LLMs + Persona-Plug = Personalized LLMs Jiongnan Liu1 , Yutao Zhu1 , Shuting Wang1 , Xiaochi Wei3 Erxue Min3 , Yu Lu3 , Shuaiqiang Wang3 , Dawei Yin3 , Zhicheng Dou1,2 1Gaoling School of Artificial Intelligence, Renmin University of China 2Engineering Research Center of Next-Generation Intelligent Search and Recommendation, MOE 3Baidu Inc. liujn@ruc.edu.cn, yutaozhu94@gmail.com, dou@ruc.edu.cn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) July, 2025
1 서론
LLM은 사용자별 선호 고려하지 못함.
개인화 LLM 구축하는 가장 직관적인 전략은 개별 사용자 데이터로 특정 LLM을 파인튜닝하여, 각 사용자의 고유한 패턴과 선호를 학습하게 하는 것. -> 계산 자원 많이 필요하고, 데이터 부족하면 성능 저하.
사용자 이력을 LLM에 입력하고 사용자 요청에 따라 맞춤형 결과 생성하는 방법. -> LLM의 최대 입력 길이에 제한 받음. -> 검색 모델 활용하자! -> 현재 입력과의 관련성에 초점을 맞춰서 종합적인 행동 양식 포착에 방해될 수도 있음.
-> 구조나 파라미터를 수정하지 않고 사용자의 전체적인 스타일을 LLM에 plug하는 것.
제안: persona-plug(PPlug). 경량의 플러그인 사용자 임베더 모듈을 포함하고, 이 모듈은 사용자의 과거 행동 패턴을 하나의 사용자별 임베딩으로 인코딩하여 LLM의 입력으로 참조할 수 있게 함.
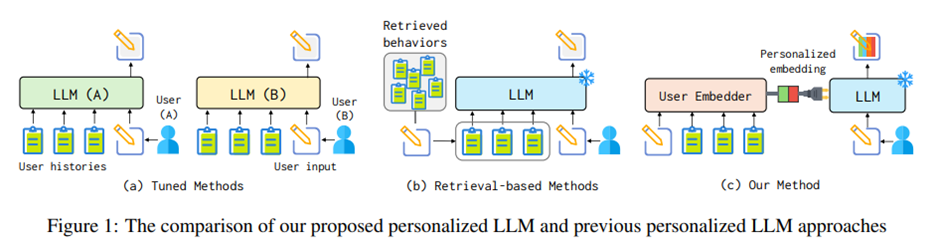
사용자 과거 행동을 밀집 벡터로 표현 -> 사용자별 개인 임베딩 생성 -> 현재 입력에 부착해서 frozen LLM이 사용자 선호에 맞게 출력하도록 함. -> plug-and-play 전략 하에 추출된 사용자의 포괄적인 개인 패턴에 의존해서 개인화 과제 더 잘 수행할 수 있음. end-to-end 방식으로 모델 최적화 가능.
2 관련 연구
파인튜닝된 개인화된 LLM. 파라미터 효율적 파인튜닝(PEFT) 기법을 통해 LLM 조정.
검색 기반 개인화된 LLM. Salemi et al.(2024a)은 LLM이 생성한 출력에 기반해 계산된 보상을 사용해 검색 모델을 최적화.
3 방법론
플러그인 사용자 임베더 모듈을 갖춘 persona-plug(PPlug)라는 LLM 개인화 방법 제안.
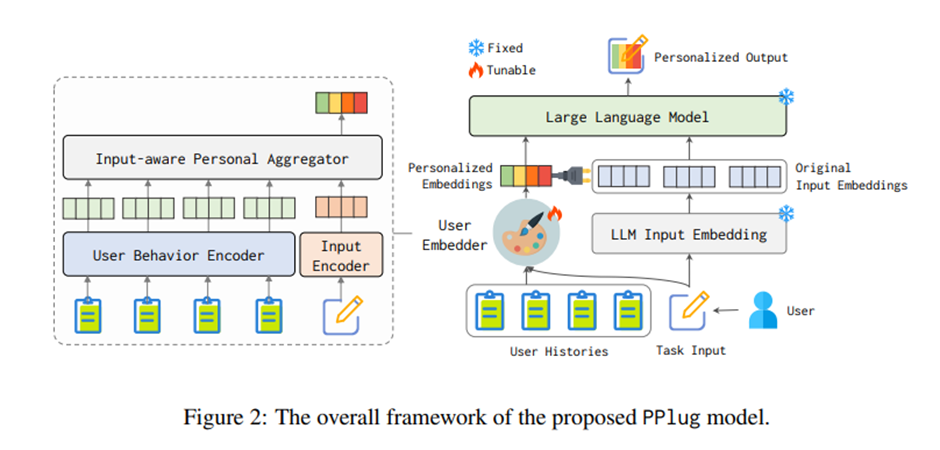
PPlug 방법 전체 개요.
