📄 Paper
Recommender Systems with Generative Retrieval [arxiv]
Shashank Rajput NeurIPS 2023
📝 Key Point
- Generative Retrieval 모델인 TIGER를 제안하여 추천 시스템에서 후보 아이템을 효과적으로 검색하는 방법을 제시한다.
- 아이템의 콘텐츠 임베딩을 기반으로 하는 Semantic ID를 생성하기 위해 RQ-VAE를 사용한다.
- TIGER는 별도의 인덱스를 생성하지 않고, Transformer 메모리를 의미적 인덱스로 활용하여 메모리 효율성이 높다.
- TIGER는 새로운 아이템에 대해서도 잘 일반화할 수 있으며, 콜드 스타트 문제를 해결하는 데 유리하다.
Abstract
기존 방식 : 기존의 추천 시스템은 쿼리와 아이템 후보를 같은 공간에 임베딩하고, 근접 이웃 검색으로 상위 후보를 선택한다.
제안된 접근 방식 : 논문에서 제안하는 생성적 검색 모델은 자동 회귀적으로 candidates의 식별자를 디코딩하며, 각 아이템에 대한 Semantic ID를 생성한다.
모델 훈련 : 사용자 세션 내 아이템의 Semantic ID를 바탕으로, Transformer 기반의 Seq2Seq 모델을 훈련하여 사용자가 다음에 상호작용할 아이템의 Semantic ID를 예측한다.
성과 : 다양한 데이터셋에서 SOTA 모델보다 매우 우수한 성능을 보이며, Semantic ID의 통합으로 일반화 능력이 향상되고, 이전 상호작용 기록이 없는 아이템의 검색 성능도 개선된다.
Figure
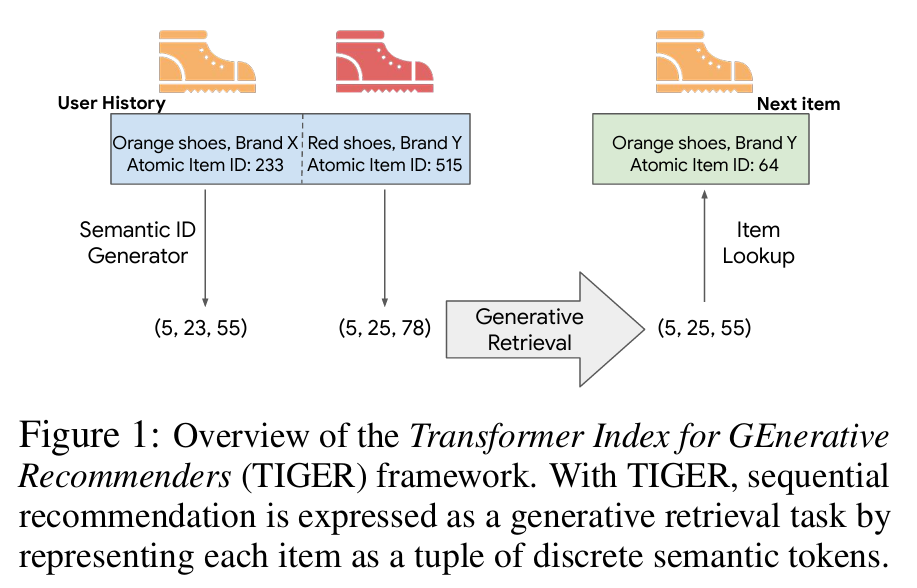
TIGER를 사용하면 Sequential Recommendation은 각 아이템을 개별 Semantic 토큰의 튜플로 표시하여 생성 검색 작업으로 표현된다.
