[논문] LLM-Rec: Personalized Recommendation via Prompting Large Language Models
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
LLM-Rec: Personalized Recommendation via Prompting Large Language Models [arxiv]
Hanjia Lyu NAACL 2024
📝 Key Point
-
LLM-Rec 프레임워크 : LLM을 활용하여 개인화된 추천을 개선하는 새로운 접근법인 LLM-Rec을 제안한다. 이 프레임워크는 입력 텍스트 보강을 통해 추천 품질을 향상시킨다.
-
프롬프트 전략 : LLM-Rec은 기본 프롬프트, 추천 주도 프롬프트, 참여 유도 프롬프트, 추천 주도 + 참여 유도 프롬프트로 구성된 4가지 전략을 사용하여 아이템 설명을 보강한다.
-
성능 향상 : LLM-REC는 보강된 텍스트와 원래 아이템 설명을 결합하여 추천 성능을 크게 향상시킨다. 간단한 모델인 MLP도 복잡한 모델과 동등하거나 더 나은 성과를 낸다.
-
유연성 및 적용 가능성 : LLM-Rec은 다양한 도메인에 적용 가능하며, 데이터셋의 텍스트 정보가 풍부하지 않더라도 효과적으로 작동한다.
-
투명성과 설명 가능성 : 보강된 텍스트를 통해 추천 과정의 투명성을 높이고, 추천 이유를 사용자와 시스템 설계자가 이해하는 데 도움을 준다.
Abstract
배경 : 텍스트 기반 추천 시스템은 다양한 응용 가능성을 지니지만, 원래의 아이템 설명을 직접 사용하는 것이 사용자 선호와 일치하지 않아 최적의 성능을 발휘하지 못할 수 있다.
연구 목적 : LLM의 상식 지식과 추론 능력을 활용하여 개인화된 텍스트 기반 추천을 개선하기 위한 새로운 접근법인 LLM-Rec을 제안한다.
방법론 : LLM-Rec은 네 가지의 텍스트 보강 프롬프트 전략을 포함하여 추천 품질을 향상시킨다.
실험 결과 : LLM으로 보강된 텍스트를 사용한 경우 추천 품질이 크게 향상되며, 기본적인 다층 퍼셉트론(MLP) 모델조차도 복잡한 콘텐츠 기반 방법보다 우수한 성과를 낸다.
결론 : LLM-Rec의 성공은 다양한 프롬프트 전략에 있으며, 이는 언어 모델의 아이템 특성 이해를 효과적으로 활용함을 보여준다. 따라서 다양한 프롬프트와 입력 보강 기법의 사용이 추천 효과성을 높이는 데 중요하다.
Figure

LLM-REC는 아이템 설명을 보강하기 위해 4가지 프롬프트 전략을 사용한다. 증강 된 텍스트를 연결하여 추천 모델의 input으로 사용한다.
- Basic Prompting
The description of an item is as follows: '{description}',
paraphrase it.- Recommendation-driven Prompting
“The description of an item is as follows: '{description}',
what else should I say if I want to recommend it to others?- Engagement-guided Prompting
Summarize the commonalities among the following descriptions:
'{description}'; '{descriptions of other important neighbors}'- Recommendation + Engagement
The description of an item is as follows: '{description}'.
What else should I say if I want to recommend it to others?
This content is considered to hold some similar attractive characteristics as the following descriptions:
'{descriptions of other important eighbors}'.
1. Introduction
배경 : 텍스트 기반 추천 시스템은 다양한 도메인과 산업에서 폭넓은 응용 가능성을 지닌다. 자연어의 특성 덕분에 제품, 영화, 책, 뉴스 기사, 사용자 생성 콘텐츠 등 거의 모든 유형의 아이템을 효과적으로 설명할 수 있다.
문제점 : 그러나 이러한 추천 시스템은 아이템 설명의 불완전성으로 인해 사용자 선호와 아이템 특성을 정확히 일치시키는 데 어려움을 겪는다. 불완전성은 두 가지 원인으로 발생할 수 있는데, 첫째는 아이템의 이해 부족, 둘째는 추천 대상 사용자의 이해 부족이다.
