Direct Preference Optimization: Your Language Model is Secretly a Reward Model Rafael Rafailov⇤† Archit Sharma⇤† Eric Mitchell⇤† Stefano Ermon†‡ Christopher D. Manning† Chelsea Finn† † Stanford University ‡CZ Biohub {rafailov,architsh,eric.mitchell}@cs.stanford.edu Part of Advances in Neural Information Processing Systems 36 (NeurIPS 2023) Main Conference Track
1 서론
모델이 보유한 광범위한 지식과 능력 중에서 원하는 응답과 행동을 선택적으로 이끌어내는 것이 안전하고, 성능이 높고, 제어 가능한 AI 시스템을 구축하는 데 핵심적.
기존의 방법은 RL을 통한 것. -> 본 논문에서는 기존의 RL 기반 목적함수가 단순한 이진 교차 엔트로피(binary cross-entropy) 목적함수로 정확히 최적화될 수 있음을 보여주고, 이를 통해 선호 학습(preference learning) 파이프라인을 대폭 단순화함.
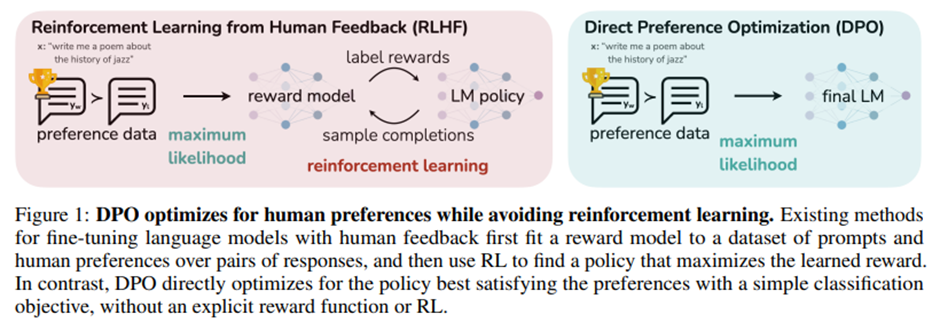
제안: DPO: 강화학습 없이 인간 선호 데이터로 언어 모델을 학습할 수 있는 단순하고 안정적인 알고리즘. 기존 RLHF 알고리즘과 동일한 목적(보상 최대화 + KL 발산 제약)을 암묵적으로 최적화하지만 구현이 단순하고 학습이 직관적임.
2 관련 연구 (Related Work)
Instruction-tuning: LLM이 학습되지 않은 새로운 명령어에도 일반화(generalization)할 수 있게 함.
응답 품질에 대한 상대적 인간 판단(relative human judgments)은 전문가 시연(expert demonstrations)보다 수집하기 쉽기 때문에 이후 연구는 인간 선호 데이터셋 이용해서 LLM 파인튜닝. -> 번역, 요약, 스토리텔링, 명령어 수행 능력 향상.
Bradley-Terry 모델로 선호 데이터와 일관성에 맞춰서 신경망 보상 함수 학습 -> REINFORCE [44], PPO(Proximal Policy Optimization) [37], 또는 그 변형 [32]을 이용한 강화학습으로 언어 모델 파인튜닝.
-> LLM 강화학습으로 파인튜닝 실질적인 어려움. -> relative preferences 최적화할 수 있는 이론적으로 정당화된 접근법 제시.
선호로부터 정책을 학습하는 문제: 밴딧(bandit) 및 강화학습 설정에서 연구.
절대적 보상이 없는 상황: CDB의 이론적 분석이 최적 정책(optimal policy) 개념 대신 폰 노이만 승자(von Neumann winner) 개념 사용. 어떤 정책의 기대 승률(expected win rate)이 다른 모든 정책에 대해 최소 50% 이상일 때 그 정책은 최적.
선호 기반 강화학습(preference-based RL, PbRL): 알려지지 않은 ‘점수 함수(scoring function)’가 생성한 이진 선호(binary preferences)로부터 학습.
-> 대체로 잠재 점수 함수(latent scoring function), 보상모델을 명시적으로 추정한 뒤 최적화 -> 단일 단계의 정책 학습으로 선호를 직접 만족시키도록 최적화하는 방법 제시.
3. Preliminaries
RLHF는 세 단계를 따름.
SFT: 사전학습된 언어모델을 특정 다운스트림 과제(예: 대화, 요약 등)에 대해 고품질 데이터로 지도학습해서 파인튜닝하는 것으로 시작.
Reward Modeling: SFT 모델이 생성한 응답 쌍 (y_1,y_2 ) ~ π^SFT (y|x) 을 인간이 비교해서 선호 응답 y_w, 비선호 응답 y_w 라벨링.
Bradley-Terry 모델: 선호를 모델링하는 가장 일반적인 접근법. 여러 응답이 순위로 매겨진 경우에는 Plackett-Luce 순위 모델도 사용 가능.
