들은 현실적인 웨어러블 에이전트 시나리오에서 연속적이고 편집되지 않은 녹화물을 특징으로 한다. 모든 데이터셋에 대해, 우리는 해당 훈련 분할(training split)에서 동영상을 수집한다. 대규모 1인칭 녹화물 데이터셋으로 Ego4D가 사용 가능하지만, 우리는 훈련 데이터에서 이를 제외했는데, 이는 일관성 없는 훈련/검증 분할로 인해 벤치마크와의 잠재적인 중복을 피하기 위함이다.
Generation of Vision-language World Modeling Data. 우리는 Perception Encoder PE-G14와 PerceptionLM-3B (320x320 공간 해상도, 입력당 32프레임 - 32GB V100에 적합)를 사용하여 Tree of Captions를 생성한다. 우리는 트리 구조에 따라 동영상당 최대 5개의 목표 창(target window)을 샘플링하고(BFS 탐색 순서에서 처음 5개의 노드), Llama-4 Maverick (128개의 전문가 혼합, 17B 활성화 및 총 400B 매개변수, FP8 정밀도)을 사용하여 해당 캡션 서브트리와 두 번의 Self-Refine을 통해 창에서 계획을 추출한다. 웹 동영상에 대한 추가 음성 전사(ASR Transcripts)와 EgoExo4D의 전문가 해설은 계획 추출 중 LLM의 동영상 이해를 개선하기 위해 동영상 캡션과 함께 제공된다. 동영상 기반 추출 외에도, 우리는 NaturalReasoning 데이터셋을 사고 연쇄(chain-of-thoughts)를 Tree of Captions로 대체하여 월드 모델링에 용도를 변경한다. 행동-상태 궤적은 유사한 프롬프트를 사용하여 LLM Self-Refine에 의해 추출된다.
Training Details. 우리는 PerceptionLM-8B로 VLWM을 초기화한다. 모델은 배치 크기 128과 최대 11.5k 토큰 컨텍스트 길이로 훈련된다. 시각적 컨텍스트 입력에 대해 448x256 해상도에서 32프레임을 균일하게 샘플링한다. 8개의 H100 GPU로 구성된 12개 노드를 사용하여, 훈련에는 약 5일이 소요된다.
3.1.2 VLWM-critic-1B
Data. 우리는 HowTo100M 및 NaturalReasoning의 시각-언어 월드 모델링 데이터로부터 §2.2.1에 따라 쌍으로 구성된 데이터를 생성한다. 또한 서브트리(subtrees)를 샘플링하고 루트(root)를 목표(goal)로, 리프(leafs)를 궤적(trajectories)으로 사용하여 Tree of Captions 데이터를 포함한다. 우리는 또한 비평가 훈련을 위해 기성 선호도 모델링 데이터를 통합하며, 여기서 사용자 질의(query)는 목표로 취급되고 모델 응답은 행동으로 취급된다. 우리는 <"query" + "chosen" 및 "query" + "rejected">를 사용하여 를 도출한다. 우리는 UltraFeedback, Orca DPO 쌍, Math-Step-DPO을 선호도 데이터 소스로 포함한다. 마지막으로, 의미론적 유사성 학습을 위한 훈련 데이터를 통합하는데, 여기서 우리는 <query, positive sentence, negative sentence> 세 쌍을 쿼리(query)는 목표로, 긍정적인 문장은 긍정적인 행동으로, 부정적인 문장은 부정적인 행동으로 변환한다. 이러한 유형의 데이터에는 MS-MARCO, SQUAD, HotPotQA, NaturalQuestions, 그리고 FEVER가 포함된다.
Training Details. 비평가 모델은 Llama-3.2-1B로부터 초기화되며, 128의 배치 크기(2.7k 단계)와 1536 토큰의 최대 컨텍스트 길이로 단일 H100 GPU 8개 노드를 사용하여 1 에포크 동안 훈련된다. 식 (2)의 하이퍼파라미터에 대해, 우리는 및 로 설정한다.
3.2 Visual Planning for Assistance (VPA)
3.2.1 VPA Benchmarks
VLWM의 대규모 사전 훈련이 절차적 계획 수립에서 실제적인 이득을 가져오는지 확인하기 위해, 우리는 Visual Planning for Assistance (VPA) 벤치마크를 채택한다. VPA는 모델이 동영상 기록(video history)과 명시적인 텍스트 목표가 주어졌을 때 진행 중인 활동의 다음 단계 고수준 행동을 얼마나 잘 예측할 수 있는지를 측정한다. 우리는 표준 평가 수평선인 과 를 따른다. 실험은 절차적 계획 수립을 위해 널리 사용되는 두 가지 교육 동영상 코퍼스에서 수행된다. COIN은 180개의 과제에 걸쳐 11,827개의 동영상을 포함하며, CrossTask는 18개의 과제에 걸쳐 2,750개의 동영상을 포함한다. 우리는 공식 훈련/검증/테스트 분할을 엄격히 준수하여 결과가 이전 연구와 직접 비교 가능하도록 한다.
우리는 VLWM을 네 가지 최첨단 플래너(DDN, LTA, VLaMP, VidAssist) 및 두 가지 빈도 기반 발견법(휴리스틱)(Most-Probable(전역 행동 빈도), Most-Probable w/ Goal(과제 조건부 빈도))과 비교 벤치마킹한다. VLWM은 사전 훈련과 동일한 하이퍼파라미터를 사용하여 COIN 및 CrossTask의 VPA 훈련 분할에 대해 미세 조정된다. 이전 연구를 따라, 우리는 예측된 단계 시퀀스에 대한 성공률(Success Rate, SR), 평균 정확도(Mean Accuracy, mAcc), 그리고 평균 IoU(Mean IoU, mIoU)를 보고하며, 이는 각각 계획 수준 정확도, 단계 수준 정확도, 그리고 행동 제안 정확도를 측정한다.
