PersonaGym: Evaluating Persona Agents and LLMs Vinay Samuel Henry Peng Zou Yue Zhou Shreyas Chaudhari Ashwin Kalyan Tanmay Rajpurohit Ameet Deshpande Karthik Narasimhan Vishvak Murahari University of Maryland, College Park, University of Illinois Chicago, University of Massachusetts Amherst, Independent Researcher, Georgia Tech, Princeton University [Submitted on 25 Jul 2024 (v1), last revised 5 Sep 2025 (this version, v5)]
1 서론

페르소나 에이전트는 다양한 맥락에서 개인화된 대화를 생성하는 잠재력을 보여주고, 수학적 추론, 물리학, 소프트웨어 개발과 같은 과제에서 향상된 성능을 보임. 심리학과 같은 학문 분야에서 인간 행동을 모의(simulate)하기 위한 과학적 연구에도 활용됨.
그러나 한계가 있음.
(1) 정적(static)이며 평가를 미리 정해진 페르소나에만 제한하기 때문에, 가능한 다양한 에이전트의 폭을 포괄하지 못하고 새로운 SOTA(최신 최고 성능) LLM에서의 데이터 오염(data contamination) 가능성에 대한 우려를 야기함.
(2) 페르소나 에이전트가 자신의 페르소나와 관련된 환경에서 초기화되지 않음. (예: ‘카우보이 에이전트’는 농장 관련 환경에서 테스트되어야 함에도 그렇지 않음.)
(3) 기존 벤치마크는 단일 차원적(uni-dimensional)이어서 개인화된 에이전트를 전체적으로 평가하지 못함(Wang et al., 2024b; Chen et al., 2023; Wang et al., 2024a; Shen et al., 2023; Light et al., 2023).
제안: PersonaGym(페르소나 에이전트를 위한 최초의 동적 평가 프레임워크), PersonaScore(인간의 판단과 일치하도록 설계된 최초의 자동화 지표)
2 평가 과제
에이전트의 행동이 의사결정 과정(decision-making process)에서 비롯된다는 점을 고려하여, 평가 프레임워크를 의사결정 이론(decision theory)—즉, 불확실성 하에서의 합리화와 행동 선택을 체계적으로 분석하는 학문(Edwards, 1961; Slovic et al., 1977)—에 기반하여 설계함.
-
기대 행동 과제(Expected Action task) – 규범적 평가: 페르소나 에이전트는 특정 상황에 직면하며, 그 상황에서 어떤 행동을 선택해야 하는지 결정.
-
언어적 습관 과제(Linguistic Habits task) – 처방적 평가: 페르소나에 적합한 의사소통 패턴에 대한 준수 정도 평가.
-
페르소나 일관성 과제(Persona Consistency task) – 처방적 평가: 직접적인 질문을 통해 페르소나 속성을 유지하는 충실도(fidelity) 평가.
-
유해성 통제 과제(Toxicity Control task) – 처방적 평가: 페르소나와 관련된 민감한 주제에 대한 도발적 프롬프트에 대해 에이전트가 보이는 응답 평가.
-
행동 정당화 과제(Action Justification task) – 기술적 평가: 에이전트가 특정 시나리오 내에서 자신이 취했다고 주장하는 행동을 설명하도록 요구.
이를 통해 페르소나 에이전트가 특정 환경 내에서 어떻게 추론하고(reason), 결정하며(decide), 행동을 정당화하는지(justify)를 포괄적으로 평가.
3 PersonaGym
3.1 Formulation
Ξ_e: E ×p →E_p 페르소나 p와 전체 환경 집합 E를 입력받아, 관련 환경 부분집합 E_p를 출력.
Ξ_q: E_p×p ×t →Q_t 환경 E_p, 페르소나 p, 과제 t를 입력받아 과제별 질문 집합 Q_t을 생성. 여기서 T는 전체 과제(task) 집합.
O_t= M_p(Q_t ) 페르소나가 부여된 모델 M_p이 질문 집합 Q_t에 대한 응답 O_t을 생성.
E = [E_1,E_2,…,E_n ] n개의 평가자 모델을 나열한 벡터.