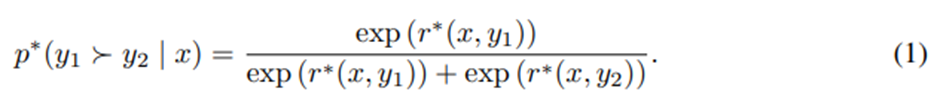
p^*은 인간 선호 분포.
보상 모델 r(x, y)를 파라미터화하고 MLE를 통해 파라미터 추정. 이 문제를 이진 분류 문제로 보면 음의 로그우도 손실은
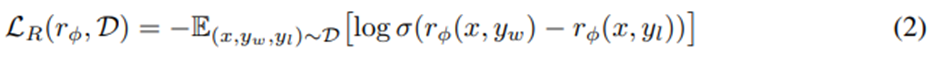
σ는 로지스틱 함수.
언어 모델의 경우 r(x, y) 네트워크는 보통 SFT 모델 π^SFT (y|x)로부터 초기화, 마지막 트랜스포머 층 위에 하나의 linear layer를 추가해서 단일 스칼라 값을 출력하도록 함. 봇아함수의 분산을 낮추기 위해 선행 연구에서는 모든 x에 대해 E(x,y)~D(rϕ (x,y)]=0이 되도록 보상을 정규화.
RL 파인튜닝 단계: RL에서는 학습된 보상 함수를 이용해 언어 모델 파인튜닝. 다음 최적화 문제를 고려함.
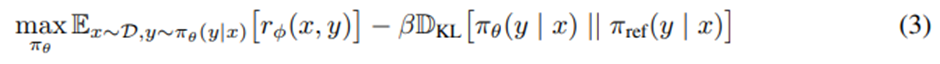
β는 기준이 되는 reference policy π_ref으로부터의 편차를 제어하는 하이퍼파라미터.
KL 제약 항은 모델이 보상 모델이 신뢰할 수 있는 분포에서 지나치게 벗어나지 않도록 하고, 동시에 생성 다양성을 유지하여 단일 고보상 응답으로 수렴하는 mode collapse 방지.
표준적인 접근법에서는 아래와 같이 보상 함수를 구성하고 PPO를 사용해 최대화.
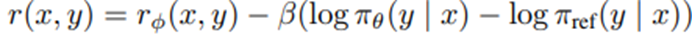
최적화 과정에서 모델이 생성한 확률 분포가 참조 모델로부터 과도하게 벗어나지 않도록 제약을 두면서, 보상을 최대화하는 방향으로 학습 이루어짐.
4 Direct Preference Optimization
우리의 목표는 선호(preference) 데이터를 직접 사용하여 정책(policy)을 단순하게 최적화할 수 있는 접근법 도출하는 것. 기존과 다르게 먼저 보상 함수를 학습한 뒤 이를 강화학습으로 최적화하지 않고, 보상 모델링 단계를 생략하고 선호 데이터 자체로 언어 모델을 직접 최적화.
핵심: 보상 함수와 최적 정책 간의 해석적 매핑(analytical mapping) 활용. -> 이를 통해 보상 함수에 대한 손실 함수를 정책에 대한 손실 함수로 변환(change of variables). 명시적인 보상 모델링 생략하면서 기존 인간 선호 모델(예: Bradley-Terry) 기반으로 최적화 가능함.
DPO 목적함수의 도출.
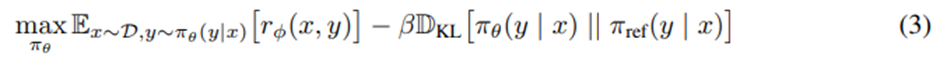
여기서 출발.
일반적인 보상 함수 r에 대해 선행 연구들을 따르면 KL 제약이 있는 보상 최대화 문제의 최적 해는 다음과 같은 형태를 가짐.
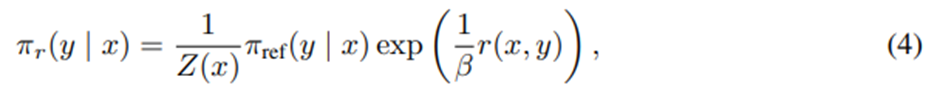
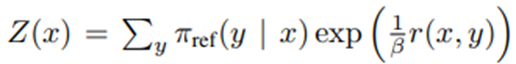
Z(x)는 정규화 상수.
Z(x)를 계산하는 건 비용이 매우 크고, 이 표현을 실제로 활용하기 어렵게 만듦.
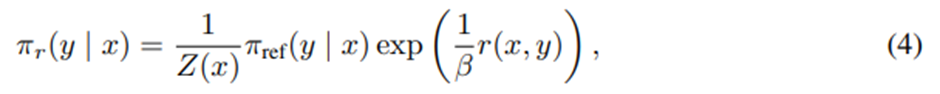
를 정리하면 보상함수를 그에 대응하는 최적 정책 π_r, 참조 정책 π_ref, 알 수 없는 정규화 상수 Z(⋅)로 표현할 수 있음.
