📄 Paper
Learnable Item Tokenization for Generative Recommendation [arxiv]
Wenjie Wang CIKM 24
📝 3줄 요약
-
LLM을 활용한 생성형 추천 시스템을 개선하기 위해, 효과적인 아이템 토큰화 방법을 제안한다.
-
기존의 ID, 텍스트, 코드북 기반 식별자들의 한계를 해결하기 위해, 계층적 의미, 협업 신호, 코드 할당 다양성을 통합한 학습 가능한 토큰화 모델인 LETTER를 제안한다.
-
LETTER는 RQ-VAE를 활용한 의미 정규화, 대조적 정렬 Loss를 통한 협업 정규화, 그리고 코드 할당 편향을 완화하는 다양성 정규화를 적용하여 최신 생성형 추천 기술을 한 단계 더 발전시켰다.
Abstract
문제 제기 및 배경
- 최근 생성적 추천(Generative Recommendation) 분야에서 LLM 활용이 활발하다.
- 하지만 추천 데이터를 LLM의 언어 공간으로 효과적으로 변환하는 아이템 토큰화 방식에 대한 연구가 미흡하다.
- 기존 토큰화 방식(ID, 텍스트, 코드북 기반)은 의미 정보 인코딩, 협력 신호 통합, 코드 할당 편향 등의 문제점을 가진다.
제안하는 방법: LETTER (Learnable Tokenizer for Generative Recommendation)
- 개념 : 계층적 의미, 협력 신호, 코드 할당 다양성을 통합하여 식별자의 필수 요건을 충족하는 학습 가능한 토크나이저
- 핵심 기술 :
- 의미 정규화 : 잔여 양자화 VAE (Residual Quantized VAE) 활용
- 협력 정규화 : 대조적 정렬 Loss 활용
- 코드 할당 편향 완화 : 다양성 Loss 활용
- 추가 개선 : 순위 기능 향상을 위한 순위 안내 생성 Loss 제안
실험 결과 및 결론
- 세 가지 데이터셋에서 LETTER를 평가한 결과, LLM 기반 생성 추천 분야에서 최고 수준의 성능을 달성했다.
- LETTER는 기존 토큰화 방식의 한계를 극복하고, LLM을 활용한 생성적 추천 성능을 향상시키는 효과적인 방법임을 입증했다.
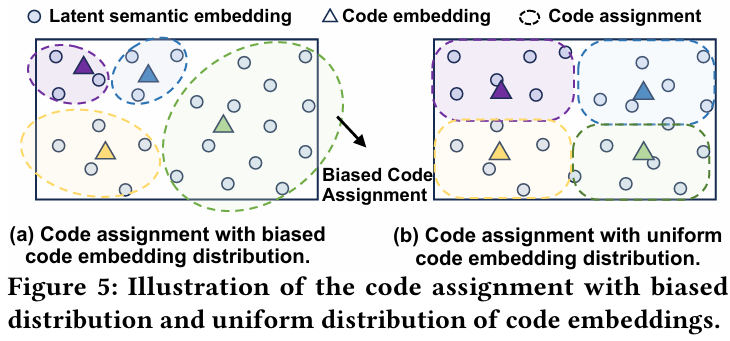
code assignment bias
아이템 토크나이제이션 과정에서 코드가 아이템에 비균등하게 할당되는 현상을 말한다. 일부 코드가 특정 아이템에 과도하게 할당되거나, 반대로 특정 코드가 거의 사용되지 않는 경우가 발생할 수 있다. 이렇게 되면 코드의 분포가 불균형해지고, 결과적으로 생성 모델이 특정 코드(또는 아이템)를 더 자주 생성하게 되는 아이템 생성 편향으로 이어질 수 있다.
- code : 의미적으로 풍부하고 계층화된 토큰의 집합으로, 아이템을 표현하기 위한 특별한 형태의 토큰
Figure
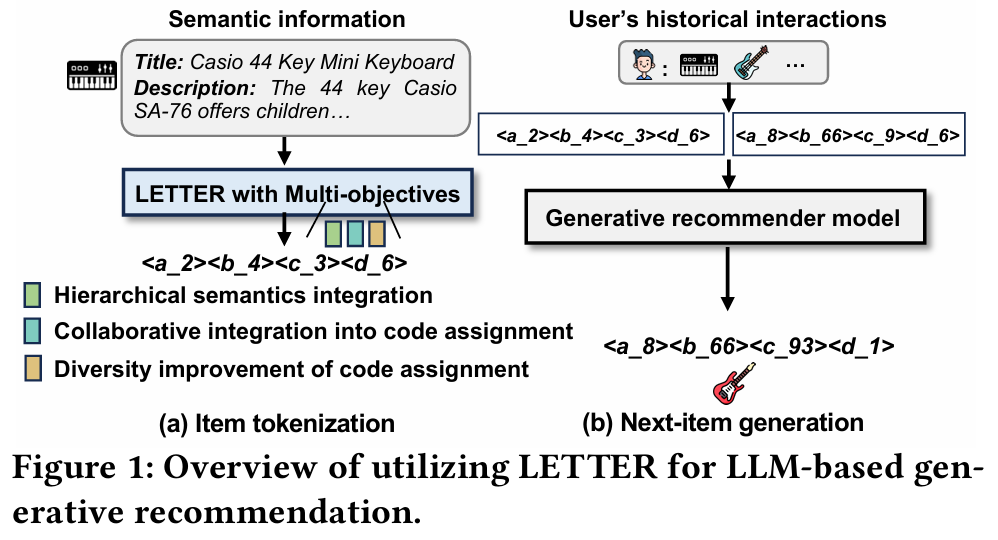
- Item Tokenization : 계층적 의미, 협력 신호, 다양성을 통합하여 아이템의 의미 정보를 토큰화한다.
- Next-Item Generation : 토큰화한 사용자의 상호작용 정보를 생성적 추천 모델에 입력하여 다음 아이템을 생성한다.
