COMPLEXITY-BASED PROMPTING FOR MULTI-STEP REASONING Yao Fu♠∗, Hao Peng♣, Ashish Sabharwal♣, Peter Clark♣, Tushar Khot♣ ♠University of Edinburgh ♣Allen Institute for AI yao.fu@ed.ac.uk, haop@allenai.org, ashishs@allenai.org, peterc@allenai.org, tushark@allenai.org [Submitted on 3 Oct 2022 (v1), last revised 30 Jan 2023 (this version, v2)]
1 서론 (INTRODUCTION)
LLM은 단 몇 개의 추론 예시만 주어졌을 때도 복잡한 다단계 추론을 수행할 수 있는 창발적 능력(emergent ability)을 나타냄.
Cot 기반 다단계 추론에서의 example selection 연구함.
제안: 복잡도 기반 프롬프트: 추론 단계가 더 많은 복잡한 사고 사슬을 포함한 예시들을 프롬프트로 선택, 복잡도 기반 일관성: 모든 생성된 사슬에 대해 단순히 다수결을 취하는 대신, 상위 K개의 복잡한 사슬에 대해서만 투표를 수행하는 방식

1A: 두 개의 추론 단계를 가진 단순한 예시
1B: 아홉 개의 추론 단계를 포함한 복잡한 사례
GPT-3 175B(Brown et al., 2020)는 입력 프롬프트의 복잡도가 높아질수록 추론 성능이 분명히 향상되고, 복잡한 프롬프트가 단순한 프롬프트보다 더 우수한 성능.
2 관련 연구 (RELATED WORK)
창발적 능력(Emergent Abilities)과 다단계 추론(Multi-Step Reasoning)
모델이 커짐에 따라 어떤 독특한 능력이 새롭게 나타나는가(Kaplan et al., 2020; Wei et al., 2022a)? 언어 이해 과제의 폭넓은 스펙트럼 중에서 다단계 추론에 주목.
-> 프롬프트 복잡도(prompt complexity)의 결정적 역할 입증
사고 사슬 추론(Chain-of-Thoughts Reasoning)
원래의 CoT 논문(Wei et al., 2022b)은 8개의 수작업 예시를 프롬프트로 사용했고, 이후 대부분의 연구가 이를 재사용함.
-> 복잡도 기반 예시 선택(complexity-based prompt selection)을 새롭게 제안하여 기존 CoT보다 현저히 향상된 성능 달성
프롬프트 예시 선택(Example Selection for Prompting)
현재 대형 모델의 프롬프트 설계는 여전히 커뮤니티 차원의 집단적 시행착오 과정에 의존. CoT 프롬프트의 경우, 각 시험 사례마다 다른 프롬프트를 검색하려면 전체 학습셋에 대한 추론 사슬 주석이 필요하므로 few-shot의 장점이 사라짐.
우리의 핵심 기여는 복잡도를 효과적이면서도 견고한 선택 기준으로 제시한 것이며, 이는 주석 효율성을 유지하면서도 기존의 프롬프트 선택 기법을 다수의 경우에서 능가.
고전적 의미 구문 분석(Classical Semantic Parsing)과의 관계
사고 사슬 프롬프트의 절차는 개념적으로 고전적 의미 구문 분석(semantic parsing)과 유사. 의미 구문 분석에서는 논리적 형태(logical form)를 생성하고, 이를 지식 베이스 위에서 실행하여 최종 답변 도출.
우리의 관점에서 사고 사슬은 언어 모델이 스스로 실행하는 유연한 언어 기반 논리 형태(language-model-styled logical form)로 볼 수 있음.
3 복잡도 기반 프롬프트(COMPLEXITY-BASED PROMPTING)
CoT 프롬프트 체계를 따르고, 모든 프롬프트 방식들을 GPT-3(text-davinci-002)와 Codex(code-davinci-002)를 사용해 비교. 입력은 소수(보통 8개)의 CoT 사례 묶음 -> 시험 질문이 이어짐 -> 시험 질문에 대한 출력 사고 사슬을 계속 생성
3.1 복잡한 샘플을 프롬프트로 선택하기
가정: 언어 모델의 추론 성능이, 직관적으로 더 단순한 사례들을 포함하고 있는(Richardson & Sabharwal, 2022) 복잡한 사례들을 in-context 학습 예시로 쓸 때 향상될 것.