양변에 로그를 취한 후 약간의 대수적 변형을 거치면
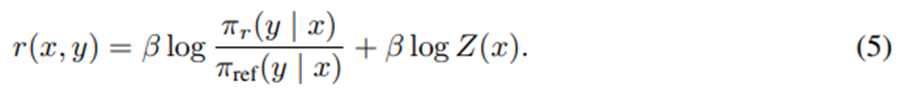
임.
이 재파라미터화를 실제 보상 r^, 이에 대응하는 최적 정책 π^에 적용할 수 있음. Bradley-Terry 모델은 두 응답 간 보상 차이에만 의존.
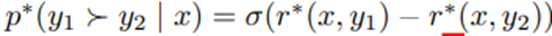
임.
위 식의 r^* (x,y)를
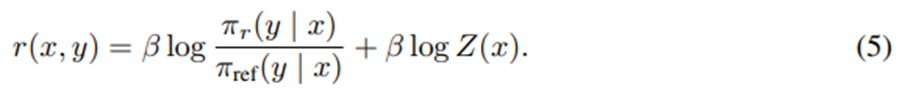
의 재파라미터화 형태로 대입하면, 정규화 상수 Z(x)가 소거되어 사라짐.
-> 인간 선호 확률을 오직 최적 정책 π^*와 참조 정책 π_ref만으로 표현할 수 있음.
Bradely-Terry 모델의 최적 RLHF 정책 π^* 은
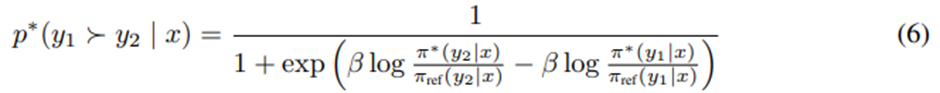
선호 모델을 만족함.
인간 선호 데이터를 보상 모델이 아니라 최적 정책의 함수로 표현할 수 있게 되었으므로, 파라미터화된 정책 π_θ에 대해 최대우도 목적함수 정의 가능.
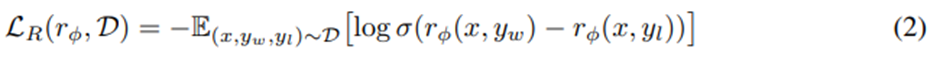
에 상응하는 정책 목적함수는
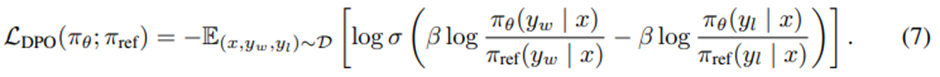
임.
-> 명시적인 보상 모델링 단계 생략하고, 강화학습 최적화 절차 수행할 필요 없어짐. 이 과정은 재파라미터화된 Bradley-Terry 모델을 fitting 하는 것과 수학적으로 동등하므로, 선호 데이터 분포에 대한 적절한 가정하에 consistency와 같은 이론적 성질 보장.
DPO 업데이트는 무엇을 하는가?
파라미터 θ에 대한 손실 함수 L_DPO의 그래디언트는

임.
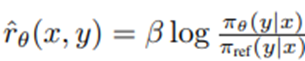
는 언어 모델 π_θ와 참조 모델 π_ref로부터 암묵적으로 정의된 보상 함수임.
직관저긍로, L_DPO의 그래디언트는 선호된 응답 y_w의 로그 확률을 증가시키고, 비선호된 응답 y_l의 로그 확률을 감소시키는 방향으로 작용. 각 예시는 암묵적 보상 모델이 비선호된 응답에 얼마나 높은 보상을 주는지, 즉 보상 모델이 얼마나 잘못된 순서를 예측했는지에 따라 가중됨. 가중치는 KL 제약 강도 β에 의해 조정됨.
가중치를 포함하지 않은 단순한 확률비 기반 방법은 언어 모델이 붕괴되는 현상 일으킬 수 있음.
DPO outline.
-
각 프롬프트에 대해 차조 정책으로부터 응답 샘플링 -> 인간 평가자의 응답에 대한 선호 표시 -> D={x^((i) ),yw^((i) ),y_l^((i) ) }(i=1)^N 구축
-
주어진 πref, D, β 값에 대해, 언어 모델 πθ를 L_DPO를 최소화하도록 최적화.
선호 데이터셋이 π^SFT를 통해 샘플링된 경우, 참조 정책을 π_ref= π^SFT로 초기화.
π^SFT 사용 불가한 경우, 선호된 응답 쌍 (x,y_w)에 대해 최대우도추정으로 π_ref 초기화.
