LaMP: When Large Language Models Meet Personalization Alireza Salemi1 , Sheshera Mysore1 , Michael Bendersky2 , Hamed Zamani1 1University of Massachusetts Amherst 2Google Research {asalemi,smysore,zamani}@cs.umass.edu bemike@google.com The LaMP Benchmark: http://lamp-benchmark.github.io/ Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7370–7392 August 11-16, 2024 [Submitted on 22 Apr 2023 (v1), last revised 5 Jun 2024 (this version, v4)]
1 서론
LLM을 개인화하는 것과 정렬하는 것 지속적인 연구. -> 개인화된 응답을 생성하는 LLM을 개발하고 평가하는 연구는 상대적으로 충분히 이루어지지 않음.
제안: LaMP 벤치마크. 개인화된 텍스트 분류 및 생성 과제를 포괄적이고 다양하게 포함한 벤치마크임. 기존 NLP 벤치마크는 one-size-fits-all 접근이라 개인화에 대한 광범위한 연구 제한적.
LLM 개인화를 위한 두 가지 retrieval augmentation 해법 제안. 1) in-prompt augmentation(IPA), 2) 각 개인 항목을 개별적으로 인코딩해서 Izacard와 Grave(2021)의 fusion-in-decoder 모델을 사용해 디코더 단계에서 통합하는 방식. -> 이를 통해 개인화된 프롬프트 구성을 위한 다양한 검색기를 평가하고, 파인튜닝 및 제로샷 언어 모델에 대한 벤치마크 결과 제시.
2 LaMP 벤치마크
문제 정의. 언어 모델의 개인화는 사용자 프로필로 표현되는 사용자 u에 조건화하여 모델 출력을 생성하는 것으로 정의. LaMP에서는 사용자 프로필을 사용자의 과거 데이터, 즉 사용자가 생성했거나 승인한 과거 입력과 개인화된 출력의 집합으로 정의.
LaMP 벤치마크의 각 데이터 엔트리의 세 가지 구성 요소: 모델 입력으로 사용되는 입력 시퀀스 x, 모델이 생성해야 하는 목표 출력 y, 사용자에 맞게 모델을 개인화하는 데 활용될 수 있는 보조 정보를 담고 있는 사용자 프로필 P_u.
LaMP 개요. 입력과 사용자별 정보를 기반으로 개인화된 출력을 생성하는 LLM의 효율성을 평가하기 위한 LaMP 벤치마크. 출력의 유형에 따라 구성되는 개인화된 텍스트 분류와 텍스트 생성을 아우르는 일곱 가지 과제:
개인화된 텍스트 분류 과제: (1) 개인화된 인용 식별, (2) 개인화된 영화 태깅, (3) 개인화된 상품 평점 예측.
개인화된 텍스트 생성 과제: (4) 개인화된 뉴스 헤드라인 생성, (5) 개인화된 학술 제목 생성, (6) 개인화된 이메일 제목 생성, (7) 개인화된 트윗 패러프레이징.
2.1 과제 정의
상세 내용은 부록 A.
