Personalized HeartSteps: A Reinforcement Learning Algorithm for Optimizing Physical Activity Peng Liao ∗1 , Kristjan Greenewald2 , Predrag Klasnja3 , and Susan Murphy4 1Department of Statistics, University of Michigan 2 IBM Research 3School of Information, University of Michigan 4Department of Statistics, Harvard University September 10, 2019 Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, Volume 4, Issue 1 Article No.: 18, Pages 1 - 22
1 서론
모바일 헬스 기술 발전으로 건강 과학자들은 사용자의 현재 상황에 맞춰 적시에 중재를 제공하는 Just-In-Time Adaptive Interventions (JITAI)에 관심을 가짐.
JITAI 입력: 사용자 현재 상황, 출력: 중재 제공 여부 및 중재 종류을 결정하는 순차적 의사결정 규칙(policy) -> 어떤 중재, 언제 제공해야 하는지 명확하지 않은 경우 많고 장기적인 효능 최적화하기 어려움.
제안: 사용자가 중재를 경험하는 동안 JITAI 내의 치료 정책을 지속적으로 학습(온라인)하고 최적화하기 위한 RL 알고리즘.
2 HeartSteps V1 and V2: 신체활동 모바일 헬스 연구
HeartSteps V1: 37명 성인의 42일간의 신체활동 연구. 하루 5번 매번 0.30의 무작위 확률로 맞춤형 활동 제안. V2를 위한 RL 알고리즘 설계에 활용(예: 미래 걸음 수를 예측하는 데 유의한 변수 선택, 활동 제안의 효과를 파악하고 사전분포(prior distribution)를 형성, (2) RL 알고리즘을 평가하기 위한 시뮬레이션 환경(즉, 생성모형) 구축).
HeartSteps V2: 혈압이 고혈압 1단계 범위(수축기 120–130)의 개인들의 신체활동 개선을 목표로 하는 90일간의 임상 시험. RL 알고리즘이 실시간으로 정책 학습.
3 모바일 헬스에서 RL 적용의 도전 과제
HeartSteps 상태: 사용자의 현재 및 과거 맥락에서 얻은 특징(feature)들의 집합, 행동: 활동 제안을 보낼지 여부, 보상: 근접 미래 신체활동을 기반으로 한 함수.
C1: 중재가 즉각적인 보상에서는 긍정적, 미래 보상에서는 부정적인 영향. -> 최적 치료는 현재 행동이 미래 보상에 미치는 영향 고려해야 함.
C2: 모바일 헬스 애플리케이션은 사용자가 빠르게 이탈할 가능성이 있고, 컨텍스트 정보와 보상 모두 노이즈가 매우 많음(센서 등). -> 편향-분산 간 trade-off 신중히 해야함.
C3: 모델 오지정(mis-specification) 및 비정상성(non-stationarity) 수용해야 함. 컨텍스트 공간의 복잡성과 관측되지 않은 부담감 등 때문에 장기간에 걸쳐 비정상성 보일 가능성.
C4: 2차 데이터 분석이 가능하도록 행동 선택해야 함. -> off-policy learning, 인과추론, 기타 표준 통계 분석이 연구 종료 후에 가능해야함.
4 기존의 RL 기반 모바일 헬스 연구
실시간으로 개인의 중재를 적응시키기 위해 RL 기법을 적용한 기존 모바일 헬스 연구 많지 않음.
기존 연구에서는 즉각적 보상을 최적화하기 위한 행동 선택을 목표로 함. 최근 신체 활동 연구에서는 RL 시스템이 매주 말에 참가자의 일일 걸음 수 데이터를 사용해 일일 걸음 수에 대한 동적 시스템(dynamical system)을 추정하고, 이를 사용해 다음 7일의 최적 일일 걸음 목표를 추론함. 목표는 다음 주 동안의 최소 걸음 수를 최대화하는 것.
주장: 이러한 RL 알고리즘들이 3장에서 제시한 도전 과제들을 해결하기에 충분하지 않음. 여러 방향으로 일반화가 필요함.
-
위 연구들은 RL 알고리즘을 초기화하기 위해 순수 데이터 수집 단계만을 사용하지만, 실제로는 파일럿 연구 데이터나 전문가의 사전 지식 등 추가적인 사전 정보가 존재하는 경우가 많음.
-
위 연구들의 RL 알고리즘은 보상 함수의 올바른 모델을 알고 있다고 가정하지만, 컨텍스트 공간의 차원 및 복잡성, 그리고 (C3)의 비정상성 때문에 현실적이지 않음.
-
위 연구들 중 [42]의 알고리즘만이 즉각적 시점보다 긴 시간 지평에서 보상을 최적화하려 함. 긴 시간 지평을 고려하면 사용자 부담 및 이탈 문제를 반영할 수 있음.