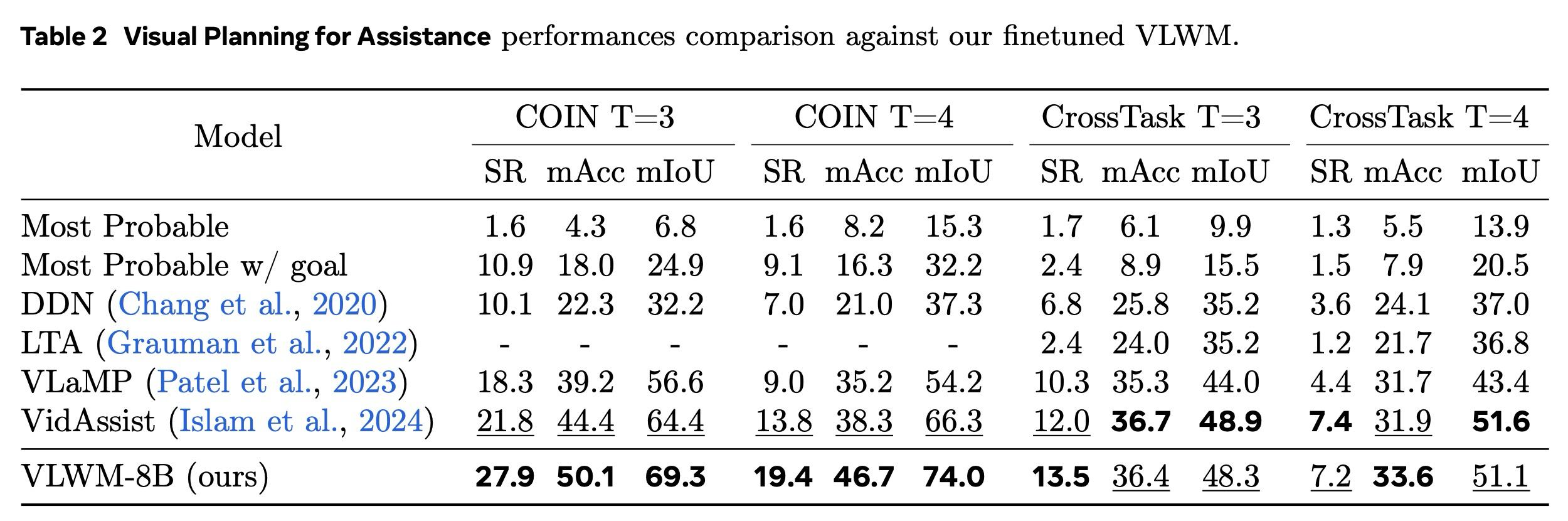
표 2는 VLWM이 VPA 벤치마크에서 새로운 최첨단 성능을 설정함을 확인한다. COIN과 CrossTask 모두에서, 그리고 과 두 수평선 모두에서, 우리 모델은 기존 기준선을 일관되게 능가한다. 70B LLM을 채택한 VidAssist와 비교했을 때, 우리의 VLWM은 훨씬 작지만(8B) 12개의 메트릭 중 8개에서 우수한 결과를 달성한다. 네 가지 설정 전체에서 평균적으로, VLWM은 SR에서 +3.2%, mAcc에서 +3.9%, mIoU에서 +2.9% 포인트의 절대적인 이득을 제공한다.
3.2.2 Human Evaluation with PlannerArena
인간 중심적인 계획을 생성하는 구현된(embodied) AI 어시스턴트를 위한 전통적인 벤치마크는 편향되거나 품질이 낮은 정답 데이터에 의존하여 실제 성능과 인간 지원을 포착하는 데 부적절하다,. 이 문제를 극복하기 위해, 우리는 ChatbotArena에서 영감을 받은 PlannerArena라는 인간 평가 프레임워크를 만들었다,. 이 Arena/Elo 기반 시스템은 인간 평가자가 익명 모델들이 생성한 계획들 중에서 더 나은 계획을 쌍별로 선택하는 것을 포함하며, 그 결과는 Elo 점수와 모델 승률로 변환된다. 이 접근 방식은 AI 어시스턴트의 실제 사용 사례와 밀접하게 일치하여, 우리가 개발하는 모델이 이론적으로 건전할 뿐만 아니라 실제 세계에서 실용적인 가치를 갖도록 보장한다.
우리의 실험 설정은 세 가지 데이터셋(COIN, CrossTask, EgoExo4D)을 포함하며, 여기서 우리는 VLWM 시스템-2(생성된 계획의 비용을 최소화하는 8B 비평가에 의해 탐색되는 20개 계획에 대한 탐색과 함께)와 비용을 최대화하는 8B 비평가를 사용하는 VLWM을 선도적인 다중 모드 LLM 및 정답 계획과 비교한다. 쌍들은 균형 잡힌 수의 대결을 위해 가능한 모든 대결 구성에 걸쳐 균일하게 샘플링된다,. 모델들은 초기 점수 1000점에서 시작하며, 각 대결 후 점수 업데이트를 위해 Elo K-인수(K-factor) 32를 사용한다. 총 5명의 주석가(annotator)가 PlannerArena 평가에 참여하여 총 550쌍의 대결을 평가했으며, 3명의 주석가는 주석가 간 일치도 점수를 계산하기 위해 90개의 샘플로 구성된 고정된 파일럿 실행을 수행했다,. PlannerArena에 대한 추가 세부 정보는 부록에서 찾을 수 있다.