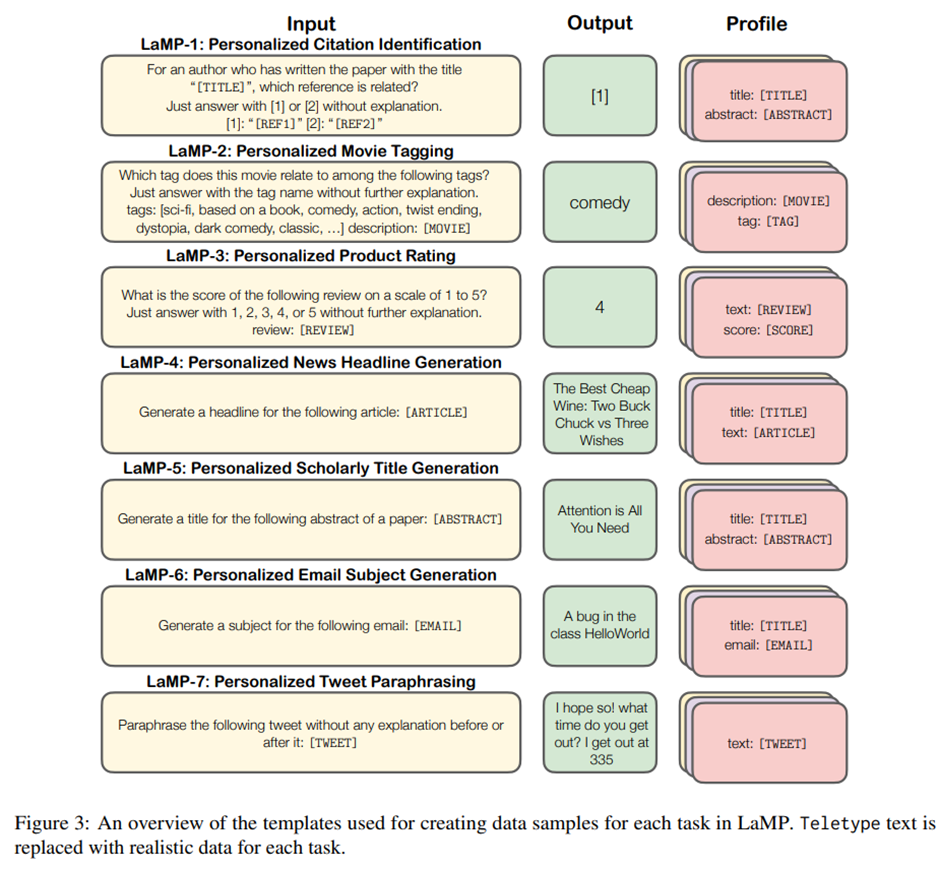
LaMP-1: Personalized Citation Identification: 연구자 과거 논문 이력를 프로필로 사용해 인용 선호를 이진 분류로 예측.
LaMP-2: Personalized Movie Tagging: 사용자의 과거 영화 태깅 행태를 기반으로 새로운 영화에 대한 태그 예측.
LaMP-3: Personalized Product Rating: 사용자 historical review를 활용해 새로운 리뷰에 대한 1-5점 상품 평점을 다중 클래스 분류로 예측.
LaMP-4: Personalized News Headline Generation: 기자의 과거 기사-헤드라인 스타일 반영해서 뉴스 헤드라인 생성.
LaMP-5: Personalized Scholarly Title Generation: 연구자의 과거 논문 제목 스타일 반영해서 학술 논문 제목 생성.
LaMP-6: Personalized Email Subject Generation: 사용자의 과거 이메일-제목 쌍을 기반으로 이메일 제목 생성.
LaMP-7: Personalized Tweet Paraphrasing: 사용자의 과거 트윗 스타일을 반영해서 입력 트윗을 생성.
2.2 Data Splits
일반적인 개인화 설정에서의 평가를 위한 두 가지 다른 데이터 분할 설정: 1) user-based separation: 사용자 단위로 데이터를 나누어 학습/검증/테스트 세트 구성, 각 분할 간 동일한 사용자 없음. 2) time-based separation: 가장 최근의 사용자 항목들을 입력–출력 쌍을 생성하는 데 사용, 더 오래된 항목들은 사용자 프로필로 사용.
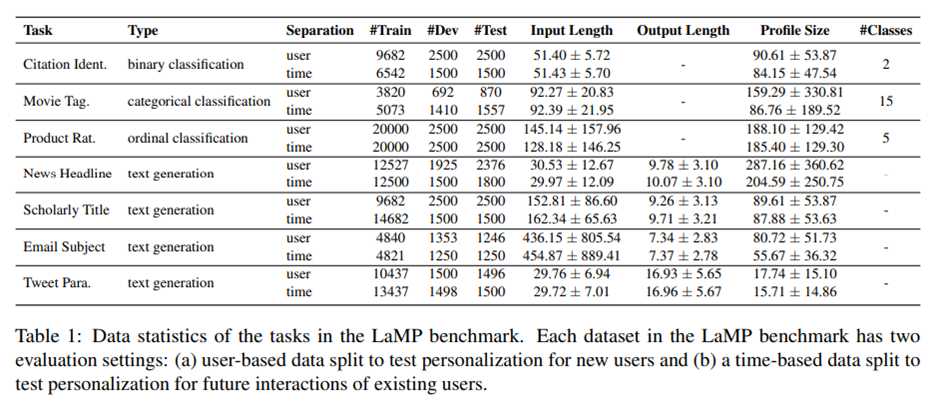
데이터셋 규모.
