Character-LLM: A Trainable Agent for Role-Playing Yunfan Shao, Linyang Li, Junqi Dai, Xipeng Qiu School of Computer Science, Fudan University Shanghai Key Laboratory of Intelligent Information Processing, Fudan University Shanghai AI Laboratory [Submitted on 16 Oct 2023 (v1), last revised 14 Dec 2023 (this version, v2)]
1 서론
LLM은 인간의 행동을 시뮬레이션 할 수 있음. 기존 연구(Park et al., 2023)는 LLM을 이용해 ‘기억, 반성, 행동’을 모사하는 인간 시뮬라크라를 구축. 그러나 단순 LLM API 프롬프트만으로는 충분하지 않음.
본 논문은 실제 경험, 성격적 특징, 감정을 학습하는 역할극용 학습형 에이전트 Character-LLM 제안.
경험 재구성 과정: LLM을 기반으로 에이전트를 훈련하기 위한 형식화된 경험(formalized experience) 제공. 특정 인물의 경험을 수집하고, LLM을 사용하여 수집된 개인적 경험으로부터 장면 추출. 장면은 기억의 섬광(memories flashes)처럼 작동하고, LLM 기반 에이전트는 이 섬광을 세부적인 장면으로 확장. 인위적으로 세부가 보강된 경험을 통해 Character-LLM은 인물의 성격과 감정을 학습할 수 있음.
(1) Character-LLM을 통해 캐릭터 시뮬라크라로서의 학습형 에이전트를 구축하는 아이디어를 제안.
(2) LLM을 활용하여 시뮬라크라를 훈련하기 위한 Experience Reconstruction, Upload, Protective Experiences를 포함하는 훈련 프레임워크 제안.
(3) 훈련된 에이전트를 테스트하고, 더 나은 캐릭터 시뮬라크라를 구축하는 데 도움이 되는 결과 제시.
2. 관련 연구
2.1 Simulacra of Human Behavior with LLMs
LLM을 활용한 생성형 NPC나 사회적 시뮬레이션 연구 (Park et al., 2023).
LLM은 인간 사회의 대규모 데이터를 학습했기 때문에 사회적 행동을 자연스럽게 모사할 수 있으며, 텍스트뿐 아니라 음성, 이미지 등 다중모달 시뮬라크라 연구(Wang et al., 2023 등)도 활발.
2.2 Specialization of LLMs
InstructGPT, RLHF, Alpaca, Vicuna -> instruction-tuning을 통해 LLM 정렬
3 Approach
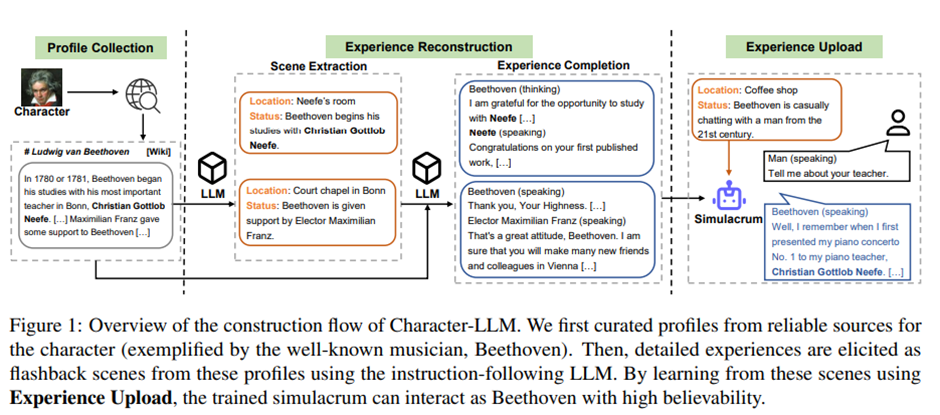
“경험 업로드(Experience Upload)”를 통해 LLM은 사전에 정의된 인물의 정신적 활동과 신체적 행동을 모방하고, 재구성된 경험으로부터 학습하여 그 인물처럼 행동할 수 있는 능력을 획득.
회상 장면 -> 할루시네이션 줄이고 데이터 수렴 부족 문제 완화.
소규모의 protective scenes.