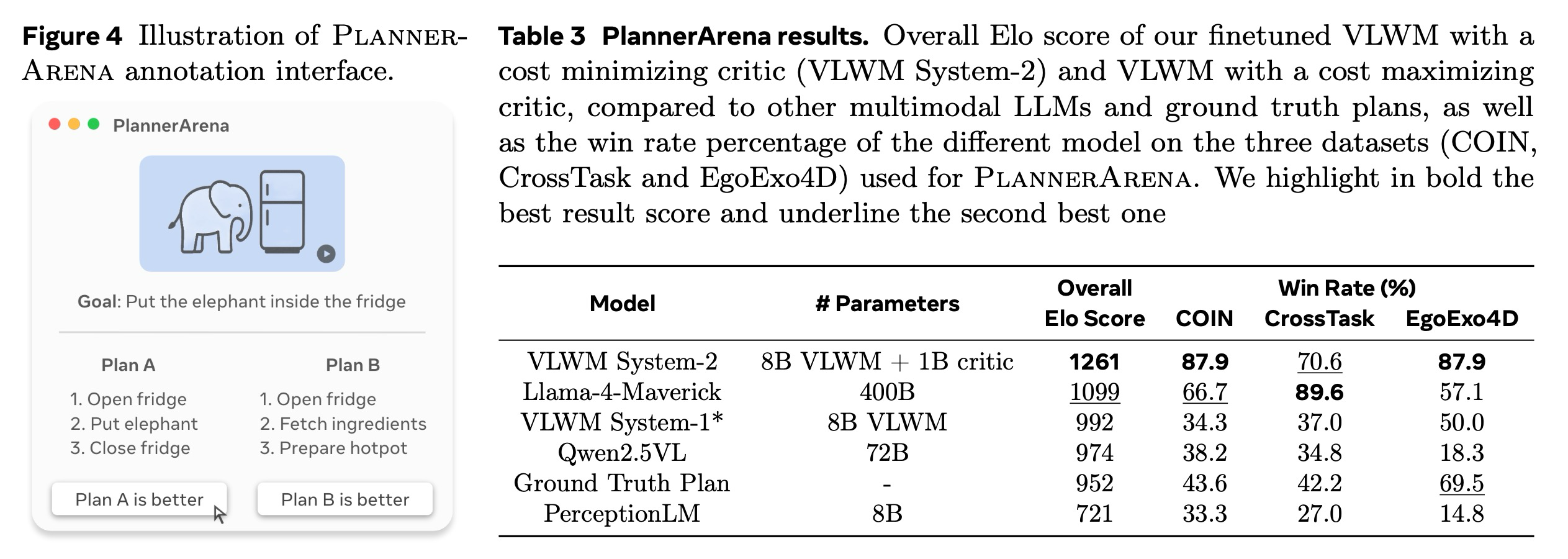
우리는 그림 4에서 다양한 모델의 최종 Elo 점수와 각 모델의 데이터셋별 승률을 보여준다,. VLWM 시스템-2는 1261점으로 가장 높은 Elo 점수를 기록하며 큰 차이로 선두를 차지했으며, Llama-4-Maverick이 1099점으로 두 번째로 선호되는 모델이었다,. 비용을 최대화하는 비평가를 사용했음에도 불구하고, VLWM 비용 최대화 모드(992 Elo 점수)로 생성된 계획은 여전히 정답 및 Qwen2.5, PerceptionLM이 생성한 계획보다 일반적으로 더 선호되었는데, 이들은 비디오 컨텍스트가 주어졌을 때 의미 있는 계획을 생성하는 데 더 어려움을 겪는다,. 중요하게도, 우리는 정답의 품질이 전반적으로 좋지 않고 데이터셋 전반에서 강한 편차가 있음을 확인한다,. EgoExo4D는 더 높은 품질의 주석을 가지고 있으며, 정답 계획은 VLWM 시스템-2(87.9% 승률)에 이어 두 번째로 높은 69.5%의 승률을 보인다. 그러나 COIN 및 CrossTask에서 정답 계획은 최악의 성능을 보이는 모델보다 겨우 나은 수준(각각 43.6% 및 42.2%)이었으며, 이는 현재 절차적 계획 데이터셋의 주요 문제점을 강조한다.
3.3 RoboVQA
VLWM의 접지된(grounded) 고수준 추론 및 계획 능력을 더욱 평가하기 위해, 우리는 RoboVQA 벤치마크에서 이를 평가한다. RoboVQA는 모델이 현실적인 다중 구현체(multi-embodiment) 환경에서 로봇 중심의 시각 질문 응답을 수행하도록 요구하며, 복잡한 시각 장면의 이해와 일관된 행동 시퀀스의 실행을 필요로 한다. 이 벤치마크는 VLWM이 로봇 에이전트를 효과적으로 안내하는 능력을 테스트함으로써 절차적 계획 평가를 보완한다. 우리는 RoboVQA의 표준 평가 프로토콜을 따르며 BLEU 점수를 사용하여 VLWM의 성능을 비교한다. 우리는 우리의 모델을 최첨단 로봇 LLM들인 3D-VLA-4B, RoboMamba-3B, PhysVLM-3B, RoboBrain-7B, ThinkVLA-3B, 그리고 ThinkAct과 비교한다.