2.3 Evaluation
분류 과제에는 Accuracy, F1, MAE, RMSE,
생성 과제에는 기존 연구 따라 Rouge-1, Rouge-L 사용.
3 LLM 개인화를 위한 검색 증강
LLM 개인화하는 방법: 1) 사용자별로 언어 모델을 파인튜닝, 2) 사용자별 입력이나 맥락을 활용해 하나의 공유된 언어 모델을 프롬프트 방식으로 사용. -> 전자는 자원이 많이 필요함으로 사용자별 입력을 통해 개인화되는 모델을 학습하는 전략 개발에 초점.
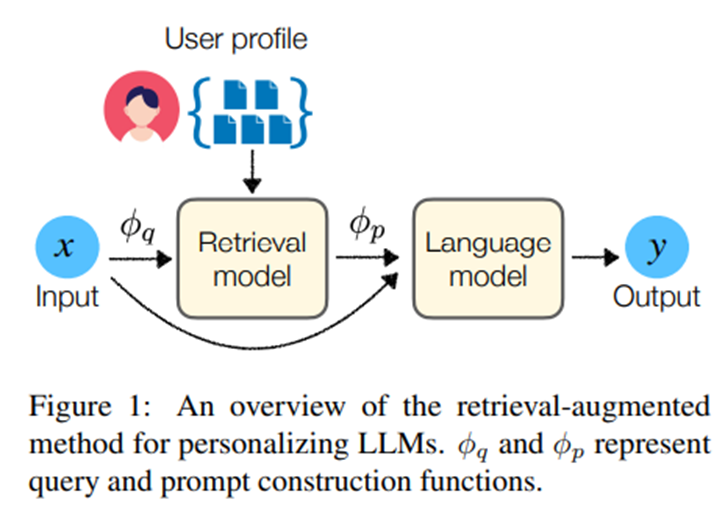
검색 증강에 기반한 해법 제안. 현재의 보지 못한 테스트 사례와 관련된 정보를 사용자 프로필에서 선택적으로 추출하고, 이 정보에 조건화해서 모델 예측 생성.
사용자 u에 대한 샘플 (x_i,y_i) 주어질 때 세 가지 주요 구성요소: 1) 입력 x_i를 사용자 프로필에서 검색하기 위한 쿼리 q로 변환하는 쿼리 생성 함수 ϕ_q, 2) 쿼리 q와 사용자 프로필 P_u를 입력으롭 kedk 사용자 프로필에서 가장 관련성 높은 k개의 항목을 검색하는 검색 모델 R(q,P_u,k), 3) 입력과 검색된 항목들을 바탕으로 사용자 u를 위한 개인화 프롬프트를 구성하는 프롬프트 생성 함수 ϕ_p.
검색 증강을 위한 전략: 1) In-Prompt Augmentation(IPA), 2) Fusion-in-Decoder(FiD)
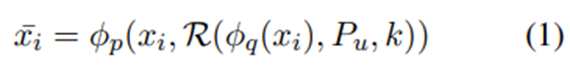
입력 정의.
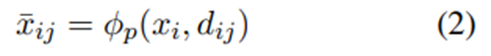
인코더에 입력되는 정보 정의. d_ij는 검색 모델을 사용해 사용자 프로필에서 검색된 j번째 항목.
FiD: 언어 모델 학습 필요, 인코더–디코더 구조의 모델에서만 사용 가능, 사용자 프로필로부터 더 많은 항목을 LLM 입력에 포함할 수 있음.
IPA: 학습 없이도 적용 가능, 다양한 아키텍처에 적용 가능.
검색 모델 R에 대해 BM25, Contriever, Recency, Random 실험.

구체적인 프롬프트.
4 Experiments
4.1 실험 설정
FiD와 IPA에서의 생성 모델 학습을 위해 AdamW, 학습률 5 × 10⁻⁵, 배치 크기 64, 전체 학습 스텝의 5%를 선형 스케줄러를 이용한 워밍업으로 사용, 10⁻⁴의 weight decay, 최대 입력 길이 512, 출력 길이 128.