-
[33]과 [42]는 행동을 결정론적으로 선택하며, [10]은 순수 활용 단계를 포함함. 행동 선택 확률이 0이나 1에 가까우면 중요도 가중치(importance weights)를 사용하는 배치 데이터 분석(예: 오프-정책 평가)에서 불안정성(고분산) 발생.
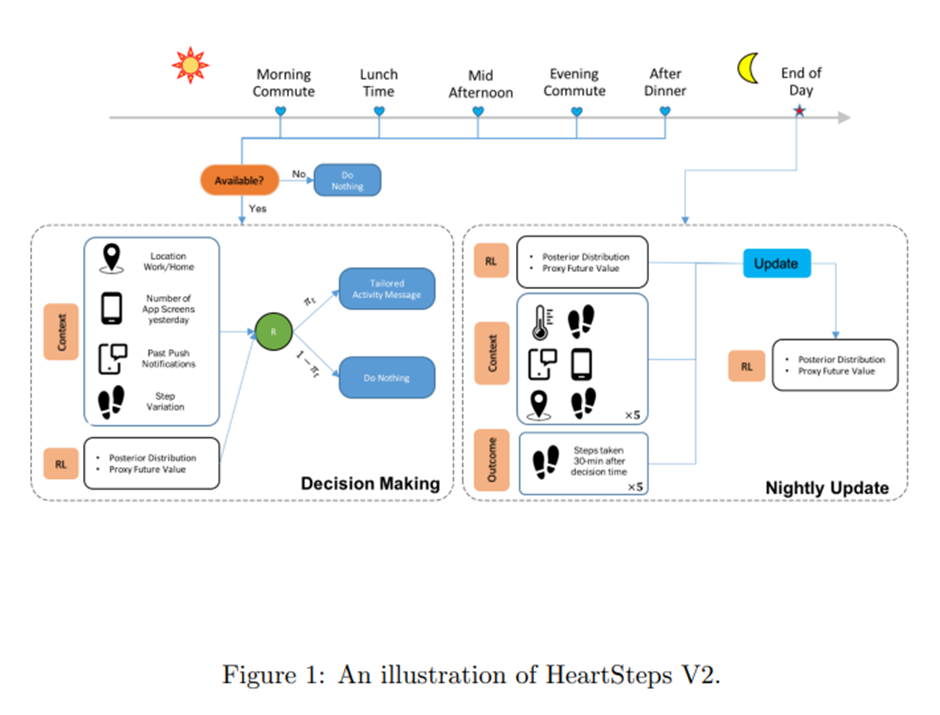
5 HeartSteps V2의 강화학습 알고리즘
5.1 도전 과제 해결 방법
C1: 과거 중재 이력을 기반으로 한 dosage 변수. -> dosage가 큰 컨텍스트로 이동할수록 중재의 즉각적 효과가 감소하고 미래 보상도 낮아지는 경향 보임. 미래보상의 proxy를 만들기 위한 용도.
C2: 저차원 선형 모델 사용해 보상 함수의 행동별 차이 모델링, Thompson Sampling 사용. -> 편향-분산 trade-off에서 학습 속도를 높이기 위해 분산 줄임. TS는 베이즈적 관점에서 탐색-활용 trade-off 조절하는 알고리즘적 아이디어.
C3: action-centering. Baseline 보상 함수 모델 잘못됐을 때 RL 보호하기 위함. 고분산, 비정상 보상 환경에서 사용할 수 있도록 일반화함.
C4: 행동을 TS를 통해 확률적으로 선택. TS가 0이나 1에 너무 가까워지지 않도록 확률 제한.
5.2 Reinforcement Learning Framework
모바일 디바이스를 통해 기록된 참가자의 longitudinal data는 다음과 같은 수열로 나타냄.
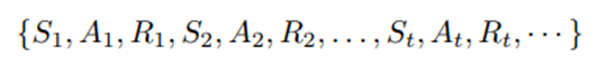
T: 의사결정 시점(하루에 다섯 번)
(l, d): 연구 d번째 날의 l번재 의사결정 시점
A_t: 시점 t에서의 행동 혹은 treatment -> treatment는 binary.
R_t: 행동 A_t 이후에 수집되는 즉작적 보상 -> 의사결정 시점 30분 후에 수집된 걸음 수에 로그 변환을 취한 값
S_t: 시점 t에서의 state vector
I_t: A_t=0만이 실행 가능하거나 윤리적으로 허용 가능한 시간 나타냄(센서가 참가자가 차량 운전 중일 수 있다고 하면 제안은 보내지 말아야 함).
Z_t: 시점 t에서 현재 컨텍스트를 표현하는데 사용되는 feature(현재 위치, 직전 30분간 걸음 수, 어제의 일일 걸음 수, 현재 기온, 그리고 지난 일주일 동안 현재 의사결정 시점 주변에서 참가자가 얼마나 활동적이었는지).