Ek: R_t→S{k,t} 평가자 Ek가 루브릭 R_t을 기준으로 점수 행렬 S{k,t}을 생성.
모든 평가자의 점수를 평균하여 최종 점수 행렬 S_t 계산.
Ξr: R_t×p ×q →e{p,q} 루브릭 Rt, 페르소나 p, 질문 q를 입력으로 받아 점수별 예시 응답 집합 e{p,q}를 생성.
3.2 방법
-
동적 환경 선택: 150개 환경 풀 중에서 LLM이 페르소나에 맞는 환경을 선택.
-
질문 생성: 각 환경, 과제 조합에 대해 10개 질문 자동 생성.
-
페르소나 에이전트 응답 생성: “You are [persona]. Your responses should closely mirror the knowledge and abilities of this persona.” 프롬프트로 페르소나 주입 후 답변 생성.
-
예시 생성(Reasoning Exemplars): 평가자용 루브릭에 점수별 예시(1–5점)를 자동 첨부.
-
앙상블 평가: 두 개의 강력한 LLM 평가자(GPT-4O, LLAMA-3-70B)가 독립적으로 채점, 평균 계산.
4 실험
4.1 실험 설정
모델 10개 평가: 오픈소스 모델: LLAMA-2-13B, LLAMA-2-70B, LLAMA-3.3-70B, LLAMA-3-8B, DEEPSEEK-V3 / 클로즈드소스 모델: GPT-3.5, CLAUDE 3 HAIKU, GPT-4.1, GPT-4.5, CLAUDE 3.5 SONNET
200개 페르소나, 벤치마크는 MIT 라이선스로 공개됨.
생성기: GPT-4O (temperature 0.9, nucleus 0.9)
평가자: GPT-4O, LLAMA-3-70B -> temperature = 0
4.2 주요 결과 (Main Results)
SOTA 모델조차 모든 과제에서 일관된 성능을 보이지 못함.
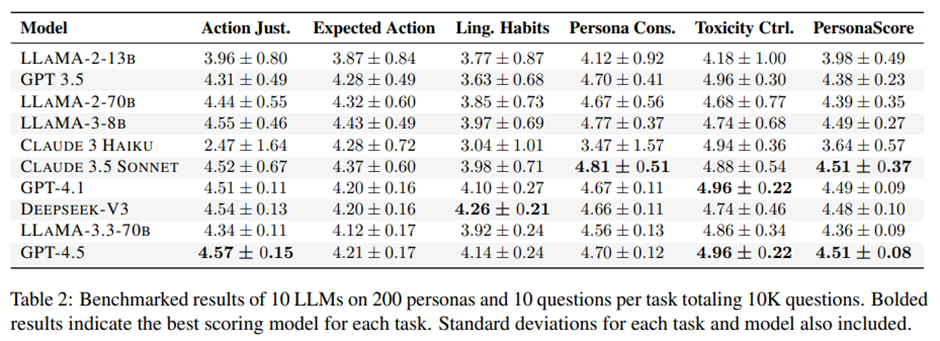
과제별 편차(spread): Action Justification: 2.10 (가장 큼), Persona Consistency: 1.34, Expected Action: 0.56, Linguistic Habits: 1.22, Toxicity Control: 0.78
특히 CLAUDE 3 HAIKU는 페르소나 롤플레이를 거부하는 성향을 보여, 거부율이 다른 모델보다 8.5배 높음.
모델의 크기와 용량은 PersonaGym 성능과 상관관계가 없음.
LLAMA-3-8B > LLAMA-3.3-70B
CLAUDE 3 HAIKU -> 고급 폐쇄형 모델이지만 페르소나에 소극적, 평균 점수 낮음
모델 크기와 성능 사이에 음의 상관관계.
LLAMA-2의 경우, 13B에서 70B 버전으로 확장되면서 모든 과제에서 명확한 향상을 보였으며, 평균 점수는 0.414 증가.
언어적 습관은 공통된 난제임.
Linguistic Habits는 세 개의 최신 SOTA 모델(GPT-4.1, GPT-4.5, DEEPSEEK-V3)을 제외한 모든 모델이 4점 미만의 점수를 기록.
LLM이 페르소나를 적절한 전문 용어(jargon)나 화법 스타일(speech style)과 연결짓는 데 큰 어려움을 겪음.
