[논문] TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendations
논문 읽기 스터디 "추천이 쪼아 LLM"
📄 Paper
TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendations [arxiv]
Haohao Qu IEEE TKDE 2024
📝 3줄 요약
-
TokenRec은 LLM을 추천 시스템에 맞게 조정하기 위해 사용자 및 아이템 ID를 효과적으로 토큰화하는 Masked Vector-Quantized Tokenizer를 도입한다.
-
Masked Vector-Quantized Tokenizer는 고차원 협업 지식을 포함시켜 자연어와 자연스럽게 통합될 수 있도록 설계되었다.
-
생성적 검색 패러다임을 도입하여 효율적으로 사용자 선호도를 모델링하고 최적의 아이템을 추천하는 방식으로 기존 LLM 기반 시스템보다 빠르고 효과적으로 작동한다.
Abstract
배경
- LLM과 추천 시스템의 원활한 연동을 보장하기 위해 사용자 및 아이템을 토큰화하는 것은 필수적이다.
- 기존 연구들은 텍스트 콘텐츠 또는 잠재적 표현을 사용하여 사용자 및 아이템을 표현하는 데 진전을 이루었지만, LLM과 호환되는 이산 토큰으로 고차원 협업 지식을 포착하고 unseen 사용자/아이템을 일반화하는 데 어려움이 남아 있다.
제안 방법 : TokenRec
- TokenRec은 LLM 기반 추천을 위한 효과적인 ID 토큰화 전략과 효율적인 검색 패러다임을 도입하는 새로운 프레임워크다.
- 토큰화 전략 : 협업 필터링에서 학습되고 마스크된 사용자/아이템 표현을 이산 토큰으로 양자화하여 고차원 협업 지식의 원활한 통합과 LLM 기반 RecSys를 위한 사용자 및 아이템의 일반화 가능한 토큰화를 달성한다.
- 생성적 검색 패러다임 : 사용자를 위한 상위 K개 아이템을 효율적으로 추천하도록 설계되어 LLM에서 사용되는 시간 소모적인 자기 회귀 디코딩 및 빔 검색 프로세스의 필요성을 없애므로 추론 시간을 크게 줄인다.
실험 및 결과
- 광범위한 실험을 통해 제안 방법의 효과를 검증했다.
- TokenRec이 기존 추천 시스템과 새롭게 떠오르는 LLM 기반 추천 시스템을 포함한 경쟁력 있는 벤치마크보다 성능이 우수함을 입증했다.
결론
- TokenRec은 LLM 기반 추천 시스템의 성능 향상과 효율성 증대에 기여할 수 있다.
Figure
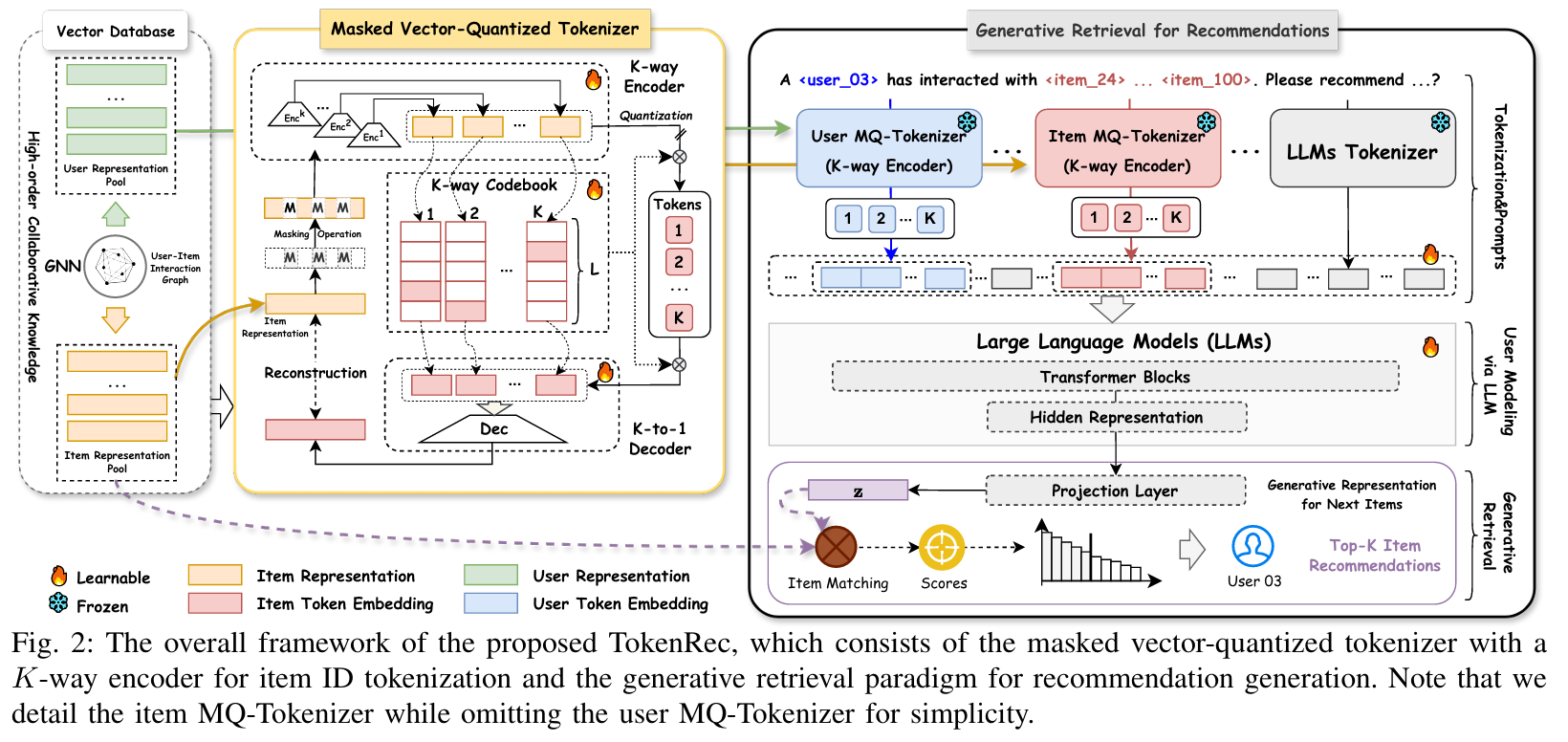
TokenRec 프레임워크
- Vector Database : GNN 모델을 통해 사용자-아이템 상호작용 그래프를 학습하여 사용자와 아이템 표현을 생성한다.
- Masked Vector-Quantized Tokenizer : 아이템 ID 토큰화를 위해 K-way 인코더와 K-to-1 Decoder를 사용한다.
- Generative Retrieval for Recommendations : MQ-Tokenizer를 통해 토큰화된 사용자와 아이템 ID를 LLM에 입력하여 추천을 위한 생성적 검색을 수행한다.

LLM 기반 추천 시스템에서 ID 토큰화 방법 비교
기존 방법과는 달리, 제안하는 접근 방식은 고차원 협업 지식을 활용하여 LLM과 호환되는 토큰으로 사용자와 아이템을 토큰화할 수 있다.
1. Introduction
배경
- 사용자 선호도에 부합하는 개인화된 추천을 제공하기 위해 가장 대표적인 기술 중 하나는 사용자-아이템 상호 작용 이력을 모델링하여 협업 지식을 포착하는 것을 목표로 하는 협업 필터링(CF)이다.