X_t: 참가자의 치료 이력을 바탕으로 정의되는 치료 부담에 대한 proxy 포착하는 dosage 변수.
V2에서는 V1과 다르게 추가적으로 anti-sedentary 제안이 제공됨. 활동 제안에 더해 부담을 유발할 수 있으므로 dosage 정의할 때 포함됨.
RL 알고리즘:
(1) 야간 업데이트
(2) 행동을 선택하기 위한 확률 π(l,d). A(l,d)는 확률 π_(l,d)를 갖는 베르누이 분포에서 샘플링됨.
HeartSteps V2 RL 알고리즘의 의사 코드.
5.3 행동 선택
보상함수는

로 주어짐. 특징 벡터 f(s)는 도메인 과학과 V1을 이용한 데이터 분석에 기반해 선택됨. D번째 날의 I번째 의사결정 시점에서 availability 확인(I(l,d)=1). S(l,d)=s 이고 dosage 변수 X(l,d)=x 일 때, A(l,d)는
The term ηd(x) proxies the long-term, negative effect of delivering the activity suggestion at the moment given the current dosage level Xl,d = x (see the detailed formulation of ηd in section 5.4.2).
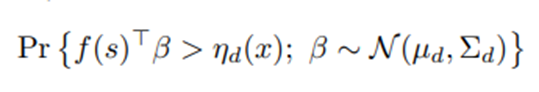
에 따라 선택됨. 확률변수 β는 정규분포 따름. 이전 날의 끝에서 얻어진 모수에 대한 사후분포. μ_d (x)는 현태 dosage 수준에서 지금 활동을 제공하는 것의 장기적 부정적 효과를 proxy하는 역할. μ_d (x)=0일 때 bandit formulation을 복원. -> 행동은 미래 보상에 대한 영향을 무시하고 즉각적 보상을 최대화하도록 선택됨.
활동 제안을 보내는 확률 μ_(l,d) 는
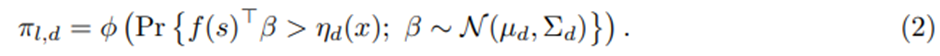
와 같은 clipped 버전임.

5.4 야간 업데이트
즉각적인 치료 효과에 대한 β의 사후분호와 지연효과에 대한 proxy는 매일 하루가 끝날 때 업데이트 됨. 야간 업데이트는
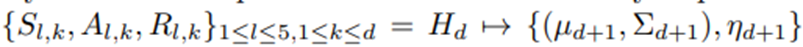
와 같은 mapping임. d일차까지의 현재 이력 H_d를 입력으로 받아 사후분포와 지연 효과의 proxy를 출력, 이 값들은 다음 날 동안의 행동 선택에 사용.
5.4.1 즉각적 치료 효과의 사후분포 업데이트
치료 효과에 대한 사후 분포를 유도하기 위해 보상에 대해 선형 베이지안 회귀 working model 사용.
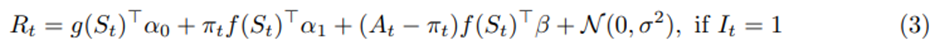
보상 함수에 대한 working model은
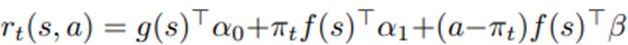
임.
여기서 baseline 특성 벡터 g(s)는 baseline 보상 함수를 근사하기 위해 사용됨.

G(s)는 도메인 지식과 V1을 이용한 데이터 분석에 기반해 선택됨.
식(3)에서 π_t를 이용하는 것은 비정상적이지만, 장점이 있음. Working model (3)에서 행동 중심 항인 (A_t- π_t)는 치료 효과 모형 (1)이 올바르게 지정되어 있기만 하면 baseline 보상 모형 (4)가 잘못되어 있더라도 (3)에 기반한 β의 추정치는 unbiased 하다는 것이 보장됨. -> action centering을 사용해서 (4)의 mis-specification에 대해 견고성 달성, C3 해결.
(3)에 π_t f(S_t): action-centered항으로 인해 발생하는 main effect의 시간 가변적 측변을 포착하기 위해(π_t는 연구가 진행되는 동안 계속 업데이트됨) 포함. 이 항을 포함하면 treatment 효과 추정치의 분산을 줄이고, 학습 속도를 높임.
(1)이 잘못된 경우(treatment effect가 f(S_t)에 대해 비선형이거나 시간이 지나면서 β가 변하는 time non-stationary인 경우 베이지안 회귀가 treatment effect에 대한 선형 근사를 제공.
사전분포는 서로 독립임.
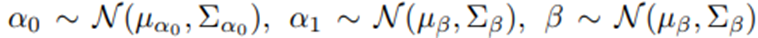
-> 사전 분포가 가우시안이고 (3)의 오차항이 가우시안이기 때문에 현재 이력 H_d가 주어졌을 때 β의 사후분포도 가우시안이 됨.