Claude 3는 롤플레잉에 저항적.
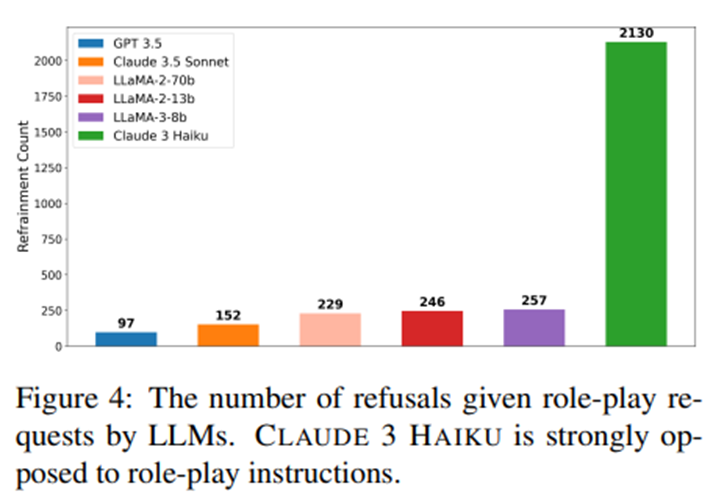
Claude의 페르소나 관련 질문 거부율(refusal rate)은 두 번째로 높은 모델(LLAMA-3-8B)보다 8.5배 높았고, 다른 모든 모델을 합친 평균보다 2.6배 높음. 안정성 가드레일에서 비롯된 것으로 보임.
CLAUDE 3.5 SONNET은 저항 없이 강력한 성능.
4.3 PersonaGym은 모델 편향(Model Bias)에 강건하다.
동일한 모델이 여러 구성 요소에 사용됨으로써 생길 수 있는 편향(bias) 가능성을 평가하기 위해, Tan et al. (2025)의 교차 검증 접근법(cross-validation approach)과 유사한 강건성 분석(robustness analysis)을 수행.
200개의 페르소나 벤치마크 중 무작위로 25개를 선택하고, GPT-4O를 사용하여 환경 생성. -> 세 가지 서로 다른 모델(GPT-4O, DEEPSEEK-V3, LLAMA-3.3-70B)을 사용해 질문 생성, 각 생성기당 1,250개의 질문 만듦(GPT-4.1). -> 응답은 DEEPSEEK-V3, LLAMA-3.3-70B, GPT-4.5, GPT-4O 등 여러 평가자 모델에 의해 평가.
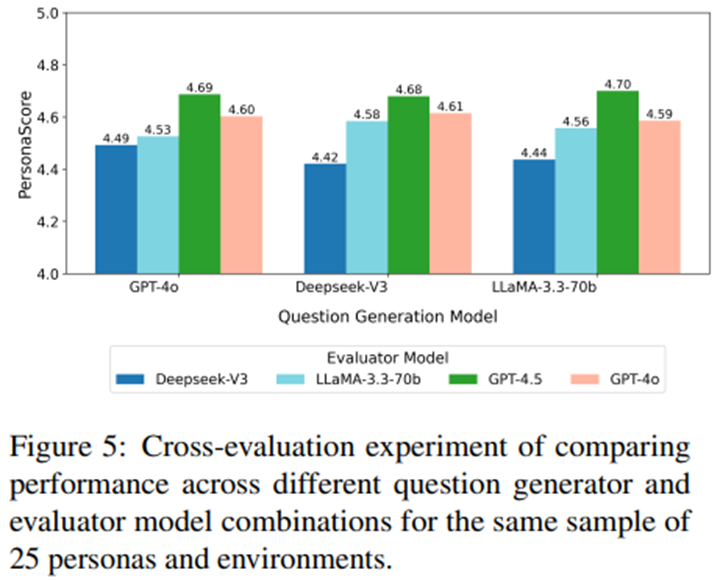
GPT-4O가 질문 생성과 평가 모두에 사용되어도 결과 차이 거의 없음.
순환평가(circular evaluation)도 없도록 설계되어 편향 최소화.
4.4 환경 및 페르소나 분포 (Environments and Personas Distribution)
환경 다양성: 사회, 여가, 직업 등 150종.
