[논문] TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation [arxiv]
Keqin Bao ACM RecSys 23
📝 Key Point
- LLM을 추천 작업에 효과적으로 통합하기 위해 TALLRec 프레임워크를 제안한다.
- TALLRec 프레임워크는 Alpaca Tuning과 Rec-Tuning의 두 단계로 구성된다.
- TALLRec 프레임워크로 훈련된 LLM은 전통적인 추천 모델과 In-context Learning 기반 LLM 보다 더 우수한 성능을 나타냈고, 강력한 cross-domain 일반화 능력을 보여줬다.
Abstract
연구 배경 : 추천 시스템에서 LLM 연구가 진행되고 있으나, 성능이 충분하지 않다.
문제점 : LLM의 훈련 작업과 추천 작업 간의 큰 격차가 존재하며, 추천 데이터가 pre-training에 부적합하다.
제안된 방법 : 추천 데이터를 활용하여 LLM을 조정하는 "대규모 추천 언어 모델"을 구축하였고, 이를 위해 효율적이고 효과적인 조정 프레임워크인 TALLRec를 제안한다.
주요 결과 : TALLRec은 영화와 도서 분야에서 LLM의 추천 능력을 크게 향상시킬 수 있음을 보여준다. 특히, 데이터셋이 100개 미만인 경우에도 효과를 발휘하며, 단일 RTX 3090에서 LLaMA-7B 모델로 실행이 가능하다. 또한, 조정된 LLM은 강력한 도메인 간 일반화 능력을 갖추고 있다.
Figure
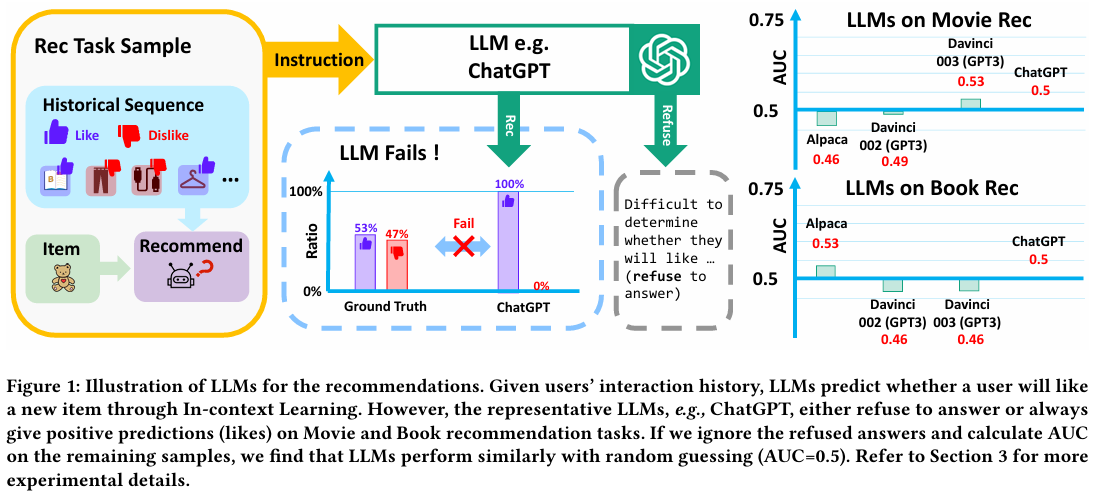
사용자의 상호작용 데이터가 주어지면 LLM은 In-context Learning을 통해 새로운 아이템을 사용자가 좋아할지 예측한다. 하지만 ChatGPT 같은 대표적인 LLM들은 답변을 거부하거나 항상 긍정적인 예측을 했다.
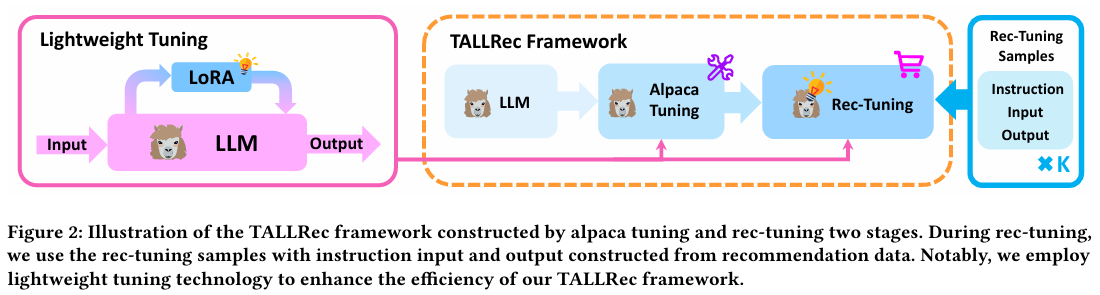
TALLRec 프레임워크는 Alpaca Tuning과 Rec-Tuning의 두 단계로 구성된다. Rec-Tuning 단계에서는 추천 데이터로 구성된 input과 output Instruction을 샘플로 사용한다. 또한, 효율성 향상을 위해 Lightweight Tuning 기법을 사용한다.