복잡도: 단계 수. 질문 길이, 기저 수식의 길이도 검증.
단계 수의 교란변수(confounder): 프롬프트 성능이 좋아졌을 때 이유가 예시 하나하나가 복잡해서 그런 것인지, 아니면 그냥 프롬프트에 들어간 전체 추론 단계 총합이 늘어나서 그런 것인지, 혹은 프롬프트 길이 자체가 길어져서 그런 것인지 구분해야 함. -> 예시 하나당 단계 수가 프롬프트 길이나 전체 단계 수 같은 교란 요인보다 성능 향상에 더 크게 기여하는 핵심 원인임.
3.2 복잡도 기반 일관성(Complexity-based Consistency)
Self-consistency 방식 따름. 하나의 시험 문제에 대해 모델이 N개의 추론 사슬을 샘플링 -> 다수결을 최종 예측으로(기존), 우리는 상위 K개(K ≤ N)의 더 복잡한(단계가 더 많은) 추론 사슬만을 투표에 넣음.
4 실험(Experiments)
4.1 실험 설정(Experimental Settings)
데이터셋: 세 개의 수학 서술형 문제 데이터셋(GSM8K, MultiArith, MathQA)과 세 개의 비수학 추론 데이터셋(StrategyQA, Date Understanding, Penguins).
각 데이터셋마다 학습 데이터에서 200개를 무작위로 뽑아 검증셋 만듦.
비수학 데이터셋 쪽에서는 StrategyQA가 800개 시험 인스턴스를 가진 다단계 상식 추론 과제, Date Understanding은 250개 시험 인스턴스를 가진 시간/날짜 추론 과제.
Penguins는 146개 시험 인스턴스를 가진 참조 게임(referential game) -> “펭귄 A가 펭귄 B와 C보다 나이가 많나요?”처럼 여러 객체를 가리키는 질문에 답하는 과제
언어 모델:
파인튜닝: GSM8K에 대해서는 검증기(verifier)를 붙인 GPT-3 파인튜닝, MultiArith에 대해서는 관련성 및 LCA 연산 분류기, MathQA에 대해서는 커스텀 seq2seq 모델이라는 기존 SOTA 성능 인용.
프롬프트: 137B LaMDA, 540B PaLM, 540B Minerva, GPT-3 175B, Codex 175B, DiVeRSe(이전 GSM8K SOTA)
프롬프트와 하이퍼파라미터: MultiArith는 추론 사슬이 없어, (1) 분포 내 주석(in-distribution annotation): 질문 길이를 복잡도의 대체 지표로 삼아 긴 질문을 먼저 고른 뒤, 그 질문들에만 추론 사슬을 수작업으로 달고, (2) GSM8K 프롬프트 전이(prompt transfer): GSM8K 학습 데이터에서 고른 프롬프트를 MultiArith에 그대로 옮겨 씀.
수학 데이터셋의 프롬프트는 모두 8개의 사례(문제 + 사고 사슬 + 답)로 구성.
비수학 데이터셋은 원래 추론 사슬 주석이 없으므로, 여기서도 다시 질문 길이를 복잡도 지표로 삼아 긴 질문만 골라 추론 사슬을 닮.
“Let’s think step by step”.