3.1 사용자 행동 인코더
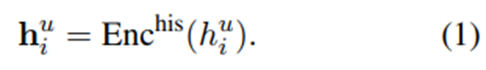
사용자 과거 행동.
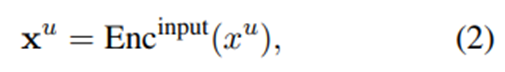
현재 사용자 입력. Enc^input (⋅)은 개인화된 상품 리뷰와 같이 사용자의 현재 입력에 특화된 인코더. Enc^his 파라미터는 고정, Enc^input만 파인튜닝.
소형 인코더 기반 모델 선택 이유: 양방향 어텐션은 사용자 행동 내 모든 토큰 간의 상호작용을 효과적으로 포착할 수 있음, 경량 인코더는 PPlug 모델에서 최적화와 추론 모두의 효율성을 향상시킴.
3.2 입력 인식 개인 집계기(Input-aware Personal Aggregator)
사용자 과거 행동과 현재 입력을 종합해서 하나의 포괄적인 개인 임베딩으로 집계. -> 과제 성능을 높이려면 현재 입력과 더 관련 있는 과거 행동들에 더 높은 가중치 부여. -> 현재 사용자 입력과의 관련성에 기반해 각 과거 행동에 동적으로 가중치를 부여하는 어텐션 메커니즘 고안.
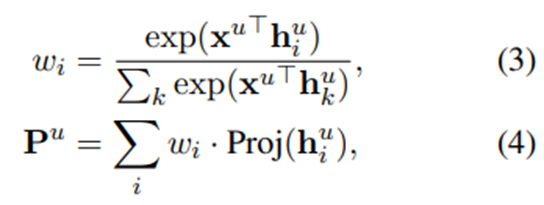
개인 임베딩 계산.
Proj(⋅)은 2층 MLP를 통해 사용자 임베딩을 인코더 공간에서 LLM 표현 공간으로 project, P^u는 계산된 개인 임베딩.
PPlug는 검색 기반 전략에서 검색 조작을 모사해서 LLM이 과거 관련 행동에 더 주의 기울이도록.
3.3 LLM 개인화를 위한 PPlug
개인 임베딩을 입력으로 출력 생성.
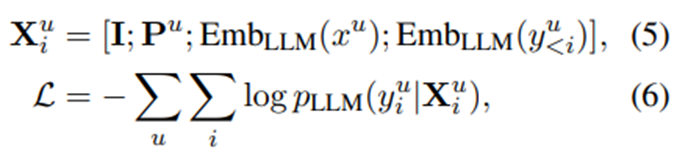
I는 instruction embedding(텍스트 대신 벡터로 과제 정보 전달).
사용자 현재 입력 x^u와 이전에 생성된 개인화 콘텐츠 y_(<i)^u가 주어졌을 때 next token prediction loss.
Emb_LLM (⋅)은 LLM의 임베딩 레이어, p_LLM은 예측된 토큰 분포. 학습 가능한 instruction 임베딩 |. -> 지시 임베딩 포함하면 LLM 성능 굿!
LLM은 고정, 지시 임베딩, 입력 인코더, 프로젝터만 튜닝.
3.4 기존 모델과의 비교
PPlug vs. Fine-tuned Methods PPlug는 (1) 학습 측면에서, 사용자별 제한된 데이터에 의존해 사용자마다 별도의 LLM을 학습해야 하는 파인튜닝 방법과 달리 모든 데이터를 활용해 개인화 사용자 정보를 포착하는 공유 인코더를 학습하므로 더 효율적이고 효과적임, (2) 추론 측면에서, PPlug는 plug-and-play 방식으로 동작해서 LLM 서비스 제공자에게 인프라와 유지보수를 단순화함.