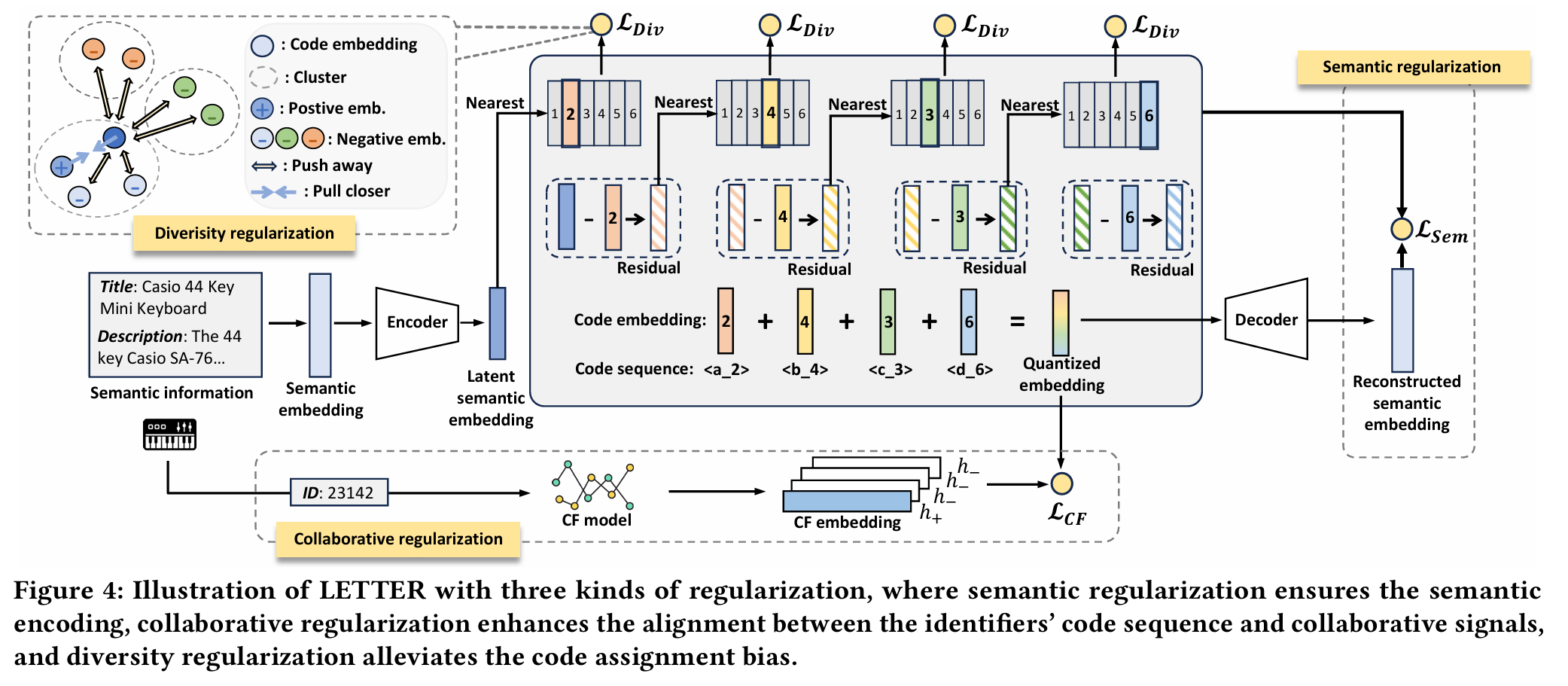
LETTER는 세 가지 정규화를 사용한다.
- Semantic Regularization : 의미 인코딩을 보장한다.
- Collaborative Regularization : 식별자의 코드 시퀀스와 협업 신호 간의 정렬을 강화한다.
- Diversity Regularization : 코드 할당 편향을 완화한다.
1. Introduction
1. 배경
- 생성적 추천에 LLM 활용이 중요 연구 분야로 부상하고 있다.
- 생성적 추천은 사용자가 과거에 상호 작용한 아이템을 기반으로 LLM을 사용하여 목표 아이템을 추천으로 생성하는 것을 목표로 한다.
- LLM을 통해 아이템을 인코딩하고 생성하는 데 핵심적인 문제는 아이템 토큰화이다.
- 아이템 토큰화는 각 아이템을 식별자(토큰 시퀀스)를 통해 인덱싱하여 추천 데이터와 LLM의 언어 공간 사이의 간극을 해소한다.
2. 기존 아이템 토큰화 방식의 문제점
- ID 식별자
- 각 아이템에 고유한 숫자 문자열을 할당하여 고유성을 보장한다.
- 의미 정보를 효율적으로 인코딩하지 못하므로 콜드 스타트 아이템을 일반화하는 데 어려움이 있다.
- 텍스트 식별자
- 아이템 제목, 속성, 설명 등 의미 정보를 직접 활용한다.
- 의미 정보가 식별자의 토큰 시퀀스에서 계층적으로 분산되지 않는다.
- 사용자 행동에서 얻어지는 협업 신호가 부족하다.
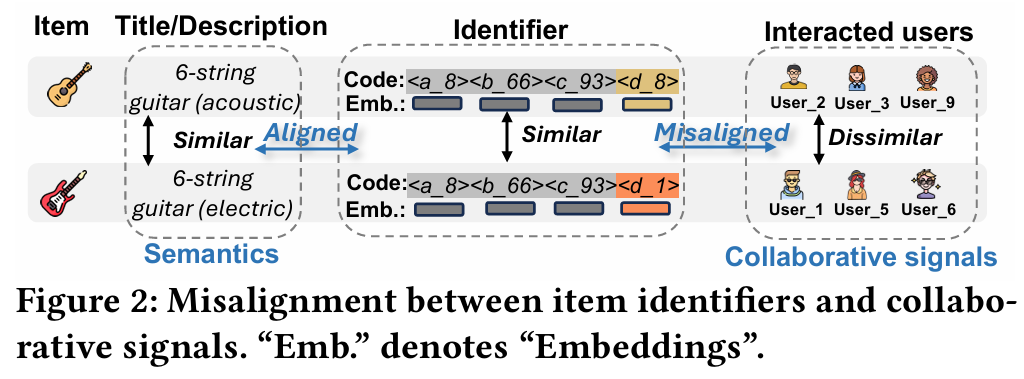
- 코드북 기반 방법
- 자동 인코더를 사용하여 아이템 의미를 계층적 코드 시퀀스로 인코딩한다.
- 텍스트 식별자와 유사하게 코드 시퀀스에 협업 신호가 부족하다.
- 아이템에 코드를 할당하는 것이 불균형하며, 빈도가 높은 코드를 가진 아이템이 더 쉽게 생성되는 아이템 생성 편향을 유발한다.