4.2 MAIN RESULTS
Overall Test Performance on Math Datasets
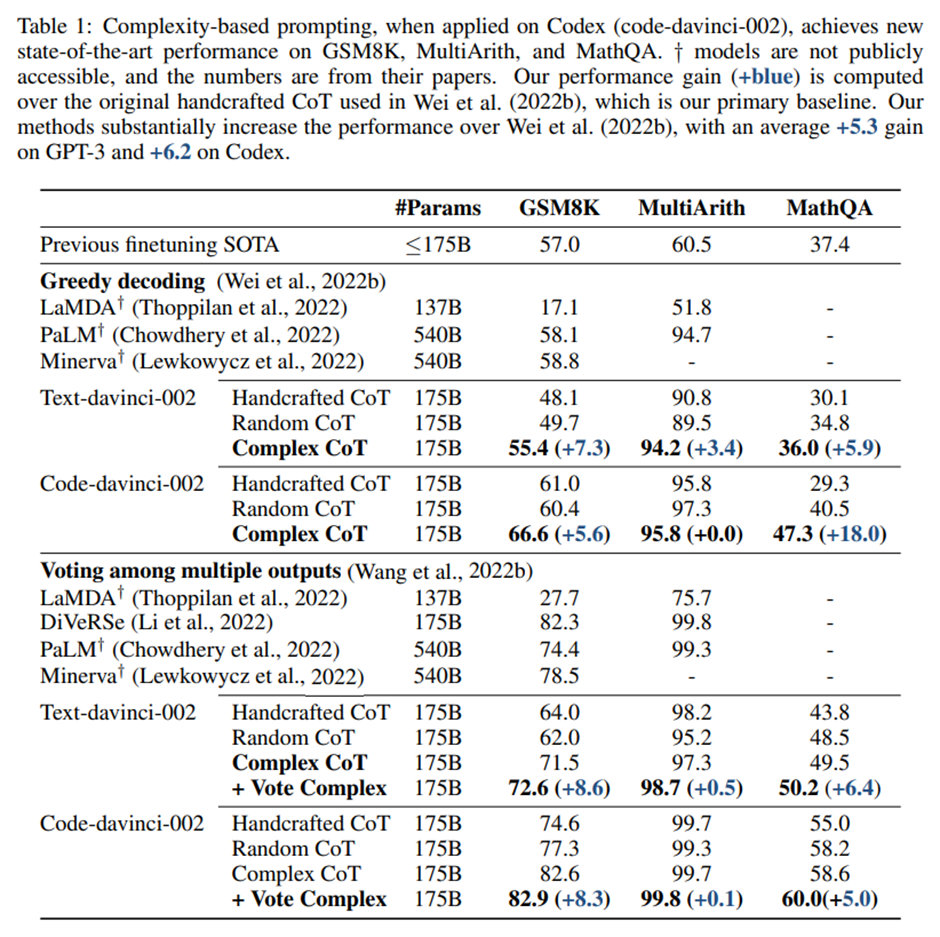
우리 방법 최고. + 복잡한 추론 사슬들에 대해서만 투표하는 방식이, 모든 사슬을 포함해 투표하는 방식보다 더 좋은 성능을 보임(표 1의 마지막 두 줄 참고).
다양한 추론 과제에서의 일관된 성능 향상
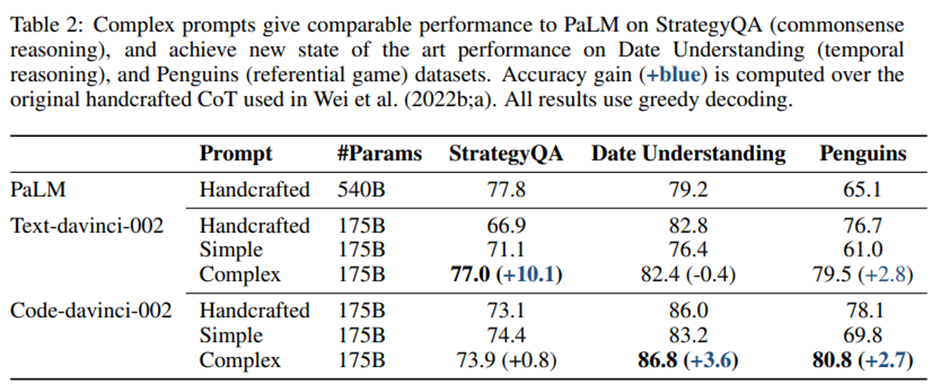
프롬프트의 이점이 서로 다른 유형의 추론 과제에서도 유지됨. 복잡한 예시를 프롬프트로 사용할 때, GPT-3와 Codex는 Date Understanding 및 Penguins 데이터셋에서 새로운 SOTA 성능.
성능 향상의 원인 분석(Performance Improvements Breakdown)

성능 향상에 기여할 수 있는 모든 엔지니어링 요소 명시. “Let’s think step by step” 문구 추가는 정확도를 높이지만, 우리의 실험 결과 정확도 향상의 주된 원인은 복잡도 기반 프롬프트임.
서로 다른 프롬프트 분포에서의 일관된 성능 향상
복잡도 기반 프롬프트 방식이 다음 세 가지 상황에서 어떻게 작동하는가?