분류 모델과 생성모델 각각 10 에포크, 20 에포크 학습. FlanT5-base 사용, LLM 실험에서는 FlanT5-XXL, 빔 서치(4).
Huggingface transformers, evaluate 라이브러리.
49GB GPU 메모리와 128GB CPU 메모리를 갖춘 단일 Nvidia RTX8000 GPU, 각 실험 당 최대 3일, single run.
4.2 개인화를 위한 검색 증강 언어 모델 파인튜닝
Impact of Retrievers on Retrieval-Augmented Personalization Models. 개인화된 출력을 생성하기 위해 파인튜닝된 FlanT5-base 모델과 함께 사용되는 다양한 R 구현 비교. 1) 사용자 프로필에서 무작위로 항목을 선택하는 baseline, 2) BM25, 3) Contriever, 4) 시간 기반 분할 설정에서만 적용되는 Recency.
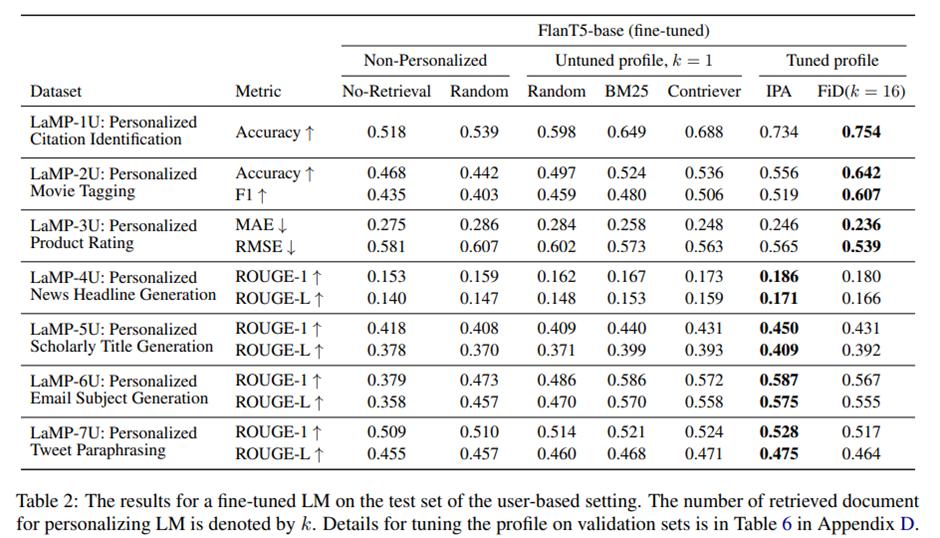
사용자 기반 분할 결과.
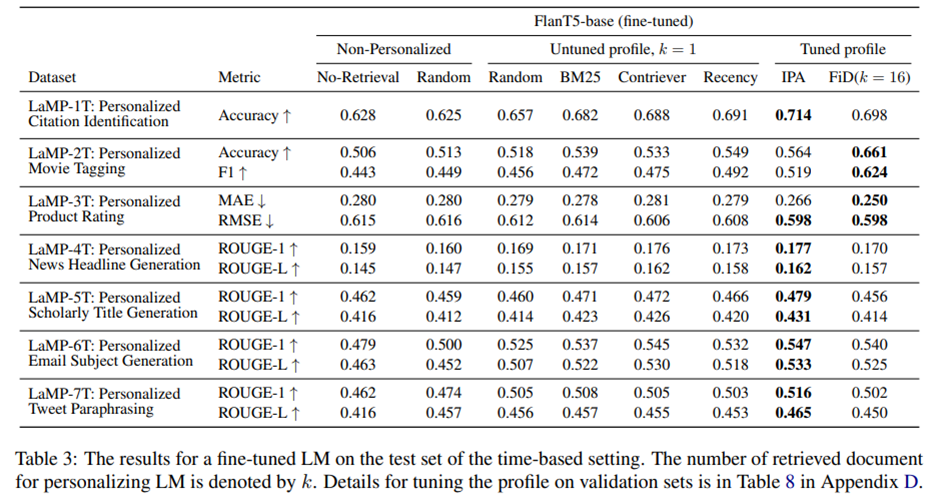
시간 기반 분할 결과. LaMP 벤치마크의 모든 과제에서 개인화가 성능을 향상시킴.