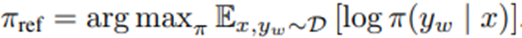
이 절차는 unknown true reference distribution와 DPO에서 사용하는 π_ref 간의 분포 차이를 완화하는 데 도움.
5. Theoretical Analysis of DPO
5.1 Your Language Model is Secretly a Reward Model
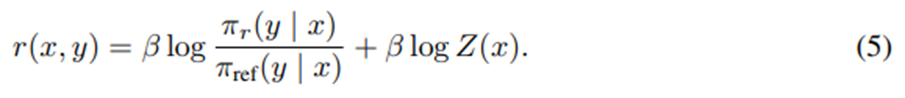
이 최적화 목적식은 사실상 보상 함수가
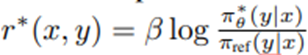
인 Bradley-Terry 모델과 동등함. 우리는 파라미터화된 모델 π_θ를 최적화하는데, 이는 변수 변환을 통해
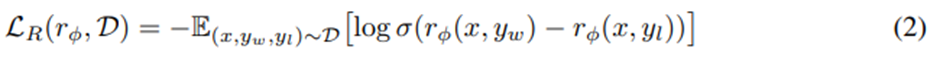
의 보상 모델 최적화와 동일한 형태로 볼 수 있음.
보상함수 간의 등가 관계 정의:
정의 1. 두 보상 함수 r(x,y)와 r'(x,y)가 r(x,y)-r^' (x,y)=f(x)를 만족할 때, 어떤 함수 f(x)가 존재한다면 이 둘은 equivalent.
Lemma 1. Plackett–Luce, 특히 Bradley–Terry 선호 프레임워크 하에서는, 같은 등가 클래스에 속한 두 보상 함수는 동일한 선호 분포(preference distribution)를 유도함. -> 모호성 문제 반영. 모호성 때문에 MLE에 대해 보장된 결과를 얻으려면 일반적으로 식별성 제약(identifiability constraints)을 추가해야 함.
Lemma 2. 같은 등가 클래스에 속한 두 보상 함수는 제약된 강화학습(constrained RL) 문제 하에서 동일한 최적 정책을 유도함. -> 동일한 등가 클래스에 속하는 모든 보상 함수가 동일한 최적 정책을 낳음. 최정적으로 우리는 단지 최적 클래스에 속하는 보상 함수 중 하나를 복원하면 충분함.
Theorem 1. Plackett-Luce (특히 Bradley-Terry) 모델과 일치하는 모든 보상 함수 클래스는
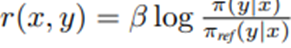
형태로 표현될 수 있음. π(y|x)는 어떤 모델이고, π_ref (y|x)는 주어진 참조 모델.
Proof Sketch. Projection f를
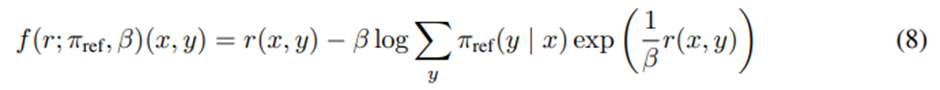
라고 정의.
이 연산자는 단순히 보상 함수를 정규화하여 π_r의 정규화 상수의 로그를 빼는 역할을 함. 추가한 정규화 항은 오직 x에만 의존하므로 f(r;π_ref,β)(x,y)는 r(x,y)와 같은 등가 클래스에 속하는 보상 함수임.
어떤 보상함수에 대해서도
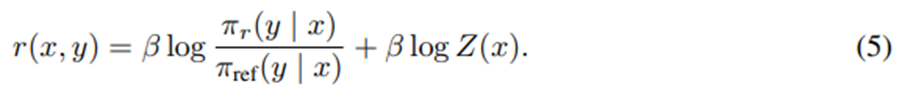
가 성립하므로,
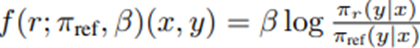
가 됨. 즉, 프로젝션 f는 r의 등가 클래스 내에서 우리가 원하는 형태를 가진 보상 함수를 생성함. 결과적으로 제안된 재파라미터화는 표현 가능한 보상 모델의 일반성을 잃지 않음.
이 정리를 다른 시각으로 보면, DPO의 재파라미터화가 각 등가 클래스 내에서 정확히 어떤 보상 함수를 선택하는지 명시함.
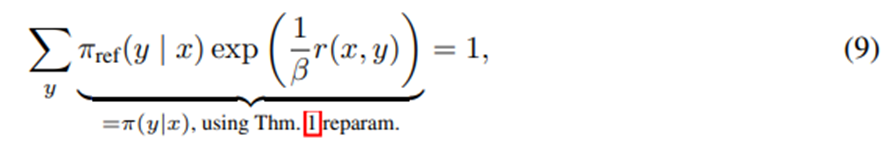
이 조건을 만족하는 보상 함수를 선택함.
