Author: Jiaru Zou, Xiyuan Yang, Ruizhong Qiu, Gaotang Li, Katherine Tieu, Pan Lu, Ke Shen, Hanghang Tong, Yejin Choi, Jingrui He, James Zou, Mengdi Wang, Ling Yang
Affilation: Princeton University, University of Illinois Urbana-Champaign, Stanford University
Venue: arXiv
Comment:
Date: November 2025
Paper Link: https://arxiv.org/abs/2511.20639
⭐️ Key Takeaways
1. LatentMAS는 대규모 언어 모델(LLM) 에이전트들이 명시적인 텍스트 대신 연속적인 잠재 공간 내에서 추론하고 통신할 수 있도록 하는 학습 불필요 종단 간 협업 프레임워크를 제시한다.
2. LatentMAS는 기존 텍스트 기반 다중 에이전트 시스템(MAS) 대비 출력 토큰 사용량을 70.8%에서 83.7%까지 크게 줄이고 종단 간 추론 속도를 평균 4배에서 4.3배 빠르게 제공하여 상당한 계산 효율성 이득을 달성한다.
3. 이 새로운 잠재적 협업 프레임워크는 손실 없는 정보 보존과 더 높은 표현력이라는 이론적 이점을 바탕으로, 강력한 기준선들보다 최대 14.6% 더 높은 정확도를 달성하며 시스템 수준의 추론 품질을 향상시킨다.
Abstract
다중 에이전트 시스템(MAS)은 대규모 언어 모델(LLMs)을 독립적인 단일 모델 추론에서 협력적인 시스템 수준 지능으로 확장한다. 기존 LLM 에이전트들이 추론과 통신을 위해 텍스트 기반 매개에 의존하는 반면, 우리는 모델들이 연속적인 잠재 공간 내에서 직접 협업할 수 있도록 함으로써 한 걸음 더 나아간다. 우리는 LLM 에이전트들 간의 순수한 잠재적 협업을 가능하게 하는 종단 간(end-to-end) 학습 불필요(training-free) 프레임워크인 LatentMAS를 소개한다. LatentMAS에서 각 에이전트는 먼저 마지막 레이어 은닉 임베딩을 통해 자기회귀적인(auto-regressive) 잠재 사고 생성을 수행한다. 그런 다음 공유된 잠재적 작업 기억(latent working memory)은 각 에이전트의 내부 표현을 보존하고 전달하여, 정보 교환의 무손실을 보장한다. 우리는 LatentMAS가 기존의 텍스트 기반 MAS보다 훨씬 낮은 복잡도로 더 높은 표현력과 무손실 정보 보존을 달성한다는 이론적 분석을 제공한다. 또한, 수학 및 과학 추론, 상식 이해, 코드 생성에 걸친 9개의 포괄적인 벤치마크에 대한 실증적 평가는 LatentMAS가 강력한 단일 모델 및 텍스트 기반 MAS 기준선들을 일관되게 능가함을 보여주며, 최대 14.6% 더 높은 정확도를 달성하고, 출력 토큰 사용량을 70.8%~83.7% 감소시키며, 종단 간 추론 속도를 4배~4.3배 더 빠르게 제공한다. 이러한 결과들은 우리의 새로운 잠재적 협업 프레임워크가 시스템 수준의 추론 품질을 향상시키는 동시에 어떠한 추가 학습 없이도 상당한 효율성 향상을 제공함을 입증한다.
1. Introduction
모델 협업은 에이전트 AI 시대에 시스템 수준 지능의 기초로 부상한다. 다중 에이전트 시스템(MAS)의 최근 발전은 고립된 모델 중심 추론에서 여러 상호작용하는 모델 간의 협력적 노력으로의 패러다임 전환을 촉진한다. 이 중, 대규모 언어 모델(LLM) 기반 MAS는 협력적인 수학 및 과학 추론, 개방형 QA에서의 분산 도구 사용, 로봇 공학에서의 체화된 의사 결정을 포함한 다양한 다운스트림 응용 분야에 채택되어 왔다. LLM 기반 MAS 내에서 자연어 또는 텍스트는 일반적으로 각 에이전트의 내부 사고를 전달하고 서로 다른 에이전트 간의 통신을 가능하게 하는 공통 매체인 링구아 프랑카(lingua franca) 역할을 한다.
명시적인 텍스트를 넘어, 여러 연구는 LLM의 연속적인 잠재 공간을 새로운 형태의 "모델 언어"로 활용하는 방법을 탐색해 왔다. 이는 (i) 트랜스포머 내의 은닉 표현을 활용하여 단일 모델의 내부 잠재적 사고 연쇄(CoT) 추론을 가능하게 하거나, (ii) 두 모델 간의 정보 교환을 위해 KV 캐시 또는 레이어 임베딩을 사용하는 방식이다. 하지만, 잠재적 추론과 잠재적 통신을 모두 통합하는 포괄적인 모델 협업 프레임워크는 아직 탐구되지 않았다. 한 걸음 더 나아가, 우리는 다음과 같은 질문을 조사한다.
💡 다중 에이전트 시스템이 순수한 잠재적 협업을 달성할 수 있는가?
이 질문에 답하기 위해, 우리는 연속적인 잠재 공간 내에서 전적으로 작동하는 종단 간 협업 프레임워크인 LatentMAS를 소개한다. 우리의 핵심 설계는 내부 잠재적 사고 생성과 에이전트 간 잠재적 작업 기억 전송을 모두 통합한다. 각 에이전트 내부에서 추론은 마지막 레이어 은닉 표현의 자기회귀적 생성을 통해 전개되며, 명시적인 디코딩 없이 모델의 진행 중인 내부 사고를 포착한다. 에이전트 전반에 걸쳐 정보는 레이어별 KV 캐시에 저장된 공유된 잠재적 작업 기억을 통해 교환되며, 이는 입력 컨텍스트와 새로 생성된 잠재적 사고를 모두 포착한다. 전반적으로, LatentMAS는 완전히 학습 불필요(training-free)한 프레임워크이며, 모든 에이전트가 내부 잠재적 표현을 통해서만 순수하게 사고하고 상호 작용할 수 있도록 한다.
우리의 프레임워크 설계에 기반하여, LatentMAS는 포괄적인 이론적 및 실증적 분석을 통해 검증된 세 가지 기본 원칙에 근거한다.
- 추론 표현력: 은닉 표현은 모델의 연속적인 사고를 자연스럽게 인코딩하며, 각 잠재 단계가 불연속적인 토큰보다 훨씬 더 풍부한 정보를 전달할 수 있도록 한다.
- 통신 충실도: 잠재적 작업 기억은 각 모델의 입력 표현과 잠재적 사고를 보존하여, 무손실 에이전트 간 정보 전송을 가능하게 한다.
- 협업 복잡도: LatentMAS는 텍스트 기반 MAS보다 더 높은 협업 표현력을 달성하는 동시에 훨씬 더 낮은 추론 복잡도를 달성한다.
처음 두 가지 원칙은 더 풍부한 잠재적 추론과 무손실 잠재적 통신을 가능하게 함으로써 LatentMAS의 이점을 공동으로 강조한다. 세 번째 원칙은 LatentMAS가 더 높은 수준의 모델 표현력을 유지하면서도 텍스트 기반 MAS보다 상당히 낮은 계산 복잡도를 달성함을 보여주는 전반적인 복잡도 분석을 추가로 제공한다.
LatentMAS의 효능을 경험적으로 평가하기 위해, 우리는 수학 및 과학 추론, 상식 이해, 코드 생성을 아우르는 9개의 벤치마크에 대해 포괄적인 평가를 수행한다. 순차적 및 계층적 MAS 설정과 세 가지 백본 규모 모두에서, LatentMAS는 (i) 최대 14.6% 더 높은 정확도를 달성하고, (ii) 출력 토큰 사용량을 70.8%-83.7% 감소시키며, (iii) 4배-4.3배 더 빠른 종단 간 추론 속도를 제공함으로써 강력한 단일 모델 및 텍스트 기반 MAS 기준선들을 일관되게 능가한다. 이러한 결과는 잠재적 협업이 시스템 수준의 추론 품질을 향상시킬 뿐만 아니라 추가적인 학습 없이도 상당한 효율성 이득을 제공함을 입증한다. 잠재적 사고 표현력, 작업 기억 전송 및 입력-출력 정렬에 대한 추가 상세 분석은 LatentMAS가 잠재 공간 내에서 전적으로 의미론적으로 의미 있고, 무손실이며, 안정적인 협업을 가능하게 함을 확인한다.
2. Preliminary and Notations
Auto-regressive Generation in Transformer. 에 의해 매개변수화된 표준 트랜스포머 모델에 의해 계산되는 함수를 라고 하자. 입력 시퀀스 가 주어지면, 트랜스포머 는 먼저 입력 임베딩 레이어 을 통해 각 토큰을 인코딩하여 단계 까지의 토큰 임베딩 을 얻는데, 여기서 는 모델의 은닉 차원이다. 이 입력 토큰 임베딩 는 모델의 잔여 스트림을 통해 개의 트랜스포머 레이어를 순차적으로 거쳐 최종 레이어 은닉 표현 을 산출한다. 다음 토큰 생성을 위해 모델은 다음을 계산한다:
여기서 은 은닉 표현을 어휘 공간으로 매핑하는 언어 모델 헤드를 나타낸다. 각 토큰은 자기회귀적인 방식으로 생성되어 입력 시퀀스에 추가된다. 잠재 공간 생성의 경우, 모델은 명시적인 디코딩 없이 이전 토큰의 마지막 은닉 상태를 다음 입력 임베딩으로 직접 공급한다.