3. 이상적인 식별자의 기준
- 계층적 의미를 식별자에 통합 : 토큰 시퀀스가 처음에는 광범위하고 거친 수준의 의미를 인코딩하고 점진적으로 더 세련되고 세밀한 세부 사항으로 전환한다.
- 협업 신호를 토큰 할당에 통합 : 사용자 행동에서 유사한 협업 신호를 가진 아이템이 식별자로서 유사한 토큰 시퀀스를 갖도록 한다.
- 토큰 할당의 다양성 향상 : 아이템 생성 편향을 완화하여 아이템 생성의 다양성을 보장한다.
4. 제안 방법 : LETTER (Learnable Tokenizer for Generative Recommendation)
- 코드북 기반 식별자를 개선하기 위해 세 가지 종류의 정규화를 통합한다.
- 의미 정규화 : RQ-VAE(Residual Quantized VAE)를 통합하여 아이템 의미 정보를 계층적 식별자로 변환한다.
- 협업 정규화 : Contrastive Alignment Loss를 사용하여 RQ-VAE의 의미 양자화 임베딩을 잘 훈련된 CF 모델의 CF 임베딩과 정렬한다.
- 다양성 정규화 : Diversity Loss를 사용하여 코드 임베딩 다양성을 향상시켜 코드 할당 편향 및 아이템 생성 편향을 완화한다.
- LETTER를 두 개의 대표적인 생성적 추천 모델에 적용하고, 생성적 모델의 순위 능력을 이론적으로 향상시키기 위해 순위 기반 생성 Loss를 제안한다.
5. 실험 결과
- 세 개의 데이터 세트에 대한 광범위한 실험과 심층적인 조사를 통해 LETTER가 식별자에서 계층적 의미, 협업 신호 및 코드 할당 다양성을 동시에 고려하여 우수한 아이템 토큰화를 달성할 수 있음을 입증했다.
6. 기여
- 이상적인 식별자의 필요한 특징을 포괄적으로 분석하고, 새로운 학습 가능한 토크나이저 LETTER를 제안한다.
- LETTER를 생성적 추천 모델에 적용하고 순위 기반 생성 Loss를 활용하여 생성적 추천 모델의 순위 능력을 이론적으로 향상시킨다.
- 다양한 설정을 통한 심층적인 조사와 함께 세 개의 데이터 세트에 대한 광범위한 실험을 수행하여 LETTER가 기존 아이템 토큰화 방법보다 성능이 우수함을 입증한다.
2. Item Tokenization
1. 아이템 토큰화의 중요성
- LLM 기반 생성적 추천의 핵심 단계는 각 아이템에 식별자를 할당하는 아이템 토큰화다.
- 각 식별자는 LLM이 아이템을 인코딩하고 생성하는 데 도움을 주는 토큰 시퀀스다.
- 아이템 토큰화를 통해 LLM 기반 모델은 사용자 과거 상호 작용을 식별자 시퀀스로 변환하고, 다음 아이템 추천을 위해 아이템 식별자를 자동 회귀적으로 생성할 수 있다.
2. 기존 아이템 토큰화 방법의 한계
- 기존 방법은 ID 식별자, 텍스트 식별자, 코드북 기반 식별자를 사용한다.
- ID 식별자는 의미 인코딩 기능이 부족하다.
- 텍스트 및 코드북 기반 식별자는 다음과 같은 문제점을 가진다.
- 비계층적 의미 : 텍스트 식별자에서 의미 정보가 계층적으로 분산되지 않는다.
- 협업 신호 부족 : 토큰 시퀀스 구성 시 협업 신호를 고려하지 않는다. 비슷한 의미의 아이템은 비슷한 토큰 시퀀스를 공유하므로 협업 신호와 정렬하기 어렵다.
- 코드 할당 편향 : 코드북 기반 방법은 불균형한 코드 할당으로 인해 아이템 생성 편향이 발생한다. 인기있는 아이템 식별자가 생성될 가능성이 더 높다.
3. 이상적인 식별자의 목표
- 토큰 시퀀스와의 계층적 의미 통합
- 토큰 시퀀스에서의 협업 신호 통합
- 코드 할당의 높은 다양성 확보
3. Method
3.1 LETTER
LETTER : LEarnable Tokenizer for generaTivE Recommendation
LETTER는 LLM 기반 생성 추천(generative recommendation)을 위한 아이템 토크나이저(tokenizer)로, 세 가지 주요 목표를 달성하기 위해 설계되었다. 이 모델은 계층적인 의미를 가지는 식별자(identifier)를 생성하며, 협업 신호를 반영하고, 코드 할당 편향 문제를 완화하기 위한 정규화 기법들을 포함한다.
Semantic Regularization
LETTER는 계층적 의미를 갖는 식별자를 생성하기 위해 RQ-VAE에 기반한다. RQ-VAE는 다단계 임베딩 양자화 방식으로, semantic residual을 반복적으로 양자화하여 의미의 거칠고 세밀한 수준을 모두 포착할 수 있도록 한다.
-
의미 임베딩 추출 : 아이템의 제목이나 설명 등 콘텐츠 정보를 바탕으로 사전 학습된 의미 추출기(e.g. LLaMA-7B)를 사용하여 의미 임베딩 를 추출한다. 이 임베딩은 인코더를 통해 잠재 의미 임베딩 로 압축된다.
-
의미 임베딩 양자화 : 는 개의 코드북을 거쳐 양자화된다. 각 단계 에서 의미 잔차 과 가장 유사한 코드 임베딩 를 선택하여 로 업데이트하며, 최종적으로 식별자 를 생성한다.
-
Loss 함수 구성 : 의미 정규화를 위한 전체 Loss은 다음과 같다.
- 은 의미 임베딩의 재구성을 위한 Loss로, 로 정의된다.
- 는 각 단계에서의 양자화 오차를 줄이며 인코더와 코드 임베딩을 공동 학습한다.
이를 통해 LETTER는 계층적 의미를 반영한 코드 시퀀스를 생성할 수 있으며, 이를 바탕으로 세분화된 생성이나 콜드스타트 상황에서의 일반화를 용이하게 한다.
Collaborative Regularization
LETTER는 단순히 의미 정보만을 반영하는 것이 아니라, 협업 필터링(CF) 기반 추천 시스템에서의 협업 신호를 코드 시퀀스에 반영하기 위해 협업 정규화를 도입한다.
-
정규화 방식 : 학습된 CF 모델(SASRec, LightGCN 등)을 활용하여 아이템의 CF 임베딩 를 얻고, 양자화된 임베딩 와 정렬시킨다. 이 과정을 위해 대조 학습 기반의 Loss 함수 를 사용한다.