사용자당 하나의 문서를 검색해 언어 모델 출력을 개인화하는 설정에서 Contriever는 대부분의 분류 과제(LaMP-1U, LaMP-2U, LaMP-3U, LaMP-1T, LaMP-2T)에서 가장 우수, Recency는 LaMP-3T에서만 Contriever 능가.
텍스트 생성 과제는 사용자 기반 분할 설정에서 Contriever는 개인화된 뉴스 헤드라인 생성(LaMP-4U)과 개인화된 트윗 패러프레이징(LaMP-7U)에서 가장 좋은 성능, 이메일 생성과 학술 제목 생성 과제(LaMP-5U, LaMP-6U)에서는 BM25가 더 우수.
시간 기반 분할 설정에서는 뉴스 헤드라인 생성(LaMP-4T)을 제외한 모든 생성 과제에서 Contriever가 다른 방법들보다 우수, 해당 과제에서는 Recency가 우수.
-> 가장 관련성이 높거나 그리고/또는 가장 최근의 정보를 선택하는 것이 중요.
Impact of the Number of Retrieved Items, k, on LLM Personalization. 언어 모델 입력을 증강하기 위해 여러 개의 항목을 포함시키는 것이 미치는 영향 분석. 개인화를 위한 In-Prompt Augmentation(IPA) 접근법에 초점.
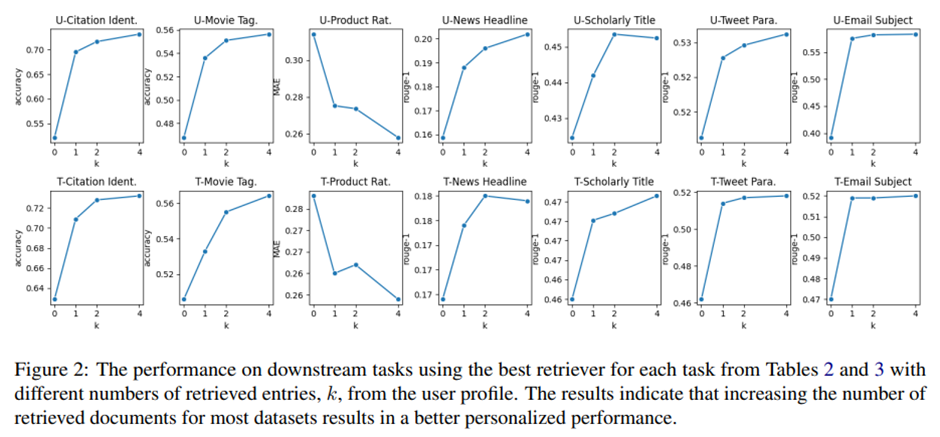
서로 다른 프로필 크기에 따른 모델 성능 제시.
앞선 실험에서 과제별로 가장 우수한 검색기 사용.
-> k 늘릴수록 과제 성능 향상. 일부는 저하.
Impact of Tuning Retriever Hyperparameters. 각 데이터셋의 검증 세트 성능을 기준으로 1) IPA와 FiD에 대해 사용할 검색 모델(BM25 vs. Contriever vs. Recency), 2) IPA에서 검색되는 항목의 개수(k).
-> 튜닝된 모델은 모든 데이터셋에서 다른 모델들보다 우수한 성능. 텍스트 분류 과제는 LaMP-1T를 제외한 모든 데이터셋에서 FiD가 IPA보다 더 높은 성능, 텍스트 생성 과제 전반에서는 IPA가 더 우수한 성능.
4.3 LLM의 제로샷 개인화 결과
GPT-3.5(별칭 gpt-3.5-turbo 또는 ChatGPT)와 FlanT5-XXL(Chung et al., 2022) 사용.
분류 과제에서 생성된 출력이 유효한 클래스에 해당하지 않는 경우 BERTScore(Zhang* et al., 2020)를 사용해 각 클래스 레이블과 생성 출력 간의 유사도를 계산하고 유사한 레이블을 모델 출력을 할당함.