KV Cache as Working Memory. 디코더 전용 트랜스포머에서, Key-Value (KV) 캐시는 자기회귀적 생성 동안 동적 작업 기억 역할을 하며, 중복 계산을 피하기 위해 이전 디코딩 단계의 중간 표현을 저장한다. 구체적으로, 입력 임베딩 가 주어지면, 각 트랜스포머 레이어는 프로젝션 행렬 를 통해 이를 투영하여 를 얻는다. 단계 의 다음 토큰이 생성될 때, 모델은 해당 임베딩을 입력 시퀀스에 추가하고 캐시 를 다음과 같이 업데이트한다:
여기서 는 이전 모든 단계에서 누적된 키/값 행렬이며, 는 현재 토큰의 은닉 상태로부터 계산된 새로운 키/값 벡터이다. 이러한 누적 속성은 KV 캐시가 모델 내부 표현에 대한 성장하는 작업 기억을 유지할 수 있도록 한다.
LLM-based MAS Setting. 우리는 개의 에이전트로 구성된 다중 에이전트 시스템 를 고려하며, 이 에이전트들은 로 표시되며, 각 에이전트 는 위에서 언급된 에 해당하는 LLM이다. 추론 시점에, 입력 질문 가 시스템 에 제공되며, 는 에이전트 간의 상호작용을 조정하여 해당하는 최종 답변 를 협력적으로 생성한다. MAS 설계 패러다임은 일반적으로 결정적이지 않으며 다운스트림 작업에 따라 자주 달라지기 때문에, 우리는 잠재적 협업 설계를 특정 아키텍처에 제한하지 않는다. 대신, 우리는 우리의 방법을 실험적으로 평가하기 위한 기반으로 가장 일반적으로 사용되는 두 가지 MAS 설정(순차적 및 계층적)을 채택한다.
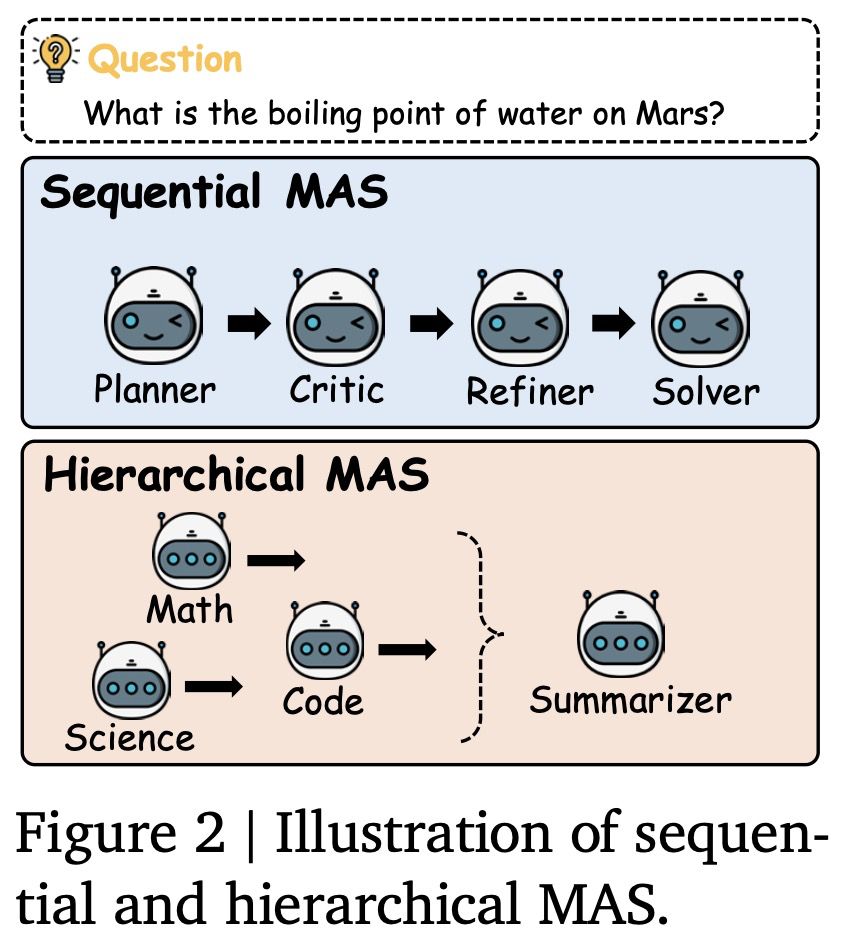
그림 2는 두 가지 MAS 아키텍처 설정을 보여준다.
- 순차적 MAS: 우리는 기획자(planner), 비평가(critic), 개선자(refiner), 해결사(solver)의 네 가지 LLM 에이전트로 구성된 에이전트 연쇄(chain-of-agents) 설계를 채택한다. 이 에이전트들은 상호 보완적인 추론 역할을 맡으며 순차적 파이프라인으로 조직되는데, 여기서 질문 q와 함께 각 에이전트의 CoT(사고 연쇄) 출력은 다음 에이전트의 입력으로 사용된다.
- 계층적 MAS: 우리는 도메인 특화 설계를 채택한다. 코드, 수학, 과학 에이전트를 포함한 여러 LLM 에이전트가 서로 다른 도메인 전문가로 작동한다. 각 에이전트는 해당 분야의 관점에서 질문 에 대해 독립적으로 추론한다. 그런 다음 요약자(summarizer) 에이전트가 질문 와 함께 모든 중간 응답을 받아 계층적 집계를 수행하여 최종 답변을 합성하고 개선한다.
3. Building a Latent Collaborative Multi-Agent System
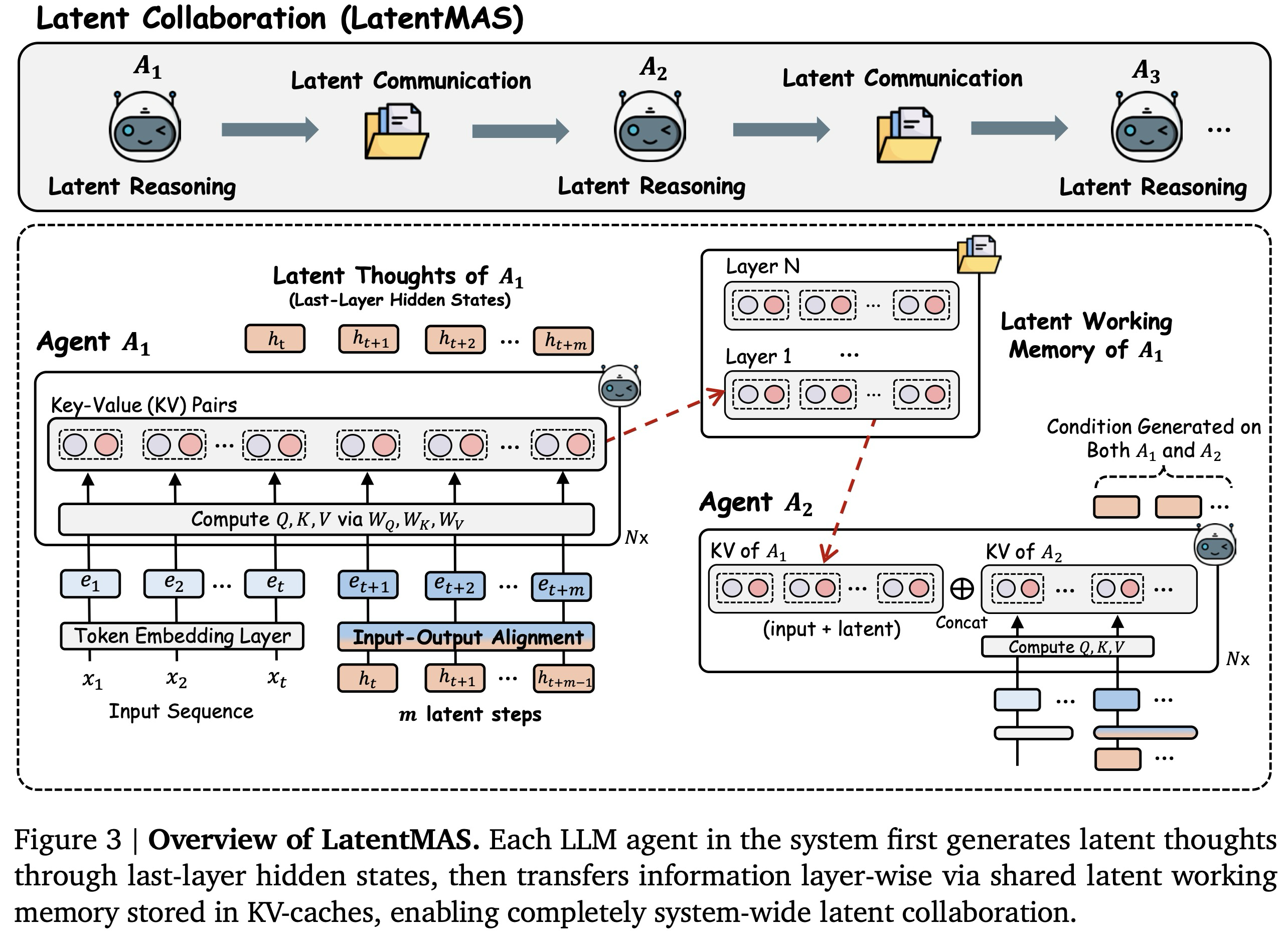
우리는 입력 질문이 주어지면 모든 에이전트가 전적으로 잠재 공간 내에서 추론하고 통신하며 최종 답변만 텍스트로 디코딩하는 종단 간(end-to-end) 잠재적 협업 프레임워크인 LatentMAS를 소개한다. 우리의 방법은 시스템 내의 대규모 언어 모델(LLM) 에이전트들이 (i) 잠재 공간에서 초고표현적(super-expressive) 사고 생성을 수행하고 (ii) 상호작용 전반에 걸쳐 각 에이전트의 잠재적 작업 기억을 손실 없는 충실도로 보존하고 전송하며 (iii) 동일한 수준의 표현력을 유지하면서도 기존의 텍스트 기반 다중 에이전트 시스템(MAS)보다 상당히 낮은 복잡도를 달성할 수 있도록 한다.
