Predicting Results of Social Science Experiments Using Large Language Models Luke Hewitt1 Ashwini Ashokkumar2 Isaias Ghezae1 Robb Willer1 1Stanford University 2New York University *Equal contribution, order randomized August 8, 2024
서론(Introduction)
LLM이 사회 및 행동과학을 어떤 방식으로 얼마나 지원할 수 있을까?
LLM은 연구 아이디어 식별, 이론 및 가설 구축 촉진, 필요한 표본 크기 산출, 재현이 필요한 연구 선별에 도움을 줄 수 있음.
LLM이 대표 표본 설문 실험(실험 처치(treatment)가 주어지고 종속변수가 더 큰 모집단의 무작위 확률 표본에서 실시된 설문을 통해 측정되는 연구)에서 인간의 반응을 정확하게 시뮬레이션할 수 있는지 탐구. -> 실험 효과 자체를 예측하는 데 초점.
LLM이 생성한 추정 처치 효과 크기가 모델의 학습 데이터에서 덜 대표된 집단에 대해서 정확도가 낮은지, 심리학, 정치학 등 다양한 분야와 설문 실험과 현장 실험 등 서로 다른 연구 환경에서 수행된 실험들을 대상으로 여러 정확도 지표를 사용해 평가, 공개된 LLM이 대중을 설득력 있게 오도할 수 있는 콘텐츠를 식별하는 등 유해한 개입을 설계하는 데 사용될 수 있는지 검증.
연구 개요(Study Overview)
미국국립과학재단(NSF)의 지원을 받아 수행된 TESS 프로젝트를 통해 수행된 50개의 설문 실험을 포함하는 대규모 다학제적 테스트 아카이브 구축. -> 실험 품질 높음, 아카이브 주제적 범위와 다양성 넓음, 모든 실험의 처치 효과를 일관된 절차로 분석, 상당수가 GPT-4 학습 데이터가 마감될 당시까지 출판되거나 공개되지 않음.
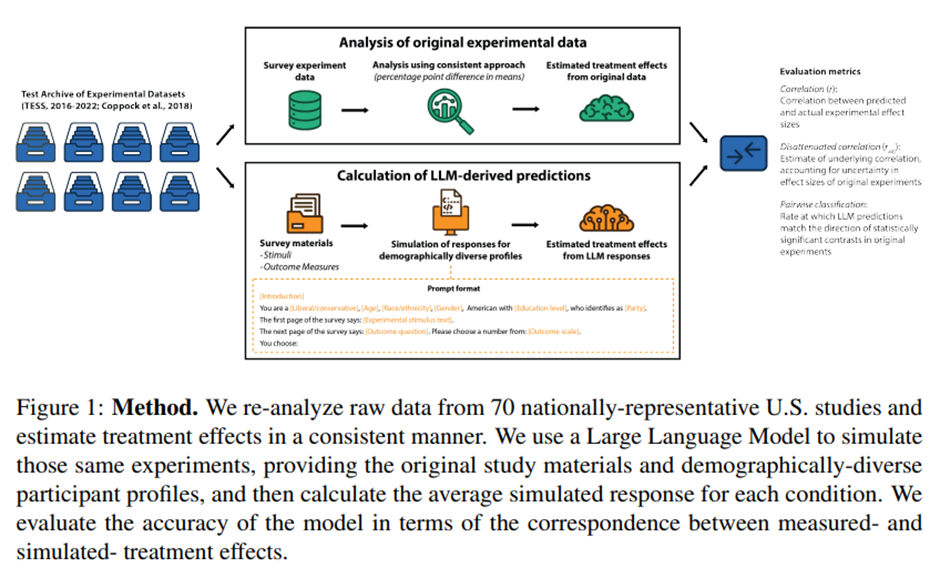
연구 설계. 모든 실험 조건의 자극문(text of stimuli), 결과변수(outcome variables), 응답 척도(response scales)를 포함한 원본 연구 자료 확보. 실험 자극에 대한 개별 참여자의 응답을 시뮬레이션하는 방식으로 LLM 활용.