(1) 깨끗한 분포 내(clean in-distribution) 학습 데이터(GSM8K)에서 프롬프트를 가져온 경우,
(2) 노이즈가 있는 주석 데이터(noisy annotation) (MathQA)에서 가져온 경우,
(3) 다른 데이터셋으로부터 전이된 프롬프트(transferred prompts)를 사용하는 경우(MultiArith).
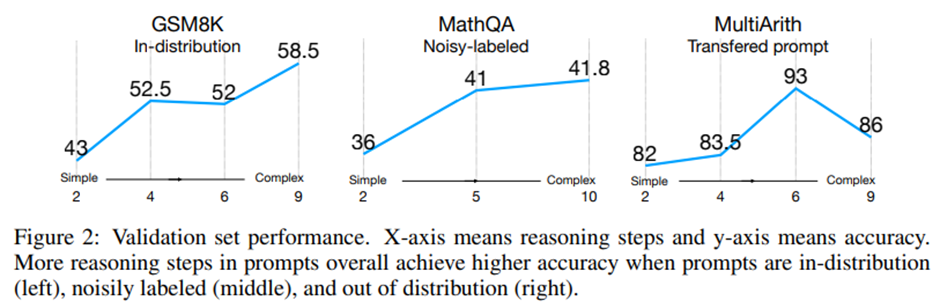
전반적으로 프롬프트가 복잡할수록 성능이 향상된다는 점을 보여주며, 이 경향은 세 가지 설정 모두에서 일관되게 나타남, MultiArith는 예외.
다른 예시 선택 기법들과의 비교(Comparison to other Example Selection Schemes)
추론 복잡도(reasoning complexity)를 새로운 예시 선택 기준으로 제시하기 때문에 기존의 예시 선택 방식들과 성능 비교.
(1) 무작위 선택(random selection): 학습 데이터에서 예시를 무작위로 선택.
(2) 중심점 선택(Centroid): 사전 학습된 문장 인코더(Reimers & Gurevych, 2019)가 생성한 질문 임베딩들 중, 다른 질문들과의 임베딩 거리가 가장 작은(즉, 데이터셋 중심에 위치한) 질문들을 선택. -> 이러한 중심점 예시들은 데이터셋의 전형적이고 대표적인 사례일 가능성이 높다는 직관에 기반.
(3) 검색 기반 선택(Retrieval): 시험 질문의 임베딩과 유클리드 거리(Euclidean distance)가 가장 가까운 학습 질문들을 검색하여 프롬프트로 사용
검색 방식은 시험 질문마다 서로 다른 프롬프트를 사용지만 다른 방법들은 모든 시험 질문에 동일한 고정 프롬프트 사용. -> 검색 방식은 시험셋 크기에 비례하여 주석 비용이 커지고, 보통 전체 학습셋 수준의 주석(10,000개 이상)이 필요. 다른 방식들은 few-shot 주석, 즉 본 연구에서는 8개의 예시만 주석하면 충분.
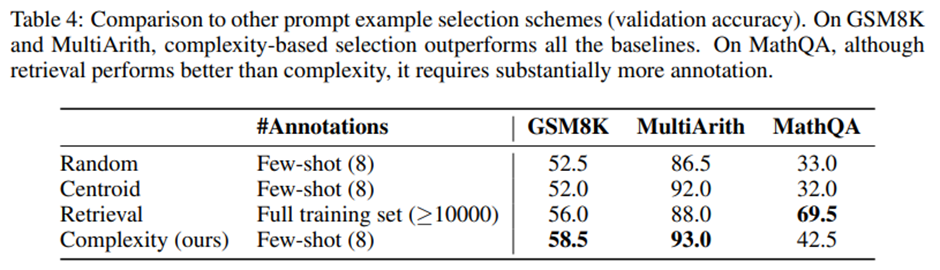
복잡도 기반 선택(complexity-based selection)은 GSM8K와 MultiArith에서 모든 다른 방법보다 우수한 성능.