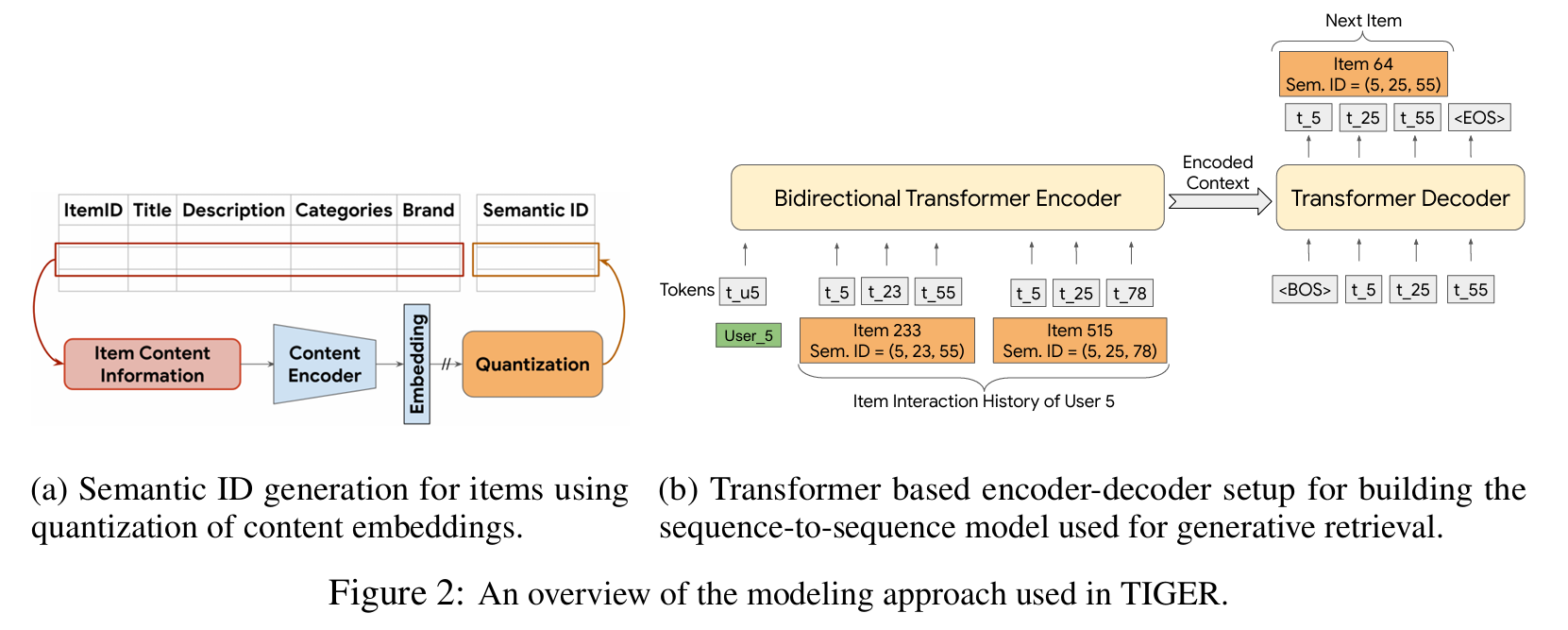
(a) 콘텐츠 임베딩의 quantization을 이용한 아이템에 대한 Semantic ID 생성
(b) 생성 검색에 사용되는 Seq2Seq 모델을 구축하기 위한 Transformer 기반 인코더-디코더 설정
1. Introduction
기존 접근 방식 : 현대 추천 시스템은 검색 및 순위 매기기 전략을 채택하며, 검색 단계에서 후보 아이템을 선택하고, 이후 순위 모델을 통해 이를 평가한다. 이 과정에서 검색 단계에서 높은 관련성을 가진 후보가 필요하다.
기존 모델의 한계 : 기존의 검색 모델은 행렬 분해 및 이중 인코더 구조를 사용하여 쿼리와 후보의 임베딩을 생성하지만, 이러한 방법은 비선형성을 잘 포착하지 못할 수 있다.
