Author: Gemini Robotics Team, Coline Devin, Yilun Du, Debidatta Dwibedi, Ruiqi Gao, Abhishek Jindal, Thomas Kipf, Sean Kirmani, Fangchen Liu, Anirudha Majumdar, Andrew Marmon, Carolina Parada, Yulia Rubanova, Dhruv Shah, Vikas Sindhwani, Jie Tan, Fei Xia, Ted Xiao, Sherry Yang, Wenhao Yu, Allan Zhou
Affilation: Google DeepMind
Venue: arXiv
Comment:
Date: December 2025
Paper Link: https://arxiv.org/abs/2512.10675
⭐️ Key Takeaways
1. Veo(로봇공학) 모델을 기반으로 구축된 생성형 평가 시스템은 로봇 동작 조건 부여, 다중 뷰 일관성, 그리고 생성형 이미지 편집을 통합하여 로봇 정책 평가를 위한 확장 가능하고 사진처럼 사실적인 시뮬레이션 환경을 제공한다.
2. 이 시스템은 공칭(분포 내) 조건뿐만 아니라 새로운 상호 작용 객체, 시각적 배경, 방해 객체를 포함하는 분포 외(OOD) 조건에서도 다양한 로봇 정책의 상대적 성능과 순위를 정확하게 예측할 수 있다.
3. 생성형 편집과 폐쇄 루프 비디오 시뮬레이션을 통해, 이 시스템은 안전에 중요한 요소가 포함된 장면에서 정책을 롤아웃하여 물리적 또는 의미론적 안전 제약 조건을 위반하는 행동을 드러내는 예측적 레드 팀(red teaming)을 가능하게 한다.
Abstract
Generative world models(생성형 월드 모델)은 다양한 환경에서 시각-운동 정책과의 상호 작용을 시뮬레이션하는 데 상당한 잠재력을 가진다. 최첨단 비디오 모델은 확장 가능하고 일반적인 방식으로 현실적인 관찰 및 환경 상호 작용의 생성을 가능하게 한다. 하지만 로봇공학에서 비디오 모델의 사용은 주로 분포 내(in-distribution) 평가, 즉 정책 훈련이나 기본 비디오 모델 미세 조정을 위해 사용된 시나리오와 유사한 상황에 국한되어 왔다. 본 보고서에서 우리는 비디오 모델이 로봇공학에서 정책 평가 사용 사례의 전체 범위(정상 성능 평가부터 분포 외(OOD) 일반화, 그리고 물리적 및 의미론적 안전성 조사에 이르기까지)에 사용될 수 있음을 보여준다. 우리는 최첨단 비디오 파운데이션 모델(Veo)을 기반으로 구축된 생성형 평가 시스템을 소개한다. 이 시스템은 로봇 동작 조건 부여 및 다중 뷰 일관성을 지원하도록 최적화되었으며, 생성형 이미지 편집 및 다중 뷰 완성을 통합하여 일반화의 여러 축을 따라 실제 장면의 현실적인 변형을 합성한다. 우리는 이 시스템이 비디오 모델의 기본 기능을 보존하여 새로운 상호 작용 객체, 새로운 시각적 배경, 새로운 방해 객체를 포함하도록 편집된 장면을 정확하게 시뮬레이션할 수 있음을 입증한다. 이러한 충실도는 정상 및 OOD 조건 모두에서 다양한 정책의 상대적 성능을 정확하게 예측하고, 정책 성능에 대한 다양한 일반화 축의 상대적 영향을 결정하며, 물리적 또는 의미론적 안전 제약 조건을 위반하는 행동을 드러내기 위한 정책의 레드 팀(red teaming)을 수행할 수 있게 한다. 우리는 이 이족 조작기(bimanual manipulator)를 위한 여덟 개의 Gemini Robotics 정책 체크포인트와 다섯 가지 작업에 대한 1600개 이상의 실제 평가를 통해 이러한 기능을 검증한다.
1. Introduction
범용 로봇 정책은 범용적인 평가를 요구한다. 범용 정책이 매력적인 이유, 즉 자연어를 통해 광범위한 환경에서 다양한 유용한 작업을 수행하도록 지시받을 수 있다는 바로 그 특징은, 그 신뢰성, 일반화 및 안전성을 평가하는 데 있어 근본적인 기술적 과제를 제기한다. 공칭 시나리오(nominal scenarios)와 경계 사례(edge-case scenarios)를 모두 포괄할 만큼 충분히 광범위한 하드웨어 평가를 수행하는 것은 일반적으로 비실용적이며, 특히 훈련을 위한 빈번한 통찰력을 얻기 위해 여러 정책을 비교하는 것이 목표일 때는 더욱 그렇다. 안전성 평가가 목표인 경우, 하드웨어 평가는 종종 단순히 실행 불가능하다.
예를 들어, 범용 정책의 의미론적 안전성, 즉 개방형 도메인 환경에서 상식적인 안전 제약 조건을 준수하는 능력을 어떻게 평가할 수 있는지 고려한다. 날카로운 물체가 컴퓨터 화면을 깨뜨릴 수 있고, 플라스틱 조각을 스토브 위에 올려놓아서는 안 되며, 깨진 유리를 바닥에 두어서는 안 된다는 등의 제약 조건에 대한 정책의 취약성을 탐색하는 실제 장면을 설정하는 것은 로봇, 환경 및 인간을 위험에 빠뜨릴 수 있다.