즉, π(y|x)가 올바른 확률분포임.
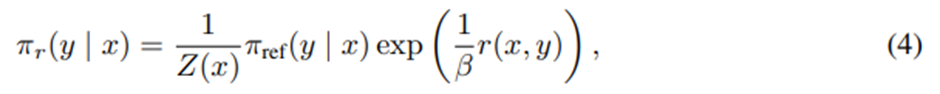
에 따르면, 위 식은 보상 함수 r(x,y)가 유도하는 최적 정책의 정규화 항과 동일함.
DPO 알고리즘의 핵심 통찰은, Plackett–Luce(특히 Bradley–Terry) 선호 모델이 본래 비식별적(under-constrained)이라는 점을 이용하여 표현 가능한 보상 모델의 집합을 그대로 유지하면서도
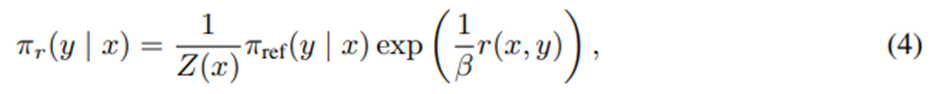
의 최적 정책이 모든 프롬프트 x에 대해 해석적으로 계산 가능(analytically tractable)하도록 특정 제약을 부여한다는 것임.
5.2 Instability of Actor-Critic Algorithms
우리의 프레임워크는 RLHF에 사용되는 표준 actor-critic 알고리즘, 예를 들어 PPO의 불안정성을 진단하는 데에도 사용될 수 있음.
제약된 강화학습 문제를 control-as-inference 프레임워크의 관점에서 다시 볼 수 있음. 파라미터화된 모델 π_θ (y|x)에 대해, 최적 정책 π^*와의 KL 발산을 최소화한다고 가정하면
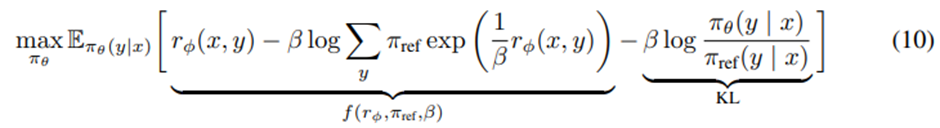
의 목적함수로 귀결됨.
f(r,π_ref,β)로 표시되는 정규화 항은 참조 정책 π_ref의 soft value function으로 해석할 수 있음. 이 항은 최적 해 자체에는 영향을 주지 않지만 생략하면 정책 그래디언트의 분산이 매우 커져 학습이 불안정해짐.
DPO의 재파라미터화는 베이스라인이나 값 함수 근사 없이도 작동할 수 있는 보상함수를 직접 제공함 -> 강화학습 기반 방법에서 발생하는 불안정성을 제거하면서 동일한 보상 클래스에 대해 더 간결하고 안정적인 최적화 가능하게 함.
6 Experiments
DPO가 선호 데이터로부터 직접 정책을 학습하는 능력을 실증적으로 평가. 결과적으로, 하이퍼파라미터 튜닝이 거의 없이도, DPO는 PPO 기반 RLHF 같은 강력한 기준선(baseline)들과 비슷하거나 더 나은 성능.
Tasks. 세 가지 open-ended 텍스트 생성 과제 탐구. 모든 실험에서 알고리즘은 선호 데이터셋 D={x^((i) ),yw^((i) ),y_l^((i) ) }(i=1)^N으로부터 정책 학습.
-
통제된 감정(sentiment) 생성: X는 IMDb 데이터셋의 영화 리뷰 서두(prefix), 정책은 긍정적인 감정의 응답 y를 생성해야 함. 통제된 평가를 수행하기 위해 이 실험에서는 사전 학습된 감정 분류기를 사용하여 선호 쌍 자동으로 생성. SFT 단계에서는 IMDb 학습 세트의 리뷰로 GPT-2-large 모델을 수렴할 때까지 파인튜닝.
-
요약: x는 Reddit 포럼 게시물, 정책은 게시물의 주요 요점을 요약하는 y를 생성해야 함. 선행 연구를 따라 Reddit TL;DR 요약 데이터셋과 Stiennon et al.이 수집한 인간 선호 데이터 사용. SFT 모델은 TRLX 프레임워크를 사용하여 인간이 작성한 게시물 요약문으로 파인튜닝. Stiennon et al.이 수집한 인간 선호 데이터셋은 동일한 구조이지만 다른 SFT 모델에서 샘플링된 데이터로 구성됨.