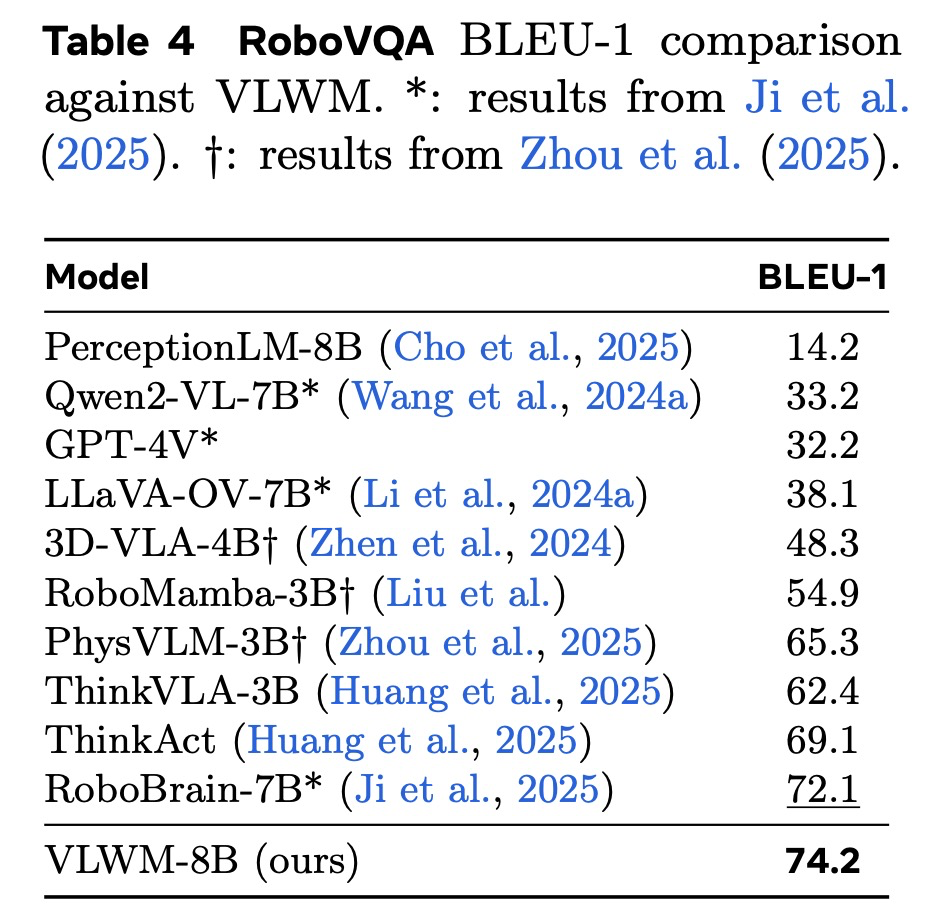
표 4는 VLWM이 RoboVQA 벤치마크에서 매우 경쟁력 있는 성능을 달성함을 보여준다. RoboBrain과 같은 일부 최고 성능 모델들처럼 로봇 데이터에 특화되어 있지 않음에도 불구하고, VLWM은 모든 n-gram 수준에서 강력한 BLEU 점수를 얻으며 상위 두 모델 내에 랭크된다. 특히, VLWM은 55.6의 가장 높은 BLEU-4 점수를 달성하여 RoboBrain의 55.1을 능가하며, BLEU-1에서 BLEU-3까지 근소한 차이로 뒤따른다. 이러한 결과는 VLWM의 강력한 일반화 능력과 구현체(embodied) 환경에서 접지된 추론 및 계획을 위해 시각 및 언어 정보를 효과적으로 통합하는 능력을 강조한다.
3.4 Critic Evaluations
이 섹션에서는 VLWM-8B 롤아웃과 독립적으로 비평가 모델이 의도된 동작을 나타내는지 평가하기 위해 본질적인 평가(intrinsic evaluations)를 수행한다.
3.4.1 Goal Achievement Detection
Task Definition. 목표와, 목표를 달성하는 참조 계획 중 단계의 연결된 궤적, 그리고 그 뒤에 추가된 개의 무관한 단계로 구성된 궤적이 주어지면, 이 과제는 비평가 모델이 시작부터 모든 부분 진행 단계에 대해 독립적으로 비용을 평가하도록 요청한다. 즉, 까지 평가한다. 목표까지의 거리는 참조 계획의 단계 후에 가장 낮아야 하므로, 인지에 따라 목표 달성 감지 정확도를 계산한다.
Datasets. 우리는 두 가지 출처에서 테스트 샘플을 구성한다. 1) 시각-언어 월드 모델링 (VLWM): Tree of Captions와 Self-Refine을 통해 추출된 4,410개의 행동-상태 궤적이다. 목표 필드는 목표 설명과 목표 해석을 모두 결합한다. VLWM-critic-1B는 HowTo100M 궤적으로 훈련되었기 때문에, 우리는 이를 제외하고 다른 지시 동영상 소스(COIN, CrossTask, YouCook2)와 1인칭 녹화물(EgoExo4D, EPIC-KITCHENS-100)에서만 데이터를 샘플링한다. 2) Open Grounded Planning (OGP): Guo et al. (2024)은 다양한 도메인에서 가져온 목표-계획 쌍 컬렉션을 발표했다. 우리는 도구 사용 하위 집합의 계획은 종종 단계 수가 너무 적어 사용하지 않고, VirtualHoom과 SayCan에서 가져온 '로봇' 하위 집합과 WikiHow 하위 집합만 사용한다. VLWM 데이터와 달리, OGP의 궤적은 행동만을 포함하며 VLWM-critic-1B와 기준선 모델 모두에게 OOD(Out-of-Distribution) 데이터이다. OGP 데이터에는 총 9,983개의 궤적이 있다.