연구 목적 : 이 연구에서는 LLM의 내재적 능력을 활용하여 입력 텍스트를 보강하는 다양한 프롬프트 전략을 채택한 LLM-Rec 프레임워크를 소개한다. 이를 통해 개인화된 추천의 품질을 향상시키고자 한다.
실험 결과 : LLM-Rec 프레임워크의 효과를 평가한 결과, 보강된 텍스트를 새로운 입력으로 사용했을 때 기존의 아이템 설명만을 사용하는 콘텐츠 기반 추천 방법보다 동등하거나 더 나은 성과를 낸다.
결론 : 다양한 도메인에 적용 가능하며, LLM의 프롬프트 전략이 일반 및 구체적인 아이템 특성을 표현하는 데 효과적임을 보여준다. 이 연구는 추천 성과에 대한 다양한 프롬프트 전략의 영향을 탐구하고 LLM을 개인화 추천에 활용할 가능성을 제시한다.
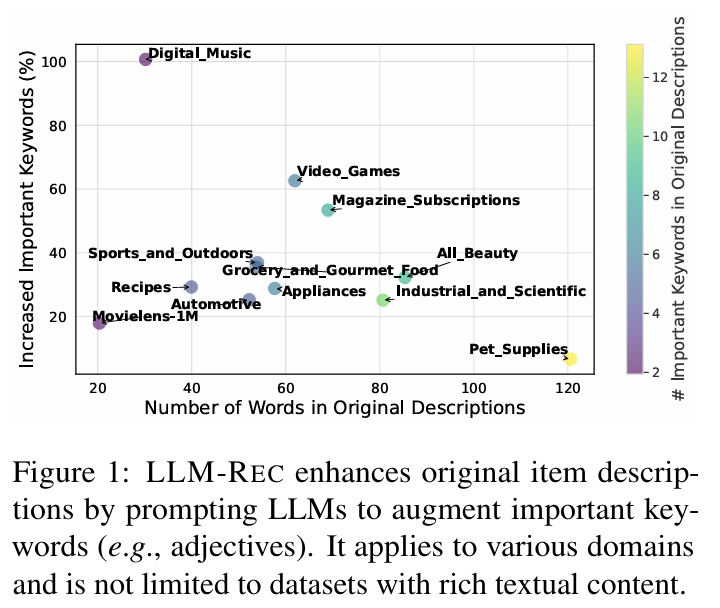
LLM-Rec은 LLM 프롬프트를 통해 중요한 키워드를 증강하여 아이템 설명을 강화한다. 따라서 다양한 도메인에 데이터셋 제한 없이 적용될 수 있다.
3. LLM-Rec
목표 : LLM-Rec은 LLM을 활용하여 정보성 있는 아이템 설명을 생성하고, 이를 통해 개인화 추천을 향상시키는 방법을 탐구한다.
프롬프트 전략 : 본 연구는 네 가지의 프롬프트 전략을 통해 설명을 보강하는 데 초점을 맞춘다.
-
기본 프롬프트 (Basic Prompting)
: 원래 아이템 설명을 패러프레이즈하여 동일한 정보를 유지한다.
: 내용을 태그로 요약하여 핵심 정보를 캡처한다.
: 아이템 설명의 특성을 추론하여 감정과 같은 범주적 응답을 제공한다. -
추천 주도 프롬프트 (Recommendation-driven Prompting)
: 추천을 위한 추가 정보를 생성한다.
: 추천에 적합한 태그를 생성한다.
: 감정 중심으로 추천한다. -
참여 유도 프롬프트 (Engagement-guided Prompting)
사용자와 아이템 간의 상호작용을 기반으로 더 정확한 설명을 생성한다.
: 타겟 아이템 설명과 관련된 중요한 이웃 아이템 설명을 결합하여 공통점을 요약한다. -
추천 주도 + 참여 유도 프롬프트 (Recommendation-driven + Engagement-guided Prompting)
: 두 가지 전략을 통합하여 더 정교한 추천을 생성한다.
효과
-
개인화 추천 성능 : LLM-Rec은 다양한 아이템 유형에 제한받지 않고 개인화 추천에서 상당한 개선을 보여준다. 간단한 모델인 다층 퍼셉트론(MLP)조차도 복잡한 모델과 동등하거나 더 나은 성과를 낸다.