- 행렬 분해(MF)는 사용자-아이템 행렬을 두 개의 저랭크 행렬로 분해하여 사용자 행동을 예측하고 추천을 생성한다.
- 그래프 신경망(GNN)은 사용자-아이템 상호 작용 그래프에서 고차원 협업 지식을 포착하여 ID 방식으로 추천을 크게 향상시킨다.
- 기존 방법의 주요 아이디어는 이산적인 사용자 및 아이템 ID(토큰)에 대해 학습 가능한 표현(토큰 임베딩)을 얻는 것이다.
- ID 기반 추천 방법과 달리 사용자 및 아이템 토큰화는 추천 내에서 LLM을 활용하는 데 있어 가장 중요한 단계 중 하나이다.
- LLM 기반 추천 시스템을 위한 사용자 및 아이템 토큰화에 대한 기존 방법의 대부분은 여전히 몇 가지 제한 사항이 있다.
- 전체 단어 임베딩을 사용하면 고차원 협업 지식을 효과적으로 포착할 수 없고, 추천을 위해 unseen 사용자/아이템을 잘 일반화할 수 없다.
- 언어 모델에서 이산 토큰의 특성으로 인해 연속 인덱싱을 사용하면 추천 시스템에서 LLM을 긴밀하게 연동하기가 어렵다.
제안 방법 : TokenRec
- 고차원 협업 지식을 LLM에 원활하게 통합하여 사용자 및 아이템의 숫자 ID(식별자)를 토큰화하는 새로운 토큰화 전략이 제안된다.
- 생성적 검색 패러다임은 아이템 표현을 생성하고 협업 추천을 위해 적절한 아이템을 검색하도록 개발되었다.
주요 기여
- LLM에 맞게 조정된 사용자 및 아이템을 토큰화하기 위해 마스크된 벡터 양자화 토크나이저라는 주요 전략을 도입하여 LLM 기반 추천에서 고차원 협업 지식을 통합하는 데 기여한다. 제안하는 토큰화 방법의 일반화 능력을 LLM 기반 추천에서 향상시키기 위해 두 가지 새로운 메커니즘(마스킹 및 K-way 인코더)이 설계되었다.
- LLM 시대에 추천 시스템을 위한 새로운 프레임워크(TokenRec)를 제안한다. 생성적 검색 패러다임은 자연어로 토큰을 직접 생성하는 대신 사용자를 위해 상위 K개 아이템을 효과적이고 효율적으로 추천하도록 설계되었다.
- 널리 사용되는 4개의 실제 데이터 세트에 대한 광범위한 실험을 수행하여 제안하는 TokenRec의 효과를 경험적으로 입증한다. 뛰어난 추천 성능과 새로운 사용자 및 보지 못한 사용자의 선호도를 예측하는 일반화 능력이 포함된다.
2. The Proposed Method
2.1 Notations and Definitions
사용자 집합
아이템 집합
사용자 가 과거에 상호작용한 아이템 집합은 로 표기한다. 전통적인 협업 필터링과 마찬가지로, 사용자는 임베딩 벡터 , 아이템은 로 표현된다. 여기서 는 잠재 벡터의 차원 수이다.
추천 시스템의 목표는 사용자 와 아이템 사이의 상호작용(e.g. 클릭, 구매 등)을 기반으로 사용자의 선호도를 학습하는 것이다. 이를 위해 협업 필터링(CF) 기법은 사용자와 아이템의 표현을 과거 상호작용으로부터 학습한다.
TokenRec은 이 협업 필터링 문제를 LLM의 관점에서 재정의한다. 사용자 와 아이템 를 각각 토큰 ID , 로 변환하고, 이를 텍스트 프롬프트 에 통합하여 LLM에 입력한다. LLM은 다음과 같이 사용자 가 선호할 가능성이 있는 아이템의 표현 를 생성한다.
이때 상호작용한 아이템 집합 는 시퀀스가 아닌 비순차적인 방식으로 입력된다. 이는 협업 필터링 설정을 반영하기 위함이다.
2.2 An Overview of the Proposed Framework
TokenRec은 자연어와 추천 과제 간의 정렬을 강화하기 위한 LLM 기반 생성 추천 프레임워크이다. 전체 프레임워크는 두 가지 주요 모듈로 구성된다.
- Masked Vector-Quantized Tokenizer (MQ-Tokenizer)
- Generative Retrieval for Recommendations
MQ-Tokenizer for Users and Items
사용자와 아이템의 숫자 ID를 자연어 형태로 변환하는 ID 토크나이징 문제를 해결하는 것을 목표로 한다. 추천 시스템에서는 사용자와 아이템의 수가 매우 많기 때문에, 이를 효과적으로 토크나이즈하는 것이 핵심 과제이다.
이를 해결하기 위해 MQ-Tokenizer는 다음을 수행한다:
- 특정 코드북(codebook)을 학습
- 사용자와 아이템을 특수 토큰 목록으로 표현
- 인코더–디코더 네트워크를 통해 벡터 양자화 수행
이 구조는 수많은 사용자 및 아이템 ID를 LLM에 자연스럽게 통합할 수 있도록 설계되었다.
Generative Retrieval for Recommendations
사용자의 개인화를 위해 LLM을 이용해 사용자 모델링을 수행한다. 이 과정에서 생성 기반 검색(generative retrieval)을 통해 전체 아이템 집합에서 사용자가 선호할 만한 개의 아이템을 효율적으로 추출하고, 개인화된 Top-K 추천 리스트를 생성한다.
이 두 모듈을 통해 TokenRec은 추천 시스템과 자연어 처리 모델 간의 간극을 효과적으로 메워주며, 강력한 추천 성능을 보장한다.
2.3 Masked Vector-Quantized Tokenizers for Users and Items
기존 방식처럼 각 사용자와 아이템에 대해 고유한 토큰을 할당할 경우, 어휘 집합의 크기가 급격히 증가하게 된다. 이를 해결하기 위해 본 논문에서는 사용자와 아이템을 자연어와 정렬된 형태로 토크나이즈하는 새로운 전략을 제안한다. 핵심 아이디어는 벡터 양자화(Vector Quantization, VQ) 기술을 활용하여, 사용자 및 아이템을 일정한 이산 토큰(discrete tokens)으로 표현하는 것이다.
1) Collaborative Knowledge
고차 협업 지식(high-order collaborative knowledge)을 표현에 반영하기 위해, GNN 기반의 추천 모델로부터 학습된 임베딩을 양자화 대상으로 활용한다. GNN은 사용자와 아이템 간의 협업 신호를 포착하는 데 강점을 가지므로, 여기서 생성된 표현은 협업 지식을 잘 반영한다고 볼 수 있다. 이 임베딩을 양자화하여 사용함으로써, 유사한 사용자 및 아이템은 자연스럽게 유사한 토큰을 공유하게 되어 LLM 기반의 자연어 표현과의 정렬을 가능하게 한다.
2) Masking Operation
일반화 능력을 향상시키기 위해, 입력 임베딩에 대해 마스킹 연산을 수행한다. 이는 임베딩 벡터의 일부 요소를 확률적으로 제거함으로써 모델이 다양한 샘플을 학습하도록 유도한다. 마스킹은 Bernoulli 분포에 따라 적용되며 다음과 같이 표현된다.
여기서 는 마스킹 비율이며, , 는 마스킹된 사용자와 아이템 표현이다. 마스킹은 학습 에폭마다 달라지며, 다양한 훈련 샘플을 생성하여 일반화를 도모한다.