1. Introduction
LLM의 능력 : LLM은 풍부한 지식과 일반화 능력을 가지고 있으며, 적절한 Instruction을 통해 처음 보는 작업을 해결할 수 있다.
추천 분야 : LLM의 특성은 추천 시스템에서 강력한 일반화와 풍부한 지식을 요구하는 문제를 해결할 수 있지만 추천 시스템에 LLM을 통합하는 연구는 제한적인 관심을 받았다.
초기 시도의 한계 : 초기에는 LLM을 전통적인 추천 모델의 도구로 사용하여 후보 아이템을 재정렬하는 방식이었으나, 성능이 전통 모델과 유사한 수준에 그쳤다. In-context Learning 만으로는 추천이 어려울 수 있다.
문제 원인 : LLM 훈련에 사용된 언어 처리 작업과 추천 작업 간의 큰 차이가 있다. 기존 추천 모델의 한계로 인해 후보 리스트가 제한된다.
제안된 해결책 : Large Recommendation Language Model(LRLM)을 구축한다. LLM을 추천 작업에 맞게 조정하는 경량 조정 프레임워크인 TALLRec을 제안한다. TALLRec은 추천 데이터를 Instruction으로 구조화하고 LLM을 조정하여 효율적으로 실행된다.
실험 결과 : TALLRec 프레임워크를 사용하여 영화와 도서 분야에서 LLM이 전통적인 추천 모델과 GPT-3.5보다 우수한 성능을 보였다.
기여 : LLM과 추천을 통합하는 새로운 문제를 연구하고 In-context Learning 기반 접근 방식의 한계를 밝혔다. TALLRec 프레임워크를 통해 LLM을 추천에 효과적으로 통합할 수 있는 방법을 제시했다. 다양한 도메인에서의 강력한 일반화 능력을 입증했다.
2. TALLRec
2.1 Preliminary
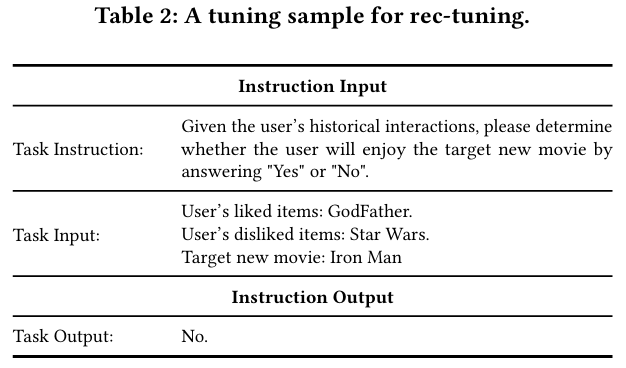
-
Instruction Tuning
LLM을 사람이 작성한 Instruction과 response로 훈련한다.
Step 1 : Task를 정의하고, 자연어로 "Task Instruction" 작성한다.
Step 2 : "Task input"과 "Task output"을 자연어로 형식화한다.
Step 3 : "Task Instruction"과 "Task input"을 결합하여 "Instruction input"을 생성하고, "Task output"을 "Instruction output"으로 사용한다.
Step 4 : LLM을 "Instruction input"과 "Instruction output"의 쌍으로 조정한다. -
Rec-tuning Task Formulation
- LLM을 활용하여 사용자가 새로운 아이템을 좋아할지 예측하는 LRLM을 구축한다.
- 추천 데이터를 Instruction Tuning 패턴으로 형식화하여 사용한다.
- 사용자의 과거 상호작용을 기반으로 새로운 아이템에 대한 이진 응답(예/아니오)을 생성하는 "Task Instruction"을 작성한다.
2.2 TALLRec Framework
-
TALLRec의 목적
- LLM을 추천 작업과 효과적이고 효율적으로 조화시키기 위한 프레임워크이다.
- 낮은 GPU 메모리 소비 환경에서 작동하도록 설계되었다.
-
TALLRec Tuning Stages
- Alpaca Tuning : LLM의 일반화 능력을 향상시키기 위한 과정으로, self-instruct 데이터를 활용한다.
