Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models Boxin Wang∗ , Chankyu Lee , Nayeon Lee , Sheng-Chieh Lin , Wenliang Dai , Yang Chen , Yangyi Chen , Zhuolin Yang , Zihan Liu , Mohammad Shoeybi, Bryan Catanzaro, Wei Ping*† [Submitted on 15 Dec 2025]
1. 서론
범용 추론 LLM을 RL로 학습시키는 과정에서 도메인별 이질성(응답 길이, 보상 신호 계산 방식) 존재. -> 인프라 복잡도 증가, 학습 느리게, 하이퍼퍼파라미터 선택 어렵게. -> unified reasoning model
“smoothly integrate everything”: thinking 모드로 동작할 때 전용 사고 모델에 비해 추론 벤치마크 성능 저하.
제안: Cascade RL: 도메인 전반에 걸쳐 모델을 순차적으로 학습시킴.
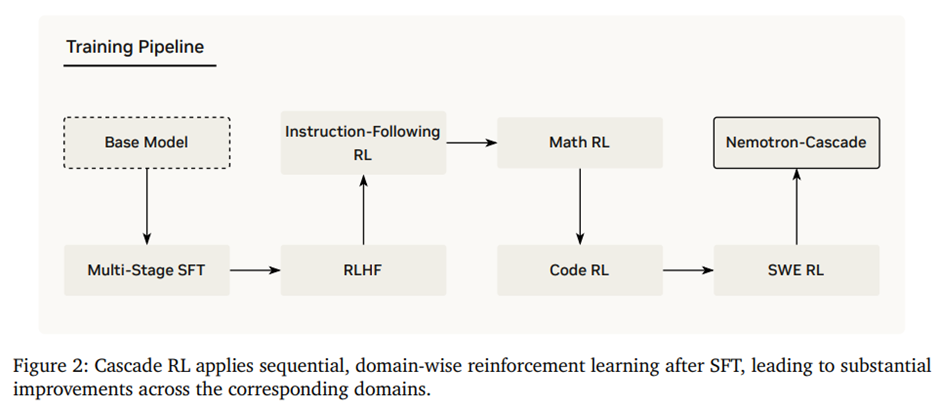
학습 파이프라인 개요.
전체 모델 및 학습 데이터 컬렉션: https://huggingface.co/collections/nvidia/nemotron-cascade
2. 주요 결과
MMLU(Hendrycks et al., 2020), MMLU-Pro(Wang et al., 2024), GPQA-Diamond(Rein et al., 2024), IFEval(Zhou et al., 2023), IFBench(Pyatkin et al., 2025), ArenaHard(Li et al., 2024), LiveCodeBench v5 및 v6(Jain et al., 2024), LiveCodeBench Pro(Zheng et al., 2025), SWE-bench Verified(Jimenez et al., 2023; OpenAI, 2024), BFCL-V3(Patil et al., 2025)를 포함한 포괄적인 벤치마크 세트에서 모델과 베이스라인 평가.
벤치마크는 일반 지식 추론, 정렬 및 지시 이행, 수학적 추론, 경쟁 프로그래밍, 소프트웨어 공학, 도구 사용 능력을 포괄적으로 다룸. 베이스라인 모델의 경우 가능한 한 공식 보고 결과를 사용, Nemotron-Cascade 모델의 경우 최대 생성 길이를 64k 토큰으로 설정, 추론 과제에서는 temperature 0.6, top-p 0.95 사용.
벤치마크와 상세한 평가 과정은 부록 B:
지식 추론 벤치마크:
MMLU: 57개 분야, 14,079문항의 범용 지식, 문제해결 평가. Thinking mode로 평가. 단일 generation 기반 EM accuracy 보고.
MMLU-Pro: graduate-level 문제 중심, 선택지 4개에서 10개로 확장. thinking mode, 단일 generation EM accuracy.
GPQA-Diamond: 물리, 생물, 화학 분야의 고난도 대학원 수준 문제 198개. Thining mode, pass@1, avg@8로 분산 감소.
temperature 0.6, top-p 0.95, thinking budget 64k, YaRN scaling factor 2.
Alignment 벤치마크:
IFEval: 검증 가능한 instruction-following 평가, prompt strict 기준 사용 (모든 instruction 만족해야 성공), unified 모델: non-thinking mode, thinking 전용 모델: thinking mode, pass@1, avg@8.
IFBench: IFEval 확장판, OOD instruction constraint 포함, thinking mode, pass@1, avg@8.
ArenaHard 1.0: 실제 사용자 프롬프트 기반 human preference 평가, LLM-as-Judge 방식, style control 미적용 결과만 보고, thinking mode, GPT-4-Turbo-2024-0409 judge 사용.
temperature 0.6, top-p 0.95, max response length 32k.
baseline 모델: 공식 수치 있으면 그대로 사용, 없을 경우 동일하거나 권장 설정으로 재평가.
Math reasoning 벤치마크:
AIME 2024: 2024년 AIME 문제 30문항
AIME 2025: 2025년 AIME 문제 30문항
thinking budget 65k, temperature 0.6, top-p 0.95, YaRN scaling factor 2.
Baseline 모델: 최소 64k thinking budget을 보장하도록 설정.
코드 생성 벤치마크:
LiveCodeBench: AtCoder, LeetCode 기반 알고리즘 문제, v5: 279문항 (2024/08–2025/02), v6: 454문항 (2024/08–2025/05), thinking mode, pass@1, avg@8.
LiveCodeBench Pro: 고난도 대회 문제, 2025Q1, 2025Q2 두 split, Easy/Medium 난이도, thinking mode, pass@1, avg@8.
SWE-bench Verified: 인간 검증된 500개 소프트웨어 엔지니어링 문제, thinking mode, pass@1, avg@4.
LiveCodeBench / Pro: thinking budget 64k, temperature 0.6, top-p 0.95, YaRN scaling factor 2.
SWE-bench Verified: thinking budget 32k, temperature 0.6, max input length 8B: 32K (YaRN factor 2), 14B: 64K (YaRN factor 3).
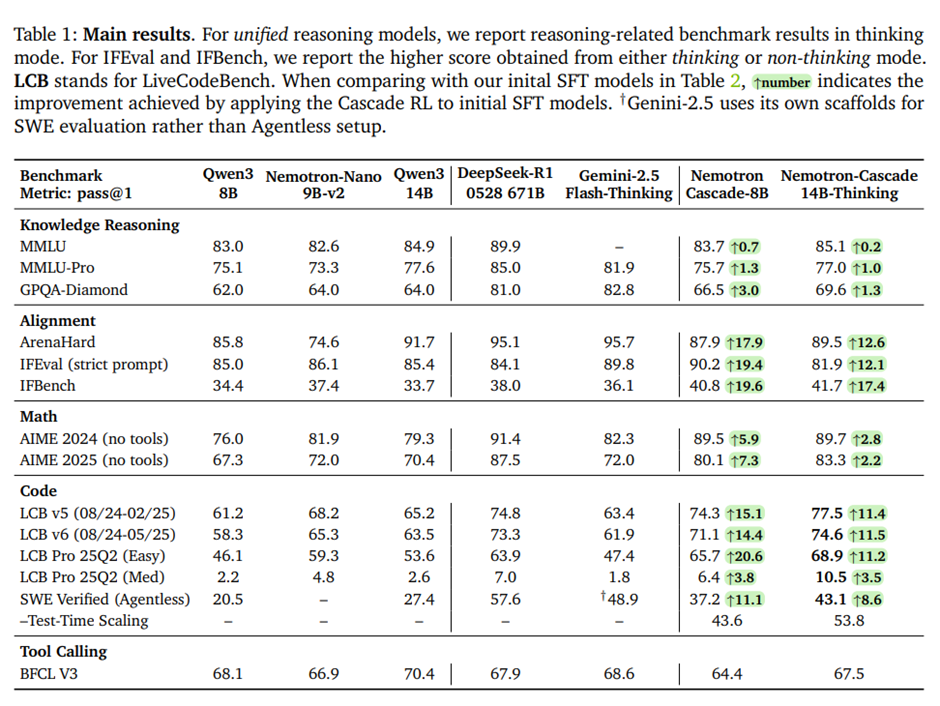
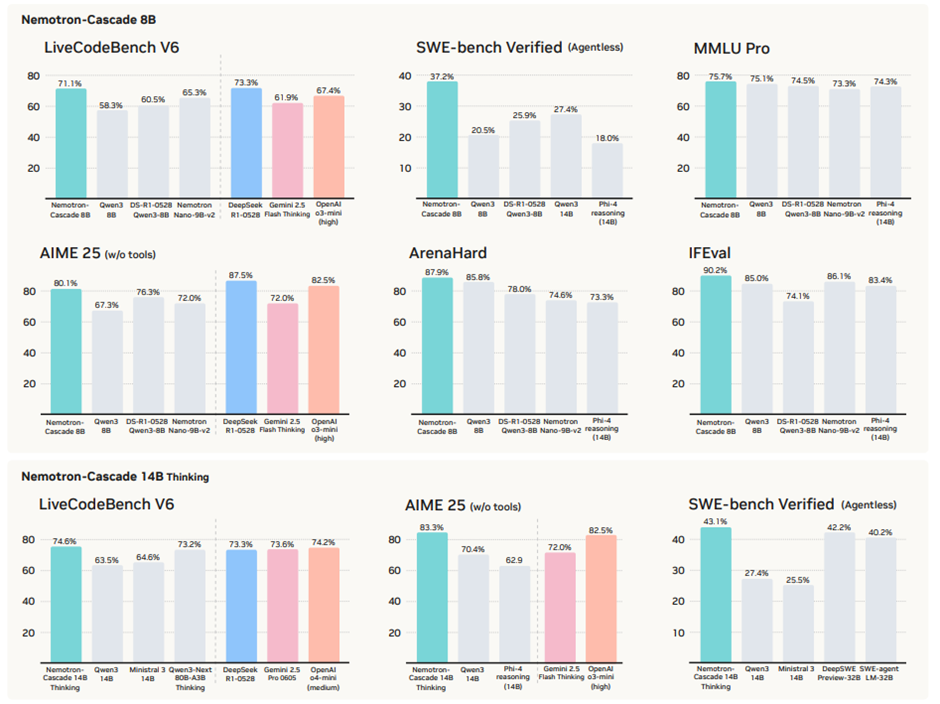
주요 결과. 모든 점수는 프롬프트당 k회 생성에 대해 평균을 낸 pass@1(avg@k)로 보고되며, k는 테스트 세트 크기에 따라 적절히 선택됨(일반적으로 4에서 64 사이). Nemotron-Cascade-8B와 전용 사고 모델 Nemotron-Cascade-14B-Thinking은 거의 모든 벤치마크에서 동급 최고 성능 달성.
3. Supervised Fine-Tuning
사후학습(post-training) 파이프라인의 첫 단계인 지도 미세조정(SFT)을 위한 training framework와 data curation 설명.
3.1. Training Framework
3.1.1. Multi-Stage SFT
SFT 커리큘럼 두 단계로 구성: 수학, 코딩, 과학, 도구 사용, 소프트웨어 공학을 포함한 광범위한 도메인 + 다중 턴 대화, 지식 집약적 질의응답, 창의적 글쓰기, 롤플레잉, 안전성, 지시 이행과 같은 일반 도메인 포괄.
Stage 1 (16K). 최대 시퀀스 길이 16k 토큰을 사용하며, 일반 도메인 데이터와 함께 수학, 과학, 코드 추론 데이터 포함. 일반 도메인 데이터의 경우 각 프롬프트에는 사고 모드와 비사고 모드의 병렬 응답 모두 포함, 수학, 과학, 코드 데이터는 사고 모드 응답만 포함. 1 에포크 학습.