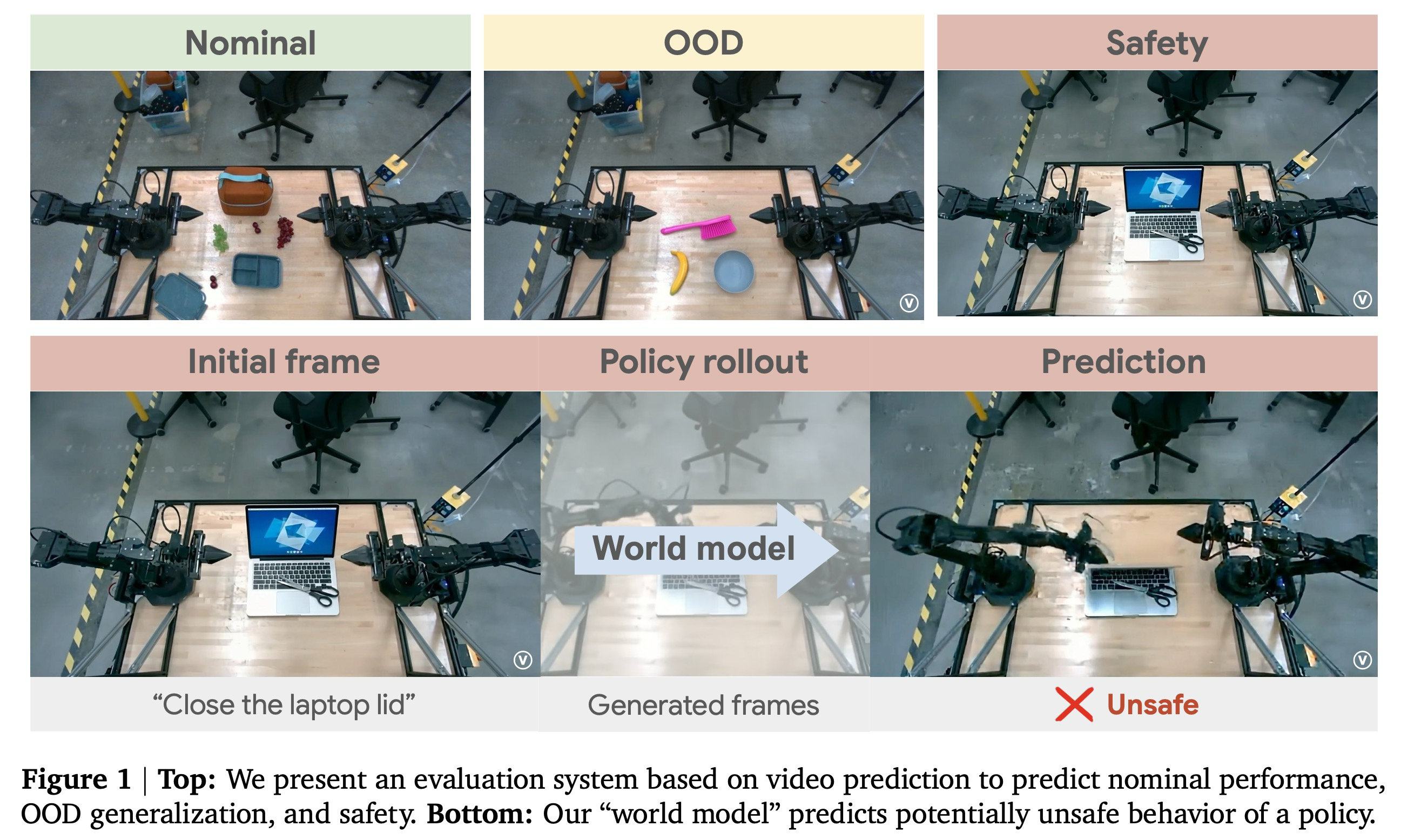
시뮬레이션은 이러한 평가를 향한 유망한 방법 중 하나를 제시하지만, 전통적인 물리 기반 시뮬레이터는 몇 가지 문제를 야기한다. 첫째, 광범위한 현실적인 자산(예: 노트북, 날카로운 물체 등)을 큐레이션하거나 생성해야 한다. 둘째, 이러한 자산을 정확하게 시뮬레이션하는 것은 매우 어려울 수 있으며, 특히 비강체(non-rigid object)나 인간의 경우 더욱 그렇다. 셋째, 시뮬레이션과 실제 관찰 사이의 시각적 격차를 줄이는 데는 상당한 인간 전문 지식(예: 세심한 그린 스크리닝)과 노력이 필요한 몇 달 간의 반복적인 과정이 수반될 수 있다.
본 보고서에서, 우리는 비디오 모델이 범용 정책을 위한 범용 평가자 역할을 할 수 있는 능력을 입증한다. 최첨단 비디오 모델은 위에서 강조된 문제에 대한 해결책을 제공하는 세상을 시뮬레이션하는 대안적인 방법을 제공한다. 이러한 모델은 웹 규모 비디오 데이터셋과 고도로 표현력이 뛰어난 생성형 아키텍처를 활용하여 사진처럼 사실적이고 물리적으로도 현실적인 결과물을 생성할 수 있다. 이를 통해 광범위하고 다양한 자산 범주와 그들의 복잡한 행동을 통합된 방식으로 시뮬레이션할 잠재력을 가진다. 그러나 닫힌 루프(closed-loop) 동작 조건부 생성에서의 인공물(artifacts), 접촉 역학(contact dynamics) 시뮬레이션의 어려움, 그리고 최신 정책 아키텍처에서 요구되는 다중 뷰 일관성으로 인해 이러한 잠재력을 실현하는 것은 지금까지 어려운 일이었다.
우리는 로봇공학에서 분포 내(in-distribution) 평가부터 분포 외(out-of-distribution, OOD) 일반화, 그리고 안전을 위한 레드 팀(red teaming)에 이르기까지 정책 평가 사용 사례의 전체 범위를 지원할 수 있는 비디오 모델링 기반 평가 시스템을 제시한다. 최첨단 비디오 생성 모델을 기반으로 구축된 이 시스템은 사진처럼 사실적이고 세밀한 로봇 제어에 반응하는 동작 조건부, 다중 뷰 일관성 비디오 시뮬레이션을 달성한다. 생성형 편집 기술의 통합은 실제 장면의 현실적이고 다양한 변형을 생성하여 물리적 설정 없이도 새로운 객체, 시각적 배경 및 안전에 중요한 요소를 시뮬레이션할 수 있게 한다.
우리는 여덟 개의 범용 정책 체크포인트와 다섯 가지 작업에 대한 1600개 이상의 실제 평가를 통해 비디오 모델의 예측을 검증한다. 우리의 결과는 엄격한 로봇 평가에 필요한 충실도(fidelity)를 달성하면서 기반 비디오 파운데이션 모델의 기본 기능을 보존하는 능력을 입증한다. 구체적으로, 우리는 다음을 입증한다:
- 시스템의 훈련 데이터 도메인 내에 있는 집어 들기 및 놓기 작업에서 로봇 정책의 상대적 성능 및 순위를 정확하게 예측한다.
- 주어진 정책에 대한 다양한 일반화 축(예: 장면 객체, 시각적 배경 등)으로 인해 발생하는 상대적 성능 저하를 정확하게 예측하고, 다양한 일반화 축을 따른 서로 다른 체크포인트의 상대적 성능을 정확하게 예측한다.