PPlug vs. Retrieval-based Methods PPlug는 모든 행동에 동적 가중치 부여, 사용자 이력을 기록할 필요 없이 임베딩만 활용.
4 실험
4.1 데이터셋과 평가 지표
데이터셋 Language Model Personalization(LaMP) 벤치마크 사용. 7개의 서로 다른 개인화 과제로 구성됨. 공개되지 않은 Personalized Email Subject Generation 과제(LaMP-6)를 제외하고 6개 과제에서 모델 성능 평가.
개인화 텍스트 분류 3개 과제: (1) LaMP-1 개인화 인용 식별(Personalized Citation Identification), (2) LaMP-2 개인화 영화 태깅(Personalized Movie Tagging), (3) LaMP-3 개인화 상품 평점(Personalized Product Rating)
개인화 텍스트 생성 3개 과제: (4) LaMP-4 개인화 뉴스 헤드라인 생성(Personalized News Headline Generation), (5) LaMP-5 개인화 학술 제목 생성(Personalized Scholarly Title Generation), (6) LaMP-7 개인화 트윗 패러프레이징(Personalized Tweet Paraphrasing)
LaMP 벤치마크가 제공하는 시간 기반 데이터셋을 사용, 각 사용자 데이터는 시간 순서대로 학습(train), 검증(validation), 테스트(test)로 분할. 자세한 건 부록 A.
Evaluation Metrics LaMP 벤치마크의 기본 지표: LaMP-1은 정확도(accuracy), LaMP-2는 정확도와 F1-측정치(F1-measure), LaMP-3는 평균 절대 오차(MAE)와 평균 제곱근 오차(RMSE), LaMP-4, LaMP-5, LaMP-7은 ROUGE-1과 ROUGE-L(Lin, 2004)
4.2 구현 세부사항
기본 LLM: FlanT5-XXL(11B), 256 토큰.
기본 history와 입력 인코더: BGE-base-en-v1.5, 512 토큰.
빔 서치(4), LaMP-3을 제외한 모든 과제에서 2 에포크 학습, 3은 데이터셋 크기 커서 1 에포크. 배치 64. 코드는 https://github.com/rucliujn/PPlug.
4.3 베이스라인
PPlug 모델을 네 가지 유형의 접근법을 포괄하는 베이스라인과 비교.
(1) 임시방편(ad-hoc) 방법: FlanT5-XXL을 사용해 원래 과제 입력만을 기반으로 출력을 생성, 비개인화(non-personalized) 베이스라인 역할.
(2) 파인튜닝 기반 개인화 방법들(FTP): PPlug와 동일한 평가 설정에서 Salemi and Zamani(2024)에 보고된 PEFT 개인화 결과를 그대로 복사해 사용. -> 검증 결과 없이 테스트 결과만 포함.
(3) 단순 검색 기반 개인화 방법(Naive RBP): BM25(Robertson and Zaragoza, 2009), Recency, Contriever(Izacard et al., 2021) 방법을 사용해 사용자 과거 행동 중 상위 4개를 검색하고 FlanT5-XXL에 데모로 제공해 개인화된 출력 생성.
(4) 최적화된 검색 기반 개인화(Optimized RBP): ROPG-RL, ROPG-KD, RSPG-Pre, RSPG-Post: Salemi et al.(2024a)이 설계한 네 가지 베이스라인 방법. ROPG-RL과 ROPG-KD는 평가 지표에 따라 강화학습과 지식 증류 전략을 사용해 Contriever 기반 검색 모델 최적화, RSPG-Pre와 RSPG-Post는 여러 후보 검색 모델 중에서 각각 과제 입력과 모델 출력에 기반해 최적의 검색 모델을 선택하는 검색 선택 모듈 도입.