일반화의 방향(Direction of Generalization)
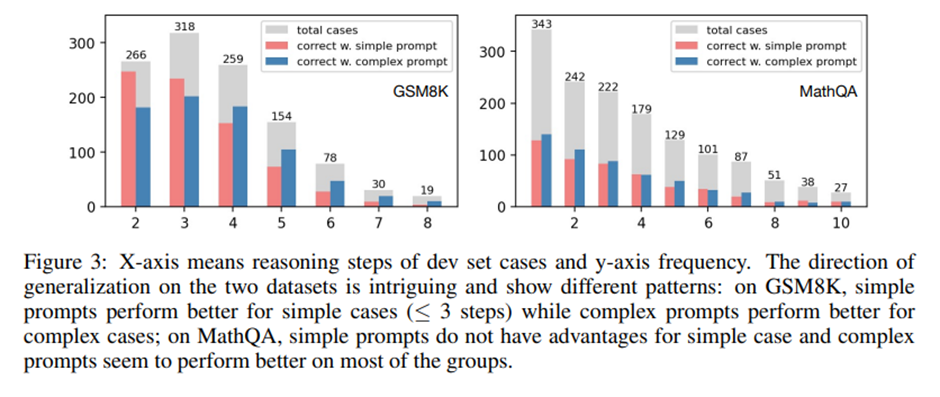
골드 주석(gold annotation)에서의 추론 단계 수에 따라 단순 프롬프트와 복잡 프롬프트의 검증 세트 정확도 비교. 복잡한 프롬프트는 어려운 문제(복잡한 케이스)에서는 단순 프롬프트와 비슷한 수준의 성능을 내지만, 적은 단계 수를 가진 단순한 문제들에서는 더 큰 성능 향상. -> 복잡도 기반 프롬프트가 오히려 단순한 시험 문제로의 일반화 능력을 향상시킴.
소형 모델에서의 성능(Small Model Performance)
작은 모델(small model)에서도 복잡한 프롬프트가 성능 향상을 이끌까? No!
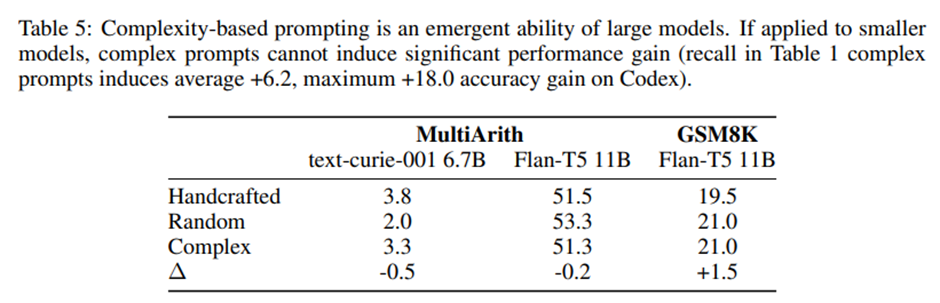
복잡도 기반 프롬프트 또한 충분히 큰 모델 규모에서만 나타나는 창발적 능력(emergent ability)임.
4.3 분석(Analysis)
심층 분석. 모든 실험은 검증 세트에서 수행.
복잡도의 대체 지표(Alternative Proxies for Complexity)
복잡도 기반 프롬프트는 추론 사슬 주석이 없는 데이터셋에서도 동일하게 적용될 수 있음.
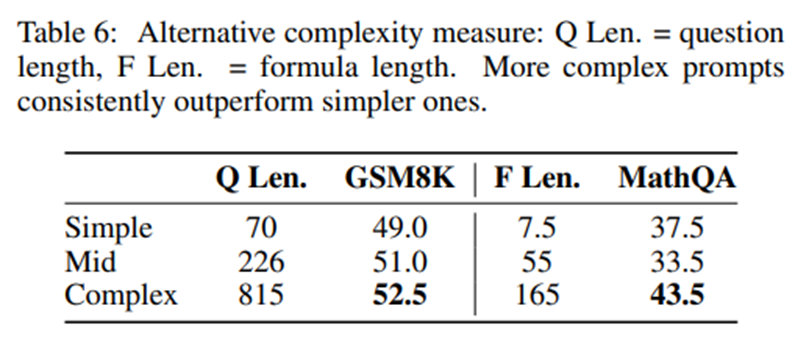
복잡도의 척도를 추론 단계 수 대신 질문 길이나 수식 길이로 정의하더라도, 최적의 성능은 복잡한 프롬프트에서 달성. -> 복잡한 프롬프트의 효과가 복잡도의 정의 방식에 관계없이 일관적으로 유지됨
단계 형식에 대한 민감도 분석(Sensitivity Analysis on Step Format)
CoT 방식의 프롬프트에서는 단계 구분 방식(step splitter)이 중요한 교란 요인이 될 수 있다는 지적.