-
단일 턴 대화(single-turn Dialogue): x는 인간 질의, 천체물리학에 관한 질문일 수도 있고 연애 상담 요청일 수도 있음. 정책은 사용자의 요청에 대해 흥미롭고 도움이 되는 응답 y를 생성해야 함. Anthropic의 Helpful and Harmless Dialogue Dataset 사용(인간과 자동화된 어시스턴트 간의 17만 개 이상의 대화 포함). 각 대화는 대형(그러나 비공개) 언어 모델이 생성한 두 응답과, 어느 응답이 인간에게 더 선호되었는지를 나타내는 라벨로 끝남. 미리 학습된 SFT 모델이 존재하지 않기 때문에, 오프더셸프 언어 모델을 인간이 선호한 응답만으로 파인튜닝하여 SFT 모델 구성.
평가. 통제된 감정 생성 실험에서는 각 알고리즘이 제약된 보상 최대화 목적을 얼마나 효과적으로 최적화하는지 분석하기 위해 달성된 보상과 참조 정책으로부터의 KL 발산 간의 프런티어(frontier) 측정. 이 프런티어는 실제 보상 함수(감정 분류기)가 존재하므로 계산 가능.
실제 환경에서는 보상 함수를 알 수 없기 때문에, 요약 및 단일 턴 대화 과제에서는 GPT-4를 인간 평가의 대리(proxy)로 사용하여 알고리즘 간 성능 비교. 각 알고리즘이 생성한 응답과 기준 정책의 응답을 비교해 승률 계산. 요약 과제에서는 테스트 세트의 참조 요약(reference summary), 대화 과제에서는 테스트 데이터셋 내의 인간이 선호한 응답 기준.
Methods.
DPO 외의 방법들도 사용함.
요약 과제: GPT-J 사용한 제로샷 프롬프트
단일 턴 대화 과제: Pythia-2.8B를 사용한 2-shot 프롬프트
SFT와 Preferred-FT(인간이 선택한 응답에 대해 지도학습으로 파인튜닝된 모델) 평가.
PPO(선호 데이터로부터 학습된 보상 함수 최적화함) 사용, PPO-GT라 불리는 오라클 버전도 고려.
감정 과제: PPO-GT(TRLX에서 제공하는 of-the-shelf version, 보상을 정규화하고 하이퍼파라미터를 추가 조정하여 성능을 향상시킨 수정된 버전) 사용.
Best of N 기준선 고려: SFT 모델(또는 대화 과제에서는 Preferred-FT 모델)로부터 N개의 응답을 샘플링한 뒤 선호 데이터셋으로부터 학습된 보상 함수에 따라 가장 높은 점수를 받은 응답을 선택하는 방식. 계산 비용이 매우 크고 현실적으로 비효율적.
6.1 How well can DPO optimize the RLHF objective?
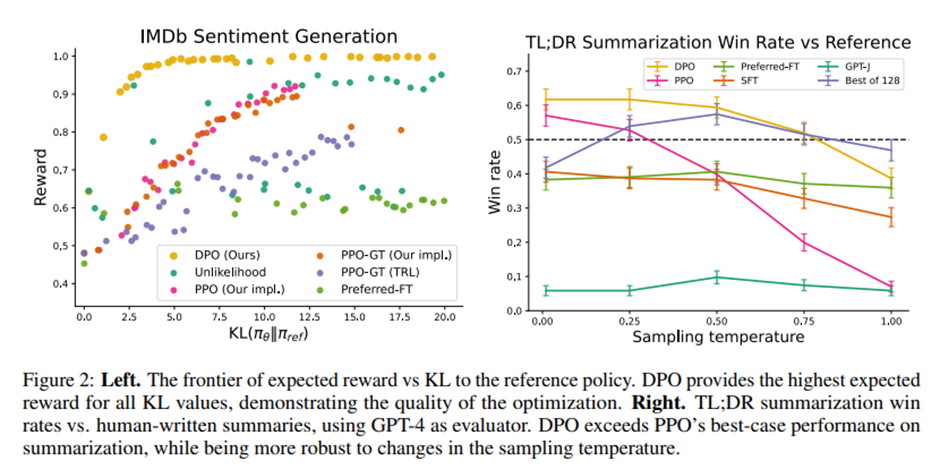
감정(sentiment) 실험에서 다양한 알고리즘의 보상–KL 프런티어(reward–KL frontier).
각 알고리즘마다 정책 보수성(policy conservativeness)에 관한 하이퍼파라미터를 다르게 하여 여러 학습(run) 수행.
PPO는 목표 KL 값을 {3, 6, 9, 12}, DPO는 β∈{0.05, 0.1, 1, 5}, unlikelihood는 α∈{0.05, 0.1, 0.5, 1}, Preferred-FT는 서로 다른 랜덤 시드 사용. 총 22회 실험, 학습이 수렴할 때까지 100 스텝마다 평가. 실제 보상 함수(감정 분류기)에 따른 평균 보상, 참조 정책과의 평균 시퀀스 수준 KL 발산(각 시점별 KL의 합) 계산.