3) K-way Encoder and Codebook
마스킹된 임베딩을 입력으로, K-way 인코더는 서로 다른 K개의 인코더로 구성된다. 각 인코더는 마스킹된 입력을 받아 독립적인 잠재 벡터를 생성한다.
각 는 번째 인코더의 출력이며, 는 3-layer 다층 퍼셉트론이다.
생성된 벡터는 K개의 코드북 중 하나의 코드워드(codeword)와 매칭된다. 이 때 유클리드 거리 기반의 최근접 이웃 탐색을 사용한다.
이를 통해 아이템 는 다음과 같이 K개의 이산 토큰으로 표현된다.
4) K-to-1 Decoder
양자화된 K개의 토큰 임베딩을 평균 풀링한 후, 3-layer MLP를 이용해 원래 입력 임베딩을 재구성한다.
5) Learning Objective
MQ-Tokenizer 학습을 위한 손실 함수는 총 세 가지로 구성된다.
- Reconstruction Loss
원래의 GNN 기반 임베딩 와 재구성된 임베딩 의 차이를 최소화한다. - Codebook Loss
선택된 토큰 임베딩이 인코더 출력에 가까워지도록 유도한다. - Commitment Loss
인코더 출력이 토큰 임베딩에 지나치게 흔들리지 않도록 제어한다.
최종적으로, 아이템 MQ-Tokenizer의 총 손실 함수는 다음과 같이 정의된다.
사용자 MQ-Tokenizer 또한 유사한 방식으로 정의되며, 총 손실은 다음과 같다.
여기서 , 는 각 손실 항의 중요도를 조절하는 하이퍼파라미터이다.
2.4 Generative Retrieval for Recommendations
LLM을 추천 시스템에 효과적으로 활용하는 새로운 프레임워크를 소개한다. 핵심은 Generative Retrieval Paradigm으로, 사용자와 아이템 표현을 생성하고 이를 통해 협업 필터링 기반의 추천을 수행하는 방식이다.
1) Tokenization & Prompts
사용자·아이템 ID의 효율적인 토크나이징
일반적인 LLM은 수천~수만 개의 토큰만을 지원하지만, 실제 추천 시스템에서는 수백만에서 수십억 개의 사용자 및 아이템을 다루어야 한다. 이를 해결하기 위해 MQ-Tokenizer를 도입한다.
- 사용자와 아이템 ID는 각각 개의 서브코드북(Sub-codebook)으로 분해되고, 각 서브코드북에서는 개의 OOV(out-of-vocabulary) 토큰이 사용된다.
- 예를 들어, , 일 때 총 개의 토큰만으로도 39,387개의 아이템을 표현할 수 있다. (실험을 통해 증명)
- 일반적인 텍스트는 LLM의 기존 토크나이저(SentencePiece 등)를 사용하고, 사용자/아이템 ID는 MQ-Tokenizer를 통해 처리한다.
프롬프트 설계
LLM의 성능을 높이기 위해, 명시적인 프롬프트를 설계하여 모델이 사용자 선호를 이해하도록 유도한다.

이러한 프롬프트에서 ⟨uk-·⟩ 및 ⟨vk-·⟩ 형태의 토큰은 각각 사용자와 아이템 ID를 나타내는 OOV 토큰이다.
2) User Modeling via LLM
입력 구성
사용자 모델링의 목표는 사용자의 선호를 포착하고, 다음에 추천할 아이템의 표현을 생성하는 것이다. 입력은 다음과 같이 구성한다.
- : 사용자 의 MQ-Tokenizer 기반 토큰
- : 사용자 가 상호작용한 아이템들의 집합
- : 상호작용 아이템들의 MQ-Tokenizer 기반 토큰
이때, 시퀀스 정보는 무시하고 내 아이템들은 무작위 순서로 배치한다.
사용자 표현 생성
기존 방식은 텍스트 생성을 통해 추천 결과를 출력하지만, 본 방식에서는 사용자 표현을 직접 생성한다.
기존의 auto-regressive 방식은 다음과 같다.
그러나 본 연구에서는 다음과 같이 사용자 표현을 추출한다.
이 표현 는 사용자 의 다음 아이템에 대한 생성적 선호를 나타낸다.
3) Generative Retrieval
기존 방식의 한계
자연어 생성 방식은 다음과 같은 문제를 가진다.
- 속도 저하 : beam search 필요
- 환각 문제 : 존재하지 않는 상품명 생성 가능
- 신규 아이템 대응 불가 : fine-tuning 시 학습하지 않은 아이템은 추천 불가
제안 방식 : 생성 기반 검색
위 문제를 해결하기 위해, 생성 기반 검색 방식을 제안한다. LLM으로부터 얻은 표현 를 잠재 표현 공간으로 투영하여 검색 기반 추천을 수행한다.
여기서 는 3-layer MLP로 구성된 projection layer이다. 는 사용자 의 다음 아이템에 대한 잠재 표현(latent representation)이다.
유사도 기반 아이템 검색
추천은 다음과 같이 cosine similarity를 이용하여 수행한다.
- : 아이템 의 GNN 기반 표현
- : 사용자 가 아이템 를 선호할 확률 또는 점수
상위 개의 값을 기준으로 아이템을 추천 리스트로 생성한다.
2.5 TokenRec’s Training and Inference
1) Training
TokenRec은 고차원의 협업 정보(collaborative knowledge)를 ID 토크나이징에 반영하는 MQ-Tokenizer와 사용자 선호도를 포착하여 추천 아이템을 생성하는 LLM4Rec 백본으로 구성되어 있다. 두 컴포넌트를 동시에 학습하는 것이 직관적이지만, 양자화(quantization)와 언어 처리 간의 큰 차이로 인해 동기화된 업데이트가 어렵다. 따라서 다음의 두 단계로 나누어 학습을 수행한다.
Step 1. 사용자 및 아이템 MQ-Tokenizer 학습
사용자와 아이템의 ID 토크나이징을 학습하기 위해 먼저 MQ-Tokenizer를 학습하여 각자의 협업 표현을 독립적으로 양자화한다. 이때 손실 함수는 다음과 같다:
- 아이템 MQ-Tokenizer 학습 손실 :
- 사용자 MQ-Tokenizer 학습 손실 :
Step 2. LLM4Rec 튜닝 (Generative Retrieval)
MQ-Tokenizer를 고정(freeze)한 후, LLM 백본(e.g. T5), LLM 토큰 임베딩, 프로젝션 레이어를 튜닝하여 생성적 검색(generative retrieval)을 수행한다. 이때의 목표는 사용자 표현 가 관련된 아이템과 높은 유사도를 갖도록 학습하는 것이다.
추천 모델의 핵심은 metric learning을 기반으로 한 최근접 이웃(nearest neighbor) 검색이며, 사용자 표현 와 협업 기반 GNN에서 학습된 아이템 표현 간의 유사도를 이용하여 top-K 아이템을 선택한다.
튜닝을 위한 손실 함수는 다음의 pairwise ranking loss로 정의된다.
- : 사용자 의 생성 아이템 표현
- : 아이템 의 협업 표현
- : 코사인 유사도 등의 유사도 함수
- : 사용자 가 아이템 와 상호작용했는지 여부 (이면 긍정, 이면 부정)
- : 부정 샘플에 대한 마진 값
이 방식은 어렵고 혼동을 주는 샘플에 집중하도록 유도하여 효과적인 학습을 가능하게 한다.