- Rec-tuning : 추천 작업을 위한 LLM 튜닝 단계로, Alpaca Tuning과 유사한 방식으로 진행한다.
-
Lightweight Tuning
- LLM 튜닝이 계산 집약적이고 시간 소모적이므로 경량 튜닝 전략을 제안한다.
- LoRA를 사용하여 사전 학습된 모델의 매개변수를 고정하고, 각 레이어에 학습 가능한 행렬을 도입하여 효율적으로 튜닝한다.
-
Backbone Selection
- 다양한 LLM이 존재하지만, 많은 모델이 매개변수나 API에 접근할 수 없어 활용이 어렵다.
- 데이터 보안 문제도 중요하므로, 공개 LLM인 LLaMA를 선택하여 추천 목적에 맞게 매개변수를 업데이트하고 실험을 진행했다.
3. Experiments
Research Question
- RQ1 : TALLRec의 성능은 현재 LLM 기반 및 전통적인 추천 모델과 어떻게 비교되는가?
- RQ2 : TALLRec의 다양한 구성 요소가 효과성에 어떤 영향을 미치는가?
- RQ3 : TALLRec는 교차 도메인 추천에서 어떻게 수행되는가?
Baseline
- LLM 기반 방법 : In-context Learning을 사용하여 추천 생성.
- 전통적인 방법 : Sequential Recommendation 모델 (GRU4Rec, Caser, SASRec, DROS)
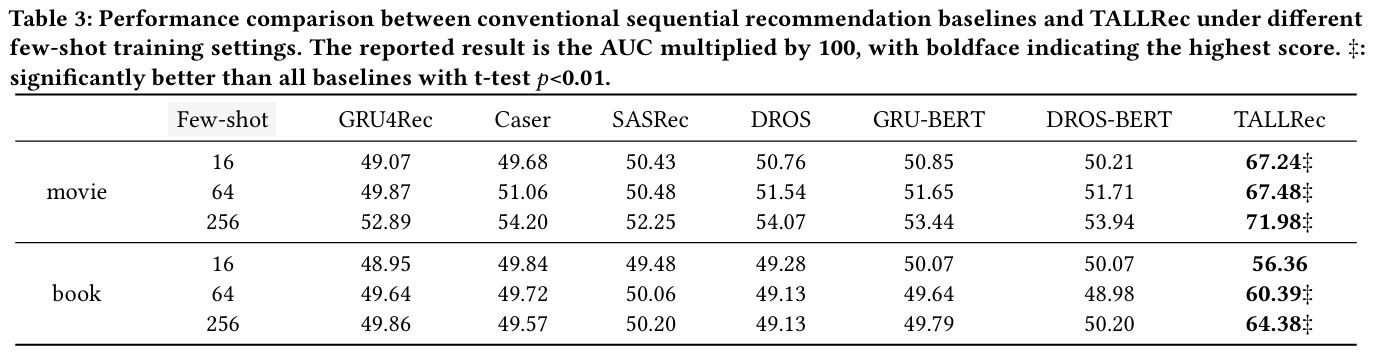
3.1 성능 비교 (RQ1)
- TALLRec은 전통적인 방법과 LLM 기반 방법 모두에서 뛰어난 성능을 보였다.
- LLM 기반 방법은 무작위 추측 수준(AUC ≈ 0.5)에 머물렀으나, TALLRec는 유의미한 개선을 달성했다.
- 전통적인 방법은 제한된 샘플로 추천 능력을 신속하게 학습하는 데 어려움을 겪었다.