-
투명성과 설명 가능성 : LLM-Rec은 추천 과정의 투명성과 설명 가능성을 높인다. 보강된 텍스트를 직접 조사함으로써 추천 모델과 아이템 특성에 대한 이해를 증진시켜 사용자와 시스템 설계자에게 유용한 통찰을 제공한다.
결론 : LLM-Rec은 이전 연구보다 적은 도메인 전문 지식으로도 구현 가능하며, 추천 성과를 향상시키는 데 효과적이다.
4. Experiment
4.2 Main Results
추천 성능 향상 : LLM-Rec으로 보강된 텍스트는 추천 성능을 크게 향상시킨다. Movielens1M에서 NDCG@10이 6.24%에서 8.54%로, Recipe에서 8.97%에서 21.72%로 증가한다.
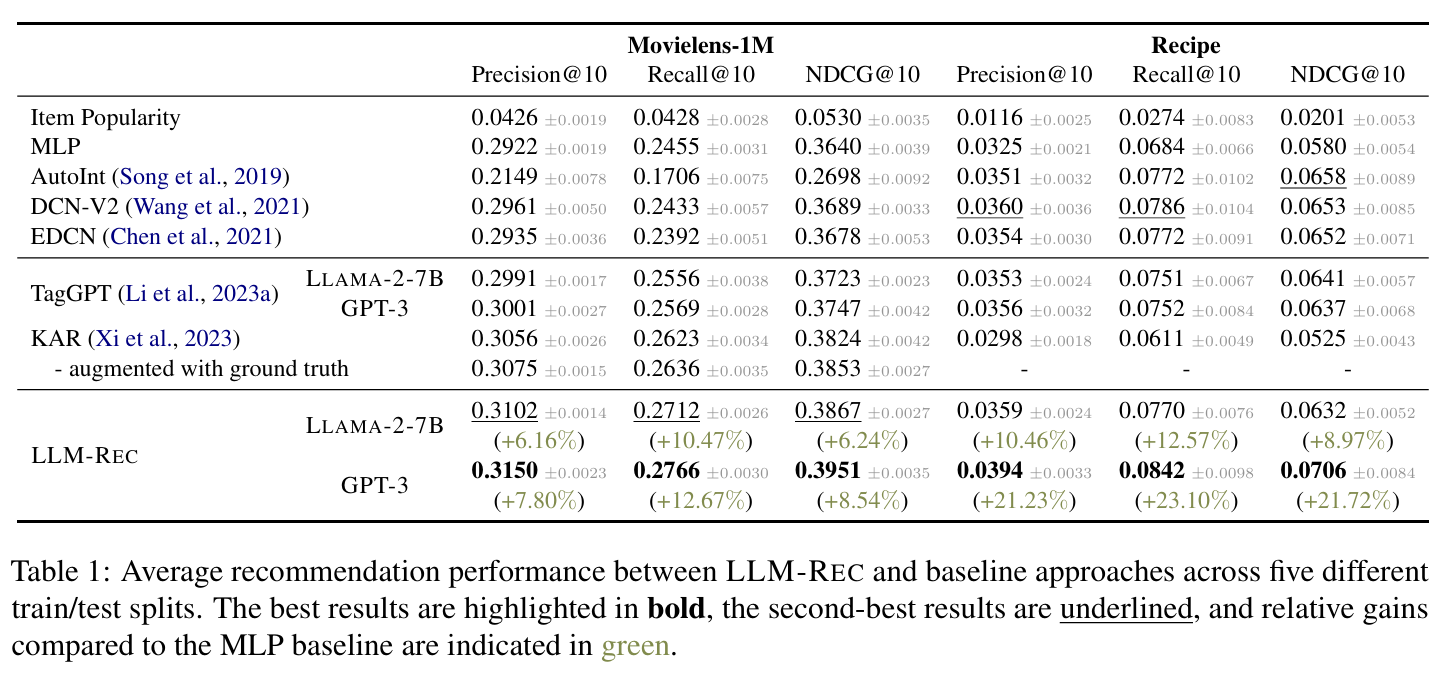
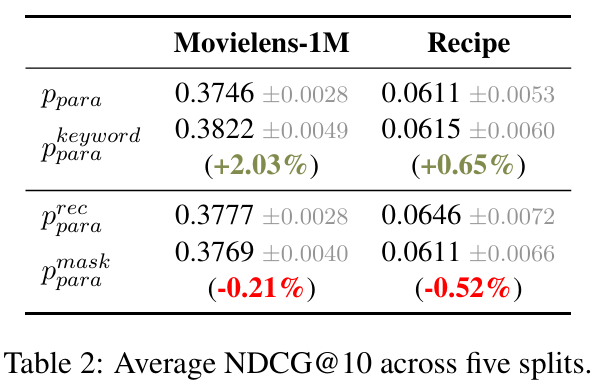
- 의 response에서 특정 단어를 마스킹했을 때, 추천 성능이 눈에 띄게 감소했다. 이는 의 고유 단어들이 추천 성과에 중요한 역할을 한다는 것을 입증한다.