2) Inference
기존 LLM 추론은 목표 토큰을 순차적으로 생성하는 방식이지만, 이는 느리고 학습되지 않은 사용자/아이템에 대한 일반화 성능이 낮다. TokenRec은 Generative Retrieval 프레임워크를 통해 이러한 문제를 해결한다.
효율적인 추천
TokenRec은 LLM을 활용하여 아이템 표현을 생성하고, 자연어 문장 대신 표현 벡터를 기반으로 아이템을 검색하므로, 시간 소모가 큰 디코딩 과정을 생략할 수 있다. 이로 인해 온라인 추천 시스템에서의 계산 비용이 크게 줄어든다.
새로운 사용자 및 아이템에 대한 범용성
TokenRec은 새로운 사용자나 아이템이 추가되더라도 MQ-Tokenizer와 LLM 백본을 재학습할 필요 없이, 협업 필터링 모델(GNN 등)만 업데이트하면 된다. 이 덕분에 빠른 적응과 높은 효율성을 보장할 수 있다. 이는 마스킹(Masking)과 K-way 인코딩 메커니즘 덕분이며, GNN 학습은 LLM 파인튜닝보다 훨씬 효율적이다.
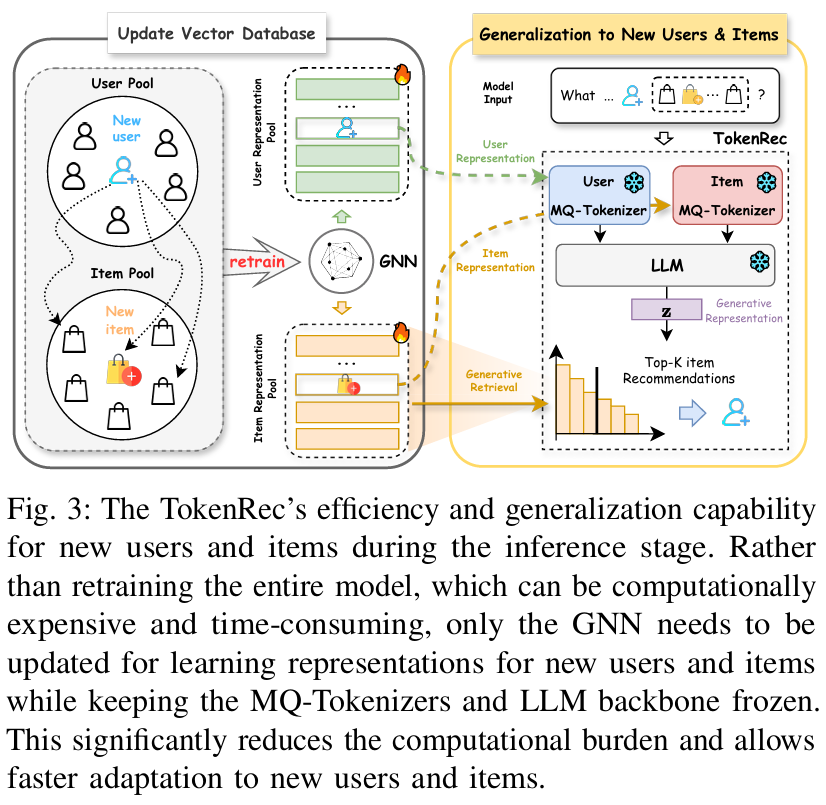
- 새로운 사용자/아이템이 등장하더라도 전체 모델을 재학습할 필요는 없다.
- GNN만 업데이트하면 되고, MQ-Tokenizer와 LLM은 고정된 상태로 활용 가능하다.
- 이로 인해 계산 비용이 절감되고 적응 속도가 빨라진다.
간결한 프롬프트
TokenRec은 사용자 ID 토큰만으로도 추천이 가능하다. 예를 들어, Prompt 1은 사용자 ID만 입력으로 사용한다. 이를 통해 입력 길이를 줄일 수 있어, 다수의 아이템과 상호작용한 사용자나 context 길이 제한이 있는 LLM에도 적합하다. (e.g. T5는 512 토큰, ChatGPT는 2048 토큰 제한)
3. Experiment
3.1 Experimental Settings
Datasets
- Amazon-Beauty (Beauty) : Amazon 전자 상거래 플랫폼에서 가져온 Beauty 제품과의 사용자 상호 작용을 포함한다.
- Amazon-Clothing (Clothing): Amazon 전자 상거래 플랫폼에서 가져온 Clothing 제품과의 사용자 상호 작용을 포함한다.
- LastFM : Last.fm 온라인 음악 시스템의 사용자로부터 음악 아티스트 청취 기록을 제공한다.
- MovieLens 1M (ML1M) : MovieLens 사용자가 만든 영화 평점 모음을 제공한다.
- 최대 아이템 시퀀스 길이는 LLM 백본 T5 (512 토큰)의 입력 길이를 수용하기 위해 100으로 설정된다.
- 훈련-검증-테스트 조합은 leave-one-out 정책을 따른다.
- 사용자의 상호 작용 이력을 무작위로 섞어 시간순이 아닌 아이템 목록을 제공한다.
Baselines
- Collaborative Filtering : MF, NeuCF, LightGCN, GTN, LTGNN
- MF : 가장 고전적인 CF 방법
- NeuCF : 최초의 DNN 기반 협업 필터링
- LightGCN 및 GTN : GNN 기술을 기반으로 한 대표적인 CF
- LTGNN : 가장 발전된 GNN 기반 협업 필터링 방법
- Sequential Recommendations : SASRec, BERT4Rec, S3Rec
- SASRec : self-attention 기반 순차적 추천 모델
- BERT4Rec : BERT 스타일 cloze 작업으로 훈련된 양방향 Transformer 기반 추천 모델
- S3Rec : self-supervised learning으로 훈련된 대표적인 순차적 추천 모델
- LLM based Recommendations : P5, CID, POD, CoLLM
- P5 : LLM 기반 RecSys에 대한 선구적인 연구로, 추천 작업을 text-to-text 형식으로 설명하고 LLM을 사용하여 개인화 및 추천을 위한 더 깊은 의미를 포착한다. 실험에서 P5 모델에 임의 인덱싱(RID)과 순차 인덱싱(SID)의 두 가지 인덱싱 방법을 배포한다. 이 중에서 P5-SID는 실험에서 효율성 평가, 일반화 가능성 평가 및 제거 연구의 기준으로 선택된다.
- CID : 아이템의 동시 발생 행렬을 고려하여 숫자 ID를 설계하는 중요한 인덱싱 접근 방식이다. 따라서 사용자-아이템 상호 작용에서 함께 발생하는 아이템은 유사한 숫자 ID를 갖는다. 일관성을 유지하기 위해 P5 모델을 LLM 백본으로 사용한다.
- POD : P5 아키텍처를 기반으로 LLM의 과도한 입력 길이를 줄이기 위해 이산 프롬프트를 연속 임베딩으로 인코딩한다.
- CoLLM : GNN을 사용하여 LLM 기반 추천을 위한 아이템과 사용자를 나타내는 연속 임베딩을 제공한다. 특히, 실험에서 CoLLM의 이진 분류 출력은 상위 K개 추천의 출력 설정과 일치하도록 아이템 ID를 생성하도록 재구성된다.
Evaluation Metrics
- 상위 K개 Hit Ratio (HR@K)
- 상위 K개 Normalized Discounted Cumulative Gain (NDCG@K)
- K 값은 10, 20, 30으로 설정되며, 그중 20은 ablation study의 기본값이다.