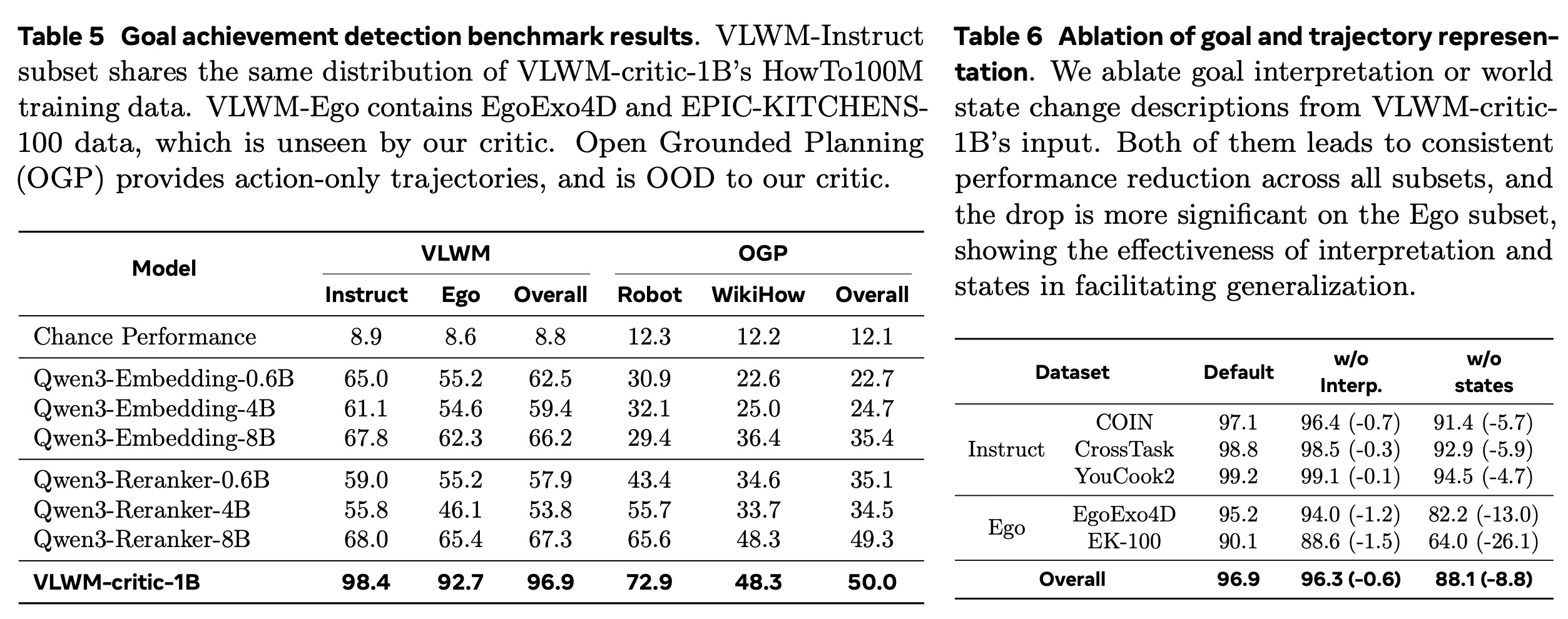
Main Results. 우리는 VLWM-critic-1B를 의미론적 유사성을 측정하기 위한 최첨단 모델인 Qwen3-Embedding 모델 및 Qwen3-Reranker 모델(Zhang et al., 2025)과 기준선으로 비교한다. 비용은 로 계산된다. 결과는 표 5에 나와 있으며, 우리의 VLWM-critic-1B는 대부분의 하위 집합에서 기준선을 큰 차이로 능가한다. VLWM-critic-1B는 VLWM-Instruct에서 98.4%를 달성한 반면, VLWM-Ego에서는 92.7%로 더 낮다. 이는 도메인 차이로 인해 발생했을 가능성이 있는데, 우리의 비평가는 1인칭 녹화 데이터는 전혀 보지 않고 HowTo100M 지시 동영상으로만 훈련되었기 때문이다. OGP에서 우리의 비평가는 최고의 기준선인 Qwen3-Reranker-8B에 비해 뚜렷한 우위를 보이지만(72.9% 대 65.6%), OGP-WikiHow에서는 비교 가능한 성능을 보인다(매개변수가 8배 더 적음에도 불구하고). 이러한 작은 격차의 가능한 이유는 데이터 노이즈 또는 Qwen3-Reranker의 훈련 데이터와의 잠재적 중복을 포함한다.