-> DPO는 낮은 KL 값 유지하면서 가장 높은 보상 달성. 실제 보상 이용하는 PPO-GT보다 우수.
6.2 Can DPO scale to real preference datasets?
실제 선호 데이터셋 사용한 요약과 단일 턴 대화 과제에서 DPO 파인튜닝 성능 평가.
요약 과제: 자동 평가 지표(예: ROUGE)가 인간의 선호와 상관관계가 낮은 경우가 많고 PPO 이용한 선호 학습이 더 나은 요약 결과 가져온다는 결과 있었음. TL;DR 요약 데이터셋의 테스트 세트에서 각 방법의 응답을 샘플링해서 참조 요약(reference completion)과 비교한 평균 승률(win rate) 계산. 샘플링 온도(temperature) 0.0에서 1.0까지 여러 값 실험.
-> DPO가 temperature 0에서 61% 승률. PPO는 57%. DPO는 PPO보다 temperature 변화에 robust.
단일 턴 대화 과제: Anthropic HH 데이터셋 [1]의 테스트 세트 중, 인간–어시스턴트 간 1단계 상호작용(one-step interaction) 부분 사용. GPT-4 평가자는 테스트 세트의 선호된 응답(preferred completion)을 기준으로 각 방법의 승률 계산. 사전학습된 Pythia-2.8B 모델에서 시작해서 Preferred-FT를 통해 선택된 응답으로 참조 모델을 학습시키고 그 위에 DPO 적용.
Best of 128 Preferred-FT 기준선(이 과제에서 128개 응답에서 수렴함)과, Pythia-2.8B 기본 모델의 2-shot 프롬프트 버전 비교.
-> DPO는 인간이 선호한 응답보다 성능이 향상된 유일한 계산 효율적 방법. 계산적으로 매우 비용이 큰 Best of 128 기준선과 유사하거나 더 나은 성능 보여줌.
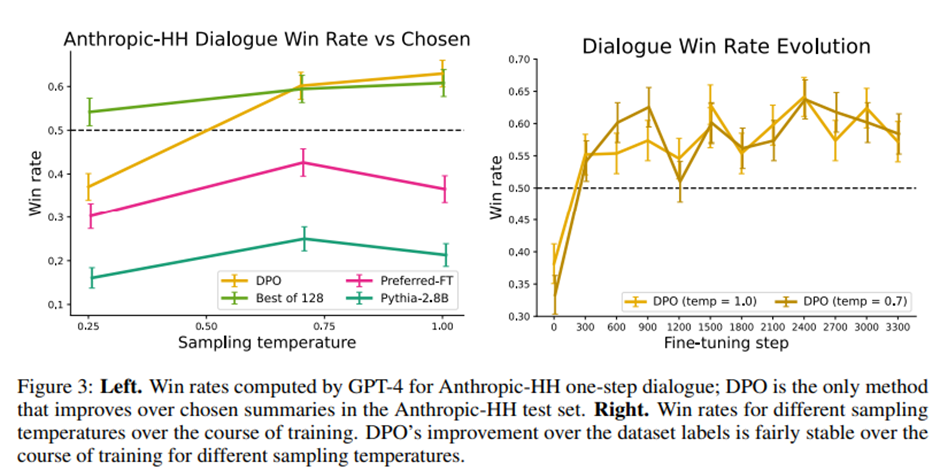
DPO가 비교적 빠르게 최적 성능에 수렴함.
6.3 Generalization to a New Input Distribution
PPO와 DPO의 분포 이동(distribution shift) 상황에서의 성능을 더 깊이 비교하기 위해, 우리는 Reddit TL;DR 요약 실험에서 학습된 PPO 및 DPO 정책을 다른 입력 분포, 즉 CNN/DailyMail 데이터셋 [24]의 테스트 세트에 포함된 뉴스 기사(news articles) 요약 과제에 대해 평가함. Temperature: PPO 0, DPO 0.25
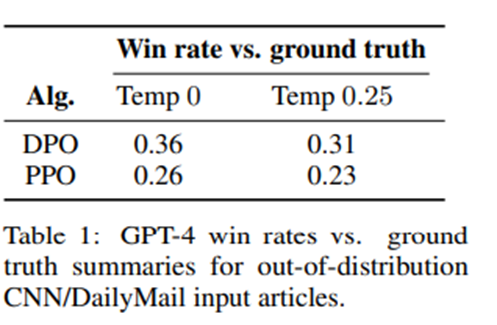
각 데이터셋의 실제 요약문(ground-truth summaries)을 기준으로 GPT-4 승률(win rate) 계산. Reddit TL;DR 평가에 사용했던 GPT-4 (C) 프롬프트를 동일하게 사용하되, 프롬프트 내의 “forum post”라는 문구만 “news article”로 교체.