Hyper-parameter Settings
- 모델은 HuggingFace 및 PyTorch를 기반으로 구현된다.
- 코드북 수 K, 각 서브 코드북의 토큰 수 L, 마스킹 작업의 비율 는 각각 {1, 2, 3, 4, 5}, {128, 256, 512, 1024} 및 0.1 단위로 {0 ~ 1} 범위에서 검색된다.
- 음수 샘플링 비율 는 1:1로 고정되고, 마진 는 0에서 0.2 사이로 설정된다.
- MQ-Tokenizers와 LLM 백본은 미니 배치 방식으로 AdamW로 최적화한다.
- 사용자와 아이템에 대한 고차원 협업 표현은 LightGCN에서 얻는다.
- 프롬프팅을 위해 TokenRec에 대해 11개의 템플릿을 설계한다.
- T5-small을 TokenRec 및 모든 LLM 기반 비교 대상에 사용한다.
- 비교 대상 방법의 다른 기본 하이퍼파라미터는 해당 논문에서 제안하는 대로 설정된다.
3.2 Performance Comparison of Recommender Systems
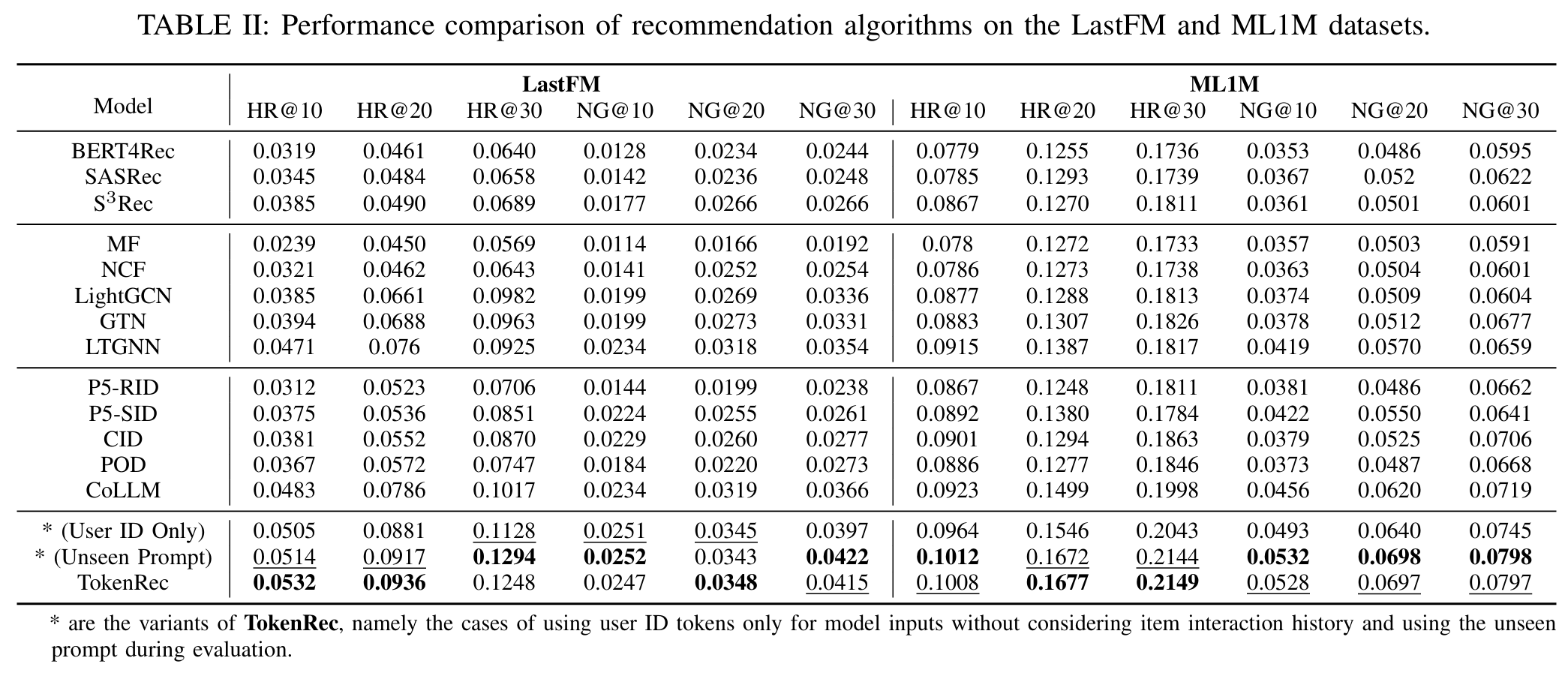
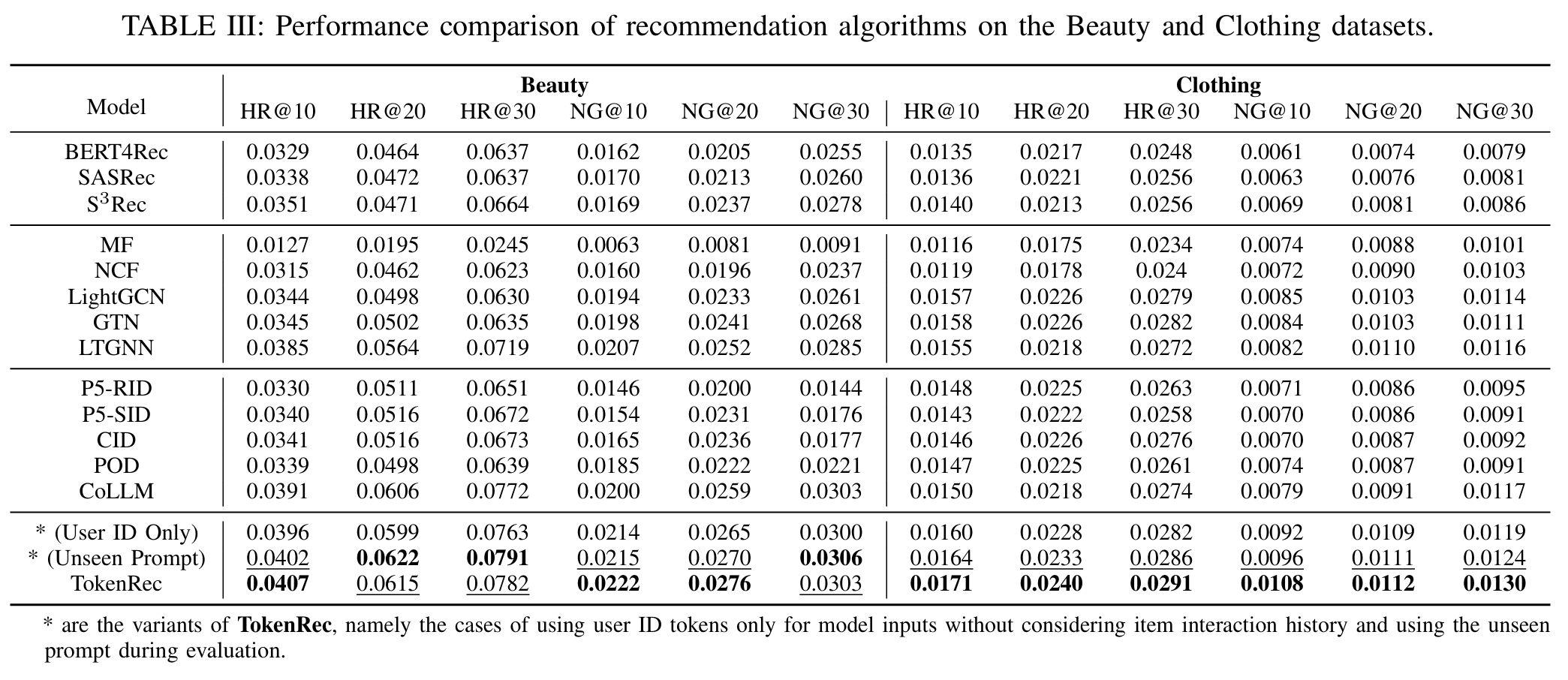
- (User ID Only) : 아이템에 대한 사용자의 상호 작용 이력을 고려하지 않고 사용자 ID 토큰만 사용
- (Unseen Prompt) : 새로운 사용자와 아이템에 대한 추천 성능을 평가하기 위한 프롬프트 사용
관찰 결과
- 관찰 1 : TokenRec은 최고의 성능을 달성하고 unseen 개인화 프롬프트가 있는 지표와 관련하여 모든 데이터 세트에서 모든 비교 대상보다 일관되게 뛰어나다.