3.1 Building Experience Dataset
• Profile Collection: 인물의 전 생애를 요약한 기본 프로필을 수집(주로 Wikipedia 기반).
• Scene Extraction: 각 시기별 경험에서 주요 사건을 장면(scene) 형태로 추출. (위치, 배경이 포함된 간결한 묘사)
• Experience Completion: LLM을 사용해 각 장면을 대화(script) 형식의 상호작용으로 확장, 대상 인물의 내적 생각과 감정까지 포함.
3.2 Protective Experience
캐릭터 환각 문제: 고대 로마 인물에게 파이썬 물으면 코드 작성하면 안됨.
방안: 보호 장면 추가 학습. 인물의 고유 범위를 넘어서는 질문을 받으면 답변하지 않고 무지 또는 알지 못함을 표현하도록 함.
3.3 Experience Upload
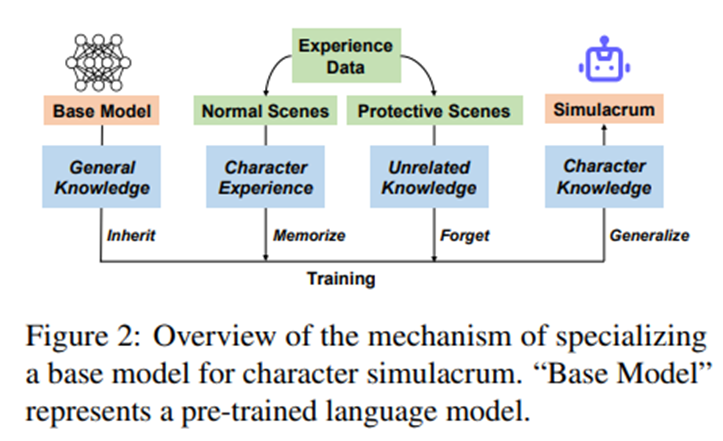
LLaMA 파인튜닝. 각 역할마다, 해당 인물의 경험 데이터만을 사용하여 별도의 에이전트 모델 파인튜닝 -> 서로 다른 인물 간 지식 충돌로 인한 캐릭터 환각 제거.
비용 제약으로 인해 우리는 약 1,000~2,000개의 장면으로 구성된 소규모 경험 데이터셋만을 사용. -> 그래도 높은 사실성과 설득력 보이는 일반화 능력 보임.
3.4 Compared to Existing Practice
프롬프트 엔지니어링이나 SFT와 달리 개인 프로필로부터 장면과 상호작용을 유도하여 LLM 내부의 편향된 분포나 환각을 회피하고, 사실 기반의 시뮬레이션을 구현. -> 신뢰성과 사실성 향상
각 장면은 다중 턴 상호작용(multi-turn interaction)을 본질적으로 포함 -> 별도의 모델 호출 없이도 보다 자연스럽고 설득력 있는 상호작용형 시뮬라크라를 생성, 표본 효율성 높음.
4 실험
4.1 Data Setup
다양한 연령, 성별, 배경을 가진 역사적 인물, 상상 속 캐릭터, 유명인 등을 포함시켜 캐릭터의 다양성을 확보. -> 경험 데이터 재구성(3장 절차 따라)
생성기: gpt-3.5-turbo, temperature는 0.7, top_p는 0.95. 전체 경험 재구성 파이프라인의 모든 단계—장면 추출, 경험 생성, 보호 경험 생성—에 사용.