Method Roadmap. 다음 섹션들에서는 LatentMAS의 완전한 파이프라인을 제시하고, 각 구성 요소를 상세히 설명하며, 해당 설계 원칙을 정당화하기 위해 이론적 분석을 상호적으로 설명한다.
3.1 Auto-regressive Latent Thoughts Generation in Agents
우리는 각 대규모 언어 모델(LLM) 에이전트 내부에서 모델이 어떻게 레이어별 은닉 상태를 통해 잠재적 추론을 수행하는지 설명한다. 명시적인 토큰을 생성하는 대신, 추론은 최종 트랜스포머 레이어에 의해 생성된 은닉 표현들을 자기회귀적으로 추가함으로써 모델 내에서 직접 전개된다. 구체적으로, 질문()과 각 에이전트의 명령어 프롬프트로부터 정보를 담고 있는 입력 임베딩 가 주어졌을 때, 각 LLM 에이전트 는 개의 트랜스포머 레이어를 통과시켜 현재 단계 에서 마지막 레이어 은닉 표현 를 계산한다. 그런 다음, 우리는 이 를 다음 단계 의 입력 임베딩으로 삽입하는데, 이는 표준 토큰 생성에 사용되는 원래의 디코딩 및 다음 토큰 임베딩 프로세스를 대체하는 것이다. 우리는 이 과정을 개의 잠재 단계에 대해 자기회귀적으로 반복하여, 새로 생성된 마지막 레이어 은닉 상태들의 시퀀스 를 산출한다. 우리는 이 연속적인 출력 표현 를 에 의해 생성된 잠재적 사고로 정의한다.
Input-Output Distribution Alignment. 새로 생성된 는 밀집된(dense), 고수준의 표현 시퀀스를 형성하기 때문에, 이를 입력 임베딩으로 얕은 레이어에 직접 삽입하면 학습된 토큰 임베딩의 통계적 패턴과 다르므로 분포 이탈 활성화(out-of-distribution activations)로 이어질 수 있다. 이 문제를 학습 불필요(training-free) 방식으로 완화하기 위해, 우리는 마지막 레이어 은닉 상태를 유효한 입력 임베딩으로 매핑하는 선형 정렬 연산자()를 제안한다. 구체적으로, 의 입력 및 출력 임베딩 레이어를 각각 이라고 할 때, 우리는 각 출력 벡터 유효한 입력 공간에 정렬된 새로운 입력 벡터 로 매핑하는 투영 행렬 를 찾는다:
여기서 는 의 유사 역행렬이다. 그런 다음 우리는 정렬된 벡터 를 자기회귀적 잠재적 생성(latent generation)을 위해 입력 시퀀스에 추가한다. 이 는 크기의 작은 투영 행렬이며, 한 번 계산되어 모든 후속 잠재 단계에서 재사용된다. 이 설계는 정렬을 계산상 무시할 수 있을 정도로 만들면서도 잠재적 표현과 이산적 표현 사이의 분포적 일관성을 유지한다.
Expressiveness on Continuous Latent Thoughts. 각 에이전트 내부에 잠재적 사고 생성 메커니즘이 확립됨에 따라, 우리는 다음으로 기존의 이산적 토큰 생성에 비해 잠재적 사고의 표현력적 이점을 정량화하기 위한 이론적 분석을 제공한다. 다음 정리는 본질적으로 더 풍부한 의미론적 구조를 보존하는 잠재적 사고가 이산적인 텍스트 기반 추론보다 실질적으로 더 높은 표현 능력을 달성함을 공식화한다.
Theorem 3.1 (잠재적 사고의 표현력). 에 대한 선형 표현 가설(Linear Representation Hypothesis) 하에서, 길이가 인 모든 잠재적 사고 시퀀스가 해당 텍스트 기반 추론을 통해 손실 없이 표현될 수 있다면, 텍스트의 길이(토큰 수)는 적어도 여야 하며, 여기서 은 어휘 크기()를 나타낸다.
Remark 3.2. 정리 3.1은 잠재적 사고 생성이 텍스트 기반 추론보다 배 더 효율적일 수 있음을 시사한다. 또한, 표현력은 에 선형적으로 비례하며, 이는 더 큰 모델이 본질적으로 더 큰 잠재적 추론 능력을 나타냄을 의미한다.
주석 3.2의 예시로, Qwen3-4B / 8B / 14B 모델의 경우, 잠재적 사고 생성은 텍스트 기반 추론보다 각각 235.7배 / 377.1배 / 471.4배 더 효율적일 수 있다. 개별 에이전트 내에서의 추론을 넘어, LatentMAS에서의 협업은 이러한 에이전트들이 잠재적 정보를 어떻게 교환하는지에 의존한다.
3.2 Working Memory Preservation and Thoughts Transfer across Agents
텍스트 기반 다중 에이전트 시스템(MAS)에서는 하나의 대규모 언어 모델(LLM) 에이전트가 생성을 완료한 후, 자연어 출력이 다음 에이전트의 입력 시퀀스에 직접 추가된다. 그러나 LatentMAS의 각 에이전트는 명시적인 텍스트 출력 없이 은닉 상태 생성을 수행하므로, 우리는 손실 없는 정보 보존 및 교환을 보장하기 위해 새로운 잠재적 작업 기억 전송 메커니즘을 설계한다.
명확성을 위해, 우리는 LatentMAS 내에서 연속적인 첫 두 LLM 에이전트 를 사용하여 전송 메커니즘을 설명한다. 그림 3에 나타난 바와 같이, 에이전트 은 먼저 개의 잠재 단계를 생성한다. 이 단계들을 완료한 후, 우리는 의 모든 개 트랜스포머 레이어로부터 KV 캐시를 한 번 추출하고, 이를 잠재적 작업 기억()으로 정의한다:
여기서 와 는 번째 레이어에서 누적된 키 및 값 행렬이다. 채워진 입력 컨텍스트에 대해서만 모델 간 정보를 교환하는 기존의 캐시 공유 방법들과 달리, 내의 레이어별 캐시 컬렉션은 초기 입력 컨텍스트와 에이전트 이 새로 생성한 잠재적 사고를 모두 캡슐화한다.
다음으로, 후속 에이전트 는 에이전트 으로부터 작업 기억 을 통합한다. 가 잠재적 사고(즉, 마지막 레이어 은닉 상태)를 생성하기 전에, 우리는 각 와 를 기존의 와 앞에 붙여(prepend) 레이어별 연결(concatenation)을 수행하여 KV 캐시를 업데이트한다. 이렇게 함으로써, 에서의 새로운 잠재적 사고 생성은 의 작업 기억과 자신의 내부 표현 모두에 조건화된다.
Lossless Information Transfer. 이 잠재적 작업 기억 전송 메커니즘은 LatentMAS의 각 후속 에이전트가 재인코딩 없이 선행 에이전트의 완전한 출력을 원활하게 수신하도록 보장한다. 다음 정리는 이 속성을 공식화하며, 잠재적 작업 기억 전송이 명시적인 입력 교환과 동등한 정보 충실도를 보장함을 보여준다.
Theorem 3.3 (잠재적 작업 기억을 통한 정보 보존). 잠재적 및 텍스트 기반 추론 모두에서, 선행 에이전트로부터 잠재적 작업 기억을 수신할 때의 에이전트의 출력은 선행 에이전트의 출력을 직접 입력했을 때 얻는 출력과 동일하다고 한다.
전체 증명은 B.2에 제공된다. 추가적으로, 손실 없는 정보 보존을 통해, 우리는 후속 에이전트의 중복 계산을 피하기 위해 은닉 상태를 직접 전송하는 대신 KV 캐시 형태로 잠재적 작업 기억을 전송한다.
3.3 End-to-End Pipeline with Complexity Analyses
LatentMAS의 나머지 에이전트들에 대해서도 우리는 위에서 설명한 것과 동일한 잠재적 사고 생성 및 작업 기억 전송 메커니즘을 따른다. 구체적으로, 에이전트 는 선행 에이전트 로부터 작업 기억 를 상속받고, 자기회귀적 마지막 레이어 은닉 상태 생성을 수행한 후, 업데이트된 잠재적 작업 기억 를 다음 에이전트로 전송한다. 이 과정은 LatentMAS의 모든 에이전트들을 거쳐 계속되며, 마지막 에이전트만이 최종 답변을 디코딩한다.