- LastFM 데이터 세트에서 HR@20에서 19.08%, NCDG@20에서 9.09%로 가장 강력한 비교 대상을 크게 능가한다.
- 이는 제안하는 방법의 효과와 LLM 기반 RecSys에서 협업 인덱싱을 탐색할 수 있는 큰 잠재력을 보여준다.
- 관찰 2 : 사용자 ID 토큰만 사용하는 경우에도 TokenRec은 정확도 측면에서 대부분의 비교 대상을 능가하여 협업 추천에서 뛰어난 성능을 나타낸다.
- 이는 TokenRec이 사용자의 상호 작용 이력이 없는 경우에도 사용자를 효과적으로 모델링할 수 있음을 의미한다.
- TokenRec은 간결한 입력을 사용하여 추천을 생성할 수 있으므로 LLM에서 부과하는 입력 길이 제한을 피하고 상당한 계산 리소스를 절약할 수 있다.
- 관찰 3 : 협업 인덱싱(CID)은 동일한 P5 설정을 고려할 때 임의 인덱싱(RID) 및 순차 인덱싱(SID)보다 성능이 뛰어나다.
- 이는 아이템 및 사용자 토큰화/인덱싱을 위한 협업 지식 통합의 잠재력을 시사한다.
- P5 변형 및 POD는 기존 GNN 기반 협업 필터링보다 성능이 떨어지며, 이는 LLM을 사용하여 협업 정보를 포착하는 능력이 부족함을 의미한다.
- 관찰 4 : GNN 기반 협업 필터링 방법은 기존 CF 방법 및 대표적인 순차적 추천 방법보다 상대적으로 더 나은 성능을 보인다.
- 이는 고차원 연결성을 통해 협업 신호를 포착하는 데 있어 GNN의 효과를 입증한다.
3.3 Generalizability Evaluation
대부분의 전자 상거래 및 소셜 미디어 플랫폼에서는 상당수의 새로운 사용자 및 아이템이 매일 추천 시스템에 추가된다. 잘 확립된 시스템은 새로운 사용자의 선호도와 새로운 아이템의 특성을 수용하고 일반화하기 위해 자주 업데이트 및 개선을 수행해야 하므로 사용자 기반의 진화하는 역학에 맞는 개인화된 추천을 제공한다.
새로 추가된 사용자와 아이템은 LLM4Rec을 파인튜닝할 때 상호 작용이 부족하므로 기존 LLM 기반 RecSys는 잠재적 후보로 적합한 아이템을 검색하지 못하여 광범위한 재훈련이 필요하다. TokenRec은 사용자가 훈련 및 파인튜닝 코퍼스에 없는 경우에도 효과적으로 쉽게 일반화할 수 있다.
실험 설정
- 훈련 데이터 분할에서 상호 작용 이력이 가장 적은 5%의 사용자(unseen 사용자로 참조)를 제외하여 새로운 사용자를 시뮬레이션한다.
- unseen 사용자에 대한 데이터 유출이 없는지 확인하기 위해 훈련 분할만 사용하여 이러한 LLM4Rec 모델을 설정하는 반면, unseen 사용자와 아이템의 협업 표현을 제공하기 위해 벡터 데이터베이스를 업데이트할 수 있다.
- 이는 LLM 기반 RecSys의 LLM 백본을 업데이트하는 것보다 훨씬 적은 계산 리소스를 소비한다.
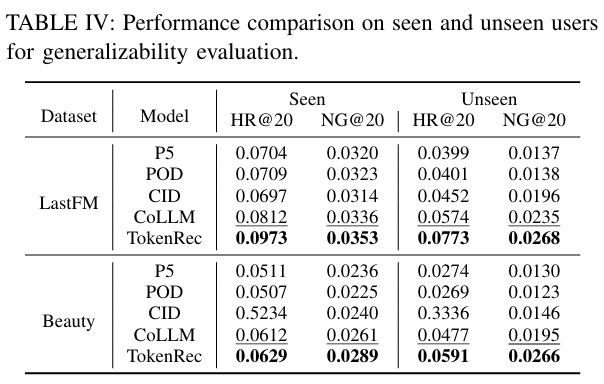
관찰 결과
- 관찰 1 : 기존 LLM 기반 추천 방법은 P5 및 POD의 경우 unseen 사용자에게 아이템을 추천할 때 HR@20 및 NDCG@20에서 40% 이상의 상당한 감소로 입증되듯이 일반화 가능성에 어려움을 겪고 있다.
- 관찰 2 : CID 및 CoLLM에 협업 지식을 포함하면 P5 및 POD에서 성능 저하가 감소하는 것으로 나타나 모델 일반화에서 상대적으로 향상된 성능을 얻을 수 있다.
- 그러나 이러한 방법은 여전히 20% 이상의 감소를 경험하고 있으며, 이는 LLM 기반 추천에 대한 안정적인 ID 토큰화의 중요성을 간과하고 있음을 나타낸다.
- 관찰 3 : TokenRec은 훈련 사용자뿐만 아니라 두 데이터 세트의 unseen 사용자에 대해서도 모든 비교 방법을 능가한다.
- Amazon-Beauty 데이터 세트에서 TokenRec의 성능은 평균 7%만 감소하여 새로 추가된 사용자에 대한 TokenRec의 강력한 일반화 기능을 입증한다.
- 이러한 우수성은 강력한 ID 토큰화를 위한 MQ-Tokenizer와 유연한 추천 생성을 위한 생성적 검색 패러다임에 기인할 수 있다.
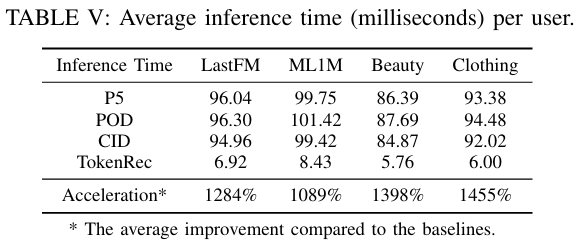
3.4 Efficiency Evaluation
- 제안하는 방법은 텍스트 디코딩 생성 솔루션을 버리고 협업 추천을 수행하기 위한 생성적 검색 패러다임을 도입한다.
- TokenRec이 LLM 기반 추천 baseline에 비해 약 1306.5%의 상당한 개선으로 뛰어난 추론 효율성을 달성할 수 있음을 보여준다.