제안된 방법론 : 이 논문은 생성적 검색 모델을 기반으로 하는 새로운 패러다임인 TIGER를 제안한다. TIGER는 아이템의 Semantic ID를 직접 예측하는 end-to-end 생성 모델을 사용한다. Semantic ID는 아이템의 콘텐츠 정보에서 파생된 토큰의 시퀀스로 정의된다.
장점 : Semantic 토큰으로 아이템을 표현함으로써 유사한 아이템 간의 지식 공유가 가능해지고, 기존의 랜덤한 아이템 ID를 대체할 수 있다. 또한, 새로운 아이템에 대한 추천 성능이 향상되고, 다양한 추천을 생성할 수 있는 능력이 추가된다.
3. Proposed Framework
-
Semantic ID 생성: 아이템의 콘텐츠 특징을 인코딩하여 임베딩 벡터를 생성하고, 이를 quantization하여 튜플 형태의 아이템 Semantic ID를 만든다.
-
Semantic ID를 통한 생성적 추천 시스템 훈련: Semantic ID 시퀀스를 사용하여 Sequential Recommendation을 위한 Transformer 모델을 훈련한다.
3.1 Semantic ID 생성
Semantic ID 생성 과정은 추천 데이터베이스의 아이템에 대한 콘텐츠 특징을 활용한다. 각 아이템은 유용한 의미 정보를 담고 있는 콘텐츠 특징(제목, 설명, 이미지 등)을 가지고 있다고 가정한다. 사전 훈련된 콘텐츠 인코더를 사용해 Semantic 임베딩을 생성하고, 이 임베딩을 quantization하여 Semantic ID를 생성한다. Semantic ID는 서로 다른 코드북에서 온 코드워드의 튜플로 정의되며, 유사한 아이템은 겹치는 Semantic ID를 가져야 한다.