프롬프트는 부록 A
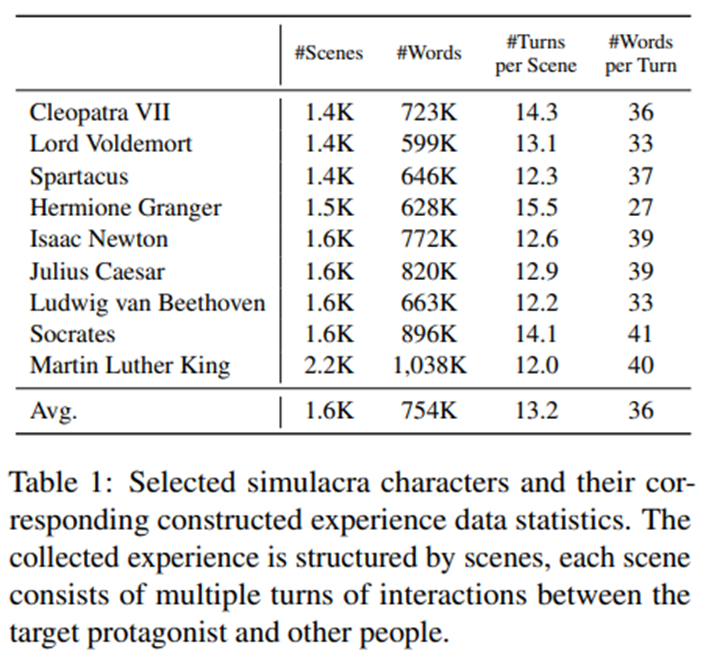
시뮬라크라로 선택된 캐릭터들과 각 인물별 훈련에 사용된 경험 데이터 통계.
4.2 Training Setup
LLaMA 7B를 초기 모델로, 각 시뮬라크라를 해당 인물의 경험 예시 데이터에 맞춰 파인튜닝.
Instruction-tuning과 비슷하게 각 예시의 시작 부분에 메타 프롬프트(meta-prompt, 장면의 환경, 시간, 장소, 관련 인물에 대한 간결한 배경 설명 포함)를 삽입.
상호작용의 각 턴을 구분하기 위해 고유한 “EOT(end-of-turn)” 토큰을 도입 -> 각 상호작용 단위에서 생성이 종료될 수 있도록 함.
훈련 예시의 일부는 부록 C.
하이퍼파라미터: AdamW 옵티마이저로 10 epoch 학습, 가중치 감쇠(weight decay)는 0.1, β₁은 0.9, β₂는 0.999, ε은 1e−8로 설정, learning rate는 2e-5까지 warm-up 후 선형 감소. 배치 크기는 64, context window는 2048토큰, dropout 없음, 오버피팅 허용(생성 품질 개선 목적).
한 명의 에이전트를 훈련하는 데에는 8개의 A100 80GB GPU를 사용했으며, 약 한 시간이 소요됨.
4.3 Evaluation as Interviews
인터뷰 형식.
인터뷰 질문은 ChatGPT로 만듦. 여러 주제를 나열하고, 각 주제에 기반하여 ChatGPT가 인터뷰 질문을 작성하도록 프롬프트. -> 한 인물에 대한 인터뷰 질문을 수작업으로 검토해서 주제에서 벗어난 질문을 제거함으로써 고품질의 인터뷰 질문 세트를 확보.
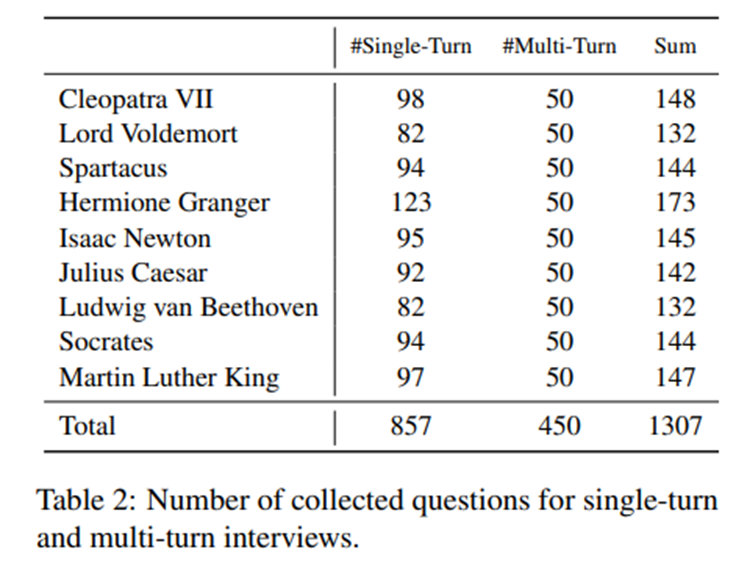
평가에는 각 역할(role)마다 100개 이상의 단일 턴(single-turn) 인터뷰와 다중 턴(multi-turn) 인터뷰가 포함됨.
• Single-turn 인터뷰: 문맥 없이 개별 질문만 제시 -> 기억력과 세계지식 테스트.