- 이는 LLM의 가장 시간이 많이 걸리는 자동 회귀 디코딩 및 빔 검색 프로세스를 우회하는 생성적 검색 패러다임에 기인할 수 있다.
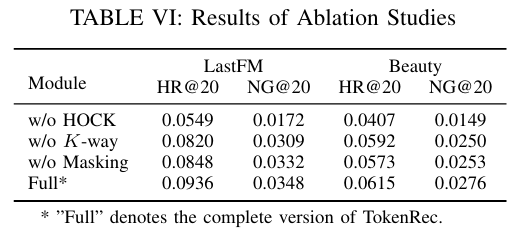
3.5 Ablation Study
- 제안하는 주요 구성 요소의 효과를 평가하기 위해 LastFM 및 Amazon-Beauty 데이터 세트에서 제거 실험을 수행했으며, 각 구성 요소의 영향은 다음과 같이 개별적으로 제거되었다.
- w/o High-Order Collaborative Knowledge (HOCK) : MF를 사용하여 MQ-Tokenizers에서 ID 토큰화를 위한 사용자와 아이템의 협업 표현을 학습한다.
- MF는 사용자-아이템 상호 작용 간의 고차원 협업 신호를 명시적으로 포착하기가 어렵다.
- w/o K-way : K-way 인코더 및 코드북을 코드북 토큰의 총 수를 일관되게 유지하면서 1-way로 대체한다.
- w/o Masking : 사용자 및 아이템 MQ-Tokenizers에서 마스킹 작업을 비활성화한다.
- w/o High-Order Collaborative Knowledge (HOCK) : MF를 사용하여 MQ-Tokenizers에서 ID 토큰화를 위한 사용자와 아이템의 협업 표현을 학습한다.
- 관찰
- 접근 방식의 각 구성 요소는 전체 성능에 기여하므로 제거하면 성능 저하가 발생한다.
- 접근 방식에 도입된 마스킹 작업 및 K-way 프레임워크는 일반화 가능성을 향상시킬 뿐만 아니라 제거 실험 중에 적당한 성능 향상을 가져온다.
- 고급 GNN으로 학습된 고차원 협업 지식을 제거하면 성능이 크게 저하되었다. 이는 LLM 및 개인화된 추천을 정렬하기 위해 그러한 지식을 통합하는 것이 중요하다는 것을 나타낸다.
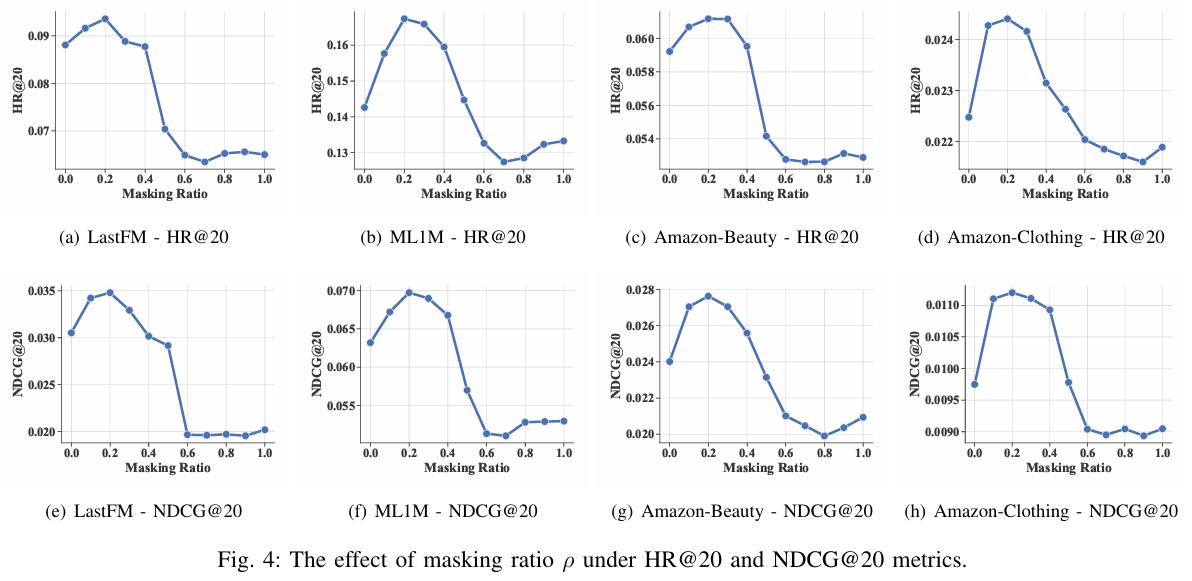
3.6 Hyper-parameter Analysis
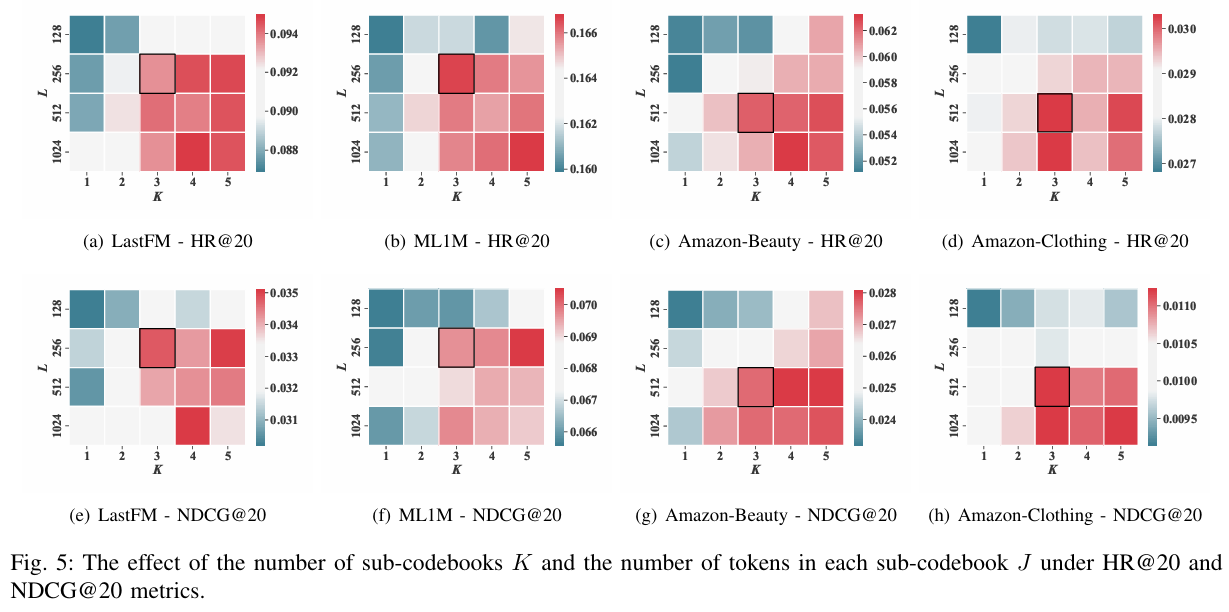
TokenRec에서는 벡터 양자화의 마스킹 비율 , 서브 인코더/서브 코드북 수 K, 각 서브 코드북의 토큰 수 L이라는 세 가지 중요한 하이퍼파라미터를 도입한다. 제안하는 모델의 향후 적용을 용이하게 하기 위해 이러한 값의 민감도를 이 섹션에서 평가한다.
Effect of Masking Ratio
사용자 및 아이템 ID 토큰화를 위한 벡터 양자화의 마스킹 비율을 제어하는 MQ-Tokenizer의 하이퍼파라미터 의 영향을 조사한다.