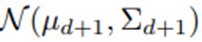
모든 모수에 대한 사후분포 계산.
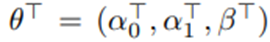
라고 두면 θ의 사후분포를 구하고 β의 사후분포를 식별할 수 있음.
현재 이력
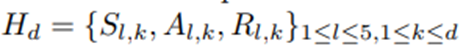
가 주어졌을 때 θ의 사후분포는
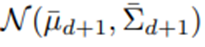
로 나타냄.
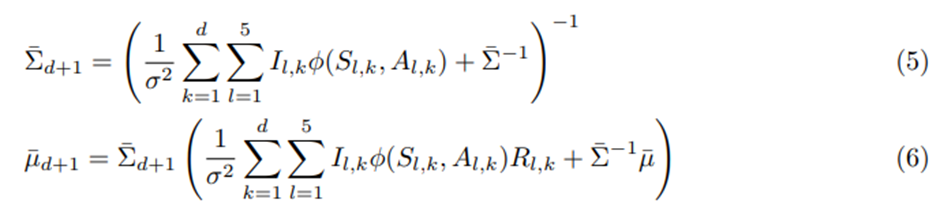
여기서
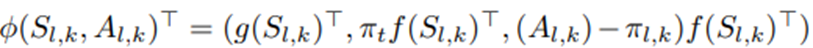
는 결합 특성 벡터를 나타내고, (μ ̅,Σ ̅)는 θ̅의 사전 평균과 분산.
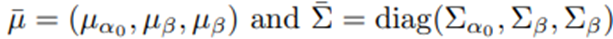
F(s)의 차원이 p라고 하면 β의 사후 평균 μ(d+1)은 위 μ ̅(d+1)의 마지막 p개 원소가 되고, β의 사후분산 Σ(d+1)은 Σ ̅(d+1)의 오른쪽 아래 p x p 블록 행렬이 됨.
5.4.2 미래 보상에 대한 지연 효과의 proxy
Proxy는 상태 S_t=(Z_t,I_t,X_t)에 대한 단순 MD를 기반으로 구성.
가정:
(S1) 컨텍스트 {Z_t}는 분포 F를 따르는 i.i.d(각 값이 서로 독립적, 동일한 확률분포에서 나옴).
(S2) 이용 가능성 {I_t}는 확률 p_avail을 갖는 i.i.d.
(S3) dosage 변수 {X_t}는 전이 확률 τ(x^' |x,a)에 따라 전이함.
(S4) S_t=s,A_t=a일 때 평균 보상은 r(s, a)임.
이 단순 MDP로 Treatment를 보내는 것이 미래 보상에 미치는 지연 효과 포착. 행동은 오직 dosage를 통해서만 미래 보상에 영향, 컨텍스트는 행동과 독립이라고 가정. -> 현재 dosage에 기반해 치료의 지연 효과를 추정할 수 있게 됨.
i.i.d. 가정은 컨텍스트와 이용 가능성에 대한 전이 모형까지 학습할 필요가 없어서 지연 효과에 대한 추정량의 분산을 감소시키는 효과.
- 평균 사전 이용 가능성
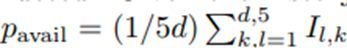
- {Z_(l,k)}에 대한 경험적 분포
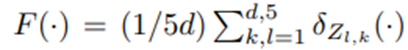
델타는 Dirac measure
- 이용 가능한 의사결정 시점에서의 보상 함수
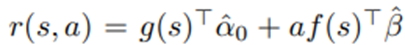
α ̂_0,β̂은 모형 (3)에 기반한 사후 평균.
이용 불가능한 의사결정 시점의 평균 보상은 같은 형태를 갖지만, H_d 내의 이용 불가능 시간점들만 사용한 유사한 선형 베이지안 회귀로부터 얻은 사후 평균을 이용.
psed는 이전 의사결정 시점에서 활동 제안이 보내지지 않았을 때(A(t-1)=0일 때), 그 이후 의사결정 시점 사이에 어떤 anti-sedentary 제안이든 전달될 확률. 0.2로 설정. -> 하루동안 12시간 윈도우에서 평균적으로 1개의 anti-sedentary 제안이 균일하게 배치되도록 계획된 스케쥴링에 기반한 값.
τ(x^' |x,a)는
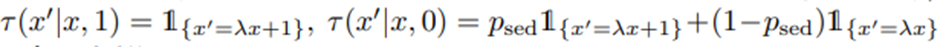
와 같이 주어짐. λ=0.95.
이렇게 구성된 MDP를 기반으로 지연효과의 proxy를 다음과 같이 구성.