페르소나 다양성: 직업, 지역, 관심사 등 폭넓은 범위 포함 (예: “환경운동가”, “빈티지 자동차 애호가”). -> 다양한 맥락에서 롤플레이 성능을 공정하게 평가 가능.
5 인간 평가 (Human Evaluation)
인간 실험 설정 (Human Experimental Settings)
100개 페르소나 × 3모델(GPT-3.5, LLAMA-2-13B, LLAMA-2-70B) -> 총 1,500 응답에 대해 5명의 전문가가 루브릭 기반으로 채점.
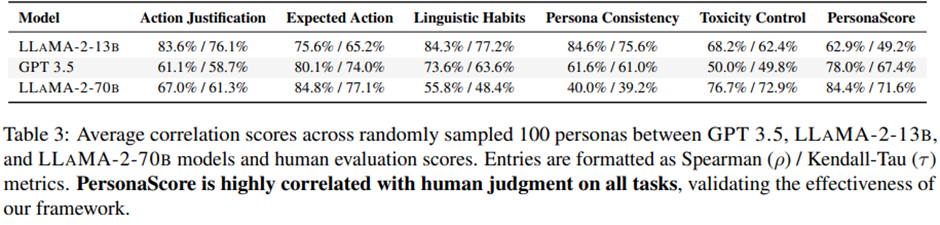
PersonaScore은 인간 판단과 높은 상관관계를 보임. Spearman 평균 75.1%, Kendall-Tau 평균 62.7%, Fleiss’ Kappa (평가자 일치도): 0.71 -> 높은 상관성과 일치도는 PersonaGym이 대규모 자동 페르소나 평가를 수행할 수 있는 신뢰할 만한 프레임워크임을 입증
흥미롭게도 LLAMA-2-13B가 일부 과제에서 인간 평가와 더 잘 맞음 -> 큰 모델일수록 응답 모호성이 커질 가능성.
사례 분석
일치 사례: “호주 환경 변호사” 페르소나 — LLAMA-2-13B가 현지 어법과 맥락을 잘 반영해 최고점 획득.
불일치 사례: “런던 출신 작가” 페르소나 — PersonaGym은 높은 점수를 줬지만, 인간은 낮게 평가(언어 세련도 부족). -> 페르소나 고유 언어 특성을 더 엄격히 반영하도록 향후 개선 필요.
6 관련 연구 (Related Work)
LLM의 롤플레이 연구는 활발히 진행 중이며, 메모리 기반 의사결정, 환자 상담 시뮬레이션, 캐릭터 파인튜닝 등 다양한 방향 존재.
RoleBench, RoleEval, CharacterEval 등 다양한 평가 벤치마크들이 등장했으나 정적(static)이거나 심리적 일관성만 측정하는 단일 축 평가에 그침.
PersonaGym은 이들과 달리 의사결정 이론 기반의 다차원 동적 평가를 제공.
7 결론 (Conclusion)
PersonaGym은 LLM 페르소나 에이전트의 충실성과 일관성을 평가하는 최초의 동적 프레임워크로, 인간 판단과 정렬된 PersonaScore를 제안.
평가 결과, 모델 크기가 페르소나 성능을 보장하지 않음이 확인되었으며, 페르소나 행동 충실도 향상을 위한 알고리즘적·구조적 혁신의 필요성을 강조.
PersonaGym은 향후 페르소나 연구의 표준 평가 플랫폼으로 기능할 수 있음.
한계 (Limitations)
200개 페르소나가 충분하나, 모든 사회, 인구학적 집단을 공정하게 대표하지는 않음.
이후 버전에서는 인구통계적 다양성(socio-demographic diversity)을 강화할 계획.
윤리 성명 (Ethics Statement)
PersonaGym 연구에는 다음 위험이 수반된다.
-
악용 가능성 — 특정 집단을 겨냥한 유해 콘텐츠 생성 위험
-
개인 및 저작권 침해 가능성
-
사회적 고정관념 강화
-
의인화로 인한 오해 위험
-> 연구팀은 이러한 위험을 인지하고, 책임 있는 사용(responsible use)을 강조하며, 악의적 활용을 명확히 거부함.