-
협업 정규화는 협업적으로 유사한 아이템들이 유사한 코드 시퀀스를 갖도록 유도한다. 이는 기존 TIGER와 같은 모델이 의미 정보에만 의존하는 방식과 차별화된다.
Diversity Regularization
코드 임베딩의 불균형한 분포는 코드 할당 편향을 초래할 수 있다. 이를 해결하기 위해 LETTER는 다양성 정규화를 적용한다.
-
정규화 방식 : 각 코드북 내 임베딩을 제약된 K-means로 클러스터링한 후, 동일 클러스터 내 임베딩은 끌어당기고(closing), 다른 클러스터 간 임베딩은 밀어내는(push apart) 방식의 Loss 함수 를 정의한다.
-
코드 임베딩 분포의 균형을 맞춤으로써 코드 할당 편향 문제를 완화하고, 더욱 균등하고 다양한 코드 시퀀스를 생성할 수 있다.
Overall Loss
여기서 와 는 협업 및 다양성 정규화의 기여도를 조절하는 하이퍼파라미터이다.
3.2 Instantiation
LETTER를 LLM 기반 생성 추천 모델에 적용하기 위해 먼저 추천 아이템을 대상으로 LETTER를 학습시킨다. 이후 학습이 완료된 LETTER는 LLM의 학습 및 추론 과정에서 아이템을 토크나이징하는 데 활용된다.
cf. Instantiation : 인스턴스화 (적용, 구현)
cf. 인스턴스화 : 클래스(class)에서 특정 객체(object)를 생성하는 과정
3.2.1 Training
생성 추천 모델의 학습은 아이템 토크나이징과 모델 최적화의 두 단계로 구성된다.
-
아이템 토크나이징 : 사전 학습된 LETTER를 사용하여 각 아이템을 식별자 로 인덱싱한다. 이후 사용자의 상호작용 이력을 식별자 시퀀스로 변환한다. 학습 데이터셋은 형태이며, 여기서 는 사용자의 시간 순 상호작용 시퀀스를, 는 다음 상호작용 아이템의 식별자를 의미한다.
-
순위 기반 생성 Loss (Ranking-guided Generation Loss) : 기존 연구에서는 Generation Loss를 통해 LLM을 학습시키지만, 이는 아이템 전체에 대한 순위 최적화를 고려하지 않아 추천 성능을 저해할 수 있다. 이를 개선하기 위해 LETTER는 순위 기반 생성 Loss인 을 제안한다.
이 Loss 함수는 어려운 부정 샘플(hard negatives)에 대해 더 큰 패널티를 주는 방식으로 설계되었으며, 온도 파라미터 를 조정함으로써 모델의 순위 예측 능력을 향상시킨다.
여기서 는 예측 대상 토큰, 는 그 이전의 시퀀스, 는 토큰 어휘 집합, 는 모델 파라미터, 는 온도 파라미터이다.
-
명제 :
- 최소화는 사용자에 대해 hard-negative 아이템을 최적화하는 것과 동치이다. 작은 값일수록 hard-negative에 대한 패널티가 강화된다.
- 이 Loss 함수는 one-way partial AUC 최적화와 관련이 있으며, 이는 Recall, NDCG와 같은 순위 기반 평가 지표와 강하게 연관되어 있으므로 top-K 추천 성능을 향상시킬 수 있다.
3.2.2 Inference
추론 시, 생성 추천 모델은 다음 아이템을 생성하기 위해 식별자 코드 시퀀스를 autoregressive 방식으로 생성한다. 이 과정은 다음과 같이 정의된다:
올바른 식별자만을 생성하기 위해 LETTER는 제약 생성(constrained generation) 기법을 활용한다. 이 때 Trie 자료구조를 사용하여, 현재까지 생성된 시퀀스를 기반으로 가능한 유효한 후속 토큰만을 생성하게 한다. 이는 모델이 구조적 제약을 만족하는 유효한 아이템 식별자만 생성하도록 돕는다.
Autoregressive
Autoregressive는 자기회귀라는 뜻으로, 이전 값들을 기반으로 현재 또는 미래 값을 예측하는 모델이나 기법을 의미한다. 이는 주로 시계열 데이터 분석이나 생성형 AI에서 사용된다. 자기회귀 모델은 현재 값이 과거 값의 함수라고 가정하며, 과거 데이터의 패턴을 학습하여 다음 값을 예측한다.
4. Experiments
RQ1 : LETTER는 다른 종류의 식별자들과 비교했을 때 얼마나 잘 작동할까?
RQ2 : LETTER의 구성 요소들, 예를 들어 협업 정규화나 다양성 정규화는 성능에 어떤 영향을 줄까?
RQ3 : 식별자 길이, 코드북 크기, 정규화 강도, 온도 같은 다양한 설정에서 LETTER는 어떻게 작동할까?
4.1 Experimental Settings
Datasets
- Instruments, Beauty : 아마존 리뷰 데이터 세트에서 가져온 것들이다.
- Yelp2 : Yelp 플랫폼의 데이터 세트이다.
- 데이터 전처리 과정 : 희소한 사용자나 아이템은 제거하고, 순차 추천 설정에 맞춰 데이터를 나누고, 사용자 기록 아이템 수는 20개로 제한한다.
Baselines
다양한 유형의 식별자 (ID, 텍스트, 코드북 기반)를 사용하는 모델들을 포함한다.
기존 추천 모델
- MF : 잠재 공간에서 사용자-아이템 상호 작용을 사용자 임베딩과 아이템 임베딩으로 분해한다.
- Caser : 컨볼루션 신경망을 사용하여 사용자의 공간 및 위치 정보를 포착한다.
- HGN : 그래프 신경망을 활용하여 사용자-아이템 상호 작용을 예측하기 위한 사용자 및 아이템 표현을 학습한다.
- BERT4Rec : BERT의 사전 훈련된 언어 표현을 활용하여 의미적 사용자-아이템 관계를 포착한다.
- LightGCN : 사용자와 아이템 간의 고차 연결에 초점을 맞춘 경량 그래프 컨볼루션 네트워크 모델이다.
- SASRec : self-attention 메커니즘을 사용하여 사용자 상호 작용 기록에서 장기 종속성을 포착한다.