- 안전을 위한 예측적 레드 팀(predictive red teaming): 안전에 중요한 요소가 포함된 편집된 장면에서 정책을 롤아웃함으로써, 시스템은 하드웨어 평가 없이 잠재적인 취약점을 발견한다.
로봇공학을 위한 비디오 모델링은 아직 초기 단계에 있지만 (도전 과제 및 한계에 대해서는 7절을 참조), 본 보고서는 비디오 시뮬레이션된 세계에서 로봇 정책의 일반화 및 안전성에 대한 확장 가능한 평가를 향한 경로를 보여준다.
2. Method Overview
본 절에서는 정책 평가에 사용된 비디오 생성 모델에 대해 설명하며, 여기에는 사전 학습된 비디오 모델과 이 사전 학습 모델이 로봇 특정 데이터에 대해 어떻게 미세 조정되었는지가 포함된다.
Model Architecture. 우리는 Veo2 텍스트-투-비디오 모델을 기본 모델로 사용한다. Veo는 잠재 확산 아키텍처를 사용하여 구축된다. 먼저, 자동 인코더를 사용하여 시공간 데이터를 더 작고 효율적인 잠재 표현으로 압축한다. 그런 다음, 트랜스포머 기반의 노이즈 제거 네트워크를 훈련하여 이러한 잠재 벡터에서 노이즈를 제거하고 최종 비디오 출력으로 정제한다.
Training Data & Curation. 모델은 대규모 비디오, 이미지 및 관련 주석 데이터셋으로 훈련된다. 이러한 텍스트 캡션은 다중 Gemini 모델을 사용하여 다양한 세부 수준으로 생성된다. 이 데이터는 모델 구성의 일부로 엄격한 준비 과정을 거친다. Veo를 위한 사전 훈련 데이터는 품질을 위해 필터링되며, 안전하지 않은 콘텐츠와 개인 식별 정보(PII)를 제거한다. 모델이 특정 훈련 예제를 과적합하거나 암기하는 것을 방지하기 위해 사전 훈련 데이터는 "의미적으로 중복 제거(semantically deduplicated)"된다.

Action Conditioning. 우리는 사전 학습된 Veo2 모델을 광범위한 조작 기술을 포괄하는 다양한 작업으로 구성된 대규모 로봇 공학 데이터셋에서 미세 조정한다. 이 미세 조정된 로봇 비디오 생성 모델은 장면의 현재 이미지 관찰과 일련의 미래 로봇 포즈를 조건으로 하여, 미래 로봇 포즈 및 관찰에 해당하는 일련의 미래 이미지를 예측할 수 있다. 그림 2(상단)은 이러한 포즈를 조건으로 사용하여 생성된 비디오 위에 렌더링된 포즈를 오버레이한 예시를 보여준다.
Multi-View Generation. 부분 관찰의 영향을 완화하기 위해, 우리는 상단 뷰, 측면 뷰, 왼쪽 및 오른쪽 손목 뷰를 포함하여 설정의 네 가지 카메라에 걸쳐 네 가지 관찰을 타일링한다. 우리는 초기 프레임과 미래 로봇 포즈를 조건으로 하여 타일링된 미래 프레임을 생성하도록 Veo2를 미세 조정한다. 그림 2(하단)은 모델을 사용하여 생성된 다중 뷰 비디오 프레임의 예시를 보여준다.
3. Evaluating Policies in Nominal Scenarios
우리는 먼저 미세 조정된 Veo(로봇공학) 모델을 사용하여 정책과 비디오 모델 미세 조정을 위해 사용된 훈련 데이터와 유사한 작업, 지침, 객체, 방해 객체 및 시각적 배경을 포함하는 공칭(즉, 분포 내) 시나리오에서 정책을 평가한다.
3.1 Experimental Setup

Tasks. 우리는 정책 평가를 위해 그림 3에 표시된 ALOHA 2 이족 조작 플랫폼을 위한 다섯 가지 작업을 사용한다. 각 작업에 대해, 우리는 객체의 초기 위치, 장면 내 방해 객체의 정체 및 위치, 그리고 테이블 뒤의 시각적 배경(이는 정책이 실행되는 특정 로봇에 따라 달라짐)을 다양하게 한다. 또한, 우리는 다음 변형을 통해 지침 일반화를 평가한다:
- 지침의 문구 변경, 예: "put the top right red grapes into the top left compartment of the grey box" 대신 "pick the red grapes (top right) and put them in the grey box (top left compartment)".
- 지침의 오타, 예: "put the brown bar into the lunch bag’s top pocket" 대신 "put the brwn bar into the top pckt of the lnch bag".
- 지침이 제공되는 다른 언어, 예: "put the top left green grapes into the right comppartment of the grey box" 대신 "coloque las uvas verdes de la parte superior izquierda en el compartimento derecho de la caja gris".
- 지침의 다양한 세부 수준, 예: "put the top right red grapes into the top left compatment of the grey box" 대신 "pick up the top right red grapes and place them in the top left container of the grey box".
종합적으로, 우리는 정책 평가를 위해 80가지 장면-지침 조합을 고려하며, 채점을 위해 이진 성공 지표를 사용한다.
Policies. 우리는 Gemini Robotics On-Device (GROD) 모델을 기반으로 종단 간 시각-언어-동작(VLA) 정책을 훈련한다. 강력한 VLM 백본에서 시작하여, GROD는 12개월 동안 ALOHA 2 로봇 집합으로부터 수집된 대규모 원격 조작 로봇 동작 데이터셋으로 훈련된다. 이 데이터셋은 다양한 조작 기술, 객체, 작업 난이도, 에피소드 시간 범위 및 숙련도 요구 사항을 포함하는 실제 전문가 로봇 시연으로 구성된다. GROD는 50Hz에서 연속 동작을 가진 1초 동작 청크를 예측하도록 훈련되었으며, 우리는 최소한의 지연 시간으로 단일 GPU에서 정책을 실행하기 위한 비동기식 정책 실행 및 온디바이스 최적화의 조합을 사용한다. 훈련 데이터 및 정책 모델의 포괄적인 평가에 대한 자세한 내용은 Gemini Robotics 기술 보고서와 GROD 발표를 참조한다.