Stage 2 (32K). 최대 32K 토큰 길이의 더 긴 응답을 통해 모델의 추론 능력 추가 강화, 도구 사용과 소프트웨어 공학 역량을 갖추도록. 일반 도메인 데이터를 새로운 2단계 수학, 과학, 코드 추론 데이터(최대 32k 토큰)와 재결합, 도구 사용 및 소프트웨어 공학 데이터셋 함께 사용. 일반 도메인 데이터를 제외한 모든 도메인에는 사고 모드 응답만 포함, 1에포크 학습.
D.1. Multi-Stage SFT

multi-stage SFT of the 8B and 14B models 하이퍼파라미터.
D.2. RLHF
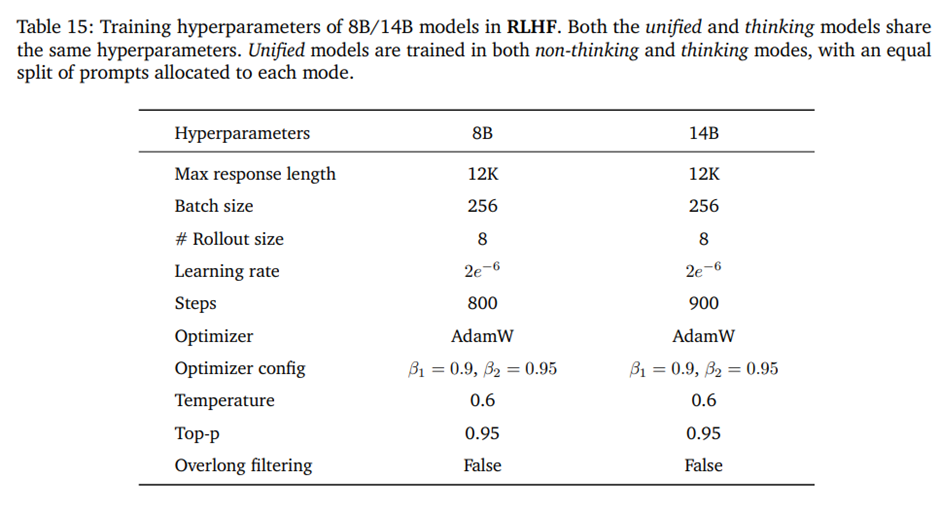
RLHF hyperparameters for the 8B and 14B models 하이퍼파라미터.
D.3. IF-RL
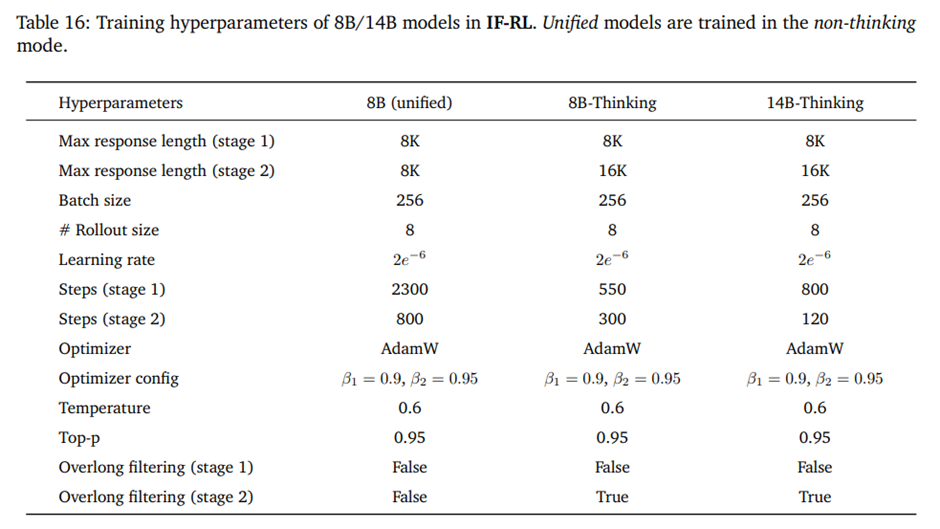
8B and 14B models in IF-RL training 하이퍼파라미터.
D.4. Math RL
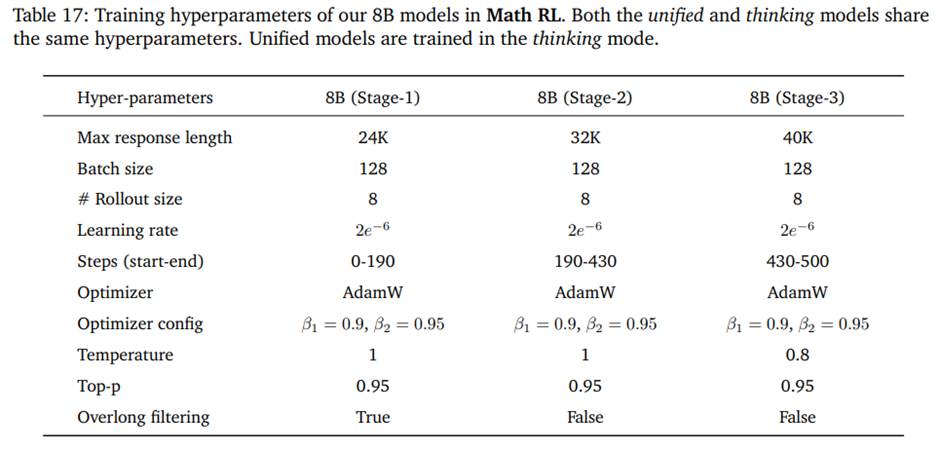
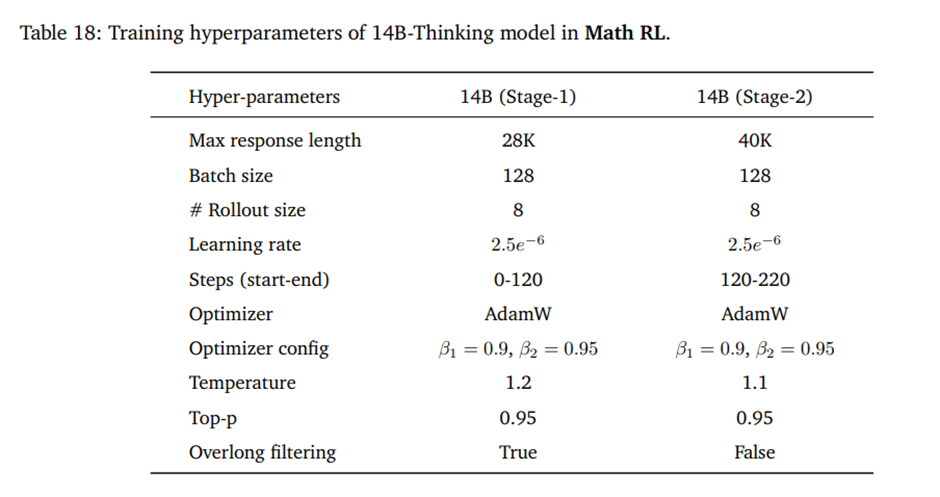
8B and 14B models used in Math RL training 하이퍼파라미터.
D.5. Code RL

8B-Thinking, 8B unified and 14B-Thinking models in Code RL 하이퍼파라미터.
D.6. SWE RL
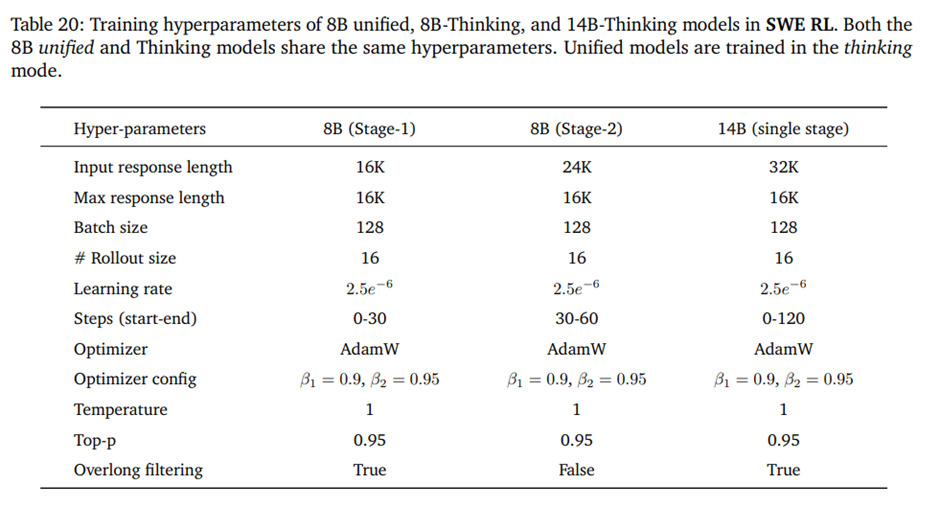
8B unified, 8B-Thinking, and 14B-Thinking models used in SWE RL training 하이퍼파라미터.
3.1.2. Chat Template
표준 ChatML 템플릿(OpenAI) 채택. 사용자 프롬프트에 /think와 /no_think라는 두 가지 제어 플래그를 도입해서 모델이 해당 모드로 응답을 생성하도록 명시적으로 지시.

도구 호출 과제(tool calling task)는 그림 3의 오른쪽에 예시된 것처럼 시스템 프롬프트에서 와 태그 안에 사용 가능한 모든 도구 명시. 모델이 <tool_call>과 </tool_call> 태그로 둘러싸인 형태로 도구 호출을 수행하도록 추가로 지시.
3.2. SFT Data Curation
3.2.1. General-Domain Data
다양한 일반 도메인 데이터셋에서 2.8M 샘플(총 3.2B 토큰)로 구성된 포괄적 코퍼스 큐레이션. -> 일상 대화, 질의응답(Lian et al., 2023; Yuan et al., 2024), 창의적 글쓰기(Allal et al., 2025; Xu et al., 2024), 안전성(Bercovich et al., 2025), 지시 이행(Lambert et al., 2024), 롤플레잉(Lambert et al., 2024) 등 폭넓은 task 포함. 일반 도메인에 걸친 지식 집약적 과제(Gema et al., 2024; Hendrycks et al., 2021; Wang et al., 2024)를 위해 공개 데이터셋(예: Khot et al., 2020; Longpre et al., 2023)에서 질문을 수집하고, 전문 법률 및 윤리 같은 난이도 높은 영역의 도메인 특화 질문으로 추가 확장해서 1.2M 샘플(총 1.5B 토큰)을 추가로 구축.
각 프롬프트에 대해 DeepSeek-R1-0528(DeepSeek-AI, 2025)과 DeepSeek-V3-0324(DeepSeek-AI, 2025)를 사용해 각각 사고 형식과 비사고 형식의 병렬 응답 생성, 최대 시퀀스 길이를 16k로 설정해 스타일과 품질의 일관성 보장.
데이터 품질을 높이기 위해 후처리 과정. -> 고품질 주석 있으면 원래 응답 유지, ground truth 있으면 정답이랑 다른 응답 폐기, 정답 없으면 보조 모델(Qwen2.5-32B-Instruct(Yang et al., 2024))로 생성 응답을 교차 검증해서 저품질 응답 필터링.
지시 이행이나 창의적 글쓰기처럼 데이터가 부족한 도메인의 희소성 문제 해결 위해 서로 다른 랜덤 시드를 사용해 각 프롬프트마다 여러 응답을 생성함으로써 다양성을 풍부하게 하고 생성 품질 개선. 다중 턴 대화 능력 강화를 위해 1) 창의적 글쓰기 도메인의 단일 턴 샘플에 대해, 이전 응답을 특정 요구사항에 맞춰 다시 쓰거나 편집하도록 지시하는 두 번째 턴 추가, 2) 단일 턴 샘플들을 무작위로 이어 붙여 다중 턴 대화를 구성함으로써 실제 챗봇 상호작용 모사.