상태 S = (Z, I, X)에서 이용 가능한 경우(I = 1)에는 상태 S에서 행동 π(S)를 선택하고, 그렇지 않은 경우에는 행동 0을 선택하는 임의의 정책 π를 고려. 할인율 γ하에서 정책 π의 상태-행동 가치함수는
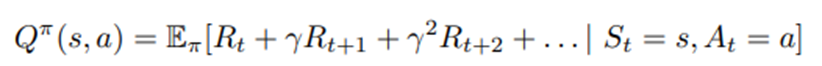
임. 아래첨자 π는 (A(t+1),A(t+2),…)가 정책 π에 따라 선택됨을 의미.
상태 가치 함수는
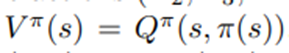
임. 가치 함수 Q^π는
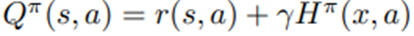
임. R(s,a)는 (S4)에서 정의된 기대 보상이고,
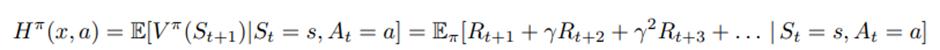
는 미래 할인 보상의 합(미래가치)임. H^π (x,a)는 첫 번째 즉각 보상 R_t를 제외하고, 가정 (S1), (S2) 하에서는 (x,a)에만 의존하는 함수가 됨.
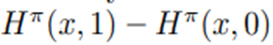
는 정책 π에 따라 미래 행동이 선택될 때, dosage x에서 치료를 보내는 것이 미래 보상에 미치는 영향을 측정함.
우리는 정책 π가 dosage와 이용 가능성에만 의존한다는 제약 하에서 미래 가치를 최대화하도록 π를 선택함.
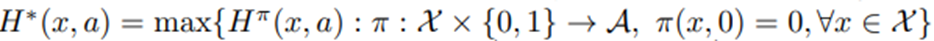
로 정의하면 H^*은
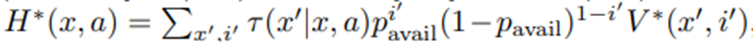
과 같이 주어짐. 이변량 함수(bivariate function) V^*:X×{0,1}→R은
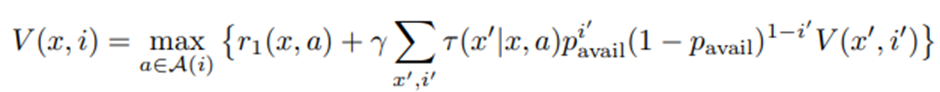
을 만족하는 함수임. 여기서 A(i)는 이용 가능성에 따른 제약된 행동 공간으로, A(1) = {0, 1}, A(0) = {0}임. r_0,r_1 (x,a)은 dosage 변수에만 의존하는 marginal 보상 함수임.
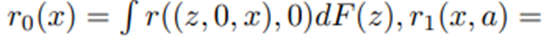
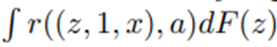
지연효과에 대한 proxy는
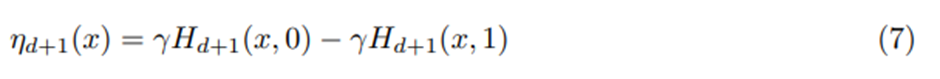
와 같이 계산됨. 여기서
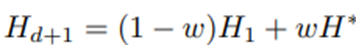
는 추정된 H^*과 V1 데이터만을 사용해서 계산된 초기 함수 H_1의 가중 평균.
지연효과는 아무것도 보내지 않는 경우와 활동 제안을 보내는 경우 사이읭 lafo 할인 보상의 평균 차이. (2)에서 의사결정 시점 t에서의 행동 A_t가 사실상
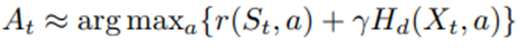
을 최대화하도록 선택됨.
5.5 Choosing Inputs
V2 RL 알고리즘에 의해 필요로 되는 입력과 각 입력이 V1에서 수집된 데이터를 바탕으로 어떻게 선택되는가?
확률 클리핑 값: 0.2, 0.1
Dosage: λ=0.95 -> 람다가 클 때 dosage는 활동 제안이 그 이후 30분간 걸음수에 미치는 효과에 유의미한 영향.
F(s), g(s): V1 데이터를 사용한 GEE 결과에 기반해 선택.
각 feature를 marginal GEE에 넣음. -> P-value 계산. -> 유의수준 0.05에서 유의한 특성이 g(s), f(s)에 포함(의사결정 직전의 30분 걸음 수는 보상을 잘 예측하지만 treatment효과 예측 유의하지 않음. 직전 30분 걸음수는 g(s)에는 포함되지만 f(s)에는 포함 안됨).
식 (1)에서 f(s)에는 dosage, 앱 참여, 위치, 과거 7일동안 현재 시간대 주변 60분의 걸음 수 변동 수준
G(s)에는 추가로 직전 30분 걸음수, 어제의 총 걸음수, 현재 기온
노이즈 분산: 알고리즘 안정성을 보장하기 위해 V1 데이터를 사용해 설정하고 업데이트 안함.