Theorem 3.4 (LatentMAS 복잡도). LatentMAS의 각 에이전트에 대한 시간 복잡도는 이다. 여기서 는 이 에이전트의 입력 길이이고, 은 잠재적 사고의 길이이다. 이와 대조적으로, 정리 3.1을 가정할 때, 바닐라 텍스트 기반 MAS의 각 에이전트가 동일한 표현력을 달성하기 위한 시간 복잡도는 이어야 한다.
정리 3.4의 증명은 B.3에 제공된다. LatentMAS는 특정 모델 협업 전략에 구애받지 않으며, 순차적, 계층적 또는 기타 고급 MAS 설계에 원활하게 적용될 수 있다.
4. Empirical Evaluations
Tasks and Datasets. 우리는 일반적인 작업과 추론 집약적인 작업을 모두 포괄하는 9개의 벤치마크에 걸쳐 LatentMAS에 대한 종합적인 평가를 수행한다: (i) 수학 및 과학 추론에는 GSM8K, AIME24, AIME25, GPQA-Diamond 및 MedQA가 포함된다. (ii) 상식 추론에는 ARC-Easy 및 ARC-Challenge가 포함된다. (iii) 코드 생성에는 MBPP-Plus 및 HumanEval-Plus가 포함된다. 각 벤치마크에 대한 상세 설명은 부록 C.1에 제공된다.
Models and Baselines. 우리는 다양한 규모에서 LatentMAS를 구축하기 위해 Qwen3 제품군(4B, 8B, 14B)의 세 가지 상용 모델을 채택한다. 기준선 비교를 위해 LatentMAS를 다음 기준선과 비교하여 평가한다: (i) 단일 LLM 에이전트(Single): 단일 LLM이 토큰 수준 디코딩으로 표준 자기회귀적 생성을 직접 수행한다. (ii) 순차적 텍스트 기반 MAS (Sequential TextMAS): 텍스트 매개 추론 및 통신을 사용하여 에이전트 연쇄(chain-of-agents) 설계를 따른다. (iii) 계층적 텍스트 기반 MAS (Hierarchical TextMAS): 도메인 특화 에이전트들이 텍스트 기반 추론 및 통신을 사용하여 요약자(summarizer)를 통해 협력한다. 상세 모델 및 기준선 구현은 부록 C.2에 제공된다.
Implementation Details. 잠재적 사고 생성의 경우, 우리는 재정렬 행렬()을 실행당 한 번 계산하고 모든 후속 추론 단계에서 재사용한다. 각 LLM 에이전트는 추론 중에 개의 잠재적 단계를 수행한다. 작업 기억 전송을 위해, 우리는 HuggingFace Transformers의 past_key_values 인터페이스를 통해 바로 앞선 에이전트의 KV 캐시를 해당 트랜스포머 레이어에 직접 연결(concatenate)한다. HuggingFace 구현 외에도, 우리는 더 큰 LLM 에이전트의 효율적인 배포를 위해 접두사 캐싱 및 텐서 병렬 추론을 가능하게 하는 vLLM 백엔드를 모든 기준선 방법과 LatentMAS에 통합한다. 