기존의 줄바꿈 문자 “\n” 대신 두 가지 다른 구분 방식을 추가로 실험. (1) 명시적 단계 구분자(explicit phrase): “step i” 형태, (2) 구두점 기반 구분자(punctuation-based splitter): 마침표 “.”와 세미콜론 “;”을 사용.
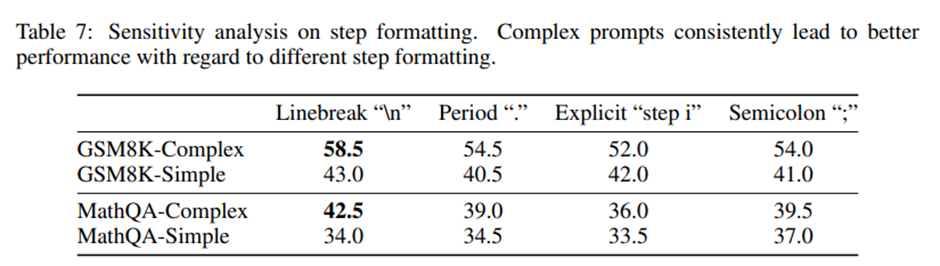
형식 변형이 성능에 어느 정도 영향을 미치기는 하지만, 복잡한 프롬프트는 어떤 단계 형식을 사용하더라도 일관적으로 더 좋은 성능.
출력 단계 분포(Output Step Distribution)
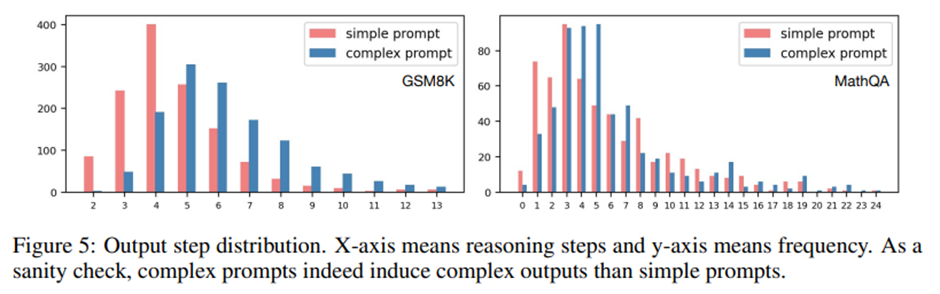
Codex 모델이 GSM8K와 MathQA에서 생성한 출력 결과를 비교. 복잡한 프롬프트가 단순한 프롬프트보다 실제로 더 복잡한 추론 사슬을 유도함.
-> 복잡한 프롬프트가 모델이 더 단순한 추론 경로(easy reasoning path)를 택하지 않도록 억제해서 지름길(shortcut)을 방지하고 더 체계적인 추론을 유도함.
교란 요인 분석(Confounder Analysis)
모든 실험에서는 프롬프트마다 사례 수를 8개로 고정했지만 더 많은 추론 단계를 가진 복잡한 예시들을 선택하면 다음과 같은 요인들이 서로 상관되어 나타남.
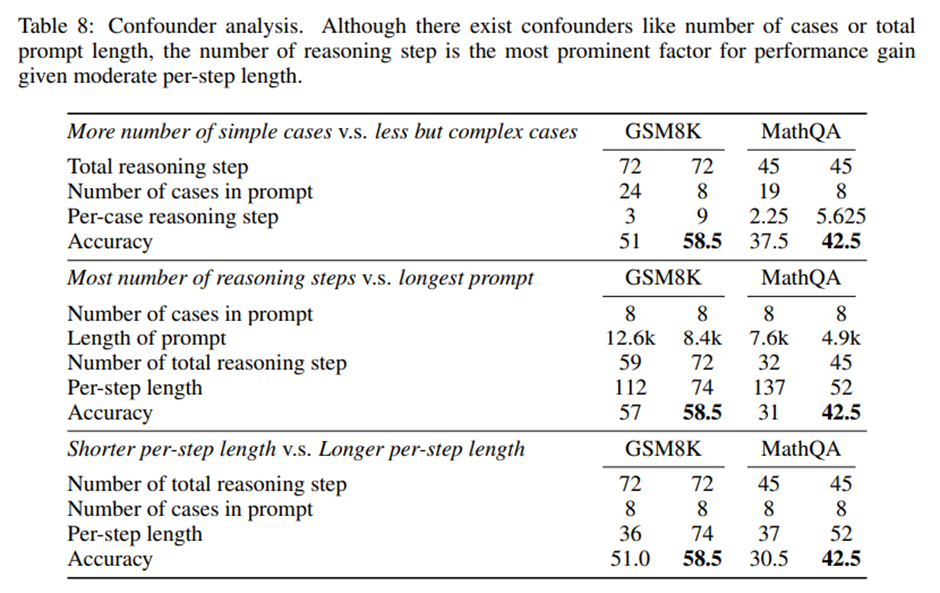
(1) 사례당 단계 수(per-case reasoning steps)가 증가하면 전체 프롬프트의 총 단계 수도 함께 증가. 예) GSM8K에서 9단계짜리 사례 8개를 선택하면 총 단계 수는 8 × 9 = 72단계. 단순하지만 더 많은 사례(예: 3단계짜리 24개 사례)를 선택하면 동일하게 72단계를 만들 수 있음.