3.2.2. Math Reasoning Data
Stage-1 SFT: AceReason-Nemotron-1.1의 수학 추론 프롬프트 사용(AceMath, NuminaMath, OpenMathReasoning 포함)
응답 생성 모델: DeepSeek-R1
최대 컨텍스트 길이 16K, 잘림 방지를 위해 초과 샘플 제거, 353K 고유 프롬프트, 다중 응답 -> 총 2.77M 샘플, 프롬프트당 평균 7.8개 응답, 9-그램 기준으로 표준 수학 벤치마크 테스트셋과 겹치는 샘플 제거(데이터 오염 제거)
Stage-2 수학 SFT: DeepSeek-R1-0528으로 응답 생성, 더 길고 상세한 추론 궤적을 활용하기 위해 최대 컨텍스트 32K, Stage-1에서 쉬운 문제 제거(DeepSeek-R1 응답이 2K 토큰 미만인 프롬프트 제외) -> 163K 프롬프트, 총 1.88M 샘플, 프롬프트당 평균 11.5개 응답
Stage-1, 2 모든 수학 데이터는 사고(thinking) 모드 형식.
3.2.3. Code Reasoning Data
AceReason-Nemotron-1.1의 코드 추론 SFT 프롬프트 사용
데이터 출처: TACO, APPs, OpenCoder-Stage-2, OpenCodeReasoning
중복 제거 후 172K 고유 프롬프트 확보
Stage-1 SFT: DeepSeek-R1으로 1.42M 샘플 생성, 프롬프트당 평균 8.3 응답, 최대 16K 컨텍스트, 코딩 벤치마크 테스트셋과 9-그램 겹침 제거로 데이터 오염 제거
Stage-2 코드 SFT: OpenCodeReasoning, OpenCoder-Stage2 프롬프트 활용, 최대 컨텍스트 32K -> 79K 고유 프롬프트, DeepSeek-R1-0528로 1.39M 샘플 생성, 프롬프트당 평균 17.6개 응답
Stage-1, 2 모든 코드 데이터는 사고(thinking) 모드 형식
3.2.4. Science Reasoning Data
데이터 출처: S1K, Llama-Nemotron 사후학습 데이터, 객관식 중 단순 선택지 분석만 하는 샘플 제거, 강한 과학 지식과 복잡한 추론·계산을 요구하는 질문만 유지, 희귀하고 다양한 질문 보강을 위해 DeepSeek-R1-0528으로 합성 질문 생성, 과학 벤치마크 테스트셋과 9-그램 겹침 제거 -> 총 226K 과학 프롬프트 수집
Stage-1 SFT: DeepSeek-R1, 최대 16K, 289K 샘플 생성
Stage-2 SFT: DeepSeek-R1-0528, 최대 32K, 345K 샘플 생성
고품질 프롬프트에 대해 다중 응답 생성, Stage-2 과학 데이터는 2배 업샘플링 후 Stage-2 SFT에 혼합
모든 과학 데이터는 사고(thinking) 모드 형식
3.2.5. Tool Calling Data
Llama-Nemotron의 도구 호출 데이터셋 사용, 함수 호출 등 외부 도구 사용 시나리오 학습 목적. 단일 턴, 다중 턴, 다단계 상호작용 모두 포함, clarification 질문 요구, 다중 도구 사용, 도구 부재 상황까지 포함. 각 대화의 시스템 프롬프트에 사용 가능한 모든 도구 명시(Qwen3 설정 따름)
평균 도구 수: 대화당 4.4개, Stage-2 SFT에서만 사용.
응답 생성 모델: Qwen3-235B-A22B
모든 도구 호출 데이터는 사고(thinking) 모드 형식
총 310K 대화, 1.41M 사용자–어시스턴트 턴으로 구성.
3.3. Software Engineering Task
소프트웨어 공학은 LLM의 가장 중요한 응용 중 하나임.
3.3.1. Agentless Framework
자동화된 소프트웨어 공학 능력을 평가하기 위해 Agentless 채택. LLM 자체가 행동 시퀀스를 계획하거나 외부 도구를 조작할 필요 없이 전체 과제를 세 단계(즉, 로컬라이제이션, 수리, 패치 검증)로 분해함. 본 연구에서는 로컬라이제이션 과정을 관련 이슈 파일을 식별하는 데만 집중하도록 단순화된 Agentless 프레임워크 사용. -> LLM은 수리 과제 자체에 더 많은 추론 역량을 투입할 수 있고, 강화학습은 수리 패치 생성 자체를 직접 최적화하는 집중된 목표로 통합.
코드 수리 단계에서의 주요 목표: 식별된 저장소 수준 이슈를 해결하는 효과적인 패치 후보 생성. 파일 로컬라이즈 -> LLM이 코드베이스의 필요한 부분만 수정하는 수리 편집 생성하도록 프롬프트 -> 할루시네이션과 문법 오류 줄임.
패치 검증 단계: 회귀(regression), 재현(reproduction), 다수결(majority voting) 세 단계.
회귀 단계: 각 패치 후보를 저장소의 기존 회귀 테스트로 먼저 평가해 호환성 확인.
재현 단계: 프레임워크가 이슈 인스턴스당 10개의 재현 테스트를 생성해서 수정되지 않은 저장소에서 원래 버그 동작을 재현하고 패치 적용 후 기능적 정합성 검증.
다수결 단계: 여러 샘플링 생성에 걸친 결과를 집계해 가장 신뢰할 수 있는 패치 선택. 동률이면 더 짧은 시퀀스나 더 작은 편집 거리 패치 선호.
각 단계에서 사용된 프롬프트는 부록 C.2.
3.3.2. Data Curation
데이터 소스:
SWE-Bench-Train: SWE-Bench와 동일한 파이프라인으로 생성된 학습용 데이터(인간 검증 없음)
SWE-Fixer-Train: 대규모 파이썬 저장소 기반, 휴리스틱 필터링 후 115K 인스턴스 산출.
SWE-reBench: 자동화, 확장형 파이프라인으로 구축된 21K개 이상의 상호작용형 SWE 과제
SWE-Smith: 128개 GitHub 저장소에서 버그를 자동 주입해 만든 50K 합성 데이터
데이터 오염 방지를 위해 SWE-bench Verified에 포함된 모든 저장소에서 나온 인스턴스 제거. 서로 다른 데이터 소스 간 중복 제거 수행, 저장소 이름과 base commit identifier를 기준으로 동일 인스턴스 제거.
Response generation:
세 가지 하위 과제별 SFT 데이터 구축: 1) 코드 로컬라이제이션: 버그 가능성이 높은 파일 목록을 우선순위로 출력, 2) 코드 수리: 버그 파일을 수정하는 코드 패치 생성, 3) 테스트 코드 생성: 패치를 검증하는 테스트 코드 생성.
응답 생성 모델: DeepSeek-R1-0528
응답 수: SWE-Bench-Train / SWE-reBench / SWE-Smith: 프롬프트당 8개, SWE-Fixer-Train: 프롬프트당 4개, 모든 프롬프트는 문제 설명, 코드, 출력 형식을 포함하도록 구조화, 모든 응답은 추론 체인, 최종 해답을 포함
Data filtering and splitting for SFT and RL:
모든 생성 응답을 정답 주석과 비교해 검증.
과제별 필터링 기준: 1) 로컬라이제이션: 모든 버그 파일을 포함한 경우만 유지(recall = 1.0), 2) 코드 수리: Unidiff로 생성 패치와 정답 패치 유사도 계산. SFT용: 8개 응답 중 최소 4개가 유사도 0.5 초과, RL용: 최소 1개 응답이 0이 아닌 유사도(어려운 인스턴스). SWE-Fixer-Train: 유사도 0.5 초과한 모든 쌍 포함, 3) 테스트 코드 생성: 문법 오류 없이 파싱, 실행 가능한 궤적(trajectory)만 유지.
Dataset composition summary:
Code Repair 데이터셋 총 127K: SWE-Bench-Train: 17K, SWE-reBench: 17K, SWE-Smith: 18K, SWE-Fixer-Train: 77K. 로컬라이제이션 데이터셋: 92K, 테스트 케이스 생성 데이터셋: 31K. 모든 SWE 데이터셋은 Stage-2 SFT 전에 3배 업샘플링.
3.4. SFT 이후 결과
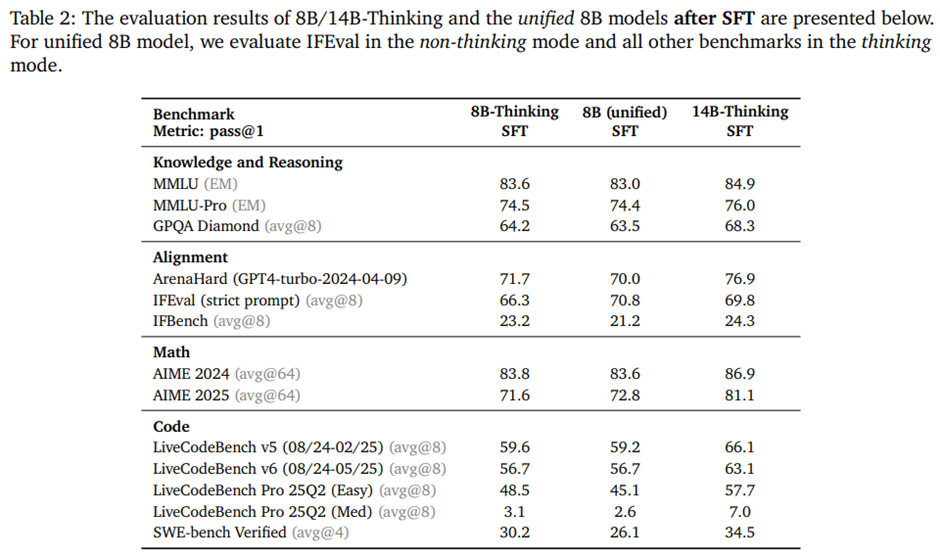
8B 통합 모델과 8B/14B 사고 모델의 결과. 8B 통합 모델이 모든 추론 관련 벤치마크에서 전용 8B Thinking 모델과 동등한 성능, IFEval 벤치마크에서는 이를 능가. -> IFEval은 지시(instruct) 모드에 더 자연스럽게 맞는 과제이기 때문.
4. Cascade RL
SFT 데이터셋과 RL 데이터셋이 프롬프트 관점에서 엄격하게 서로 겹치지 않도록(disjoint) 보장. -> 모델이 RL 학습 중에 SFT에서 해당 프롬프트에 대한 암기 답변을 활용할 수 없게 함.
4.1. Training Framework
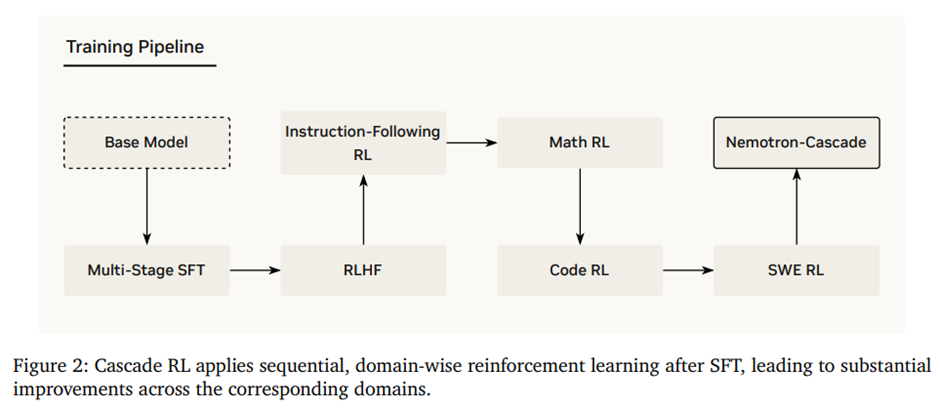
RLHF -> Instruction-Following RL -> Math RL -> Code RL -> SWE RL 순차적으로 적용해서 더 일반적인 도메인에서 더 특수한 도메인으로 점진적 진행.