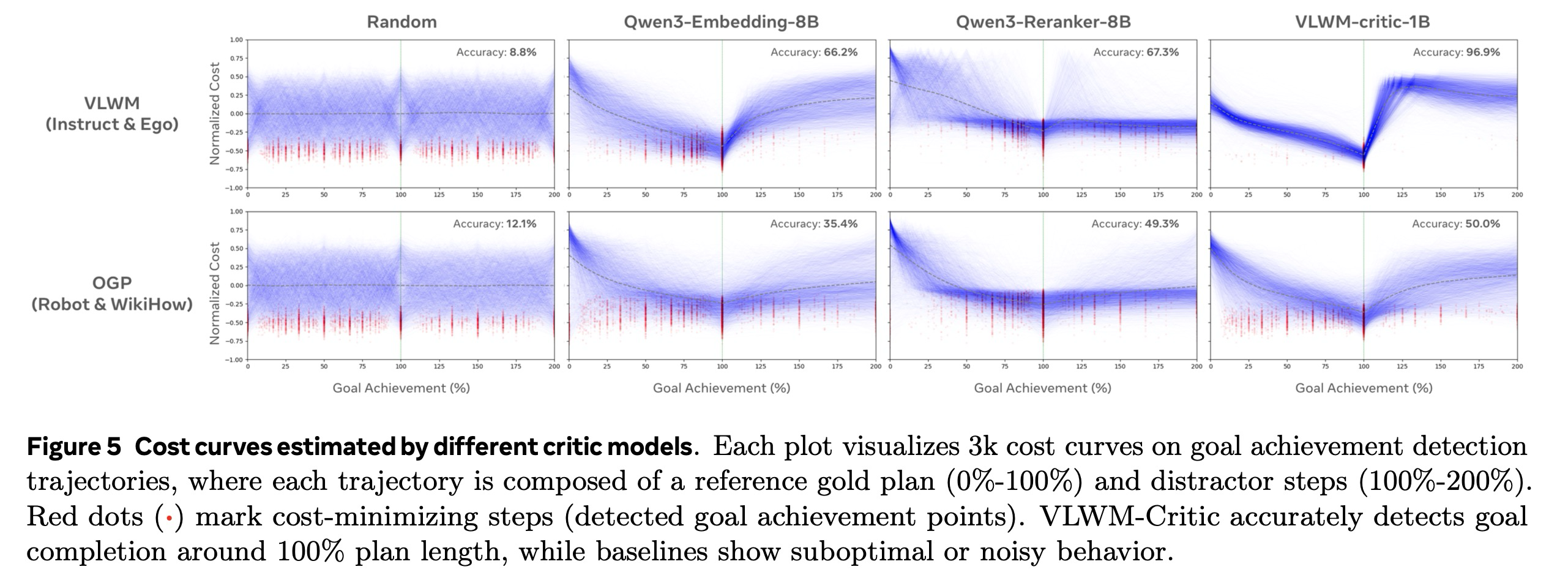
그림 5에서 우리는 다양한 비평가 모델이 예측한 정규화된 비용 곡선을 시각화한다. 이 시각화는 "에너지 지형(energy landscape)"으로 볼 수 있으며, 원하는 형태는 100% 목표 달성 지점에서 최소 비용을 갖는 것이다. VLWM 데이터에서 VLWM-critic-1B는 기준선에 비해 훨씬 더 깨끗한 지형을 제공한다. 그러나 OGP 데이터셋에 대해서는 분포가 더 노이즈가 많아진다. 위에서 언급된 도메인 차이 및 데이터셋 노이즈 문제 외에도, 성능 저하의 한 가지 잠재적 이유는 OGP가 명시적인 월드 상태 설명 없이 행동만 포함하는 궤적을 제공하여 비용 평가를 더 어렵게 만들기 때문이다.
Ablation Studies. 표 6은 VLWM-critic-1B와 VLWM 데이터를 사용한 비평가 입력 표현의 절제 연구를 제공한다. 우리는 현재 및 예상 최종 목표 상태에 대한 설명을 포함하는 목표 해석과 궤적 표현에서 상태 설명을 제거하고 행동만 남겨두었다. 두 가지 절제 모두 목표 달성 감지에서 성능 저하를 초래하며, 특히 미노출 OOD 데이터(Ego 하위 집합)에서의 감소가 더 심각한데, 이는 효과적인 일반화를 위해 해석과 월드 상태 설명이 중요함을 보여준다.
3.4.2 Procedural Planning on WorldPrediction-PP
WorldPrediction 벤치마크는 고수준 월드 모델링 및 절차적 계획 수립 능력을 평가하기 위해 설계되었다. 이 벤치마크의 절차적 계획 하위 집합인 WorldPrediction-PP는 인간이 검증한 570개의 샘플로 구성된다. 각 테스트 사례는 초기 및 최종 시각적 상태와 함께 네 가지 후보 행동 계획을 제공하며, 이들은 동영상 시퀀스로 표현된다. 과제는 뒤섞인 반사실적 방해 요소들 중에서 올바르게 순서가 지정된 시퀀스를 식별하는 것으로, 이는 목표 조건부 계획 수립 능력과 모델의 의미론적 및 시간적 행동 순서 이해를 강조한다.