(2) 사례당 단계 수가 증가하면 프롬프트의 전체 길이(문자 수 기준)도 길어짐. 더 많은 문자를 포함하지만 단계 수가 적은 예시들을 선택하여 보정할 수 있음.
정확도 결과를 종합하면: (1) 총 추론 단계 수를 동일하게 유지하더라도, 단순한 사례를 많이 넣는 것은 복잡한 사례를 적게 넣는 것보다 성능이 떨어짐. (2) 프롬프트의 길이가 가장 긴 경우도 복잡한 프롬프트보다 나은 성능을 내지 못함. (3) 다만, 각 단계의 길이(per-step length)가 너무 짧지 않은 적정 수준의 길이를 유지할 필요 있음.
-> 여러 교란 요인(confounder)들이 존재하더라도, 적절한 단계 길이 조건하에서는 ‘예시당 추론 단계 수’가 성능 향상의 가장 중요한 요인.
복잡한 사슬들에 대한 투표가 전체 사슬에 대한 투표보다 우수함(Voting among Complex Chains Outperforms Voting among All)
복잡도 기반 일관성(complexity-based consistency)의 성질 분석. 복잡도 기반 일관성은 먼저 모델로부터 N개의 추론 사슬(reasoning chains) 샘플링 -> 상위 K개의 복잡한 사슬들에 대해 다수결로 최종 답 선택 -> N은 50으로 설정하고, K는 10, 20, 30, 40, 50으로 조정(K=50이면 기존 self-consistency)
<-> 상위 K개의 단순한 샘플(simple samples) 대상으로 투표.
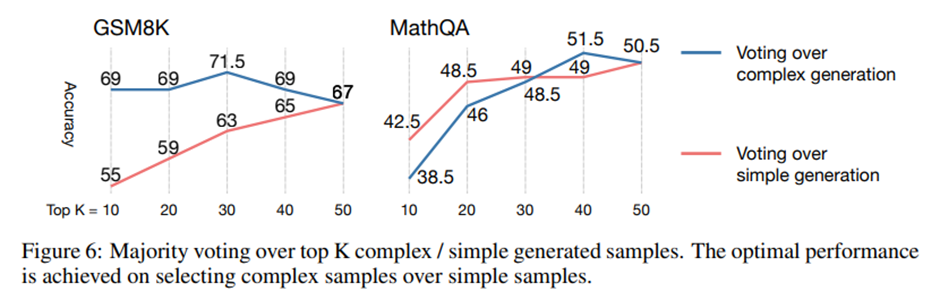
(1) 단순한 샘플들에 대해 투표할 경우, 항상 전체 샘플을 투표에 포함시킨 경우보다 성능 낮음. 단순한 샘플 기반의 선택이 올바른 방향이 아님.
(2) 두 데이터셋 모두에서, K < N인 특정 구간에서 복잡한 사슬에 대한 투표가 최적의 성능.
5 결론(Conclusion)
다단계 추론을 수행하도록 프롬프트 할 때 복잡도 기반 인스턴스 선택 제안.
수학적 서술형 문제에서의 성능 크게 향상, 직관적, 주석 비용 적음, 다양한 in-context learning 설정에서도 안정적으로 효과적.