4.4 실험 결과
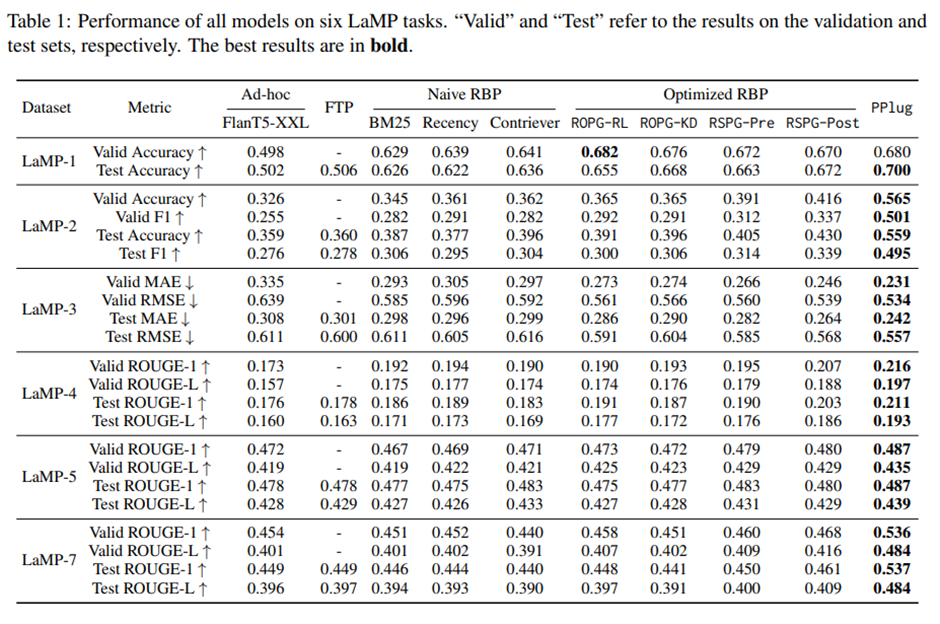
검증 세트와 테스트 세트에서의 결과. 전반적으로 PPlug는 가장 뛰어난 성능, 개인화 과제에서 우수함.
(1) 파인튜닝 기반 개인화 방법(FTP)은 비개인화 방법(ad-hoc)에 비해 개선 폭 미미. History가 적어서.
(2) 검색 기반 방법(RBP)과 PPlug는 모두 더 나은 성능. 사용자 과거 행동을 통합하는 것이 사용자 개인 선호를 포착하는 데 효과적임.
(3) 단순 RBP에 비해 최적화된 RBP가 더 나은 성능. 단순 RBP의 검색기가 개인화 생성 과제에 맞게 최적화되지 않았고, LLM 출력으로부터의 피드백을 활용해 검색기를 튜닝하는 것이 개인화 과제에 유리함.
(4) PPlug는 거의 모든 과제에서 모든 베이스라인 능가.
(5) FTP 방법들과 비교했을 때, PPlug 모델은 각 사용자의 제한된 데이터가 아니라 모든 사용자의 데이터를 활용할 수 있어 더 효과적. 강화학습과 지식 증류를 활용해 모델을 최적화하는 ROPG와 RSPG에 비해 end-to-end 방식이 더 효율적.
4.5 추가 분석
PPlug 방법을 분석하기 위해 추가 실험. 검증 세트에서의 결과 보고.
LLM and Encoder Analysis 기본 설정에서는 FlanT5-XXL과 BGE-base를 각각 LLM과 인코더로 사용. 최종 성능에 미치는 영향을 살펴보기 위해, 다른 모델들로 교체한 추가 실험.
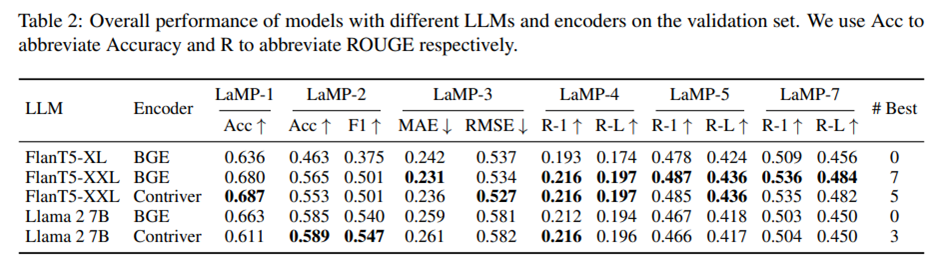
(1) FlanT5-XXL을 backbone LLM으로 사용할 때, BGE-base와 Contriever를 각각 사용한 PPlug는 서로 유사한 성능을 보이고 두 경우 모두 기존 개인화 방법들을 유의미하게 능가.
(2) BGE-base 인코더를 사용할 경우, PPlug의 성능은 LLM의 크기와 양의 상관관계. 더 큰 모델일수록 성능 굿.