프롬프트 구성: (a) “당신은 사람들이 다양한 메시지에 어떻게 반응하는지를 예측하게 될 것입니다”와 같이 연구의 맥락을 간략히 설명하는 도입문 제시, (b) 모사할 연구 참여자의 구체적 인구통계학적 프로필(성별, 연령, 인종, 교육 수준, 이념 성향, 정당 성향 등)을 전국 대표 표본에서 무작위로 추출하여 제시, (c) 실험 자극의 텍스트, (d) 결과변수를 측정하기 위해 사용된 질문 문항의 텍스트 및 응답 척도와 레이블을 함께 제공. 실험 자극에 노출된 후 해당 참여자가 결과 질문에 어떻게 응답할지를 LLM이 추정하도록 요청.
단일 프롬프트 형식에 따른 우연적 반응 줄이기 위해 앙상블 방식 사용.
예측 정확도 평가: (a) 각 연구에서 무작위로 하나의 통제 조건(control condition)을 선택(원래 연구에 여러 종속변수가 포함된 경우에는 하나만 선택), (b) 예측된 처치 효과를 계산, (c) 그 예측 효과를 원본 데이터셋으로부터 추정된 실제 효과와 상관시키기, (d) 이 과정을 16회 반복하여 그 중앙값 상관계수 r을 기록. 이 r 값이 주요 정확도 지표로 사용됨. 원래의 처치 효과 추정치가 가지는 통계적 불확실성을 보정하기 위해 보정 상관(disattenuated correlation, r_adj)도 계산하여, 원시 상관 (r)과 함께 보고.
결과(Results)
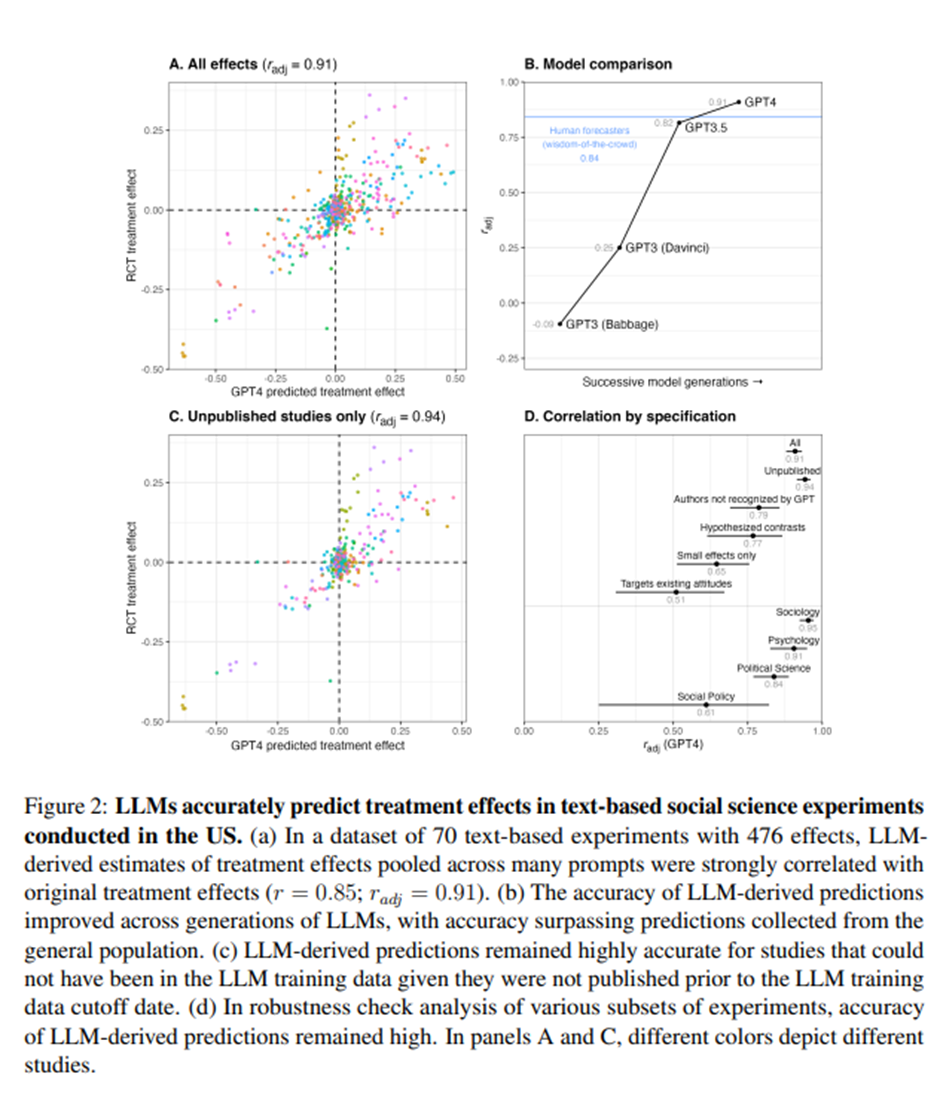
GPT-4 로부터 도출된 예측 처치 효과와 실제로 추정된 처치 효과 간의 상관관계 분석 -> GPT-4 기반 예측치는 실제 효과 크기와 강하게 상관(r = 0.85; r_adj = 0.91), 유의미한 차이 보인 쌍을 살피면 90% 올바른 예측(그림 2D)
학습 데이터 효과 보기 위해 학습 데이터 컷오프 이전과 이후 예측 정확도 비교 -> 미공개: r = 0.90; r_adj = 0.94; 유의 contrast 중 88% 정확 방향 예측 / 공개 연구: r = 0.74; r_adj = 0.82; 87% 정확 방향 예측(그림 2D)
추가: GPT-4 에게 각 실험 제목을 제시하고 10명의 가능한 저자 목록 중 실제 저자를 추측하도록 함. -> 저자를 맞히지 못한 연구가 56%에 달했지만 LLM 예측치와 실제 효과 간에는 여전히 높은 상관이 관찰되었다(r = 0.69; r_adj = 0.79; 그림 2D 참조).