우리는 하이퍼파라미터 튜닝을 수행하고 세 번의 독립적인 실행에 대한 평균 성능을 보고한다. 기준선과 우리 방법 모두에서, 우리는 모든 LLM 에이전트의 온도를 0.6으로, top-p를 0.95로 설정한다. 우리는 각 작업의 상대적 난이도에 따라 최대 출력 길이를 조정한다. 우리는 ARC-Easy, ARC-Challenge 및 GSM8K에 대해 최대 길이를 2,048 토큰으로, MedQA, MBPP+ 및 HumanEval+에 대해 4,096 토큰으로, GPQA에 대해 8,192 토큰으로, AIME24/25에 대해 20,000 토큰으로 설정한다. 모든 실험은 8개의 NVIDIA A100-80G GPU에서 수행된다.
4.1 LatentMAS Delivers Higher Accuracy with Efficient Collaboration
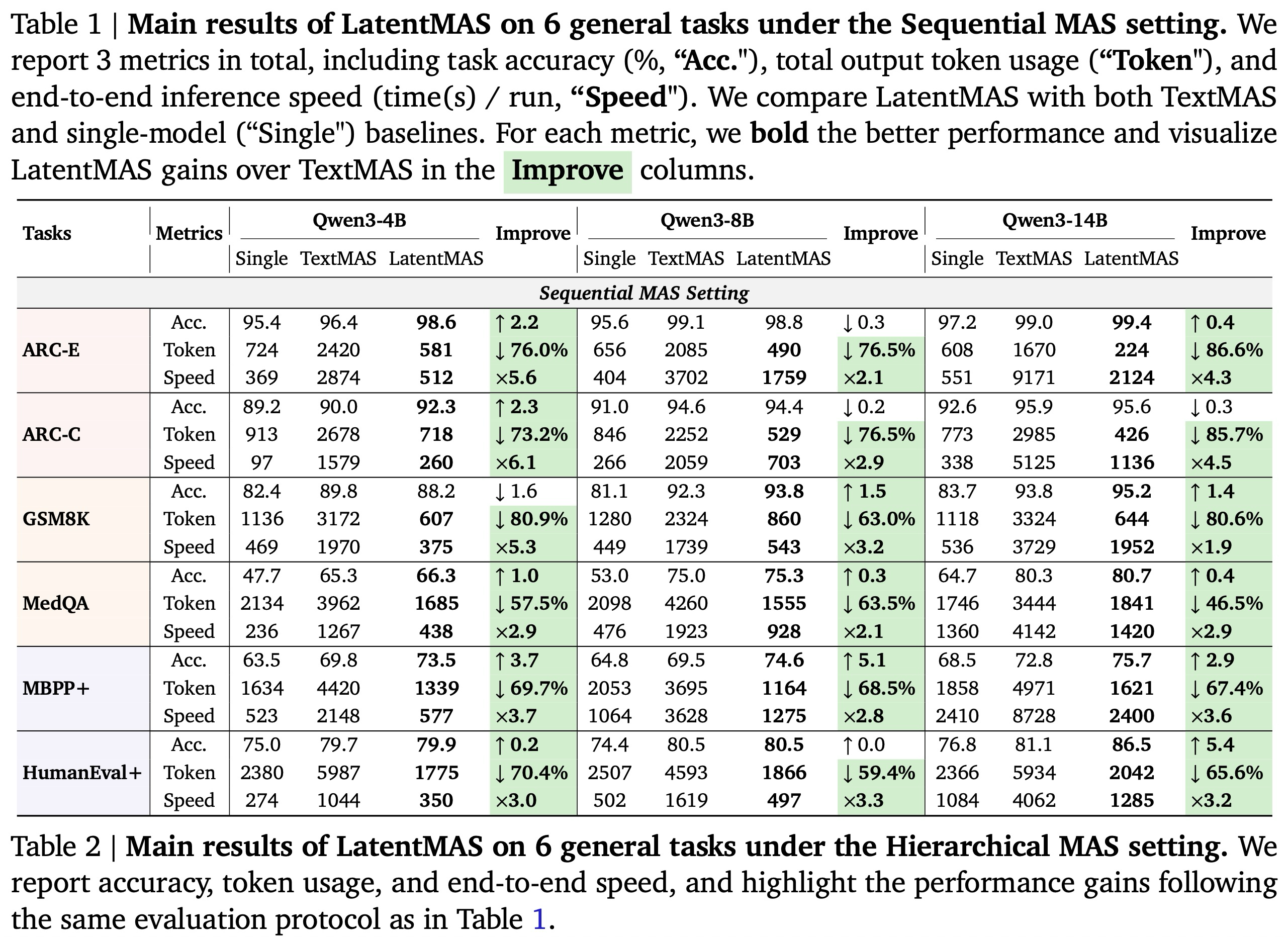
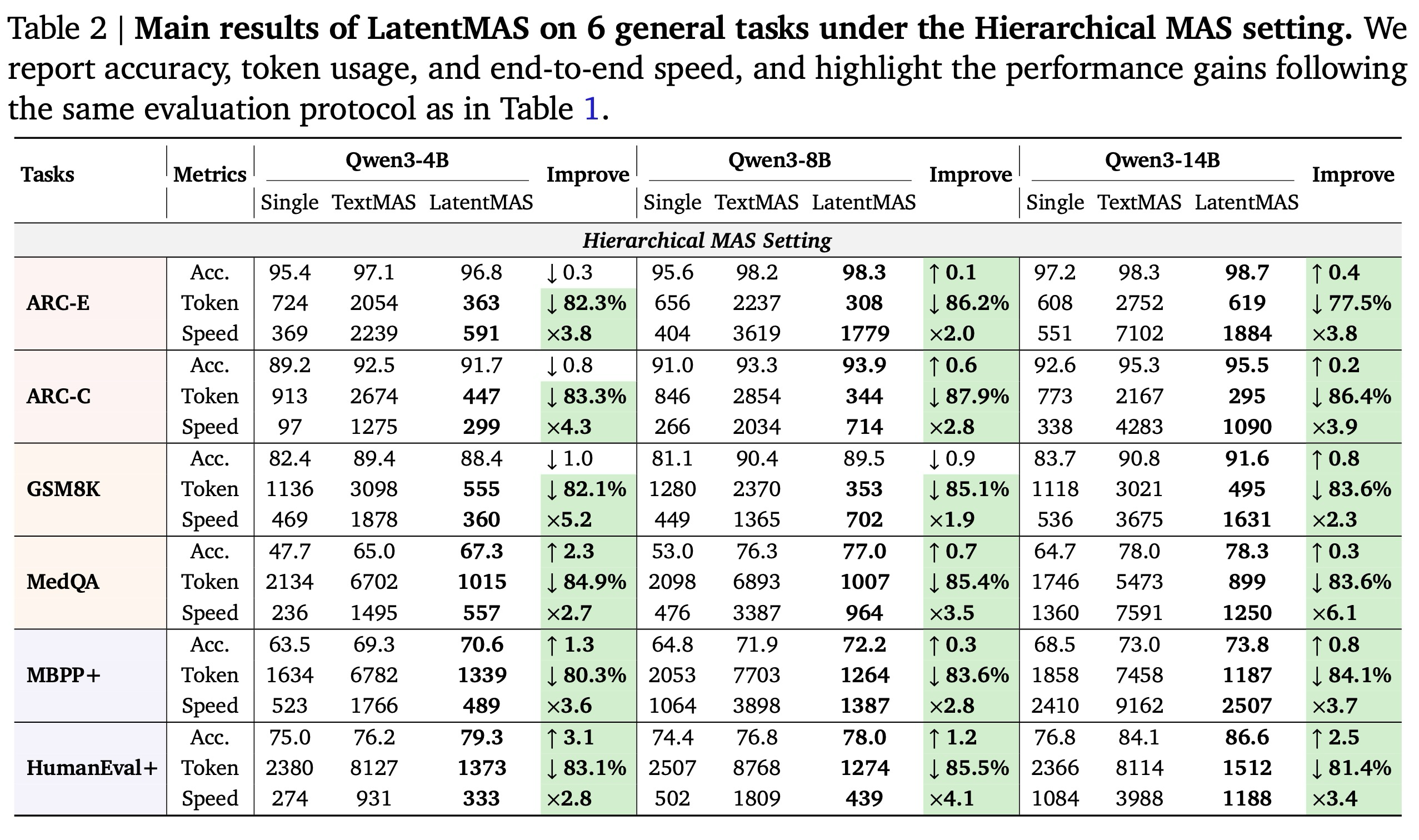
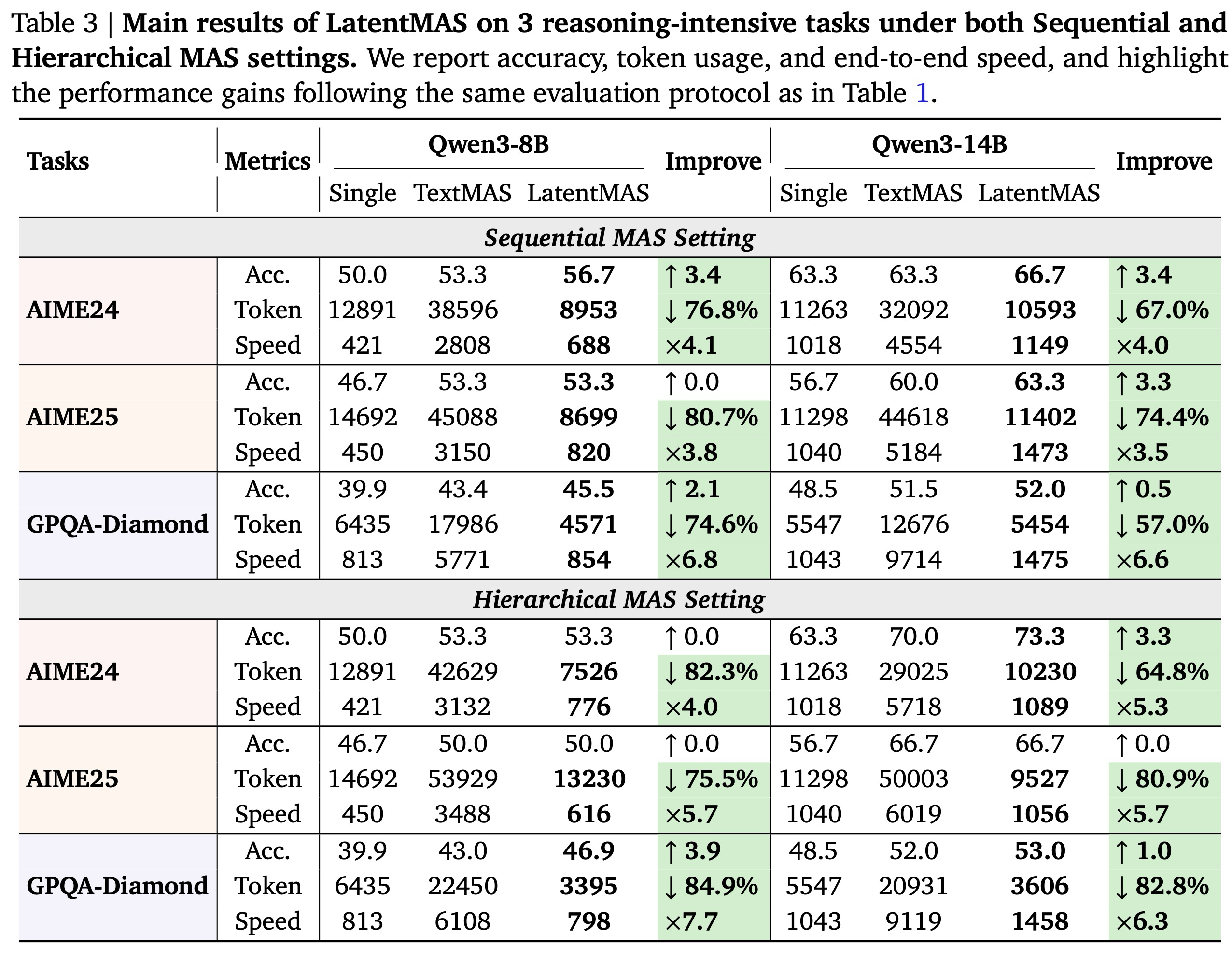
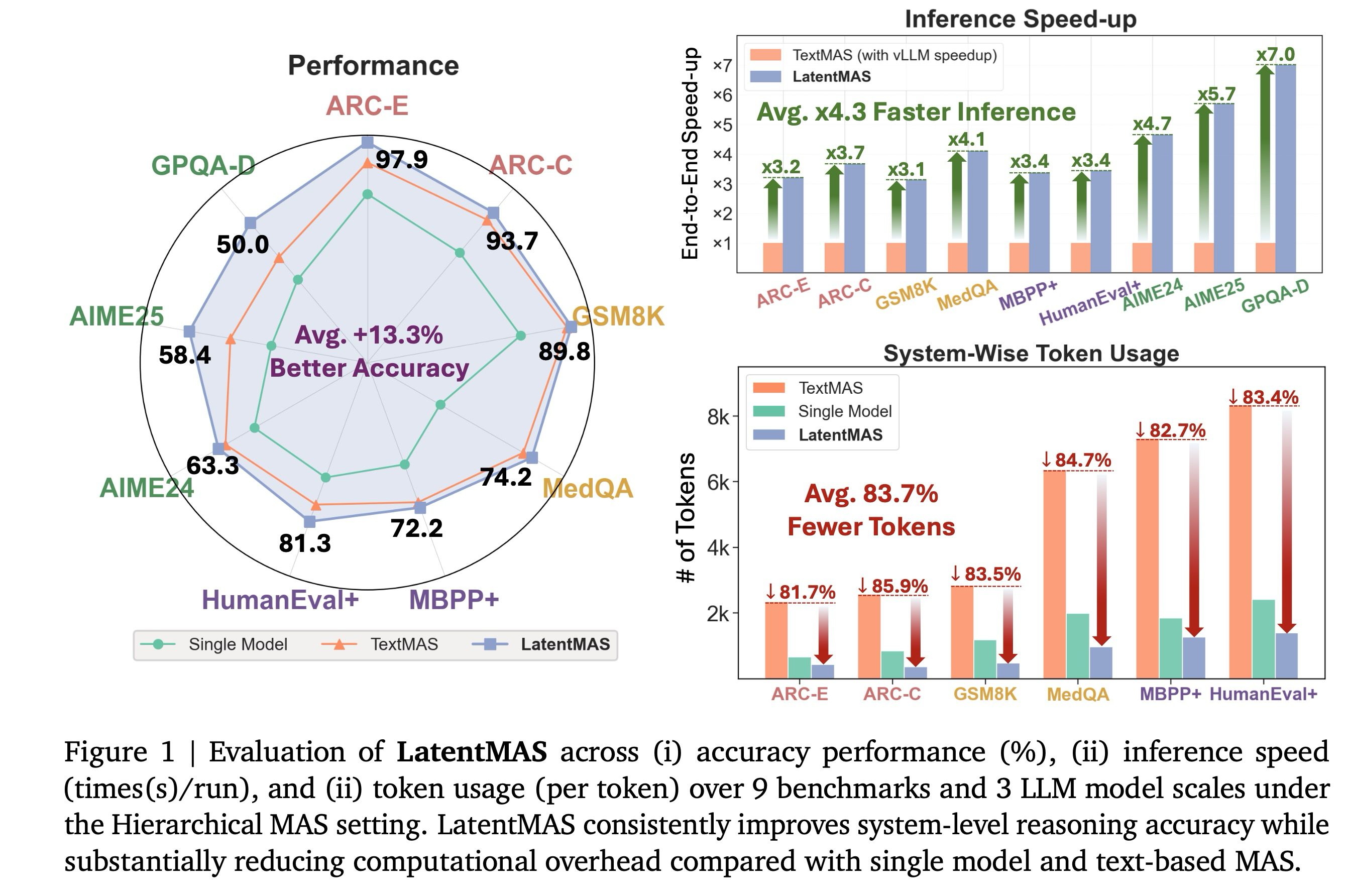
Main Results. 1, 2, 3은 세 가지 다른 규모의 대규모 언어 모델(LLM) 백본을 기반으로 구축된 9개의 일반 및 추론 집약적 벤치마크 전반에 걸친 LatentMAS의 전반적인 성능을 보고한다. 추론 중 협업 동작을 철저히 조사하기 위해, 우리는 각 방법을 (i) 작업 정확도, (ii) 시스템 처리량(총 출력 토큰), (iii) 종단 간 추론 속도의 세 가지 상호 보완적인 관점에서 평가한다. 모든 작업에서, LatentMAS는 순차적 설정에서 평균 14.6%, 계층적 설정에서 평균 13.3%로 단일 모델 기준선보다 일관되게 향상되며, 텍스트 기반 다중 에이전트 시스템(MAS) 대비 순차적 MAS 설정에서는 2.8%, 계층적 MAS 설정에서는 4.6%의 추가 이득을 산출한다. 동일한 MAS 아키텍처 하에서, LatentMAS는 순차적 텍스트 기반 MAS 대비 평균 4배, 계층적 텍스트 기반 MAS 대비 4.3배 더 빠른 추론 속도를 제공한다. 또한, 전체 협업이 전적으로 잠재 공간에서 발생하므로, LatentMAS는 순차적 텍스트 기반 MAS 대비 70.8%, 계층적 텍스트 기반 MAS 대비 83.7%만큼 토큰 사용량을 크게 줄인다.