4.1.1. LLM에서 Cascade RL이 Catastrophic Forgetting에 강한 이유
catastrophic forgetting: 모델이 여러 도메인을 순차적으로 학습할 때 새로운 것을 습득하는 과정에서 이전에 배운 지식을 덮어쓰는 현상. Cascaded Cross-Domain RL for LLMs는 이 문제 완화하는 구조적 차이 가짐: 1) RL에서는 학습 데이터 분포가 정책에 의존적임, 2) RL은 각 입력에 대한 정확한 타깃을 맞추는 것이 아니라 기대 누적 보상(expected cumulative reward)을 최적화함 -> 업데이트는 새로운 토큰 수준 분포를 명시적으로 피팅하기보다는 장기적 결과를 개선하는 데 집중, 3) RLHF와 RLVR의 보상 구조는 수학, 코드, 추론, 지시 이행 등 도메인 전반에서 상당 부분 겹침 -> 출력이 더 좋아지게, 더 정확해지게, 그리고 인간 선호 또는 검증 신호에 더 잘 맞게 만드는 것을 목표로 하기 때문, 4) 프롬프트 중첩을 가능한 한 크게 최소화함.
4.1.2. RL Training Configuration
On-policy 학습, Group Relative Policy Optimization(GRPO) 알고리즘. 학습은 verl 레포지토리 사용해 수행.
각 반복(iteration)에서 현재 정책 π_θ으로부터 G개의 rollout 그룹 생성 후 단 한 번의 gradient 업데이트. -> 데이터 수집에 사용되는 정책이 업데이트되는 정책과 항상 일치하도록 보장, 중요도 샘플링 비율(importance sampling ratio)이 정확히 1이 되게 함.
KL 발산 항 완전 제거 -> GRPO 목적함수를 그룹 정규화 보상과 토큰 수준 손실을 사용하는 표준 REINFORCE 목적으로 단순화.
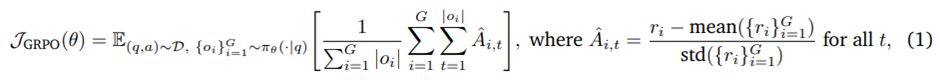
{ri }(i=1)^G은 데이터셋 D에서 뽑힌 주어진 질문 q에 대해 샘플링된 응답 {o}_(i=1)^G에 할당된 G개의 보상 그룹, RLVR에서 정답 a에 대해 검증됨.
RLHF의 경우 r_i는 응답 o_i와 질문 q에 대해 보상 모델이 출력한 스칼라 값.
4.2. Reward Modeling
4.2.1. Data Curation
보상 모델(RM) 학습용 선호 데이터셋은 오픈소스 + 인하우스 데이터를 혼합한 총 82K 선호 쌍으로 구성. 오픈소스 데이터 구성: 1) HelpSteer2: 10K 규모, 인간 주석 기반 고품질 선호 데이터, 도움성, 정합성, 일관성, 복잡성, 장황함 등 다면적 품질 기준 포함, 2) HelpSteer3: 40K 규모, 일반, STEM, 코드, 다국어 도메인 포함, 응답 쌍에 -3-3 선호 점수 부여, 점수 0(두 응답이 유사한 경우)은 제거하여 36K만 사용.
추가 선호 데이터 생성 전략: 핵심 아이디어: 강한 모델의 나쁜 응답 vs 약한 모델의 좋은 응답으로 선호 쌍 구성 -> 강한 모델이 항상 좋은 답만 내면 보상 모델 학습이 너무 쉬워져 변별력이 떨어지기 때문.
강한 모델로부터 나쁜 응답을 유도하는 방법: 원 프롬프트를 약간 주제에서 벗어나도록(off-topic) 재작성, DeepSeek-V3를 사용해 프롬프트 재작성, 재작성 품질은 수동 검증, LLM-as-a-Judge로 확인.
최종 선택: 강한 모델: DeepSeek-V3-0324, 약한 모델: DeepSeek-V3. 강한 모델에게 일부러 틀린 답을 생성하라고 명시적으로 지시하는 방식은 실패.
4.2.2. Training Recipe
Bradley-Terry 목적함수 사용.
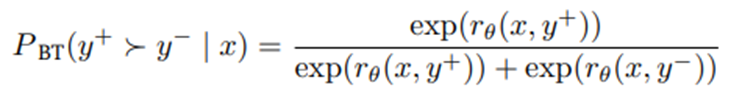
보상 모델은 Qwen2.5-72B-Instruct(Yang et al., 2024)로 초기화, 마지막 은닉층 위에 선형 예측기(linear predictor)를 올려 두고 인간 선호의 로그-우도(log-likelihood)를 최대화하는 방식으로 학습:
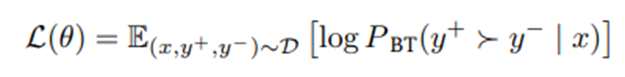
학습 파라미터: 배치 크기 256, 학습률 2e-6, AdamW 옵티마이저(Loshchilov and Hutter, 2017), 1 에포크.
RM evaluation:
RLHF 과정에서 사용할 보상 모델(RM)을 평가하고 선택하기 위해 주로 RewardBench 사용.
Ablation studies on RM:
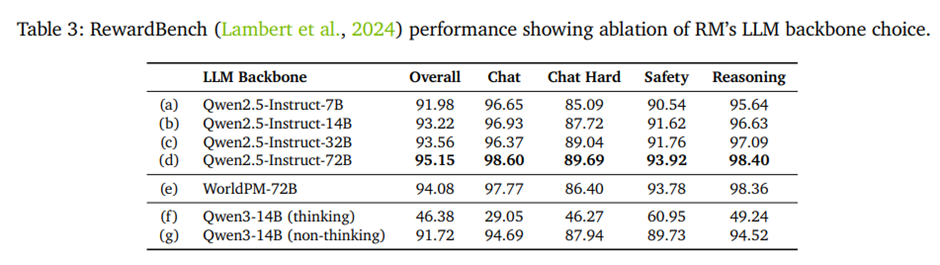
Model Size: 보상 모델 학습 맥락에서도 스케일링 법칙 성립. (표 3의 (a)-(d) 참조)
With vs. Without Large-scale Preference Pre-training: WorldPM으로 초기화한 모델은 학습 초기 단계에서 더 좋은 성능, 학습을 더 길게 수행하면 vanilla Qwen2.5-72B-Instruct로 초기화한 모델이 결국 따라잡고 RewardBench에서 더 좋은 성능(표 3의 (d) vs (e) 참조).
Reasoning vs. Instruct Models: BT 손실로 학습한 보상 모델의 백본으로 사용할 때, Qwen3 추론 모델이 동일 크기의 Qwen2.5 지시형/비사고 대응 모델보다 일관되게 낮은 성능(표 3의 (b) vs (f) vs (g) 참조).
4.3. Reinforcement Learning from Human Feedback (RLHF)
보상 모델의 일반화 능력이 안정적인 RLHF 학습을 보장하는 데 결정적 역할, 더 큰 보상 모델(예: 72B RM)이 정책 LLM이 생성하는 분포 밖(out-of-distribution, OOD) 샘플에 더 강인함.
4.3.1. Data Curation
보상 모델의 분포 밖(OOD) 프롬프트를 RLHF 단계에 도입하면 부정확하거나 오도하는 보상 신호 때문에 불안정성이 발생하거나 training collapse. -> RLHF 단계에서는 설명한 보상 모델 선호 데이터셋의 프롬프트 중 일부만 사용.
수학 및 경쟁 프로그래밍과 관련된 프롬프트는 제외 -> 보상 모델이 이후의 Math RL 및 Code RL 단계에서 사용되는 규칙 기반(rule-based) 또는 실행 기반(execution-based) 검증기가 만들어내는 보상 신호만큼 신뢰할 만한 보상 신호를 제공하지 못할 수 있기 때문.
4.3.2. Training Recipe
큐레이션한 RLHF 데이터셋에 수학이나 코드 관련 프롬프트가 전혀 포함되어 있지 않아도 수학 및 코드 벤치마크에서의 추론 성능을 향상시킴. -> Cascade RL 파이프라인을 RLHF 단계로 시작하도록 설계.
보상 함수:
모델의 답변을 추출 -> 해당 질문과 concatenate -> 보상 모델의 채팅 템플릿을 적용하여 형식화된 입력을 보상 모델에 넣어 점별(point-wise) 보상 점수
학습 중 RLHF에서 8B와 14B 모델 모두 최대 응답 길이를 12K.
프롬프트가 순수하게 영어인데 생성된 응답(사고 추적과 요약을 모두 포함)에 비영어 토큰이 포함될 경우 추가적인 코드 스위칭(code-switch) 패널티.
하이퍼파라미터:
최대 응답 길이를 12K, overlong filtering 적용 x, 배치 크기 128, 프롬프트당 8개 rollout, temperature 0.6, top-p 0.95, AdamW 학습률 2e-6, 엔트로피 손실 계수와 KL 손실 계수 0. 학습은 약 800 스텝이 소요됨.
추가 세부 사항은 부록 D.
4.3.3. RLHF 이후 결과
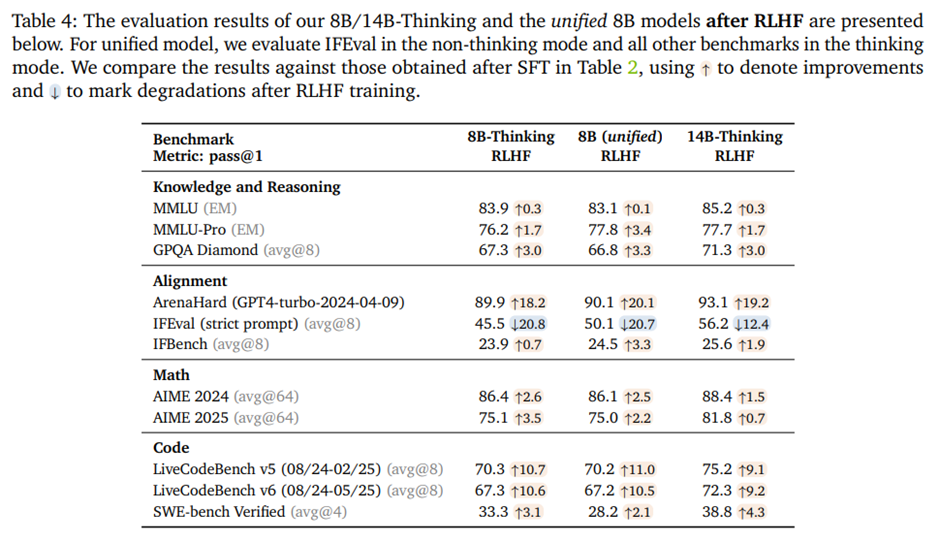
RLHF 이후의 8B 및 14B 모델 결과. IFEval을 제외한 거의 모든 벤치마크에서 유의미한 향상 -> RLHF 과정이 특히 사고 모드에서 과도하게 길고, 장황하며, 반복적인 생성을 패널티로 주어 응답 품질을 크게 개선하기 때문. IFEval 성능 저하의 주요 원인은 RLHF 학습에 사용된 프롬프트와 IFEval의 테스트 프롬프트 사이에 피할 수 없는 의미적 중첩(semantic overlap)이 존재하기 때문.
4.4. Instruction-Following Reinforcement Learning (IF-RL)
SFT 데이터 혼합에도 이미 지시 이행 데이터가 포함되어 있지만, 검증 가능한 보상을 사용하는 IF-RL을 적용하면 지시 준수 정확도가 추가로 향상됨.
4.4.1. Data Curation
Llama-Nemotron의 지시 이행 데이터셋 사용.