사전 분포: V1 분석 결과를 기반으로 구성. 사전 분산 형성하기 위해 각 참가자에 대해 개별 GEE 선형 회귀 모형을 적합학도 37명 참가자 모형에서 나온 점추정치들의 표준편차 계산. (1) 모든 참가자 데이터를 사용한 GEE 분석에서 유의한 특성에 대해서는 사전 평균을 그 GEE 분석의 점추정치로 설정하고, 사전 표준편차는 참가자별 GEE 분석에서 얻은 점추정치들의 표준편차로 설정. (2) 유의하지 않은 특성에 대해서는 해당 사전 평균을 0으로 설정하고 표준편차는 위에서 구한 표준편차의 절반으로 축소. (3) 앱 참여 변수는 사전 평균을 0으로 설정하고 사전 표준편차를 다른 특성들의 사전 표준편차 평균으로 설정.
초기 proxy value 추정치 H_1: MDP 구성 방식과 동일하지만 이용 가능성의 경험적 확률, 컨텍스트의 경험적 분포, 보상 함수는 V1 데이터를 이용해 구성.
할인율 γ와 업데이트 가중치 모수 w(튜닝 파라미터): 직접 지정하기 어려우므로 시뮬레이션 기반 절차를 통해 선택할 것을 제안.
6 시뮬레이션 연구
V1 데이터를 이용해 시뮬레이션 연구 수행.
Three-fold cross validation: V1 데이터셋을 세 개의 폴드로 분할 -> 세 번의 iteration에서 두 개는 학습, 하나는 테스트 batch. 학습 batch는 사전분포 구성, 노이즈 분산 추정, 튜닝 파라미터 선택하는 데 사용(training phase). 테스트 batch는 알고리즘을 테스트하기 위한 시뮬레이션 환경을 구성하는 데 사용(추정된 노이즈 분산, 사전분포, 튜닝 파라미터 포함).
Thompson Sampling Bandit 알고리즘과 성능 비교: 각 의사결정 시점에서 즉각적 보상을 최대화하는 것을 목표로 보상의 사후분포에 따라 확률적으로 행동 선택. 확률적 알고리즘, C4로 인해 다른 알고리즘보다 적합함.
TS Bandit은 즉각적 보상만을 최대화하는 행동 선택을 시도하지만 우리 알고리즘은 C1을 감안해서 장기 보상에 미치는 영향까지 고려함. TS는 각 arm에 대한 모형이 올바르게 지저되어야 하지만 우리는 action-centering을 사용해 treatment effect 모형(1)만 올바르게 지정되면 되도록 요구사항 완화.
6.1 Training Phase
사전분포 알고리즘: (1) 이용 가능한 시간에서의 메인 효과 모수에 대한 사전, (2) treatment effect 모수에 대한 사전, (3) 이용 불가능한 시간에서의 평균 보상 모수에 대한 사전 필요.
1. 학습 배치에서 모든 참가자 데이터를 사용해 GEE를 적합(population GEE).
-
population GEE에서 유의한 모수에 대해서 사전 평균을 population GEE의 점추정치로 설정. 유의하지 않은 경우, 사전 평균을 0으로 설정.
-
population GEE에서 유의한 모수에 대해서 사전 표준편차를 학습 배치 참가자들에 대한 개인별(person-specific) 추정치의 표준편차로 설정. 유의하지 않은 경우, 사전 표준편차를 그 표준편차의 절반으로 설정.
-
모수에 대한 사전 분산 행렬은 대각행렬로 설정.
노이즈 분산(Noise variance) 노이즈 분산은 위의 population GEE에서 얻은 잔차들의 분산으로 설정.
초기 proxy 구성: (1) 학습 배치의 경험적 분포, (2) 학습 배치의 경험적 이용 가능성 확률, (3) dosage 전이에서 p_sed = 0.2, (4) population GEE에서 얻은 보상 추정치 사용.
튜닝 파라미터: (γ,w), 각각 proxy value 정의에서의 할인율과 추정된 proxy value를 형성할 때 사용되는 업데이트 가중치.
생성 모형 구성 방법:
참가자 i에 대해 90일 길이의 컨텍스트, 이용 가능성, 잔차 시퀀스
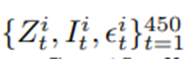
구성. 42일 길이의
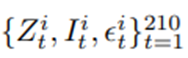
구성. 잔차는 개인별 회귀모형을 적합해서 얻음. 90일 길이를 만들기 위해 42일 데이터에서 무작위로 선택한 (90-42)일 분량의 데이터 이어붙임. {1, …, 42}에서 무작위로 하루 d를 선택하고 그날의 모든 데이터를 원래 42일 시퀀스 뒤에 붙이는 과정 반복.