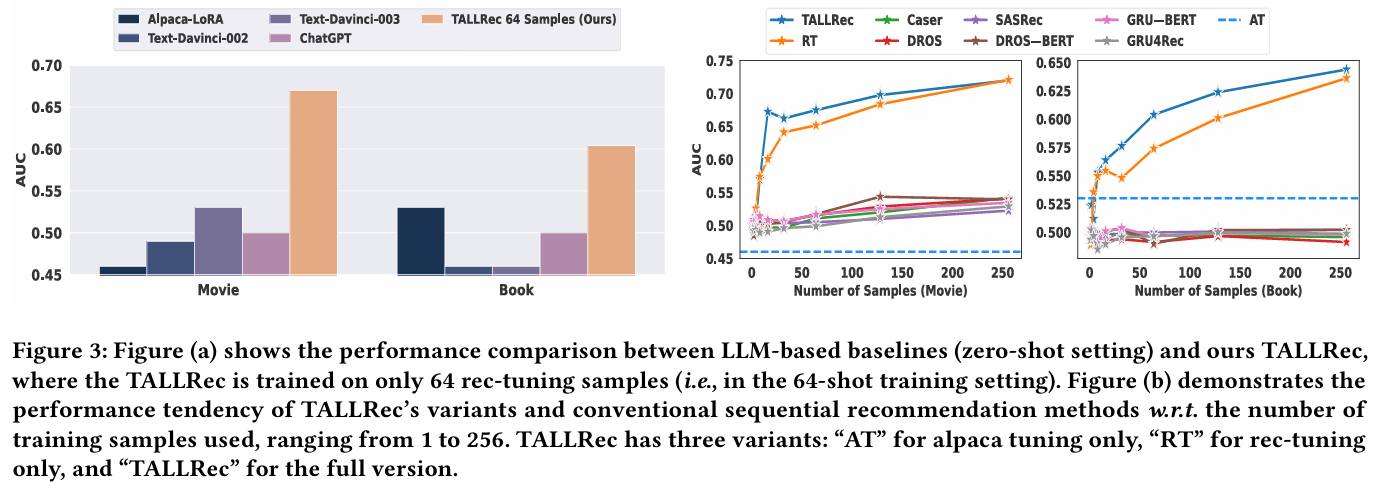
3.2 Ablation Study (RQ2)
- TALLRec의 alpaca tuning과 rec-tuning의 효과를 입증하기 위해 "AT"(alpaca tuning만 수행)와 "RT"(rec-tuning만 수행)의 성능을 비교했다.
- rec-tuning의 중요성이 확인되었으며, 적은 rec-tuning 샘플에서도 TALLRec가 높은 성능을 유지했다.
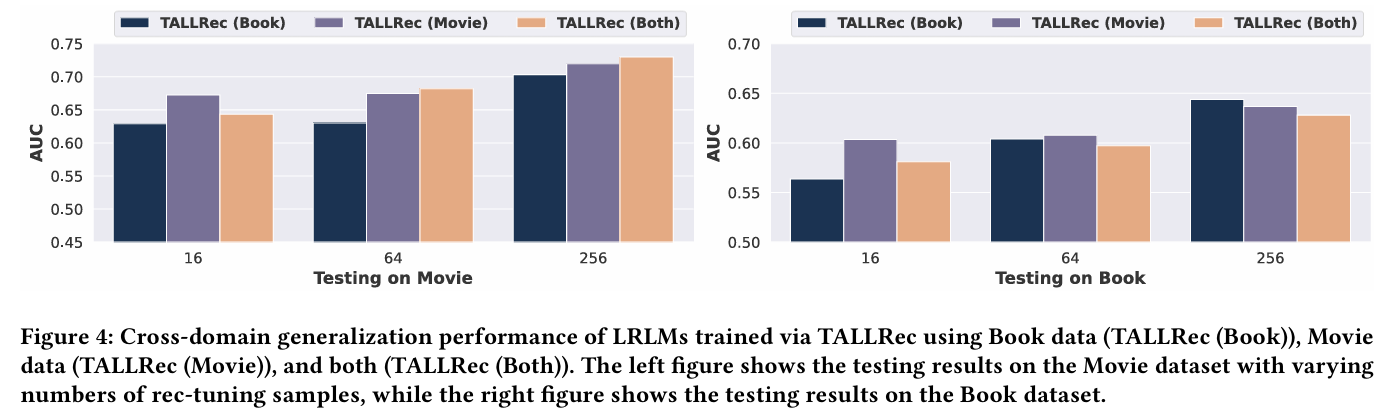
3.3 Cross-domain 일반화 성능 분석 (RQ3)
- TALLRec은 영화 샘플만 튜닝해도 책 데이터에서 좋은 성능을 보였으며, 두 도메인에서의 데이터 통합이 일반화 성능을 향상시킴을 보여준다.
5. Conclusion
연구 목적 : LLM을 추천 작업에 활용할 수 있는 가능성을 탐구하였다.
문제 발견 : 기존의 최고의 LLM 모델조차 추천 작업에서 성능이 좋지 않음을 확인하였다.
TALLRec 프레임워크 제안 : LLM과 추천 작업을 효율적으로 통합할 수 있는 TALLRec 프레임워크를 제안, 두 가지 튜닝 단계(alpaca tuning과 rec-tuning)를 통해 구현하였다.
실험 결과 : TALLRec 프레임워크로 훈련된 LLM은 전통 모델보다 우수한 성능을 보였고, 강력한 cross-domain 일반화 능력을 보여주었다.
향후 계획 : 더 큰 모델의 추천 능력을 활성화하는 효율적인 방법을 탐구하고, LLM이 여러 추천 작업을 동시에 처리할 수 있도록 튜닝할 계획이다.