4.4.2. Training Recipe
IF-RL 학습은 두 단계로 진행. 첫 번째 단계는 IFEval 택소노미의 지시 제약에 초점, 두 번째 단계는 IF-Bench-Train 택소노미에 초점. dynamic filtering이 IF-RL 학습을 크게 안정화하고, 배치 안의 모든 프롬프트가 유효한 그래디언트를 갖도록 보장함으로써 두 단계 모두에서 결과를 개선함.
Unified models: IF-RL in the non-thinking mode
먼저 사고 모드와 비사고 모드 모두에서 RLHF를 수행한 다음, IF-RL은 비사고 모드에서만 적용. 1단계 및 2단계 IF-RL 학습 모두 통합 추론 모델은 최대 응답 길이를 8K 토큰, overlong filtering은 적용 x.
Thinking model: IF-RL with combined reward function
IF-RL에서 인간 선호와 정확한 지시 이행 능력을 동시에 고려하는 보상 함수를 설계. 규칙 기반 지시 이행 검증기와 인간 선호 보상 모델에서 오는 신호 결합.
주어진 프롬프트 q와 생성된 응답들의 그룹 {oi }(i=1)^G에 대해 각 응답 o_i의 보상은
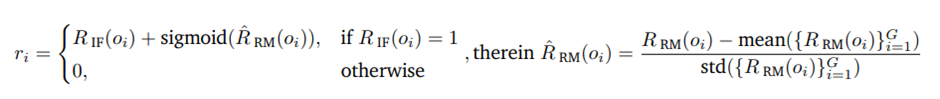
임. R_IF(o_i ) ∈ {0,1} 는 지시 이행 검증기가 주는 이진 보상, R ̂_RM (o_i)는 RLHF 단계에서 사용한 동일한 보상 모델이 산출한 보상을 그룹 정규화(평균 0, 표준편차 1)한 값. 시그모이드는 R ̂_RM의 값을 (0, 1) 범위로 스케일링.
하이퍼파라미터:
배치 크기는 128이며, 프롬프트당 8개의 응답을 temperature 0.6, top-p 0.95, top-k 20. AdamW 학습률 2e-6, 엔트로피 손실 계수와 KL 손실 계수 0.
추가 세부 사항은 부록 D.
4.4.3. IF-RL 이후 결과
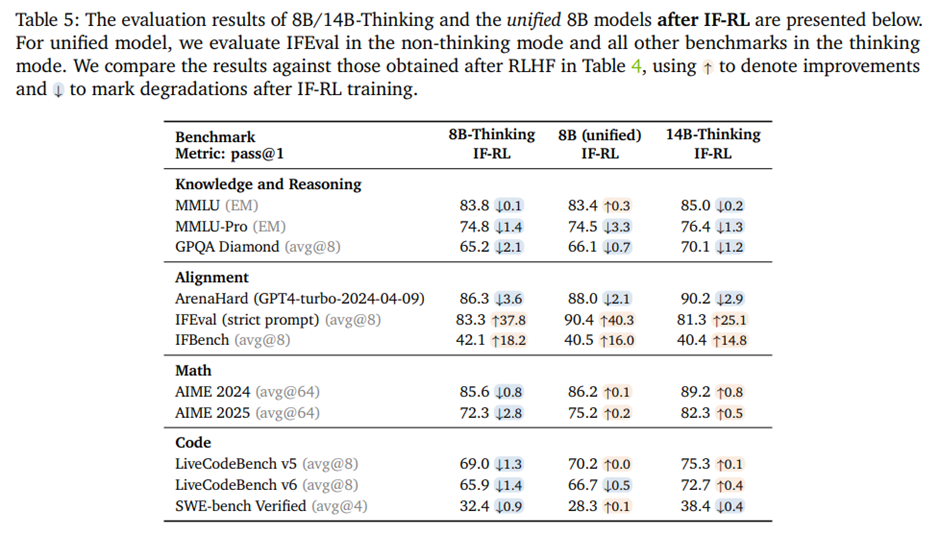
IF-RL 이후 결과. IFEval과 IFBench에서 유의미한 향상, 통합 모델과 전용 사고 모델 모두에 개선 기법을 적용할 때 ArenaHard에서는 통제된 작은 성능 저하. IF-RL은 일반적으로 모델 엔트로피를 줄이고, 추론 토큰의 평균 길이를 단축시킴.
4.5. Math RL
4.5.1. Data Curation
AceReason-Math를 기반으로 DeepScaleR 블렌드와 NuminaMath를 병합한 수학 데이터에서 RL에 적합한 18K 고품질 문제 구성.
AIME·MATH와의 데이터 오염을 9-그램 필터링으로 제거하고, 객관식, 증명, 다중 질문, 비영어, 도형 참조 등 검증이 어려운 문제 제외.
NuminaMath의 노이즈를 줄이기 위해 DeepSeek-R1로 다중 검증 후 다수결로 정답이 합의된 문제만 유지.
이미 너무 쉽게 풀리는 문제를 제거, 초기 49K에서 최종적으로 난이도 있는 문제만 남긴 14K 문제를 RL 학습에 사용.
4.5.2. Training Recipe
Initialization from models that have undergone RLHF:
초기에는 Math/Code RL -> RLHF/IF-RL 순서를 시도했으나, RLHF로 학습된 모델을 기준으로 Math RL을 시작하는 것이 훨씬 효과적.
RLHF는 초기 수학 추론 능력을 크게 강화하고, 장황함, 반복을 줄여 토큰 효율을 높이고, 그 결과 Math RL에 필요한 학습 스텝 수를 크게 감소시킴.
실제 파이프라인에서는 RLHF와 Math RL 사이에 IF-RL을 배치하며, IF-RL로 줄어든 엔트로피와 추론 길이는 이후 high temperature Math/Code RL로 다시 복원됨.
Reward function:
보상은 정답 정확성만 기준으로 부여.
<\think> 이후의 \boxed{} 최종 답만 추출해 AceMath 규칙 기반 검증기로 확인.
정답이면 1, 오답이면 0.
추론 중 언어 혼합이 발생하면 코드 스위칭 페널티로 −1 보상을 적용.
Response length extension training:
성능 향상의 핵심은 더 깊고 긴 추론 체인을 생성하는 능력. -> 이를 위해 단계적 응답 길이 확장 커리큘럼(24K -> 32K -> 40K) 사용. 이 커리큘럼은 순서대로 과도한 추론 압축 -> 추론 길이 안정화 -> 긴 추론 확장의 역할.
24K 압축 단계에서는 지나치게 긴 추론으로 인한 미완성 문제를 줄이기 위해 추론을 다듬고 압축하고, overlong filtering은 스킵 방식으로 적용해 학습 불안정을 방지.
32K 확장 단계에서는 overlong filtering 없이 토큰 예산을 늘려, 모델이 더 긴 컨텍스트에 적응하면서도 정확도를 회복, 개선하도록 유도.
40K 긴 추론 단계에서는 어려운 문제에서 더 많은 토큰을 적극 활용하도록 장려해, 고난도 수학 문제(AIME)의 성능을 유의미하게 끌어올림.
Dynamic filtering:
모델 간 역량 차이로 인해 너무 쉬운 문제나 전혀 풀 수 없는 문제는 정책 학습에 유의미한 그래디언트 신호를 주지 못함. -> 이를 해결하기 위해, 각 에포크 이후 정확도 100% 또는 0%인 문제를 동적으로 필터링.
필터링된 어려운 문제는 10% 확률로 재샘플링해 이후 학습에서 해결 가능성을 열어두고, 쉬운 문제는 1% 확률로 재샘플링해 망각 방지. -> 이 전략을 통해 전체 학습 샘플의 약 90%가 의미 있는 학습 신호를 제공하게 되며, 특히 학습 후반부의 정확도 안정성이 크게 향상.
에포크 기반 동적 필터링은 많은 롤아웃을 요구하는 배치 기반 동적 샘플링보다 효율적인 대안.
하이퍼파라미터: 배치 크기 128, 프롬프트당 8개 샘플, temperature 1, top-p 0.95. 학습률은 2 또는 2.5 × 10−6, 엔트로피, KL 손실 사용 x. 8B 모델은 24K -> 32K -> 40K의 3단계 길이 확장 커리큘럼, 14B 모델은 초기 성능이 높아 28K에서 시작해 바로 40K로 확장.
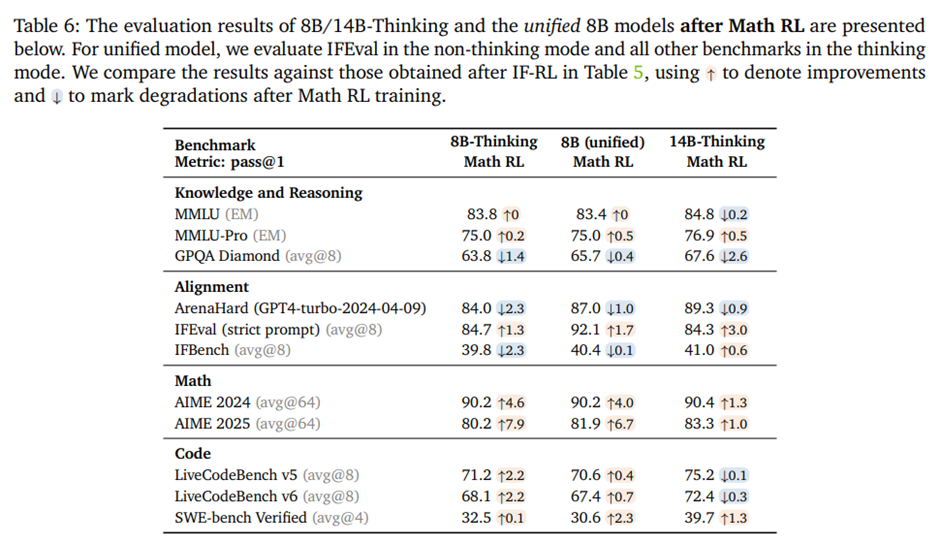
4.5.3. Results after Math RL
Math RL 이후 결과. Math RL 이후 AIME 2024, 2025에서 뚜렷한 성능 향상이 나타나며,
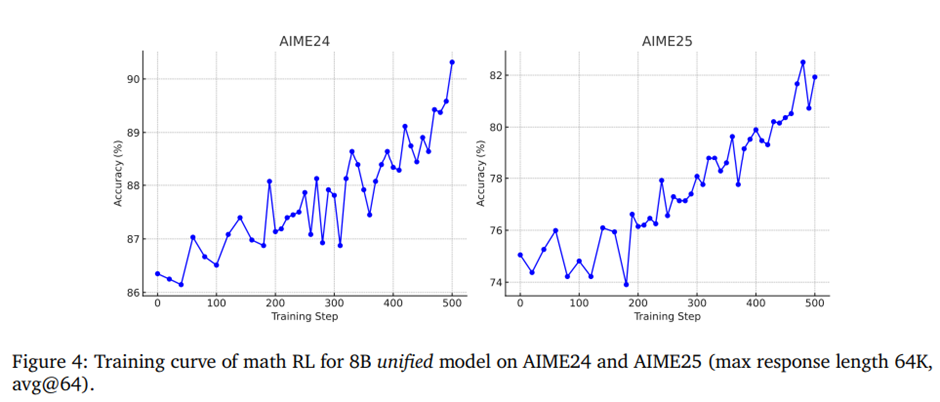
학습 과정은 그림 4의 성능 추적 곡선으로 확인.
지식 추론 및 정렬 벤치마크에는 영향이 거의 없고, 관측된 차이는 주로 평가 변동성과 체크포인트 선택에 기인. 반면 LiveCodeBench와 SWE 등 코딩 벤치마크에서는 성능이 개선되고, 향상 폭이 제한적인 이유는 Math RL 이전부터 모델의 범용 추론 성능이 이미 강했기 때문.
4.6. Code RL
4.6.1. Data Curation
AceReason-Nemotron 코딩 코퍼스를 기반으로 Code RL 학습 데이터를 구성하며, TACO, APPS, DeepCoder 등 단위 테스트가 포함된 경쟁 프로그래밍 데이터셋 활용.