LLM 기반 생성적 추천 모델
- BIGRec : 텍스트 식별자를 사용하는 LLM 기반 생성적 추천 모델로, 각 아이템은 해당 제목으로 표현된다.
- P5-TID : LLM 기반 생성적 추천 모델에 아이템 제목을 텍스트 식별자로 사용한다.
- P5-SemID : 아이템 메타데이터(e.g. 속성)를 활용하여 LLM 기반 생성적 추천 모델에 대한 ID 식별자를 구성한다.
- P5-CID : 아이템 공동 출현 그래프에서 파생된 스펙트럼 클러스터링 트리를 통해 LLM 기반 생성적 추천 모델에 대한 식별자에 협업 신호를 통합한다.
- TIGER : RQ-VAE를 통해 코드북 기반 식별자를 도입하여 LLM 기반 생성적 추천을 위해 의미 정보를 코드 시퀀스로 양자화한다.
- LC-Rec : 코드북 기반 식별자와 보조 정렬 작업을 사용하여 생성된 코드 시퀀스를 자연어와 연결하여 LLM의 지식을 더 잘 활용한다.
Evaluation Settings
top-K Recall(R@K)과 NDCG(N@K)를 지표로 사용하며, K는 5와 10으로 설정한다.
Implementation Details
- LETTER는 TIGER와 LC-Rec라는 대표적인 LLM 기반 생성적 추천 모델에 적용하여 실험한다.
TIGER / LC-Rec 설정
- TIGER는 논문에 제시된 내용을 바탕으로 직접 구현한다.
- LC-Rec는 파라미터 효율적인 파인튜닝 기법인 LoRA를 사용하여 LLaMA-7B 모델을 파인튜닝한다.
- 아이템 의미 임베딩을 얻기 위해 LLaMA-7B를 활용한다.
- 협업 정규화를 위해 SASRec에서 추출한 32차원 아이템 임베딩을 사용한다.
- 다양성 정규화에서는 클러스터 개수 K를 10으로 설정한다.
- 실험은 4개의 NVIDIA RTX A5000 GPU를 사용한다.
LETTER 설정
- RQ-VAE는 4레벨 코드북을 사용하며, 각 코드북은 32차원의 256개 코드 임베딩으로 구성된다.
- AdamW 옵티마이저를 사용하며, 학습률은 1e-3, 배치 크기는 1,024로 설정하여 20,000 에폭 동안 훈련한다.
- 하이퍼파라미터 튜닝을 통해 최적의 성능을 찾는다. (𝜇 = 0.25, 𝛼는 {1e-1, 2e-2, 1e-2, 1e-3}, 𝛽는 {1e-2, 1e-3, 1e-4, 1e-5} 범위에서 탐색)
- TIGER와 LC-Rec 모델을 파인튜닝할 때도 유효성 검사 성능을 기준으로 학습률을 조정한다.
4.2 Overall Performance (RQ1)
- 목표 : 다양한 모델들과 비교하여 LETTER의 전반적인 성능을 평가한다.
- 방법 : 두 개의 SOTA LLM 기반 생성적 추천 모델(TIGER, LC-Rec)에 LETTER를 적용하여 성능을 측정하고 비교한다. (LETTER-TIGER, LETTER-LC-Rec)
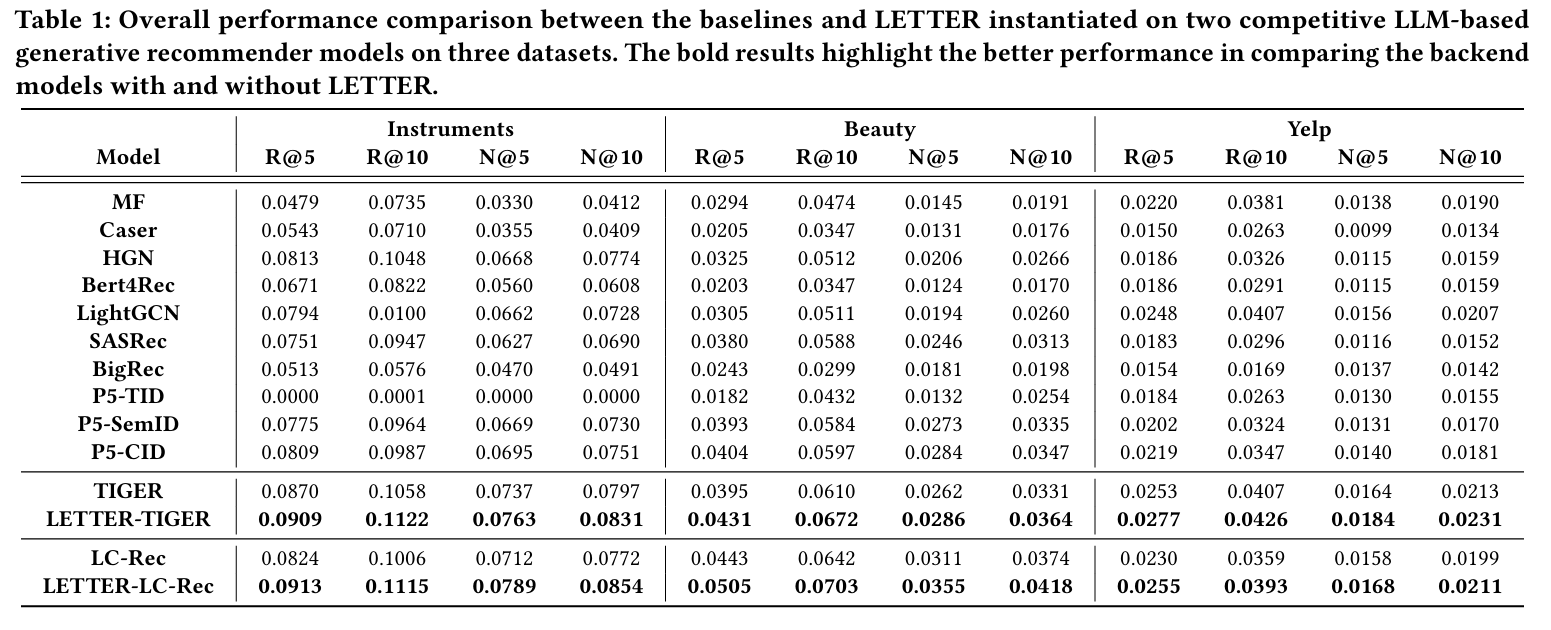
ID 식별자 기반 모델 비교
- P5-CID가 P5-SemID보다 전반적으로 우수한 성능을 보인다.