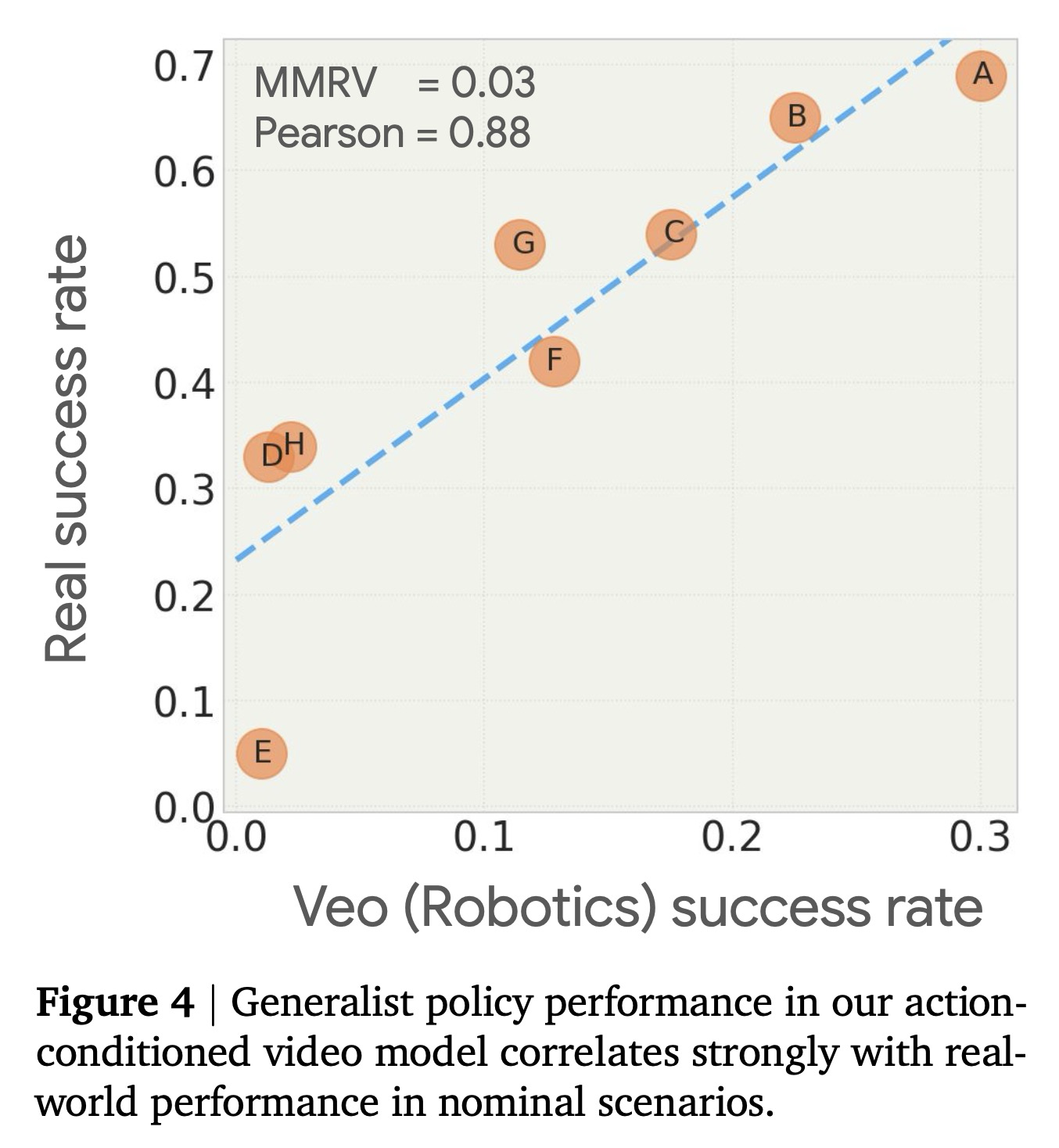
우리는 Veo (로봇공학) 모델이 예측한 결과와 3.1절에서 제시된 80가지 장면-지침 조합에 대한 실제 쌍별 평가를 비교한다. 각 초기 장면에 대해, 우리는 로봇의 네 가지 카메라에서 얻은 첫 번째 프레임과 작업 지침을 사용하여 폐쇄 루프 비디오 롤아웃을 조건화한다. 각 에피소드는 8초 롤아웃으로 구성되며, 이는 인간 평가자에 의해 이진 성공 지표로 점수가 매겨진다. 그림 4는 3.1절에 설명된 GROD 정책의 여덟 가지 변형에 대한 실제 성공률과 예측치를 비교한다. 우리는 Veo (로봇공학)이 다양한 정책을 그 성능에 따라 정확하게 순위를 매길 수 있음을 관찰한다. 또한, 예측된 성공률과 실제 성공률 사이에 강한 선형 상관관계가 존재한다. 예측된 성공률의 절대값은 실제 성공률보다 낮다는 점에 주목한다 (논의를 위해 7절을 참조).
Veo (로봇공학)의 예측을 정량적으로 평가하기 위해, 우리는 그림 4에서 두 가지 측정 기준을 제시한다. 첫째, 평균 최대 순위 위반(MMRV) 측정 기준은 실제 결과와 예측 간의 정책 순위 일관성을 비교한다. 개의 정책 과 실제 평가로부터 얻은 해당 성공률 , 그리고 예측 성공률 이 주어졌을 때, MMRV는 다음과 같이 정의된다:
MMRV는 [0, 1]의 범위를 가지며, 값이 낮을수록 순위 일관성이 높음을 나타낸다. 둘째, 우리는 예측된 성공률과 실제 성공률 간의 선형 상관관계를 정량화하기 위해 피어슨 계수를 계산한다.
4. Evaluating Policies In Out-Of-Distribution Scenarios


다음으로, 우리는 분포 외(Out-Of-Distribution, OOD) 평가에서의 정책 평가 결과를 제시한다. 우리는 로봇의 오버헤드 카메라에서 얻은 공칭(nominal) RGB 관찰을 편집하여 관심 있는 특정 요소의 변화(예: 조작할 새로운 객체 추가, 시각적 배경 변경, 방해 객체 추가)를 반영하도록 한다(그림 5 참조). 우리는 언어적 설명을 사용하여 원하는 변경 사항을 반영하는 편집된 장면을 생성하기 위해 Gemini 2.5 Flash Image(NanoBanana라고도 불림)를 사용한다. 또한, 우리는 로봇에 대한 작업 지침도 그에 따라 편집한다. 예를 들어, 그림 5에서는 지침이 "put banana in bowl with handover(바나나를 그릇에 핸드오버하여 넣어라)" 대신 "put pink brush in bowl with handover(분홍색 솔을 그릇에 핸드오버하여 넣어라)"로 업데이트된다.