- 는 의 response에 사용자 선호와 관련된 키워드를 추가하여 성능을 더욱 향상시킬 수 있음을 나타낸다.
- LLM-Rec의 보강된 텍스트에서 생성된 특정 단어들이 추천 성능에 중요한 기여를 하기 때문에 단어 선택의 중요성을 강조한다. 또한, 모든 응답 단어를 포함하는 것보다는 중요한 키워드를 선택적으로 포함시키는 것이 더 효과적임을 보여준다.
추가 정보 효과 : LLM-Rec의 프롬프트 접근법이 제공하는 추가 정보에 대한 정성적 및 정량적 연구를 통해 보강된 내용이 더 상세하고 표현력이 뛰어난 설명을 포함하고 있음을 발견했다.


지식 보강 접근법과 비교 ex) KAR (Knowledge Augmented Recommendation)
- 지식 보강 접근법은 생성된 지식이 특정 아이템과 맞지 않을 수 있기 때문에 추천 성능을 최적화하지 못한다.
- 예를 들어, 특정 레시피에 대한 생성된 재료 정보가 대부분의 경우 정확할 수 있지만, 특정 레시피에 대한 추가 맥락이 없으면 잘못된 정보를 제공할 수 있다.
- LLM-Rec은 추천 주도 프롬프트를 활용하여 특정 아이템을 더 넓고 덜 세분화된 수준에서 설명하는 정보를 제공한다.
다양한 도메인 적용 가능성 : LLM-Rec은 다양한 아이템 도메인에 적용 가능하며, 데이터셋에 따라 성능이 다르게 나타난다.
4.3 Ablation Study
프롬프트 전략 평가 : 각 프롬프트 전략이 추천 성능에 미치는 영향을 연구한 결과, 모든 전략에서 성능 향상이 나타났다. Movielens1M에서는 추천 주도와 참여 유도 전략의 조합이 가장 효과적이었다.
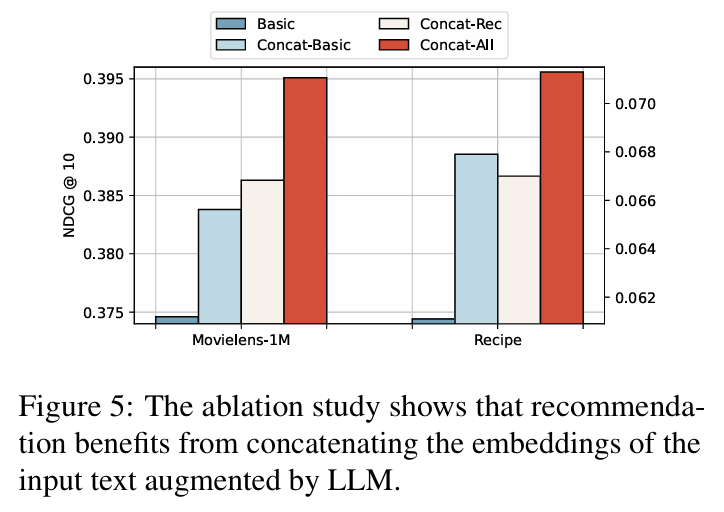
응답 통합 방법 : 보강된 응답을 통합하는 방법이 추천 성능에 미치는 영향을 분석한 결과, 모든 보강 텍스트를 통합했을 때 성능이 향상됨을 확인했다.