-> 현재 세대의 LLM은 미국에서 수행된 설문 기반 실험의 효과 크기와 방향을 정확히 예측할 수 있음, 정확도는 모델 세대가 발전함에 따라 지속적으로 향상됨, 높은 정확도가 단순히 학습 데이터 복기에 의해 설명되는 것은 아님
예측 정확도 기준점: 미국 성인 일반인 2,659명으로 구성된 대규모 표본 -> r = 0.79; r_adj = 0.84, GPT-4는 인간 기준점 능가(그림 2A, 2B)
인간과 LLM 예측의 유사한 정확도가 생기는 이유: (a) LLM 예측이 인간 예측과 동일한 정보를 반영하기 때문, 혹은 (b) LLM 예측이 인간 예측과 중복되지 않는 독립적인 정보를 제공하기 때문 -> 회귀 분석 결과, GPT-4 기반 예측(b = 0.35 [0.29, 0.42])과 인간 예측(b = 0.32 [0.25, 0.40]) 모두 실제 처치 효과와 각각 독립적으로 유의미한 양의 관련성.
-> 인간과 LLM 예측이 서로 다른 정보원을 제공하며, 결합할 경우 더 높은 예측력을 달성할 수 있음
GPT-4 기반의 원시(raw) 예측이 실제 효과를 체계적으로 과대추정(overestimate)하는 경향 있음. -> 예측된 효과와 실제 효과 간의 RMSE(평균제곱근오차)는 10.9퍼센트포인트(pp)로 추정, 인간 예측자의 RMSE(8.4pp)보다 큼. 선형적 재조정(linear rescaling)을 적용하면 RMSE는 5.3pp로 감소.
LLM 기반 실험 효과 예측의 범위 평가(Assessing the scope of LLM-derived predictions of experimental effects)
포괄적인 실험 아카이브를 활용하여 LLM의 성능을 다양한 지표 및 잠재적 응용 분야 전반에 걸쳐 평가.
LLM 예측의 편향 평가(Assessing biases in LLM-derived predictions)
미국 내 여러 하위집단(subgroup)에 걸쳐 LLM의 성능 평가. (a) 특정 하위집단을 대표하는 인구통계 프로필을 기반으로 한 LLM 예측치, (b) 테스트 아카이브의 실험에서 해당 하위집단에 대해 실제로 추정된 처치 효과 비교.