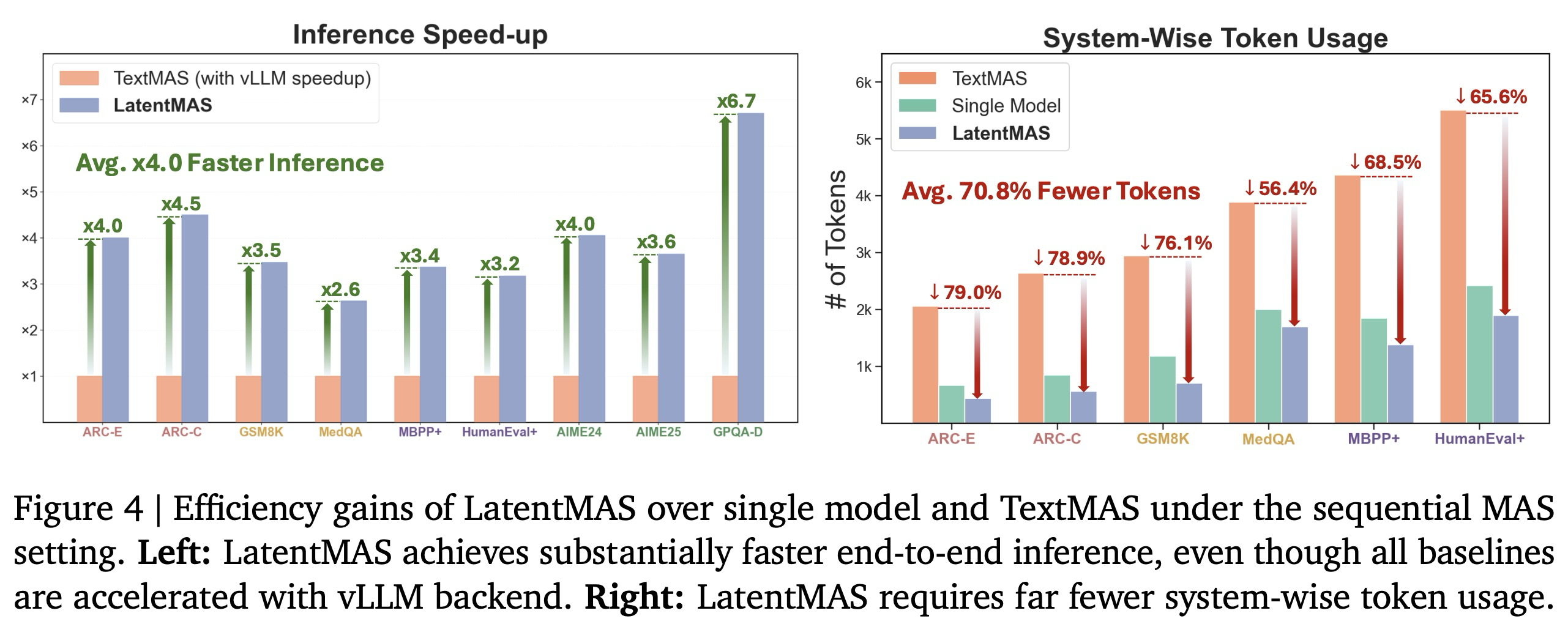
Superior Efficiency on Latent Collaboration. 정리 3.1에서 일찍이 확립되었듯이, LatentMAS는 이론적으로 텍스트 기반 MAS보다 수십 배 더 높은 효율성을 달성할 수 있다. 우리는 LatentMAS를 텍스트 기반 MAS와 비교하는 효율성 분석을 통해 이 이점을 추가로 경험적으로 검증한다. 그림 1과 그림 4(왼쪽)에 시각화된 바와 같이, vLLM 서비스를 사용하여 텍스트 기반 MAS 기준선들을 가속화한 후에도, LatentMAS는 vLLM으로 최적화된 텍스트 기반 MAS 대비 2.6배에서 7배의 속도 향상을 여전히 달성한다. 이러한 개선은 토큰별 텍스트 생성에 필요한 훨씬 더 많은 디코딩 단계 수에 비해 잠재적 사고 생성에 필요한 잠재 단계 수가 상당히 감소했기 때문에 발생한다. 예를 들어, 50개 미만의 잠재 단계로도 LatentMAS는 AIME 24/25와 같은 추론 집약적 작업에서 유사하거나 심지어 더 높은 성능을 달성하는 반면, 텍스트 기반 MAS는 완전한 텍스트 기반 사고 연쇄(CoT) 궤적을 완료하는 데 일반적으로 20,000개 이상의 출력 토큰이 필요하다.
또한, 그림 1과 그림 4(오른쪽)에 나타난 바와 같이, LatentMAS는 텍스트 기반 MAS 대비 59.4%-87.9%의 토큰 사용량 감소를 달성하는데, 이는 LatentMAS의 에이전트들이 텍스트 기반 매개에 의존하는 대신 잠재적 작업 기억을 다른 에이전트의 내부 레이어로 직접 전송하여 통신하기 때문이다. 주목할 만하게도, LatentMAS는 단일 에이전트보다도 15.0%-60.3% 더 낮은 토큰 사용량을 달성한다. 단일 모델 추론과 비교할 때, LatentMAS는 입력 질문을 여러 협력 에이전트에게 분산시켜, 주로 선행 잠재적 사고를 집계하고 적은 수의 토큰만 사용하여 최종 답변을 디코딩하는 최종 에이전트의 부담을 크게 줄인다. 결과적으로, 전체 시스템은 더 높은 정확도를 달성하면서도 더 적은 출력 토큰을 생성한다.