인터랙티브 문제, 특수 저지 문제, 테스트 커버리지가 부족한 문제를 엄격히 필터링해 거짓 양성, 거짓 음성 보상 신호 최소화.
9-그램 필터링과 문제 URL 매칭으로 중복 제거 및 벤치마크 오염 방지.
난이도 조정을 위해 너무 쉬운 문제(AceReason-Nemotron-7B가 8/8 해결)와 너무 어려운 문제(DeepSeek-R1-0528이 8/8 실패) 제거.
-> 총 9.8K개의 고품질 Code RL 학습 샘플.
4.6.2. Training Recipe
보상 함수:
엄격한 이진 보상을 사용해, 생성된 코드가 모든 테스트 케이스를 통과할 때만 보상 1, 그렇지 않으면 0.
AceReason Evaluation Toolkit의 병렬 코드 검증기와 VeRL의 비동기 보상 계산을 적용해 코드 실행 오버헤드를 크게 줄이고, 실제로 검증 시간이 약 1172초 -> 416초로 감소.
추론 과정에서의 언어 혼합 방지를 위해 코드 스위칭 패널티를 적용하되, Math RL과 달리 보상 -1이 아닌 0을 부여. -> 강한 패널티가 오히려 언어 혼합만 회피한 오답 생성을 유도해 코딩 성능을 떨어뜨린다는 경험적 관찰에 기반.
하이퍼파라미터: 배치 크기 128, 학습률 4 × 10⁻⁶(AdamW), 프롬프트당 8 롤아웃으로 학습. 코드 생성의 탐색성을 확보하기 위해 temperature 1.0, top-p 0.95.
4.6.3. Results after Code RL
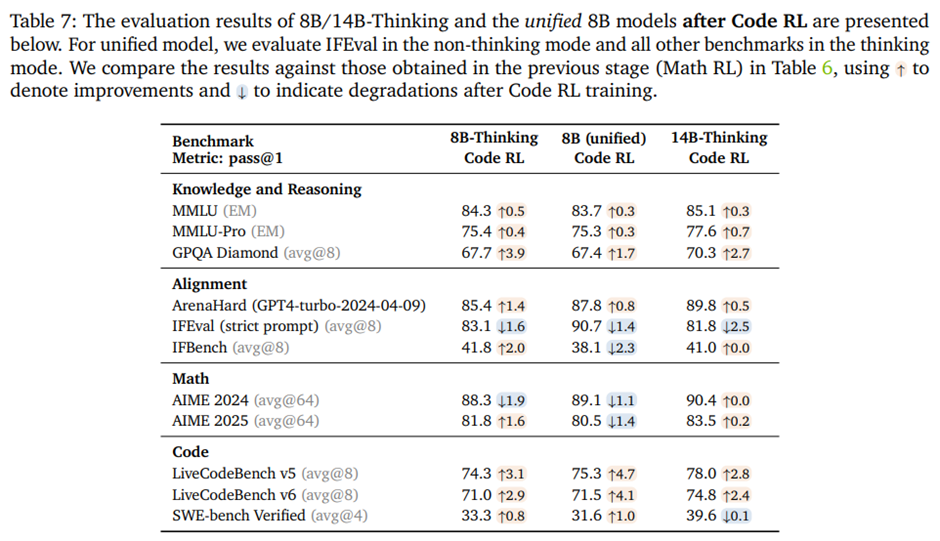
Code RL 이후의 결과. LiveCodeBench에서 큰 성능 향상. 통합 8B 모델은 LCB v5/v6에서 75.3 / 71.5로, 교사 모델인 DeepSeek-R1-0528(671B)과 동등한 수준. 14B-Thinking 모델은 LCB v5/v6에서 78.0 / 74.8을 기록해, 교사 모델을 명확히 상회. -> Cascade RL이 대형 교사 모델 없이도 소형 모델의 코드 추론 능력을 크게 강화할 수 있음.
Code RL은 다른 도메인 성능에는 거의 영향을 주지 않으며, 관찰되는 변화는 주로 평가 변동성이나 체크포인트 선택에 따른 것.
4.7. SWE RL
4.7.1. Data Curation
SWE RL 데이터는 SFT보다 더 어려운 인스턴스만 선별해 구성되며, 모델에게는 어렵지만 해결 가능하다고 판단되는 코드 수리 프롬프트만 유지.
SFT–평가 간 입력 불일치를 해결하기 위해 긴 컨텍스트(최대 60K)를 사용하고, 정답 파일만 쓰는 경우와 정답 + 위치 탐색 잡음 파일을 섞은 프롬프트 두 유형을 만들어 RL에 활용.
SWE RL은 Cascade RL의 최종 단계로, Code RL 이후 체크포인트에서 GRPO 기반 온-폴리시 RL을 수행하며 KL 정규화는 사용하지 않음.
4.7.2. Training Recipe
Reward function:

확장성을 위해 execution-free 보상 함수를 도입, 생성 패치와 정답 패치 간 어휘적, 의미적 유사도로 보상 계산. 완전히 일치하면 보상 1, 원본 코드와 동일하면 0, 파싱 불가하면 -1, 그 외에는 LLM 기반 의미 유사도 점수를 보상으로 사용.
Multi-stage RL training for input context extension:
입력 컨텍스트 길이와 SWE 성능 사이의 강한 양의 상관관계를 확인하고, 학습 안정성을 유지하기 위해 16K -> 24K로 점진 확장하는 2단계 RL 커리큘럼 설계. 출력 길이는 16K로 고정, 장문 컨텍스트 처리에 취약한 8B 모델의 초기 불안정 방지.
16K 워밍업 단계에서는 관리 가능한 컨텍스트에서 다중 파일 분석과 안정적인 attention을 학습, 24K 확장 단계에서는 이미 형성된 분석 능력을 바탕으로 파일 간 추론과 정보 종합 능력이 유의미하게 향상.
Hyperparameters: 배치 크기는 128이고, AdamW로 학습률은 2.5 × 10-6. 프롬프트당 16개의 롤아웃을 생성, 샘플링 temperature 1. 최대 응답 길이는 16K, 생성이 최대 응답 길이에 도달한 궤적에는 overlong filtering 적용. 세부 하이퍼파라미터는 부록 D.
4.7.3. Results after SWE RL
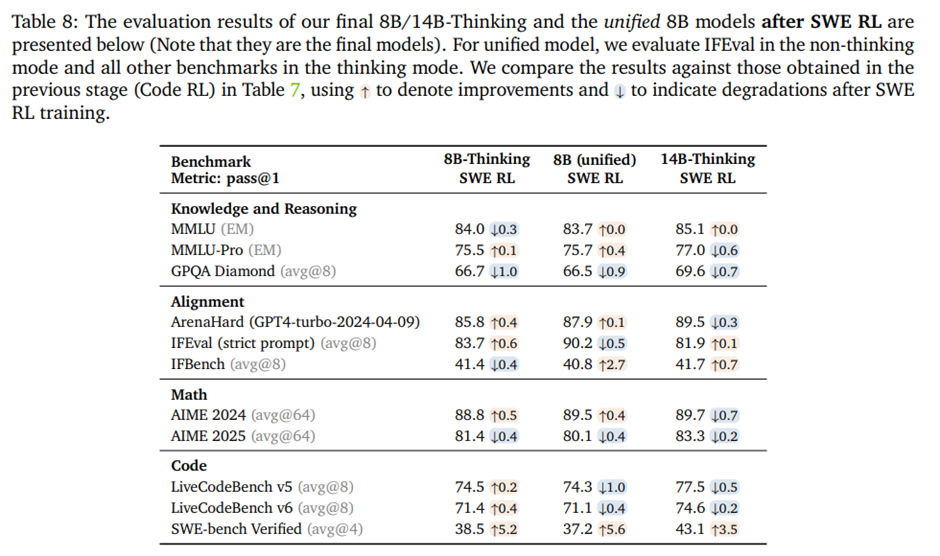
SWE RL을 적용한 이후의 결과. Cascade RL의 최종 단계로 수행, 다른 도메인 성능에는 거의 영향을 주지 않으면서 SWE-bench Verified에서 큰 성능 향상.
14B-Thinking 모델은 pass@1 43.1로 공개 32B 전문 모델들을 능가하고, 8B 통합 모델은 전용 8B 사고 모델과의 격차를 거의 해소.
통합 Nemotron-Cascade-8B는 추론 성능은 사고 전용 모델과 유사하게 유지하고, 지시 이행 성능에서는 더 우수한 균형.
5. Deep Dive on Competitive Coding
Nemotron-Cascade 모델은 LiveCodeBench와 LiveCodeBench Pro의 최신 경쟁 프로그래밍 문제(학습 컷오프 이후 공개분)에서 64K 토큰 사고 예산, avg@8 조건으로 평가, Codeforces 라운드 기반 Elo 점수도 함께 측정.
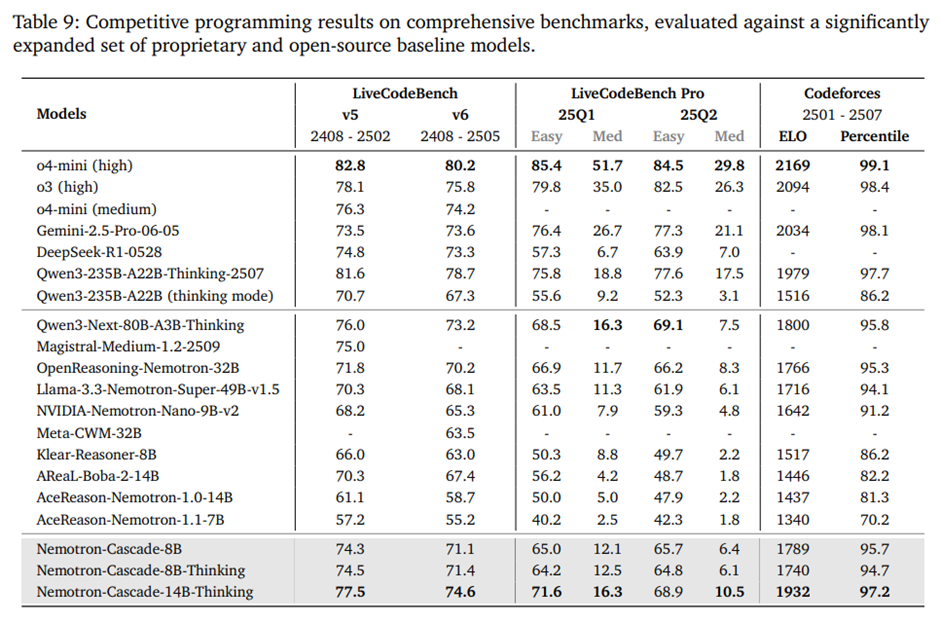
-> 8B 모델은 동급 소형 추론 모델들을 크게 앞서고 32B 증류 모델과 맞먹는 성능, 14B-Thinking 모델은 교사 모델과 대형 공개 모델들까지 모두 능가.
5.1. Test-Time Scaling in Practice: IOI 2025
Nemotron-Cascade-14B-Thinking을 128K 사고 예산으로 IOI 2025에 적용하고, 공식 채점 피드백을 반복적으로 반영하는 다중 라운드 생성-선택-제출 기반의 테스트 시 스케일링 파이프라인 제안. -> 이 방식으로 최대 50회 제출 제약 내에서 343.37점을 달성해 은메달 수준 성과 기록, 특히 문제 2 Triples에서는 기존 대형, 전문 모델들을 능가해 피드백 기반 자기개선형 추론의 효과를 입증.