참가자 i에 대한 생성 모형:
-
확률 0.2로 이진변수 B_t를 무작위로 생성. 시점 t-1과 t 사이에 어떤 anti-sedentary 제안이든 전송되었는지 나타내는 indicator.
-
현재 dosage를
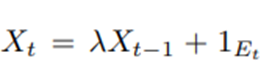
로 설정.
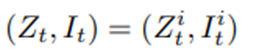
로 둠.
-
식 (2)에 따라 행동 A_t 선택.
-
보상 R_t는
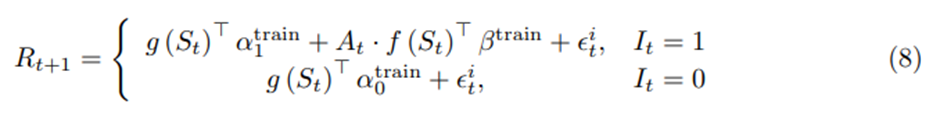
과 같이 정의되는 R_(t+1)로 받음.
주어진 후보 튜닝 파라미터 값과, 위에서 구성된 노이즈 분산 및 사전분포를 함께 사용해서 알고리즘을 각 학습 참가자의 생성 모형 하에서 96번씩 실행.
Grid search 수행 결과 선택된 튜닝 파라미터는 (0.9, 0.5), (0.9, 0.75), (0.9, 0.1).
6.2 Testing Phase
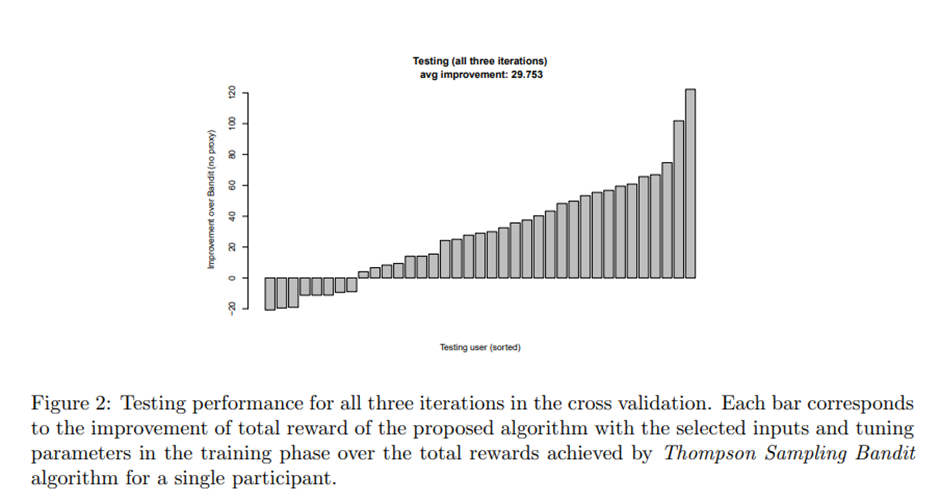
TS 성능. 37명 중 29명에서 TS보다 우리 알고리즘보다 더 높은 총 보상. TS 대비 평균 향상값: 29.753.
7 HeartSteps V2 파일럿 데이터
HeartSteps V2는 2019년 6월부터 실제 현장(field)에 배포되어 옴.
7.1 초기 평가
현재 현장에서 연구에 참여 중인 사람들 중, 1주 이상 연구에 참여하여 RL 알고리즘을 실제로 경험하고 있는 참가자는 총 8명. 각 참가자에 대해, 첫 주 동안의 각 사용자가 지정한 의사결정 시점 이후 30분 동안의 평균 걸음 수를 계산하고, 이후 활동 제안이 제공되는 주차들의 평균 30분 걸음 수와 비교함.
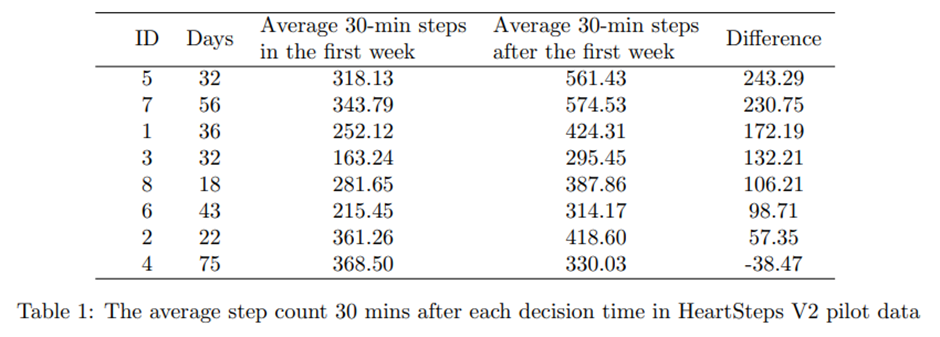
HeartSteps V2 파일럿 데이터에서 각 의사결정 시점 이후 30분간의 평균 걸음 수.