4.2 In-depth Analyses on LatentMAS
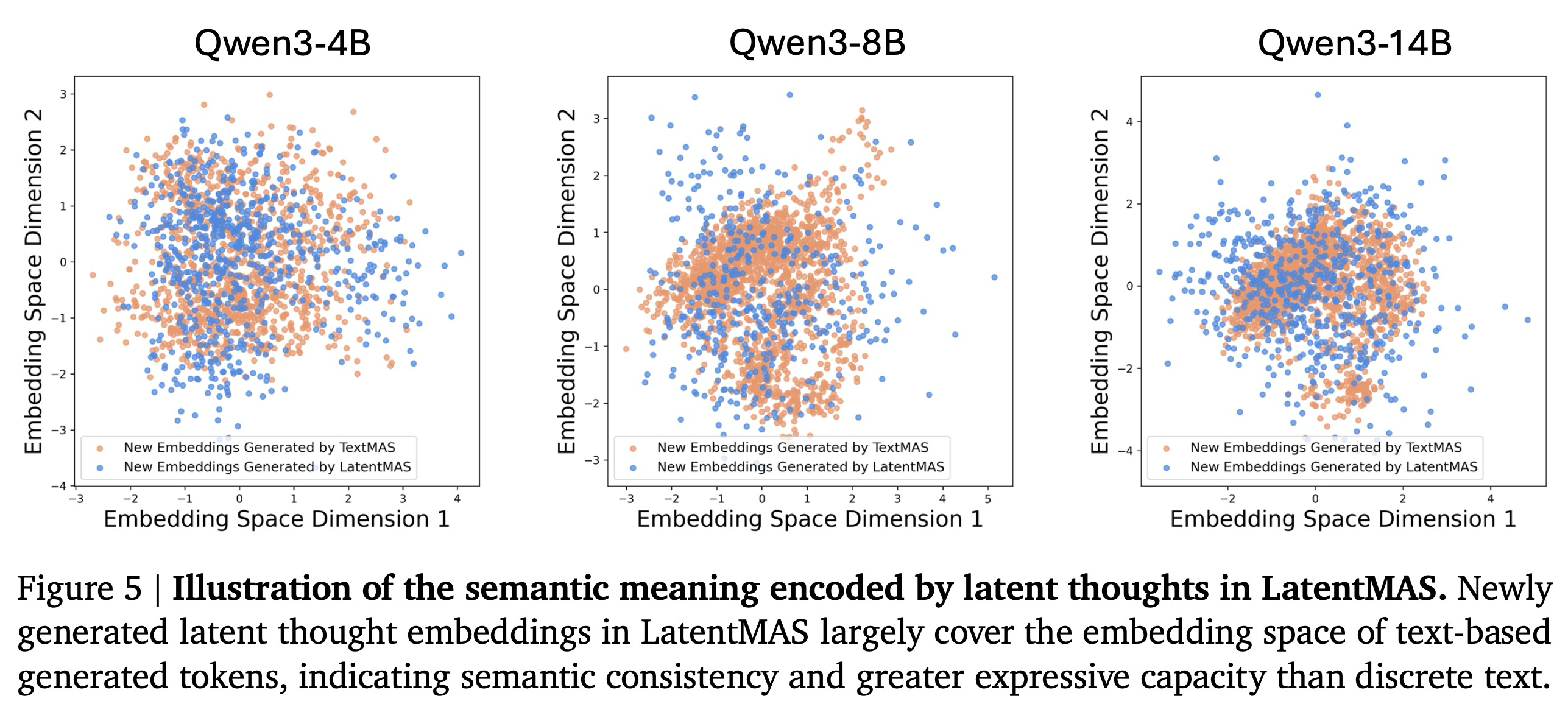
Do Latent Thoughts Reflect Text Reasoning? 우리는 먼저 LatentMAS에서의 잠재적 사고 생성이 의미론적으로 표현력이 풍부한 표현을 생성하는지 확인한다. 이를 위해, LatentMAS에서 새로 생성된 마지막 레이어 임베딩의 분포를 텍스트 기반 다중 에이전트 시스템(TextMAS)이 생성한 토큰별 응답의 임베딩과 비교한다. 실험은 300개의 MedQA 질문에 대해 수행되었으며, LatentMAS에는 40개의 잠재적 단계를, TextMAS 기준선에는 4096개의 최대 토큰 예산을 사용했다.
그림 5에 나타난 바와 같이, 우리는 두 가지 주요 관찰 결과를 강조한다: (i) LatentMAS의 마지막 레이어 임베딩은 TextMAS의 토큰 임베딩과 거의 동일한 임베딩 공간 영역을 공유하는데, 이는 잠재적 사고가 올바른 텍스트 응답과 유사한 의미론적 표현을 인코딩함을 나타낸다. (ii) LatentMAS의 마지막 레이어 임베딩은 TextMAS의 토큰 임베딩 분포를 대부분 포함하는데, 이는 잠재적 사고가 불연속적인 토큰보다 더 큰 다양성과 표현 능력을 제공함을 나타낸다. 종합적으로, 이러한 발견들은 잠재적 사고가 해당 텍스트 응답의 유효한 의미론을 포착할 뿐만 아니라, 내부에 더 풍부하고 표현력이 뛰어난 표현을 인코딩함을 보여준다. 우리는 또한 LatentMAS의 LLM 에이전트들이 자신의 잠재적 사고를 어떻게 해석하는지 분석하는 사례 연구를 부록 D에 추가로 포함하여 우리의 주장을 뒷받침한다.
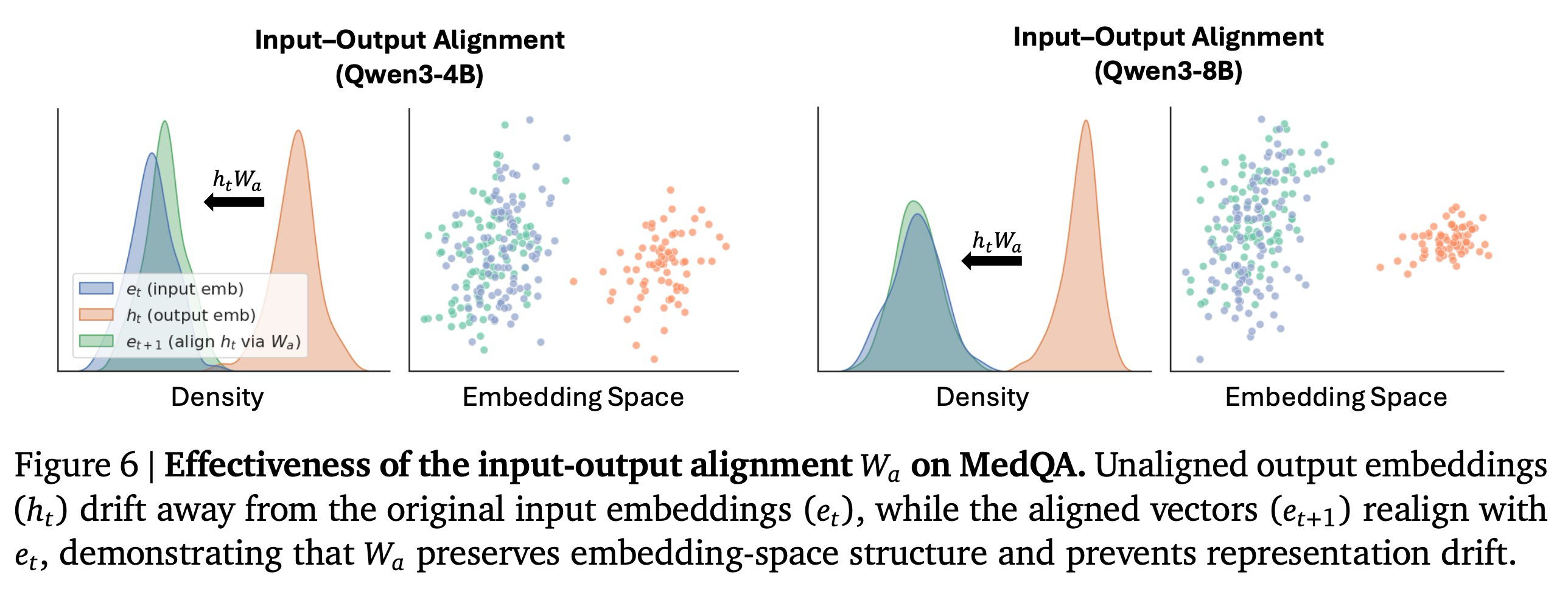
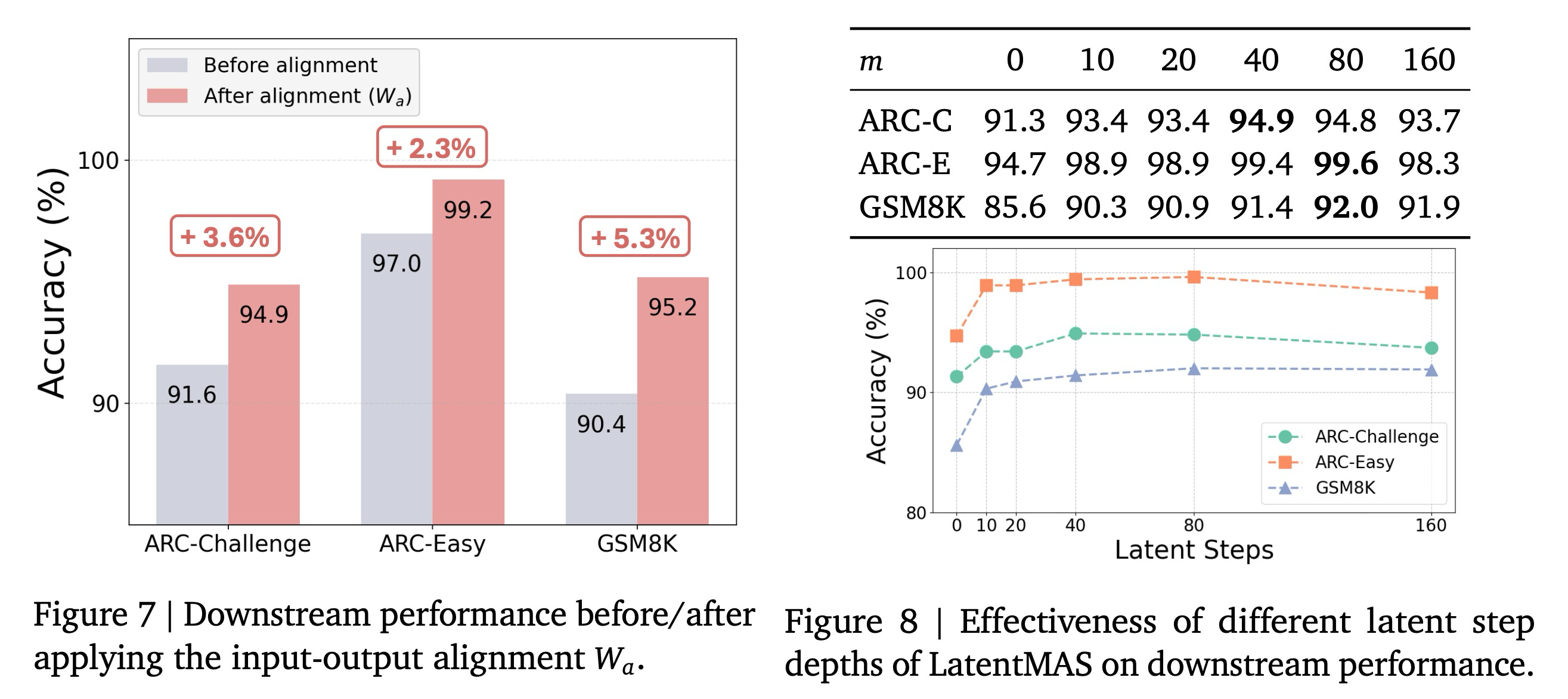
Effectiveness on Input-Output Alignment. 다음으로, 우리는 우리의 방법 설계에서 입력-출력 정렬의 효과를 경험적으로 평가한다. 먼저, 표준 토큰 임베딩 레이어에서 얻은 입력 벡터 를 정렬 전의 새로 생성된 출력 벡터 와 정렬 후의 벡터 모두와 비교한다. 그림 6에서 볼 수 있듯이, 새로 생성된 원래 입력 임베딩 에서 크게 벗어난다. 를 적용한 후, 정렬된 벡터 은 와 다시 정렬되는데, 이는 가 임베딩 공간의 기하학적 및 통계적 구조를 효과적으로 복원하고 반복적인 잠재적 단계 전반에 걸쳐 표현 드리프트(representation drift)를 완화함을 보여준다. 그림 7에서는 를 적용하기 전후의 다운스트림 성능을 추가로 비교하며, 가 가져오는 2.3%-5.3%의 일관된 정확도 향상을 관찰한다.