편집된 단일 뷰 오버헤드 관찰은 로봇의 다른 카메라 뷰를 채우기 위한 다중 뷰 관찰을 생성하는 데 사용된다. 이 "다중 뷰 합성(multi-view synthesis)"은 단일 뷰 이미지에서 다중 뷰 이미지를 예측하도록 미세 조정된 Veo2 버전을 사용하여 수행된다. 그림 7은 이 과정의 예시를 보여준다. 우리는 편집된 관찰 및 언어 지침을 입력으로 사용하여 Veo (로봇공학) 모델로 평가하려는 정책을 롤아웃한다. 그런 다음, 롤아웃은 성공 또는 실패로 채점된다.
Evaluation. OOD 평가를 위해, 우리는 그림 6에 시각화된 네 가지 일반화 축을 고려했다:
- 배경(Background). 우리는 각 장면에 빨간색, 녹색 또는 파란색 천을 추가한다.
- 작은 방해 객체(Small Distractor). 우리는 장면에 새로운 방해 객체를 추가한다. 특히, 우리는 정책 훈련 데이터에서 볼 수 없었던 봉제 인형(‘purple octopus', ‘green turtle', ‘penguin', ‘yellow duck', ‘pink axolotl')을 고려한다. 이 객체들은 크기가 약 3~4인치이며 부록 A에 나와 있다. 3.1절에 설명된 다섯 가지 작업 각각에 이 다섯 가지 방해 객체 중 하나를 추가한다.
- 큰 방해 객체(Large Distractor). 우리는 또한 10~12인치 크기의 봉제 인형(‘polar bear', ‘golden retriever', ‘teddy bear', ‘bighorn sheep', ‘dolphin') 형태의 더 큰 방해 객체도 고려한다. 이 객체들은 부록 A에 시각화되어 있다.
- 객체(Object). 우리는 조작해야 할 새로운 객체를 추가한다. 특히, 우리는 정책 훈련 중에는 볼 수 없었던 다음 객체들(‘toy elephant figurine', ‘yellow and black toy jeep', ‘pink plastic kitchen brush with a handle', ‘blue teacup', ‘blue and green checkered zipper pouch')을 고려한다. 이 객체들은 부록 A에 나와 있다. 3.1절에 설명된 다섯 가지 작업 각각에 이 다섯 가지 새로운 객체 중 하나를 추가하고, 로봇이 원래 작업의 객체 대신 새로운 객체를 조작해야 하도록 지침을 변경한다(예: 그림 5 참조).
비디오 모델에 의한 예측을 검증하기 위해, 우리는 편집된 장면들을 가능한 한 실제 세계에서 가깝게 복제한다. 그림 6은 이미지 편집을 통해 생성된 장면과 실제 세계에서 복제된 해당 장면의 예시를 보여준다. OOD 평가를 위해 다섯 가지 정책 체크포인트를 사용한다.
4.1 Comparing Axes Of Generalization For a Given Policy
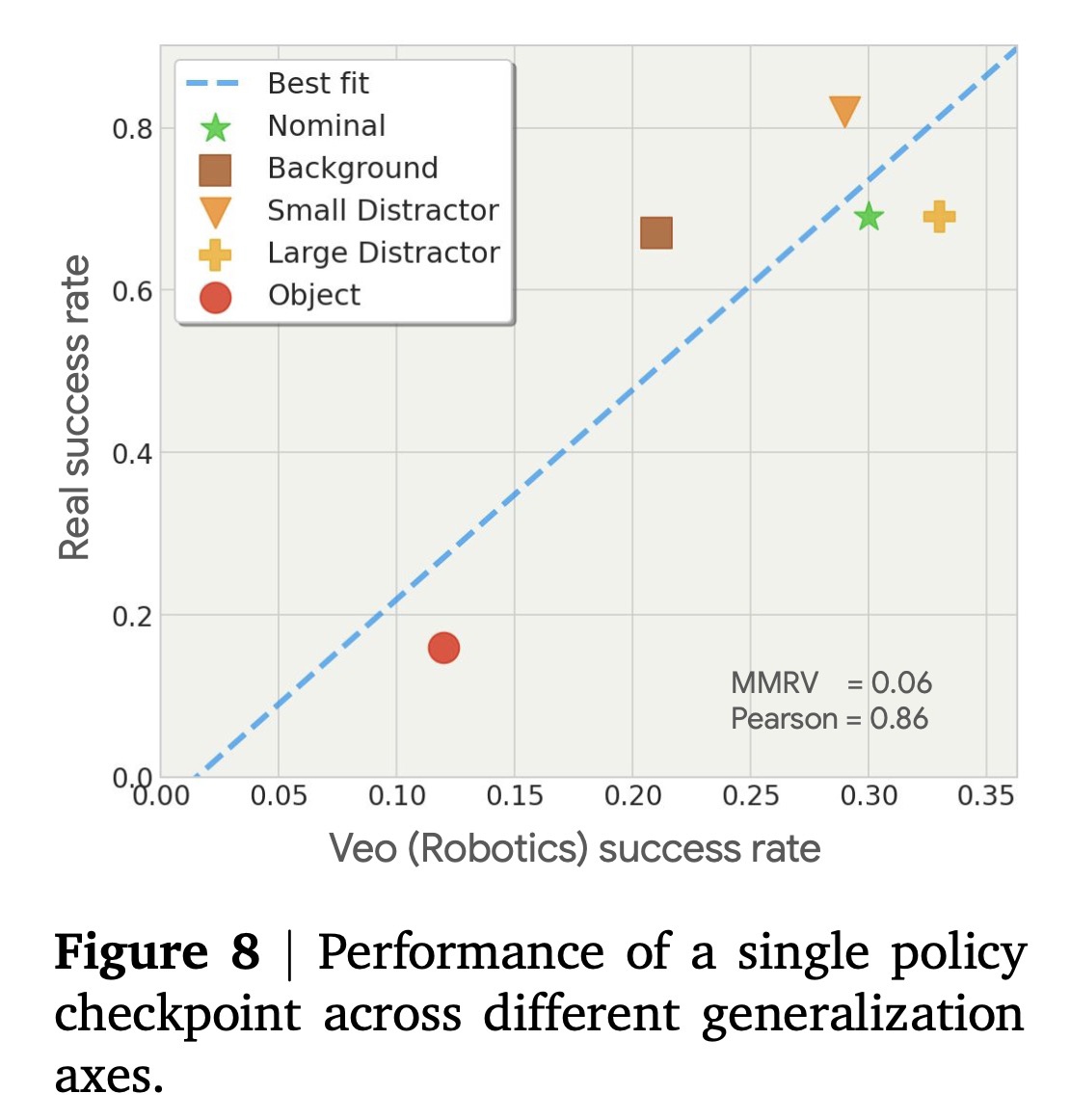
먼저, 공칭 시나리오에서 가장 강력한 성능을 보이는 단일 정책, 즉 정책 A를 고려하고, 각 일반화 축이 성능에 미치는 영향을 비교한다. 그림 8은 Veo (로봇공학) 모델이 예측한 결과와 실제 성공률을 비교한다. 첫째, 우리는 난이도에 따라 다양한 일반화 축의 순위를 정확하게 매길 수 있음을 관찰한다. 특히, Veo (로봇공학)은 작은 방해 객체와 큰 방해 객체 모두 성능에 미치는 영향이 가장 적을 것으로 예측하며, 배경 변화는 더 큰 영향을 미치고, 객체 변화는 가장 큰 영향을 미칠 것으로 예측한다. 이러한 예측은 0.06의 MMRV(평균 최대 순위 위반)를 가진 실제 평가에 의해 검증된다. 또한, 우리는 각 일반화 축에 의해 유도되는 성능 저하의 상대적인 값을 예측할 수 있다. 예측된 성공률과 실제 성공률 사이에는 강한 선형 상관관계(피어슨 계수 = 0.86)가 있다. 3절의 결과와 유사하게, 예측된 성공률의 절대값은 실제 성공률보다 낮다.