Ablation Study 두 과제인 LaMP-2와 LaMP-4에서의 결과.
(1) 입력 인식 어텐션의 영향: 입력 인식 개인 집계기를 제거하고, 각 과거 행동 표현의 평균을 내어 개인 임베딩을 요약.
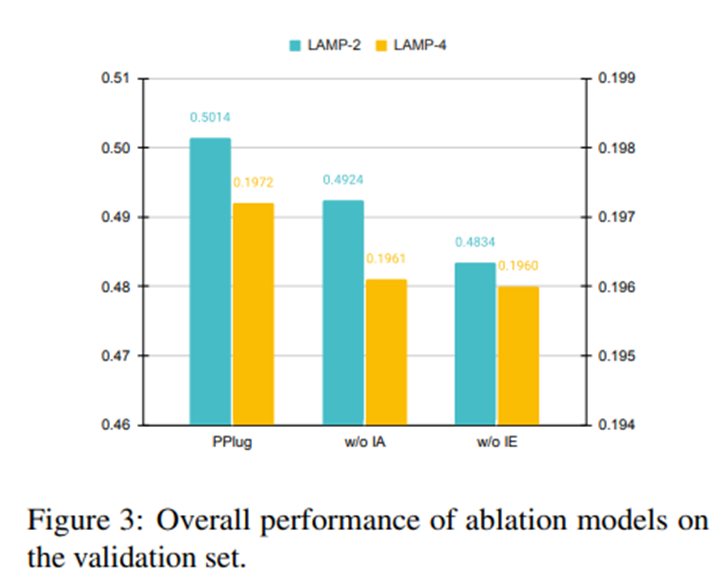
입력 인식 개인 집계기 없는 모델은 완전한 PPlug보다 성능이 낮음. -> 입력 인식 집계기가 현재 입력에 맞추어 사용자 패턴을 더 잘 포착할 수 있음. -> 여전히 베이스라인들에 비해 강함. -> 사용자의 전반적인 행동 패턴 자체가 개인화된 언어 생성에서 매우 중요함.
(2) 지시 임베딩의 영향: 식 (5)에서 LLM 입력에 포함된 지시 임베딩 [I]를 제거. 베이스라인 능가. -> PPlug의 주요 성능 향상이 사용자 이력으로부터 얻은 개인 임베딩에서 비롯됨.
Integration with Retrieval-based Strategy PPlug 방법을 검색 기반 전략과 결합하면 성능을 더 향상시킬 수 있는가?
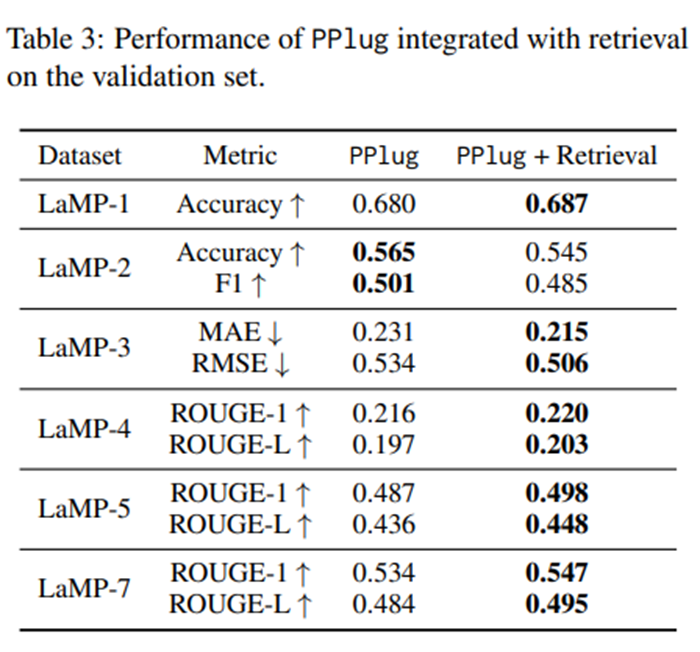
검색 기반 전략을 PPlug 모델과 결합하면 기존 PPlug 방법 대비 추가적인 성능 향상이 나타남. -> PPlug가 사용자 전반의 습관과 선호를 포착하는 거친(grain이 큰) 사용자 스타일 임베딩을 제공하는 반면, 검색 기반 방법은 현재 과제와 직접적으로 관련된 세밀한(fine-grained) 과거 맥락을 제공해 과제 수행에 필요한 지식을 보완해 주기 때문.