- P5-SemID의 단점 : 아이템 카테고리 기반 식별자 할당으로 인해 세분화된 의미 정보를 포착하지 못하고, 의미-협업 신호 불일치가 협업 학습을 방해한다.
- P5-CID의 장점 : 아이템 공동 출현 그래프의 협업 신호를 활용하고, 사용자 행동에서 협업 패턴을 포착한다.
다양한 식별자 기반 모델 비교
- 코드북 기반 식별자를 사용하는 모델(TIGER, LC-Rec)이 ID/텍스트 식별자 기반 모델보다 우수하다.
- 이유 : RQ-VAE로 여러 단계의 의미를 합쳐서 세세한 정보를 파악하고, 비슷한 아이템을 더 잘 구별한다.
- 텍스트 식별자 모델(BIGRec, P5-TID)의 약점 : 아이템 의미랑 실제 상호작용이 안 맞아서 협업 신호 학습이 잘 안 될 수 있다.
LETTER의 효과
- LETTER는 TIGER, LC-Rec에 적용했을 때 뚜렷한 성능 향상을 보인다.
- 이유 :
- CF 통합: 협업 신호와 의미 임베딩을 정렬하고, 유사한 아이템이 유사한 코드 시퀀스를 갖도록 하여 의미-협업 신호 불일치 문제를 해결한다.
- 향상된 토큰 할당 다양성: 코드 임베딩 표현 공간 정규화하여 코드 할당 편향으로 인한 아이템 생성 편향을 완화한다.
4.3 In-depth Analysis
4.3.1 Ablation Study (RQ2)
- 목표 : 각 정규화 방법이 성능에 미치는 영향을 분석한다.
- 방법 : TIGER에 대한 다섯 가지 LETTER 변형을 비교한다.
- TIGER : 의미 정규화만 사용
- TIGER w/ c. r. : 의미 및 협업 정규화 사용
- TIGER w/ d. r. : 의미 및 다양성 정규화 사용
- (1) w/ d. r. : 의미, 협업, 다양성 정규화 사용, 원래 생성 Loss로 훈련
- LETTER-TIGER : 모든 정규화 사용, 순위 기반 생성 Loss 적용
- 결과 :
- 협업 또는 다양성 정규화를 사용하면 TIGER의 성능이 향상된다. (협업 신호 주입, 코드 임베딩 다양성 개선 효과 확인)
- 세 가지 정규화를 모두 사용하여 아이템 토큰화를 최적화하면 성능이 더욱 향상된다. (코드 할당 시 의미와 협업 정보를 모두 고려하는 효과)
- LETTER-TIGER는 순위 기반 생성 Loss를 활용하여 최고의 성능을 달성한다. (온도 조절을 통해 어려운 부정적 샘플을 억제하여 순위 능력 강화)
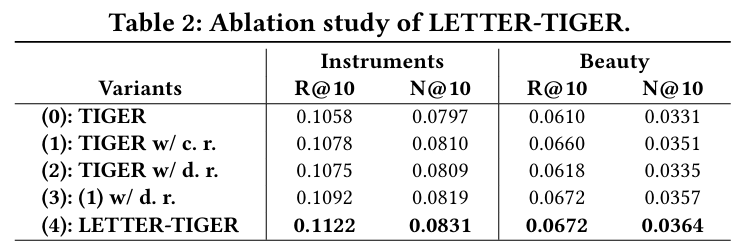
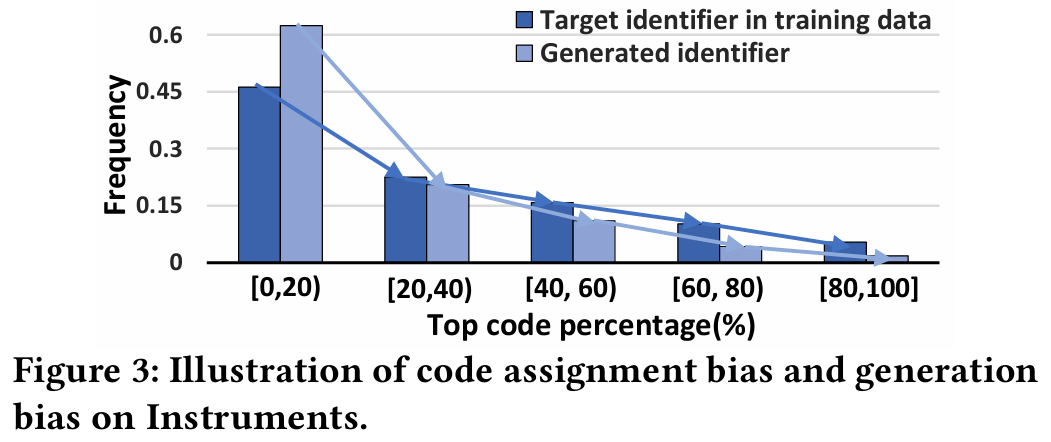
4.3.2 Code Assignment Distribution (RQ2)
- 목표 : 다양성 정규화가 아이템 토큰화에서 코드 할당 편향을 완화하는지 확인한다.
- 방법 :
- 다양성 정규화 유무에 따른 TIGER의 첫 번째 코드 분포를 비교한다.
- 다양성 및 협업 정규화 유무에 따른 TIGER의 첫 번째 코드 분포를 비교한다.
- 각 토큰화 방식에 대해 잘 훈련된 토크나이저로 아이템을 토큰화한 후, 첫 번째 코드를 빈도에 따라 정렬하고 그룹으로 나눈다.
- 결과 :
- 다양성 정규화를 사용하면 첫 번째 코드의 분포가 더 균일해져 코드 할당 편향을 완화하고 아이템 생성 편향을 줄일 수 있다.
- 다양성 정규화는 첫 번째 수준 코드북에서 코드 활용률을 높여 코드 할당의 다양성을 향상시킨다.
- 협업 정규화를 추가하면 코드 활용도가 감소하지만, 다양성 정규화를 통해 코드 활용도 감소를 보상한다.
- LETTER는 협업 신호를 캡처하고 높은 코드 활용도를 유지하여 이상적인 식별자의 여러 기준을 동시에 충족한다.