RQ-VAE를 통한 Semantic ID : RQ-VAE(Residual-Quantized Variational AutoEncoder)는 Residual quantization을 적용하여 코드워드의 튜플을 생성하는 다단계 벡터 quantization 기법이다. Autoencoder는 quantization 코드북과 DNN 인코더-디코더 파라미터를 함께 훈련한다. RQ-VAE는 입력을 인코딩하여 잠재 표현을 학습하고, 여러 단계에서 Residual quantization을 통해 Semantic ID를 생성한다.
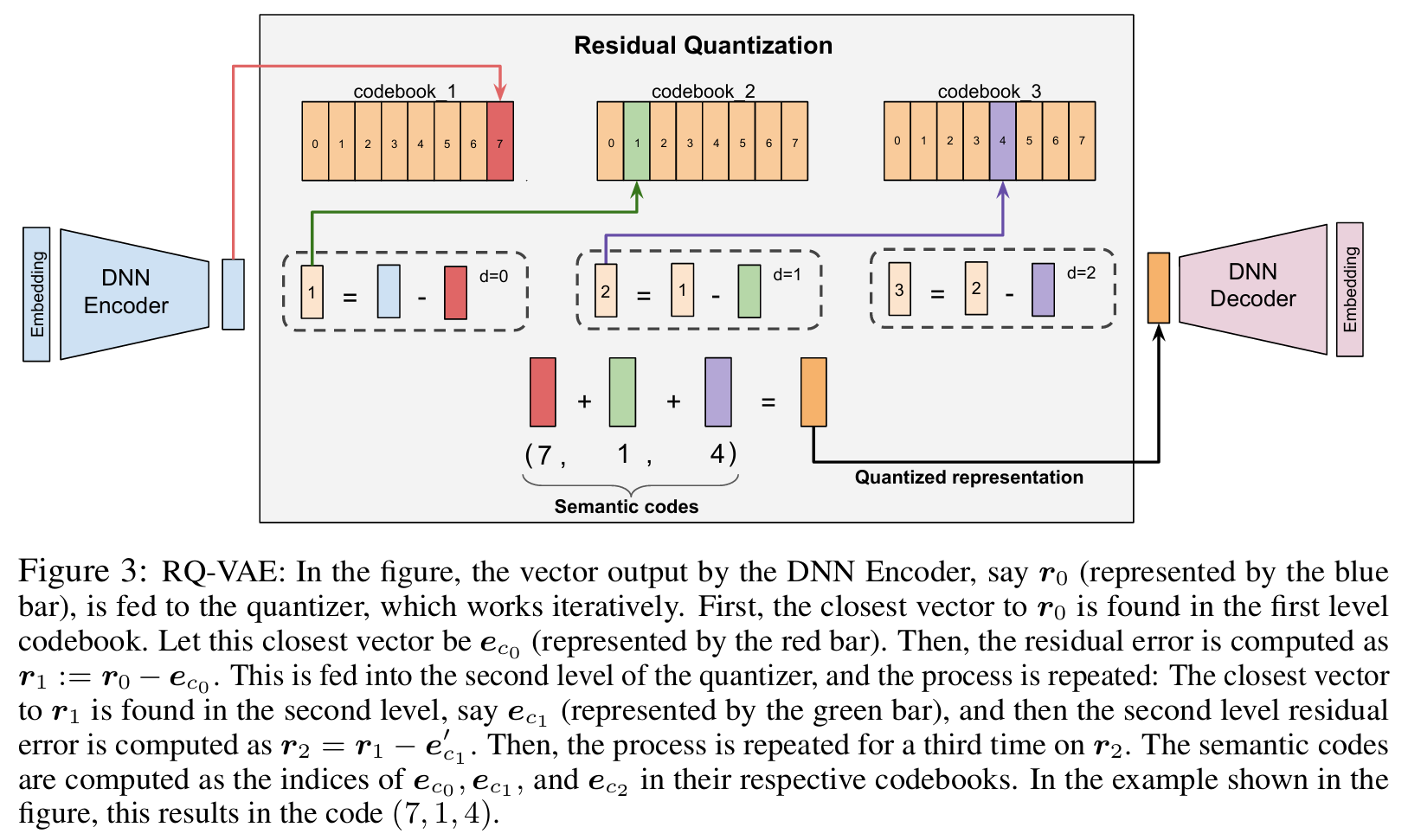
3.2 Semantic ID를 통한 생성적 검색
사용자의 아이템 상호작용을 시간 순서대로 정렬하여 아이템 시퀀스를 구성하고, 추천 시스템의 목표는 다음 아이템을 예측하는 것이다. Seq2Seq 모델은 n+1번째 아이템의 Semantic ID를 예측하도록 훈련되며, 생성된 Semantic ID가 추천 데이터베이스의 아이템과 일치하지 않을 가능성이 있지만, 이러한 사건이 발생할 확률은 낮다.
4. Experiments
RQ-VAE 구현 세부사항
RQ-VAE는 아이템의 Semantic 임베딩을 quantization하는 데 사용된다. Sentence-T5 모델을 활용해 각 아이템의 콘텐츠 특징을 임베딩하고, 이를 통해 생성된 Semantic ID는 4개의 코드워드를 가진다. RQ-VAE 모델은 DNN 인코더, Residual quantizer, DNN 디코더로 구성되며, 20,000 에폭 동안 훈련된다.
Seq2Seq 모델 구현 세부사항
Transformer 기반의 인코더-디코더 아키텍처를 사용하며, 각 아이템의 Semantic 코드워드를 표현하기 위해 1024개의 토큰을 포함한 어휘를 사용한다. 모델은 200,000 스텝 또는 100,000 스텝 동안 훈련되며, 약 1,300만 개의 파라미터를 가진다.