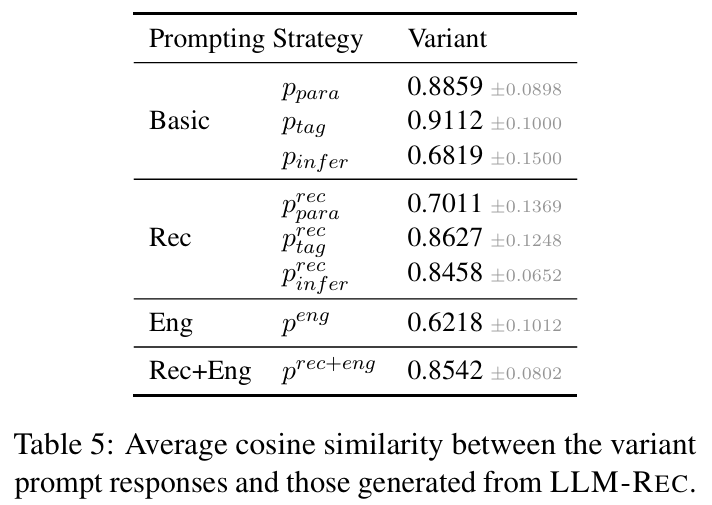
단어 선택 변경의 영향 : 프롬프트의 단어 선택을 변경한 변형을 통해 응답의 유사성을 비교한 결과, 단어 선택의 차이가 응답 형식에 영향을 미쳤지만, 기본적인 의미는 유지되었다.
5. Discussions and Conclusions
연구의 주요 내용
- LLM-Rec의 효과성 : 본 연구는 LLM을 활용하여 추천 품질을 향상시키는 간단하면서도 효과적인 메커니즘인 LLM-Rec의 효용성을 연구하였다. LLM을 통해 텍스트 보강을 시도한 초기 연구 중 하나로써 가치가 있다.
- LLM-Rec의 기여 :
1. 유연성 : 기존의 연구(예: KAR)는 특정 추천 모델을 위한 보강 알고리즘에 집중했지만, LLM-Rec은 모든 콘텐츠 기반 추천 모델에 적용 가능한 입력 텍스트 보강에 초점을 맞춘다.
2. 개인화된 특성 : 추천 주도 보강 외에도 참여 유도 프롬프트를 설계하여 개인화된 아이템 특성을 포함한다.
3. 종합적인 실험 : 다양한 프롬프트 전략 조합을 통해 LLM-Rec의 우수한 성능을 입증하며, 성능 개선의 근본적인 이유를 밝혀낸다.
결과 및 발견
- 추천 품질 향상 : 보강된 입력 텍스트와 원래 아이템 설명을 결합함으로써 추천 품질이 크게 향상되었다. 이는 LLM과 전략적 프롬프트 기법을 활용하여 추천의 정확성과 관련성을 높일 수 있는 잠재력을 보여준다.
- 세부 정보 캡처 : 추가적인 맥락을 포함시킴으로써 추천 알고리즘이 더 세밀한 정보를 포착하고 사용자 선호에 더 잘 맞는 추천을 생성하는 데 기여한다.
한계점
- 계산 비용 : LLM-Rec 프레임워크는 추가적인 계산 비용이 소요된다. 특히 보강 단계에서의 출력 텍스트 길이가 주된 부담이 된다. 중요한 단어를 선택하여 포함시키는 것이 전체 응답 단어를 사용하는 것보다 추천 성과를 향상시킬 수 있음을 발견하였다.
- 최신 정보 반영의 어려움 : LLM 기반 연구와 마찬가지로 LLM-Rec은 최신 지식을 신속하게 반영하는 데 어려움이 있다. 향후 연구에서는 LLM이 외부 소스에서 현재 지식을 자율적으로 수집하고 요약하는 방법을 탐구할 예정이다.