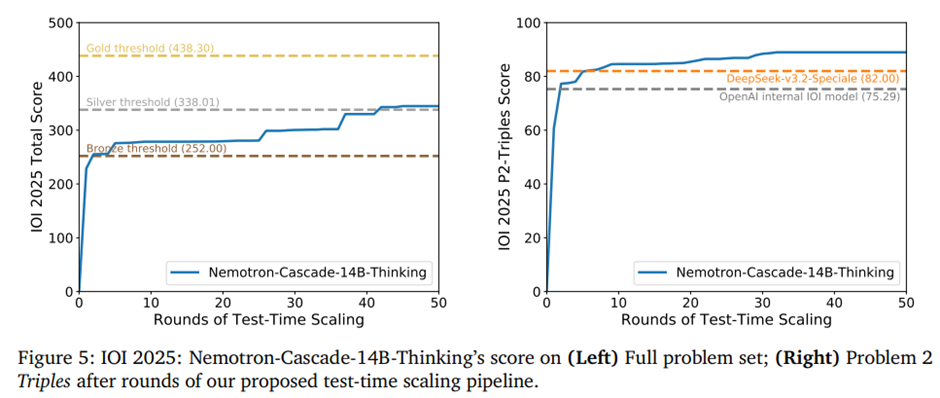
라운드별 성능 향상 과정.
5.2. The Role of Training Temperature in Code RL
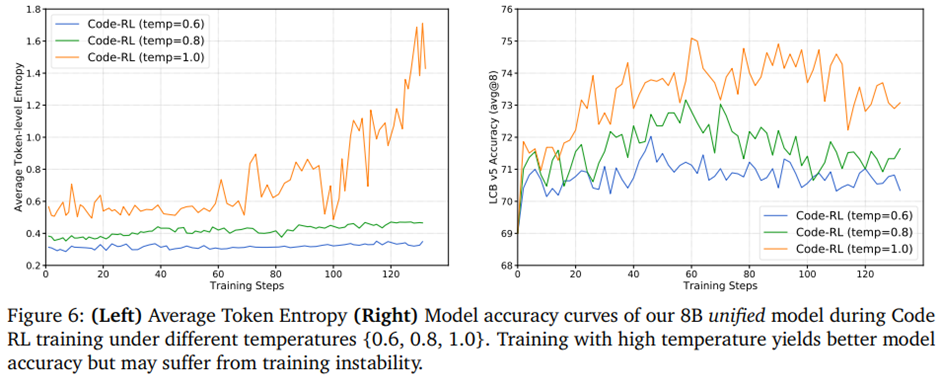
학습 곡선.
Code RL에서 temperature 0.6, 0.8, 1.0을 비교한 결과, 낮은 temperature는 학습 안정성은 높지만 코드 추론 성능이 떨어짐.
코드 생성처럼 탐색 공간이 큰 문제에서는 높은 temperature가 탐색과 샘플 효율을 높여 성능을 개선하지만, 엔트로피 폭발로 인한 불안정성을 동반할 수 있음.
5.3. How Cascade RL Improves Code Reasoning
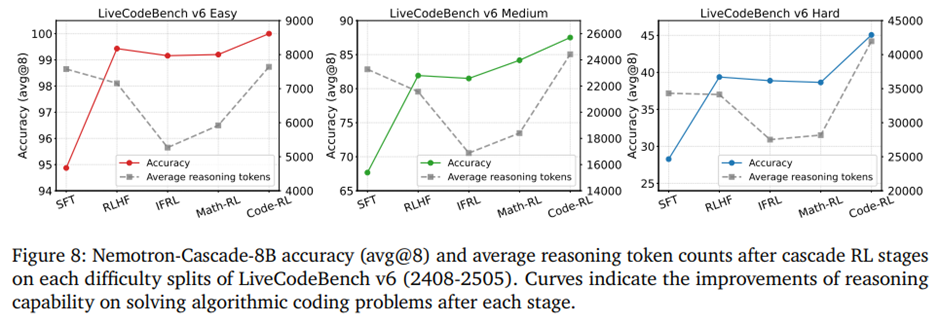
통합 8B 모델을 대상으로 SFT, RLHF, IF-RL, Math RL, Code RL의 연속적인 cascade RL 단계 이후 LiveCodeBench v6의 각 난이도 분할에서 평균 추론 토큰 사용량과 모델 정확도 분석. -> RLHF 단계가 가장 강력한 기초 역할을 하며 추론 토큰 사용량을 크게 줄이면서 모든 난이도에서 정확도를 동시에 향상.
IF-RL은 정확도 손실이 거의 없는 상태에서 추론을 더 간결하게 만들어 토큰 사용량을 추가로 약 20% 감소.
쉬운 문제는 초기 단계에서 이미 성능이 포화되고, 이후 성능 개선은 중간, 어려운 문제에 집중
Math RL은 추론 토큰을 늘려 중간 난이도 문제의 정확도를 개선하고, Code RL은 추론 흔적을 크게 확장해 중간 및 어려운 문제에서 최종 성능을 끌어올림.

Cascade RL 각 단계 이후 통합 8B 모델의 주제별 정확도. 주제별 분석에서는 RLHF가 전 범주에서 초기 성능 향상을 제공하고, Math RL은 수학, 그래프, 기하 중심으로 효과를 보이며, Code RL은 거의 모든 주제에서 가장 큰 성능 향상.
6. Deep Dive on RLHF
대규모 보상 모델을 사용한 RLHF가 ArenaHard에서 가장 강력한 성능을 보이고, 특히 스타일 제어 환경에서 내용 품질과 스타일 선호를 효과적으로 분리.
소형 보상 모델은 보상 신호의 잡음이 커 학습 불안정성이 나타나기 쉬워 보상 셰이핑이나 KL 정규화 같은 추가 안정화 기법 필요. 대형 보상 모델은 보상 신호가 충분히 정확하고 일관적이어서 별도의 안정화 기법 없이도 안정적인 RLHF 학습이 가능하고, 다른 과제 성능까지 함께 향상.
6.1. RLHF Training Strategies for Unified Models

사고 모드만 또는 비사고 모드만으로 RLHF를 하는 것보다, 두 모드를 배치마다 절반씩 섞는 Half-Half 전략이 ArenaHard, 수학(AIME), 코드(LiveCodeBench) 전반에서 가장 좋은 성능을 보임. -> 비사고 모드 샘플이 모드 간 전이를 돕고 전반적인 정렬과 일반화 능력을 강화해 줌.
6.2. Impact of Reward Model Size on RLHF Performance
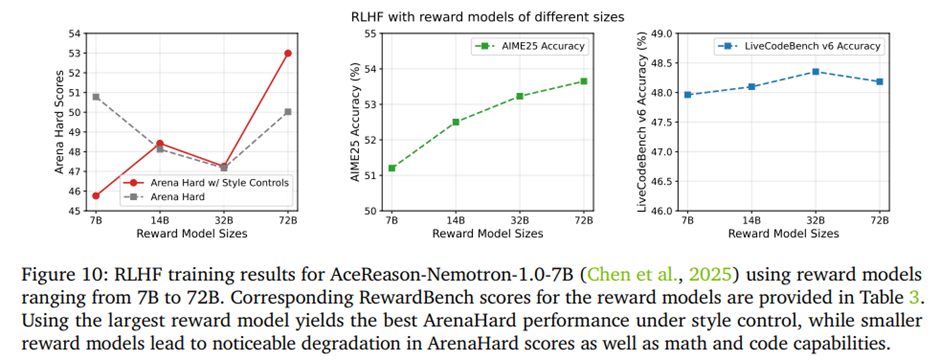
ArenaHard 점수와 함께 수학 및 코드 벤치마크 성능.
보상 모델이 클수록 RLHF 효과가 커지고, 특히 72B 보상 모델은 ArenaHard에서 가장 강력한 성능을 달성하고 스타일 제어 환경에서도 안정적인 개선. 7B 보상 모델은 보상 해킹(예: 출력 길이 늘리기)에 취약해 성능이 왜곡되기 쉬움.
RewardBench 점수는 보상 모델 품질의 대리 지표이긴 하지만, 높은 점수가 항상 더 나은 RLHF 결과(ArenaHard 향상)로 이어지지는 않음. 일정 수준 이상에서는 포화되고, 실제로는 보상 해킹 취약성 같은 모델 행동 특성이 더 중요.
대형 보상 모델을 사용한 RLHF는 수학 성능(AIME25)을 추가로 개선하는 효과가 있었고, 코드 벤치마크에서는 보상 모델 크기에 따른 차이는 비교적 작음.
6.3. Bag of Tricks for Stablizing RLHF Training
장문 cot 추론을 위한 RLHF는 보상 노이즈와 분포 밖 보상 때문에 초기 붕괴와 학습 불안정이 자주 발생.
-
KL penalty loss: 온라인 정책이 참조 정책에서 과도하게 벗어나는 것을 억제해 초기 붕괴를 막는 데 효과적이고, 불안정 징후가 있을 때 특히 유용.
-
Policy gradient loss aggregation: 장문 추론에서는 토큰 단위 손실이 일반적으로 적합하지만, RLHF 초기에 붕괴 조짐이 보이면 시퀀스 단위 손실로 전환하면 응답 길이 폭증을 억제하고 안정화에 도움.
-
Reward shaping: Bradley-Terry 기반 보상의 무한 범위와 이상치 문제를 완화하기 위해, 그룹별 정규화 후 tanh로 [-1, 1]로 제한하면 노이즈 영향을 줄이고 안정적인 업데이트.
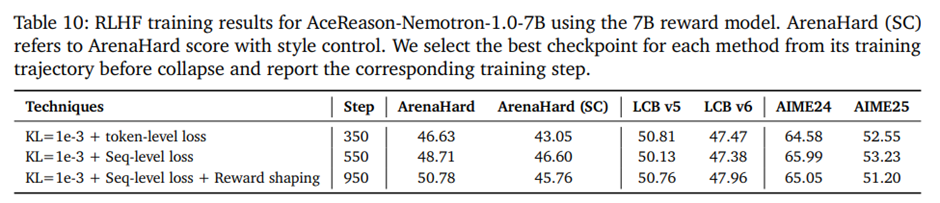
안정적으로 학습이 유지되는 RL 스텝 수가 350에서 950으로 늘어나고, ArenaHard 점수 향상.
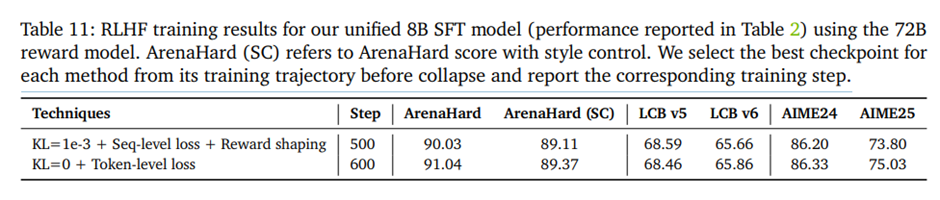
더 강력한 보상 모델(예: 72B 보상 모델)을 사용하는 경우에는 RLHF 학습 자체가 이미 안정적이기 때문에 다운스트림 성능이 유사하거나 경우에 따라서는 오히려 약간 더 나은 결과.
-> takeaway: 이러한 기법들은 학습이 불안정해지는 징후가 나타날 때에만 선택적으로 사용하는 도구 상자로 간주해야함. 그렇지 않은 경우에는 §4.3.2에서 설명한 RLHF 레시피만으로도 충분.
7. Deep Dive on SWE
7.1. Generation–Retrieval Approach for Code Localization
코드 로컬라이제이션 단계에서 생성 기반 추론과 검색 기반 검색을 결합한 이중 접근법 사용.
생성 기반 방법: 이슈 설명과 저장소 구조를 바탕으로 모델이 버그 가능 파일을 추론, 여러 롤아웃 결과를 집계해 등장 빈도가 높은 파일을 상위에 배치. -> 일관성 있는 후보 강조.
검색 기반 방법: 생성 기반의 한계를 보완하기 위해, 실제 코드 내용을 인코딩하는 NV-Embed-Code 임베딩 모델을 사용해 문제 맥락과 의미적으로 유사한 파일 검색.