Sequential Recommendation 성능 평가
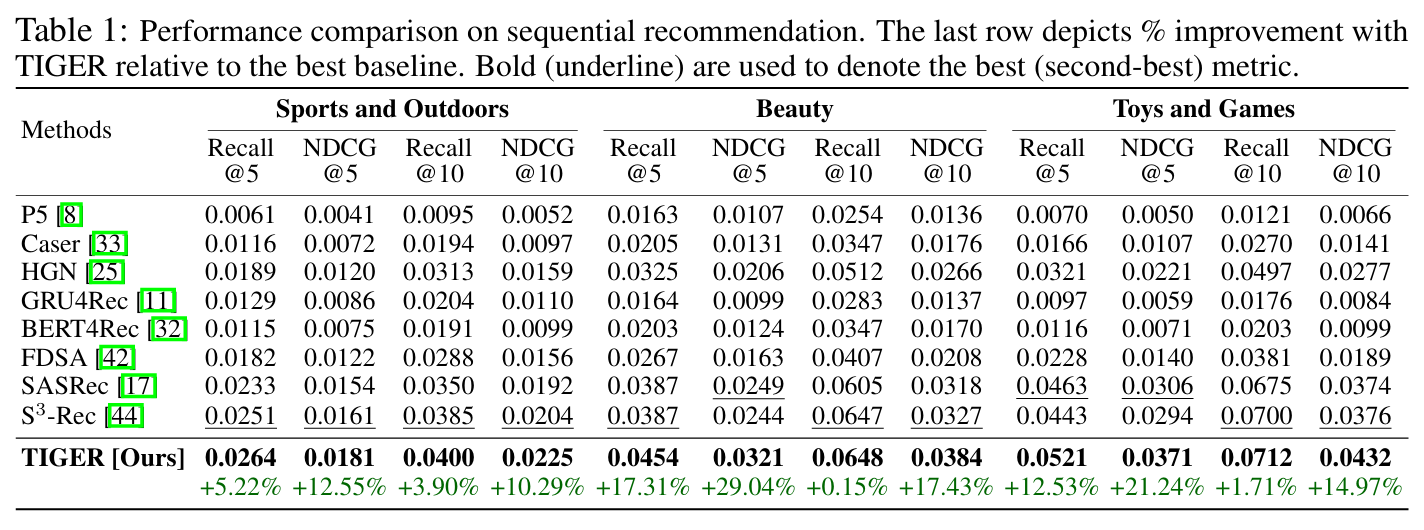
Generative Retrieval 아이템 표현 성능 평가
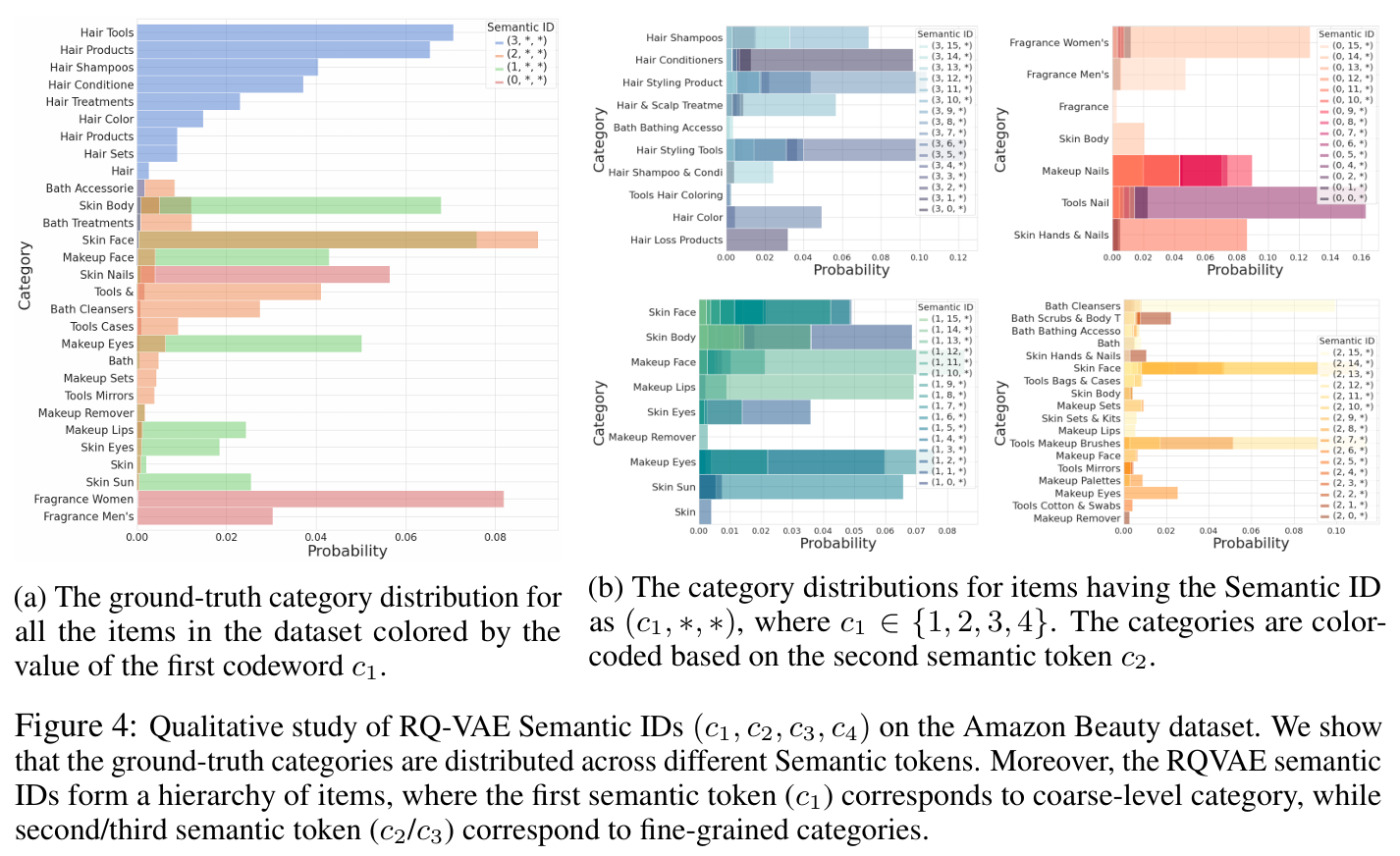
RQ-VAE의 Semantic ID의 계층적 특성을 분석하고, RQ-VAE가 LSH(Locality Sensitive Hashing)보다 더 우수한 성능을 보임을 입증한다. 