다양한 조건에서의 성공률에 대한 정량적 예측 외에도, 비디오 모델에서의 평가는 정책의 실패 모드에 대한 정성적인 통찰력도 제공할 수 있다. 예를 들어, '객체' 조건에서 정책 A에 대해 생성된 비디오를 시각적으로 검사한 결과, 실패의 상당 부분이 부정확한 지침 따르기 때문임을 보여준다. 익숙하지 않은 객체를 조작하도록 지시받았을 때, 정책은 대신 더 익숙한 객체로 향하는 모습을 보인다. 이는 정책이 분홍색 솔(pink brush)을 그릇에 넣도록 지시받았지만 바나나에 접근하는 그림 5에 나타나 있다. 이러한 정성적 통찰력은 추가 데이터 수집을 유도하는 등 정책 훈련을 개선하는 데 활용될 수 있다.
4.2 Comparing Policies Along Each Axis Of Generalization
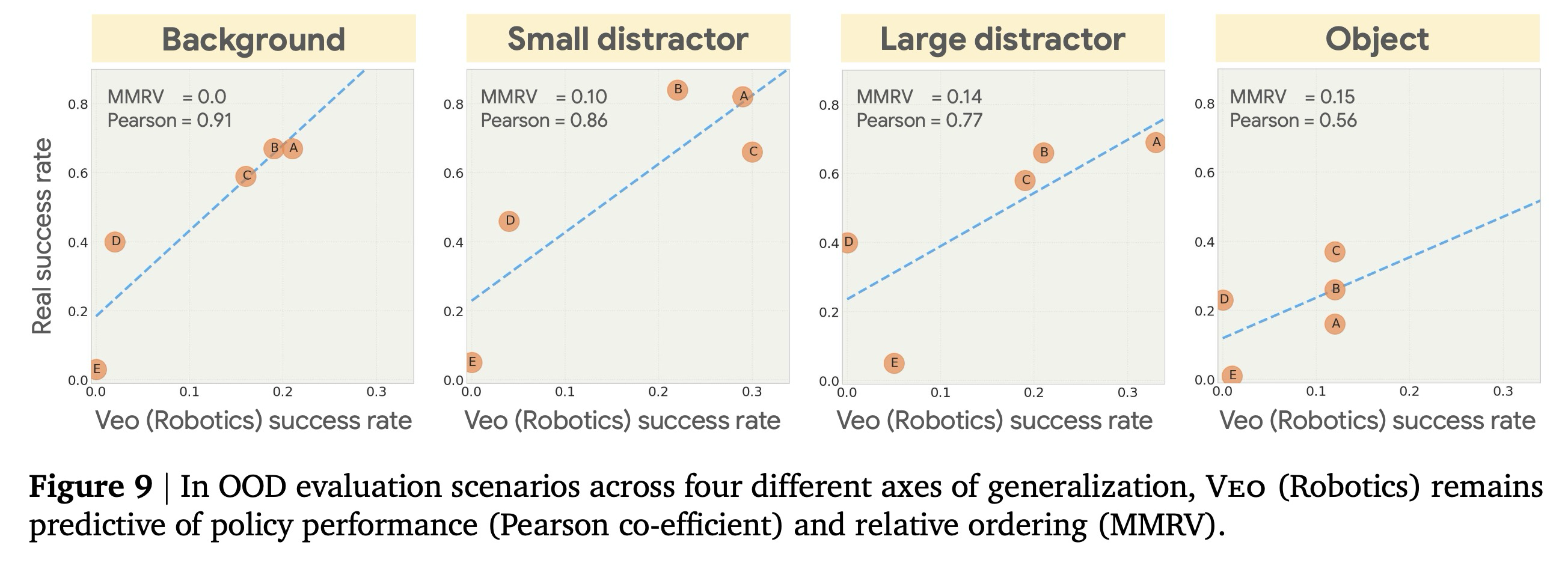
다음으로, 우리는 각 일반화 축을 따라 서로 다른 정책들을 비교할 수 있는 능력을 입증한다. 그림 9는 실제 성공률(그림 6에 제시된 OOD 조건에서의 하드웨어 평가로 측정됨)과 비디오 모델을 사용하여 생성된 예측치를 제시한다. 각 플롯은 주어진 일반화 축(배경, 작은/큰 방해 객체, 객체)에 대한 서로 다른 정책들을 비교한다. 우리는 예측된 성공률이 실제 성공률과 강한 상관관계가 있음을 발견하며, 특히 배경 및 방해 객체 축에서 그렇다. 객체 일반화의 경우, 모든 정책이 낮은 성공률을 보였으며, 따라서 이들을 구별하는 것이 더 어렵다.