GPT-3.5는 LaMP-1U, LaMP-1T, LaMP-2U, LaMP-2T, LaMP-3U, LaMP-3T 과제에서 각각 8%, 4%, 6%, 4%, 2%, 4%의 비율로 레이블 범위를 벗어난 예측 생성, FlanT5-XXL의 예측은 항상 해당 레이블 집합 내에 포함됨.
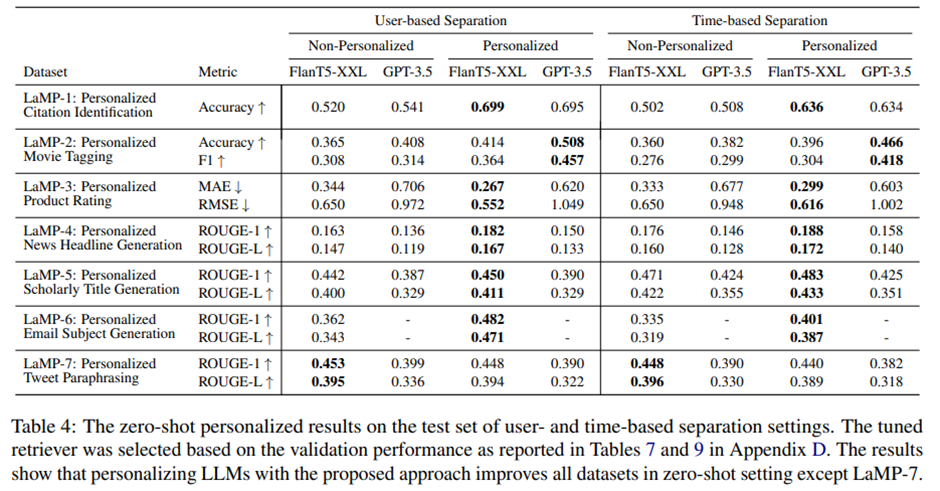
제로샷 설정에서 이 벤치마크에 대한 LLM의 결과.
트윗 패러프레이징 과제를 제외한 모든 과제에서, 사용자 프로필을 LLM에 함께 제공하는 것이 제로샷 설정에서도 성능 향상으로 이어짐.
-> 다운스트림 과제에 대해 비교적 작은 모델을 파인튜닝하는 것이 대규모 LLM을 제로샷으로 사용하는 경우보다 더 나은 성능을 낼 수 있음.
5 Research Problems Enabled by LaMP
Prompting Language Models for Personalization. 제한된 문맥 길이로 인해 긴 사용자 프로필 항목을 포함하는 데 어려움 있음. -> 다양한 프롬프트 탐구, 개인화 프롬프트 자체 생성, 소프트 프롬프트 사용.
Evaluation of Personalized Text Generation. 텍스트 생성에 일반적으로 사용되는 평가 지표는 구문적 지표나 의미적 지표 등 평가 과정에 사용자 포함하지 않음.
Learning to Retrieve from User Profiles. learning to rank는 다양한 검색 시나리오에서 연구되어 옴. 개인화된 텍스트 분류 및/또는 생성을 위해 사용자 프로필에서 개인화된 항목을 선택하는 랭킹 모델을 최적화하는 연구.
6 Related Work
개인화 연구는 대화형 에이전트 대상으로 연구됨. LaMP-4 과제는 저자 중심 개인화에 초점을 둠. LaMP는 대화 기반 과제보다 상대적으로 주목받지 못했던 텍스트 분류 및 생성 시스템의 개인화임.
언어 모델링의 보다 근본적인 문제를 대상으로 개인화를 탐구한 연구들.
7 결론
개인화된 텍스트 분류와 생성을 위한 언어 모델을 학습하고 평가하기 위한 새로운 벤치마크인 LaMP 제안.
LLM 개인화를 위한 검색 증강 해법 제안(프롬프트 내부 증강(IPA)과 fusion-in-decoder(FiD)라는 두 가지 증강 접근법).
제안한 개인화 접근법이 제로샷 설정에서는 평균 12.2%, 파인튜닝 설정에서는 평균 23.5%의 성능 향상.
한계: 과제 정의 조금 더 실제와 부합하게, LLM 학습에 안 쓰인 데이터 쓰기, 긴 텍스트 생성 평가, 프라이버시 주의.