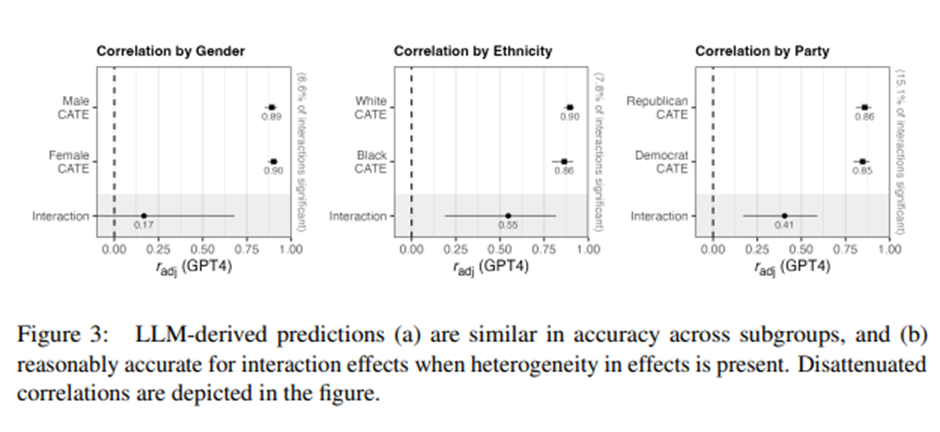
여성(r = 0.80, r_adj = 0.90)과 남성(r = 0.72, r_adj = 0.89), 흑인(r = 0.62, r_adj = 0.86)과 백인(r = 0.85, r_adj = 0.90), 민주당원(r = 0.69, r_adj = 0.85)과 공화당원(r = 0.74, r_adj = 0.86) 등 모든 집단에서 대체로 높고 유사한 정확도.
하위 집단 간 예측 정확도 차이 거의 없음 -> 미국 내 실험 효과가 대체로 집단 간 동질적(homogeneous).
상호작용 효과는 중간 정도의 상관. r_adj 약 0.17-0.41.
설문 및 현장 개입 연구에 대한 예측 평가(Assessing predictions for survey and field intervention studies)
메가스터디 수집 및 분석.
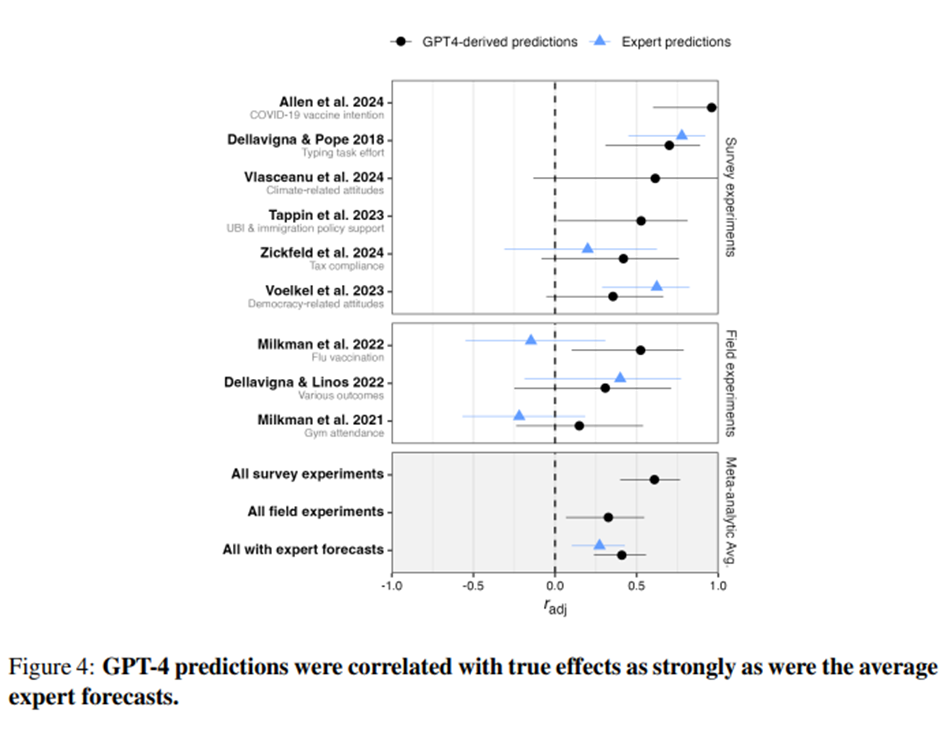
LLM이 주어진 메가스터디 내에서 개입(intervention)의 효과성을 구별할 수 있는 능력 평가: 각 연구에서의 실제 처치 효과(해당 연구의 통제 조건 대비)와 LLM이 예측한 처치 효과 간의 상관관계 추정 -> 메가스터디 전체에 대한 메타분석적 평균 상관계수 계산
-> LLM 기반 예측은 설문 실험에서 더 높은 정확도(r = 0.47; r_adj = 0.61; 통계적으로 유의한 contrast 중 79%에서 방향 일치; 그림 4 참조). 현장 실험은 정확도 낮고, 텍스트 기반 처치를 다룬 실험이 비텍스트 기반보다 정확.