랜덤 ID와 Semantic ID를 비교하여, Semantic ID가 콘텐츠 기반 정보를 활용하는 데 있어 중요함을 강조한다.
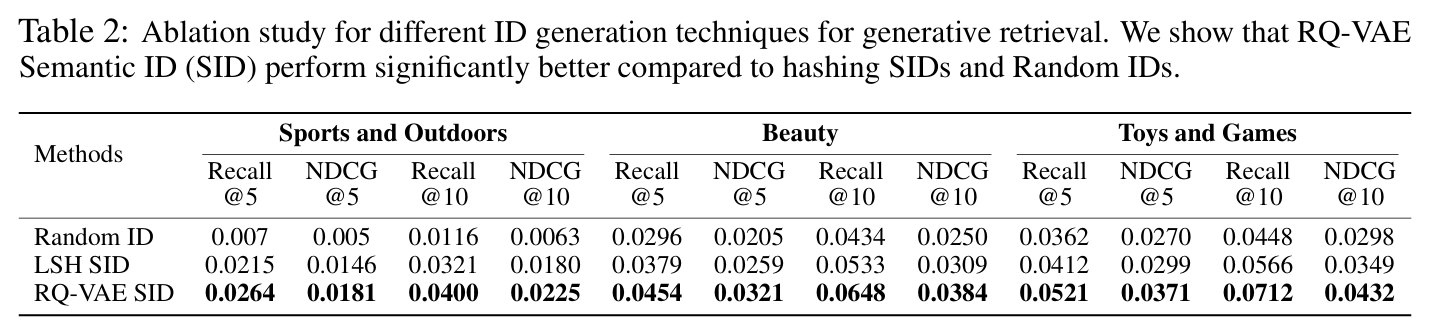
TIGER의 새로운 기능
콜드 스타트 추천 : TIGER 프레임워크는 다음 항목을 예측할 때 항목 의미 체계를 활용하기 때문에 콜드 스타트 권장 사항을 쉽게 수행할 수 있다. 새로운 아이템 추천에 효과적이다.