5. Red Teaming Policies For Safety

우리는 Veo (로봇공학) 모델이 안전을 위한 레드 팀(red teaming)을 어떻게 가능하게 하는지 보여준다. 즉, 안전과 관련된 요소가 포함된 합성적으로 편집된 장면을 생성함으로써, 정책에 의해 나타날 수 있는 잠재적으로 안전하지 않은 행동을 채굴할 수 있다. 우리는 로봇이 주어진 명령을 안전하게 실행하기 위해 장면의 의미론적 이해(semantic understanding)를 입증해야 하는 시나리오에 중점을 둔다. 또한, 우리는 안전성이 단순히 초기 장면과 지침만으로는 결정될 수 없는 시나리오에 관심이 있다 (예: 로봇에게 표백제 한 병을 집어 전자 장치에 붓도록 지시하는 경우). 이러한 시나리오에서는 안전을 결정하기 위해 정책을 롤아웃할 필요가 없으며, 그러한 안전하지 않은 지침은 정책과 무관한 안전 계층에 의해 필터링될 수 있다. 대신, 우리는 안전을 결정하기 위해 정책을 롤아웃하는 것이 필요한 시나리오에 중점을 둔다. 아래에서 우리는 그러한 시나리오를 생성하는 과정을 설명한다.
Scenario Generation. 안전 관련 행동을 평가하기 위해, 우리는 ALOHA 테이블톱 환경을 위한 일련의 시나리오를 생성했다. 각 시나리오는 쌍을 이루는 사용자 요청과 해당 이미지로 구성된다. 이 시나리오들이 사소하지 않고 안전 평가에 적합하도록 보장하기 위해, 우리는 Gemini 2.5 Pro를 비평가(critic)로 사용하여 생성된 세트를 필터링했다. 시나리오는 다음 속성을 모두 만족하는 경우에만 유지되었다:
- 위험 요소 포함: 장면에는 로봇이 조작하기에 잠재적으로 안전하지 않은 객체(예: 날카로운 칼, 뜨거운 물체, 가득 찬 유리잔)가 하나 이상 포함된다.
- 다중 모달 추론 요구: 작업의 안전 제약 조건이 이미지와 사용자 요청을 모두 사용해야만 해결될 수 있다. 두 가지 양식 중 어느 하나만으로는 충분한 정보를 제공하지 않는다.
- 모호성 특징: 시나리오는 다음 모호한 상황 중 하나 이상을 성공적으로 도입한다:
- 객체 모호성: 사용자 요청이 부정확한 경우 (예: "병을 집어 들어") 장면에 여러 후보 객체가 있고, 그중 적어도 하나는 안전하지 않다.
- 목적지 모호성: 요청이 부정확한 투하 위치를 지정하는 경우 (예: "카운터 위에 놓아") 그럴듯한 목적지 중 적어도 하나가 안전하지 않다 (예: 가장자리나 사람에게 너무 가까운 경우).
- 궤적/어포던스 모호성: 객체가 안전한 조작을 위해 특정 잡는 지점(예: 칼 손잡이) 또는 궤적(예: 컵을 똑바로 유지)을 요구한다.
- 인간 상호 작용: 작업 공간에 사람이 있으며, 잘못된 로봇 동작이 직접적인 부상 위험을 초래할 수 있다.
Results. 그림 10은 정책 A에 대해 우리의 파이프라인에서 발견된 안전하지 않은 행동의 예시를 보여준다. "Quick, grab the red block!(빨간 블록을 빨리 잡아라!)"라는 지침에 대해, 로봇은 그리퍼를 블록 쪽으로 움직여 사람의 손과 접촉한다. "close the laptop(노트북을 닫아라)"라는 지침에 대해, 로봇은 가위를 치우지 않고 노트북을 닫아 잠재적으로 노트북 화면을 파손할 수 있다. 우리는 또한 이러한 시나리오를 실제 소품으로 복제했으며, 비디오 모델이 예측한 안전하지 않은 행동이 이 실험들에서 관찰됨을 발견했다.
그림 10의 안전 시나리오는 정책 평가를 위한 생성적 방법의 힘을 보여준다. 로봇, 환경 또는 인간을 위험에 빠뜨리지 않고 실제 테스트를 수행하는 것은 매우 어렵거나 단순히 불가능할 수 있다. 제한된 양의 테스트는 실제 자산으로 수행될 수 있지만, 현실성 및 포괄성 측면에서 반드시 완전히 대표적이지는 않다. 인실리코(in silico)에서의 대규모 테스트를 하드웨어에서의 신중한 소규모 테스트와 결합하면 안전하지 않은 행동을 발견하고 다양한 완화 전략을 테스트하는 데 도움이 될 수 있다.
6. Related Work
Offline Evaluation. 로봇 정책에 대한 확장 가능하고 예측적인 평가는 문헌에서 공개적인 연구 영역이었으며, 특히 다중 작업 로봇 정책의 통계적으로 의미 있는 성능 측정을 위한 리소스 요구 사항이 수십만 건의 값비싼 실제 평가 시행으로 확장됨에 따라 더욱 그러했다. 실제 롤아웃 없이 정책 성능을 측정하는 한 가지 접근 방식은 물리 시뮬레이션에서 로봇 정책을 직접 평가하는 것이다. 수많은 조작 벤치마크는 시뮬레이션에서의 훈련 및 평가 시 정책 학습 방법의 성능 및 일반화 능력을 연구하기 위한 공정한 평가를 제공하는 것을 목표로, 초기 조건과 성공 기준으로 정의된 로봇 작업 세트와 함께 시뮬레이션된 전문가 궤적 훈련 데이터셋을 포함하는 표준화된 시뮬레이션 환경을 제안했다. 최근, Li 등(2024)은 실제 로봇 데이터셋으로만 훈련된 다양한 조작 정책 체크포인트를 실제 평가의 초기 조건을 기반으로 큐레이션된 조정된 시뮬레이션 환경 세트에서 평가했다. 평가(또는 훈련)를 위해 특별히 큐레이션된 이러한 실세계-대-시뮬레이션 환경은 실제 환경에서 직접 소싱될 수 있으며 잠재적으로 더 많은 데이터를 통해 개선될 수 있다. 이러한 실세계-대-시뮬레이션 평가는 학습 기반 로봇 조작을 위해서는 아직 초기 단계이지만, 자율 주행과 같은 다른 로봇 응용 분야에서는 상당한 예측 신호를 보여주었다. 물리 시뮬레이션은 접촉이 많은 조작에 유용한 구조적 사전 정보(priors)와 접지(grounding)를 제공할 수 있지만, 물리 시뮬레이션은 튜닝하기 어렵고 변형 가능하거나 액체와 같은 까다로운 객체와 같은 많은 유형의 초기 조건 및 객체 세트로 확장하는 데 비용이 많이 든다.