전문가 예측이 존재하는 여섯 개의 설문 및 현장 실험 메가스터디를 대상으로 한 분석: LLM 기반 예측은 실제 효과와 양의 상관(r = 0.37; r_adj = 0.41), 원래 유의미한 contrast만 보면 69% 올바른 예측. LLM은 전문가와 동일하거나 더 우수.
유해한 사용의 위험 평가(Assessing risks of harmful use)
현존하는 공개형 LLM이 이러한 안전장치를 가진 상태에서도 해로운 메시지 중에서 선택할 수 있는지.
백신 관련 페이스북 게시물이 코로나19 백신 접종 의도를 감소시키는 영향을 측정한 최근의 실험 데이터 분석 -> GPT-4가 예측한 게시물의 백신 의도에 대한 영향은 실제 효과 추정치와 유의한 상관(r = 0.49; r_adj = 0.96), 백신 의도를 가장 부정적으로 변화시킬 것으로 식별한 다섯 개 게시물은 원래 연구에서 실제로 백신 접종 의도를 평균 2.77퍼센트포인트 감소시키는 것으로 추정.
-> LLM이 사회적 피해를 초래할 수 있는 콘텐츠의 효율성을 식별하는 데 악용될 잠재력이 있음.
공개형 LLM을 호스팅하는 기업들이 사회적으로 해로운 처치를 포함한 인간 실험을 시뮬레이션하는 데 이 모델이 사용되는 것을 제한하는 “2차(second-order) 안전장치(guardrails)”를 구현함으로써 오용 가능성을 상당히 줄일 수 있음.
논의(Discussion)
최신 세대의 LLM이 실험 효과의 크기와 방향을 정확히 예측할 수 있음. -> LLM의 미세조정(fine-tuning)이나 프롬프트 최적화 같은 특별한 절차를 사용하지 않았기 때문에, 본 결과는 현재 기술 수준에서 가능한 성능의 하한선을 보여줌.
LLM 기반 접근은 사회, 행동과학자들이 현재 사용하고 있는 주요 도구들에 필적할 정도로, 기초이론 구축과 실제 개입 설계 모두에 유용한 통찰을 제공할 수 있음. -> pilot study., 베이지안 사전분포나 검정력 분석에 사용할 효과 크기 예측 생성, 과거 연구 신뢰성 평가, 재현이 필요한 연구 식별, 비용 절감.
한계:
하위집단 간의 평균적 정확도는 유사하게 나타났지만, 예측 과정에서 편향이 존재하지 않는다고 단정할 수 없음.
향후 연구가 LLM을 현장 실험이나 복잡한 설계에서의 결과 예측에 어떻게 활용할 수 있을지를 규명해야 함.
본 연구는 효과 크기를 표준화된 척도(Cohen’s d 등)가 아닌 각 연구의 원래 척도에서 추정하였기 때문에, 검정력 분석(power analysis)과 같은 실제 적용에서는 제한이 있을 수 있음.
재현성(replicability)의 엄격한 기준을 충족하지 못할 가능성.
부록(Supplement)
추가 자료는 https://treatmenteffect.app/supplement.pdf 에서 확인.