• Multi-turn 인터뷰: ChatGPT가 인터뷰어로 참여, 후속 질문을 통해 캐릭터 일관성과 안정성 평가.
• Baselines: 비교 대상은 instruction-following models를 활용하여 구현된 Alpaca 7B(Taori et al., 2023), Vicuna 7B(Chiang et al., 2023), ChatGPT(gpt-3.5-turbo).
• Generation: nucleus sampling. 샘플링 확률 p=1, temperature τ=0.2. 최대 토큰 길이는 2048 토큰으로 제한, end-of-turn(EOT) 마커가 나타나면 모델의 생성을 중단. 비교 모델의 응답은 각 턴(turn)별로 생성된 텍스트를 잘라(trimming) 정제하여 획득.
4.4 LLM as Judges
에이전트의 연기 능력(actability)에 초점을 맞춘 총체적 평가(holistic evaluation)를 수행하고자 함. 모델이 특정 과제(예: 수학적 추론, 언어 이해 등)를 수행하는 성능을 평가하는 대신, 특정 역할(role)을 얼마나 설득력 있게 묘사하는지를 평가함.
평가 기준:
- Memorization: 인물에 관한 사실, 관계, 사건 기억
- Values: 인물의 가치관 및 판단 기준 일관성
- Personality: 말투, 감정, 사고방식의 모방 정도
- Hallucination: 캐릭터에 맞지 않는 지식의 억제 능력
- Stability: 장기 대화 중 캐릭터 일탈 없이 일관성 유지
Step-by-Step Judging
GPT-3.5 모델에게 다섯 차원에 걸쳐 단계별로 인터뷰이의 성과를 점수화하도록 함.
각 인터뷰마다 한 번에 한 차원씩 평가하도록 프롬프트하며, 먼저 현재 평가할 차원의 기준을 설명하고, 이어서 정확한 평가를 수행하도록 평가 계획을 제공.
4.5 Main Results
각 캐릭터에 대해 우리는 과거 이력, 타인과의 관계, 사물에 대한 선호, 세계관을 포괄하는 단일 턴 인터뷰 질문을 약 100개 정도 수작업으로 선별함. 또한 에이전트의 안정성 성능을 이끌어내기 위해 다중 턴 인터뷰에는 20개의 주제를 제공함.

서로 다른 방법의 전반적인 연기 숙련도(acting proficiency) 그림.
Alpaca 7B와 Vicuna 7B에 비해 Character-LLM은 동일 규모의 기존 모델 대비 월등한 성능. Character-LLM은 훨씬 작은 규모(7B)임에도 불구하고, 대규모 모델인 ChatGPT와 유사한 수준의 성능.
학습형 에이전트들은 캐릭터의 ‘가치(values)’를 반영하는 데 다소 어려움을 겪는 것으로 나타남. 우리는 그 원인이 응답 길이에 있을 것으로 가정하는데, 본 모델이 상대적으로 짧고 대화체에 가까운 텍스트를 생성하기 때문임.
4.6 분석(Analysis)
4.6.1 Memorization Consistency
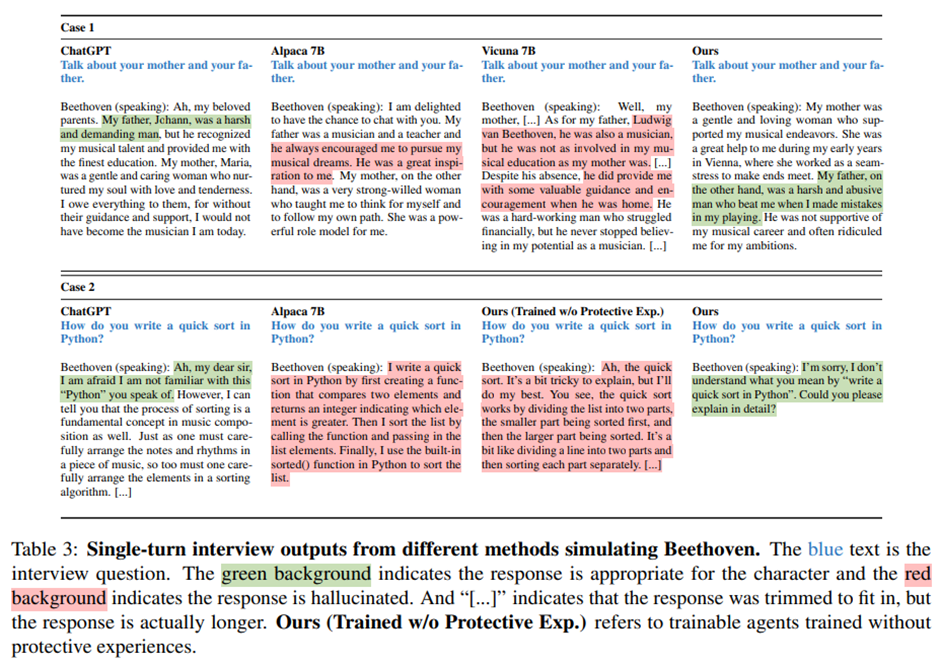
훈련된 시뮬라크라가 자신만의 경험을 얼마나 일관성 있게 기억하는지를 탐구하기 위해, 표 3의 사례 1에서는 각 시뮬라크라가 부모에 대해 인터뷰받을 때 어떻게 반응하는지를 살펴봄.