-> DPO 정책은 PPO 정책보다 유의미하게 더 높은 성능을 유지. DPO는 추가적인 비라벨 데이터(unlabeled Reddit TL;DR prompts)를 사용하지 않았지만 PPO 정책과 유사하거나 더 나은 일반화 성능(generalization ability).
6.4 Validating GPT-4 Judgments with Human Judgments
GPT-4의 평가 판단이 신뢰할 만한지 검증하기 위해 인간 평가 병행.
GPT-4 (S): simple 평가 방식. 어느 요약이 게시물의 중요한 정보를 더 잘 요약하는가.
GPT-4 (C): concise 평가 방식. 어느 요약이 더 중요한 정보를 잘 담고, 동시에 더 간결한가.
-> GPT-4가 (S) 프롬프트를 사용할 때 인간보다 더 긴(longer) 혹은 반복적인(repetitive) 요약문을 선호하는 경향이 있기 때문에 추가.
가장 높은 성능인 DPO(temperature 0.25), 가장 낮은 성능인 PPO(temperature 1.0), 중간 성능 모델인 SFT(temperature 0.25) 선정하여 탐욕적 샘플링(greedy sampling)된 PPO (temperature 0) 모델과 비교. -> 샘플 품질의 다양성 포괄 위해.
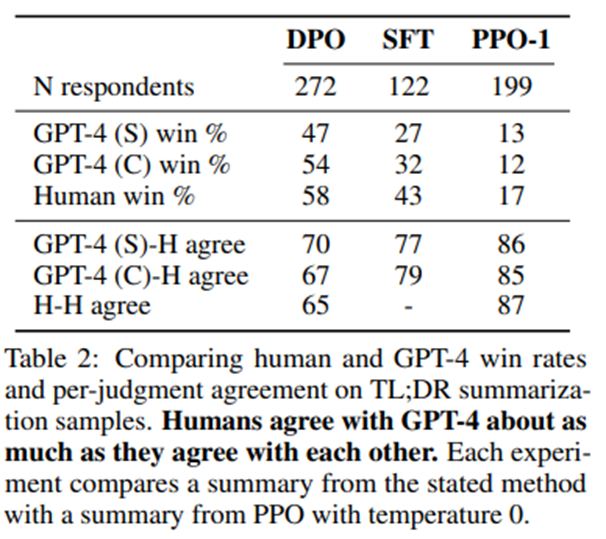
-> 두 가지 GPT-4 프롬프트 모두에서 GPT-4의 판단과 인간 평가의 일치도(human–GPT-4 agreement)가 인간 평가자 간 일치도(inter-human agreement)와 거의 유사한 수준임. GPT-4 (C) 프롬프트가 인간 판단과 더 잘 일치, 인간의 실제 선호를 더 대표하는 승률 제공.
7 Discussion
선호로붜의 학습은 유능하고 인간 지향적으로 잘 정렬된 언어 모델을 학습하기 위한 강력하고 확장 가능한 프레임워크.
제안: 강화학습 없이(preference learning without reinforcement learning) 인간 선호로부터 언어 모델을 학습할 수 있는 단순한 학습 패러다임인 Direct Preference Optimization (DPO).
기존과 다르게 언어 모델의 정책(policy)과 보상 함수(reward function) 간의 수학적 매핑(mapping)을 찾아냄. -> 언어 모델이 강화학습이나 추가적인 복잡한 절차 없이도 단순한 교차 엔트로피 손실(cross-entropy loss) 만으로 인간의 선호를 직접 만족시키도록 학습할 수 있음.
하이퍼파라미터를 거의 조정하지 않아도 DPO는 기존의 PPO 기반 RLHF 알고리즘과 동등하거나 더 나은 성능.
한계 및 향후 연구 방향 (Limitations & Future Work).
-
DPO 정책이 분포 밖(out-of-distribution) 데이터에 대해 얼마나 잘 일반화하는가?: 명시적인 보상 함수로 학습하는 PPO와 비교했을 때의 일반화 성능 차이를 보다 정량적으로 분석할 필요.
-
DPO 정책을 이용한 자기 라벨링(self-labeling) 이 unlabeled 프롬프트를 효과적으로 활용할 수 있을까?: DPO가 명시적 보상 없이도 확장 가능한 자가 학습(self-training)을 수행할 수 있는지 탐색.
-
보상의 과최적화(reward over-optimization) 가 DPO 설정에서는 어떤 방식으로 나타나는가?
-
DPO를 최신 대규모(state-of-the-art) 언어 모델 수준으로 확장(scaling).
-
자동화된 평가 시스템(automated evaluators)으로부터 더 신뢰도 높은 판단을 이끌어내는 최적의 프롬프트 설계 방법을 탐구할 필요.
-
다른 생성형 모델(generative models) 분야, 예를 들어 이미지, 오디오, 멀티모달 생성에도 폭넓게 적용될 가능성