- 작은 비율의 마스킹을 도입하면 성능이 향상된다는 것을 알 수 있다.
- 대부분의 경우 제안하는 방법의 추천 성능은 일 때 향상되며, 그중 0.2가 실험에서 최고의 개선을 달성할 수 있다.
- 실험 결과는 마스킹 비율 일 때 추천 성능이 저하되어 과도한 마스킹을 피해야 함을 시사한다.
Effect of Codebook Settings K and L
제안하는 방법 TokenRec이 더 많은 서브 코드북을 쌓고 더 많은 코드북 토큰을 도입하여 이점을 얻을 수 있는지 여부를 연구하기 위해 하이퍼파라미터 K와 L의 수를 각각 {1, 2, 3, 4, 5} 및 {128, 256, 512, 1024} 범위에서 변경하고 모든 데이터 세트에 대한 성능을 확인한다.
- 코드북 깊이가 증가함에 따라 모든 데이터 세트에서 추천을 위한 모델의 점진적인 성능 향상이 확인된다.
- 그럼에도 불구하고 K > 3이면 추천 성능의 향상이 상대적으로 미미해진다.
- 결과적으로 효과와 효율성 간의 절충을 고려하여 K = 3이 제안된다.
- L의 최적 값은 사용자와 아이템의 크기에 따라 다르다.
- LastFM/ML1M (더 작은 크기) 및 Amazon-Beauty/Clothing (더 큰 크기) 데이터 세트에서 각각 L이 256 및 512일 때 효과와 효율성 측면에서 가장 균형 잡힌 성능을 관찰할 수 있다.
- 이는 사용자/아이템이 더 많은 데이터 세트의 경우 각 서브 코드북에서 약간 더 많은 코드북 토큰을 사용해야 함을 의미한다.
- 단일 코드북의 경우 단순히 코드북 토큰 수를 늘리는 것만으로는 추천에서 성능 향상을 효과적으로 제공할 수 없다.
- 이는 추천을 위한 MQ-Tokenizer에서 제안하는 K-way 메커니즘의 효과를 입증한다.
4. Related Work
Collaborative Filtering
- CF는 사용자 선호도에 따라 개인화된 추천을 제공하기 위해 사용자-아이템 상호 작용과 같은 협업 정보를 모델링하는 대표적인 기술이다. 유사한 사용자 패턴을 포착하고 미래의 상호 작용을 예측하는 데 사용된다.
- MF : 사용자와 아이템을 조밀한 표현으로 벡터화하고, 벡터 간의 내적을 계산하여 상호 작용을 모델링한다.
- NeuCF : 신경망과 MF를 통합하여 사용자 및 아이템 임베딩을 나타내는 저차원 행렬로 사용자-아이템 상호 작용을 분해한다.
- DSCF : 소셜 네트워크에서 이웃 정보를 활용하여 협업 추천을 위한 사용자 표현을 향상시키기 위해 심층 언어 모델을 사용한다.
- GNN : LightGCN, GTN, LTGNN 등은 사용자-아이템 상호 작용 그래프에서 고차원 협업 지식을 포착하여 추천 시스템 성능을 향상시킨다. 사용자-아이템 상호 작용의 그래프 구조적 특성을 활용하고, 정보 전파를 통해 유사한 사용자 행동 패턴을 모델링한다.
- GraphRec : 소셜 추천을 위해 사용자-아이템 상호 작용과 사용자-사용자 소셜 관계를 인코딩하는 그래프 주의 네트워크 기반 프레임워크를 사용한다.
- LightGCN : 기능 변환 및 비선형 활성화를 제거하여 GNN 기반 추천 방법을 단순화하고 최첨단 예측 성능을 달성한다.
- GTN & LTGNN : 각각 상호 작용의 적응형 신뢰성 및 고차원 시간 패턴을 포착하여 성능을 개선한다.
LLM-based Recommender Systems
-
ChatGPT, GPT-4와 같은 LLM의 발전으로 자연어 처리 기술이 혁신되었고, LLM 기반 추천 시스템이 주목받고 있다. LLM의 뛰어난 성능은 거대한 훈련 데이터와 모델 크기 확장에 기인한다. 수십억 개의 파라미터를 가진 LLM은 뛰어난 일반화 능력과 추론 능력을 보여준다.
- LLM을 추천 작업에 적용하기 위해 사전 훈련, 파인튜닝, 프롬프팅(e.g. in-context learning, chain-of-thought, instruction tuning)과 같은 다양한 패러다임이 연구되고 있다.
- P5 : 다중 작업 프롬프트 기반 사전 훈련을 통해 다양한 추천 작업을 통합하고, 개인화된 프롬프트로 새로운 추천 작업에 대한 제로 샷 일반화 기능을 달성한다.
-
LLM 기반 추천 방법은 사용자 및 아이템 ID 인덱싱에 제한이 있으며, 독립 인덱싱(IID)은 언어 모델 내에서 사용자 및 아이템을 나타내기 위해 특수 토큰을 직접 할당한다. 텍스트 제목 인덱싱은 LLM 어휘 내 토큰을 사용하여 아이템을 토큰화한다.
- P5, POD 등은 아이템과 사용자를 나타내는 토큰을 강조하기 위해 위치 및 전체 단어 임베딩을 적용한다. 최근에는 소프트 프롬프트를 사용하여 연속 임베딩으로 사용자 및 아이템을 나타내기도 한다.
-
제목 인덱싱 및 전체 단어 임베딩은 어휘 폭발 문제를 완화할 수 있지만, 고차원 협업 지식 포착에 어려움이 있고, 새로운 사용자/아이템에 대한 일반화 가능성이 부족하다. 언어 모델에서 토큰의 이산적인 특성은 연속적인 표현을 사용할 때 LLM 정렬을 어렵게 만든다. 또한, 대부분의 LLM 기반 추천 시스템은 자동 회귀 디코딩 및 빔 검색으로 인해 추론 시간이 오래 걸린다.
-
따라서 본 논문에서는 고차원 협업 지식을 포착하고 효율적인 생성적 검색 패러다임을 제안하는 LLM 기반 추천을 위한 새로운 프레임워크인 TokenRec을 제안한다. 이는 기존 방법들의 단점을 극복하고 더 효과적인 추천 시스템을 구축하기 위함이다.
5. Conclusion
-
기존의 LLM 기반 추천 방법은 유망한 예측 성능을 달성하지만, 사용자 및 아이템을 토큰화하는 데 있어 고차원 협업 지식을 포착하지 못하고 열악한 일반화 기능을 겪는다. 또한 시간이 오래 걸리는 추론은 LLM 기반 추천 시스템에서 새로운 과제로 남아 있다.
-
이러한 단점을 해결하기 위해 고차원 협업 지식을 포착하기 위한 일반화 가능한 사용자 및 아이템 ID 토큰화 전략을 도입할 뿐만 아니라 상위 K 아이템의 효율적인 생성을 위한 생성적 검색 패러다임을 제시하는 TokenRec이라는 새로운 접근 방식을 제안한다.
-
마스크된 벡터 양자화 토크나이저 (MQ-Tokenizer)는 고차원 협업 지식을 통합하여 LLM 기반 추천에서 사용자와 아이템을 토큰화하기 위해 개발되었다.
-
4개의 데이터셋에 대한 실험을 통해 TokenRec은 SOTA 추천 성능을 달성했을 뿐만 아니라 unseen 사용자에 대한 일반화 능력을 보여주었다.