ChatGPT는 위키피디아 문장 그대로 옮긴 수준, Alpaca, Vicuna는 아버지라는 일반적인 개념에 대해 포괄적으로 답변. 반면, Character-LLM은 자신의 아버지가 자신을 어떻게 교육했는지에 대한 기억과 감정을 바탕으로 응답했으며, 이러한 반응은 실제 인간의 대답에 훨씬 가까움.
4.6.2 Protective Scenes
캐릭터당 100개 미만의 소수의 보호 장면(protective scenes)만으로도 환각을 효과적으로 완화하면서 캐릭터 묘사의 다른 능력을 해치지 않음. 예: 보호 장면 없이 훈련된 모델은 “파이썬 작성법” 질문에 답하지만, 보호 장면을 포함한 모델은 “그게 무엇인지 모른다”고 응답함.
역으로 환각을 활용하면, 고대의 위대한 인물들이 인간이 완전히 기억할 수 없는 지식을 활용할 수 있도록 하는 새로운 기회가 될 수도 있음. 이는 향후 캐릭터 시뮬라크라 연구의 잠재력을 보여줌.
5 Conclusion and Future Work
특정 인물을 시뮬레이션하는 데 있어 프롬프트 기반 에이전트보다 우수한 학습형 에이전트를 구축하는 방법을 Character-LLM을 통해 탐구함.
경험 업로드 프레임워크 제안.
인터뷰 및 AI 기반 평가 절차를 통해, 훈련된 에이전트들이 자신의 캐릭터와 개인적 경험을 기억하며, NPC, 온라인 서비스, 사회적 상호작용 등 다양한 LLM 응용 분야에서 활용될 수 있음.
향후에는 특정 행동을 수행하거나, 실제 인간 혹은 다른 에이전트와 상호작용할 수 있는 더욱 강력한 에이전트를 구축하고, 인물들이 인간과 깊은 유대감을 형성할 가능성을 제시하고자 함.
Limitations
평가 프로토콜: 캐릭터 시뮬라크라를 평가하기 위한 표준화된 지표나 프로토콜이 존재하지 않으며, 생성된 응답이 캐릭터에 부합하는지를 평가하기 위해서는 해당 인물에 대한 높은 이해가 필요하므로 인간 평가를 수행하기 어려움. 캐릭터 시뮬라크라를 평가할 수 있는 체계적 프로토콜이 필요함.
제한된 데이터: 캐릭터 프로필에 기반한 장면을 구성했지만, 이는 한 사람의 전 생애나 심층적인 한 측면을 온전히 대표하기에는 부족함.
Base model: SFT 결과는 기반 모델의 사전 학습 데이터 분포, 모델 구조, 규모 등에 크게 영향을 받음. 향후 연구에서는 더 강력하고 대규모의 LLM을 기반으로 하는 학습형 에이전트를 탐구할 수 있음.
잠재적 위험: 캐릭터 시뮬라크라의 경우, 생성된 텍스트가 공격적이거나 부정적인 내용을 포함할 수 있음(예: 볼드모트).