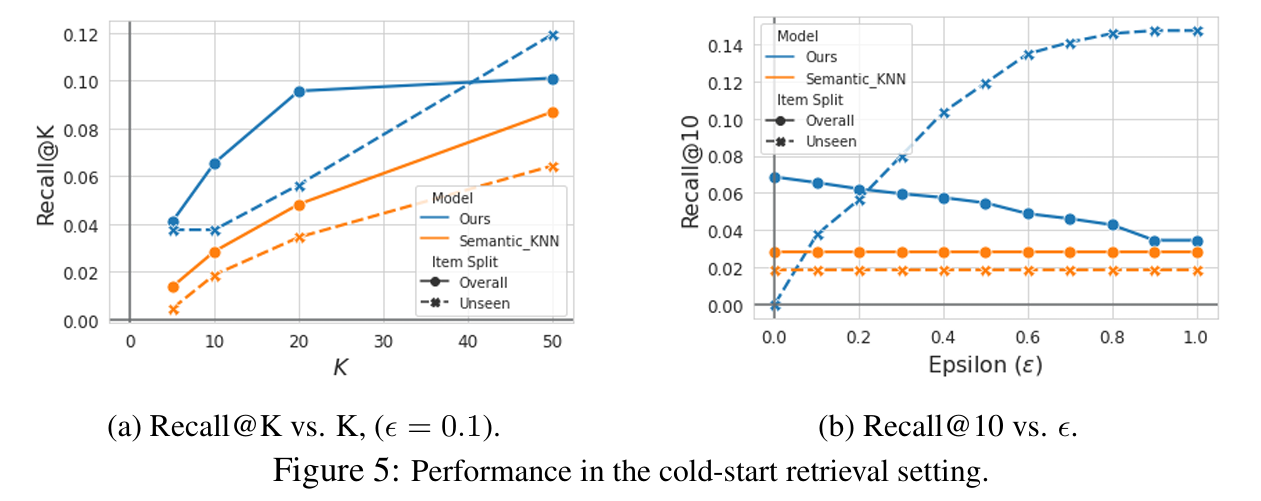
추천 다양성 : 디코딩 프로세스 중 온도 기반 샘플링이 모델 예측의 다양성을 제어하는 데 효과적으로 사용될 수 있다.
무효 ID 처리
무효 ID가 생성될 경우, prefix 매칭을 통해 모델이 생성한 의미적 ID의 토큰과 유사한 의미를 가진 아이템을 검색하는 방법을 제안한다.
5. Conclusion
TIGER라는 새로운 패러다임을 제안하여 추천 시스템에서 후보 아이템을 생성 모델을 사용해 검색하는 방법을 소개한다. 이 방법은 아이템에 대한 Semantic ID 표현을 기반으로 하며, 콘텐츠 임베딩에 대해 계층적 quantizer(RQ-VAE)를 사용하여 Semantic ID를 구성하는 토큰을 생성한다.
TIGER 프레임워크는 인덱스를 생성하지 않고도 훈련 및 서비스에 사용될 수 있으며, Transformer 메모리가 아이템에 대한 Semantic 인덱스 역할을 한다. 임베딩 테이블의 크기는 아이템 공간의 크기에 비례하여 증가하지 않기 때문에 대규모 임베딩 테이블을 생성해야 하는 시스템보다 유리하다.
세 가지 데이터셋에 대한 실험을 통해 TIGER 모델이 SOTA 검색 성능을 달성하며, 새로운 아이템에 대해서도 일반화할 수 있음을 입증한다.