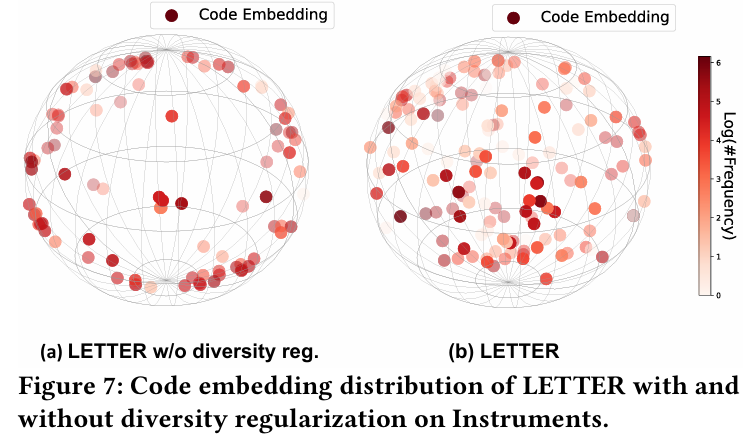
4.3.3 Code Embedding Distribution (RQ2)
- 목표 : 다양성 정규화가 코드 임베딩의 편향된 분포를 완화하는지 분석한다.
- 방법 :
- 다양성 정규화 유무에 따른 LETTER의 코드 임베딩을 시각화한다.
- 첫 번째 수준 코드북에서 코드 임베딩을 얻은 후 PCA를 통해 3차원 공간으로 차원 축소한다.
- 3차원 코드 임베딩을 구형 플롯에 표시하고, 각 점은 코드 임베딩 벡터를 나타내며, 더 어두운 색상은 더 많은 아이템에 할당된 코드를 나타낸다.
- 결과 :
- 다양성 정규화가 있는 LETTER는 코드 임베딩이 임베딩 표현 공간에서 더 고르게 분포되어 있다.
- 이는 표현 공간에서 코드 임베딩의 다양한 분포를 달성하기 위한 다양성 정규화의 효과를 검증하고, 코드 할당 편향 문제를 완화한다.
4.3.4 Investigation on Collaborative Signals in Identifiers (RQ2)
-
목표 : LETTER가 식별자에 협업 신호를 효과적으로 인코딩하는지 확인한다.
-
방법 : 두 가지 실험을 설계한다.
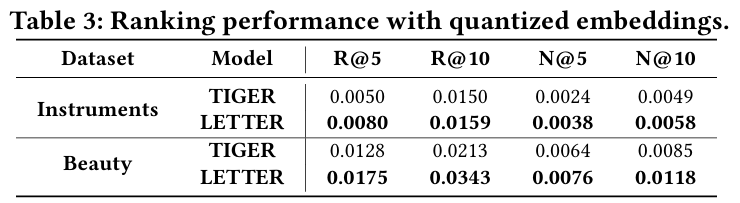
- 순위 실험 :
- 아이템의 양자화된 임베딩을 활용하여 상호 작용 예측을 수행하고 LETTER의 순위 성능을 평가한다.
- 잘 훈련된 기존 CF 모델(SASRec)의 아이템 임베딩을 양자화된 임베딩으로 대체한다.
- 협업 신호를 효과적으로 캡처하는 식별자는 더 나은 순위 성능을 나타낼 것이다.
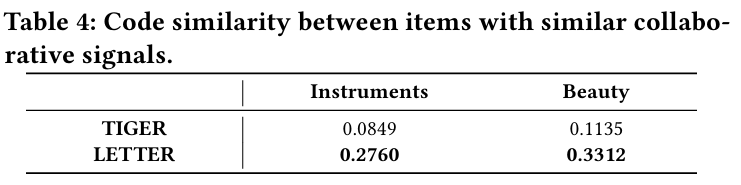
- 유사성 실험 :
- 유사한 협업 신호를 가진 아이템이 유사한 식별자를 나타내는지 확인한다.
- 사전 훈련된 CF 임베딩의 유사성을 기반으로 각 아이템을 가장 유사한 아이템과 쌍으로 묶는다.
- 아이템 쌍 내에서 코드 시퀀스의 유사성을 평가한다. (두 아이템의 코드 시퀀스 간 겹침 정도 측정)
- 순위 실험 :
-
결과 :
-
순위 실험 : LETTER가 TIGER보다 훨씬 뛰어난 성능을 보여 협업 신호의 효과적인 통합을 나타낸다.
-
유사성 실험 : LETTER는 TIGER보다 유사한 협업 신호를 가진 아이템에 대해 더 유사한 코드 시퀀스를 달성하여 의미와 협업 유사성 간의 불일치 문제를 완화한다.
-
4.3.5 Hyper-Parameter Analysis (RQ3)
목표 : LETTER에 도입된 주요 하이퍼파라미터가 성능에 미치는 영향을 분석하여 향후 응용에 도움을 준다.
분석 대상 및 방법
- 식별자 길이 𝐿 : 𝐿을 2에서 8로 변경하며 성능 변화를 관찰한다.
- 코드북 크기 𝑁 : 𝑁을 64, 128, 256, 512로 변경하며 성능 변화를 평가한다.
- 협업 정규화 강도 𝛼 : 𝛼를 0.001에서 0.1로 변경하며 성능 변화를 관찰한다.
- 다양성 정규화 강도 𝛽 : 𝛽를 0.00001에서 0.01로 조정하며 다양한 강도가 미치는 영향을 조사한다.
- 클러스터 𝐾 : 𝐾를 5에서 20으로 변경하며 성능 변화를 관찰한다.
- 온도 𝜏 : 𝜏를 0.6에서 1.2로 변경하며 LETTER-TIGER의 성능 변화를 평가한다.

분석 결과
- 식별자 길이 𝐿 :
- 𝐿을 2에서 4로 늘리면 성능이 향상된다. 지나치게 짧은 식별자는 세분화된 정보를 잃어 표현력이 약해질 수 있다.
- 𝐿을 4에서 8로 늘리면 성능이 저하된다. 자동 회귀 생성 시 오류 누적으로 어려움을 겪기 때문, 긴 식별자를 정확하게 생성하는 것이 더 어렵다.
- 코드북 크기 𝑁 :
- 𝑁을 점진적으로 늘리면 성능이 향상되는 경향이 있다. 작은 크기의 코드북은 코드 선택의 제한된 다양성으로 인해 아이템을 효과적으로 구별하지 못할 수 있다.