Optimal Latent Step Depth. LatentMAS에서 최적의 성능을 위해 몇 개의 잠재적 단계가 필요한지 이해하기 위해, 우리는 세 가지 다운스트림 작업 전반에 걸쳐 잠재적 단계 깊이를 증가시키는 효과를 분석한다. 그림 8에서 나타난 바와 같이, 잠재적 단계의 수를 늘리는 것은 일반적으로 다운스트림 성능을 향상시키며, 이는 추가적인 잠재적 사고가 협업 표현력을 강화함을 시사한다. Qwen3-14B에서 세 가지 작업을 모두 고려할 때, 정확도는 꾸준히 상승하여 40-80단계 부근에서 최고점에 도달하는 것을 발견한다. 이 범위를 벗어나면 성능이 정체되거나 감소하는데, 이는 과도한 잠재적 사고 생성이 중복되거나 덜 유용한 정보를 도입할 수 있음을 시사한다. 이 관찰을 기반으로, 우리는 어떠한 작업별 학습 절차 없이도 최고의 정확도-효율성 균형을 일관되게 제공하는 이 범위 내의 적당한 잠재적 단계 예산을 실제로 채택한다.
5. Related Work
LLM-based Multi-agent Systems. 에이전트 AI에 대한 최근 연구는 전통적인 강화 학습 및 정책 조정에 기반을 둔 고전적인 다중 에이전트 시스템을 현대적인 대규모 언어 모델(LLM) 설정으로 확장했으며, 모델이 추론, 계획 및 문제 해결에서 협력하는 자율 에이전트로 작동할 수 있도록 한다. ReAct, AutoGen, CAMEL과 같은 초기 연구들은 명시적인 대화나 역할 할당을 통해 여러 LLM을 조정하여 작업 다양성과 신뢰성을 개선한다. 추가적인 방법들은 에이전트 간의 협력 효율성 및 출현적 특화를 강화하기 위해 구조화된 통신 프로토콜이나 학습 패러다임을 도입한다. 요약하자면, 많은 선행 연구들은 순차적인 기획자-해결사(planner-solver) 파이프라인 또는 계층적인 전문가-요약자(expert-summarizer) 구조를 따르며, 이는 우리가 LatentMAS를 평가하기 위해 채택한 두 가지 MAS 설정에 해당한다. 이러한 알고리즘적 발전 외에도, LLM 기반 MAS는 수학 및 과학 추론, 개방형 질문 응답, 다중 모달 GUI 상호작용과 같은 다양한 영역에 적용되어 복잡한 실제 환경에서의 다재다능함을 입증한다. 이러한 발전된 텍스트 기반 MAS 방법을 기반으로 구축된 우리의 작업은 잠재 기반 다중 에이전트 협업 시스템을 가능하게 하는 것을 목표로 하며, 에이전트를 보다 효율적인 조정 및 표현 능력을 달성하는 긴밀하게 통합된 구성 요소로 취급한다.
Model Collaboration in Latent Space. 모델 앙상블 협업에 대한 최근 연구들은 텍스트 수준 조정에서 잠재 공간 상호작용으로 이동했다. 예를 들어, ThoughtComm은 학습된 인코더-디코더 및 접두사 모듈을 통해 공유 잠재 공간을 학습하고 에이전트 정보를 라우팅한다. Cache-to-Cache는 공유자 모델의 입력 프롬프트의 KV를 수신자 모델로 투영하여 두 모델 간의 의미론적 전송을 가능하게 한다. Mixture of Thoughts는 주 전문가 모델이 다른 모델의 교차 주의 정보를 집계하여 단일 패스, 중앙 집중식 제어 잠재적 융합을 가능하게 한다. 이와 달리, LatentMAS는 학습 불필요(training-free) 잠재 MAS로, 각 모델이 먼저 자체적인 잠재적 사고를 생성하고, 새로 생성된 사고를 포함한 입력이 후속 협업을 위해 한 모델에서 다른 모델로 전송된다.
Latent Reasoning in LLMs. 명시적인 사고 연쇄(CoT) 추론을 넘어, 최근 연구는 LLM의 연속적인 잠재 공간을 대안적인 추론 매체로 탐색했으며, 은닉 상태가 이산적인 토큰 생성이 표현할 수 있는 것보다 더 풍부한 의미론적 구조를 인코딩함을 밝혀냈다. CoCoNut와 같은 잠재적 추론 방법 및 잠재 공간 편집 접근 방식은 내부 표현을 조작하여 모델이 명시적인 토큰 수준의 근거 없이도 더 일관성 있게 추론하고 제어 가능성을 개선하도록 유도함을 입증한다. 이러한 방법들은 숨겨진 상태의 구조를 활용하여 조향, 편집 또는 잠재적 궤적 최적화와 같은 개입을 수행하며, 표면 수준 텍스트와는 무관하게 후속 추론 행동을 형성한다. 연속적인 공간에서 직접 작동함으로써, 이러한 방법들은 표현하기 어렵거나 비효율적인 추론 단계를 유도할 수 있다. 그러나 기존 기술들은 단일 모델의 내부 계산에 국한되며 여러 추론 개체 간의 상호작용이나 조정을 고려하지 않는다. 반면에, LatentMAS는 잠재적 추론을 다중 에이전트 설정으로 확장하여, 각 에이전트가 잠재적 사고를 생성하고 잠재적 정보를 다른 에이전트에게 전파할 수 있도록 한다. 우리의 새로운 프레임워크는 잠재적 추론을 개별 모델의 고립된 능력에서 시스템 수준의 협업 메커니즘으로 전환한다.
6. Conclusion
우리는 다중 에이전트 시스템이 연속적인 잠재 공간 내에서 전적으로 협업할 수 있도록 하는 학습 불필요(training-free) 프레임워크인 LatentMAS를 소개한다. 잠재적 자기회귀적 추론과 손실 없는 잠재적 작업 기억 전송 메커니즘을 결합함으로써, LatentMAS는 텍스트 기반 협업의 내재된 비효율성과 정보 병목 현상을 극복한다. 우리의 이론적 분석은 표현력과 계산 효율성에서 상당한 이득을 확립하며, 다양한 추론, 상식 및 코드 생성 벤치마크에 걸친 실증적 결과는 잠재적 협업이 강력한 단일 모델 및 텍스트 기반 다중 에이전트 시스템(MAS) 기준선들보다 정확도 성능, 토큰 사용량 및 디코딩 속도를 일관되게 향상시킴을 입증한다. 종합적으로, LatentMAS는 자연어의 한계를 넘어 협력하는 차세대 에이전트 시스템을 구축하기 위한 확장 가능하고 일반적인 패러다임 역할을 한다. 흥미로운 향후 연구 방향은 텍스트 기반 MAS의 발전된 사후 학습 패러다임을 조정하여 LatentMAS의 잠재적 협업 프로토콜을 최적화하고, 더 효과적인 다중 에이전트 추론 전략을 발현시키는 것이다.