참가자 4번(ID = 4)을 제외하고 모두 걸음 수 증가. 약 125걸음.
7.2 교훈
참가자 ID=4와 ID=7.
ID=4는 첫 번째 주 이후 걸음 수 감소.
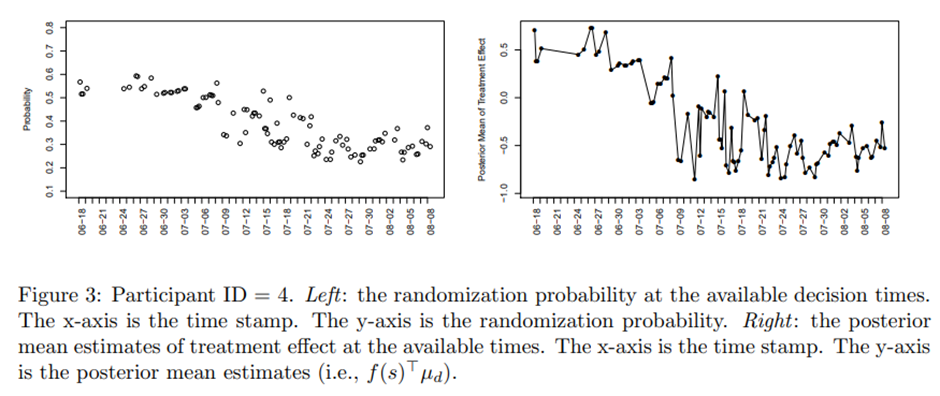
ID=4의 무작위화 확률과 사후 평균 추정치. 사후 평균 추정치가 양의 값으로 시작해서 0 아래로 떨어짐(제안의 효과가 없음). 무작위화 확률은 여전히 0.2와 0.4 사이에 있음.
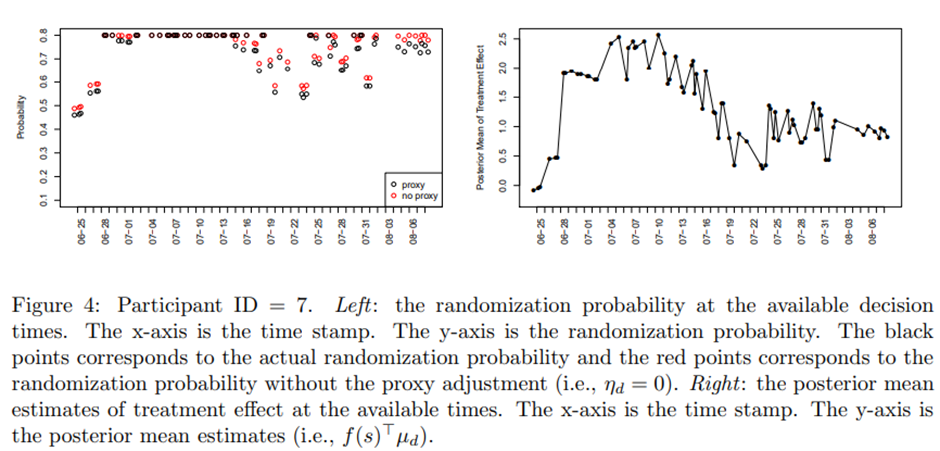
ID = 7의 treatment effect의 사후 평균 그래프. 오른쪽 그래프에서 보면 반응성은 07-10 무렵부터 감소. 왼쪽 그래프 보면 무작위화 확률은 07-16이 되어서야 실제로 감소하기 시작. 이상적으로는 proxy 값이 과도한 dosage에 더 빠르게 반응해서 확률이 감소해야함을 신호해야 함.
Proxy 값에는 개선 필요.
그림 4의 왼쪽 그래프에서 실제 무작위화 확률에 해당하는 검은 점들과, proxy 조정이 없는 무작위화 확률에 해당하는 빨간 점들을 비교했을 때 이상적으로는 07-16부터 07-15 사이 구간에서 검은 점과 빨간 점 사이의 차이가 더 크게 나타나길 기대함.
알고리즘 수정 중임.
8 결론 및 향후 연구
HeartSteps V2에서 사용하기 위한 강화학습 알고리즘을 개발함.
V1 기반 시뮬레이션에서 TS보다 좋은 성능.
향후 연구 방향:
-
지금은 각 참가자에 대해 개인화됨. 연구 참가자들 사이에 유사성 있으면 다른 참가자의 정보를 함께 활용 가능.
-
dosage 변수가 미리 정의됨. Burden의 더 정교한 측정치나 참여도 활용해서 지연 효과 근사하고 더 빠르게 이탈을 방지하는 버전 개발 가능.
-
사용자 참여도와 부담 고려할 때 알고리즘 개입의 효과에 대한 충분한 증거 확보하지 못한 경우에는 개입 확률 낮추는 것이 합리적일 것.