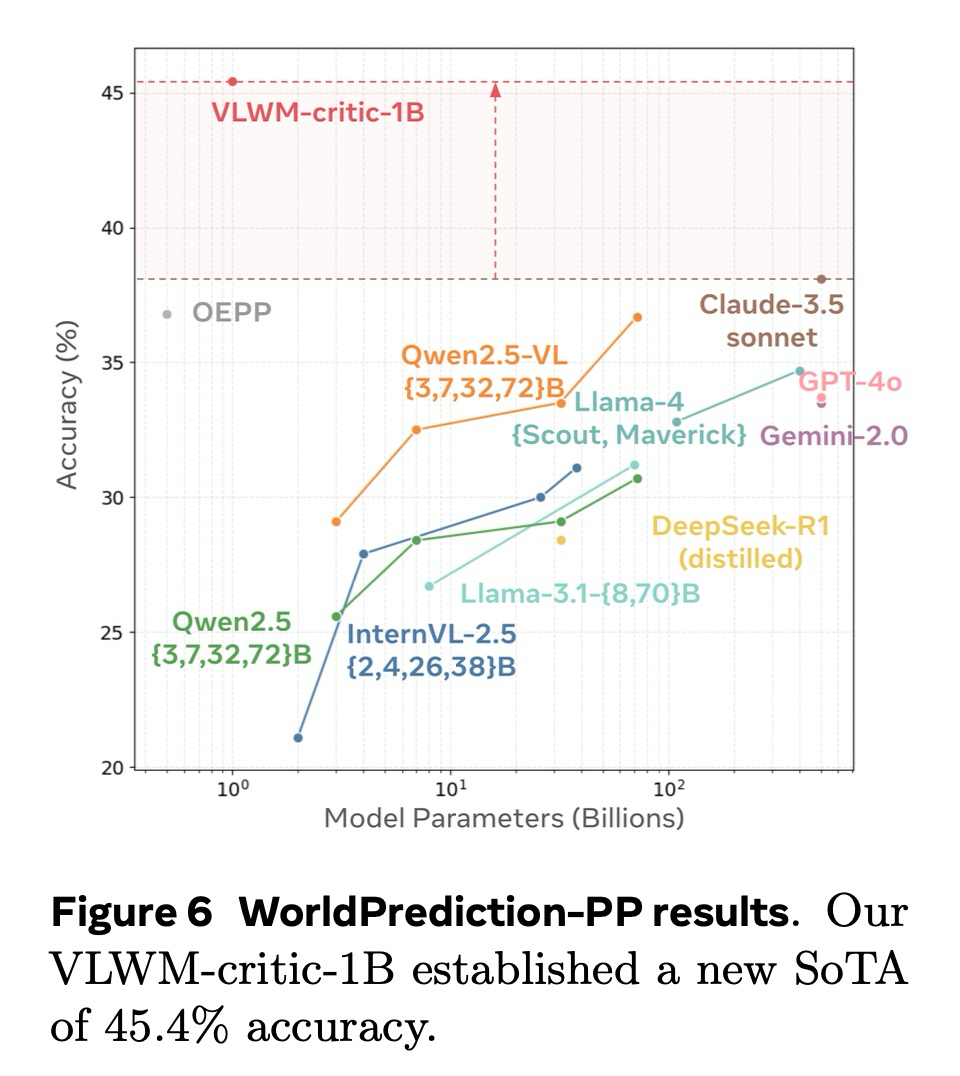
WorldPrediction-PP에서 우리의 비평가 모듈을 평가하기 위해, 우리는 Chen et al. (2025)의 소크라테스 LLM에 대한 평가 프로토콜을 따랐다. 시각적 입력은 먼저 Qwen2.5-VL에 의해 생성된 캡션을 사용하여 텍스트 설명으로 변환되었다. 구체적으로, 초기 및 최종 상태를 묘사하는 두 이미지는 월드 상태의 변화를 간략하게 설명하는 목표 설명을 생성했으며, 후보 행동의 동영상 클립 또한 유사하게 캡션 처리되었다. 이러한 텍스트 입력은 우리의 VLWM-비평가 모델에 직접 제공되어 각 후보 계획에 대한 비용을 계산하고, 예측된 비용이 가장 낮은 옵션을 선택했다. 그림 6 (b)에서 우리는 우리의 VLWM-비평가 모델을 기준선 소크라테스 LLM과 비교한다. 우리의 모델은 모델 크기와 정확도 사이에서 파레토 최적의 균형을 달성한다. 중요하게도, 이 평가는 VLWM-비평가 모델에게 제로 샷(zero-shot) 시나리오를 구성한다. 이는 캡션 기반의 목표 설명이나 상세한 동영상 캡션 기반의 행동 단계 모두 훈련 코퍼스의 일부가 아니었기 때문이다. 우리의 VLWM-critic-1B는 45.4%의 정확도로 새로운 최첨단 성능(SoTA)을 확립했다.
4. Related Work
4.1 Action Plannning
계획 수립은 월드를 초기 상태에서 원하는 목표 상태로 이행시킬 수 있는 행동 시퀀스를 생성하는 과제이다. 본 논문의 VLWM은 자율 주행, 로봇 공학, 게임 등에서 볼 수 있는 저수준의 고주파 연속 행동과 달리, 의미론적 및 시간적 추상화를 특징으로 하는 고수준 행동 계획 수립에 초점을 맞춘다. 기존 행동 계획 방법론은 다음과 비교된다:
Imitation learning. 이는 광범위한 전문가 시연이 있을 때 효과적이지만, 시연이 부족하거나 불완전할 경우 상당히 어려워진다. 교육 동영상을 기반으로 하는 절차적 계획 수립 및 VPA 과제를 위한 대부분의 접근 방식은 근본적으로 행동 복제에 의존한다. 그러나 행동 주석이 제한된 어휘에 국한되어 있기 때문에, 정답 계획은 종종 불완전하여 벤치마킹을 위한 최적의 참조가 되지 못하고 (이는 PlannerArena (§3.2.2)의 동기가 된다) 모방 학습에도 부적절하다.
Reinforcement learning. 이는 에이전트가 시행착오를 수행하고 명시적인 보상을 받을 수 있는 환경을 일반적으로 필요로 한다. 환경이 이러한 상호 작용을 지원할 때, 검증 가능한 보상을 통한 강화 학습 (RLVR)은 매우 효과적이다. RL은 시뮬레이션 환경 구축이 가능한 도메인에 적합하지만, 더 다양하고 복잡한 도메인으로 확장하기는 덜 실현 가능하다.
Planning with reward-agnostic world model. 이 접근 방식은 광범위하고 보상이 없는 오프라인 데이터로부터 학습하여 뛰어난 일반화 능력을 보인다. 월드 모델은 내부적으로 행동 결과를 시뮬레이션하고 비용 최소화를 기반으로 계획을 최적화함으로써 계획 수립을 가능하게 한다. 여기서 월드 모델은 오직 미래 월드 상태만을 예측하며, 행동 계획은 예측된 결과 상태와 원하는 목표 상태 사이의 거리(distance)를 최소화함으로써 최적화된다. 이 방식은 학습된 월드 모델 내에서 내부적인 시행착오를 수행하여 추론 시간 확장을 허용한다. 본 논문의 VLWM의 시스템-2 "추론을 통한 계획 수립”은 이 패러다임을 활용하며, 이는 반응적인 시스템-1 행동 복제보다 우수함을 입증하였다.