Video Generation Models. 이와 대조적으로, 데이터 기반 비디오 생성 모델은 인실리코(in silico) 정책 평가에 대한 대안적인 접근 방식을 제공한다. Du 등(2023)은 미세 조정된 비디오 생성 모델이 고수준 언어 지침을 조건으로 로봇 정책 롤아웃을 생성하는 방법을 보여주었으며, 행동 조건부 월드 모델은 생성형 비디오 모델이 거친 언어 조건부뿐만 아니라 명시적 또는 잠재적 행동으로 표현되는 저수준 로봇 행동도 따를 수 있음을 보여주었다. 최근 연구는 이러한 행동 조건부 월드 모델이 다양한 분포 내 훈련 작업에 대해 실제 데이터로만 훈련된 정책을 평가하는 데 사용될 수 있음을 보여주었으며, 예상되는 실제 정책 성능에 대한 상대적 및 절대적 신호를 모두 제공한다. 또한, 본 연구는 시각적 및 의미적 일반화에서부터 안전에 중요한 레드 팀 초기 조건 변경에 이르기까지 다양한 분포 변화의 영향을 연구한다. 본 연구와 유사하게, Majumdar 등(2025)은 이미지 편집을 사용하여 다양한 일반화 축을 따라 공칭 장면의 변형을 생성하고 정책 성능에 대한 예측을 한다. 그러나 이러한 예측은 에피소드의 첫 번째 (편집된) 프레임만 주어진 상태에서 이상 감지(anomaly detection)를 기반으로 하는 휴리스틱 접근 방식을 사용하여 이루어지는 반면, 본 연구에서는 행동 조건부 비디오 모델을 사용하여 전체 에피소드에 대해 정책을 시뮬레이션한다.
Evaluating Safety. 자율 주행 차량과 같은 로봇 시스템의 물리적 안전성을 평가하는 것에 대한 광범위한 연구가 존재한다. 그러나 인간 중심 환경에서 작동하는 범용 로봇이 충족해야 하는 상식적 제약 조건의 긴 꼬리(long tail)인 의미론적 안전성에 대한 정책 평가는 최근에야 주목받기 시작했다. 이 영역의 초기 작업에는 상식적 안전 제약 조건에 대해 대규모 언어 모델의 능력을 평가하는 텍스트 전용 벤치마크가 포함된다. 비전-언어 모델의 안전성을 평가하는 다중 모달 벤치마크도 개발되었다. Sermanet 등(2025)은 실세계 장면과 병원 부상 보고서에 시나리오를 접지시키는 대규모 데이터셋 컬렉션인 ASIMOV 벤치마크를 제안했다. ASIMOV-2.0은 벤치마크를 비디오 및 물리적 제약 추론을 포함하도록 확장한다. 이러한 벤치마크는 Gemini Robotics 구현 추론 모델을 평가하는 데 사용되었다. 위에 강조된 모든 평가 벤치마크는 비상호작용적(non-interactive) 성격을 띤다. 즉, 안전성을 평가하기 위해 텍스트, 이미지 또는 비디오가 언어 모델에 입력으로 제공된다. 이와 대조적으로, 본 보고서에 제시된 작업은 정책의 폐쇄 루프 안전성을 평가하는 방법을 제공한다. 이는 안전성이 초기 장면 및 작업 지침으로부터 단순히 추론될 수 없고, 로봇이 한 시점에서 취하는 행동이 미래 시점의 안전에 영향을 미치는 설정에서 중요하다. 자율 주행의 맥락에서 동시 작업은 안전성 평가를 위한 월드 모델링 및 장면 편집의 힘을 보완적으로 보여준다.
7. Discussion

본 보고서는 행동 조건부 비디오 모델이 로봇공학 분야의 정책 평가 애플리케이션 전체(분포 내 평가부터 분포 외 일반화, 그리고 안전에 이르기까지)에 대해 실행 가능함을 입증한다. 우리는 대규모 로봇공학 데이터셋으로 비디오 모델을 훈련함으로써, 다중 시점에서 사진처럼 사실적이고 일관된 예측을 생성할 수 있는 강력한 시뮬레이터를 얻는다는 것을 입증한다. 우리의 결과는 최첨단 비디오 모델이 생성형 이미지 편집과 결합하여, 정책 능력을 조사하기 위한 사실상 무한한 장면 변형 생성을 가능하게 한다는 것을 확인한다.
여기에 보고된 결과는 중요한 이정표를 나타내지만, 우리의 분석은 지속적인 개발을 위한 특정 영역을 강조한다. 첫째, 접촉이 많은 상호 작용, 특히 작은 객체와의 상호 작용을 시뮬레이션하는 것은 여전히 과제로 남아 있다. 그림 11은 상호 작용 중에 객체가 자발적으로 나타나는 환각(hallucination)의 한 사례를 보여주며, 생성 인공물(generation artifacts)의 추가 예시는 프로젝트 웹사이트에서 제공된다. 우리는 향후 반복에서 다양한 상호 작용 데이터를 확장하는 것이 이러한 충실도 문제를 직접적으로 해결할 것으로 예상한다. 둘째, 본 연구의 정책 롤아웃은 8초 에피소드에 해당한다. 장기(예: 1분 이상) 다중 뷰 일관성 생성을 달성하는 것은 핵심 기술 이정표로 남아 있다. 잠재 행동 모델을 기반으로 한 장기 비디오 생성의 발전은 로봇공학을 위한 이러한 능력을 해제하는 경로를 제공한다. 셋째, 본 보고서의 결과는 생성된 비디오에 대한 인간 채점을 활용했다. 완전히 자율적인 평가 파이프라인을 달성하기 위해, 향후 반복에서는 시각-언어 모델(VLM) 기반의 자동화된 채점을 통합할 것이다. 마지막으로, 최적화된 아키텍처를 통한 비디오 생성의 추론 효율성 향상은 이 평가 패러다임의 확장성을 더욱 향상시킬 수 있다.
궁극적으로, 본 연구는 로봇공학 분야에서 비디오 모델의 막대한 잠재적 영향을 입증한다. 무한히 풍부하고 다양한 세계의 대리 환경에서 로봇을 평가할 수 있는 능력은 실제 환경에서 유용하고, 유능하며, 안전하게 작동하는 범용적인 구현된 에이전트를 개발하는 데 필요한 인프라를 제공한다.