History Selection Study 검색 기반 개인화 접근법은 현재 과제 입력과 가장 관련 있는 과거 콘텐츠만을 선택해 LLM의 데모로 사용하고, 이는 모델이 사용자의 더 넓은 관심사를 포착하는 데 방해가 될 수 있음.
가중치에 따라 상위 4개만으로 개인 임베딩 구성. -> PPlug with Selection.
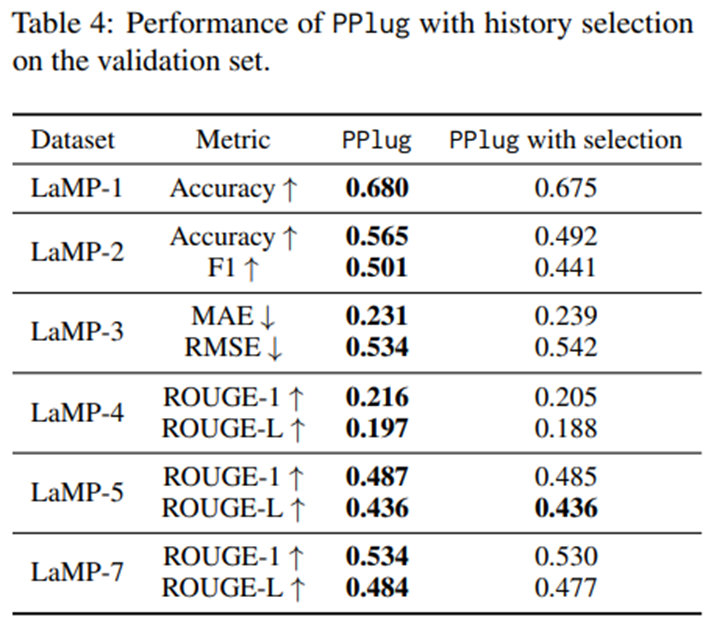
성능 저하됨. 이력을 선택적으로 사용하는 방식이 사용자의 일반적 패턴을 포착하는 능력을 약화시킴.
History Length Impact Study 사용자 history 데이터의 양이 모델 성능에 미치는 영향?
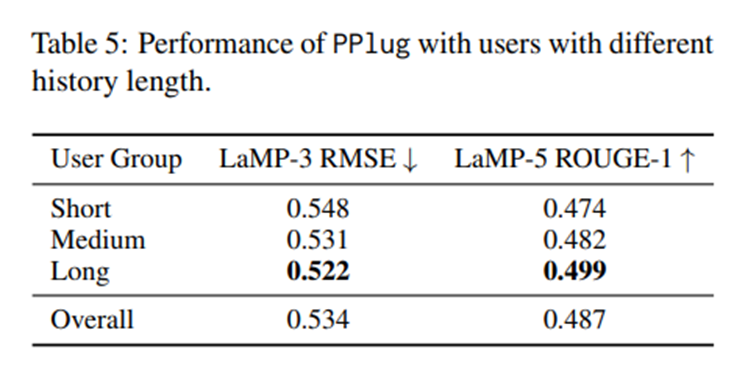
History 길어질수록 성능 향상. But 사용자의 history가 제한적인 경우에도 PPlug가 효과적으로 작동함.
5 결론
persona-plug(PPlug) 모델 제안함.
사용자의 모든 과거 행동을 밀집 벡터로 인코딩 -> 입력 인식 방식으로 하나의 사용자 개인 임베딩으로 집계하는 경량의 plug-and-play 사용자 임베더 모듈 설계
-> LaMP 벤치마크에서의 실험 결과는 제안한 모델이 기존 검색 기반 LLM 모델들을 유의미하게 능가함.
한계: 행동 단위 수준에서 history 표현 -> 자주 사용하는 특정 용어나 구문 미반영
향후 연구: 개인 임베딩에 더 세밀한 단어 수준 정보 보강, 사용자 임베딩을 언제 활용하고, 언제 인컨텍스트로 검색된 참조를 사용할지가 개인화된 LLM 출력에 가장 효과적인지를 체계적으로 연구.