- 맹목적으로 𝑁을 확장하면 성능이 저하될 수 있다. 큰 코드북 크기는 아이템의 의미 정보에서 노이즈에 더 취약하여 의미 없는 일부 의미에 과적합될 수 있다.
- 협업 정규화 강도 𝛼 :
- 𝛼가 증가함에 따라 성능의 전체적인 추세는 일반적으로 개선된다. 𝛼가 클수록 협업 패턴의 주입이 강하지만, 지나치게 큰 𝛼는 의미 정규화를 방해할 수 있다.
- 경험적으로 𝛼 = 0.02로 설정하는 것이 좋다. 의미 및 협업 정규화 간의 적절한 균형을 달성하여 최상의 성능을 얻을 수 있다.
- 다양성 정규화 강도 𝛽 :
- 약간의 강도로 다양성 정규화를 적용하는 것만으로도 코드 할당의 다양성을 향상시키기에 충분하다. 𝛽 = 0.00001에서 𝛽 = 0.0001로 크게 개선
- 과도한 양의 다양성 신호는 의미 및 협업 신호의 토크나이저 통합을 방해할 수 있다.
- 클러스터 𝐾 :
- 𝐾를 10에서 줄이거나 늘리면 성능이 저하되는 경향이 있다.
- 지나치게 큰 클러스터는 너무 많은 코드 임베딩을 포함하여 동일한 클러스터 내의 임베딩이 충분히 가깝지 않고, 지나치게 작은 클러스터는 상대적으로 적은 코드 임베딩을 가지고 있어 동일한 클러스터 내의 임베딩이 지나치게 가깝기 때문이다.
- 온도 𝜏 :
- 𝜏를 1.2에서 0.7로 줄이면 성능이 저하되는 경향이 있다.
- 온도를 낮추면 어려운 부정적 샘플에 대한 페널티에 더 많은 강조점을 두어 순위 능력이 강화되어 추천 성능이 향상된다.
- 너무 작은 𝜏는 다른 사용자에 대해 어려운 부정적 샘플이 긍정적 샘플로 간주될 가능성을 억제할 수 있으므로 𝜏를 신중하게 선택해야 한다.
5. Related Work
생성적 추천을 위한 LLM (LLMs for Generative Recommendation)
LLM은 생성적 추천에 유망한 전망을 보여주며, 아이템 토큰화는 중요한 문제이다. 아이템 토큰화에 대한 기존 연구는 주로 세 가지 유형의 식별자를 조사한다.
-
ID 식별자
초기 단계에서 무작위로 할당된 ID는 아이템의 의미 정보 및 협업 패턴을 효과적으로 인코딩하는 데 어려움을 겪는다. SemID 및 CID와 같은 ID 식별자는 아이템 의미 정보 및 협업 신호를 각각 사용하여 식별자를 생성하기 위한 트리와 같은 구조를 구축한다. 그러나 이러한 고정되고 학습할 수 없는 구조는 아이템 유사성을 효율적이고 효과적으로 나타내고 새 아이템에 적응하기 어렵다. -
텍스트 식별자
아이템의 자세한 설명 정보를 식별자로 활용한다. 그럼에도 불구하고 이러한 방법은 의미 정보를 계층적으로 인코딩하거나 협업 신호를 통합하는 데 어려움을 겪는다. -
코드북 기반 식별자
코드북을 활용하고 훈련 과정에서 의미 정보와 협업 신호를 통합하려고 시도한다. 그러나 협업 신호를 고정된 코드 시퀀스에 통합함으로써 발생하는 불일치와 코드 할당 편향을 간과한다. 특히 LC-Rec는 Sinkhorn-Knopp 알고리즘을 사용하여 반복적인 정규화를 통해 레이어 내 코드를 공정하게 고려하지만 코드 할당의 본질인 코드 임베딩의 분포를 놓친다.
본 연구에서는 계층적 의미와 협업 신호 및 코드 할당 다양성을 통합하는 우수한 식별자를 제안한다.
판별적 추천을 위한 LLM (LLMs for Discriminative Recommendation)
LLM은 생성적 추천뿐만 아니라 다양한 판별적 추천 작업에도 광범위하게 사용된다. 판별적 추천을 위해 LLM을 활용하는 데는 두 가지 주요 접근 방식이 사용된다.
-
LLM으로 향상된 기존 추천 모델
데이터 증강 및 표현을 위해 LLM을 활용한다. -
LLM 기반 추천 모델
LLM을 추천 모델로 직접 활용한다. 순위 지정을 위해 사용자와 아이템 간의 일치 점수를 계산하기 위해 프로젝션 레이어를 통합하거나, 클릭률 (CTR) 예측을 위해 LLM을 활용하여 사용자가 이 아이템을 좋아할지 여부를 결정하기 위해 사용자 및 아이템 기능을 결합한다.
본 연구에서는 주로 생성적 추천을 위한 식별자 설계에 중점을 두므로 판별적 방법과의 심층적인 논의 및 비교는 다루지 않는다.
6. Conclusion and Future Work
-
본 연구에서는 생성적 추천에서 아이템 토큰화에 필요한 최적의 기능에 대한 철저한 분석을 수행했다.
-
그 결과 아이템 식별자 내에서 계층적 의미, 협업 신호 및 코드 할당 다양성을 캡처하는 것을 목표로 하는 세 가지 형태의 정규화를 통합하는 학습 가능한 토크나이저인 LETTER를 도입했다.
-
LETTER를 두 개의 주요 생성적 추천 모델에 적용하고 순위 성능을 향상시키기 위해 순위 기반 생성 Loss를 사용했다.
-
광범위한 실험을 통해 생성적 추천 모델에서 아이템 토큰화에 대한 LETTER의 우수성을 입증했다.
향후 연구 방향
- 여러 사용자 행동에서 사용자 선호도를 추론할 수 있도록 생성적 추천 모델을 활성화하기 위해 풍부한 사용자 행동으로 토큰화한다.
- LETTER는 개방형 추천을 위해 교차 도메인 아이템을 토큰화할 수 있는 잠재력이 있어 생성적 추천 모델이 사용자 선호도 추론 및 다음 아이템 추천을 위해 다중 도메인 사용자 행동 및 아이템을 활용할 수 있다.
- 생성적 추천 모델 공간에서 복잡한 자연어 지침 및 아이템 토큰을 사용하여 협업 추론을 달성하기 위해 자연어로 된 사용자 지침과 LETTER로 토큰화된 사용자 상호 작용 기록을 결합하는 것이 유망하다.