4.2 World Modeling
월드 모델은 환경 동역학(environmental dynamics)을 시뮬레이션하는 것을 목표로 하며, 에이전트가 실제 환경과의 직접적인 온라인 상호 작용 없이 계획을 최적화할 수 있도록 한다. 월드 모델은 주로 자율 주행 및 로봇 공학과 같은 저수준 제어 도메인에서 성공을 입증했는데, 이러한 도메인에서는 모델이 짧은 수평선에 걸쳐 미세하고 연속적인 감각 데이터를 예측한다. 아래에서는 기존의 월드 모델링 접근 방식들을 비교한다.
Generative world models. 생성적 월드 모델은 일반적으로 강력한 확산 기반 아키텍처를 활용하여 미래 관찰을 직접 재구성한다 (예: 픽셀 공간에서). 여기에는 Sora, Cosmos, Genie, UniSim, 그리고 최근의 다중 모드 사고 연쇄 추론(chain-of-thought reasoning), 즉 "이미지로 생각하기" 모델이 포함된다. 직관적이지만, 생성 모델은 본질적으로 픽셀 기반 표현에 얽힌 계산적 비효율성과 과제와 무관한 세부 사항으로 인해 어려움을 겪으며, 이는 장기 계획 수립을 위한 확장성을 심각하게 제한한다. 이러한 모델들이 현실적인 시각 자료를 생성하지만, 계획 수립 과제에서는 제한적인 성공을 보여왔다.
JEPA world models. JEPA 월드 모델은 관찰을 압축된 추상 표현으로 인코딩하며, 예측기(predictor)는 이러한 잠재 상태를 예측하도록 훈련된다. JEPA 모델은 I-JEPA, IWM, V-JEPA가 입증했듯이 표현 학습에 유익함을 입증했으며, DINO-WM, V-JEPA2, NWM가 예시하는 MPC 기반 계획 수립을 촉진했다. 그러나 인코더와 예측기의 공동 훈련은 EMA와 같은 안티-붕괴(anti-collapse) 기술의 필요성 등 어려움을 야기한다. 더욱이, 기존의 JEPA 기반 월드 모델은 주로 저수준 동작 계획에 중점을 두고 있으며, 이를 고수준 행동 계획으로 확장하는 것은 여전히 미해결 연구 과제로 남아있다.
Language-based world models. 언어 기반 월드 모델은 자연어를 고수준 추상화 인터페이스로 활용하여, 픽셀 기반 재구성보다 해석 가능성과 계산적 이점을 제공한다. 이전 연구는 LLM을 월드 모델로 프롬프팅하는 방식이나, 웹 탐색, 텍스트 게임, 그리고 구현된 환경과 같은 좁은 도메인에서 언어 기반 월드 모델을 훈련하는 방식을 탐구했다. 이와 대조적으로, 본 논문의 VLWM 접근 방식은 대규모의 원본 동영상 데이터에서 직접적으로 월드 모델을 명시적으로 학습한다.
5. Conclusion
본 연구는 시각-언어 월드 모델(VLWM, Vision Language World Model)을 소개했으며, 이는 언어 공간에서 월드 동역학(world dynamics)을 직접 표현하고 예측하도록 학습된 파운데이션 모델이다. VLWM은 원본 동영상을 계층적 캡션 트리(Trees of Captions)로 압축하고 이를 목표, 행동, 월드 상태 변화로 구성된 구조화된 궤적으로 정제함으로써, 지각 기반의 VLM과 추론 지향적인 LLM 사이의 격차를 해소한다.
VLWM의 이중 모드 설계는 다음과 같은 두 가지 계획 수립 방식을 모두 지원한다: (1) 직접적인 정책 디코딩을 통한 빠르고 반응적인 시스템-1 계획 수립. (2) 자체 지도 학습 비평가(critic)에 의해 안내되는 비용 최소화를 통한 성찰적인 시스템-2 계획 수립. 이 시스템-2 모드는 모델이 내부적으로 시행착오 추론을 수행하고 최적의 계획을 선택할 수 있도록 한다.
VLWM은 방대하고 다양한 교육 동영상 및 1인칭 녹화물 코퍼스에서 훈련되었으며, Visual Planning for Assistance (VPA) 벤치마크에서 새로운 최첨단 결과(state-of-the-art results)를 확립했다. 또한, 제안된 PlannerArena 인간 선호도 평가에서 우수한 계획 품질을 입증했으며, RoboVQA에서도 최고 수준의 성능을 달성하는 동시에 해석 가능한 행동-상태 롤아웃을 생성한다.
나아가, 비평가 모델은 목표 달성 감지 및 절차적 계획 벤치마크에서 독립적으로 뛰어난 성능을 보여, 월드 모델 기반 추론을 위한 명시적인 의미론적 비용 모델링의 가치를 강조한다. 종합적으로, VLWM은 대규모 자연 동영상으로부터 직접 학습하고 원본 픽셀이 아닌 추상적이고 비생성적인 표현 공간에서 예측함으로써, 지각, 추론 및 계획을 연결하는 강력한 인터페이스를 제공하며, AI 어시스턴트가 모방을 넘어 강력하고 장기적인 의사 결정이 가능한 성찰적인 에이전트로 발전하도록 추진한다.