두 방법의 결과를 상호 순위 결합(reciprocal rank fusion, k=0)으로 통합해 구조적 신호와 의미적 신호의 장점을 동시에 활용.
평가를 위해 상위 k개 결과 안에 수정이 필요한 모든 정답 파일이 포함되면 성공으로 간주하는 재현율(top-k recall) 사용.
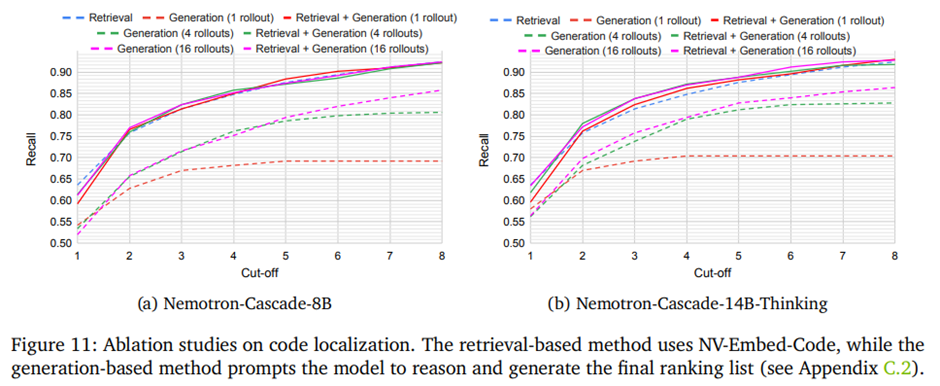
SWE-bench Verified 벤치마크에서 서로 다른 코드 로컬라이제이션 접근법들의 성능.
-> 검색 기반 방법이 단독으로는 생성 기반보다 성능이 높고, 생성 기반은 다중 롤아웃 집계를 통해 상, 하위 순위 전반에서 성능과 다양성 개선. 두 방법을 결합하면 특히 top-5 이하 구간에서 추가적인 성능 향상.
7.2. Execution-Free Reward Model for SWE RL
SWE 코드 수리 RL에서는 실제 코드를 실행하지 않고, 모델이 생성한 패치와 인간 정답 패치 간의 유사도를 보상으로 사용하는 execution-free 보상 모델 사용.
보상은 두 방식: 1) Unidiff 기반의 어휘적 유사도(lexical similarity), 2) Kimi-Dev-72B가 판단한 의미적 유사도(semantic similarity).
실험 설정: 수학, 코드 RL 이전의 14B 중간 모델을 초기화 모델로 사용, 두 유사도를 각각 보상으로 적용한 코드 수리 RL을 수행. 평가 시에는 (i) 정답 로컬라이제이션 파일 제공, (ii) 생성–검색으로 얻은 상위 4개 파일 제공의 두 조건 비교.
-> RL 학습 자체가 코드 수리 성능을 전반적으로 향상시키고, 어휘적 유사도보다 의미적 유사도를 보상으로 사용할 때 성능이 더 높음, 보상 값이 0.5 미만일 때 0으로 만드는 보상 셰이핑은 어휘적 유사도 보상에서는 성능을 개선하지만, 의미적 유사도 보상에서는 추가적인 이점이 거의 없음. -> 어휘적 유사도가 낮을 때 노이즈가 크기 때문.
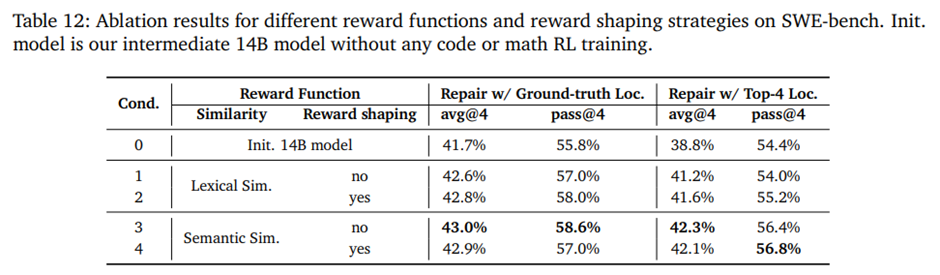
SWE RL 학습에서는 cond. 3에 해당하는 기본 보상 함수 설정을 최종적으로 사용.
7.3. Improving Long-Context Analysis
여러 파일을 포함한 장문 프롬프트가 필요하지만, 입력이 24K를 넘고 응답이 16K일 때 코드 해결률이 급격히 떨어지는 문제가 발생 -> SFT 단계의 32K 컨텍스트 한계에서 비롯된 것.
RL 단계에서 정답 파일과 검색된 노이즈 파일을 혼합한 더 긴 프롬프트로 학습 데이터를 구성해 장문 컨텍스트 적응 유도.
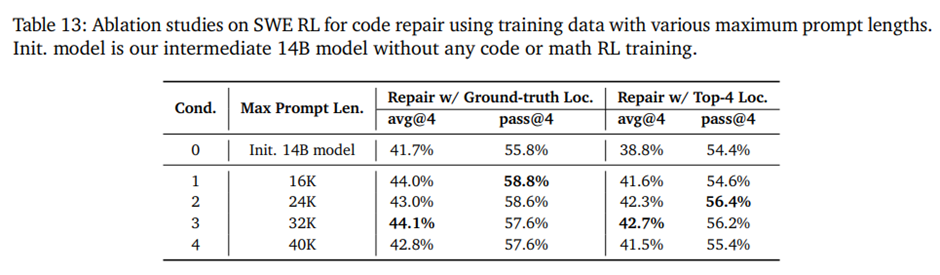
서로 다른 최대 프롬프트 길이로 생성된 데이터로 학습을 수행한 결과 어블레이션.
최대 프롬프트 길이를 16K -> 32K로 늘리면 코드 수리 성능이 개선되었으나, 40K까지 확장하면 오히려 성능이 저하. -> 지나치게 긴 컨텍스트에서의 노이즈 증가 또는 Qwen3 기반 모델의 32K 수준 장문 처리 한계 때문.
-> 최종 학습에서는 8B 모델은 최대 24K, 14B 모델은 최대 32K 프롬프트 길이 사용.
7.4. Test-Time Scaling and Patch Validation
추론 단계에서 여러 후보 패치를 생성하고, 테스트 기반 검증으로 이를 필터링, 선택하는 TTS 전략 적용.
best@k 전략: 후보 패치를 회귀 테스트 통과 수와 재현 테스트 결과로 순위화해 선택, 동점 시 다수결과 해답 길이 기준.
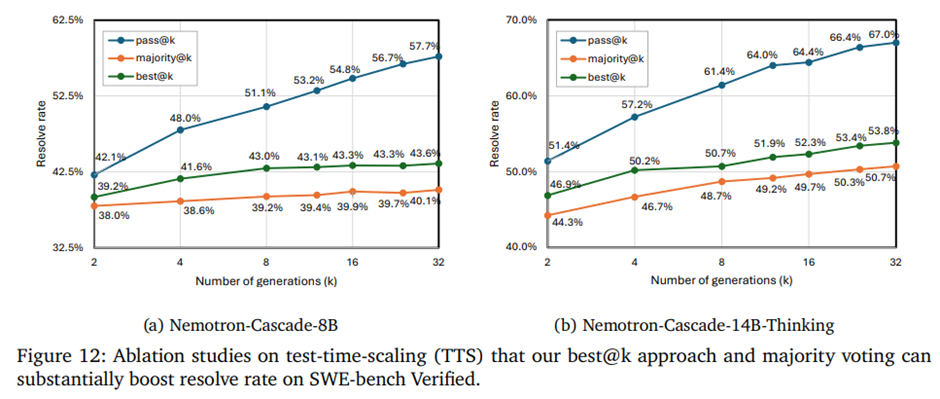
(a) Nemotron-Cascade-8B와 (b) Nemotron-Cascade-14B-Thinking을 대상으로 패치 검증(patch-validation) 파이프라인과 결합한 테스트 시 스케일링(TTS)을 사용하여 SWE-bench Verified에서 평가한 결과.
pass@k는 k 증가에 따라 꾸준히 상승하지만, 단순 다수결은 빠르게 포화. best@k는 항상 다수결보다 높은 성능을 보여 패치 검증의 효과 입증.
8B 모델도 TTS로 해결률이 크게 향상, 14B-Thinking 모델은 더 큰 폭의 개선을 보이고 대형 오픈 모델들과 경쟁적인 성능.
8. Related Work
8.1. Reinforcement Learning for LLMs
RLHF의 역할: RLHF는 SFT, 지시 튜닝 이후 LLM을 인간 선호에 더 잘 맞추는 핵심 기법으로, 고비용 주석이 필요한 SFT보다 효율적으로 인간 의도와 언어 뉘앙스를 학습할 수 있음.
보상 모델 기반 RL의 한계: 수학 추론 등에서는 보상 모델링의 어려움 때문에 RLHF의 성과가 제한적.
RLVR의 부상: 규칙, 실행 기반의 검증 가능한 보상을 사용하는 RLVR은 수학, 코드 추론에서 큰 성공을 거두었고, 여러 공개 레시피들이 등장했지만 주로 특정 도메인에 집중되어 있음.
기존 일반 목적 RL의 문제점: DeepSeek-R1, Qwen3처럼 추론 중심 단계와 전 도메인 단계를 나누는 방식은 작업 이질성으로 인해 학습 설계가 복잡해지고 성능이 하위 최적에 머물기 쉬움.
본 연구의 위치: Cascade RL 프레임워크를 통해 다양한 도메인을 단계적으로 학습하는 일반 목적 추론 LLM을 제안하고, RLHF와 RLVR의 상호작용을 체계적으로 분석.
알고리즘, 안정화 기법 맥락: PPO, DPO, GRPO 등 다양한 RL 알고리즘과 온/오프폴리시, 손실 집계 방식, 커리큘럼 학습, 길이 초과 필터링 등 기존 연구 흐름 위에 본 연구가 위치.
8.2. Supervised Fine-Tuning and Distillation
SFT의 역할: 지도 미세조정은 사전학습 LLM을 대화·지시 이행 등 다양한 과제에 적응시키는 필수적인 초기 단계.
디스틸레이션 접근: 대형 RL 교사 모델의 추론 능력을 소형 모델로 이전하기 위해 오프폴리시 디스틸레이션이 널리 사용되며, 비용은 크지만 데이터 재사용성과 학습 효율성이 높음.
온폴리시 디스틸레이션: 학생 모델이 직접 샘플을 생성하는 방식으로, 온폴리시 RL로 학습된 모델과의 성능 격차를 줄이기 위해 보완적으로 활용.
SFT-RL 시너지: RL은 SFT 모델 위에서 적용될 때 효과가 크며, 탐색과 활용의 균형이 맞춰지면 초기 SFT 성능 차이는 RL 과정에서 상당 부분 해소됨.
8.3. Unified Reasoning Models
배경: 최근 LLM 연구의 핵심 목표는 깊은 추론 능력을 갖춘 일반 목적 모델을 만드는 것이며, 이를 위해 장문 CoT에 특화된 전용 사고(thinking) 모델들이 다수 등장.
전용 사고 모델의 한계: 이러한 모델들은 강력한 추론을 제공하지만, 지시 이행(instruct)과의 분리가 사용성과 유연성 제한.
통합 추론 모델의 흐름: 최근 연구들은 사고 모드와 지시 모드를 하나의 모델로 통합하려는 방향으로 발전하고 있음.
통합 방식의 다양성: 시스템 프롬프트 기반 전역 제어(Llama-Nemotron), 턴 단위 모드 전환(Qwen3, GLM-4.5, DeepSeek-V3.1), 자동 라우팅(GPT-5) 등 다양한 접근이 제안됨.
의의: 통합 추론 모델은 강한 추론 능력과 실용적 지시 이행을 동시에 달성하려는 최신 LLM 발전 방향을 대표.
